| 1 | Bootstrapped Meta-Learning | 8.00 | 9.00 | 1.00 | | Oral |
| 2 | Filtered-CoPhy: Unsupervised Learning of Counterfactual Physics in Pixel Space | 7.00 | 8.67 | 1.67 | | Oral |
| 3 | A Fine-Grained Analysis on Distribution Shift | 6.67 | 8.67 | 2.00 | | Oral |
| 4 | Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme | 7.67 | 8.67 | 1.00 | | Oral |
| 5 | Expressiveness and Approximation Properties of Graph Neural Networks | 7.00 | 8.50 | 1.50 | | Oral |
| 6 | DISCOVERING AND EXPLAINING THE REPRESENTATION BOTTLENECK OF DNNS | 7.25 | 8.50 | 1.25 | | Oral |
| 7 | Understanding over-squashing and bottlenecks on graphs via curvature | 7.00 | 8.50 | 1.50 | | Oral |
| 8 | Neural Structured Prediction for Inductive Node Classification | 7.25 | 8.50 | 1.25 | | Oral |
| 9 | Provably Filtering Exogenous Distractors using Multistep Inverse Dynamics | 6.25 | 8.00 | 1.75 | | Oral |
| 10 | Comparing Distributions by Measuring Differences that Affect Decision Making | 8.00 | 8.00 | 0.00 | | Oral |
| 11 | Data-Efficient Graph Grammar Learning for Molecular Generation | 7.50 | 8.00 | 0.50 | | Oral |
| 12 | Non-Transferable Learning: A New Approach for Model Ownership Verification and Applicability Authorization | 7.33 | 8.00 | 0.67 | | Oral |
| 13 | Efficiently Modeling Long Sequences with Structured State Spaces | 8.00 | 8.00 | 0.00 | | Oral |
| 14 | Hyperparameter Tuning with Renyi Differential Privacy | 7.00 | 8.00 | 1.00 | | Oral |
| 15 | MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling | 8.00 | 8.00 | 0.00 | | Oral |
| 16 | Unsupervised Vision-Language Grammar Induction with Shared Structure Modeling | 7.00 | 8.00 | 1.00 | | Oral |
| 17 | Vision-Based Manipulators Need to Also See from Their Hands | 7.33 | 8.00 | 0.67 | | Oral |
| 18 | Meta-Learning with Fewer Tasks through Task Interpolation | 7.00 | 8.00 | 1.00 | | 6, 8, 8, 5, 8 | | 8, 8, 8, 8, 8 |
| Oral |
| 19 | Finetuned Language Models are Zero-Shot Learners | 8.00 | 8.00 | 0.00 | | Oral |
| 20 | iLQR-VAE : control-based learning of input-driven dynamics with applications to neural data | 7.33 | 8.00 | 0.67 | | Oral |
| 21 | Transform2Act: Learning a Transform-and-Control Policy for Efficient Agent Design | 6.75 | 8.00 | 1.25 | | Oral |
| 22 | Asymmetry Learning for Counterfactually-invariant Classification in OOD Tasks | 6.00 | 8.00 | 2.00 | | Oral |
| 23 | Minibatch vs Local SGD with Shuffling: Tight Convergence Bounds and Beyond | 8.00 | 8.00 | 0.00 | | Oral |
| 24 | Frame Averaging for Invariant and Equivariant Network Design | 6.00 | 8.00 | 2.00 | | Oral |
| 25 | Contrastive Label Disambiguation for Partial Label Learning | 8.00 | 8.00 | 0.00 | | Oral |
| 26 | RISP: Rendering-Invariant State Predictor with Differentiable Simulation and Rendering for Cross-Domain Parameter Estimation | 8.00 | 8.00 | 0.00 | | Oral |
| 27 | The Hidden Convex Optimization Landscape of Regularized Two-Layer ReLU Networks: an Exact Characterization of Optimal Solutions | 8.00 | 8.00 | 0.00 | | Oral |
| 28 | Real-Time Neural Voice Camouflage | 6.00 | 8.00 | 2.00 | | Oral |
| 29 | Natural Language Descriptions of Deep Features | 8.00 | 8.00 | 0.00 | | Oral |
| 30 | Rethinking the Representational Continuity: Towards Unsupervised Continual Learning | 6.75 | 8.00 | 1.25 | | Oral |
| 31 | Language modeling via stochastic processes | 7.00 | 8.00 | 1.00 | | Oral |
| 32 | Fine-Tuning Distorts Pretrained Features and Underperforms Out-of-Distribution | 6.25 | 8.00 | 1.75 | | Oral |
| 33 | The Information Geometry of Unsupervised Reinforcement Learning | 7.00 | 8.00 | 1.00 | | Oral |
| 34 | Poisoning and Backdooring Contrastive Learning | 6.75 | 8.00 | 1.25 | | Oral |
| 35 | Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models | 7.60 | 8.00 | 0.40 | | 8, 6, 8, 8, 8 | | 8, 8, 8, 8, 8 |
| Oral |
| 36 | BEiT: BERT Pre-Training of Image Transformers | 7.50 | 8.00 | 0.50 | | Oral |
| 37 | A New Perspective on 'How Graph Neural Networks Go Beyond Weisfeiler-Lehman?' | 8.00 | 8.00 | 0.00 | | Oral |
| 38 | Extending the WILDS Benchmark for Unsupervised Adaptation | 7.00 | 7.50 | 0.50 | | Oral |
| 39 | Large Language Models Can Be Strong Differentially Private Learners | 6.50 | 7.50 | 1.00 | | Oral |
| 40 | CycleMLP: A MLP-like Architecture for Dense Prediction | 6.75 | 7.50 | 0.75 | | Oral |
| 41 | Coordination Among Neural Modules Through a Shared Global Workspace | 7.50 | 7.50 | 0.00 | | Oral |
| 42 | Weighted Training for Cross-Task Learning | 7.50 | 7.50 | 0.00 | | Oral |
| 43 | StyleAlign: Analysis and Applications of Aligned StyleGAN Models | 7.50 | 7.50 | 0.00 | | Oral |
| 44 | Sparse Communication via Mixed Distributions | 7.25 | 7.50 | 0.25 | | Oral |
| 45 | Domino: Discovering Systematic Errors with Cross-Modal Embeddings | 5.67 | 7.33 | 1.67 | | Oral |
| 46 | GeoDiff: A Geometric Diffusion Model for Molecular Conformation Generation | 6.67 | 7.33 | 0.67 | | Oral |
| 47 | Open-Set Recognition: A Good Closed-Set Classifier is All You Need | 6.67 | 7.33 | 0.67 | | Oral |
| 48 | ProtoRes: Proto-Residual Network for Pose Authoring via Learned Inverse Kinematics | 6.67 | 7.33 | 0.67 | | Oral |
| 49 | Pyraformer: Low-Complexity Pyramidal Attention for Long-Range Time Series Modeling and Forecasting | 6.00 | 7.00 | 1.00 | | Oral |
| 50 | Resolving Training Biases via Influence-based Data Relabeling | 5.75 | 7.00 | 1.25 | | Oral |
| 51 | Neural Collapse Under MSE Loss: Proximity to and Dynamics on the Central Path | 6.00 | 7.00 | 1.00 | | Oral |
| 52 | F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization | 6.25 | 6.50 | 0.25 | | Oral |
| 53 | Variational Inference for Discriminative Learning with Generative Modeling of Feature Incompletion | 6.25 | 6.25 | 0.00 | | Oral |
| 54 | Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation | 5.00 | 5.00 | 0.00 | | Oral |
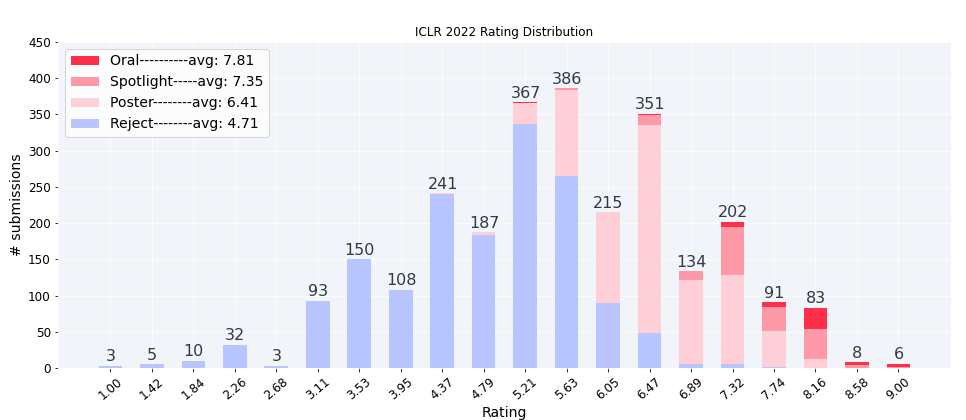
 /
/ ) to get submission info quickly.
) to get submission info quickly.