| 1 | Adversarial Rademacher Complexity of Deep Neural Networks | 6.25 | 7.50 | 1.25 | | Reject |
| 2 | Deconfounding to Explanation Evaluation in Graph Neural Networks | 6.75 | 7.50 | 0.75 | | Reject |
| 3 | Low-rank Matrix Recovery with Unknown Correspondence | 7.25 | 7.25 | 0.00 | | Reject |
| 4 | A Branch and Bound Framework for Stronger Adversarial Attacks of ReLU Networks | 5.50 | 7.00 | 1.50 | | Reject |
| 5 | Multi-scale Feature Learning Dynamics: Insights for Double Descent | 7.00 | 7.00 | 0.00 | | Reject |
| 6 | Efficient and Modular Implicit Differentiation | 6.33 | 7.00 | 0.67 | | Reject |
| 7 | Flow-based Recurrent Belief State Learning for POMDPs | 5.00 | 7.00 | 2.00 | | Reject |
| 8 | DP-REC: Private & Communication-Efficient Federated Learning | 5.75 | 7.00 | 1.25 | | Reject |
| 9 | Sharp Learning Bounds for Contrastive Unsupervised Representation Learning | 6.40 | 6.80 | 0.40 | | 5, 8, 5, 8, 6 | | 6, 8, 6, 8, 6 |
| Reject |
| 10 | EqR: Equivariant Representations for Data-Efficient Reinforcement Learning | 5.50 | 6.75 | 1.25 | | Reject |
| 11 | Lottery Tickets can have Structural Sparsity | 5.75 | 6.75 | 1.00 | | Reject |
| 12 | Trainable Learning Rate | 6.67 | 6.67 | 0.00 | | 10, 8, 6, 8, 3, 5 | | 10, 8, 6, 8, 3, 5 |
| Reject |
| 13 | AQUILA: Communication Efficient Federated Learning with Adaptive Quantization of Lazily-Aggregated Gradients | 6.67 | 6.67 | 0.00 | | Reject |
| 14 | DIVERSIFY to Generalize: Learning Generalized Representations for Time Series Classification | 6.00 | 6.67 | 0.67 | | Reject |
| 15 | Transformer with a Mixture of Gaussian Keys | 5.60 | 6.60 | 1.00 | | 6, 5, 6, 5, 6 | | 6, 6, 8, 5, 8 |
| Reject |
| 16 | Hierarchical Modular Framework for Long Horizon Instruction Following | 5.50 | 6.60 | 1.10 | | Reject |
| 17 | Revisiting Out-of-Distribution Detection: A Simple Baseline is Surprisingly Effective | 6.40 | 6.60 | 0.20 | | 8, 10, 5, 3, 6 | | 8, 10, 6, 3, 6 |
| Reject |
| 18 | NormFormer: Improved Transformer Pretraining with Extra Normalization | 5.25 | 6.50 | 1.25 | | Reject |
| 19 | Lottery Image Prior | 4.75 | 6.50 | 1.75 | | Reject |
| 20 | Decision boundary variability and generalization in neural networks | 5.50 | 6.50 | 1.00 | | Reject |
| 21 | Unsupervised Pose-Aware Part Decomposition for 3D Articulated Objects | 6.50 | 6.50 | 0.00 | | Reject |
| 22 | Dynamic Least-Squares Regression | 5.75 | 6.50 | 0.75 | | Reject |
| 23 | DFSSATTEN: Dynamic Fine-grained Structured Sparse Attention Mechanism | 6.00 | 6.50 | 0.50 | | Reject |
| 24 | Transferring Hierarchical Structure with Dual Meta Imitation Learning | 6.00 | 6.50 | 0.50 | | Reject |
| 25 | Boosting the Confidence of Near-Tight Generalization Bounds for Uniformly Stable Randomized Algorithms | 6.50 | 6.50 | 0.00 | | Reject |
| 26 | WaveCorr: Deep Reinforcement Learning with Permutation Invariant Policy Networks for Portfolio Management | 6.50 | 6.50 | 0.00 | | Reject |
| 27 | Direct Evolutionary Optimization of Variational Autoencoders With Binary Latents | 6.00 | 6.40 | 0.40 | | 5, 6, 8, 6, 5 | | 5, 8, 8, 6, 5 |
| Reject |
| 28 | Designing Less Forgetful Networks for Continual Learning | 5.80 | 6.40 | 0.60 | | 6, 5, 8, 5, 5 | | 8, 6, 8, 5, 5 |
| Reject |
| 29 | A Geometric Perspective on Variational Autoencoders | 5.80 | 6.40 | 0.60 | | 5, 5, 6, 5, 8 | | 6, 6, 6, 6, 8 |
| Reject |
| 30 | If your data distribution shifts, use self-learning | 6.33 | 6.33 | 0.00 | | Reject |
| 31 | Natural Attribute-based Shift Detection | 6.33 | 6.33 | 0.00 | | Reject |
| 32 | Public Data-Assisted Mirror Descent for Private Model Training | 3.00 | 6.33 | 3.33 | | Reject |
| 33 | Recurrent Model-Free RL is a Strong Baseline for Many POMDPs | 5.67 | 6.33 | 0.67 | | Reject |
| 34 | Robust Cross-Modal Semi-supervised Few Shot Learning | 5.67 | 6.33 | 0.67 | | Reject |
| 35 | Independent Component Alignment for Multi-task Learning | 5.67 | 6.33 | 0.67 | | Reject |
| 36 | Learning Similarity Metrics for Volumetric Simulations with Multiscale CNNs | 6.33 | 6.33 | 0.00 | | Reject |
| 37 | Complex-valued deep learning with differential privacy | 6.00 | 6.33 | 0.33 | | Reject |
| 38 | FrugalMCT: Efficient Online ML API Selection for Multi-Label Classification Tasks | 6.25 | 6.25 | 0.00 | | Reject |
| 39 | Generalization in Deep RL for TSP Problems via Equivariance and Local Search | 5.25 | 6.25 | 1.00 | | Reject |
| 40 | CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery | 6.25 | 6.25 | 0.00 | | Reject |
| 41 | Subjective Learning for Open-Ended Data | 5.25 | 6.25 | 1.00 | | Reject |
| 42 | Faster No-Regret Learning Dynamics for Extensive-Form Correlated Equilibrium | 6.25 | 6.25 | 0.00 | | Reject |
| 43 | RieszNet and ForestRiesz: Automatic Debiased Machine Learning with Neural Nets and Random Forests | 5.50 | 6.25 | 0.75 | | Reject |
| 44 | Recursive Construction of Stable Assemblies of Recurrent Neural Networks | 5.50 | 6.25 | 0.75 | | Reject |
| 45 | Online approximate factorization of a kernel matrix by a Hebbian neural network | 5.25 | 6.25 | 1.00 | | Reject |
| 46 | Universal Joint Approximation of Manifolds and Densities by Simple Injective Flows | 5.50 | 6.25 | 0.75 | | Reject |
| 47 | Max-Affine Spline Insights Into Deep Network Pruning | 5.50 | 6.25 | 0.75 | | Reject |
| 48 | Domain-wise Adversarial Training for Out-of-Distribution Generalization | 5.25 | 6.25 | 1.00 | | Reject |
| 49 | Structure by Architecture: Disentangled Representations without Regularization | 6.25 | 6.25 | 0.00 | | Reject |
| 50 | Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation | 5.50 | 6.25 | 0.75 | | Reject |
| 51 | Best Practices in Pool-based Active Learning for Image Classification | 5.25 | 6.25 | 1.00 | | Reject |
| 52 | Robust Losses for Learning Value Functions | 5.75 | 6.25 | 0.50 | | Reject |
| 53 | End-to-End Balancing for Causal Continuous Treatment-Effect Estimation | 6.75 | 6.25 | -0.50 | | Reject |
| 54 | Auditing AI models for Verified Deployment under Semantic Specifications | 6.25 | 6.25 | 0.00 | | Reject |
| 55 | Meta-Learning Dynamics Forecasting Using Task Inference | 6.25 | 6.25 | 0.00 | | Reject |
| 56 | Normalized Attention Without Probability Cage | 6.00 | 6.25 | 0.25 | | Reject |
| 57 | ANCER: Anisotropic Certification via Sample-wise Volume Maximization | 5.50 | 6.25 | 0.75 | | Reject |
| 58 | Synthesising Audio Adversarial Examples for Automatic Speech Recognition | 6.25 | 6.25 | 0.00 | | Reject |
| 59 | Privacy-preserving Task-Agnostic Vision Transformer for Image Processing | 5.50 | 6.25 | 0.75 | | Reject |
| 60 | On the Convergence of Projected Alternating Maximization for Equitable and Optimal Transport | 6.33 | 6.25 | -0.08 | | Reject |
| 61 | Lower Bounds on the Robustness of Fixed Feature Extractors to Test-time Adversaries | 5.40 | 6.20 | 0.80 | | 5, 8, 6, 3, 5 | | 6, 8, 6, 6, 5 |
| Reject |
| 62 | A theoretically grounded characterization of feature representations | 5.20 | 6.20 | 1.00 | | 6, 3, 8, 3, 6 | | 6, 6, 8, 5, 6 |
| Reject |
| 63 | The Geometry of Adversarial Subspaces | 4.25 | 6.00 | 1.75 | | Reject |
| 64 | Multi-Objective Online Learning | 5.50 | 6.00 | 0.50 | | Reject |
| 65 | ModeRNN: Harnessing Spatiotemporal Mode Collapse in Unsupervised Predictive Learning | 4.67 | 6.00 | 1.33 | | Reject |
| 66 | Generate, Annotate, and Learn: Generative Models Advance Self-Training and Knowledge Distillation | 6.50 | 6.00 | -0.50 | | Reject |
| 67 | Tesseract: Gradient Flip Score to Secure Federated Learning against Model Poisoning Attacks | 5.25 | 6.00 | 0.75 | | Reject |
| 68 | On the Relationship between Heterophily and Robustness of Graph Neural Networks | 4.25 | 6.00 | 1.75 | | Reject |
| 69 | Adaptive Cross-Layer Attention for Image Restoration | 6.00 | 6.00 | 0.00 | | Reject |
| 70 | C-MinHash: Improving Minwise Hashing with Circulant Permutation | 5.25 | 6.00 | 0.75 | | Reject |
| 71 | Adam is no better than normalized SGD: Dissecting how adaptivity improves GAN performance | 6.00 | 6.00 | 0.00 | | Reject |
| 72 | HydraSum - Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models | 5.75 | 6.00 | 0.25 | | Reject |
| 73 | Data Quality Matters For Adversarial Training: An Empirical Study | 5.67 | 6.00 | 0.33 | | Reject |
| 74 | Zero-Shot Coordination via Semantic Relationships Between Actions and Observations | 5.50 | 6.00 | 0.50 | | Reject |
| 75 | Multi-agent Performative Prediction: From Global Stability and Optimality to Chaos | 5.33 | 6.00 | 0.67 | | Reject |
| 76 | Conditional Expectation based Value Decomposition for Scalable On-Demand Ride Pooling | 6.00 | 6.00 | 0.00 | | Reject |
| 77 | Image2Point: 3D Point-Cloud Understanding with 2D Image Pretrained Models | 6.20 | 6.00 | -0.20 | | 8, 5, 5, 8, 5 | | 6, 6, 6, 6, 6 |
| Reject |
| 78 | Understanding Metric Learning on Unit Hypersphere and Generating Better Examples for Adversarial Training | 5.50 | 6.00 | 0.50 | | Reject |
| 79 | Distance-Based Background Class Regularization for Open-Set Recognition | 6.00 | 6.00 | 0.00 | | Reject |
| 80 | Decoupled Kernel Neural Processes: Neural Network-Parameterized Stochastic Processes using Explicit Data-driven Kernel | 5.50 | 6.00 | 0.50 | | Reject |
| 81 | Self-GenomeNet: Self-supervised Learning with Reverse-Complement Context Prediction for Nucleotide-level Genomics Data | 4.75 | 6.00 | 1.25 | | Reject |
| 82 | Learning Symmetric Representations for Equivariant World Models | 5.50 | 6.00 | 0.50 | | Reject |
| 83 | SplitRegex: Faster Regex Synthesis via Neural Example Splitting | 6.00 | 6.00 | 0.00 | | Reject |
| 84 | Trading Coverage for Precision: Conformal Prediction with Limited False Discoveries | 5.50 | 6.00 | 0.50 | | Reject |
| 85 | Test Time Robustification of Deep Models via Adaptation and Augmentation | 4.75 | 6.00 | 1.25 | | Reject |
| 86 | Weakly Supervised Label Learning Flows | 6.40 | 6.00 | -0.40 | | 8, 5, 5, 6, 8 | | 6, 5, 5, 6, 8 |
| Reject |
| 87 | Relative Molecule Self-Attention Transformer | 5.67 | 6.00 | 0.33 | | Reject |
| 88 | Exploiting Redundancy: Separable Group Convolutional Networks on Lie Groups | 5.50 | 6.00 | 0.50 | | Reject |
| 89 | Cluster-based Feature Importance Learning for Electronic Health Record Time-series | 5.00 | 6.00 | 1.00 | | Reject |
| 90 | Beyond Target Networks: Improving DeepQ-learning with Functional Regularization | 6.00 | 6.00 | 0.00 | | Reject |
| 91 | A Joint Subspace View to Convolutional Neural Networks | 5.60 | 6.00 | 0.40 | | 5, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
| Reject |
| 92 | Specialized Transformers: Faster, Smaller and more Accurate NLP Models | 5.00 | 6.00 | 1.00 | | Reject |
| 93 | Better state exploration using action sequence equivalence | 5.33 | 6.00 | 0.67 | | Reject |
| 94 | Momentum Doesn't Change The Implicit Bias | 4.25 | 6.00 | 1.75 | | Reject |
| 95 | Token Pooling in Vision Transformers | 6.00 | 6.00 | 0.00 | | Reject |
| 96 | High Fidelity Visualization of What Your Self-Supervised Representation Knows About | 5.75 | 6.00 | 0.25 | | Reject |
| 97 | Programmable 3D snapshot microscopy with Fourier convolutional networks | 5.50 | 6.00 | 0.50 | | Reject |
| 98 | Distribution Matching in Deep Generative Models with Kernel Transfer Operators | 5.00 | 6.00 | 1.00 | | Reject |
| 99 | Mistill: Distilling Distributed Network Protocols from Examples | 4.25 | 6.00 | 1.75 | | Reject |
| 100 | Newer is not always better: Rethinking transferability metrics, their peculiarities, stability and performance | 6.00 | 6.00 | 0.00 | | Reject |
| 101 | GrASP: Gradient-Based Affordance Selection for Planning | 6.00 | 6.00 | 0.00 | | Reject |
| 102 | CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP | 5.50 | 6.00 | 0.50 | | Reject |
| 103 | ZenDet: Revisiting Efficient Object Detection Backbones from Zero-Shot Neural Architecture Search | 5.33 | 6.00 | 0.67 | | Reject |
| 104 | Zero-Cost Operation Scoring in Differentiable Architecture Search | 5.50 | 6.00 | 0.50 | | Reject |
| 105 | Sample and Communication-Efficient Decentralized Actor-Critic Algorithms with Finite-Time Analysis | 6.00 | 6.00 | 0.00 | | Reject |
| 106 | Effects of Data Geometry in Early Deep Learning | 6.00 | 6.00 | 0.00 | | Reject |
| 107 | Neural Simulated Annealing | 5.50 | 6.00 | 0.50 | | Reject |
| 108 | Information-Aware Time Series Meta-Contrastive Learning | 6.33 | 6.00 | -0.33 | | Reject |
| 109 | Thinking Deeper With Recurrent Networks: Logical Extrapolation Without Overthinking | 5.75 | 6.00 | 0.25 | | Reject |
| 110 | Transfer Learning for Bayesian HPO with End-to-End Meta-Features | 5.80 | 6.00 | 0.20 | | 5, 5, 8, 6, 5 | | 5, 6, 8, 6, 5 |
| Reject |
| 111 | G3: Representation Learning and Generation for Geometric Graphs | 5.50 | 6.00 | 0.50 | | Reject |
| 112 | ProgFed: Effective, Communication, and Computation Efficient Federated Learning by Progressive Training | 5.00 | 6.00 | 1.00 | | Reject |
| 113 | Lightweight Convolutional Neural Networks By Hypercomplex Parameterization | 4.50 | 6.00 | 1.50 | | Reject |
| 114 | Safe Linear-Quadratic Dual Control with Almost Sure Performance Guarantee | 5.25 | 6.00 | 0.75 | | Reject |
| 115 | Semi-supervised learning of partial differential operators and dynamical flows | 5.33 | 6.00 | 0.67 | | Reject |
| 116 | How to measure deep uncertainty estimation performance and which models are naturally better at providing it | 5.40 | 6.00 | 0.60 | | 3, 10, 6, 3, 5 | | 6, 8, 6, 5, 5 |
| Reject |
| 117 | Patches Are All You Need? | 5.33 | 6.00 | 0.67 | | Reject |
| 118 | Adversarial Style Transfer for Robust Policy Optimization in Reinforcement Learning | 5.00 | 6.00 | 1.00 | | Reject |
| 119 | Is Heterophily A Real Nightmare For Graph Neural Networks on Performing Node Classification? | 6.00 | 6.00 | 0.00 | | Reject |
| 120 | Repairing Systematic Outliers by Learning Clean Subspaces in VAEs | 5.67 | 6.00 | 0.33 | | Reject |
| 121 | Zeroth-Order Actor-Critic | 5.00 | 6.00 | 1.00 | | Reject |
| 122 | Counterfactual Graph Learning for Link Prediction | 6.50 | 6.00 | -0.50 | | Reject |
| 123 | Physics Informed Convex Artificial Neural Networks (PICANNs) for Optimal Transport based Density Estimation | 5.50 | 6.00 | 0.50 | | Reject |
| 124 | Attentional meta-learners for few-shot polythetic classification | 5.00 | 6.00 | 1.00 | | Reject |
| 125 | SoftHebb: Bayesian inference in unsupervised Hebbian soft winner-take-all networks | 4.75 | 6.00 | 1.25 | | Reject |
| 126 | Towards Unsupervised Content Disentanglement in Sentence Representations via Syntactic Roles | 4.75 | 6.00 | 1.25 | | Reject |
| 127 | Linear algebra with transformers | 5.50 | 6.00 | 0.50 | | Reject |
| 128 | Exploiting Minimum-Variance Policy Evaluation for Policy Optimization | 6.00 | 6.00 | 0.00 | | Reject |
| 129 | Deep Classifiers with Label Noise Modeling and Distance Awareness | 5.75 | 6.00 | 0.25 | | Reject |
| 130 | Fast Adaptive Anomaly Detection | 6.00 | 6.00 | 0.00 | | 8, 6, 3, 8, 5 | | 8, 6, 3, 8, 5 |
| Reject |
| 131 | Hypergraph Convolutional Networks via Equivalency between Hypergraphs and Undirected Graphs | 6.00 | 6.00 | 0.00 | | Reject |
| 132 | GSmooth: Certified Robustness against Semantic Transformations via Generalized Randomized Smoothing | 4.75 | 6.00 | 1.25 | | Reject |
| 133 | Collaboration of Experts: Achieving 80% Top-1 Accuracy on ImageNet with 100M FLOPs | 5.25 | 6.00 | 0.75 | | Reject |
| 134 | Conditional GANs with Auxiliary Discriminative Classifier | 5.25 | 6.00 | 0.75 | | Reject |
| 135 | ZARTS: On Zero-order Optimization for Neural Architecture Search | 6.00 | 6.00 | 0.00 | | Reject |
| 136 | EVaDE : Event-Based Variational Thompson Sampling for Model-Based Reinforcement Learning | 5.50 | 6.00 | 0.50 | | Reject |
| 137 | Towards the Memorization Effect of Neural Networks in Adversarial Training | 4.75 | 6.00 | 1.25 | | Reject |
| 138 | Adversarial Style Augmentation for Domain Generalized Urban-Scene Segmentation | 6.00 | 6.00 | 0.00 | | Reject |
| 139 | Variational Component Decoder for Source Extraction from Nonlinear Mixture | 5.50 | 6.00 | 0.50 | | Reject |
| 140 | Fact-driven Logical Reasoning | 5.25 | 6.00 | 0.75 | | Reject |
| 141 | Adaptive Label Smoothing with Self-Knowledge | 5.75 | 6.00 | 0.25 | | Reject |
| 142 | ScheduleNet: Learn to solve multi-agent scheduling problems with reinforcement learning | 5.75 | 6.00 | 0.25 | | Reject |
| 143 | Self-Supervised Structured Representations for Deep Reinforcement Learning | 6.00 | 6.00 | 0.00 | | Reject |
| 144 | Indiscriminate Poisoning Attacks Are Shortcuts | 5.00 | 6.00 | 1.00 | | Reject |
| 145 | ST-DDPM: Explore Class Clustering for Conditional Diffusion Probabilistic Models | 5.50 | 6.00 | 0.50 | | Reject |
| 146 | How BPE Affects Memorization in Transformers | 5.33 | 6.00 | 0.67 | | Reject |
| 147 | Gotta Go Fast When Generating Data with Score-Based Models | 5.25 | 6.00 | 0.75 | | Reject |
| 148 | Global Convergence and Stability of Stochastic Gradient Descent | 6.00 | 6.00 | 0.00 | | Reject |
| 149 | New Perspective on the Global Convergence of Finite-Sum Optimization | 4.75 | 6.00 | 1.25 | | Reject |
| 150 | Sharper Utility Bounds for Differentially Private Models | 6.00 | 6.00 | 0.00 | | Reject |
| 151 | Practical No-box Adversarial Attacks with Training-free Hybrid Image Transformation | 5.50 | 6.00 | 0.50 | | Reject |
| 152 | Mean-Variance Efficient Reinforcement Learning by Expected Quadratic Utility Maximization | 5.80 | 5.80 | 0.00 | | 5, 8, 6, 5, 5 | | 5, 8, 6, 5, 5 |
| Reject |
| 153 | Mixed-Memory RNNs for Learning Long-term Dependencies in Irregularly Sampled Time Series | 5.40 | 5.80 | 0.40 | | 5, 5, 3, 8, 6 | | 5, 5, 3, 8, 8 |
| Reject |
| 154 | Self-Supervised Prime-Dual Networks for Few-Shot Image Classification | 5.60 | 5.80 | 0.20 | | 5, 5, 6, 6, 6 | | 6, 5, 6, 6, 6 |
| Reject |
| 155 | k-Median Clustering via Metric Embedding: Towards Better Initialization with Privacy | 5.50 | 5.75 | 0.25 | | Reject |
| 156 | Reducing the Teacher-Student Gap via Adaptive Temperatures | 5.75 | 5.75 | 0.00 | | Reject |
| 157 | Self-Supervise, Refine, Repeat: Improving Unsupervised Anomaly Detection | 5.67 | 5.75 | 0.08 | | Reject |
| 158 | SeqPATE: Differentially Private Text Generation via Knowledge Distillation | 5.50 | 5.75 | 0.25 | | Reject |
| 159 | HALP: Hardware-Aware Latency Pruning | 5.50 | 5.75 | 0.25 | | Reject |
| 160 | Contrastive Attraction and Contrastive Repulsion for Representation Learning | 5.75 | 5.75 | 0.00 | | Reject |
| 161 | PMIC: Improving Multi-Agent Reinforcement Learning with Progressive Mutual Information Collaboration | 4.75 | 5.75 | 1.00 | | Reject |
| 162 | Accelerating Stochastic Simulation with Interactive Neural Processes | 5.25 | 5.75 | 0.50 | | Reject |
| 163 | Invariance Through Inference | 5.00 | 5.75 | 0.75 | | Reject |
| 164 | Action-Sufficient State Representation Learning for Control with Structural Constraints | 5.75 | 5.75 | 0.00 | | Reject |
| 165 | EAT-C: Environment-Adversarial sub-Task Curriculum for Efficient Reinforcement Learning | 5.50 | 5.75 | 0.25 | | Reject |
| 166 | Degradation Attacks on Certifiably Robust Neural Networks | 4.00 | 5.75 | 1.75 | | Reject |
| 167 | Double Descent in Adversarial Training: An Implicit Label Noise Perspective | 5.50 | 5.75 | 0.25 | | Reject |
| 168 | Estimating and Penalizing Induced Preference Shifts in Recommender Systems | 4.67 | 5.75 | 1.08 | | Reject |
| 169 | Learning Symmetric Locomotion using Cumulative Fatigue for Reinforcement Learning | 5.50 | 5.75 | 0.25 | | Reject |
| 170 | Why Should I Trust You, Bellman? Evaluating the Bellman Objective with Off-Policy Data | 5.25 | 5.75 | 0.50 | | Reject |
| 171 | Test-Time Adaptation to Distribution Shifts by Confidence Maximization and Input Transformation | 5.25 | 5.75 | 0.50 | | Reject |
| 172 | Exploring Non-Contrastive Representation Learning for Deep Clustering | 5.25 | 5.75 | 0.50 | | Reject |
| 173 | Meaningfully Explaining Model Mistakes Using Conceptual Counterfactuals | 4.50 | 5.75 | 1.25 | | Reject |
| 174 | Sound Source Detection from Raw Waveforms with Multi-Scale Synperiodic Filterbanks | 5.00 | 5.75 | 0.75 | | Reject |
| 175 | Do Androids Dream of Electric Fences? Safety-Aware Reinforcement Learning with Latent Shielding | 4.25 | 5.75 | 1.50 | | Reject |
| 176 | f-Mutual Information Contrastive Learning | 5.00 | 5.75 | 0.75 | | Reject |
| 177 | Stabilized Likelihood-based Imitation Learning via Denoising Continuous Normalizing Flow | 5.75 | 5.75 | 0.00 | | Reject |
| 178 | Learning Audio-Visual Dereverberation | 5.50 | 5.75 | 0.25 | | Reject |
| 179 | Complex Locomotion Skill Learning via Differentiable Physics | 5.50 | 5.75 | 0.25 | | Reject |
| 180 | Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training | 4.75 | 5.75 | 1.00 | | Reject |
| 181 | Dense Gaussian Processes for Few-Shot Segmentation | 5.75 | 5.75 | 0.00 | | Reject |
| 182 | Loss Function Learning for Domain Generalization by Implicit Gradient | 5.25 | 5.75 | 0.50 | | Reject |
| 183 | PRIMA: Planner-Reasoner Inside a Multi-task Reasoning Agent | 5.50 | 5.75 | 0.25 | | Reject |
| 184 | Gating Mechanisms Underlying Sequence-to-Sequence Working Memory | 5.00 | 5.75 | 0.75 | | Reject |
| 185 | Blur Is an Ensemble: Spatial Smoothings to Improve Accuracy, Uncertainty, and Robustness | 5.75 | 5.75 | 0.00 | | Reject |
| 186 | ShiftAddNAS: Hardware-Inspired Search for More Accurate and Efficient Neural Networks | 5.25 | 5.75 | 0.50 | | Reject |
| 187 | Fair Node Representation Learning via Adaptive Data Augmentation | 5.50 | 5.75 | 0.25 | | Reject |
| 188 | Clustered Task-Aware Meta-Learning by Learning from Learning Paths | 5.25 | 5.75 | 0.50 | | Reject |
| 189 | Learning to Give Checkable Answers with Prover-Verifier Games | 5.50 | 5.75 | 0.25 | | Reject |
| 190 | Contextual Multi-Armed Bandit with Communication Constraints | 5.25 | 5.75 | 0.50 | | Reject |
| 191 | Implicit Regularization of Bregman Proximal Point Algorithm and Mirror Descent on Separable Data | 5.50 | 5.75 | 0.25 | | Reject |
| 192 | One Objective for All Models --- Self-supervised Learning for Topic Models | 5.50 | 5.75 | 0.25 | | Reject |
| 193 | Locally Invariant Explanations: Towards Causal Explanations through Local Invariant Learning | 5.25 | 5.75 | 0.50 | | Reject |
| 194 | Fully Online Meta-Learning Without Task Boundaries | 4.67 | 5.75 | 1.08 | | Reject |
| 195 | Spectral Multiplicity Entails Sample-wise Multiple Descent | 5.75 | 5.75 | 0.00 | | Reject |
| 196 | On the Unreasonable Effectiveness of Feature Propagation in Learning on Graphs with Missing Node Features | 5.50 | 5.75 | 0.25 | | Reject |
| 197 | Calibration Regularized Training of Deep Neural Networks using Kernel Density Estimation | 5.25 | 5.75 | 0.50 | | Reject |
| 198 | Decentralized Cooperative Multi-Agent Reinforcement Learning with Exploration | 5.75 | 5.75 | 0.00 | | Reject |
| 199 | Sample-efficient actor-critic algorithms with an etiquette for zero-sum Markov games | 5.00 | 5.75 | 0.75 | | Reject |
| 200 | Implicit Bias of Linear Equivariant Networks | 5.50 | 5.75 | 0.25 | | Reject |
| 201 | Surprise Minimizing Multi-Agent Learning with Energy-based Models | 4.50 | 5.75 | 1.25 | | Reject |
| 202 | SPARK: co-exploring model SPArsity and low-RanKness for compact neural networks | 5.50 | 5.75 | 0.25 | | Reject |
| 203 | What Doesn't Kill You Makes You Robust(er): How to Adversarially Train against Data Poisoning | 5.25 | 5.75 | 0.50 | | Reject |
| 204 | Stability based Generalization Bounds for Exponential Family Langevin Dynamics | 5.75 | 5.75 | 0.00 | | Reject |
| 205 | Self-consistent Gradient-like Eigen Decomposition in Solving Schrödinger Equations | 5.75 | 5.75 | 0.00 | | Reject |
| 206 | Koopman Q-learning: Offline Reinforcement Learning via Symmetries of Dynamics | 5.50 | 5.75 | 0.25 | | Reject |
| 207 | A Closer Look at Smoothness in Domain Adversarial Training | 5.25 | 5.75 | 0.50 | | Reject |
| 208 | Did I do that? Blame as a means to identify controlled effects in reinforcement learning | 4.50 | 5.75 | 1.25 | | Reject |
| 209 | Disentangling deep neural networks with rectified linear units using duality | 5.75 | 5.75 | 0.00 | | Reject |
| 210 | Only tails matter: Average-Case Universality and Robustness in the Convex Regime | 5.25 | 5.75 | 0.50 | | Reject |
| 211 | Scaling-up Diverse Orthogonal Convolutional Networks by a Paraunitary Framework | 5.25 | 5.75 | 0.50 | | Reject |
| 212 | Convergence Analysis and Implicit Regularization of Feedback Alignment for Deep Linear Networks | 5.75 | 5.75 | 0.00 | | Reject |
| 213 | A Sampling-Free Approximation of Gaussian Variational Auto-Encoders | 4.75 | 5.75 | 1.00 | | Reject |
| 214 | Revisiting Virtual Nodes in Graph Neural Networks for Link Prediction | 5.50 | 5.75 | 0.25 | | Reject |
| 215 | Local Patch AutoAugment with Multi-Agent Collaboration | 5.25 | 5.75 | 0.50 | | Reject |
| 216 | Representation Disentanglement in Generative Models with Contrastive Learning | 5.75 | 5.75 | 0.00 | | Reject |
| 217 | Few-shot Learning with Big Prototypes | 5.00 | 5.75 | 0.75 | | Reject |
| 218 | TAG: Task-based Accumulated Gradients for Lifelong learning | 5.25 | 5.75 | 0.50 | | Reject |
| 219 | PhaseFool: Phase-oriented Audio Adversarial Examples via Energy Dissipation | 5.33 | 5.75 | 0.42 | | Reject |
| 220 | Layer-wise Adaptive Model Aggregation for Scalable Federated Learning | 5.25 | 5.75 | 0.50 | | Reject |
| 221 | Learning Visual-Linguistic Adequacy, Fidelity, and Fluency for Novel Object Captioning | 5.25 | 5.75 | 0.50 | | Reject |
| 222 | Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation | 5.50 | 5.75 | 0.25 | | Reject |
| 223 | Hierarchical Cross Contrastive Learning of Visual Representations | 5.50 | 5.75 | 0.25 | | Reject |
| 224 | α-Weighted Federated Adversarial Training | 5.75 | 5.75 | 0.00 | | Reject |
| 225 | Monotonic Improvement Guarantees under Non-stationarity for Decentralized PPO | 5.75 | 5.75 | 0.00 | | Reject |
| 226 | The Infinite Contextual Graph Markov Model | 5.75 | 5.75 | 0.00 | | Reject |
| 227 | On Margin Maximization in Linear and ReLU Networks | 5.50 | 5.75 | 0.25 | | Reject |
| 228 | How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models | 5.33 | 5.75 | 0.42 | | Reject |
| 229 | Accelerating Training of Deep Spiking Neural Networks with Parameter Initialization | 6.25 | 5.75 | -0.50 | | Reject |
| 230 | RMNet: Equivalently Removing Residual Connection from Networks | 5.50 | 5.75 | 0.25 | | Reject |
| 231 | Bounding Membership Inference | 5.50 | 5.75 | 0.25 | | Reject |
| 232 | Gradient-Guided Importance Sampling for Learning Discrete Energy-Based Models | 5.33 | 5.75 | 0.42 | | Reject |
| 233 | Expressiveness of Neural Networks Having Width Equal or Below the Input Dimension | 5.50 | 5.75 | 0.25 | | Reject |
| 234 | Blessing of Class Diversity in Pre-training | 5.75 | 5.75 | 0.00 | | Reject |
| 235 | What to expect of hardware metric predictors in NAS | 5.00 | 5.75 | 0.75 | | Reject |
| 236 | Transformed CNNs: recasting pre-trained convolutional layers with self-attention | 5.50 | 5.75 | 0.25 | | Reject |
| 237 | Low Entropy Deep Networks | 5.25 | 5.75 | 0.50 | | Reject |
| 238 | A Closer Look at Prototype Classifier for Few-shot Image Classification | 4.67 | 5.67 | 1.00 | | Reject |
| 239 | Hierarchically Regularized Deep Forecasting | 5.67 | 5.67 | 0.00 | | Reject |
| 240 | Learning Sample Reweighting for Adversarial Robustness | 6.60 | 5.67 | -0.93 | | 8, 6, 6, 8, 5 | | 8, 6, 6, 8, 3, 3 |
| Reject |
| 241 | Learning Stochastic Shortest Path with Linear Function Approximation | 5.67 | 5.67 | 0.00 | | Reject |
| 242 | Reinforcement Learning with Efficient Active Feature Acquisition | 4.67 | 5.67 | 1.00 | | Reject |
| 243 | Gradient play in stochastic games: stationary points, convergence, and sample complexity | 6.33 | 5.67 | -0.67 | | Reject |
| 244 | Distributional Perturbation for Efficient Exploration in Distributional Reinforcement Learning | 5.67 | 5.67 | 0.00 | | Reject |
| 245 | Multi-Domain Self-Supervised Learning | 5.67 | 5.67 | 0.00 | | Reject |
| 246 | Practical and Private Heterogeneous Federated Learning | 5.33 | 5.67 | 0.33 | | Reject |
| 247 | Learning to Generalize Compositionally by Transferring Across Semantic Parsing Tasks | 5.33 | 5.67 | 0.33 | | Reject |
| 248 | Empirical Study of the Decision Region and Robustness in Deep Neural Networks | 4.67 | 5.67 | 1.00 | | Reject |
| 249 | Deep Reinforcement Learning for Equal Risk Option Pricing and Hedging under Dynamic Expectile Risk Measures | 5.67 | 5.67 | 0.00 | | Reject |
| 250 | The Power of Contrast for Feature Learning: A Theoretical Analysis | 5.67 | 5.67 | 0.00 | | Reject |
| 251 | MANDERA: Malicious Node Detection in Federated Learning via Ranking | 6.33 | 5.67 | -0.67 | | Reject |
| 252 | Modelling neuronal behaviour with time series regression: Recurrent Neural Networks on synthetic C. elegans data | 5.67 | 5.67 | 0.00 | | Reject |
| 253 | Structural Causal Interpretation Theorem | 4.67 | 5.67 | 1.00 | | Reject |
| 254 | Graph Kernel Neural Networks | 5.33 | 5.67 | 0.33 | | Reject |
| 255 | Feature Flow Regularization: Improving Structured Sparsity in Deep Neural Networks | 5.33 | 5.67 | 0.33 | | Reject |
| 256 | Automatic Termination for Hyperparameter Optimization | 5.33 | 5.67 | 0.33 | | Reject |
| 257 | Shift-tolerant Perceptual Similarity Metric | 5.67 | 5.67 | 0.00 | | Reject |
| 258 | Message Function Search for Hyper-relational Knowledge Graph | 5.67 | 5.67 | 0.00 | | Reject |
| 259 | NAFS: A Simple yet Tough-to-Beat Baseline for Graph Representation Learning | 5.33 | 5.67 | 0.33 | | Reject |
| 260 | Boundary-aware Pre-training for Video Scene Segmentation | 5.67 | 5.67 | 0.00 | | Reject |
| 261 | Metrics Matter: A Closer Look on Self-Paced Reinforcement Learning | 5.33 | 5.67 | 0.33 | | Reject |
| 262 | Collaborate to Defend Against Adversarial Attacks | 5.00 | 5.67 | 0.67 | | Reject |
| 263 | PARS: PSEUDO-LABEL AWARE ROBUST SAMPLE SELECTION FOR LEARNING WITH NOISY LABELS | 5.67 | 5.67 | 0.00 | | Reject |
| 264 | Style Equalization: Unsupervised Learning of Controllable Generative Sequence Models | 5.67 | 5.67 | 0.00 | | Reject |
| 265 | Planckian jitter: enhancing the color quality of self-supervised visual representations | 5.00 | 5.67 | 0.67 | | Reject |
| 266 | ScaLA: Speeding-Up Fine-tuning of Pre-trained Transformer Networks via Efficient and Scalable Adversarial Perturbation | 5.33 | 5.67 | 0.33 | | Reject |
| 267 | LASSO: Latent Sub-spaces Orientation for Domain Generalization | 5.40 | 5.60 | 0.20 | | 3, 5, 5, 8, 6 | | 5, 6, 5, 6, 6 |
| Reject |
| 268 | Mixture Representation Learning with Coupled Autoencoders | 5.20 | 5.60 | 0.40 | | 5, 5, 3, 5, 8 | | 5, 5, 5, 5, 8 |
| Reject |
| 269 | Limitations of Active Learning With Deep Transformer Language Models | 4.80 | 5.60 | 0.80 | | 6, 3, 3, 6, 6 | | 6, 5, 5, 6, 6 |
| Reject |
| 270 | Learning shared neural manifolds from multi-subject FMRI data | 5.00 | 5.60 | 0.60 | | 5, 5, 6, 6, 3 | | 5, 6, 8, 6, 3 |
| Reject |
| 271 | Learning to Solve Multi-Robot Task Allocation with a Covariant-Attention based Neural Architecture | 5.40 | 5.60 | 0.20 | | 5, 3, 6, 8, 5 | | 5, 3, 6, 8, 6 |
| Reject |
| 272 | Second-Order Unsupervised Feature Selection via Knowledge Contrastive Distillation | 4.75 | 5.60 | 0.85 | | Reject |
| 273 | Federated Robustness Propagation: Sharing Adversarial Robustness in Federated Learning | 5.00 | 5.60 | 0.60 | | 3, 5, 8, 6, 3 | | 3, 6, 8, 8, 3 |
| Reject |
| 274 | Counting Substructures with Higher-Order Graph Neural Networks: Possibility and Impossibility Results | 5.60 | 5.60 | 0.00 | | 6, 5, 6, 6, 5 | | 6, 5, 6, 6, 5 |
| Reject |
| 275 | Provably Robust Detection of Out-of-distribution Data (almost) for free | 4.40 | 5.60 | 1.20 | | 3, 3, 6, 5, 5 | | 8, 3, 6, 6, 5 |
| Reject |
| 276 | Fully Steerable 3D Spherical Neurons | 5.60 | 5.60 | 0.00 | | 5, 5, 8, 5, 5 | | 5, 5, 8, 5, 5 |
| Reject |
| 277 | Understanding Knowledge Integration in Language Models with Graph Convolutions | 5.40 | 5.60 | 0.20 | | 8, 6, 3, 5, 5 | | 8, 6, 3, 5, 6 |
| Reject |
| 278 | Translatotron 2: Robust direct speech-to-speech translation | 5.00 | 5.60 | 0.60 | | 5, 5, 6, 3, 6 | | 6, 5, 6, 5, 6 |
| Reject |
| 279 | KNIFE: Kernelized-Neural Differential Entropy Estimation | 5.00 | 5.60 | 0.60 | | 6, 5, 3, 6, 5 | | 6, 6, 5, 6, 5 |
| Reject |
| 280 | Deep Ensemble as a Gaussian Process Posterior | 5.60 | 5.60 | 0.00 | | 5, 5, 5, 8, 5 | | 5, 5, 5, 8, 5 |
| Reject |
| 281 | Localized Persistent Homologies for more Effective Deep Learning | 5.00 | 5.50 | 0.50 | | Reject |
| 282 | Restricted Category Removal from Model Representations using Limited Data | 4.50 | 5.50 | 1.00 | | Reject |
| 283 | Rethinking Temperature in Graph Contrastive Learning | 5.00 | 5.50 | 0.50 | | Reject |
| 284 | Scalable multimodal variational autoencoders with surrogate joint posterior | 4.25 | 5.50 | 1.25 | | Reject |
| 285 | DRIBO: Robust Deep Reinforcement Learning via Multi-View Information Bottleneck | 5.00 | 5.50 | 0.50 | | Reject |
| 286 | No Shifted Augmentations (NSA): strong baselines for self-supervised Anomaly Detection | 5.25 | 5.50 | 0.25 | | Reject |
| 287 | Learning Pseudometric-based Action Representations for Offline Reinforcement Learning | 4.75 | 5.50 | 0.75 | | Reject |
| 288 | Towards Generic Interface for Human-Neural Network Knowledge Exchange | 5.33 | 5.50 | 0.17 | | Reject |
| 289 | Langevin Autoencoders for Learning Deep Latent Variable Models | 5.50 | 5.50 | 0.00 | | Reject |
| 290 | Inductive Biases and Variable Creation in Self-Attention Mechanisms | 5.50 | 5.50 | 0.00 | | Reject |
| 291 | Constrained Density Matching and Modeling for Effective Contextualized Alignment | 5.50 | 5.50 | 0.00 | | Reject |
| 292 | Stochastic Reweighted Gradient Descent | 5.50 | 5.50 | 0.00 | | Reject |
| 293 | LatentKeypointGAN: Controlling GANs via Latent Keypoints | 5.25 | 5.50 | 0.25 | | Reject |
| 294 | Prioritized training on points that are learnable, worth learning, and not yet learned | 4.75 | 5.50 | 0.75 | | Reject |
| 295 | FoveaTer: Foveated Transformer for Image Classification | 5.00 | 5.50 | 0.50 | | Reject |
| 296 | Learning Context-Adapted Video-Text Retrieval by Attending to User Comments | 5.50 | 5.50 | 0.00 | | Reject |
| 297 | Coherent and Consistent Relational Transfer Learning with Autoencoders | 5.50 | 5.50 | 0.00 | | Reject |
| 298 | Recurrent Parameter Generators | 5.50 | 5.50 | 0.00 | | Reject |
| 299 | Correct-N-Contrast: a Contrastive Approach for Improving Robustness to Spurious Correlations | 4.50 | 5.50 | 1.00 | | Reject |
| 300 | Source-Target Unified Knowledge Distillation for Memory-Efficient Federated Domain Adaptation on Edge Devices | 5.50 | 5.50 | 0.00 | | Reject |
| 301 | A Risk-Sensitive Policy Gradient Method | 4.75 | 5.50 | 0.75 | | Reject |
| 302 | Explanatory Learning: Beyond Empiricism in Neural Networks | 5.25 | 5.50 | 0.25 | | Reject |
| 303 | Convolutional Neural Network Dynamics: A Graph Perspective | 5.25 | 5.50 | 0.25 | | Reject |
| 304 | Head2Toe: Utilizing Intermediate Representations for Better OOD Generalization | 5.50 | 5.50 | 0.00 | | Reject |
| 305 | Second-Order Rewards For Successor Features | 5.33 | 5.50 | 0.17 | | Reject |
| 306 | First-Order Optimization Inspired from Finite-Time Convergent Flows | 5.25 | 5.50 | 0.25 | | Reject |
| 307 | Reward Learning as Doubly Nonparametric Bandits: Optimal Design and Scaling Laws | 6.00 | 5.50 | -0.50 | | Reject |
| 308 | Analyzing Populations of Neural Networks via Dynamical Model Embedding | 5.25 | 5.50 | 0.25 | | Reject |
| 309 | Learning Symbolic Rules for Reasoning in Quasi-Natural Language | 5.00 | 5.50 | 0.50 | | Reject |
| 310 | NAIL: A Challenging Benchmark for Na'ive Logical Reasoning | 5.25 | 5.50 | 0.25 | | Reject |
| 311 | A Frequency Perspective of Adversarial Robustness | 6.00 | 5.50 | -0.50 | | Reject |
| 312 | Targeted Environment Design from Offline Data | 5.00 | 5.50 | 0.50 | | Reject |
| 313 | When less is more: Simplifying inputs aids neural network understanding | 4.75 | 5.50 | 0.75 | | Reject |
| 314 | Show Your Work: Scratchpads for Intermediate Computation with Language Models | 5.50 | 5.50 | 0.00 | | Reject |
| 315 | Fooling Adversarial Training with Induction Noise | 4.50 | 5.50 | 1.00 | | Reject |
| 316 | On the Implicit Biases of Architecture & Gradient Descent | 5.25 | 5.50 | 0.25 | | Reject |
| 317 | Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation | 5.50 | 5.50 | 0.00 | | Reject |
| 318 | Learning Surface Parameterization for Document Image Unwarping | 5.50 | 5.50 | 0.00 | | Reject |
| 319 | Reasoning-Modulated Representations | 5.25 | 5.50 | 0.25 | | Reject |
| 320 | NeuroSED: Learning Subgraph Similarity via Graph Neural Networks | 5.00 | 5.50 | 0.50 | | Reject |
| 321 | Hierarchical Multimodal Variational Autoencoders | 5.50 | 5.50 | 0.00 | | Reject |
| 322 | Towards General Robustness to Bad Training Data | 5.25 | 5.50 | 0.25 | | Reject |
| 323 | Distributed Skellam Mechanism: a Novel Approach to Federated Learning with Differential Privacy | 5.00 | 5.50 | 0.50 | | Reject |
| 324 | Scaling Fair Learning to Hundreds of Intersectional Groups | 5.00 | 5.50 | 0.50 | | Reject |
| 325 | AdaFocal: Calibration-aware Adaptive Focal Loss | 5.00 | 5.50 | 0.50 | | Reject |
| 326 | Losing Less: A Loss for Differentially Private Deep Learning | 5.50 | 5.50 | 0.00 | | Reject |
| 327 | Deep learning via message passing algorithms based on belief propagation | 4.50 | 5.50 | 1.00 | | Reject |
| 328 | Calibrated ensembles - a simple way to mitigate ID-OOD accuracy tradeoffs | 4.75 | 5.50 | 0.75 | | Reject |
| 329 | SAFER: Data-Efficient and Safe Reinforcement Learning Through Skill Acquisition | 5.50 | 5.50 | 0.00 | | Reject |
| 330 | A Statistical Manifold Framework for Point Cloud Data | 5.50 | 5.50 | 0.00 | | Reject |
| 331 | Mitigating Dataset Bias Using Per-Sample Gradients From A Biased Classifier | 5.25 | 5.50 | 0.25 | | Reject |
| 332 | An evaluation of quality and robustness of smoothed explanations | 4.75 | 5.50 | 0.75 | | Reject |
| 333 | Retrieval-Augmented Reinforcement Learning | 4.75 | 5.50 | 0.75 | | Reject |
| 334 | Invariance in Policy Optimisation and Partial Identifiability in Reward Learning | 4.67 | 5.50 | 0.83 | | Reject |
| 335 | Re-evaluating Word Mover's Distance | 5.00 | 5.50 | 0.50 | | Reject |
| 336 | A Variance Reduction Method for Neural-based Divergence Estimation | 5.50 | 5.50 | 0.00 | | Reject |
| 337 | Efficient Out-of-Distribution Detection via CVAE data Generation | 5.50 | 5.50 | 0.00 | | Reject |
| 338 | A Hierarchical Bayesian Approach to Inverse Reinforcement Learning with Symbolic Reward Machines | 5.50 | 5.50 | 0.00 | | Reject |
| 339 | Multi-Task Neural Processes | 4.75 | 5.50 | 0.75 | | Reject |
| 340 | Neurosymbolic Deep Generative Models for Sequence Data with Relational Constraints | 5.50 | 5.50 | 0.00 | | Reject |
| 341 | Counterbalancing Teacher: Regularizing Batch Normalized Models for Robustness | 5.50 | 5.50 | 0.00 | | Reject |
| 342 | FLOAT: FAST LEARNABLE ONCE-FOR-ALL ADVERSARIAL TRAINING FOR TUNABLE TRADE-OFF BETWEEN ACCURACY AND ROBUSTNESS | 4.75 | 5.50 | 0.75 | | Reject |
| 343 | Multi-Agent Reinforcement Learning with Shared Resource in Inventory Management | 5.25 | 5.50 | 0.25 | | Reject |
| 344 | Learning Diverse Options via InfoMax Termination Critic | 5.00 | 5.50 | 0.50 | | Reject |
| 345 | Uncertainty-Aware Deep Video Compression with Ensembles | 5.00 | 5.50 | 0.50 | | Reject |
| 346 | Where do Models go Wrong? Parameter-Space Saliency Maps for Explainability | 6.33 | 5.50 | -0.83 | | Reject |
| 347 | Training Multi-Layer Over-Parametrized Neural Network in Subquadratic Time | 5.50 | 5.50 | 0.00 | | Reject |
| 348 | Neural tangent kernel eigenvalues accurately predict generalization | 4.75 | 5.50 | 0.75 | | Reject |
| 349 | Few-Shot Classification with Task-Adaptive Semantic Feature Learning | 4.50 | 5.50 | 1.00 | | Reject |
| 350 | Evaluating Predictive Distributions: Does Bayesian Deep Learning Work? | 5.50 | 5.50 | 0.00 | | Reject |
| 351 | Avoiding Overfitting to the Importance Weights in Offline Policy Optimization | 5.25 | 5.50 | 0.25 | | Reject |
| 352 | Learn the Time to Learn: Replay Scheduling for Continual Learning | 4.75 | 5.50 | 0.75 | | Reject |
| 353 | Self-Contrastive Learning | 5.25 | 5.50 | 0.25 | | Reject |
| 354 | DEUP: Direct Epistemic Uncertainty Prediction | 4.75 | 5.50 | 0.75 | | Reject |
| 355 | Inverse Contextual Bandits: Learning How Behavior Evolves over Time | 5.50 | 5.50 | 0.00 | | Reject |
| 356 | Improving zero-shot generalization in offline reinforcement learning using generalized similarity functions | 4.75 | 5.50 | 0.75 | | Reject |
| 357 | Efficient representations for privacy-preserving inference | 5.00 | 5.50 | 0.50 | | Reject |
| 358 | Neural Bootstrapping Attention for Neural Processes | 5.50 | 5.50 | 0.00 | | Reject |
| 359 | Logarithmic Unbiased Quantization: Practical 4-bit Training in Deep Learning | 5.00 | 5.50 | 0.50 | | Reject |
| 360 | Coarformer: Transformer for large graph via graph coarsening | 4.75 | 5.50 | 0.75 | | Reject |
| 361 | On the relationship between disentanglement and multi-task learning | 5.00 | 5.50 | 0.50 | | Reject |
| 362 | Safe Opponent-Exploitation Subgame Refinement | 4.75 | 5.50 | 0.75 | | Reject |
| 363 | Maximum Likelihood Training of Parametrized Diffusion Model | 4.75 | 5.50 | 0.75 | | Reject |
| 364 | Spectral Bias in Practice: the Role of Function Frequency in Generalization | 4.25 | 5.50 | 1.25 | | Reject |
| 365 | SANE: Specialization-Aware Neural Network Ensemble | 4.75 | 5.50 | 0.75 | | Reject |
| 366 | Model Validation Using Mutated Training Labels: An Exploratory Study | 5.50 | 5.50 | 0.00 | | Reject |
| 367 | Semantically Controllable Generation of Physical Scenes with Explicit Knowledge | 5.25 | 5.50 | 0.25 | | Reject |
| 368 | Instance-Adaptive Video Compression: Improving Neural Codecs by Training on the Test Set | 5.50 | 5.50 | 0.00 | | Reject |
| 369 | Search Spaces for Neural Model Training | 4.75 | 5.50 | 0.75 | | Reject |
| 370 | Plan Better Amid Conservatism: Offline Multi-Agent Reinforcement Learning with Actor Rectification | 5.50 | 5.50 | 0.00 | | Reject |
| 371 | Denoising Diffusion Gamma Models | 5.00 | 5.50 | 0.50 | | Reject |
| 372 | Tactics on Refining Decision Boundary for Improving Certification-based Robust Training | 4.25 | 5.50 | 1.25 | | Reject |
| 373 | Auto-Encoding Inverse Reinforcement Learning | 5.50 | 5.50 | 0.00 | | Reject |
| 374 | On Learning to Solve Cardinality Constrained Combinatorial Optimization in One-Shot: A Re-parameterization Approach via Gumbel-Sinkhorn-TopK | 5.00 | 5.50 | 0.50 | | Reject |
| 375 | Thompson Sampling for (Combinatorial) Pure Exploration | 5.25 | 5.50 | 0.25 | | Reject |
| 376 | Generalization of GANs and overparameterized models under Lipschitz continuity | 5.50 | 5.50 | 0.00 | | Reject |
| 377 | Provably Improved Context-Based Offline Meta-RL with Attention and Contrastive Learning | 5.50 | 5.50 | 0.00 | | Reject |
| 378 | Detecting Worst-case Corruptions via Loss Landscape Curvature in Deep Reinforcement Learning | 5.50 | 5.50 | 0.00 | | Reject |
| 379 | On Heterogeneously Distributed Data, Sparsity Matters | 4.25 | 5.50 | 1.25 | | Reject |
| 380 | Balancing Average and Worst-case Accuracy in Multitask Learning | 5.25 | 5.50 | 0.25 | | Reject |
| 381 | On Reward Maximization and Distribution Matching for Fine-Tuning Language Models | 5.00 | 5.50 | 0.50 | | Reject |
| 382 | Learning and controlling the source-filter representation of speech with a variational autoencoder | 5.00 | 5.50 | 0.50 | | Reject |
| 383 | How to train RNNs on chaotic data? | 5.25 | 5.50 | 0.25 | | Reject |
| 384 | Inductive Lottery Ticket Learning for Graph Neural Networks | 5.00 | 5.50 | 0.50 | | Reject |
| 385 | FED-χ2: Secure Federated Correlation Test | 5.00 | 5.50 | 0.50 | | Reject |
| 386 | Deep Representations for Time-varying Brain Datasets | 4.50 | 5.50 | 1.00 | | Reject |
| 387 | Representation mitosis in wide neural networks | 5.00 | 5.50 | 0.50 | | Reject |
| 388 | 3D Pre-training improves GNNs for Molecular Property Prediction | 5.00 | 5.50 | 0.50 | | Reject |
| 389 | CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models | 5.50 | 5.50 | 0.00 | | Reject |
| 390 | Lifting Imbalanced Regression with Self-Supervised Learning | 5.50 | 5.50 | 0.00 | | Reject |
| 391 | Role Diversity Matters: A Study of Cooperative Training Strategies for Multi-Agent RL | 4.50 | 5.50 | 1.00 | | Reject |
| 392 | SLASH: Embracing Probabilistic Circuits into Neural Answer Set Programming | 5.50 | 5.50 | 0.00 | | Reject |
| 393 | Towards Federated Learning on Time-Evolving Heterogeneous Data | 4.50 | 5.50 | 1.00 | | Reject |
| 394 | Distributed Optimal Margin Distribution Machine | 5.50 | 5.50 | 0.00 | | Reject |
| 395 | Hinge Policy Optimization: Rethinking Policy Improvement and Reinterpreting PPO | 5.50 | 5.50 | 0.00 | | Reject |
| 396 | Gradient-based Meta-solving and Its Applications to Iterative Methods for Solving Differential Equations | 5.00 | 5.50 | 0.50 | | Reject |
| 397 | Test-time Batch Statistics Calibration for Covariate Shift | 5.25 | 5.50 | 0.25 | | Reject |
| 398 | Self-Supervised Representation Learning via Latent Graph Prediction | 5.25 | 5.50 | 0.25 | | Reject |
| 399 | Contrastively Enforcing Distinctiveness for Multi-Label Classification | 5.33 | 5.50 | 0.17 | | Reject |
| 400 | Short optimization paths lead to good generalization | 5.50 | 5.50 | 0.00 | | Reject |
| 401 | On the Global Convergence of Gradient Descent for multi-layer ResNets in the mean-field regime | 5.00 | 5.50 | 0.50 | | Reject |
| 402 | Towards Understanding the Condensation of Neural Networks at Initial Training | 5.00 | 5.50 | 0.50 | | Reject |
| 403 | Generalizable Person Re-identification Without Demographics | 5.75 | 5.50 | -0.25 | | Reject |
| 404 | Accuracy-Privacy Trade-off in Deep Ensemble: A Membership Inference Perspective | 5.25 | 5.50 | 0.25 | | Reject |
| 405 | Intra-class Mixup for Out-of-Distribution Detection | 5.00 | 5.50 | 0.50 | | Reject |
| 406 | Divergence-Regularized Multi-Agent Actor-Critic | 5.50 | 5.50 | 0.00 | | Reject |
| 407 | Adaptive Inertia: Disentangling the Effects of Adaptive Learning Rate and Momentum | 5.50 | 5.50 | 0.00 | | Reject |
| 408 | Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents | 5.40 | 5.40 | 0.00 | | 8, 3, 8, 3, 5 | | 6, 5, 8, 3, 5 |
| Reject |
| 409 | Generalized Fourier Features for Coordinate-Based Learning of Functions on Manifolds | 5.40 | 5.40 | 0.00 | | 3, 6, 5, 3, 10 | | 3, 6, 5, 3, 10 |
| Reject |
| 410 | Identity-Disentangled Adversarial Augmentation for Self-supervised Learning | 5.50 | 5.40 | -0.10 | | Reject |
| 411 | ACTIVE REFINEMENT OF WEAKLY SUPERVISED MODELS | 5.40 | 5.40 | 0.00 | | 6, 5, 6, 5, 5 | | 6, 5, 6, 5, 5 |
| Reject |
| 412 | Proving Theorems using Incremental Learning and Hindsight Experience Replay | 5.40 | 5.40 | 0.00 | | 8, 5, 5, 6, 3 | | 8, 5, 5, 6, 3 |
| Reject |
| 413 | Post-Training Quantization Is All You Need to Perform Cross-Platform Learned Image Compression | 4.60 | 5.40 | 0.80 | | 6, 3, 6, 5, 3 | | 6, 3, 6, 6, 6 |
| Reject |
| 414 | Weakly Supervised Graph Clustering | 5.20 | 5.40 | 0.20 | | 6, 6, 6, 5, 3 | | 5, 6, 6, 5, 5 |
| Reject |
| 415 | Spatially Invariant Unsupervised 3D Object-Centric Learning and Scene Decomposition | 5.40 | 5.40 | 0.00 | | 5, 6, 5, 5, 6 | | 5, 6, 5, 5, 6 |
| Reject |
| 416 | PIVQGAN: Posture and Identity Disentangled Image-to-Image Translation via Vector Quantization | 5.40 | 5.40 | 0.00 | | 5, 6, 5, 5, 6 | | 5, 6, 5, 5, 6 |
| Reject |
| 417 | Improving Out-of-Distribution Robustness via Selective Augmentation | 5.00 | 5.33 | 0.33 | | Reject |
| 418 | A Simple Approach to Adversarial Robustness in Few-shot Image Classification | 5.00 | 5.33 | 0.33 | | Reject |
| 419 | Generative Modeling for Multitask Visual Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 420 | A Simple Reward-free Approach to Constrained Reinforcement Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 421 | Learn Together, Stop Apart: a Novel Approach to Ensemble Pruning | 5.33 | 5.33 | 0.00 | | Reject |
| 422 | An Empirical Investigation of the Role of Pre-training in Lifelong Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 423 | Text Generation with Efficient (Soft)Q-Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 424 | HyperTransformer: Attention-Based CNN Model Generation from Few Samples | 5.33 | 5.33 | 0.00 | | Reject |
| 425 | Long Document Summarization with Top-Down and Bottom-Up Representation Inference | 5.33 | 5.33 | 0.00 | | Reject |
| 426 | Stability analysis of SGD through the normalized loss function | 5.33 | 5.33 | 0.00 | | Reject |
| 427 | Task-driven Discovery of Perceptual Schemas for Generalization in Reinforcement Learning | 4.33 | 5.33 | 1.00 | | Reject |
| 428 | S3: Supervised Self-supervised Learning under Label Noise | 5.00 | 5.33 | 0.33 | | Reject |
| 429 | RAVE: A variational autoencoder for fast and high-quality neural audio synthesis | 5.33 | 5.33 | 0.00 | | Reject |
| 430 | Temporal abstractions-augmented temporally contrastive learning: an alternative to the Laplacian in RL | 4.33 | 5.33 | 1.00 | | Reject |
| 431 | Multi-Objective Model Selection for Time Series Forecasting | 5.33 | 5.33 | 0.00 | | Reject |
| 432 | Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis | 5.50 | 5.33 | -0.17 | | Reject |
| 433 | Learning to Efficiently Sample from Diffusion Probabilistic Models | 5.33 | 5.33 | 0.00 | | Reject |
| 434 | SPP-RL: State Planning Policy Reinforcement Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 435 | Beyond Faithfulness: A Framework to Characterize and Compare Saliency Methods | 5.33 | 5.33 | 0.00 | | Reject |
| 436 | Locality-Based Mini Batching for Graph Neural Networks | 4.33 | 5.33 | 1.00 | | Reject |
| 437 | Back to Basics: Efficient Network Compression via IMP | 4.67 | 5.33 | 0.67 | | Reject |
| 438 | STRIC: Stacked Residuals of Interpretable Components for Time Series Anomaly Detection | 4.67 | 5.33 | 0.67 | | Reject |
| 439 | Kokoyi: Executable LaTeX for End-to-end Deep Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 440 | A Principled Permutation Invariant Approach to Mean-Field Multi-Agent Reinforcement Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 441 | Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions | 4.33 | 5.33 | 1.00 | | Reject |
| 442 | Learning Identity-Preserving Transformations on Data Manifolds | 5.33 | 5.33 | 0.00 | | Reject |
| 443 | 1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB's Convergence Speed | 5.33 | 5.33 | 0.00 | | Reject |
| 444 | Uncertainty-based out-of-distribution detection requires suitable function space priors | 4.67 | 5.33 | 0.67 | | Reject |
| 445 | Lagrangian Method for Episodic Learning | 5.33 | 5.33 | 0.00 | | Reject |
| 446 | Gradient Broadcast Adaptation: Defending against the backdoor attack in pre-trained models | 5.33 | 5.33 | 0.00 | | Reject |
| 447 | Neuronal Learning Analysis using Cycle-Consistent Adversarial Networks | 4.67 | 5.33 | 0.67 | | Reject |
| 448 | Neural Capacitance: A New Perspective of Neural Network Selection via Edge Dynamics | 5.33 | 5.33 | 0.00 | | Reject |
| 449 | InstaHide’s Sample Complexity When Mixing Two Private Images | 5.33 | 5.33 | 0.00 | | Reject |
| 450 | A Generalised Inverse Reinforcement Learning Framework | 5.33 | 5.33 | 0.00 | | Reject |
| 451 | Model-Based Robust Adaptive Semantic Segmentation | 5.33 | 5.33 | 0.00 | | Reject |
| 452 | Partial Information as Full: Reward Imputation with Sketching in Bandits | 4.67 | 5.33 | 0.67 | | Reject |
| 453 | Help Me Explore: Minimal Social Interventions for Graph-Based Autotelic Agents | 5.33 | 5.33 | 0.00 | | Reject |
| 454 | p-Laplacian Based Graph Neural Networks | 5.33 | 5.33 | 0.00 | | Reject |
| 455 | Coresets for Kernel Clustering | 5.33 | 5.33 | 0.00 | | Reject |
| 456 | One-Shot Generative Domain Adaptation | 5.33 | 5.33 | 0.00 | | Reject |
| 457 | Adversarial twin neural networks: maximizing physics recovery for physical system | 4.33 | 5.33 | 1.00 | | Reject |
| 458 | Momentum Contrastive Autoencoder: Using Contrastive Learning for Latent Space Distribution Matching in WAE | 5.33 | 5.33 | 0.00 | | Reject |
| 459 | SPIDE: A Purely Spike-based Method for Training Feedback Spiking Neural Networks | 5.00 | 5.33 | 0.33 | | Reject |
| 460 | Learning with convolution and pooling operations in kernel methods | 5.67 | 5.33 | -0.33 | | Reject |
| 461 | Robust Generalization of Quadratic Neural Networks via Function Identification | 5.33 | 5.33 | 0.00 | | Reject |
| 462 | Stochastic Projective Splitting: Solving Saddle-Point Problems with Multiple Regularizers | 4.67 | 5.33 | 0.67 | | Reject |
| 463 | Training-Free Robust Multimodal Learning via Sample-Wise Jacobian Regularization | 5.00 | 5.33 | 0.33 | | Reject |
| 464 | MQTransformer: Multi-Horizon Forecasts with Context Dependent and Feedback-Aware Attention | 5.33 | 5.33 | 0.00 | | Reject |
| 465 | Meta-free few-shot learning via representation learning with weight averaging | 5.00 | 5.33 | 0.33 | | Reject |
| 466 | A Study of Face Obfuscation in ImageNet | 5.33 | 5.33 | 0.00 | | Reject |
| 467 | On the Convergence of Nonconvex Continual Learning with Adaptive Learning Rate | 5.25 | 5.25 | 0.00 | | Reject |
| 468 | Learning to perceive objects by prediction | 5.25 | 5.25 | 0.00 | | Reject |
| 469 | Randomized Signature Layers for Signal Extraction in Time Series Data | 5.25 | 5.25 | 0.00 | | Reject |
| 470 | Faster Reinforcement Learning with Value Target Lower Bounding | 3.00 | 5.25 | 2.25 | | Reject |
| 471 | HyperCGAN: Text-to-Image Synthesis with HyperNet-Modulated Conditional Generative Adversarial Networks | 5.25 | 5.25 | 0.00 | | Reject |
| 472 | Conditional set generation using Seq2seq models | 5.00 | 5.25 | 0.25 | | Reject |
| 473 | Fast Finite Width Neural Tangent Kernel | 5.00 | 5.25 | 0.25 | | Reject |
| 474 | Pseudo Knowledge Distillation: Towards Learning Optimal Instance-specific Label Smoothing Regularization | 5.25 | 5.25 | 0.00 | | Reject |
| 475 | A Free Lunch from the Noise: Provable and Practical Exploration for Representation Learning | 5.33 | 5.25 | -0.08 | | Reject |
| 476 | EF21 with Bells & Whistles: Practical Algorithmic Extensions of Modern Error Feedback | 5.25 | 5.25 | 0.00 | | Reject |
| 477 | On the regularization landscape for the linear recommendation models | 5.25 | 5.25 | 0.00 | | Reject |
| 478 | SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient | 4.25 | 5.25 | 1.00 | | Reject |
| 479 | Teamwork makes von Neumann work:Min-Max Optimization in Two-Team Zero-Sum Games | 4.25 | 5.25 | 1.00 | | Reject |
| 480 | Rethinking Again the Value of Network Pruning -- A Dynamical Isometry Perspective | 4.75 | 5.25 | 0.50 | | Reject |
| 481 | Universal Controllers with Differentiable Physics for Online System Identification | 5.25 | 5.25 | 0.00 | | Reject |
| 482 | Structured Energy Network as a dynamic loss function. Case study. A case study with multi-label Classification | 5.00 | 5.25 | 0.25 | | Reject |
| 483 | Regularizing Deep Neural Networks with Stochastic Estimators of Hessian Trace | 5.25 | 5.25 | 0.00 | | Reject |
| 484 | Revisiting the Lottery Ticket Hypothesis: A Ramanujan Graph Perspective | 4.25 | 5.25 | 1.00 | | Reject |
| 485 | Disentangling Properties of Contrastive Methods | 5.33 | 5.25 | -0.08 | | Reject |
| 486 | Guided-TTS:Text-to-Speech with Untranscribed Speech | 5.25 | 5.25 | 0.00 | | Reject |
| 487 | Connecting Graph Convolution and Graph PCA | 5.25 | 5.25 | 0.00 | | Reject |
| 488 | Understanding AdamW through Proximal Methods and Scale-Freeness | 4.50 | 5.25 | 0.75 | | Reject |
| 489 | Memory-Constrained Policy Optimization | 5.25 | 5.25 | 0.00 | | Reject |
| 490 | Compressed-VFL: Communication-Efficient Learning with Vertically Partitioned Data | 5.25 | 5.25 | 0.00 | | Reject |
| 491 | Avoiding Robust Misclassifications for Improved Robustness without Accuracy Loss | 5.25 | 5.25 | 0.00 | | Reject |
| 492 | Adaptive Generalization for Semantic Segmentation | 5.25 | 5.25 | 0.00 | | Reject |
| 493 | FSL: Federated Supermask Learning | 4.00 | 5.25 | 1.25 | | Reject |
| 494 | Improving Long-Horizon Imitation Through Language Prediction | 4.75 | 5.25 | 0.50 | | Reject |
| 495 | Asynchronous Multi-Agent Actor-Critic with Macro-Actions | 5.25 | 5.25 | 0.00 | | Reject |
| 496 | Learning from One and Only One Shot | 5.25 | 5.25 | 0.00 | | Reject |
| 497 | AutoOED: Automated Optimal Experimental Design Platform with Data- and Time-Efficient Multi-Objective Optimization | 4.75 | 5.25 | 0.50 | | Reject |
| 498 | Learning Equivariances and Partial Equivariances From Data | 5.00 | 5.25 | 0.25 | | Reject |
| 499 | Boundary Graph Neural Networks for 3D Simulations | 4.75 | 5.25 | 0.50 | | Reject |
| 500 | How Does the Task Landscape Affect MAML Performance? | 4.75 | 5.25 | 0.50 | | Reject |
| 501 | Learning to Abstain in the Presence of Uninformative Data | 5.25 | 5.25 | 0.00 | | Reject |
| 502 | Tight lower bounds for Differentially Private ERM | 5.50 | 5.25 | -0.25 | | Reject |
| 503 | Factored World Models for Zero-Shot Generalization in Robotic Manipulation | 5.75 | 5.25 | -0.50 | | Reject |
| 504 | GRAPHIX: A Pre-trained Graph Edit Model for Automated Program Repair | 4.75 | 5.25 | 0.50 | | Reject |
| 505 | Learning Graph Structure from Convolutional Mixtures | 4.75 | 5.25 | 0.50 | | Reject |
| 506 | On the Practicality of Deterministic Epistemic Uncertainty | 5.50 | 5.25 | -0.25 | | Reject |
| 507 | Detecting Modularity in Deep Neural Networks | 5.25 | 5.25 | 0.00 | | Reject |
| 508 | FitVid: High-Capacity Pixel-Level Video Prediction | 5.25 | 5.25 | 0.00 | | Reject |
| 509 | Structured Stochastic Gradient MCMC | 4.75 | 5.25 | 0.50 | | Reject |
| 510 | FedNAS: Federated Deep Learning via Neural Architecture Search | 4.75 | 5.25 | 0.50 | | Reject |
| 511 | Communicate Then Adapt: An Effective Decentralized Adaptive Method for Deep Training | 5.25 | 5.25 | 0.00 | | Reject |
| 512 | Automatic Concept Extraction for Concept Bottleneck-based Video Classification | 5.25 | 5.25 | 0.00 | | Reject |
| 513 | Finding lost DG: Explaining domain generalization via model complexity | 4.75 | 5.25 | 0.50 | | Reject |
| 514 | Offline Reinforcement Learning with Resource Constrained Online Deployment | 4.75 | 5.25 | 0.50 | | Reject |
| 515 | Wavelet Feature Maps Compression for Low Bandwidth Convolutional Neural Networks | 4.75 | 5.25 | 0.50 | | Reject |
| 516 | Intrusion-Free Graph Mixup | 5.25 | 5.25 | 0.00 | | Reject |
| 517 | Hybrid Cloud-Edge Networks for Efficient Inference | 4.25 | 5.25 | 1.00 | | Reject |
| 518 | AutoNF: Automated Architecture Optimization of Normalizing Flows Using a Mixture Distribution Formulation | 5.25 | 5.25 | 0.00 | | Reject |
| 519 | Parallel Deep Neural Networks Have Zero Duality Gap | 4.25 | 5.25 | 1.00 | | Reject |
| 520 | Task Conditioned Stochastic Subsampling | 5.25 | 5.25 | 0.00 | | Reject |
| 521 | PACE: A Parallelizable Computation Encoder for Directed Acyclic Graphs | 4.75 | 5.25 | 0.50 | | Reject |
| 522 | Unsupervised Learning of Neurosymbolic Encoders | 5.00 | 5.25 | 0.25 | | Reject |
| 523 | The Low-Rank Simplicity Bias in Deep Networks | 5.00 | 5.25 | 0.25 | | Reject |
| 524 | Motion Planning Transformers: One Model to Plan them All | 5.25 | 5.25 | 0.00 | | Reject |
| 525 | Intriguing Properties of Input-dependent Randomized Smoothing | 5.25 | 5.25 | 0.00 | | Reject |
| 526 | Robust Models Are More Interpretable Because Attributions Look Normal | 4.75 | 5.25 | 0.50 | | Reject |
| 527 | Concentric Spherical GNN for 3D Representation Learning | 5.25 | 5.25 | 0.00 | | Reject |
| 528 | Monotonicity as a requirement and as a regularizer: efficient methods and applications | 5.25 | 5.25 | 0.00 | | Reject |
| 529 | Non-reversible Parallel Tempering for Uncertainty Approximation in Deep Learning | 6.00 | 5.25 | -0.75 | | Reject |
| 530 | Causal Reinforcement Learning using Observational and Interventional Data | 5.00 | 5.25 | 0.25 | | Reject |
| 531 | Code Editing from Few Exemplars by Adaptive Multi-Extent Composition | 5.25 | 5.25 | 0.00 | | Reject |
| 532 | A new look at fairness in stochastic multi-armed bandit problems | 4.75 | 5.25 | 0.50 | | Reject |
| 533 | Online Unsupervised Learning of Visual Representations and Categories | 5.00 | 5.25 | 0.25 | | Reject |
| 534 | Unconditional Diffusion Guidance | 4.75 | 5.25 | 0.50 | | Reject |
| 535 | A Good Representation Detects Noisy Labels | 5.00 | 5.25 | 0.25 | | Reject |
| 536 | Adaptive Q-learning for Interaction-Limited Reinforcement Learning | 4.50 | 5.25 | 0.75 | | Reject |
| 537 | Semi-Empirical Objective Functions for Neural MCMC Proposal Optimization | 4.00 | 5.25 | 1.25 | | Reject |
| 538 | AI-SARAH: Adaptive and Implicit Stochastic Recursive Gradient Methods | 4.50 | 5.25 | 0.75 | | Reject |
| 539 | Bag-of-Vectors Autoencoders for Unsupervised Conditional Text Generation | 4.75 | 5.25 | 0.50 | | Reject |
| 540 | Generating Symbolic Reasoning Problems with Transformer GANs | 4.25 | 5.25 | 1.00 | | Reject |
| 541 | Towards Coherent and Consistent Use of Entities in Narrative Generation | 5.25 | 5.25 | 0.00 | | Reject |
| 542 | Unit Ball Model for Embedding Hierarchical Structures in the Complex Hyperbolic Space | 5.25 | 5.25 | 0.00 | | Reject |
| 543 | Graph Attention Multi-layer Perceptron | 4.75 | 5.25 | 0.50 | | Reject |
| 544 | Multilevel physics informed neural networks (MPINNs) | 5.25 | 5.25 | 0.00 | | Reject |
| 545 | Propagating Distributions through Neural Networks | 5.00 | 5.25 | 0.25 | | Reject |
| 546 | Transfer and Marginalize: Explaining Away Label Noise with Privileged Information | 5.50 | 5.25 | -0.25 | | Reject |
| 547 | Generalizable Learning to Optimize into Wide Valleys | 4.75 | 5.25 | 0.50 | | Reject |
| 548 | Efficient Wasserstein and Sinkhorn Policy Optimization | 5.25 | 5.25 | 0.00 | | Reject |
| 549 | DAdaQuant: Doubly-adaptive quantization for communication-efficient Federated Learning | 5.25 | 5.25 | 0.00 | | Reject |
| 550 | Distributionally Robust Learning for Uncertainty Calibration under Domain Shift | 4.75 | 5.25 | 0.50 | | Reject |
| 551 | Mismatched No More: Joint Model-Policy Optimization for Model-Based RL | 5.25 | 5.25 | 0.00 | | Reject |
| 552 | Stepping Back to SMILES Transformers for Fast Molecular Representation Inference | 5.25 | 5.25 | 0.00 | | Reject |
| 553 | Deep Active Learning by Leveraging Training Dynamics | 5.25 | 5.25 | 0.00 | | Reject |
| 554 | Demystifying How Self-Supervised Features Improve Training from Noisy Labels | 5.25 | 5.25 | 0.00 | | Reject |
| 555 | Ensemble-in-One: Learning Ensemble within Random Gated Networks for Enhanced Adversarial Robustness | 5.00 | 5.25 | 0.25 | | Reject |
| 556 | A Unified Knowledge Distillation Framework for Deep Directed Graphical Models | 5.25 | 5.25 | 0.00 | | Reject |
| 557 | Beyond Examples: Constructing Explanation Space for Explaining Prototypes | 4.75 | 5.25 | 0.50 | | Reject |
| 558 | Adversarial Collaborative Learning on Non-IID Features | 5.25 | 5.25 | 0.00 | | Reject |
| 559 | SGDEM: stochastic gradient descent with energy and momentum | 4.50 | 5.25 | 0.75 | | Reject |
| 560 | Geometric Algebra Attention Networks for Small Point Clouds | 5.25 | 5.25 | 0.00 | | Reject |
| 561 | ZeroSARAH: Efficient Nonconvex Finite-Sum Optimization with Zero Full Gradient Computations | 6.00 | 5.25 | -0.75 | | Reject |
| 562 | On Pseudo-Labeling for Class-Mismatch Semi-Supervised Learning | 5.00 | 5.25 | 0.25 | | Reject |
| 563 | Bypassing Logits Bias in Online Class-Incremental Learning with a Generative Framework | 4.75 | 5.25 | 0.50 | | Reject |
| 564 | Improving Meta-Continual Learning Representations with Representation Replay | 4.25 | 5.25 | 1.00 | | Reject |
| 565 | Randomized Primal-Dual Coordinate Method for Large-scale Linearly Constrained Nonsmooth Nonconvex Optimization | 5.25 | 5.25 | 0.00 | | Reject |
| 566 | Tell me why!—Explanations support learning relational and causal structure | 4.50 | 5.25 | 0.75 | | Reject |
| 567 | Benign Overfitting in Adversarially Robust Linear Classification | 5.33 | 5.25 | -0.08 | | Reject |
| 568 | ViViT: Curvature access through the generalized Gauss-Newton's low-rank structure | 5.25 | 5.25 | 0.00 | | Reject |
| 569 | Composing Partial Differential Equations with Physics-Aware Neural Networks | 5.00 | 5.25 | 0.25 | | Reject |
| 570 | Learning to Collaborate | 5.25 | 5.25 | 0.00 | | Reject |
| 571 | Defending Graph Neural Networks via Tensor-Based Robust Graph Aggregation | 5.25 | 5.25 | 0.00 | | Reject |
| 572 | Non-Denoising Forward-Time Diffusions | 5.25 | 5.25 | 0.00 | | Reject |
| 573 | GIR Framework: Learning Graph Positional Embeddings with Anchor Indication and Path Encoding | 5.25 | 5.25 | 0.00 | | Reject |
| 574 | Transductive Universal Transport for Zero-Shot Action Recognition | 5.25 | 5.25 | 0.00 | | Reject |
| 575 | Subpixel object segmentation using wavelets and multiresolution analysis | 5.25 | 5.25 | 0.00 | | Reject |
| 576 | Continuous Control with Action Quantization from Demonstrations | 5.33 | 5.25 | -0.08 | | Reject |
| 577 | That Escalated Quickly: Compounding Complexity by Editing Levels at the Frontier of Agent Capabilities | 5.00 | 5.25 | 0.25 | | Reject |
| 578 | Feature Selection in the Contrastive Analysis Setting | 4.75 | 5.25 | 0.50 | | Reject |
| 579 | Task-Agnostic Graph Neural Explanations | 5.25 | 5.25 | 0.00 | | Reject |
| 580 | Towards Understanding Label Smoothing | 5.25 | 5.25 | 0.00 | | Reject |
| 581 | Iterative Memory Network for Long Sequential User Behavior Modeling in Recommender Systems | 4.75 | 5.25 | 0.50 | | Reject |
| 582 | Learning Controllable Elements Oriented Representations for Reinforcement Learning | 5.25 | 5.25 | 0.00 | | Reject |
| 583 | Few-shot graph link prediction with domain adaptation | 5.25 | 5.25 | 0.00 | | Reject |
| 584 | Successive POI Recommendation via Brain-inspired Spatiotemporal Aware Representation | 5.25 | 5.25 | 0.00 | | Reject |
| 585 | Information-Theoretic Generalization Bounds for Iterative Semi-Supervised Learning | 5.25 | 5.25 | 0.00 | | Reject |
| 586 | Private Multi-Winner Voting For Machine Learning | 5.75 | 5.20 | -0.55 | | Reject |
| 587 | Expected Improvement-based Contextual Bandits | 5.50 | 5.20 | -0.30 | | Reject |
| 588 | Dense-to-Sparse Gate for Mixture-of-Experts | 4.40 | 5.20 | 0.80 | | 5, 3, 6, 5, 3 | | 5, 5, 6, 5, 5 |
| Reject |
| 589 | TorchGeo: deep learning with geospatial data | 5.20 | 5.20 | 0.00 | | 5, 6, 5, 5, 5 | | 5, 6, 5, 5, 5 |
| Reject |
| 590 | Speech-MLP: a simple MLP architecture for speech processing | 5.20 | 5.20 | 0.00 | | 5, 3, 5, 8, 5 | | 5, 3, 5, 8, 5 |
| Reject |
| 591 | ZerO Initialization: Initializing Residual Networks with only Zeros and Ones | 5.20 | 5.20 | 0.00 | | 5, 6, 5, 5, 5 | | 5, 6, 5, 5, 5 |
| Reject |
| 592 | Reasoning With Hierarchical Symbols: Reclaiming Symbolic Policies For Visual Reinforcement Learning | 5.00 | 5.20 | 0.20 | | 6, 3, 8, 5, 3 | | 6, 3, 8, 6, 3 |
| Reject |
| 593 | Local Calibration: Metrics and Recalibration | 5.25 | 5.20 | -0.05 | | Reject |
| 594 | Fundamental Limits of Transfer Learning in Binary Classifications | 5.20 | 5.20 | 0.00 | | 6, 6, 3, 6, 5 | | 6, 6, 3, 6, 5 |
| Reject |
| 595 | Depth Without the Magic: Inductive Bias of Natural Gradient Descent | 5.33 | 5.20 | -0.13 | | Reject |
| 596 | Multi-Agent Language Learning: Symbolic Mapping | 4.80 | 5.20 | 0.40 | | 5, 5, 6, 5, 3 | | 6, 6, 6, 5, 3 |
| Reject |
| 597 | Gradient Explosion and Representation Shrinkage in Infinite Networks | 4.80 | 5.20 | 0.40 | | 5, 3, 8, 5, 3 | | 5, 3, 8, 5, 5 |
| Reject |
| 598 | The Needle in the haystack: Out-distribution aware Self-training in an Open-World Setting | 5.20 | 5.20 | 0.00 | | 5, 3, 5, 8, 5 | | 5, 3, 5, 8, 5 |
| Reject |
| 599 | Reinforcement Learning for Adaptive Mesh Refinement | 4.80 | 5.20 | 0.40 | | 3, 5, 5, 5, 6 | | 5, 5, 5, 5, 6 |
| Reject |
| 600 | Discovering the neural correlate informed nosological relation among multiple neuropsychiatric disorders through dual utilisation of diagnostic information | 4.60 | 5.20 | 0.60 | | 5, 1, 5, 6, 6 | | 8, 1, 5, 6, 6 |
| Reject |
| 601 | Provably Calibrated Regression Under Distribution Drift | 5.00 | 5.00 | 0.00 | | Reject |
| 602 | Robust Imitation via Mirror Descent Inverse Reinforcement Learning | 5.33 | 5.00 | -0.33 | | Reject |
| 603 | Why be adversarial? Let's cooperate!: Cooperative Dataset Alignment via JSD Upper Bound | 5.00 | 5.00 | 0.00 | | Reject |
| 604 | D2-GCN: Data-Dependent GCNs for Boosting Both Efficiency and Scalability | 4.75 | 5.00 | 0.25 | | Reject |
| 605 | Neural Tangent Kernel Empowered Federated Learning | 5.00 | 5.00 | 0.00 | | Reject |
| 606 | VUT: Versatile UI Transformer for Multimodal Multi-Task User Interface Modeling | 5.00 | 5.00 | 0.00 | | Reject |
| 607 | Data Scaling Laws in NMT: The Effect of Noise and Architecture | 5.00 | 5.00 | 0.00 | | Reject |
| 608 | When in Doubt, Summon the Titans: A Framework for Efficient Inference with Large Models | 4.75 | 5.00 | 0.25 | | Reject |
| 609 | Attention: Self-Expression Is All You Need | 5.00 | 5.00 | 0.00 | | Reject |
| 610 | Equalized Robustness: Towards Sustainable Fairness Under Distributional Shifts | 5.00 | 5.00 | 0.00 | | Reject |
| 611 | Novelty detection using ensembles with regularized disagreement | 4.80 | 5.00 | 0.20 | | 6, 3, 5, 5, 5 | | 6, 3, 5, 6, 5 |
| Reject |
| 612 | Resmax: An Alternative Soft-Greedy Operator for Reinforcement Learning | 5.25 | 5.00 | -0.25 | | Reject |
| 613 | Antonymy-Synonymy Discrimination through the Repelling Parasiamese Neural Network | 5.00 | 5.00 | 0.00 | | Reject |
| 614 | Decentralized Cross-Entropy Method for Model-Based Reinforcement Learning | 4.33 | 5.00 | 0.67 | | Reject |
| 615 | Practical Adversarial Attacks on Brain--Computer Interfaces | 4.25 | 5.00 | 0.75 | | Reject |
| 616 | Effective Polynomial Filter Adaptation for Graph Neural Networks | 4.00 | 5.00 | 1.00 | | Reject |
| 617 | Resolving label uncertainty with implicit generative models | 5.00 | 5.00 | 0.00 | | Reject |
| 618 | Object-Centric Neural Scene Rendering | 4.50 | 5.00 | 0.50 | | Reject |
| 619 | Automated Mobile Attention KPConv Networks via A Wide & Deep Predictor | 4.25 | 5.00 | 0.75 | | Reject |
| 620 | Adversarial Weight Perturbation Improves Generalization in Graph Neural Networks | 5.00 | 5.00 | 0.00 | | Reject |
| 621 | Self-supervised regression learning using domain knowledge: Applications to improving self-supervised image denoising | 5.00 | 5.00 | 0.00 | | Reject |
| 622 | Communicating Natural Programs to Humans and Machines | 5.00 | 5.00 | 0.00 | | Reject |
| 623 | Interrogating Paradigms in Self-supervised Graph Representation Learning | 4.50 | 5.00 | 0.50 | | Reject |
| 624 | Quantifying the Controllability of Coarsely Characterized Networked Dynamical Systems | 5.00 | 5.00 | 0.00 | | Reject |
| 625 | Revisiting Locality-Sensitive Binary Codes from Random Fourier Features | 4.75 | 5.00 | 0.25 | | Reject |
| 626 | The hidden label-marginal biases of segmentation losses | 5.00 | 5.00 | 0.00 | | Reject |
| 627 | Word Sense Induction with Knowledge Distillation from BERT | 5.00 | 5.00 | 0.00 | | 3, 6, 5, 6, 5 | | 3, 6, 5, 6, 5 |
| Reject |
| 628 | Data Sharing without Rewards in Multi-Task Offline Reinforcement Learning | 4.33 | 5.00 | 0.67 | | Reject |
| 629 | Learning-Augmented Sketches for Hessians | 5.00 | 5.00 | 0.00 | | Reject |
| 630 | An Optimization Perspective on Realizing Backdoor Injection Attacks on Deep Neural Networks in Hardware | 5.00 | 5.00 | 0.00 | | Reject |
| 631 | Scaling Densities For Improved Density Ratio Estimation | 4.75 | 5.00 | 0.25 | | Reject |
| 632 | A Boosting Approach to Reinforcement Learning | 4.50 | 5.00 | 0.50 | | Reject |
| 633 | Two Sides of the Same Coin: Heterophily and Oversmoothing in Graph Convolutional Neural Networks | 5.00 | 5.00 | 0.00 | | Reject |
| 634 | A Distributional Robustness Perspective on Adversarial Training with the∞-Wasserstein Distance | 5.00 | 5.00 | 0.00 | | Reject |
| 635 | Variance Reduced Domain Randomization for Policy Gradient | 5.00 | 5.00 | 0.00 | | Reject |
| 636 | Xi-learning: Successor Feature Transfer Learning for General Reward Functions | 5.00 | 5.00 | 0.00 | | Reject |
| 637 | FCause: Flow-based Causal Discovery | 4.80 | 5.00 | 0.20 | | 3, 5, 5, 8, 3 | | 3, 6, 5, 8, 3 |
| Reject |
| 638 | Near-Optimal Algorithms for Autonomous Exploration and Multi-Goal Stochastic Shortest Path | 4.75 | 5.00 | 0.25 | | Reject |
| 639 | Plug-In Inversion: Model-Agnostic Inversion for Vision with Data Augmentations | 4.75 | 5.00 | 0.25 | | Reject |
| 640 | Learning an Ethical Module for Bias Mitigation of pre-trained Models | 4.75 | 5.00 | 0.25 | | Reject |
| 641 | Understanding the Generalization of Adam in Learning Neural Networks with Proper Regularization | 5.25 | 5.00 | -0.25 | | Reject |
| 642 | State-Action Joint Regularized Implicit Policy for Offline Reinforcement Learning | 5.00 | 5.00 | 0.00 | | Reject |
| 643 | On Optimal Early Stopping: Overparametrization versus Underparametrization | 5.00 | 5.00 | 0.00 | | Reject |
| 644 | Abelian Neural Networks | 4.67 | 5.00 | 0.33 | | Reject |
| 645 | Direct Molecular Conformation Generation | 4.25 | 5.00 | 0.75 | | Reject |
| 646 | Closed-Loop Control of Additive Manufacturing via Reinforcement Learning | 5.00 | 5.00 | 0.00 | | Reject |
| 647 | Introspective Learning : A Two-Stage approach for Inference in Neural Networks | 5.00 | 5.00 | 0.00 | | Reject |
| 648 | Representations of Computer Programs in the Human Brain | 4.00 | 5.00 | 1.00 | | Reject |
| 649 | SABAL: Sparse Approximation-based Batch Active Learning | 5.00 | 5.00 | 0.00 | | Reject |
| 650 | A Simple and Debiased Sampling Method for Personalized Ranking | 5.00 | 5.00 | 0.00 | | Reject |
| 651 | Value-aware transformers for 1.5d data | 4.67 | 5.00 | 0.33 | | Reject |
| 652 | COLA: Consistent Learning with Opponent-Learning Awareness | 4.75 | 5.00 | 0.25 | | Reject |
| 653 | Examining Scaling and Transfer of Language Model Architectures for Machine Translation | 5.00 | 5.00 | 0.00 | | Reject |
| 654 | Evaluating the Robustness of Time Series Anomaly and Intrusion Detection Methods against Adversarial Attacks | 4.33 | 5.00 | 0.67 | | Reject |
| 655 | Debiasing Pretrained Text Encoders by Paying Attention to Paying Attention | 5.00 | 5.00 | 0.00 | | Reject |
| 656 | Equivariant Heterogeneous Graph Networks | 5.00 | 5.00 | 0.00 | | Reject |
| 657 | Sequential Covariate Shift Detection Using Classifier Two-Sample Tests | 4.00 | 5.00 | 1.00 | | Reject |
| 658 | Mix-MaxEnt: Creating High Entropy Barriers To Improve Accuracy and Uncertainty Estimates of Deterministic Neural Networks | 4.75 | 5.00 | 0.25 | | Reject |
| 659 | Finite-Time Error Bounds for Distributed Linear Stochastic Approximation | 5.20 | 5.00 | -0.20 | | 8, 3, 5, 5, 5 | | 5, 5, 5, 5, 5 |
| Reject |
| 660 | NUQ: Nonparametric Uncertainty Quantification for Deterministic Neural Networks | 4.33 | 5.00 | 0.67 | | Reject |
| 661 | Escaping Saddle Points in Nonconvex Minimax Optimization via Cubic-Regularized Gradient Descent-Ascent | 5.40 | 5.00 | -0.40 | | 8, 8, 3, 3, 5 | | 8, 6, 3, 3, 5 |
| Reject |
| 662 | Are BERT Families Zero-Shot Learners? A Study on Their Potential and Limitations | 5.50 | 5.00 | -0.50 | | Reject |
| 663 | Towards Demystifying Representation Learning with Non-contrastive Self-supervision | 5.00 | 5.00 | 0.00 | | Reject |
| 664 | Bit-aware Randomized Response for Local Differential Privacy in Federated Learning | 4.75 | 5.00 | 0.25 | | Reject |
| 665 | A composable autoencoder-based algorithm for accelerating numerical simulations | 4.00 | 5.00 | 1.00 | | Reject |
| 666 | Permutation invariant graph-to-sequence model for template-free retrosynthesis and reaction prediction | 4.25 | 5.00 | 0.75 | | Reject |
| 667 | Beyond Object Recognition: A New Benchmark towards Object Concept Learning | 5.50 | 5.00 | -0.50 | | Reject |
| 668 | Adversarial robustness against multiplelp-threat models at the price of one and how to quickly fine-tune robust models to another threat model | 4.50 | 5.00 | 0.50 | | Reject |
| 669 | Equal Experience in Recommender Systems | 5.00 | 5.00 | 0.00 | | Reject |
| 670 | Exploring unfairness in Integrated Gradients based attribution methods | 5.00 | 5.00 | 0.00 | | Reject |
| 671 | Decomposing Texture and Semantics for Out-of-distribution Detection | 5.50 | 5.00 | -0.50 | | Reject |
| 672 | VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning | 4.33 | 5.00 | 0.67 | | Reject |
| 673 | FEVERLESS: Fast and Secure Vertical Federated Learning based on XGBoost for Decentralized Labels | 5.00 | 5.00 | 0.00 | | Reject |
| 674 | Grounding Aleatoric Uncertainty in Unsupervised Environment Design | 5.00 | 5.00 | 0.00 | | Reject |
| 675 | Pairwise Adversarial Training for Unsupervised Class-imbalanced Domain Adaptation | 5.00 | 5.00 | 0.00 | | Reject |
| 676 | Fully Decentralized Model-based Policy Optimization with Networked Agents | 4.33 | 5.00 | 0.67 | | Reject |
| 677 | Efficient Packing: Towards 2x NLP Speed-Up without Loss of Accuracy for BERT | 5.00 | 5.00 | 0.00 | | 5, 6, 5, 6, 3 | | 5, 6, 5, 6, 3 |
| Reject |
| 678 | Nonparametric Learning of Two-Layer ReLU Residual Units | 5.00 | 5.00 | 0.00 | | Reject |
| 679 | MergeBERT: Program Merge Conflict Resolution via Neural Transformers | 5.00 | 5.00 | 0.00 | | Reject |
| 680 | YOUR AUTOREGRESSIVE GENERATIVE MODEL CAN BE BETTER IF YOU TREAT IT AS AN ENERGY-BASED ONE | 4.80 | 5.00 | 0.20 | | 5, 6, 5, 5, 3 | | 5, 6, 5, 6, 3 |
| Reject |
| 681 | Optimized Separable Convolution: Yet Another Efficient Convolution Operator | 5.00 | 5.00 | 0.00 | | Reject |
| 682 | Provable Hierarchy-Based Meta-Reinforcement Learning | 5.67 | 5.00 | -0.67 | | Reject |
| 683 | Geometric Random Walk Graph Neural Networks via Implicit Layers | 4.50 | 5.00 | 0.50 | | Reject |
| 684 | What can multi-cloud configuration learn from AutoML? | 4.50 | 5.00 | 0.50 | | Reject |
| 685 | Structured Uncertainty in the Observation Space of Variational Autoencoders | 4.75 | 5.00 | 0.25 | | Reject |
| 686 | Wakening Past Concepts without Past Data: Class-incremental Learning from Placebos | 5.00 | 5.00 | 0.00 | | Reject |
| 687 | Learnability and Expressiveness in Self-Supervised Learning | 4.50 | 5.00 | 0.50 | | Reject |
| 688 | Rethinking the limiting dynamics of SGD: modified loss, phase space oscillations, and anomalous diffusion | 4.25 | 5.00 | 0.75 | | Reject |
| 689 | Combining Diverse Feature Priors | 4.75 | 5.00 | 0.25 | | Reject |
| 690 | Continuous Control With Ensemble Deep Deterministic Policy Gradients | 4.60 | 5.00 | 0.40 | | 6, 6, 3, 3, 5 | | 6, 6, 5, 3, 5 |
| Reject |
| 691 | Self-Distribution Distillation: Efficient Uncertainty Estimation | 4.50 | 5.00 | 0.50 | | Reject |
| 692 | CheXT: Knowledge-Guided Cross-Attention Transformer for Abnormality Classification and Localization in Chest X-rays | 5.00 | 5.00 | 0.00 | | Reject |
| 693 | Function-Space Variational Inference for Deep Bayesian Classification | 5.00 | 5.00 | 0.00 | | Reject |
| 694 | INFERNO: Inferring Object-Centric 3D Scene Representations without Supervision | 4.00 | 5.00 | 1.00 | | Reject |
| 695 | Constrained Discrete Black-Box Optimization using Mixed-Integer Programming | 4.25 | 5.00 | 0.75 | | Reject |
| 696 | MLP-based architecture with variable length input for automatic speech recognition | 3.50 | 5.00 | 1.50 | | Reject |
| 697 | Teacher's pet: understanding and mitigating biases in distillation | 5.00 | 5.00 | 0.00 | | Reject |
| 698 | Adversarial Attacks on Spiking Convolutional Networks for Event-based Vision | 4.50 | 5.00 | 0.50 | | Reject |
| 699 | Improving Generative Adversarial Networks via Adversarial Learning in Latent Space | 4.50 | 5.00 | 0.50 | | Reject |
| 700 | Fieldwise Factorized Networks for Tabular Data Classification | 5.00 | 5.00 | 0.00 | | Reject |
| 701 | Translating Robot Skills: Learning Unsupervised Skill Correspondences Across Robots | 5.50 | 5.00 | -0.50 | | Reject |
| 702 | Imperceptible Black-box Attack via Refining in Salient Region | 4.50 | 5.00 | 0.50 | | Reject |
| 703 | Non-deep Networks | 5.00 | 5.00 | 0.00 | | Reject |
| 704 | FedGEMS: Federated Learning of Larger Server Models via Selective Knowledge Fusion | 4.00 | 5.00 | 1.00 | | Reject |
| 705 | MS2-Transformer: An End-to-End Model for MS/MS-assisted Molecule Identification | 5.00 | 5.00 | 0.00 | | Reject |
| 706 | In defense of dual-encoders for neural ranking | 5.00 | 5.00 | 0.00 | | Reject |
| 707 | Differentiable Top-k Classification Learning | 4.25 | 5.00 | 0.75 | | Reject |
| 708 | Learning Global Spatial Information for Multi-View Object-Centric Models | 4.00 | 5.00 | 1.00 | | Reject |
| 709 | Contrastive Representation Learning for 3D Protein Structures | 5.00 | 5.00 | 0.00 | | Reject |
| 710 | Multi-Agent Constrained Policy Optimisation | 5.00 | 5.00 | 0.00 | | Reject |
| 711 | RL-DARTS: Differentiable Architecture Search for Reinforcement Learning | 5.00 | 5.00 | 0.00 | | Reject |
| 712 | Data-Dependent Randomized Smoothing | 5.00 | 5.00 | 0.00 | | Reject |
| 713 | On the Adversarial Robustness of Vision Transformers | 5.00 | 5.00 | 0.00 | | Reject |
| 714 | Contrastive Learning of 3D Shape Descriptor with Dynamic Adversarial Views | 5.00 | 5.00 | 0.00 | | Reject |
| 715 | Learning Universal User Representations via Self-Supervised Lifelong Behaviors Modeling | 4.33 | 5.00 | 0.67 | | Reject |
| 716 | A Variance Principle Explains why Dropout Finds Flatter Minima | 5.00 | 5.00 | 0.00 | | Reject |
| 717 | On The Quality Assurance Of Concept-Based Representations | 5.00 | 5.00 | 0.00 | | Reject |
| 718 | Enforcing physics-based algebraic constraints for inference of PDE models on unstructured grids | 5.00 | 5.00 | 0.00 | | Reject |
| 719 | Understanding Square Loss in Training Overparametrized Neural Network Classifiers | 5.20 | 5.00 | -0.20 | | 5, 6, 6, 6, 3 | | 5, 5, 6, 6, 3 |
| Reject |
| 720 | Spatial Frequency Sensitivity Regularization for Robustness | 4.25 | 5.00 | 0.75 | | Reject |
| 721 | Objective Evaluation of Deep Visual Interpretations on Time Series Data | 4.50 | 5.00 | 0.50 | | Reject |
| 722 | TRAKR – A reservoir-based tool for fast and accurate classification of neural time-series patterns | 4.33 | 5.00 | 0.67 | | Reject |
| 723 | FlowX: Towards Explainable Graph Neural Networks via Message Flows | 4.75 | 5.00 | 0.25 | | Reject |
| 724 | Short-term memory in neural language models | 4.60 | 5.00 | 0.40 | | 3, 6, 6, 5, 3 | | 5, 6, 6, 5, 3 |
| Reject |
| 725 | A Comprehensive Overhaul of Distilling Unconditional GANs | 4.60 | 5.00 | 0.40 | | 6, 5, 3, 3, 6 | | 6, 5, 5, 3, 6 |
| Reject |
| 726 | Greedy Bayesian Posterior Approximation with Deep Ensembles | 5.00 | 5.00 | 0.00 | | Reject |
| 727 | Neural Manifold Clustering and Embedding | 4.80 | 5.00 | 0.20 | | 6, 5, 5, 5, 3 | | 6, 6, 5, 5, 3 |
| Reject |
| 728 | Can Reinforcement Learning Efficiently Find Stackelberg-Nash Equilibria in General-Sum Markov Games? | 4.75 | 5.00 | 0.25 | | Reject |
| 729 | Model-Agnostic Meta-Attack: Towards Reliable Evaluation of Adversarial Robustness | 5.00 | 5.00 | 0.00 | | Reject |
| 730 | I-PGD-AT: Efficient Adversarial Training via Imitating Iterative PGD Attack | 5.00 | 5.00 | 0.00 | | Reject |
| 731 | Trident Pyramid Networks: The importance of processing at the feature pyramid level for better object detection | 5.00 | 5.00 | 0.00 | | Reject |
| 732 | Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution | 4.50 | 5.00 | 0.50 | | Reject |
| 733 | Input Dependent Sparse Gaussian Processes | 5.00 | 5.00 | 0.00 | | 5, 6, 3, 3, 8 | | 5, 6, 3, 3, 8 |
| Reject |
| 734 | On Multi-objective Policy Optimization as a Tool for Reinforcement Learning: Case Studies in Offline RL and Finetuning | 5.00 | 5.00 | 0.00 | | Reject |
| 735 | Variational Inference via Resolution of Singularities | 4.50 | 5.00 | 0.50 | | Reject |
| 736 | Learning Dynamics Models for Model Predictive Agents | 4.50 | 5.00 | 0.50 | | Reject |
| 737 | Fully differentiable model discovery | 5.00 | 5.00 | 0.00 | | Reject |
| 738 | Training Data Size Induced Double Descent For Denoising Neural Networks and the Role of Training Noise Level | 4.25 | 5.00 | 0.75 | | Reject |
| 739 | EMFlow: Data Imputation in Latent Space via EM and Deep Flow Models | 5.00 | 5.00 | 0.00 | | Reject |
| 740 | Offline Meta-Reinforcement Learning with Online Self-Supervision | 5.00 | 5.00 | 0.00 | | Reject |
| 741 | EP-GAN: Unsupervised Federated Learning with Expectation-Propagation Prior GAN | 5.00 | 5.00 | 0.00 | | Reject |
| 742 | Apollo: An Adaptive Parameter-wised Diagonal Quasi-Newton Method for Nonconvex Stochastic Optimization | 5.00 | 5.00 | 0.00 | | Reject |
| 743 | SubMix: Practical Private Prediction for Large-scale Language Models | 5.00 | 5.00 | 0.00 | | Reject |
| 744 | Symmetry-driven graph neural networks | 5.00 | 5.00 | 0.00 | | Reject |
| 745 | Aug-ILA: More Transferable Intermediate Level Attacks with Augmented References | 4.75 | 5.00 | 0.25 | | Reject |
| 746 | Heterologous Normalization | 5.00 | 5.00 | 0.00 | | Reject |
| 747 | Let Your Heart Speak in its Mother Tongue: Multilingual Captioning of Cardiac Signals | 5.00 | 5.00 | 0.00 | | Reject |
| 748 | Semi-supervised learning objectives as log-likelihoods in a generative model of data curation | 5.67 | 5.00 | -0.67 | | Reject |
| 749 | Logarithmic landscape and power-law escape rate of SGD | 5.00 | 5.00 | 0.00 | | Reject |
| 750 | Understanding and Scheduling Weight Decay | 5.00 | 5.00 | 0.00 | | Reject |
| 751 | A framework of deep neural networks via the solution operator of partial differential equations | 4.50 | 5.00 | 0.50 | | Reject |
| 752 | Decouple and Reconstruct: Mining Discriminative Features for Cross-domain Object Detection | 5.00 | 5.00 | 0.00 | | Reject |
| 753 | TempoRL: Temporal Priors for Exploration in Off-Policy Reinforcement Learning | 5.00 | 4.86 | -0.14 | | 5, 3, 5, 5, 6, 6 | | 3, 3, 6, 3, 8, 8, 3 |
| Reject |
| 754 | Multiresolution Equivariant Graph Variational Autoencoder | 4.83 | 4.83 | 0.00 | | 5, 5, 5, 5, 3, 6 | | 5, 5, 5, 5, 3, 6 |
| Reject |
| 755 | Improving and Assessing Anomaly Detectors for Large-Scale Settings | 5.00 | 4.80 | -0.20 | | 5, 6, 3, 5, 6 | | 5, 5, 3, 5, 6 |
| Reject |
| 756 | Efficient Training and Inference of Hypergraph Reasoning Networks | 4.40 | 4.80 | 0.40 | | 3, 5, 3, 5, 6 | | 3, 6, 3, 6, 6 |
| Reject |
| 757 | DeepSplit: Scalable Verification of Deep Neural Networks via Operator Splitting | 4.80 | 4.80 | 0.00 | | 3, 5, 8, 3, 5 | | 3, 5, 8, 3, 5 |
| Reject |
| 758 | Count-GNN: Graph Neural Networks for Subgraph Isomorphism Counting | 4.80 | 4.80 | 0.00 | | 3, 5, 8, 5, 3 | | 3, 5, 8, 5, 3 |
| Reject |
| 759 | Learning Stable Classifiers by Transferring Unstable Features | 4.60 | 4.80 | 0.20 | | 6, 3, 5, 3, 6 | | 6, 3, 6, 3, 6 |
| Reject |
| 760 | Analogies and Feature Attributions for Model Agnostic Explanation of Similarity Learners | 4.60 | 4.80 | 0.20 | | 1, 6, 5, 5, 6 | | 1, 6, 6, 5, 6 |
| Reject |
| 761 | Neurally boosted supervised spectral clustering | 4.80 | 4.80 | 0.00 | | 3, 5, 3, 5, 8 | | 3, 5, 3, 5, 8 |
| Reject |
| 762 | An Equivalence Between Data Poisoning and Byzantine Gradient Attacks | 4.75 | 4.80 | 0.05 | | Reject |
| 763 | PROMISSING: Pruning Missing Values in Neural Networks | 4.60 | 4.80 | 0.20 | | 3, 6, 6, 5, 3 | | 3, 6, 6, 6, 3 |
| Reject |
| 764 | Disentangling Sources of Risk for Distributional Multi-Agent Reinforcement Learning | 4.60 | 4.80 | 0.20 | | 6, 3, 3, 5, 6 | | 6, 3, 3, 6, 6 |
| Reject |
| 765 | When high-performing models behave poorly in practice: periodic sampling can help | 4.80 | 4.80 | 0.00 | | 5, 5, 6, 5, 3 | | 5, 5, 6, 5, 3 |
| Reject |
| 766 | Towards understanding how momentum improves generalization in deep learning | 4.80 | 4.80 | 0.00 | | 5, 6, 5, 3, 5 | | 5, 6, 5, 3, 5 |
| Reject |
| 767 | Bayesian Active Learning with Fully Bayesian Gaussian Processes | 4.50 | 4.75 | 0.25 | | Reject |
| 768 | Ask2Mask: Guided Data Selection for Masked Speech Modeling | 4.00 | 4.75 | 0.75 | | Reject |
| 769 | Sphere2Vec: Self-Supervised Location Representation Learning on Spherical Surfaces | 4.75 | 4.75 | 0.00 | | Reject |
| 770 | DreamerPro: Reconstruction-Free Model-Based Reinforcement Learning with Prototypical Representations | 4.25 | 4.75 | 0.50 | | Reject |
| 771 | Knowledge Guided Geometric Editing for Unsupervised Drug Design | 4.00 | 4.75 | 0.75 | | Reject |
| 772 | New Definitions and Evaluations for Saliency Methods: Staying Intrinsic and Sound | 4.25 | 4.75 | 0.50 | | Reject |
| 773 | A NEW BACKBONE FOR HYPERSPECTRAL IMAGE RECONSTRUCTION | 4.33 | 4.75 | 0.42 | | Reject |
| 774 | Physics-Informed Neural Operator for Learning Partial Differential Equations | 5.75 | 4.75 | -1.00 | | Reject |
| 775 | TransSlowDown: Efficiency Attacks on Neural Machine Translation Systems | 4.75 | 4.75 | 0.00 | | Reject |
| 776 | Edge Partition Modulated Graph Convolutional Networks | 3.67 | 4.75 | 1.08 | | Reject |
| 777 | Learning Invariant Reward Functions through Trajectory Interventions | 4.25 | 4.75 | 0.50 | | Reject |
| 778 | Localized Randomized Smoothing for Collective Robustness Certification | 4.75 | 4.75 | 0.00 | | Reject |
| 779 | Unsupervised Neural Machine Translation with Generative Language Models Only | 4.75 | 4.75 | 0.00 | | Reject |
| 780 | Ensembles and Cocktails: Robust Finetuning for Natural Language Generation | 5.50 | 4.75 | -0.75 | | Reject |
| 781 | A Communication-Efficient Distributed Gradient Clipping Algorithm for Training Deep Neural Networks | 4.75 | 4.75 | 0.00 | | Reject |
| 782 | Finding General Equilibria in Many-Agent Economic Simulations using Deep Reinforcement Learning | 4.00 | 4.75 | 0.75 | | Reject |
| 783 | Revisiting Layer-wise Sampling in Fast Training for Graph Convolutional Networks | 4.75 | 4.75 | 0.00 | | Reject |
| 784 | Effective Uncertainty Estimation with Evidential Models for Open-World Recognition | 4.50 | 4.75 | 0.25 | | Reject |
| 785 | Recognizing and overcoming the greedy nature of learning in multi-modal deep neural networks | 5.00 | 4.75 | -0.25 | | Reject |
| 786 | On Adversarial Bias and the Robustness of Fair Machine Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 787 | A Rate-Distortion Approach to Domain Generalization | 4.50 | 4.75 | 0.25 | | Reject |
| 788 | Dual Training of Energy-Based Models with Overparametrized Shallow Neural Networks | 4.75 | 4.75 | 0.00 | | Reject |
| 789 | Where is the bottleneck in long-tailed classification? | 4.75 | 4.75 | 0.00 | | Reject |
| 790 | Noise-Contrastive Variational Information Bottleneck Networks | 4.75 | 4.75 | 0.00 | | Reject |
| 791 | Pretrained models are active learners | 4.75 | 4.75 | 0.00 | | Reject |
| 792 | Online MAP Inference and Learning for Nonsymmetric Determinantal Point Processes | 4.75 | 4.75 | 0.00 | | Reject |
| 793 | Flashlight: Enabling Innovation in Tools for Machine Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 794 | Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 795 | Closed-loop Control for Online Continual Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 796 | Defending Backdoor Data Poisoning Attacks by Using Noisy Label Defense Algorithm | 4.75 | 4.75 | 0.00 | | Reject |
| 797 | BWCP: Probabilistic Learning-to-Prune Channels for ConvNets via Batch Whitening | 4.75 | 4.75 | 0.00 | | Reject |
| 798 | Active Learning over Multiple Domains in Natural Language Tasks | 4.75 | 4.75 | 0.00 | | Reject |
| 799 | On the Evolution of Neuron Communities in a Deep Learning Architecture | 4.75 | 4.75 | 0.00 | | Reject |
| 800 | Target Propagation via Regularized Inversion | 4.75 | 4.75 | 0.00 | | Reject |
| 801 | Few-Shot Attribute Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 802 | Cost-Sensitive Hierarchical Classification through Layer-wise Abstentions | 4.75 | 4.75 | 0.00 | | Reject |
| 803 | On the Safety of Interpretable Machine Learning: A Maximum Deviation Approach | 4.50 | 4.75 | 0.25 | | Reject |
| 804 | Learning Time-dependent PDE Solver using Message Passing Graph Neural Networks | 4.25 | 4.75 | 0.50 | | Reject |
| 805 | Certified Robustness for Free in Differentially Private Federated Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 806 | EfficientPhys: Enabling Simple, Fast, and Accurate Camera-Based Vitals Measurement | 4.75 | 4.75 | 0.00 | | Reject |
| 807 | Theoretical Analysis of Consistency Regularization with Limited Augmented Data | 4.00 | 4.75 | 0.75 | | Reject |
| 808 | Fast and Reliable Evaluation of Adversarial Robustness with Minimum-Margin Attack | 4.75 | 4.75 | 0.00 | | Reject |
| 809 | An Empirical Study of Pre-trained Models on Out-of-distribution Generalization | 4.75 | 4.75 | 0.00 | | Reject |
| 810 | Generative Posterior Networks for Approximately Bayesian Epistemic Uncertainty Estimation | 4.25 | 4.75 | 0.50 | | Reject |
| 811 | STORM: Sketch Toward Online Risk Minimization | 4.75 | 4.75 | 0.00 | | Reject |
| 812 | DAIR: Disentangled Attention Intrinsic Regularization for Safe and Efficient Bimanual Manipulation | 4.75 | 4.75 | 0.00 | | Reject |
| 813 | On the One-sided Convergence of Adam-type Algorithms in Non-convex Non-concave Min-max Optimization | 4.75 | 4.75 | 0.00 | | Reject |
| 814 | Set Norm and Equivariant Skip Connections: Putting the Deep in Deep Sets | 4.75 | 4.75 | 0.00 | | Reject |
| 815 | Monotone deep Boltzmann machines | 4.75 | 4.75 | 0.00 | | Reject |
| 816 | Reinforcement Learning State Estimation for High-Dimensional Nonlinear Systems | 4.75 | 4.75 | 0.00 | | Reject |
| 817 | Exploring Covariate and Concept Shift for Detection and Confidence Calibration of Out-of-Distribution Data | 5.00 | 4.75 | -0.25 | | Reject |
| 818 | EBM Life Cycle: MCMC Strategies for Synthesis, Defense, and Density Modeling | 4.75 | 4.75 | 0.00 | | Reject |
| 819 | Continual Backprop: Stochastic Gradient Descent with Persistent Randomness | 4.75 | 4.75 | 0.00 | | Reject |
| 820 | Fast and Efficient Once-For-All Networks for Diverse Hardware Deployment | 4.75 | 4.75 | 0.00 | | Reject |
| 821 | On Anytime Learning at Macroscale | 4.25 | 4.75 | 0.50 | | Reject |
| 822 | Dynamic Graph Representation Learning via Graph Transformer Networks | 4.75 | 4.75 | 0.00 | | Reject |
| 823 | Gaussian Differential Privacy Transformation: from identification to application | 4.25 | 4.75 | 0.50 | | Reject |
| 824 | Constraint-based graph network simulator | 4.00 | 4.75 | 0.75 | | Reject |
| 825 | Can Stochastic Gradient Langevin Dynamics Provide Differential Privacy for Deep Learning? | 4.75 | 4.75 | 0.00 | | Reject |
| 826 | Feudal Reinforcement Learning by Reading Manuals | 4.75 | 4.75 | 0.00 | | Reject |
| 827 | MeshInversion: 3D textured mesh reconstruction with generative prior | 4.75 | 4.75 | 0.00 | | Reject |
| 828 | Deep Fair Discriminative Clustering | 4.75 | 4.75 | 0.00 | | Reject |
| 829 | Learning a metacognition for object detection | 4.50 | 4.75 | 0.25 | | Reject |
| 830 | FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients | 4.75 | 4.75 | 0.00 | | Reject |
| 831 | A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes | 4.75 | 4.75 | 0.00 | | Reject |
| 832 | Improving Hyperparameter Optimization by Planning Ahead | 4.75 | 4.75 | 0.00 | | Reject |
| 833 | Label Smoothed Embedding Hypothesis for Out-of-Distribution Detection | 4.75 | 4.75 | 0.00 | | Reject |
| 834 | Domain Invariant Adversarial Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 835 | Generating Realistic 3D Molecules with an Equivariant Conditional Likelihood Model | 4.25 | 4.75 | 0.50 | | Reject |
| 836 | Molecular Graph Representation Learning via Heterogeneous Motif Graph Construction | 4.75 | 4.75 | 0.00 | | Reject |
| 837 | Towards fast and effective single-step adversarial training | 4.75 | 4.75 | 0.00 | | Reject |
| 838 | Statistically Meaningful Approximation: a Theoretical Analysis for Approximating Turing Machines with Transformers | 4.75 | 4.75 | 0.00 | | Reject |
| 839 | Gradient-based Counterfactual Explanations using Tractable Probabilistic Models | 4.75 | 4.75 | 0.00 | | Reject |
| 840 | Diverse and Consistent Multi-view Networks for Semi-supervised Regression | 4.50 | 4.75 | 0.25 | | Reject |
| 841 | BoolNet: Streamlining Binary Neural Networks Using Binary Feature Maps | 4.75 | 4.75 | 0.00 | | Reject |
| 842 | Discriminator-Weighted Offline Imitation Learning from Suboptimal Demonstrations | 4.75 | 4.75 | 0.00 | | Reject |
| 843 | One Thing to Fool them All: Generating Interpretable, Universal, and Physically-Realizable Adversarial Features | 4.75 | 4.75 | 0.00 | | Reject |
| 844 | Supervised Permutation Invariant Networks for solving the CVRP with bounded fleet size | 4.75 | 4.75 | 0.00 | | Reject |
| 845 | Fast Deterministic Stackelberg Actor-Critic | 4.75 | 4.75 | 0.00 | | Reject |
| 846 | Discrepancy-Optimal Meta-Learning for Domain Generalization | 4.75 | 4.75 | 0.00 | | Reject |
| 847 | Revisiting and Advancing Fast Adversarial Training Through the lens of Bi-Level Optimization | 4.25 | 4.75 | 0.50 | | Reject |
| 848 | Discovering Latent Network Topology in Contextualized Representations with Randomized Dynamic Programming | 4.75 | 4.75 | 0.00 | | Reject |
| 849 | You May Need both Good-GAN and Bad-GAN for Anomaly Detection | 4.75 | 4.75 | 0.00 | | Reject |
| 850 | Learning to Shape Rewards using a Game of Two Partners | 4.25 | 4.75 | 0.50 | | Reject |
| 851 | Federated Learning with GAN-based Data Synthesis for Non-IID Clients | 4.00 | 4.75 | 0.75 | | Reject |
| 852 | Bandwidth-based Step-Sizes for Non-Convex Stochastic Optimization | 5.00 | 4.75 | -0.25 | | Reject |
| 853 | Enhancing semi-supervised learning via self-interested coalitional learning | 5.00 | 4.75 | -0.25 | | Reject |
| 854 | Task-aware Privacy Preservation for Multi-dimensional Data | 4.75 | 4.75 | 0.00 | | Reject |
| 855 | Improving greedy core-set configurations for active learning with uncertainty-scaled distances | 4.75 | 4.75 | 0.00 | | Reject |
| 856 | PERSONALIZED LAB TEST RESPONSE PREDICTION WITH KNOWLEDGE AUGMENTATION | 4.50 | 4.75 | 0.25 | | Reject |
| 857 | How to Improve Sample Complexity of SGD over Highly Dependent Data? | 4.75 | 4.75 | 0.00 | | Reject |
| 858 | Text-Driven Image Manipulation via Semantic-Aware Knowledge Transfer | 4.25 | 4.75 | 0.50 | | Reject |
| 859 | Invariance-Guided Feature Evolution for Few-Shot Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 860 | Understanding the Interaction of Adversarial Training with Noisy Labels | 4.75 | 4.75 | 0.00 | | Reject |
| 861 | Approximating Instance-Dependent Noise via Instance-Confidence Embedding | 4.50 | 4.75 | 0.25 | | Reject |
| 862 | Learning to Solve Combinatorial Problems via Efficient Exploration | 4.50 | 4.75 | 0.25 | | Reject |
| 863 | Interpreting Reinforcement Policies through Local Behaviors | 4.75 | 4.75 | 0.00 | | Reject |
| 864 | Detecting Adversarial Examples Is (Nearly) As Hard As Classifying Them | 4.75 | 4.75 | 0.00 | | Reject |
| 865 | ParaDiS: Parallelly Distributable Slimmable Neural Networks | 4.75 | 4.75 | 0.00 | | Reject |
| 866 | Adaptive Region Pooling for Fine-Grained Representation Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 867 | Generative Negative Replay for Continual Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 868 | Identifying the Limits of Cross-Domain Knowledge Transfer for Pretrained Models | 4.75 | 4.75 | 0.00 | | Reject |
| 869 | Automatic prior selection for meta Bayesian optimization with a case study on tuning deep neural network optimizers | 4.25 | 4.75 | 0.50 | | Reject |
| 870 | Adaptive Pseudo-labeling for Quantum Calculations | 4.75 | 4.75 | 0.00 | | Reject |
| 871 | On the Convergence and Calibration of Deep Learning with Differential Privacy | 5.00 | 4.75 | -0.25 | | Reject |
| 872 | Anarchic Federated Learning | 4.50 | 4.75 | 0.25 | | Reject |
| 873 | Diffusion-Based Representation Learning | 4.75 | 4.75 | 0.00 | | Reject |
| 874 | Defending Against Backdoor Attacks Using Ensembles of Weak Learners | 4.75 | 4.75 | 0.00 | | Reject |
| 875 | Estimating Instance-dependent Label-noise Transition Matrix using DNNs | 4.25 | 4.75 | 0.50 | | Reject |
| 876 | Range-Net: A High Precision Neural SVD | 4.75 | 4.75 | 0.00 | | Reject |
| 877 | Universality of Deep Neural Network Lottery Tickets: A Renormalization Group Perspective | 4.75 | 4.75 | 0.00 | | Reject |
| 878 | FedProf: Selective Federated Learning with Representation Profiling | 4.75 | 4.75 | 0.00 | | Reject |
| 879 | CoLLIE: Continual Learning of Language Grounding from Language-Image Embeddings | 4.25 | 4.75 | 0.50 | | Reject |
| 880 | Batch size-invariance for policy optimization | 4.00 | 4.75 | 0.75 | | Reject |
| 881 | Cognitively Inspired Learning of Incremental Drifting Concepts | 4.75 | 4.75 | 0.00 | | Reject |
| 882 | Dynamic Parameterized Network for CTR Prediction | 4.67 | 4.67 | 0.00 | | Reject |
| 883 | Curriculum Discovery through an Encompassing Curriculum Learning Framework | 4.67 | 4.67 | 0.00 | | Reject |
| 884 | Zero-Shot Recommender Systems | 4.67 | 4.67 | 0.00 | | Reject |
| 885 | G-Mixup: Graph Augmentation for Graph Classification | 4.33 | 4.67 | 0.33 | | Reject |
| 886 | Self-Organized Polynomial-time Coordination Graphs | 4.67 | 4.67 | 0.00 | | Reject |
| 887 | Gesture2Vec: Clustering Gestures using Representation Learning Methods for Co-speech Gesture Generation | 4.67 | 4.67 | 0.00 | | Reject |
| 888 | Towards Generative Latent Variable Models for Speech | 4.67 | 4.67 | 0.00 | | Reject |
| 889 | GARNET: A Spectral Approach to Robust and Scalable Graph Neural Networks | 4.67 | 4.67 | 0.00 | | Reject |
| 890 | Escaping Stochastic Traps with Aleatoric Mapping Agents | 4.33 | 4.67 | 0.33 | | Reject |
| 891 | Subspace State-Space Identification and Model Predictive Control of Nonlinear Dynamical Systems Using Deep Neural Network with Bottleneck | 4.00 | 4.67 | 0.67 | | Reject |
| 892 | ON THE GENERALIZATION OF WASSERSTEIN ROBUST FEDERATED LEARNING | 4.67 | 4.67 | 0.00 | | Reject |
| 893 | On-Target Adaptation | 5.00 | 4.67 | -0.33 | | Reject |
| 894 | Deep Inverse Reinforcement Learning via Adversarial One-Class Classification | 4.67 | 4.67 | 0.00 | | Reject |
| 895 | Towards Generalizable Personalized Federated Learning with Adaptive Local Adaptation | 4.67 | 4.67 | 0.00 | | Reject |
| 896 | Kernel Deformed Exponential Families for Sparse Continuous Attention | 4.67 | 4.67 | 0.00 | | Reject |
| 897 | On Transportation of Mini-batches: A Hierarchical Approach | 4.67 | 4.67 | 0.00 | | Reject |
| 898 | Meta-OLE: Meta-learned Orthogonal Low-Rank Embedding | 5.33 | 4.67 | -0.67 | | Reject |
| 899 | Exploring the Robustness of Distributional Reinforcement Learning against Noisy State Observations | 4.00 | 4.67 | 0.67 | | Reject |
| 900 | Surgical Prediction with Interpretable Latent Representation | 4.67 | 4.67 | 0.00 | | Reject |
| 901 | Graph Information Matters: Understanding Graph Filters from Interaction Probability | 3.67 | 4.67 | 1.00 | | Reject |
| 902 | Closed-Loop Data Transcription to an LDR via Minimaxing Rate Reduction | 4.67 | 4.67 | 0.00 | | Reject |
| 903 | Delving into Feature Space: Improving Adversarial Robustness by Feature Spectral Regularization | 4.67 | 4.67 | 0.00 | | Reject |
| 904 | Graph Barlow Twins: A self-supervised representation learning framework for graphs | 4.67 | 4.67 | 0.00 | | Reject |
| 905 | Cross-Architecture Distillation Using Bidirectional CMOW Embeddings | 4.67 | 4.67 | 0.00 | | Reject |
| 906 | Sparse MoEs meet Efficient Ensembles | 4.67 | 4.67 | 0.00 | | Reject |
| 907 | Quantized sparse PCA for neural network weight compression | 4.67 | 4.67 | 0.00 | | Reject |
| 908 | What classifiers know what they don't know? | 4.67 | 4.67 | 0.00 | | Reject |
| 909 | Robust Deep Neural Networks for Heterogeneous Tabular Data | 4.67 | 4.67 | 0.00 | | Reject |
| 910 | Trading Quality for Efficiency of Graph Partitioning: An Inductive Method across Graphs | 4.67 | 4.67 | 0.00 | | 6, 3, 5, 5, 6, 3 | | 6, 3, 5, 5, 6, 3 |
| Reject |
| 911 | Deep Active Learning with Noise Stability | 4.00 | 4.67 | 0.67 | | Reject |
| 912 | Connecting Data to Mechanisms with Meta Structual Causal Model | 4.67 | 4.67 | 0.00 | | Reject |
| 913 | Global Magnitude Pruning With Minimum Threshold Is All We Need | 4.67 | 4.67 | 0.00 | | Reject |
| 914 | On the Impact of Hard Adversarial Instances on Overfitting in Adversarial Training | 4.67 | 4.67 | 0.00 | | Reject |
| 915 | Tractable Dendritic RNNs for Identifying Unknown Nonlinear Dynamical Systems | 4.67 | 4.67 | 0.00 | | Reject |
| 916 | A Scaling Law for Syn-to-Real Transfer: How Much Is Your Pre-training Effective? | 4.67 | 4.67 | 0.00 | | Reject |
| 917 | Learned Index with Dynamicϵ | 4.67 | 4.67 | 0.00 | | Reject |
| 918 | Distributed Zeroth-Order Optimization: Convergence Rates That Match Centralized Counterpart | 4.67 | 4.67 | 0.00 | | Reject |
| 919 | Distributional Generalization: Structure Beyond Test Error | 4.67 | 4.67 | 0.00 | | Reject |
| 920 | Polyphonic Music Composition: An Adversarial Inverse Reinforcement Learning Approach | 4.67 | 4.67 | 0.00 | | Reject |
| 921 | Born Again Neural Rankers | 4.67 | 4.67 | 0.00 | | Reject |
| 922 | Neural Structure Mapping For Learning Abstract Visual Analogies | 4.20 | 4.60 | 0.40 | | 5, 3, 5, 5, 3 | | 5, 5, 5, 5, 3 |
| Reject |
| 923 | One for Many: an Instagram inspired black-box adversarial attack | 4.40 | 4.60 | 0.20 | | 5, 5, 3, 6, 3 | | 5, 6, 3, 6, 3 |
| Reject |
| 924 | A Systematic Evaluation of Domain Adaptation Algorithms On Time Series Data | 4.20 | 4.60 | 0.40 | | 5, 5, 3, 5, 3 | | 5, 5, 5, 5, 3 |
| Reject |
| 925 | Dominant Datapoints and the Block Structure Phenomenon in Neural Network Hidden Representations | 4.00 | 4.60 | 0.60 | | Reject |
| 926 | Secure Distributed Training at Scale | 4.50 | 4.60 | 0.10 | | Reject |
| 927 | High Precision Score-based Diffusion Models | 4.60 | 4.60 | 0.00 | | 3, 5, 5, 5, 5 | | 3, 5, 5, 5, 5 |
| Reject |
| 928 | Towards Physical, Imperceptible Adversarial Attacks via Adversarial Programs | 4.60 | 4.60 | 0.00 | | 5, 6, 3, 3, 6 | | 5, 6, 3, 3, 6 |
| Reject |
| 929 | Dynamic and Efficient Gray-Box Hyperparameter Optimization for Deep Learning | 4.40 | 4.60 | 0.20 | | 3, 3, 6, 5, 5 | | 3, 3, 6, 5, 6 |
| Reject |
| 930 | Learning to Infer the Structure of Network Games | 4.60 | 4.60 | 0.00 | | 3, 5, 6, 6, 3 | | 3, 5, 6, 6, 3 |
| Reject |
| 931 | Agnostic Personalized Federated Learning with Kernel Factorization | 4.60 | 4.60 | 0.00 | | 3, 6, 5, 3, 6 | | 3, 6, 5, 3, 6 |
| Reject |
| 932 | k-Mixup Regularization for Deep Learning via Optimal Transport | 5.00 | 4.60 | -0.40 | | 3, 8, 6, 5, 3 | | 3, 6, 6, 5, 3 |
| Reject |
| 933 | LEAN: graph-based pruning for convolutional neural networks by extracting longest chains | 4.20 | 4.60 | 0.40 | | 5, 3, 5, 3, 5 | | 5, 5, 5, 3, 5 |
| Reject |
| 934 | Learning Predictive, Online Approximations of Explanatory, Offline Algorithms | 4.25 | 4.60 | 0.35 | | Reject |
| 935 | FedPAGE: A Fast Local Stochastic Gradient Method for Communication-Efficient Federated Learning | 4.75 | 4.60 | -0.15 | | Reject |
| 936 | Maximum Entropy Population Based Training for Zero-Shot Human-AI Coordination | 4.00 | 4.60 | 0.60 | | 3, 3, 6, 5, 3 | | 3, 5, 6, 6, 3 |
| Reject |
| 937 | Invariant Learning with Partial Group Labels | 4.00 | 4.50 | 0.50 | | Reject |
| 938 | Resilience to Multiple Attacks via Adversarially Trained MIMO Ensembles | 4.50 | 4.50 | 0.00 | | Reject |
| 939 | How to Adapt Your Large-Scale Vision-and-Language Model | 4.50 | 4.50 | 0.00 | | Reject |
| 940 | rQdia: Regularizing Q-Value Distributions With Image Augmentation | 4.50 | 4.50 | 0.00 | | Reject |
| 941 | Learning Two-Step Hybrid Policy for Graph-Based Interpretable Reinforcement Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 942 | Learning to Model Editing Processes | 4.50 | 4.50 | 0.00 | | Reject |
| 943 | Unifying Distribution Alignment as a Loss for Imbalanced Semi-supervised Learning | 5.00 | 4.50 | -0.50 | | Reject |
| 944 | Learning Neural Implicit Functions as Object Representations for Robotic Manipulation | 3.50 | 4.50 | 1.00 | | Reject |
| 945 | How does Contrastive Pre-training Connect Disparate Domains? | 4.50 | 4.50 | 0.00 | | Reject |
| 946 | Why do embedding spaces look as they do? | 4.50 | 4.50 | 0.00 | | Reject |
| 947 | CSQ: Centered Symmetric Quantization for Extremely Low Bit Neural Networks | 4.50 | 4.50 | 0.00 | | Reject |
| 948 | OVD-Explorer: A General Information-theoretic Exploration Approach for Reinforcement Learning | 5.00 | 4.50 | -0.50 | | Reject |
| 949 | Efficient Certification for Probabilistic Robustness | 4.50 | 4.50 | 0.00 | | Reject |
| 950 | TIME-LAPSE: Learning to say “I don't know” through spatio-temporal uncertainty scoring | 4.00 | 4.50 | 0.50 | | Reject |
| 951 | NODEAttack: Adversarial Attack on the Energy Consumption of Neural ODEs | 4.50 | 4.50 | 0.00 | | Reject |
| 952 | Fragment-Based Sequential Translation for Molecular Optimization | 4.50 | 4.50 | 0.00 | | Reject |
| 953 | A Deep Latent Space Model for Directed Graph Representation Learning | 4.25 | 4.50 | 0.25 | | Reject |
| 954 | Less is More: Dimension Reduction Finds On-Manifold Adversarial Examples in Hard-Label Attacks | 4.50 | 4.50 | 0.00 | | Reject |
| 955 | SegTime: Precise Time Series Segmentation without Sliding Window | 4.50 | 4.50 | 0.00 | | Reject |
| 956 | Structured Pruning Meets Orthogonality | 4.25 | 4.50 | 0.25 | | Reject |
| 957 | Disentangling Generalization in Reinforcement Learning | 4.00 | 4.50 | 0.50 | | Reject |
| 958 | Model-Efficient Deep Learning with Kernelized Classification | 4.50 | 4.50 | 0.00 | | Reject |
| 959 | Adversarial Distributions Against Out-of-Distribution Detectors | 4.50 | 4.50 | 0.00 | | Reject |
| 960 | Scalable Robust Federated Learning with Provable Security Guarantees | 4.33 | 4.50 | 0.17 | | Reject |
| 961 | Learning Representations for Pixel-based Control: What Matters and Why? | 4.50 | 4.50 | 0.00 | | Reject |
| 962 | FedDrop: Trajectory-weighted Dropout for Efficient Federated Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 963 | CAGE: Probing Causal Relationships in Deep Generative Models | 4.00 | 4.50 | 0.50 | | Reject |
| 964 | The Role of Learning Regime, Architecture and Dataset Structure on Systematic Generalization in Simple Neural Networks | 4.50 | 4.50 | 0.00 | | Reject |
| 965 | Quasi-Newton policy gradient algorithms | 4.50 | 4.50 | 0.00 | | Reject |
| 966 | LPRules: Rule Induction in Knowledge Graphs Using Linear Programming | 4.50 | 4.50 | 0.00 | | Reject |
| 967 | Pruning Edges and Gradients to Learn Hypergraphs from Larger Sets | 4.50 | 4.50 | 0.00 | | Reject |
| 968 | Federated Learning with Heterogeneous Architectures using Graph HyperNetworks | 4.50 | 4.50 | 0.00 | | Reject |
| 969 | Pareto Frontier Approximation Network (PA-Net) Applied to Multi-objective TSP | 4.50 | 4.50 | 0.00 | | Reject |
| 970 | An Investigation into the Role of Author Demographics in ICLR Participation and Review | 4.50 | 4.50 | 0.00 | | Reject |
| 971 | Learning Efficient and Robust Ordinary Differential Equations via Diffeomorphisms | 4.50 | 4.50 | 0.00 | | Reject |
| 972 | Adaptive Behavior Cloning Regularization for Stable Offline-to-Online Reinforcement Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 973 | AIR-Net: Adaptive and Implicit Regularization Neural Network for matrix completion | 4.50 | 4.50 | 0.00 | | Reject |
| 974 | Addressing the Stability-Plasticity Dilemma via Knowledge-Aware Continual Learning | 4.25 | 4.50 | 0.25 | | Reject |
| 975 | Understanding Generalized Label Smoothing when Learning with Noisy Labels | 4.75 | 4.50 | -0.25 | | Reject |
| 976 | Iterative Hierarchical Attention for Answering Complex Questions over Long Documents | 4.00 | 4.50 | 0.50 | | Reject |
| 977 | Hypothesis Driven Coordinate Ascent for Reinforcement Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 978 | Brittle interpretations: The Vulnerability of TCAV and Other Concept-based Explainability Tools to Adversarial Attack | 4.00 | 4.50 | 0.50 | | Reject |
| 979 | Logit Attenuating Weight Normalization | 4.50 | 4.50 | 0.00 | | Reject |
| 980 | Local Augmentation for Graph Neural Networks | 4.50 | 4.50 | 0.00 | | Reject |
| 981 | Variable Length Variable Quality Audio Steganography | 4.50 | 4.50 | 0.00 | | Reject |
| 982 | Characterizing and Measuring the Similarity of Neural Networks with Persistent Homology | 4.50 | 4.50 | 0.00 | | Reject |
| 983 | Representation Consolidation from Multiple Expert Teachers | 4.50 | 4.50 | 0.00 | | Reject |
| 984 | Pareto Navigation Gradient Descent: a First Order Algorithm for Optimization in Pareto Set | 4.75 | 4.50 | -0.25 | | Reject |
| 985 | Imitation Learning from Pixel Observations for Continuous Control | 4.50 | 4.50 | 0.00 | | Reject |
| 986 | From SCAN to Real Data: Systematic Generalization via Meaningful Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 987 | Differentially Private SGD with Sparse Gradients | 4.50 | 4.50 | 0.00 | | Reject |
| 988 | Inference-Time Personalized Federated Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 989 | Eigenspace Restructuring: a Principle of Space and Frequency in Neural Networks | 5.75 | 4.50 | -1.25 | | Reject |
| 990 | PARL: Enhancing Diversity of Ensemble Networks to Resist Adversarial Attacks via Pairwise Adversarially Robust Loss Function | 4.00 | 4.50 | 0.50 | | Reject |
| 991 | Density-based Clustering with Kernel Diffusion | 4.00 | 4.50 | 0.50 | | Reject |
| 992 | Provable Learning of Convolutional Neural Networks with Data Driven Features | 4.50 | 4.50 | 0.00 | | Reject |
| 993 | FaceDet3D: Facial Expressions with 3D Geometric Detail Hallucination | 4.50 | 4.50 | 0.00 | | Reject |
| 994 | FastRPB: a Scalable Relative Positional Encoding for Long Sequence Tasks | 4.50 | 4.50 | 0.00 | | Reject |
| 995 | Generative Adversarial Training for Neural Combinatorial Optimization Models | 4.50 | 4.50 | 0.00 | | Reject |
| 996 | Protect the weak: Class focused online learning for adversarial training | 4.50 | 4.50 | 0.00 | | Reject |
| 997 | Combining Differential Privacy and Byzantine Resilience in Distributed SGD | 4.50 | 4.50 | 0.00 | | Reject |
| 998 | SiT: Simulation Transformer for Particle-based Physics Simulation | 4.50 | 4.50 | 0.00 | | Reject |
| 999 | MAGNEx: A Model Agnostic Global Neural Explainer | 4.50 | 4.50 | 0.00 | | Reject |
| 1000 | SpecTRA: Spectral Transformer for Graph Representation Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 1001 | Personalized Neural Architecture Search for Federated Learning | 4.50 | 4.50 | 0.00 | | Reject |
| 1002 | BLOOD: Bi-level Learning Framework for Out-of-distribution Generalization | 4.50 | 4.50 | 0.00 | | Reject |
| 1003 | Bolstering Stochastic Gradient Descent with Model Building | 4.50 | 4.50 | 0.00 | | Reject |
| 1004 | Understanding the robustness-accuracy tradeoff by rethinking robust fairness | 4.50 | 4.50 | 0.00 | | Reject |
| 1005 | BCDR: Betweenness Centrality-based Distance Resampling for Graph Shortest Distance Embedding | 5.00 | 4.50 | -0.50 | | Reject |
| 1006 | A General Unified Graph Neural Network Framework Against Adversarial Attacks | 4.50 | 4.50 | 0.00 | | Reject |
| 1007 | Divide and Explore: Multi-Agent Separate Exploration with Shared Intrinsic Motivations | 4.50 | 4.50 | 0.00 | | Reject |
| 1008 | Generating Novel Scene Compositions from Single Images and Videos | 4.50 | 4.50 | 0.00 | | Reject |
| 1009 | Interactively Generating Explanations for Transformer Language Models | 4.50 | 4.50 | 0.00 | | Reject |
| 1010 | PI-GNN: Towards Robust Semi-Supervised Node Classification against Noisy Labels | 4.50 | 4.50 | 0.00 | | Reject |
| 1011 | An object-centric sensitivity analysis of deep learning based instance segmentation | 4.25 | 4.50 | 0.25 | | Reject |
| 1012 | GANet: Glyph-Attention Network for Few-Shot Font Generation | 4.50 | 4.50 | 0.00 | | Reject |
| 1013 | Model-Based Opponent Modeling | 4.50 | 4.50 | 0.00 | | Reject |
| 1014 | Centroid Approximation for Bootstrap | 4.50 | 4.50 | 0.00 | | Reject |
| 1015 | Deep Q-Network with Proximal Iteration | 4.50 | 4.50 | 0.00 | | Reject |
| 1016 | Log-Polar Space Convolution | 4.50 | 4.50 | 0.00 | | Reject |
| 1017 | How to decay your learning rate | 4.50 | 4.50 | 0.00 | | Reject |
| 1018 | A Broad Dataset is All You Need for One-Shot Object Detection | 4.50 | 4.50 | 0.00 | | Reject |
| 1019 | Riemannian Manifold Embeddings for Straight-Through Estimator | 4.50 | 4.50 | 0.00 | | Reject |
| 1020 | Physical Gradients for Deep Learning | 4.25 | 4.50 | 0.25 | | Reject |
| 1021 | Classical and Quantum Algorithms for Orthogonal Neural Networks | 4.50 | 4.50 | 0.00 | | Reject |
| 1022 | Learning Rich Nearest Neighbor Representations from Self-supervised Ensembles | 4.50 | 4.50 | 0.00 | | Reject |
| 1023 | DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons | 4.50 | 4.50 | 0.00 | | Reject |
| 1024 | Path Integrals for the Attribution of Model Uncertainties | 4.50 | 4.50 | 0.00 | | Reject |
| 1025 | Prototype Based Classification from Hierarchy to Fairness | 4.50 | 4.50 | 0.00 | | Reject |
| 1026 | Stochastic Deep Networks with Linear Competing Units for Model-Agnostic Meta-Learning | 3.50 | 4.50 | 1.00 | | Reject |
| 1027 | Embedding Compression with Hashing for Efficient Representation Learning in Graph | 4.50 | 4.50 | 0.00 | | Reject |
| 1028 | Taking ROCKET on an efficiency mission: A distributed solution for fast and accurate multivariate time series classification | 4.43 | 4.43 | 0.00 | | 5, 3, 6, 5, 6, 3, 3 | | 5, 3, 6, 5, 6, 3, 3 |
| Reject |
| 1029 | Fast and Sample-Efficient Domain Adaptation for Autoencoder-Based End-to-End Communication | 4.40 | 4.40 | 0.00 | | 5, 3, 6, 3, 5 | | 5, 3, 6, 3, 5 |
| Reject |
| 1030 | A Study on Representation Transfer for Few-Shot Learning | 4.40 | 4.40 | 0.00 | | 5, 5, 3, 6, 3 | | 5, 5, 3, 6, 3 |
| Reject |
| 1031 | Learning Higher-Order Dynamics in Video-Based Cardiac Measurement | 4.40 | 4.40 | 0.00 | | 5, 6, 5, 3, 3 | | 5, 6, 5, 3, 3 |
| Reject |
| 1032 | Mind Your Bits and Errors: Prioritizing the Bits that Matter in Variational Autoencoders | 4.40 | 4.40 | 0.00 | | 5, 3, 5, 3, 6 | | 5, 3, 5, 3, 6 |
| Reject |
| 1033 | Symmetric Machine Theory of Mind | 4.00 | 4.40 | 0.40 | | 6, 3, 3, 3, 5 | | 6, 3, 5, 3, 5 |
| Reject |
| 1034 | Human-Level Control without Server-Grade Hardware | 4.20 | 4.40 | 0.20 | | 3, 5, 5, 5, 3 | | 3, 5, 5, 6, 3 |
| Reject |
| 1035 | Transliteration: A Simple Technique For Improving Multilingual Language Modeling | 4.00 | 4.40 | 0.40 | | 3, 3, 3, 6, 5 | | 5, 3, 3, 6, 5 |
| Reject |
| 1036 | Multi-Resolution Continuous Normalizing Flows | 4.40 | 4.40 | 0.00 | | 6, 5, 3, 5, 3 | | 6, 5, 3, 5, 3 |
| Reject |
| 1037 | Learning Temporally-Consistent Representations for Data-Efficient Reinforcement Learning | 4.40 | 4.40 | 0.00 | | 5, 3, 5, 6, 3 | | 5, 3, 5, 6, 3 |
| Reject |
| 1038 | REFACTOR: Learning to Extract Theorems from Proofs | 4.40 | 4.40 | 0.00 | | 5, 3, 3, 6, 5 | | 5, 3, 3, 6, 5 |
| Reject |
| 1039 | Gradual Domain Adaptation in the Wild: When Intermediate Distributions are Absent | 4.40 | 4.40 | 0.00 | | 6, 3, 5, 3, 5 | | 6, 3, 5, 3, 5 |
| Reject |
| 1040 | WHY FLATNESS DOES AND DOES NOT CORRELATE WITH GENERALIZATION FOR DEEP NEURAL NETWORKS | 4.40 | 4.40 | 0.00 | | 3, 3, 5, 5, 6 | | 3, 3, 5, 5, 6 |
| Reject |
| 1041 | Uniform Generalization Bounds for Overparameterized Neural Networks | 4.80 | 4.40 | -0.40 | | 6, 1, 8, 3, 6 | | 6, 1, 6, 3, 6 |
| Reject |
| 1042 | Aggressive Q-Learning with Ensembles: Achieving Both High Sample Efficiency and High Asymptotic Performance | 4.00 | 4.40 | 0.40 | | 3, 3, 5, 3, 6 | | 3, 6, 5, 3, 5 |
| Reject |
| 1043 | On the Impact of Client Sampling on Federated Learning Convergence | 4.40 | 4.40 | 0.00 | | 5, 5, 3, 6, 3 | | 5, 5, 3, 6, 3 |
| Reject |
| 1044 | Graph Convolutional Networks via Adaptive Filter Banks | 4.40 | 4.40 | 0.00 | | 6, 3, 5, 3, 5 | | 6, 3, 5, 3, 5 |
| Reject |
| 1045 | On Convergence of Federated Averaging Langevin Dynamics | 4.40 | 4.40 | 0.00 | | 3, 5, 3, 5, 6 | | 3, 5, 3, 5, 6 |
| Reject |
| 1046 | NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search | 4.40 | 4.40 | 0.00 | | 5, 5, 3, 6, 3 | | 5, 5, 3, 6, 3 |
| Reject |
| 1047 | Privacy Auditing of Machine Learning using Membership Inference Attacks | 3.67 | 4.33 | 0.67 | | Reject |
| 1048 | ED2: An Environment Dynamics Decomposition Framework for World Model Construction | 4.33 | 4.33 | 0.00 | | Reject |
| 1049 | Adaptive Activation-based Structured Pruning | 4.33 | 4.33 | 0.00 | | Reject |
| 1050 | Explore and Control with Adversarial Surprise | 4.33 | 4.33 | 0.00 | | Reject |
| 1051 | Learning Neural Causal Models with Active Interventions | 4.33 | 4.33 | 0.00 | | Reject |
| 1052 | MixRL: Data Mixing Augmentation for Regression using Reinforcement Learning | 4.33 | 4.33 | 0.00 | | Reject |
| 1053 | Learning to Act with Affordance-Aware Multimodal Neural SLAM | 4.67 | 4.33 | -0.33 | | Reject |
| 1054 | DPP-TTS: Diversifying prosodic features of speech via determinantal point processes | 3.67 | 4.33 | 0.67 | | Reject |
| 1055 | Character Generation through Self-Supervised Vectorization | 4.33 | 4.33 | 0.00 | | Reject |
| 1056 | Encoding Hierarchical Information in Neural Networks Helps in Subpopulation Shift | 4.33 | 4.33 | 0.00 | | Reject |
| 1057 | Distributionally Robust Recourse Action | 4.33 | 4.33 | 0.00 | | Reject |
| 1058 | C5T5: Controllable Generation of Organic Molecules with Transformers | 4.33 | 4.33 | 0.00 | | Reject |
| 1059 | Robust Robotic Control from Pixels using Contrastive Recurrent State-Space Models | 4.67 | 4.33 | -0.33 | | Reject |
| 1060 | Automated Channel Pruning with Learned Importance | 4.33 | 4.33 | 0.00 | | Reject |
| 1061 | Analyzing the Effects of Classifier Lipschitzness on Explainers | 4.33 | 4.33 | 0.00 | | Reject |
| 1062 | BIGRoC: Boosting Image Generation via a Robust Classifier | 4.67 | 4.33 | -0.33 | | Reject |
| 1063 | Non-Parametric Neuro-Adaptive Control Subject to Task Specifications | 3.00 | 4.33 | 1.33 | | Reject |
| 1064 | Distribution-Driven Disjoint Prediction Intervals for Deep Learning | 4.33 | 4.33 | 0.00 | | Reject |
| 1065 | Safe Deep RL in 3D Environments using Human Feedback | 4.67 | 4.33 | -0.33 | | Reject |
| 1066 | Contrastive Embeddings for Neural Architectures | 4.33 | 4.33 | 0.00 | | Reject |
| 1067 | Benchmarking person re-identification approaches and training datasets for practical real-world implementations | 4.00 | 4.33 | 0.33 | | Reject |
| 1068 | Multivariate Time Series Forecasting with Latent Graph Inference | 4.33 | 4.33 | 0.00 | | Reject |
| 1069 | Robustmix: Improving Robustness by Regularizing the Frequency Bias of Deep Nets | 4.33 | 4.33 | 0.00 | | Reject |
| 1070 | Soteria: In search of efficient neural networks for private inference | 4.33 | 4.33 | 0.00 | | Reject |
| 1071 | An Efficient and Reliable Tolerance-Based Algorithm for Principal Component Analysis | 4.33 | 4.33 | 0.00 | | Reject |
| 1072 | Assisted Learning for Organizations with Limited Imbalanced Data | 4.33 | 4.33 | 0.00 | | Reject |
| 1073 | Directional Bias Helps Stochastic Gradient Descent to Generalize in Nonparametric Model | 4.33 | 4.33 | 0.00 | | Reject |
| 1074 | A Collaborative Attention Adaptive Network for Financial Market Forecasting | 4.33 | 4.33 | 0.00 | | Reject |
| 1075 | DIGRAC: Digraph Clustering Based on Flow Imbalance | 4.33 | 4.33 | 0.00 | | Reject |
| 1076 | Chaining Data - A Novel Paradigm in Artificial Intelligence Exemplified with NMF based Clustering | 4.67 | 4.33 | -0.33 | | Reject |
| 1077 | Towards Scheduling Federated Deep Learning using Meta-Gradients for Inter-Hospital Learning | 4.33 | 4.33 | 0.00 | | Reject |
| 1078 | Imbalanced Adversarial Training with Reweighting | 4.25 | 4.25 | 0.00 | | Reject |
| 1079 | Zero-Shot Reward Specification via Grounded Natural Language | 4.25 | 4.25 | 0.00 | | Reject |
| 1080 | Text Style Transfer with Confounders | 4.25 | 4.25 | 0.00 | | Reject |
| 1081 | Learning Minimal Representations with Model Invariance | 4.25 | 4.25 | 0.00 | | Reject |
| 1082 | Data-Efficient Augmentation for Training Neural Networks | 4.25 | 4.25 | 0.00 | | Reject |
| 1083 | Low-Cost Algorithmic Recourse for Users With Uncertain Cost Functions | 4.25 | 4.25 | 0.00 | | Reject |
| 1084 | Logical Activation Functions: Logit-space equivalents of Boolean Operators | 4.25 | 4.25 | 0.00 | | Reject |
| 1085 | Two Birds, One Stone: Achieving both Differential Privacy and Certified Robustness for Pre-trained Classifiers via Input Perturbation | 4.25 | 4.25 | 0.00 | | Reject |
| 1086 | Improving Fairness via Federated Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1087 | SPLID: Self-Imitation Policy Learning through Iterative Distillation | 4.25 | 4.25 | 0.00 | | Reject |
| 1088 | Generating Scenes with Latent Object Models | 3.75 | 4.25 | 0.50 | | Reject |
| 1089 | Adversarially Robust Models may not Transfer Better: Sufficient Conditions for Domain Transferability from the View of Regularization | 4.00 | 4.25 | 0.25 | | Reject |
| 1090 | Distinguishing rule- and exemplar-based generalization in learning systems | 4.00 | 4.25 | 0.25 | | Reject |
| 1091 | Brain insights improve RNNs' accuracy and robustness for hierarchical control of continually learned autonomous motor motifs | 4.25 | 4.25 | 0.00 | | Reject |
| 1092 | Explaining Off-Policy Actor-Critic From A Bias-Variance Perspective | 4.25 | 4.25 | 0.00 | | Reject |
| 1093 | Federated Learning via Plurality Vote | 4.25 | 4.25 | 0.00 | | Reject |
| 1094 | Adapting Stepsizes by Momentumized Gradients Improves Optimization and Generalization | 4.50 | 4.25 | -0.25 | | Reject |
| 1095 | Cell2State: Learning Cell State Representations From Barcoded Single-Cell Gene-Expression Transitions | 4.25 | 4.25 | 0.00 | | Reject |
| 1096 | On the interventional consistency of autoencoders | 4.25 | 4.25 | 0.00 | | Reject |
| 1097 | AARL: Automated Auxiliary Loss for Reinforcement Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1098 | Learning Neural Acoustic Fields | 3.00 | 4.25 | 1.25 | | Reject |
| 1099 | CONTROLLING THE MEMORABILITY OF REAL AND UNREAL FACE IMAGES | 4.25 | 4.25 | 0.00 | | Reject |
| 1100 | Automatic Forecasting via Meta-Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1101 | SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training | 4.25 | 4.25 | 0.00 | | Reject |
| 1102 | Decision Tree Algorithms for MDP | 4.25 | 4.25 | 0.00 | | Reject |
| 1103 | Pretraining for Language Conditioned Imitation with Transformers | 4.25 | 4.25 | 0.00 | | Reject |
| 1104 | Learning Structure from the Ground up---Hierarchical Representation Learning by Chunking | 4.25 | 4.25 | 0.00 | | Reject |
| 1105 | Non-convex Optimization for Learning a Fair Predictor under Equalized Loss Fairness Constraint | 4.50 | 4.25 | -0.25 | | Reject |
| 1106 | Node-Level Differentially Private Graph Neural Networks | 4.25 | 4.25 | 0.00 | | Reject |
| 1107 | What Would the Expertdo(⋅)?: Causal Imitation Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1108 | Deep Probability Estimation | 4.50 | 4.25 | -0.25 | | Reject |
| 1109 | Tackling Oversmoothing of GNNs with Contrastive Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1110 | Contrastive Mutual Information Maximization for Binary Neural Networks | 4.25 | 4.25 | 0.00 | | Reject |
| 1111 | Learning Rate Grafting: Transferability of Optimizer Tuning | 4.25 | 4.25 | 0.00 | | Reject |
| 1112 | Congested bandits: Optimal routing via short-term resets | 4.25 | 4.25 | 0.00 | | Reject |
| 1113 | Efficient Image Representation Learning with Federated Sampled Softmax | 4.25 | 4.25 | 0.00 | | Reject |
| 1114 | Learning Graph Representations for Influence Maximization | 4.50 | 4.25 | -0.25 | | Reject |
| 1115 | Extreme normalization: approximating full-data batch normalization with single examples | 4.25 | 4.25 | 0.00 | | Reject |
| 1116 | DEEP GRAPH TREE NETWORKS | 3.75 | 4.25 | 0.50 | | Reject |
| 1117 | The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning | 4.25 | 4.25 | 0.00 | | Reject |
| 1118 | SGORNN: Combining Scalar Gates and Orthogonal Constraints in Recurrent Networks | 4.00 | 4.25 | 0.25 | | Reject |
| 1119 | Understanding Overfitting in Reweighting Algorithms for Worst-group Performance | 4.25 | 4.25 | 0.00 | | Reject |
| 1120 | Advancing Nearest Neighbor Explanation-by-Example with Critical Classification Regions | 4.25 | 4.25 | 0.00 | | Reject |
| 1121 | RainNet: A Large-Scale Imagery Dataset for Spatial Precipitation Downscaling | 4.25 | 4.25 | 0.00 | | Reject |
| 1122 | Unified Recurrence Modeling for Video Action Anticipation | 5.00 | 4.25 | -0.75 | | Reject |
| 1123 | On Invariance Penalties for Risk Minimization | 4.25 | 4.25 | 0.00 | | Reject |
| 1124 | Perturbation Deterioration: The Other Side of Catastrophic Overfitting | 4.25 | 4.25 | 0.00 | | Reject |
| 1125 | MetaBalance: High-Performance Neural Networks for Class-Imbalanced Data | 4.25 | 4.25 | 0.00 | | Reject |
| 1126 | SpanDrop: Simple and Effective Counterfactual Learning for Long Sequences | 4.25 | 4.25 | 0.00 | | Reject |
| 1127 | LCS: Learning Compressible Subspaces for Adaptive Network Compression at Inference Time | 4.25 | 4.25 | 0.00 | | Reject |
| 1128 | Evaluating Deep Graph Neural Networks | 4.25 | 4.25 | 0.00 | | Reject |
| 1129 | A Fair Generative Model Using Total Variation Distance | 4.00 | 4.25 | 0.25 | | Reject |
| 1130 | Delayed Geometric Discounts: An alternative criterion for Reinforcement Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1131 | Bit-wise Training of Neural Network Weights | 4.00 | 4.25 | 0.25 | | Reject |
| 1132 | Does Entity Abstraction Help Generative Transformers Reason? | 4.25 | 4.25 | 0.00 | | Reject |
| 1133 | Sharp Attention for Sequence to Sequence Learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1134 | An Investigation on Hardware-Aware Vision Transformer Scaling | 5.00 | 4.25 | -0.75 | | Reject |
| 1135 | Graph Piece: Efficiently Generating High-Quality Molecular Graphs with Substructures | 3.50 | 4.25 | 0.75 | | Reject |
| 1136 | VoiceFixer: Toward General Speech Restoration with Neural Vocoder | 4.25 | 4.25 | 0.00 | | Reject |
| 1137 | Reward Shifting for Optimistic Exploration and Conservative Exploitation | 4.00 | 4.25 | 0.25 | | Reject |
| 1138 | Red Alarm for Pre-trained Models: Universal Vulnerability to Neuron-Level Backdoor Attacks | 4.25 | 4.25 | 0.00 | | Reject |
| 1139 | Improved Image Generation via Sparsity | 4.25 | 4.25 | 0.00 | | Reject |
| 1140 | Triangular Dropout: Variable Network Width without Retraining | 4.00 | 4.25 | 0.25 | | Reject |
| 1141 | Improving Adversarial Defense with Self-supervised Test-time Fine-tuning | 4.25 | 4.25 | 0.00 | | Reject |
| 1142 | Meta-Learning an Inference Algorithm for Probabilistic Programs | 4.25 | 4.25 | 0.00 | | Reject |
| 1143 | Isotropic Contextual Representations through Variational Regularization | 4.25 | 4.25 | 0.00 | | Reject |
| 1144 | Enforcing fairness in private federated learning via the modified method of differential multipliers | 4.25 | 4.25 | 0.00 | | Reject |
| 1145 | Pixab-CAM: Attend Pixel, not Channel | 4.25 | 4.25 | 0.00 | | Reject |
| 1146 | White Paper Assistance: A Step Forward Beyond the Shortcut Learning | 3.75 | 4.25 | 0.50 | | Reject |
| 1147 | Video Forgery Detection Using Multiple Cues on Fusion of EfficientNet and Swin Transformer | 4.25 | 4.25 | 0.00 | | Reject |
| 1148 | Beyond Quantization: Power aware neural networks | 4.25 | 4.25 | 0.00 | | Reject |
| 1149 | ContraQA: Question Answering under Contradicting Contexts | 4.25 | 4.25 | 0.00 | | Reject |
| 1150 | A Koopman Approach to Understanding Sequence Neural Models | 4.25 | 4.25 | 0.00 | | Reject |
| 1151 | SemiRetro: Semi-template framework boosts deep retrosynthesis prediction | 6.00 | 4.25 | -1.75 | | Reject |
| 1152 | Can standard training with clean images outperform adversarial one in robust accuracy? | 4.25 | 4.25 | 0.00 | | Reject |
| 1153 | VICE: Variational Inference for Concept Embeddings | 4.25 | 4.25 | 0.00 | | Reject |
| 1154 | Evaluating generative networks using Gaussian mixtures of image features | 4.50 | 4.25 | -0.25 | | Reject |
| 1155 | GraphEBM: Towards Permutation Invariant and Multi-Objective Molecular Graph Generation | 4.25 | 4.25 | 0.00 | | Reject |
| 1156 | Two Regimes of Generalization for Non-Linear Metric Learning | 4.00 | 4.25 | 0.25 | | Reject |
| 1157 | Kalman Filter Is All You Need: Optimization Works When Noise Estimation Fails | 4.25 | 4.25 | 0.00 | | Reject |
| 1158 | Learning to Prompt for Vision-Language Models | 4.25 | 4.25 | 0.00 | | Reject |
| 1159 | Learning Explicit Credit Assignment for Multi-agent Joint Q-learning | 4.25 | 4.25 | 0.00 | | Reject |
| 1160 | Learning to Solve an Order Fulfillment Problem in Milliseconds with Edge-Feature-Embedded Graph Attention | 4.25 | 4.25 | 0.00 | | Reject |
| 1161 | Semi-supervised Long-tailed Recognition using Alternate Sampling | 4.20 | 4.20 | 0.00 | | 5, 5, 1, 5, 5 | | 5, 5, 1, 5, 5 |
| Reject |
| 1162 | Why so pessimistic? Estimating uncertainties for offline RL through ensembles, and why their independence matters. | 4.50 | 4.20 | -0.30 | | Reject |
| 1163 | SpaceMAP: Visualizing Any Data in 2-dimension by Space Expansion | 4.20 | 4.20 | 0.00 | | 5, 5, 3, 5, 3 | | 5, 5, 3, 5, 3 |
| Reject |
| 1164 | On the Expressiveness and Learning of Relational Neural Networks on Hypergraphs | 4.20 | 4.20 | 0.00 | | 3, 5, 5, 3, 5 | | 3, 5, 5, 3, 5 |
| Reject |
| 1165 | DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models | 5.00 | 4.20 | -0.80 | | Reject |
| 1166 | QTN-VQC: An End-to-End Learning Framework for Quantum Neural Networks | 3.80 | 4.20 | 0.40 | | 5, 3, 5, 3, 3 | | 5, 3, 5, 3, 5 |
| Reject |
| 1167 | Wavelet-Packet Powered Deepfake Image Detection | 4.67 | 4.20 | -0.47 | | Reject |
| 1168 | Knowledge Based Multilingual Language Model | 4.40 | 4.20 | -0.20 | | 3, 6, 3, 5, 5 | | 3, 5, 3, 5, 5 |
| Reject |
| 1169 | On the exploitative behavior of adversarial training against adversarial attacks | 4.20 | 4.20 | 0.00 | | 5, 5, 3, 3, 5 | | 5, 5, 3, 3, 5 |
| Reject |
| 1170 | Stable cognitive maps for Path Integration emerge from fusing visual and proprioceptive sensors | 4.00 | 4.20 | 0.20 | | 6, 3, 3, 3, 5 | | 5, 5, 3, 3, 5 |
| Reject |
| 1171 | Language Model Pre-training on True Negatives | 4.20 | 4.20 | 0.00 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 5, 5 |
| Reject |
| 1172 | Noise Reconstruction and Removal Network: A New Way to Denoise FIB-SEM Images | 3.80 | 4.20 | 0.40 | | 3, 5, 3, 5, 3 | | 3, 5, 5, 5, 3 |
| Reject |
| 1173 | Causal Discovery via Cholesky Factorization | 4.20 | 4.20 | 0.00 | | 6, 3, 6, 3, 3 | | 6, 3, 6, 3, 3 |
| Reject |
| 1174 | BANANA: a Benchmark for the Assessment of Neural Architectures for Nucleic Acids | 3.80 | 4.20 | 0.40 | | 5, 5, 3, 3, 3 | | 5, 5, 3, 3, 5 |
| Reject |
| 1175 | Poisoned classifiers are not only backdoored, they are fundamentally broken | 4.20 | 4.20 | 0.00 | | 5, 5, 3, 5, 3 | | 5, 5, 3, 5, 3 |
| Reject |
| 1176 | Improving Neural Network Generalization via Promoting Within-Layer Diversity | 4.20 | 4.20 | 0.00 | | 5, 3, 5, 3, 5 | | 5, 3, 5, 3, 5 |
| Reject |
| 1177 | Modeling label correlations implicitly through latent label encodings for multi-label text classification | 4.40 | 4.00 | -0.40 | | 8, 3, 3, 3, 5 | | 6, 3, 3, 3, 5 |
| Reject |
| 1178 | Density Estimation for Conservative Q-Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1179 | Learning Representation for Bayesian Optimization with Collision-free Regularization | 4.00 | 4.00 | 0.00 | | Reject |
| 1180 | Evaluating Robustness of Cooperative MARL | 4.00 | 4.00 | 0.00 | | Reject |
| 1181 | Containerized Distributed Value-Based Multi-Agent Reinforcement Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1182 | Tessellated 2D Convolution Networks: A Robust Defence against Adversarial Attacks | 4.00 | 4.00 | 0.00 | | Reject |
| 1183 | Picking Daisies in Private: Federated Learning from Small Datasets | 3.50 | 4.00 | 0.50 | | Reject |
| 1184 | Offline-Online Reinforcement Learning: Extending Batch and Online RL | 4.00 | 4.00 | 0.00 | | Reject |
| 1185 | Contrastive Pre-training for Zero-Shot Information Retrieval | 4.00 | 4.00 | 0.00 | | Reject |
| 1186 | Less data is more: Selecting informative and diverse subsets with balancing constraints | 4.00 | 4.00 | 0.00 | | Reject |
| 1187 | Q-learning for real time control of heterogeneous microagent collectives | 4.00 | 4.00 | 0.00 | | Reject |
| 1188 | Selective Token Generation for Few-shot Language Modeling | 4.00 | 4.00 | 0.00 | | Reject |
| 1189 | Neural Implicit Representations for Physical Parameter Inference from a Single Video | 4.20 | 4.00 | -0.20 | | 6, 6, 3, 3, 3 | | 5, 6, 3, 3, 3 |
| Reject |
| 1190 | Metric Learning on Temporal Graphs via Few-Shot Examples | 4.00 | 4.00 | 0.00 | | Reject |
| 1191 | Transformers are Meta-Reinforcement Learners | 4.00 | 4.00 | 0.00 | | Reject |
| 1192 | Physics Informed Machine Learning of SPH: Machine Learning Lagrangian Turbulence | 4.00 | 4.00 | 0.00 | | 3, 6, 3, 3, 5 | | 3, 6, 3, 3, 5 |
| Reject |
| 1193 | Using Document Similarity Methods to create Parallel Datasets for Code Translation | 4.00 | 4.00 | 0.00 | | Reject |
| 1194 | Generating Antimicrobial Peptides from Latent Secondary Structure Space | 3.00 | 4.00 | 1.00 | | Reject |
| 1195 | Learning to Pool in Graph Neural Networks for Extrapolation | 4.00 | 4.00 | 0.00 | | Reject |
| 1196 | WHAT TO DO IF SPARSE REPRESENTATION LEARNING FAILS UNEXPECTEDLY? | 5.00 | 4.00 | -1.00 | | Reject |
| 1197 | Unsupervised Object Learning via Common Fate | 4.00 | 4.00 | 0.00 | | Reject |
| 1198 | Implicit Jacobian regularization weighted with impurity of probability output | 4.00 | 4.00 | 0.00 | | Reject |
| 1199 | Distributed Methods with Compressed Communication for Solving Variational Inequalities, with Theoretical Guarantees | 4.00 | 4.00 | 0.00 | | Reject |
| 1200 | Proper Straight-Through Estimator: Breaking symmetry promotes convergence to true minimum | 4.00 | 4.00 | 0.00 | | Reject |
| 1201 | FLAME-in-NeRF: Neural control of Radiance Fields for Free View Face Animation | 4.00 | 4.00 | 0.00 | | Reject |
| 1202 | Influence-Based Reinforcement Learning for Intrinsically-Motivated Agents | 3.50 | 4.00 | 0.50 | | Reject |
| 1203 | SALT : Sharing Attention between Linear layer and Transformer for tabular dataset | 4.00 | 4.00 | 0.00 | | Reject |
| 1204 | CausalDyna: Improving Generalization of Dyna-style Reinforcement Learning via Counterfactual-Based Data Augmentation | 4.00 | 4.00 | 0.00 | | Reject |
| 1205 | PDQN - A Deep Reinforcement Learning Method for Planning with Long Delays: Optimization of Manufacturing Dispatching | 3.50 | 4.00 | 0.50 | | Reject |
| 1206 | M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining | 4.00 | 4.00 | 0.00 | | 6, 3, 3, 5, 3 | | 6, 3, 3, 5, 3 |
| Reject |
| 1207 | Class-Weighted Evaluation Metrics for Imbalanced Data Classification | 4.50 | 4.00 | -0.50 | | Reject |
| 1208 | sbfδ2-exploration for Reinforcement Learning | 4.25 | 4.00 | -0.25 | | Reject |
| 1209 | Federated Learning with Partial Model Personalization | 4.00 | 4.00 | 0.00 | | Reject |
| 1210 | Model Fusion of Heterogeneous Neural Networks via Cross-Layer Alignment | 4.00 | 4.00 | 0.00 | | Reject |
| 1211 | Robust and Personalized Federated Learning with Spurious Features: an Adversarial Approach | 4.00 | 4.00 | 0.00 | | Reject |
| 1212 | Hessian-Free High-Resolution Nesterov Acceleration for Sampling | 4.00 | 4.00 | 0.00 | | 3, 1, 6, 6 | | 3, 1, 6, 6, 3, 5 |
| Reject |
| 1213 | Rethinking Client Reweighting for Selfish Federated Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1214 | Genome Sequence Reconstruction Using Gated Graph Convolutional Network | 4.00 | 4.00 | 0.00 | | Reject |
| 1215 | Match Prediction Using Learned History Embeddings | 4.00 | 4.00 | 0.00 | | Reject |
| 1216 | ES-Based Jacobian Enables Faster Bilevel Optimization | 4.00 | 4.00 | 0.00 | | Reject |
| 1217 | On the benefits of deep RL in accelerated MRI sampling | 4.00 | 4.00 | 0.00 | | Reject |
| 1218 | Weakly-Supervised Learning of Disentangled and Interpretable Skills for Hierarchical Reinforcement Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1219 | Private Multi-Task Learning: Formulation and Applications to Federated Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1220 | On the Latent Holes 🧀 of VAEs for Text Generation | 4.00 | 4.00 | 0.00 | | Reject |
| 1221 | Iterative Sketching and its Application to Federated Learning | 4.25 | 4.00 | -0.25 | | Reject |
| 1222 | SLIM-QN: A Stochastic, Light, Momentumized Quasi-Newton Optimizer for Deep Neural Networks | 4.00 | 4.00 | 0.00 | | 3, 3, 6, 5, 3 | | 3, 3, 6, 5, 3 |
| Reject |
| 1223 | Confidence-aware Training of Smoothed Classifiers for Certified Robustness | 4.00 | 4.00 | 0.00 | | Reject |
| 1224 | GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures | 4.00 | 4.00 | 0.00 | | Reject |
| 1225 | Heterogeneous Wasserstein Discrepancy for Incomparable Distributions | 4.00 | 4.00 | 0.00 | | Reject |
| 1226 | Learning-to-Count by Learning-to-Rank: Weakly Supervised Object Counting & Localization Using Only Pairwise Image Rankings | 3.00 | 4.00 | 1.00 | | Reject |
| 1227 | Understanding Graph Learning with Local Intrinsic Dimensionality | 4.00 | 4.00 | 0.00 | | Reject |
| 1228 | ImpressLearn: Continual Learning via Combined Task Impressions | 4.00 | 4.00 | 0.00 | | Reject |
| 1229 | Adaptive Learning of Tensor Network Structures | 4.25 | 4.00 | -0.25 | | Reject |
| 1230 | Mako: Semi-supervised continual learning with minimal labeled data via data programming | 4.00 | 4.00 | 0.00 | | Reject |
| 1231 | Reinforcement Learning with Ex-Post Max-Min Fairness | 4.00 | 4.00 | 0.00 | | Reject |
| 1232 | Semi-supervised Offline Reinforcement Learning with Pre-trained Decision Transformers | 4.00 | 4.00 | 0.00 | | Reject |
| 1233 | Pretext Tasks Selection for Multitask Self-Supervised Speech Representation Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1234 | Synthetic Reduced Nearest Neighbor Model for Regression | 4.00 | 4.00 | 0.00 | | Reject |
| 1235 | On Hard Episodes in Meta-Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1236 | E2CM: Early Exit via Class Means for Efficient Supervised and Unsupervised Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1237 | Neural Temporal Logic Programming | 4.33 | 4.00 | -0.33 | | Reject |
| 1238 | Provable hierarchical lifelong learning with a sketch-based modular architecture | 4.00 | 4.00 | 0.00 | | Reject |
| 1239 | Classify and Generate Reciprocally: Simultaneous Positive-Unlabelled Learning and Conditional Generation with Extra Data | 4.25 | 4.00 | -0.25 | | Reject |
| 1240 | Robust Imitation Learning from Corrupted Demonstrations | 4.00 | 4.00 | 0.00 | | Reject |
| 1241 | Sparse Hierarchical Table Ensemble | 4.00 | 4.00 | 0.00 | | Reject |
| 1242 | FedDiscrete: A Secure Federated Learning Algorithm Against Weight Poisoning | 4.00 | 4.00 | 0.00 | | Reject |
| 1243 | Causal discovery from conditionally stationary time-series | 4.00 | 4.00 | 0.00 | | Reject |
| 1244 | Local Reweighting for Adversarial Training | 4.00 | 4.00 | 0.00 | | Reject |
| 1245 | Boosting Search Engines with Interactive Agents | 4.00 | 4.00 | 0.00 | | Reject |
| 1246 | Sampling from Discrete Energy-Based Models with Quality/Efficiency Trade-offs | 3.67 | 4.00 | 0.33 | | Reject |
| 1247 | Edge Rewiring Goes Neural: Boosting Network Resilience via Policy Gradient | 3.67 | 4.00 | 0.33 | | Reject |
| 1248 | Multi-modal Self-supervised Pre-training for Regulatory Genome Across Cell Types | 4.00 | 4.00 | 0.00 | | Reject |
| 1249 | A Novel Convergence Analysis for the Stochastic Proximal Point Algorithm | 4.75 | 4.00 | -0.75 | | Reject |
| 1250 | Increase and Conquer: Training Graph Neural Networks on Growing Graphs | 4.00 | 4.00 | 0.00 | | Reject |
| 1251 | Logic Pre-Training of Language Models | 4.00 | 4.00 | 0.00 | | Reject |
| 1252 | Simpler Calibration for Survival Analysis | 4.00 | 4.00 | 0.00 | | Reject |
| 1253 | Particle Based Stochastic Policy Optimization | 4.00 | 4.00 | 0.00 | | Reject |
| 1254 | Characterising the Area Under the Curve Loss Function Landscape | 4.00 | 4.00 | 0.00 | | Reject |
| 1255 | Truth Table Deep Convolutional Neural Network, A New SAT-Encodable Architecture - Application To Complete Robustness | 4.00 | 4.00 | 0.00 | | Reject |
| 1256 | PDAML: A Pseudo Domain Adaptation Paradigm for Subject-independent EEG-based Emotion Recognition | 4.00 | 4.00 | 0.00 | | Reject |
| 1257 | Adversarial Robustness as a Prior for Learned Representations | 4.00 | 4.00 | 0.00 | | Reject |
| 1258 | Discovering Classification Rules for Interpretable Learning with Linear Programming | 4.00 | 4.00 | 0.00 | | Reject |
| 1259 | Towards Structured Dynamic Sparse Pre-Training of BERT | 4.00 | 4.00 | 0.00 | | 6, 3, 3, 5, 3 | | 6, 3, 3, 5, 3 |
| Reject |
| 1260 | Sparsistent Model Discovery | 4.00 | 4.00 | 0.00 | | Reject |
| 1261 | EinSteinVI: General and Integrated Stein Variational Inference | 4.00 | 4.00 | 0.00 | | Reject |
| 1262 | Improving State-of-the-Art in One-Class Classification by Leveraging Unlabeled Data | 4.00 | 4.00 | 0.00 | | Reject |
| 1263 | Inducing Reusable Skills From Demonstrations with Option-Controller Network | 4.00 | 4.00 | 0.00 | | Reject |
| 1264 | BioLCNet: Reward-modulated Locally Connected Spiking Neural Networks | 3.67 | 4.00 | 0.33 | | Reject |
| 1265 | Regularized-OFU: an efficient algorithm for general contextual bandit with optimization oracles | 4.00 | 4.00 | 0.00 | | Reject |
| 1266 | Meta Attention For Off-Policy Actor-Critic | 4.00 | 4.00 | 0.00 | | Reject |
| 1267 | Network Learning in Quadratic Games from Fictitious Plays | 4.00 | 4.00 | 0.00 | | Reject |
| 1268 | A Theoretical and Empirical Model of the Generalization Error under Time-Varying Learning Rate | 4.00 | 4.00 | 0.00 | | Reject |
| 1269 | Should we Replace CNNs with Transformers for Medical Images? | 4.00 | 4.00 | 0.00 | | Reject |
| 1270 | MDFL: A UNIFIED FRAMEWORK WITH META-DROPOUT FOR FEW-SHOT LEARNING | 4.00 | 4.00 | 0.00 | | Reject |
| 1271 | Equivalent Distance Geometry Error for Molecular Conformation Comparison | 4.00 | 4.00 | 0.00 | | Reject |
| 1272 | Online Tuning for Offline Decentralized Multi-Agent Reinforcement Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1273 | Additive Poisson Process: Learning Intensity of Higher-Order Interaction in Poisson Processes | 4.00 | 4.00 | 0.00 | | Reject |
| 1274 | DCoM: A Deep Column Mapper for Semantic Data Type Detection | 4.00 | 4.00 | 0.00 | | Reject |
| 1275 | Evolution Strategies as an Alternate Learning method for Hierarchical Reinforcement Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1276 | Classification and Uncertainty Quantification of Corrupted Data using Semi-Supervised Autoencoders | 4.00 | 4.00 | 0.00 | | Reject |
| 1277 | Learning the Representation of Behavior Styles with Imitation Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1278 | Unifying Top-down and Bottom-up for Recurrent Visual Attention | 4.00 | 4.00 | 0.00 | | Reject |
| 1279 | SCformer: Segment Correlation Transformer for Long Sequence Time Series Forecasting | 3.67 | 4.00 | 0.33 | | Reject |
| 1280 | 3D-Transformer: Molecular Representation with Transformer in 3D Space | 4.00 | 4.00 | 0.00 | | Reject |
| 1281 | L2BGAN: An image enhancement model for image quality improvement and image analysis tasks without paired supervision | 4.00 | 4.00 | 0.00 | | Reject |
| 1282 | Tabular Data Imputation: Choose KNN over Deep Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1283 | Bayesian Relational Generative Model for Scalable Multi-modal Learning | 4.00 | 4.00 | 0.00 | | Reject |
| 1284 | AF2: Adaptive Focus Framework for Aerial Imagery Segmentation | 4.00 | 4.00 | 0.00 | | Reject |
| 1285 | AAVAE: Augmentation-Augmented Variational Autoencoders | 3.80 | 3.80 | 0.00 | | 3, 3, 3, 5, 5 | | 3, 3, 3, 5, 5 |
| Reject |
| 1286 | The NTK Adversary: An Approach to Adversarial Attacks without any Model Access | 4.00 | 3.80 | -0.20 | | Reject |
| 1287 | Autoregressive Latent Video Prediction with High-Fidelity Image Generator | 3.80 | 3.80 | 0.00 | | 3, 3, 5, 3, 5 | | 3, 3, 5, 3, 5 |
| Reject |
| 1288 | Design in the Dark: Learning Deep Generative Models for De Novo Protein Design | 4.00 | 3.80 | -0.20 | | Reject |
| 1289 | Provable Federated Adversarial Learning via Min-max Optimization | 3.80 | 3.80 | 0.00 | | 3, 3, 5, 5, 3 | | 3, 3, 5, 5, 3 |
| Reject |
| 1290 | Attend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association | 3.80 | 3.80 | 0.00 | | 3, 3, 5, 5, 3 | | 3, 3, 5, 5, 3 |
| Reject |
| 1291 | S3ADNet: Sequential Anomaly Detection with Pessimistic Contrastive Learning | 3.80 | 3.80 | 0.00 | | 5, 3, 1, 5, 5 | | 5, 3, 1, 5, 5 |
| Reject |
| 1292 | Accelerating Optimization using Neural Reparametrization | 3.75 | 3.75 | 0.00 | | Reject |
| 1293 | The Remarkable Effectiveness of Combining Policy and Value Networks in A*-based Deep RL for AI Planning | 3.50 | 3.75 | 0.25 | | Reject |
| 1294 | Generalization to Out-of-Distribution transformations | 3.75 | 3.75 | 0.00 | | Reject |
| 1295 | Composing Features: Compositional Model Augmentation for Steerability of Music Transformers | 3.75 | 3.75 | 0.00 | | Reject |
| 1296 | Connectivity Matters: Neural Network Pruning Through the Lens of Effective Sparsity | 3.75 | 3.75 | 0.00 | | Reject |
| 1297 | Low-Precision Stochastic Gradient Langevin Dynamics | 3.75 | 3.75 | 0.00 | | Reject |
| 1298 | Understanding Sharpness-Aware Minimization | 3.75 | 3.75 | 0.00 | | Reject |
| 1299 | Language Model Pre-training Improves Generalization in Policy Learning | 3.75 | 3.75 | 0.00 | | Reject |
| 1300 | The weighted mean trick – optimization strategies for robustness | 3.75 | 3.75 | 0.00 | | Reject |
| 1301 | SparRL: Graph Sparsification via Deep Reinforcement Learning | 3.50 | 3.75 | 0.25 | | Reject |
| 1302 | Learning to Persuade | 3.75 | 3.75 | 0.00 | | Reject |
| 1303 | DiBB: Distributing Black-Box Optimization | 3.75 | 3.75 | 0.00 | | Reject |
| 1304 | Equivalence of State Equations from Different Methods in High-dimensional Regression | 3.75 | 3.75 | 0.00 | | Reject |
| 1305 | Exact Stochastic Newton Method for Deep Learning: the feedforward networks case. | 3.75 | 3.75 | 0.00 | | Reject |
| 1306 | The Manifold Hypothesis for Gradient-Based Explanations | 3.75 | 3.75 | 0.00 | | Reject |
| 1307 | Unifying Categorical Models by Explicit Disentanglement of the Labels' Generative Factors | 3.75 | 3.75 | 0.00 | | Reject |
| 1308 | Towards Understanding Data Values: Empirical Results on Synthetic Data | 3.75 | 3.75 | 0.00 | | Reject |
| 1309 | Rewardless Open-Ended Learning (ROEL) | 3.75 | 3.75 | 0.00 | | Reject |
| 1310 | Differentiable Self-Adaptive Learning Rate | 3.75 | 3.75 | 0.00 | | Reject |
| 1311 | Deep Fusion of Multi-attentive Local and Global Features with Higher Efficiency for Image Retrieval | 3.75 | 3.75 | 0.00 | | Reject |
| 1312 | Greedy-based Value Representation for Efficient Coordination in Multi-agent Reinforcement Learning | 3.75 | 3.75 | 0.00 | | Reject |
| 1313 | HODA: Protecting DNNs Against Model Extraction Attacks via Hardness of Samples | 3.75 | 3.75 | 0.00 | | Reject |
| 1314 | Divergent representations of ethological visual inputs emerge from supervised, unsupervised, and reinforcement learning | 3.75 | 3.75 | 0.00 | | Reject |
| 1315 | An Attempt to Model Human Trust with Reinforcement Learning | 3.25 | 3.75 | 0.50 | | Reject |
| 1316 | Understanding the Generalization Gap in Visual Reinforcement Learning | 3.75 | 3.75 | 0.00 | | Reject |
| 1317 | A Two-Stage Neural-Filter Pareto Front Extractor and the need for Benchmarking | 3.75 | 3.75 | 0.00 | | Reject |
| 1318 | AriEL: volume coding for sentence generation comparisons | 3.75 | 3.75 | 0.00 | | Reject |
| 1319 | Topic Aware Neural Language Model: Domain Adaptation of Unconditional Text Generation Models | 3.00 | 3.67 | 0.67 | | Reject |
| 1320 | Go with the Flow: the distribution of information processing in multi-path networks | 3.67 | 3.67 | 0.00 | | Reject |
| 1321 | Learning When and What to Ask: a Hierarchical Reinforcement Learning Framework | 3.67 | 3.67 | 0.00 | | Reject |
| 1322 | Context-invariant, multi-variate time series representations | 3.67 | 3.67 | 0.00 | | Reject |
| 1323 | Contractive error feedback for gradient compression | 3.67 | 3.67 | 0.00 | | Reject |
| 1324 | Bayesian Exploration for Lifelong Reinforcement Learning | 4.33 | 3.67 | -0.67 | | Reject |
| 1325 | Understanding the Success of Knowledge Distillation -- A Data Augmentation Perspective | 4.33 | 3.67 | -0.67 | | Reject |
| 1326 | Quasi-potential theory for escape problem: Quantitative sharpness effect on SGD's escape from local minima | 4.00 | 3.67 | -0.33 | | Reject |
| 1327 | The guide and the explorer: smart agents for resource-limited iterated batch reinforcement learning | 3.67 | 3.67 | 0.00 | | Reject |
| 1328 | Explaining Scaling Laws of Neural Network Generalization | 4.00 | 3.67 | -0.33 | | Reject |
| 1329 | Causally Focused Convolutional Networks Through Minimal Human Guidance | 3.67 | 3.67 | 0.00 | | Reject |
| 1330 | To Impute or Not To Impute? Missing Data in Treatment Effect Estimation | 3.67 | 3.67 | 0.00 | | Reject |
| 1331 | The Effect of diversity in Meta-Learning | 3.67 | 3.67 | 0.00 | | Reject |
| 1332 | The Importance of the Current Input in Sequence Modeling | 3.00 | 3.67 | 0.67 | | Reject |
| 1333 | Neural Architecture Search via Ensemble-based Knowledge Distillation | 3.67 | 3.67 | 0.00 | | Reject |
| 1334 | Generating High-Fidelity Privacy-Conscious Synthetic Patient Data for Causal Effect Estimation with Multiple Treatments | 3.67 | 3.67 | 0.00 | | Reject |
| 1335 | GCF: Generalized Causal Forest for Heterogeneous Treatment Effect Estimation Using Nonparametric Methods | 3.67 | 3.67 | 0.00 | | Reject |
| 1336 | Model Compression via Symmetries of the Parameter Space | 3.67 | 3.67 | 0.00 | | Reject |
| 1337 | Self-supervised Learning for Sequential Recommendation with Model Augmentation | 3.67 | 3.67 | 0.00 | | Reject |
| 1338 | Certified Adversarial Robustness Under the Bounded Support Set | 3.67 | 3.67 | 0.00 | | Reject |
| 1339 | Modeling Adversarial Noise for Adversarial Defense | 3.67 | 3.67 | 0.00 | | Reject |
| 1340 | VISCOS Flows: Variational Schur Conditional Sampling with Normalizing Flows | 3.67 | 3.67 | 0.00 | | Reject |
| 1341 | Learning Homophilic Incentives in Sequential Social Dilemmas | 3.67 | 3.67 | 0.00 | | Reject |
| 1342 | Meta-Forecasting by combining Global Deep Representations with Local Adaptation | 3.00 | 3.67 | 0.67 | | Reject |
| 1343 | Evolving Neural Update Rules for Sequence Learning | 3.67 | 3.67 | 0.00 | | Reject |
| 1344 | Foreground-attention in neural decoding: Guiding Loop-Enc-Dec to reconstruct visual stimulus images from fMRI | 3.67 | 3.67 | 0.00 | | Reject |
| 1345 | An Interpretable Graph Generative Model with Heterophily | 3.67 | 3.67 | 0.00 | | Reject |
| 1346 | Open Set Domain Adaptation with Zero-shot Learning on Graph | 3.67 | 3.67 | 0.00 | | Reject |
| 1347 | Manifold Micro-Surgery with Linearly Nearly Euclidean Metrics | 3.67 | 3.67 | 0.00 | | Reject |
| 1348 | Towards simple time-to-event modeling: optimizing neural networks via rank regression | 3.60 | 3.60 | 0.00 | | 3, 1, 5, 6, 3 | | 3, 1, 5, 6, 3 |
| Reject |
| 1349 | Disentangled generative models for robust dynamical system prediction | 3.40 | 3.60 | 0.20 | | 1, 3, 5, 5, 3 | | 1, 3, 6, 5, 3 |
| Reject |
| 1350 | Improved Generalization Bound for Deep Neural Networks Using Geometric Functional Analysis | 3.60 | 3.60 | 0.00 | | 5, 3, 1, 6, 3 | | 5, 3, 1, 6, 3 |
| Reject |
| 1351 | CareGraph: A Graph-based Recommender System for Diabetes Self-Care | 3.50 | 3.50 | 0.00 | | Reject |
| 1352 | Takeuchi's Information Criteria as Generalization Measures for DNNs Close to NTK Regime | 3.50 | 3.50 | 0.00 | | Reject |
| 1353 | Pessimistic Model Selection for Offline Deep Reinforcement Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1354 | Offline Pre-trained Multi-Agent Decision Transformer | 3.50 | 3.50 | 0.00 | | Reject |
| 1355 | Neural network architectures for disentangling the multimodal structure of data ensembles | 3.50 | 3.50 | 0.00 | | Reject |
| 1356 | PKCAM: Previous Knowledge Channel Attention Module | 3.50 | 3.50 | 0.00 | | Reject |
| 1357 | Sequoia: A Software Framework to Unify Continual Learning Research | 4.25 | 3.50 | -0.75 | | Reject |
| 1358 | Design and Evaluation for Robust Continual Learning | 3.00 | 3.50 | 0.50 | | Reject |
| 1359 | Reachability Traces for Curriculum Design in Reinforcement Learning | 3.00 | 3.50 | 0.50 | | Reject |
| 1360 | Disentangling One Factor at a Time | 3.00 | 3.50 | 0.50 | | Reject |
| 1361 | MaiT: integrating spatial locality into image transformers with attention masks | 3.50 | 3.50 | 0.00 | | Reject |
| 1362 | Variational Wasserstein gradient flow | 3.50 | 3.50 | 0.00 | | Reject |
| 1363 | Towards Uncertainties in Deep Learning that Are Accurate and Calibrated | 3.50 | 3.50 | 0.00 | | Reject |
| 1364 | SpSC: A Fast and Provable Algorithm for Sampling-Based GNN Training | 3.50 | 3.50 | 0.00 | | Reject |
| 1365 | Continual Learning in Deep Networks: an Analysis of the Last Layer | 3.50 | 3.50 | 0.00 | | Reject |
| 1366 | Cycle monotonicity of adversarial attacks for optimal domain adaptation | 3.50 | 3.50 | 0.00 | | Reject |
| 1367 | Conditional Generative Quantile Networks via Optimal Transport and Convex Potentials | 3.50 | 3.50 | 0.00 | | Reject |
| 1368 | Evolutionary perspective on model fine-tuning | 3.50 | 3.50 | 0.00 | | Reject |
| 1369 | Neural Circuit Architectural Priors for Embodied Control | 3.50 | 3.50 | 0.00 | | Reject |
| 1370 | f-Divergence Thermodynamic Variational Objective: a Deformed Geometry Perspective | 3.50 | 3.50 | 0.00 | | Reject |
| 1371 | Bayesian Learning with Information Gain Provably Bounds Risk for a Robust Adversarial Defense | 3.50 | 3.50 | 0.00 | | Reject |
| 1372 | When do Convolutional Neural Networks Stop Learning? | 3.50 | 3.50 | 0.00 | | Reject |
| 1373 | Beyond Prioritized Replay: Sampling States in Model-Based Reinforcement Learning via Simulated Priorities | 3.50 | 3.50 | 0.00 | | Reject |
| 1374 | DESTA: A Framework for Safe Reinforcement Learning with Markov Games of Intervention | 3.50 | 3.50 | 0.00 | | Reject |
| 1375 | HD-cos Networks: Efficient Neural Architechtures for Secure Multi-Party Computation | 3.50 | 3.50 | 0.00 | | Reject |
| 1376 | L-SR1 Adaptive Regularization by Cubics for Deep Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1377 | Embedding models through the lens of Stable Coloring | 3.50 | 3.50 | 0.00 | | Reject |
| 1378 | Benchmarking Sample Selection Strategies for Batch Reinforcement Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1379 | Communicating via Markov Decision Processes | 3.50 | 3.50 | 0.00 | | Reject |
| 1380 | KINet: Keypoint Interaction Networks for Unsupervised Forward Modeling | 3.50 | 3.50 | 0.00 | | Reject |
| 1381 | Label Augmentation with Reinforced Labeling for Weak Supervision | 3.50 | 3.50 | 0.00 | | Reject |
| 1382 | Multi-batch Reinforcement Learning via Sample Transfer and Imitation Learning | 3.75 | 3.50 | -0.25 | | Reject |
| 1383 | Soft Actor-Critic with Inhibitory Networks for Faster Retraining | 3.50 | 3.50 | 0.00 | | Reject |
| 1384 | Fight fire with fire: countering bad shortcuts in imitation learning with good shortcuts | 3.50 | 3.50 | 0.00 | | Reject |
| 1385 | Hermitry Ratio: Evaluating the validity of perturbation methods for explainable deep learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1386 | Scalable Hierarchical Embeddings of Complex Networks | 3.50 | 3.50 | 0.00 | | Reject |
| 1387 | On Learning with Fairness Trade-Offs | 3.50 | 3.50 | 0.00 | | Reject |
| 1388 | GRODIN: Improved Large-Scale Out-of-Domain detection via Back-propagation | 3.50 | 3.50 | 0.00 | | Reject |
| 1389 | SERCNN: Stacked Embedding Recurrent Convolutional Neural Network in Depression Detection on Twitter | 3.50 | 3.50 | 0.00 | | Reject |
| 1390 | Effect of Pressure for Compositionality on Language Emergence | 3.75 | 3.50 | -0.25 | | Reject |
| 1391 | Spatio-temporal Disentangled representation learning for mobility prediction | 3.50 | 3.50 | 0.00 | | Reject |
| 1392 | On the Effectiveness of Quasi Character-Level Models for Machine Translation | 3.50 | 3.50 | 0.00 | | Reject |
| 1393 | Bootstrapped Hindsight Experience replay with Counterintuitive Prioritization | 3.50 | 3.50 | 0.00 | | Reject |
| 1394 | 3D Meta-Registration: Meta-learning 3D Point Cloud Registration Functions | 3.50 | 3.50 | 0.00 | | Reject |
| 1395 | The Connection between Out-of-Distribution Generalization and Privacy of ML Models | 4.33 | 3.50 | -0.83 | | Reject |
| 1396 | Model-Invariant State Abstractions for Model-Based Reinforcement Learning | 4.25 | 3.50 | -0.75 | | Reject |
| 1397 | Revealing the Incentive to Cause Distributional Shift | 3.50 | 3.50 | 0.00 | | Reject |
| 1398 | Language Modeling using LMUs: 10x Better Data Efficiency or Improved Scaling Compared to Transformers | 3.50 | 3.50 | 0.00 | | Reject |
| 1399 | Neuron-Enhanced Autoencoder based Collaborative filtering: Theory and Practice | 3.50 | 3.50 | 0.00 | | Reject |
| 1400 | Neuro-Symbolic Forward Reasoning | 3.50 | 3.50 | 0.00 | | Reject |
| 1401 | Data-oriented Scene Recognition | 3.50 | 3.50 | 0.00 | | Reject |
| 1402 | Task-oriented Dialogue System for Automatic Disease Diagnosis via Hierarchical Reinforcement Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1403 | Momentum Conserving Lagrangian Neural Networks | 3.50 | 3.50 | 0.00 | | Reject |
| 1404 | Continual Learning Using Task Conditional Neural Networks | 3.50 | 3.50 | 0.00 | | Reject |
| 1405 | Predictive Maintenance for Optical Networks in Robust Collaborative Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1406 | A Topological View of Rule Learning in Knowledge Graphs | 4.25 | 3.50 | -0.75 | | Reject |
| 1407 | Nested Policy Reinforcement Learning for Clinical Decision Support | 3.50 | 3.50 | 0.00 | | Reject |
| 1408 | Personalized Heterogeneous Federated Learning with Gradient Similarity | 3.50 | 3.50 | 0.00 | | Reject |
| 1409 | Deep Learning of Intrinsically Motivated Options in the Arcade Learning Environment | 3.50 | 3.50 | 0.00 | | Reject |
| 1410 | Initializing ReLU networks in an expressive subspace of weights | 3.50 | 3.50 | 0.00 | | Reject |
| 1411 | Accelerating HEP simulations with Neural Importance Sampling | 3.50 | 3.50 | 0.00 | | Reject |
| 1412 | Yformer: U-Net Inspired Transformer Architecture for Far Horizon Time Series Forecasting | 3.75 | 3.50 | -0.25 | | Reject |
| 1413 | GAETS: A Graph Autoencoder Time Series Approach Towards Battery Parameter Estimation | 3.50 | 3.50 | 0.00 | | Reject |
| 1414 | Variability of Neural Networks and Han-Layer: A Variability-Inspired Model | 3.50 | 3.50 | 0.00 | | Reject |
| 1415 | Relative Entropy Gradient Sampler for Unnormalized Distributions | 3.50 | 3.50 | 0.00 | | Reject |
| 1416 | Iterative Decoding for Compositional Generalization in Transformers | 3.50 | 3.50 | 0.00 | | Reject |
| 1417 | Positive-Unlabeled Learning with Uncertainty-aware Pseudo-label Selection | 3.50 | 3.50 | 0.00 | | Reject |
| 1418 | Constituency Tree Representation for Argument Unit Recognition | 3.50 | 3.50 | 0.00 | | Reject |
| 1419 | Do What Nature Did To Us: Evolving Plastic Recurrent Neural Networks For Generalized Tasks | 3.50 | 3.50 | 0.00 | | Reject |
| 1420 | Local Permutation Equivariance For Graph Neural Networks | 3.50 | 3.50 | 0.00 | | Reject |
| 1421 | A Survey on Evidential Deep Learning For Single-Pass Uncertainty Estimation | 3.50 | 3.50 | 0.00 | | Reject |
| 1422 | RoMA: a Method for Neural Network Robustness Measurement and Assessment | 3.50 | 3.50 | 0.00 | | Reject |
| 1423 | How memory architecture affects learning in a simple POMDP: the two-hypothesis testing problem | 3.50 | 3.50 | 0.00 | | Reject |
| 1424 | ClsVC: Learning Speech Representations with two different classification tasks. | 3.50 | 3.50 | 0.00 | | Reject |
| 1425 | A General Theory of Relativity in Reinforcement Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1426 | FROB: Few-shot ROBust Model for Classification with Out-of-Distribution Detection | 3.50 | 3.50 | 0.00 | | Reject |
| 1427 | Towards Learning to Speak and Hear Through Multi-Agent Communication over a Continuous Acoustic Channel | 3.75 | 3.50 | -0.25 | | Reject |
| 1428 | Compressing Transformer-Based Sequence to Sequence Models With Pre-trained Autoencoders for Text Summarization | 3.00 | 3.50 | 0.50 | | Reject |
| 1429 | Off-Policy Reinforcement Learning with Delayed Rewards | 3.50 | 3.50 | 0.00 | | Reject |
| 1430 | Using a one dimensional parabolic model of the full-batch loss to estimate learning rates during training | 3.50 | 3.50 | 0.00 | | Reject |
| 1431 | JOINTLY LEARNING TOPIC SPECIFIC WORD AND DOCUMENT EMBEDDING | 3.50 | 3.50 | 0.00 | | Reject |
| 1432 | Offline Decentralized Multi-Agent Reinforcement Learning | 3.50 | 3.50 | 0.00 | | Reject |
| 1433 | LEARNING DISTRIBUTIONS GENERATED BY SINGLE-LAYER RELU NETWORKS IN THE PRESENCE OF ARBITRARY OUTLIERS | 4.00 | 3.50 | -0.50 | | Reject |
| 1434 | On the Capacity and Superposition of Minima in Neural Network Loss Function Landscapes | 3.50 | 3.50 | 0.00 | | Reject |
| 1435 | Picking up the pieces: separately evaluating supernet training and architecture selection | 3.00 | 3.40 | 0.40 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 5 |
| Reject |
| 1436 | Label Refining: a semi-supervised method to extract voice characteristics without ground truth | 3.40 | 3.40 | 0.00 | | 3, 3, 3, 5, 3 | | 3, 3, 3, 5, 3 |
| Reject |
| 1437 | Stabilized Self-training with Negative Sampling on Few-labeled Graph Data | 3.40 | 3.40 | 0.00 | | 5, 5, 3, 3, 1 | | 5, 5, 3, 3, 1 |
| Reject |
| 1438 | RAR: Region-Aware Point Cloud Registration | 3.00 | 3.40 | 0.40 | | Reject |
| 1439 | Defect Transfer GAN: Diverse Defect Synthesis for Data Augmentation | 3.40 | 3.40 | 0.00 | | 3, 3, 5, 3, 3 | | 3, 3, 5, 3, 3 |
| Reject |
| 1440 | WaveSense: Efficient Temporal Convolutions with Spiking Neural Networks for Keyword Spotting | 4.40 | 3.40 | -1.00 | | 3, 3, 3, 5, 8 | | 3, 3, 3, 5, 3 |
| Reject |
| 1441 | Conjugation Invariant Learning with Neural Networks | 3.40 | 3.40 | 0.00 | | 3, 3, 3, 5, 3 | | 3, 3, 3, 5, 3 |
| Reject |
| 1442 | Folded Hamiltonian Monte Carlo for Bayesian Generative Adversarial Networks | 3.33 | 3.33 | 0.00 | | Reject |
| 1443 | GenTAL: Generative Denoising Skip-gram Transformer for Unsupervised Binary Code Similarity Detection | 3.33 | 3.33 | 0.00 | | Reject |
| 1444 | SVMnet: Non-parametric image classification based on convolutional SVM ensembles for small training sets | 3.25 | 3.25 | 0.00 | | Reject |
| 1445 | Loss meta-learning for forecasting | 3.25 | 3.25 | 0.00 | | Reject |
| 1446 | Encoding Event-Based Gesture Data With a Hybrid SNN Guided Variational Auto-encoder | 3.25 | 3.25 | 0.00 | | Reject |
| 1447 | Pretrained Language Models are Symbolic Mathematics Solvers too! | 3.25 | 3.25 | 0.00 | | Reject |
| 1448 | On Locality in Graph Learning via Graph Neural Network | 3.25 | 3.25 | 0.00 | | Reject |
| 1449 | Adaptive Speech Duration Modification using a Deep-Generative Framework | 3.25 | 3.25 | 0.00 | | Reject |
| 1450 | C+1 Loss: Learn to Classify C Classes of Interest and the Background Class Differentially | 3.75 | 3.25 | -0.50 | | Reject |
| 1451 | Shaped Rewards Bias Emergent Language | 3.60 | 3.20 | -0.40 | | 8, 3, 1, 3, 3 | | 6, 3, 1, 3, 3 |
| Reject |
| 1452 | Compound Multi-branch Feature Fusion for Real Image Restoration | 3.20 | 3.20 | 0.00 | | 3, 3, 6, 1, 3 | | 3, 3, 6, 1, 3 |
| Reject |
| 1453 | Information-theoretic stochastic contrastive conditional GAN: InfoSCC-GAN | 3.00 | 3.00 | 0.00 | | Reject |
| 1454 | IA-MARL: Imputation Assisted Multi-Agent Reinforcement Learning for Missing Training Data | 4.00 | 3.00 | -1.00 | | Reject |
| 1455 | Multi-Trigger-Key: Towards Multi-Task Privacy-Preserving In Deep Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1456 | HYPOCRITE: Homoglyph Adversarial Examples for Natural Language Web Services in the Physical World | 3.00 | 3.00 | 0.00 | | Reject |
| 1457 | FEDERATED LEARNING FRAMEWORK BASED ON TRIMMED MEAN AGGREGATION RULES | 3.00 | 3.00 | 0.00 | | Reject |
| 1458 | Graph Similarities and Dual Approach for Sequential Text-to-Image Retrieval | 3.00 | 3.00 | 0.00 | | Reject |
| 1459 | Learning sparse DNNs with soft thresholding of weights during training | 3.00 | 3.00 | 0.00 | | Reject |
| 1460 | LatTe Flows: Latent Temporal Flows for Multivariate Sequence Analysis | 3.00 | 3.00 | 0.00 | | Reject |
| 1461 | The magnitude vector of images | 3.00 | 3.00 | 0.00 | | Reject |
| 1462 | A Modulation Layer to Increase Neural Network Robustness Against Data Quality Issues | 3.00 | 3.00 | 0.00 | | Reject |
| 1463 | SSFL: Tackling Label Deficiency in Federated Learning via Personalized Self-Supervision | 3.00 | 3.00 | 0.00 | | Reject |
| 1464 | DNBP: Differentiable Nonparametric Belief Propagation | 3.00 | 3.00 | 0.00 | | Reject |
| 1465 | Generalizing Successor Features to continuous domains for Multi-task Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1466 | Squeezing SGD Parallelization Performance in Distributed Training Using Delayed Averaging | 3.00 | 3.00 | 0.00 | | Reject |
| 1467 | LRN: Limitless Routing Networks for Effective Multi-task Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1468 | TotalRecall: A Bidirectional Candidates Generation Framework for Large Scale Recommender & Advertising Systems | 3.00 | 3.00 | 0.00 | | Reject |
| 1469 | Softmax Gradient Tampering: Decoupling the Backward Pass for Improved Fitting | 3.00 | 3.00 | 0.00 | | Reject |
| 1470 | TimeVAE: A Variational Auto-Encoder for Multivariate Time Series Generation | 3.50 | 3.00 | -0.50 | | Reject |
| 1471 | Learning an Object-Based Memory System | 3.67 | 3.00 | -0.67 | | Reject |
| 1472 | An Application of Pseudo-log-likelihoods to Natural Language Scoring | 2.50 | 3.00 | 0.50 | | Reject |
| 1473 | Superior Performance with Diversified Strategic Control in FPS Games Using General Reinforcement Learning | 3.50 | 3.00 | -0.50 | | Reject |
| 1474 | Image Compression and Classification Using Qubits and Quantum Deep Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1475 | Stochastic Induction of Decision Trees with Application to Learning Haar Tree | 3.00 | 3.00 | 0.00 | | Reject |
| 1476 | Marginal Tail-Adaptive Normalizing Flows | 3.00 | 3.00 | 0.00 | | Reject |
| 1477 | Intervention Adversarial Auto-Encoder | 3.00 | 3.00 | 0.00 | | Reject |
| 1478 | Robust Feature Selection using Sparse Centroid-Encoder | 3.00 | 3.00 | 0.00 | | Reject |
| 1479 | Neural Networks Playing Dough: Investigating Deep Cognition With a Gradient-Based Adversarial Attack | 3.00 | 3.00 | 0.00 | | Reject |
| 1480 | Reconstructing Word Embeddings via Scatteredk-Sub-Embedding | 3.00 | 3.00 | 0.00 | | Reject |
| 1481 | Ensemble Kalman Filter (EnKF) for Reinforcement Learning (RL) | 3.00 | 3.00 | 0.00 | | Reject |
| 1482 | DL-based prediction of optimal actions of human experts | 3.00 | 3.00 | 0.00 | | Reject |
| 1483 | Image Functions In Neural Networks: A Perspective On Generalization | 3.00 | 3.00 | 0.00 | | Reject |
| 1484 | Interventional Black-Box Explanations | 3.00 | 3.00 | 0.00 | | Reject |
| 1485 | Guiding Transformers to Process in Steps | 3.00 | 3.00 | 0.00 | | Reject |
| 1486 | Determining the Ethno-nationality of Writers Using Written English Text | 3.00 | 3.00 | 0.00 | | Reject |
| 1487 | Linear Convergence of SGD on Overparametrized Shallow Neural Networks | 3.00 | 3.00 | 0.00 | | Reject |
| 1488 | Assessing two novel distance-based loss functions for few-shot image classification | 3.00 | 3.00 | 0.00 | | Reject |
| 1489 | Orthogonalising gradients to speedup neural network optimisation | 3.00 | 3.00 | 0.00 | | Reject |
| 1490 | EXPLAINABLE AI-BASED DYNAMIC FILTER PRUNING OF CONVOLUTIONAL NEURAL NETWORKS | 3.00 | 3.00 | 0.00 | | Reject |
| 1491 | Knothe-Rosenblatt transport for Unsupervised Domain Adaptation | 3.00 | 3.00 | 0.00 | | Reject |
| 1492 | Succinct Compression: Near-Optimal and Lossless Compression of Deep Neural Networks during Inference Runtime | 3.00 | 3.00 | 0.00 | | Reject |
| 1493 | Towards Understanding Distributional Reinforcement Learning: Regularization, Optimization, Acceleration and Sinkhorn Algorithm | 3.00 | 3.00 | 0.00 | | Reject |
| 1494 | Interpreting Molecule Generative Models for Interactive Molecule Discovery | 3.00 | 3.00 | 0.00 | | Reject |
| 1495 | Continual Learning of Neural Networks for Realtime Wireline Cable Position Inference | 3.00 | 3.00 | 0.00 | | Reject |
| 1496 | Invariant Causal Mechanisms through Distribution Matching | 4.00 | 3.00 | -1.00 | | Reject |
| 1497 | When Complexity Is Good: Do We Need Recurrent Deep Learning For Time Series Outlier Detection? | 3.00 | 3.00 | 0.00 | | Reject |
| 1498 | Stability and Generalisation in Batch Reinforcement Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1499 | Inferring Offensiveness In Images From Natural Language Supervision | 3.00 | 3.00 | 0.00 | | Reject |
| 1500 | Learning affective meanings that derives the social behavior using Bidirectional Encoder Representations from Transformers | 2.50 | 3.00 | 0.50 | | Reject |
| 1501 | DNN Quantization with Attention | 3.00 | 3.00 | 0.00 | | Reject |
| 1502 | Hyperspherical embedding for novel class classification | 3.00 | 3.00 | 0.00 | | Reject |
| 1503 | Differentiable Hyper-parameter Optimization | 3.00 | 3.00 | 0.00 | | Reject |
| 1504 | Model-based Reinforcement Learning with a Hamiltonian Canonical ODE Network | 3.00 | 3.00 | 0.00 | | Reject |
| 1505 | Maximum Likelihood Estimation for Multimodal Learning with Missing Modality | 3.00 | 3.00 | 0.00 | | Reject |
| 1506 | Predicting subscriber usage: Analyzing multi-dimensional time-series using Convolutional Neural Networks | 3.00 | 3.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
| Reject |
| 1507 | Continuous Deep Q-Learning in Optimal Control Problems: Normalized Advantage Functions Analysis | 3.00 | 3.00 | 0.00 | | Reject |
| 1508 | Genetic Algorithm for Constrained Molecular Inverse Design | 3.00 | 3.00 | 0.00 | | Reject |
| 1509 | SOInter: A Novel Deep Energy-Based Interpretation Method for Explaining Structured Output Models | 3.00 | 3.00 | 0.00 | | Reject |
| 1510 | Interactive Model with Structural Loss for Language-based Abductive Reasoning | 3.00 | 3.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
| Reject |
| 1511 | There are free lunches | 3.00 | 3.00 | 0.00 | | Reject |
| 1512 | Federated Inference through Aligning Local Representations and Learning a Consensus Graph | 3.00 | 3.00 | 0.00 | | Reject |
| 1513 | iPrune: A Magnitude Based Unstructured Pruning Method for Efficient Binary Networks in Hardware | 3.00 | 3.00 | 0.00 | | Reject |
| 1514 | Maximum Mean Discrepancy for Generalization in the Presence of Distribution and Missingness Shift | 3.00 | 3.00 | 0.00 | | Reject |
| 1515 | A Study of Aggregation of Long Time-series Input for LSTM Neural Networks | 3.00 | 3.00 | 0.00 | | Reject |
| 1516 | Path-specific Causal Fair Prediction via Auxiliary Graph Structure Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1517 | Generalizing MLPs With Dropouts, Batch Normalization, and Skip Connections | 3.00 | 3.00 | 0.00 | | Reject |
| 1518 | ACCTS: an Adaptive Model Training Policy for Continuous Classification of Time Series | 3.00 | 3.00 | 0.00 | | Reject |
| 1519 | LSP : Acceleration and Regularization of Graph Neural Networks via Locality Sensitive Pruning of Graphs | 3.00 | 3.00 | 0.00 | | 3, 3, 1, 3, 5 | | 3, 3, 1, 3, 5 |
| Reject |
| 1520 | MT-GBM: A Multi-Task Gradient Boosting Machine with Shared Decision Trees | 3.00 | 3.00 | 0.00 | | Reject |
| 1521 | Multi-scale fusion self attention mechanism | 3.00 | 3.00 | 0.00 | | Reject |
| 1522 | FedMorph: Communication Efficient Federated Learning via Morphing Neural Network | 3.00 | 3.00 | 0.00 | | Reject |
| 1523 | Analytically Tractable Bayesian Deep Q-Learning | 3.00 | 3.00 | 0.00 | | Reject |
| 1524 | CONTEXT AUGMENTATION AND FEATURE REFINEMENT NETWORK FOR TINY OBJECT DETECTION | 3.00 | 3.00 | 0.00 | | Reject |
| 1525 | Improving Sentiment Classification Using 0-Shot Generated Labels for Custom Transformer Embeddings | 3.00 | 3.00 | 0.00 | | Reject |
| 1526 | Lottery Ticket Structured Node Pruning for Tabular Datasets | 3.00 | 3.00 | 0.00 | | Reject |
| 1527 | AA-PINN: ATTENTION AUGMENTED PHYSICS INFORMED NEURAL NETWORKS | 3.00 | 3.00 | 0.00 | | Reject |
| 1528 | Finding One Missing Puzzle of Contextual Word Embedding: Representing Contexts as Manifold | 2.60 | 2.60 | 0.00 | | 1, 3, 3, 3, 3 | | 1, 3, 3, 3, 3 |
| Reject |
| 1529 | Incorporating User-Item Similarity in Hybrid Neighborhood-based Recommendation System | 2.60 | 2.60 | 0.00 | | 5, 3, 1, 3, 1 | | 5, 3, 1, 3, 1 |
| Reject |
| 1530 | A multi-domain splitting framework for time-varying graph structure | 3.00 | 2.60 | -0.40 | | Reject |
| 1531 | A neural network framework for learning Green's function | 2.50 | 2.50 | 0.00 | | Reject |
| 1532 | Exploring General Intelligence of Program Analysis for Multiple Tasks | 2.50 | 2.50 | 0.00 | | Reject |
| 1533 | Mind Your Solver! On Adversarial Attack and Defense for Combinatorial Optimization | 2.50 | 2.50 | 0.00 | | Reject |
| 1534 | Network Pruning Optimization by Simulated Annealing Algorithm | 2.50 | 2.50 | 0.00 | | Reject |
| 1535 | Exploring and Evaluating Personalized Models for Code Generation | 2.50 | 2.50 | 0.00 | | Reject |
| 1536 | Meta-Referential Games to Learn Compositional Learning Behaviours | 2.50 | 2.50 | 0.00 | | Reject |
| 1537 | Where can quantum kernel methods make a big difference? | 3.25 | 2.50 | -0.75 | | Reject |
| 1538 | Persistent Homology Captures the Generalization of Neural Networks Without A Validation Set | 2.50 | 2.50 | 0.00 | | Reject |
| 1539 | Neural Combinatorial Optimization with Reinforcement Learning : Solving theVehicle Routing Problem with Time Windows | 2.50 | 2.50 | 0.00 | | Reject |
| 1540 | Pruning Compact ConvNets For Efficient Inference | 2.50 | 2.50 | 0.00 | | Reject |
| 1541 | Interest-based Item Representation Framework for Recommendation with Multi-Interests Capsule Network | 2.50 | 2.50 | 0.00 | | Reject |
| 1542 | Contextual Fusion For Adversarial Robustness | 2.50 | 2.50 | 0.00 | | Reject |
| 1543 | An Effective GCN-based Hierarchical Multi-label classification for Protein Function Prediction | 2.50 | 2.50 | 0.00 | | Reject |
| 1544 | Building the Building Blocks: From Simplification to Winning Trees in Genetic Programming | 2.50 | 2.50 | 0.00 | | Reject |
| 1545 | Interpretable Semantic Role Relation Table for Supporting Facts Recognition of Reading Comprehension | 2.50 | 2.50 | 0.00 | | Reject |
| 1546 | Manifold Distance Judge, an Adversarial Samples Defense Strategy Based on Service Orchestration | 2.50 | 2.50 | 0.00 | | Reject |
| 1547 | Two Instances of Interpretable Neural Network for Universal Approximations | 2.50 | 2.50 | 0.00 | | Reject |
| 1548 | How does BERT address polysemy of Korean adverbial postpositions -ey, -eyse, and -(u)lo? | 2.50 | 2.50 | 0.00 | | Reject |
| 1549 | Researchonfusionalgorithmofmulti−a | 2.50 | 2.50 | 0.00 | | Reject |
| 1550 | Deep banach space kernels | 2.33 | 2.33 | 0.00 | | Reject |
| 1551 | Dataset transformations trade-offs to adapt machine learning methods across domains | 2.33 | 2.33 | 0.00 | | Reject |
| 1552 | Representing value functions in power systems using parametric network series | 2.33 | 2.33 | 0.00 | | Reject |
| 1553 | Mistake-driven Image Classification with FastGAN and SpinalNet | 2.33 | 2.33 | 0.00 | | Reject |
| 1554 | Occupy & Specify: Investigations into a Maximum Credit Assignment Occupancy Objective for Data-efficient Reinforcement Learning | 2.33 | 2.33 | 0.00 | | Reject |
| 1555 | ConVAEr: Convolutional Variational AutoEncodeRs for incremental similarity learning | 2.33 | 2.33 | 0.00 | | Reject |
| 1556 | Dissecting Local Properties of Adversarial Examples | 2.33 | 2.33 | 0.00 | | Reject |
| 1557 | TS-BERT: A fusion model for Pre-trainning Time Series-Text Representations | 2.33 | 2.33 | 0.00 | | Reject |
| 1558 | LMSA: Low-relation Mutil-head Self-Attention Mechanism in Visual Transformer | 2.33 | 2.33 | 0.00 | | Reject |
| 1559 | A stepped sampling method for video detection using LSTM | 2.33 | 2.33 | 0.00 | | Reject |
| 1560 | AestheticNet: Reducing bias in facial data sets under ethical considerations | 2.25 | 2.25 | 0.00 | | Reject |
| 1561 | Neural networks with trainable matrix activation functions | 2.20 | 2.20 | 0.00 | | 1, 3, 3, 1, 3 | | 1, 3, 3, 1, 3 |
| Reject |
| 1562 | OUMG: Objective and Universal Metric for Text Generation with Guiding Ability | 2.20 | 2.20 | 0.00 | | 1, 1, 3, 3, 3 | | 1, 1, 3, 3, 3 |
| Reject |
| 1563 | DATA-DRIVEN EVALUATION OF TRAINING ACTION SPACE FOR REINFORCEMENT LEARNING | 2.00 | 2.00 | 0.00 | | Reject |
| 1564 | Convergence of Generalized Belief Propagation Algorithm on Graphs with Motifs | 2.00 | 2.00 | 0.00 | | Reject |
| 1565 | Experience Replay More When It's a Key Transition in Deep Reinforcement Learning | 2.00 | 2.00 | 0.00 | | Reject |
| 1566 | Single-Cell Capsule Attention : an interpretable method of cell type classification for single-cell RNA-sequencing data | 2.00 | 2.00 | 0.00 | | Reject |
| 1567 | A New Perspective on Fluid Simulation: An Image-to-Image Translation Task via Neural Networks | 2.00 | 2.00 | 0.00 | | Reject |
| 1568 | AutoMO-Mixer: An automated multi-objective multi-layer perspecton Mixer model for medical image based diagnosis | 2.00 | 2.00 | 0.00 | | Reject |
| 1569 | ANOMALY DETECTION WITH FRAME-GROUP ATTENTION IN SURVEILLANCE VIDEOS | 2.00 | 2.00 | 0.00 | | Reject |
| 1570 | DMSANET: DUAL MULTI SCALE ATTENTION NETWORK | 2.00 | 2.00 | 0.00 | | Reject |
| 1571 | Self Reward Design with Fine-grained Interpretability | 1.80 | 1.80 | 0.00 | | 1, 3, 1, 3, 1 | | 1, 3, 1, 3, 1 |
| Reject |
| 1572 | Zero-shot detection of daily objects in YCB video dataset | 1.80 | 1.80 | 0.00 | | 1, 1, 1, 3, 3 | | 1, 1, 1, 3, 3 |
| Reject |
| 1573 | Multi-Task Distribution Learning | 1.67 | 1.67 | 0.00 | | Reject |
| 1574 | Benchmarking Machine Learning Robustness in Covid-19 Spike Sequence Classification | 1.67 | 1.67 | 0.00 | | Reject |
| 1575 | Network robustness as a mathematical property: training, evaluation and attack | 1.67 | 1.67 | 0.00 | | Reject |
| 1576 | Deep convolutional recurrent neural network for short-interval EEG motor imagery classification | 1.67 | 1.67 | 0.00 | | Reject |
| 1577 | AASEG: ATTENTION AWARE NETWORK FOR REAL TIME SEMANTIC SEGMENTATION | 1.50 | 1.50 | 0.00 | | Reject |
| 1578 | Training sequence labeling models using prior knowledge | 1.00 | 1.00 | 0.00 | | Reject |
| 1579 | Graph Tree Neural Networks | 1.00 | 1.00 | 0.00 | | Reject |
| 1580 | UNCERTAINTY QUANTIFICATION USING VARIATIONAL INFERENCE FOR BIOMEDICAL IMAGE SEGMENTATION | 1.00 | 1.00 | 0.00 | | Reject |
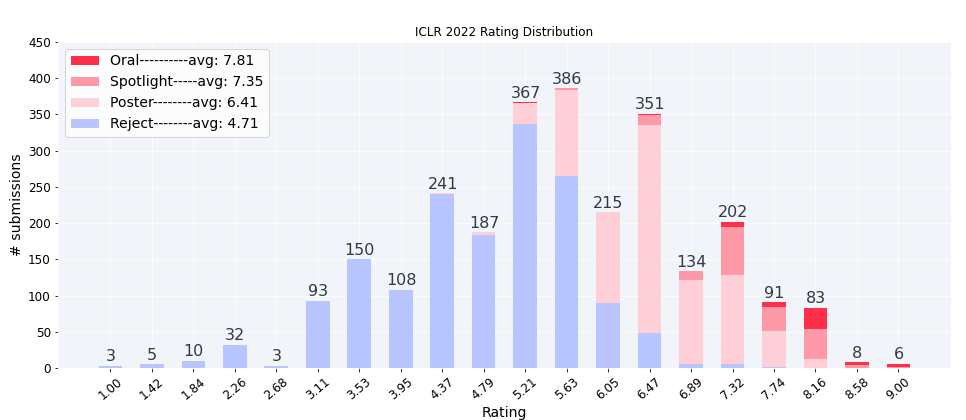
 /
/ ) to get submission info quickly.
) to get submission info quickly.