| 1 | Bootstrapped Meta-Learning | 8.00 | 9.00 | 1.00 | | Oral |
| 2 | Towards a Unified View of Parameter-Efficient Transfer Learning | 8.00 | 8.67 | 0.67 | | Spotlight |
| 3 | Filtered-CoPhy: Unsupervised Learning of Counterfactual Physics in Pixel Space | 7.00 | 8.67 | 1.67 | | Oral |
| 4 | A Fine-Grained Analysis on Distribution Shift | 6.67 | 8.67 | 2.00 | | Oral |
| 5 | Self-Supervision Enhanced Feature Selection with Correlated Gates | 8.00 | 8.67 | 0.67 | | Spotlight |
| 6 | Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme | 7.67 | 8.67 | 1.00 | | Oral |
| 7 | What Happens after SGD Reaches Zero Loss? --A Mathematical Framework | 8.00 | 8.50 | 0.50 | | Spotlight |
| 8 | Score-Based Generative Modeling with Critically-Damped Langevin Diffusion | 8.00 | 8.50 | 0.50 | | Spotlight |
| 9 | Sample Efficient Deep Reinforcement Learning via Uncertainty Estimation | 6.00 | 8.50 | 2.50 | | Spotlight |
| 10 | Expressiveness and Approximation Properties of Graph Neural Networks | 7.00 | 8.50 | 1.50 | | Oral |
| 11 | DISCOVERING AND EXPLAINING THE REPRESENTATION BOTTLENECK OF DNNS | 7.25 | 8.50 | 1.25 | | Oral |
| 12 | Understanding over-squashing and bottlenecks on graphs via curvature | 7.00 | 8.50 | 1.50 | | Oral |
| 13 | Scaling Laws for Neural Machine Translation | 7.50 | 8.50 | 1.00 | | Spotlight |
| 14 | Neural Structured Prediction for Inductive Node Classification | 7.25 | 8.50 | 1.25 | | Oral |
| 15 | Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks | 6.00 | 8.00 | 2.00 | | Spotlight |
| 16 | EViT: Expediting Vision Transformers via Token Reorganizations | 7.00 | 8.00 | 1.00 | | Spotlight |
| 17 | Provably Filtering Exogenous Distractors using Multistep Inverse Dynamics | 6.25 | 8.00 | 1.75 | | Oral |
| 18 | Comparing Distributions by Measuring Differences that Affect Decision Making | 8.00 | 8.00 | 0.00 | | Oral |
| 19 | Programmatic Reinforcement Learning without Oracles | 6.33 | 8.00 | 1.67 | | Spotlight |
| 20 | AdaRL: What, Where, and How to Adapt in Transfer Reinforcement Learning | 7.50 | 8.00 | 0.50 | | Spotlight |
| 21 | Data-Efficient Graph Grammar Learning for Molecular Generation | 7.50 | 8.00 | 0.50 | | Oral |
| 22 | Iterative Refinement Graph Neural Network for Antibody Sequence-Structure Co-design | 8.00 | 8.00 | 0.00 | | Spotlight |
| 23 | Fast Regression for Structured Inputs | 5.67 | 8.00 | 2.33 | | Poster |
| 24 | Non-Transferable Learning: A New Approach for Model Ownership Verification and Applicability Authorization | 7.33 | 8.00 | 0.67 | | Oral |
| 25 | Efficiently Modeling Long Sequences with Structured State Spaces | 8.00 | 8.00 | 0.00 | | Oral |
| 26 | Assessing Generalization of SGD via Disagreement | 8.00 | 8.00 | 0.00 | | Spotlight |
| 27 | Independent SE(3)-Equivariant Models for End-to-End Rigid Protein Docking | 6.00 | 8.00 | 2.00 | | Spotlight |
| 28 | Spike-inspired rank coding for fast and accurate recurrent neural networks | 6.33 | 8.00 | 1.67 | | Spotlight |
| 29 | MT3: Multi-Task Multitrack Music Transcription | 8.00 | 8.00 | 0.00 | | Spotlight |
| 30 | Hyperparameter Tuning with Renyi Differential Privacy | 7.00 | 8.00 | 1.00 | | Oral |
| 31 | MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling | 8.00 | 8.00 | 0.00 | | Oral |
| 32 | Unsupervised Vision-Language Grammar Induction with Shared Structure Modeling | 7.00 | 8.00 | 1.00 | | Oral |
| 33 | Vision-Based Manipulators Need to Also See from Their Hands | 7.33 | 8.00 | 0.67 | | Oral |
| 34 | Meta-Learning with Fewer Tasks through Task Interpolation | 7.00 | 8.00 | 1.00 | | 6, 8, 8, 5, 8 | | 8, 8, 8, 8, 8 |
| Oral |
| 35 | Finetuned Language Models are Zero-Shot Learners | 8.00 | 8.00 | 0.00 | | Oral |
| 36 | The Inductive Bias of In-Context Learning: Rethinking Pretraining Example Design | 6.60 | 8.00 | 1.40 | | 8, 8, 5, 6, 6 | | 8, 8, 8, 8, 8 |
| Spotlight |
| 37 | Granger causal inference on DAGs identifies genomic loci regulating transcription | 6.75 | 8.00 | 1.25 | | Poster |
| 38 | iLQR-VAE : control-based learning of input-driven dynamics with applications to neural data | 7.33 | 8.00 | 0.67 | | Oral |
| 39 | Possibility Before Utility: Learning And Using Hierarchical Affordances | 8.00 | 8.00 | 0.00 | | Spotlight |
| 40 | PER-ETD: A Polynomially Efficient Emphatic Temporal Difference Learning Method | 7.00 | 8.00 | 1.00 | | Poster |
| 41 | Path Auxiliary Proposal for MCMC in Discrete Space | 5.25 | 8.00 | 2.75 | | Spotlight |
| 42 | Transform2Act: Learning a Transform-and-Control Policy for Efficient Agent Design | 6.75 | 8.00 | 1.25 | | Oral |
| 43 | TAMP-S2GCNets: Coupling Time-Aware Multipersistence Knowledge Representation with Spatio-Supra Graph Convolutional Networks for Time-Series Forecasting | 8.00 | 8.00 | 0.00 | | Spotlight |
| 44 | Understanding Latent Correlation-Based Multiview Learning and Self-Supervision: An Identifiability Perspective | 6.67 | 8.00 | 1.33 | | Spotlight |
| 45 | Asymmetry Learning for Counterfactually-invariant Classification in OOD Tasks | 6.00 | 8.00 | 2.00 | | Oral |
| 46 | Adaptive Control Flow in Transformers Improves Systematic Generalization | 6.67 | 8.00 | 1.33 | | Poster |
| 47 | Minibatch vs Local SGD with Shuffling: Tight Convergence Bounds and Beyond | 8.00 | 8.00 | 0.00 | | Oral |
| 48 | Scalable Sampling for Nonsymmetric Determinantal Point Processes | 7.50 | 8.00 | 0.50 | | Spotlight |
| 49 | Frame Averaging for Invariant and Equivariant Network Design | 6.00 | 8.00 | 2.00 | | Oral |
| 50 | Contrastive Label Disambiguation for Partial Label Learning | 8.00 | 8.00 | 0.00 | | Oral |
| 51 | Sampling with Mirrored Stein Operators | 8.00 | 8.00 | 0.00 | | Spotlight |
| 52 | Reinforcement Learning under a Multi-agent Predictive State Representation Model: Method and Theory | 8.00 | 8.00 | 0.00 | | Spotlight |
| 53 | DemoDICE: Offline Imitation Learning with Supplementary Imperfect Demonstrations | 7.33 | 8.00 | 0.67 | | Poster |
| 54 | RISP: Rendering-Invariant State Predictor with Differentiable Simulation and Rendering for Cross-Domain Parameter Estimation | 8.00 | 8.00 | 0.00 | | Oral |
| 55 | Learning transferable motor skills with hierarchical latent mixture policies | 6.50 | 8.00 | 1.50 | | Spotlight |
| 56 | SphereFace2: Binary Classification is All You Need for Deep Face Recognition | 7.00 | 8.00 | 1.00 | | Spotlight |
| 57 | Evaluating Distributional Distortion in Neural Language Modeling | 6.33 | 8.00 | 1.67 | | Poster |
| 58 | A General Analysis of Example-Selection for Stochastic Gradient Descent | 8.00 | 8.00 | 0.00 | | Spotlight |
| 59 | The Hidden Convex Optimization Landscape of Regularized Two-Layer ReLU Networks: an Exact Characterization of Optimal Solutions | 8.00 | 8.00 | 0.00 | | Oral |
| 60 | Real-Time Neural Voice Camouflage | 6.00 | 8.00 | 2.00 | | Oral |
| 61 | Natural Language Descriptions of Deep Features | 8.00 | 8.00 | 0.00 | | Oral |
| 62 | Rethinking the Representational Continuity: Towards Unsupervised Continual Learning | 6.75 | 8.00 | 1.25 | | Oral |
| 63 | Explanations of Black-Box Models based on Directional Feature Interactions | 6.50 | 8.00 | 1.50 | | Spotlight |
| 64 | EntQA: Entity Linking as Question Answering | 8.00 | 8.00 | 0.00 | | Spotlight |
| 65 | Byzantine-Robust Learning on Heterogeneous Datasets via Bucketing | 7.00 | 8.00 | 1.00 | | Spotlight |
| 66 | NeuPL: Neural Population Learning | 6.50 | 8.00 | 1.50 | | Poster |
| 67 | Wiring Up Vision: Minimizing Supervised Synaptic Updates Needed to Produce a Primate Ventral Stream | 6.75 | 8.00 | 1.25 | | Spotlight |
| 68 | RelaxLoss: Defending Membership Inference Attacks without Losing Utility | 7.33 | 8.00 | 0.67 | | Spotlight |
| 69 | Language modeling via stochastic processes | 7.00 | 8.00 | 1.00 | | Oral |
| 70 | Fine-Tuning Distorts Pretrained Features and Underperforms Out-of-Distribution | 6.25 | 8.00 | 1.75 | | Oral |
| 71 | Ab-Initio Potential Energy Surfaces by Pairing GNNs with Neural Wave Functions | 7.33 | 8.00 | 0.67 | | Spotlight |
| 72 | Tackling the Generative Learning Trilemma with Denoising Diffusion GANs | 7.50 | 8.00 | 0.50 | | Spotlight |
| 73 | Universal Approximation Under Constraints is Possible with Transformers | 7.00 | 8.00 | 1.00 | | Spotlight |
| 74 | Learning Strides in Convolutional Neural Networks | 6.75 | 8.00 | 1.25 | | Spotlight |
| 75 | Progressive Distillation for Fast Sampling of Diffusion Models | 7.00 | 8.00 | 1.00 | | Spotlight |
| 76 | Convergent Graph Solvers | 7.00 | 8.00 | 1.00 | | Poster |
| 77 | The Information Geometry of Unsupervised Reinforcement Learning | 7.00 | 8.00 | 1.00 | | Oral |
| 78 | Poisoning and Backdooring Contrastive Learning | 6.75 | 8.00 | 1.25 | | Oral |
| 79 | Neural Deep Equilibrium Solvers | 8.00 | 8.00 | 0.00 | | Poster |
| 80 | Inductive Relation Prediction Using Analogy Subgraph Embeddings | 5.80 | 8.00 | 2.20 | | 6, 5, 6, 6, 6 | | 8, 8, 8, 8, 8 |
| Poster |
| 81 | Probabilistic Implicit Scene Completion | 6.80 | 8.00 | 1.20 | | 6, 6, 8, 8, 6 | | 8, 8, 8, 8, 8 |
| Spotlight |
| 82 | Perceiver IO: A General Architecture for Structured Inputs & Outputs | 7.50 | 8.00 | 0.50 | | Spotlight |
| 83 | Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models | 7.60 | 8.00 | 0.40 | | 8, 6, 8, 8, 8 | | 8, 8, 8, 8, 8 |
| Oral |
| 84 | How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective | 6.50 | 8.00 | 1.50 | | Spotlight |
| 85 | Emergent Communication at Scale | 8.00 | 8.00 | 0.00 | | Spotlight |
| 86 | RotoGrad: Gradient Homogenization in Multitask Learning | 7.50 | 8.00 | 0.50 | | Spotlight |
| 87 | Towards Deployment-Efficient Reinforcement Learning: Lower Bound and Optimality | 8.00 | 8.00 | 0.00 | | Spotlight |
| 88 | BEiT: BERT Pre-Training of Image Transformers | 7.50 | 8.00 | 0.50 | | Oral |
| 89 | Meta Discovery: Learning to Discover Novel Classes given Very Limited Data | 7.50 | 8.00 | 0.50 | | Spotlight |
| 90 | GNN-LM: Language Modeling based on Global Contexts via GNN | 7.67 | 8.00 | 0.33 | | Spotlight |
| 91 | Fast Differentiable Matrix Square Root | 6.33 | 8.00 | 1.67 | | Poster |
| 92 | On the Connection between Local Attention and Dynamic Depth-wise Convolution | 7.33 | 8.00 | 0.67 | | Spotlight |
| 93 | Visual Representation Learning Does Not Generalize Strongly Within the Same Domain | 6.75 | 8.00 | 1.25 | | Poster |
| 94 | A New Perspective on 'How Graph Neural Networks Go Beyond Weisfeiler-Lehman?' | 8.00 | 8.00 | 0.00 | | Oral |
| 95 | SHINE: SHaring the INverse Estimate from the forward pass for bi-level optimization and implicit models | 6.00 | 8.00 | 2.00 | | Spotlight |
| 96 | On the Optimal Memorization Power of ReLU Neural Networks | 8.00 | 8.00 | 0.00 | | Spotlight |
| 97 | Task Relatedness-Based Generalization Bounds for Meta Learning | 7.50 | 8.00 | 0.50 | | Spotlight |
| 98 | Understanding Domain Randomization for Sim-to-real Transfer | 7.25 | 7.75 | 0.50 | | Spotlight |
| 99 | Planning in Stochastic Environments with a Learned Model | 7.00 | 7.75 | 0.75 | | Spotlight |
| 100 | Source-Free Adaptation to Measurement Shift via Bottom-Up Feature Restoration | 6.60 | 7.60 | 1.00 | | 8, 6, 5, 6, 8 | | 8, 8, 6, 8, 8 |
| Spotlight |
| 101 | Local Feature Swapping for Generalization in Reinforcement Learning | 5.00 | 7.60 | 2.60 | | 5, 3, 6, 5, 6 | | 8, 6, 8, 8, 8 |
| Poster |
| 102 | QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization | 6.00 | 7.50 | 1.50 | | Poster |
| 103 | Learnability Lock: Authorized Learnability Control Through Adversarial Invertible Transformations | 5.50 | 7.50 | 2.00 | | Poster |
| 104 | Optimization and Adaptive Generalization of Three layer Neural Networks | 7.25 | 7.50 | 0.25 | | Poster |
| 105 | Label Encoding for Regression Networks | 5.50 | 7.50 | 2.00 | | Spotlight |
| 106 | On the Importance of Firth Bias Reduction in Few-Shot Classification | 7.00 | 7.50 | 0.50 | | Spotlight |
| 107 | Approximation and Learning with Deep Convolutional Models: a Kernel Perspective | 7.50 | 7.50 | 0.00 | | Poster |
| 108 | Case-based Reasoning for Better Generalization in Text-Adventure Games | 5.75 | 7.50 | 1.75 | | Poster |
| 109 | Conditional Image Generation by Conditioning Variational Auto-Encoders | 6.00 | 7.50 | 1.50 | | Poster |
| 110 | DiffSkill: Skill Abstraction from Differentiable Physics for Deformable Object Manipulations with Tools | 6.33 | 7.50 | 1.17 | | Poster |
| 111 | When Can We Learn General-Sum Markov Games with a Large Number of Players Sample-Efficiently? | 8.00 | 7.50 | -0.50 | | Poster |
| 112 | The Boltzmann Policy Distribution: Accounting for Systematic Suboptimality in Human Models | 6.75 | 7.50 | 0.75 | | Poster |
| 113 | Accelerated Policy Learning with Parallel Differentiable Simulation | 6.00 | 7.50 | 1.50 | | Poster |
| 114 | NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy | 7.50 | 7.50 | 0.00 | | Poster |
| 115 | Know Your Action Set: Learning Action Relations for Reinforcement Learning | 5.25 | 7.50 | 2.25 | | Poster |
| 116 | LORD: Lower-Dimensional Embedding of Log-Signature in Neural Rough Differential Equations | 7.25 | 7.50 | 0.25 | | Poster |
| 117 | Understanding the Role of Self Attention for Efficient Speech Recognition | 6.75 | 7.50 | 0.75 | | Spotlight |
| 118 | StyleNeRF: A Style-based 3D Aware Generator for High-resolution Image Synthesis | 7.50 | 7.50 | 0.00 | | Poster |
| 119 | Extending the WILDS Benchmark for Unsupervised Adaptation | 7.00 | 7.50 | 0.50 | | Oral |
| 120 | Environment Predictive Coding for Visual Navigation | 6.25 | 7.50 | 1.25 | | Poster |
| 121 | Unsupervised Federated Learning is Possible | 7.00 | 7.50 | 0.50 | | Poster |
| 122 | Latent Variable Sequential Set Transformers for Joint Multi-Agent Motion Prediction | 5.50 | 7.50 | 2.00 | | Spotlight |
| 123 | Deconstructing the Inductive Biases of Hamiltonian Neural Networks | 7.50 | 7.50 | 0.00 | | Spotlight |
| 124 | Learning more skills through optimistic exploration | 7.25 | 7.50 | 0.25 | | Spotlight |
| 125 | Large Language Models Can Be Strong Differentially Private Learners | 6.50 | 7.50 | 1.00 | | Oral |
| 126 | Meta-Imitation Learning by Watching Video Demonstrations | 5.25 | 7.50 | 2.25 | | Poster |
| 127 | Hybrid Local SGD for Federated Learning with Heterogeneous Communications | 5.75 | 7.50 | 1.75 | | Spotlight |
| 128 | Training invariances and the low-rank phenomenon: beyond linear networks | 6.75 | 7.50 | 0.75 | | Spotlight |
| 129 | CycleMLP: A MLP-like Architecture for Dense Prediction | 6.75 | 7.50 | 0.75 | | Oral |
| 130 | Continuous-Time Meta-Learning with Forward Mode Differentiation | 7.00 | 7.50 | 0.50 | | Spotlight |
| 131 | Pixelated Butterfly: Simple and Efficient Sparse training for Neural Network Models | 7.00 | 7.50 | 0.50 | | Spotlight |
| 132 | Hindsight is 20/20: Leveraging Past Traversals to Aid 3D Perception | 7.50 | 7.50 | 0.00 | | Poster |
| 133 | Can an Image Classifier Suffice For Action Recognition? | 7.25 | 7.50 | 0.25 | | Poster |
| 134 | Generative Models as a Data Source for Multiview Representation Learning | 6.25 | 7.50 | 1.25 | | Poster |
| 135 | CrossBeam: Learning to Search in Bottom-Up Program Synthesis | 7.00 | 7.50 | 0.50 | | Poster |
| 136 | Continual Learning with Filter Atom Swapping | 7.00 | 7.50 | 0.50 | | Spotlight |
| 137 | Information Prioritization through Empowerment in Visual Model-based RL | 5.50 | 7.50 | 2.00 | | Poster |
| 138 | Revisiting flow generative models for Out-of-distribution detection | 5.75 | 7.50 | 1.75 | | Poster |
| 139 | HyAR: Addressing Discrete-Continuous Action Reinforcement Learning via Hybrid Action Representation | 6.75 | 7.50 | 0.75 | | Poster |
| 140 | Mention Memory: incorporating textual knowledge into Transformers through entity mention attention | 6.50 | 7.50 | 1.00 | | Poster |
| 141 | Coordination Among Neural Modules Through a Shared Global Workspace | 7.50 | 7.50 | 0.00 | | Oral |
| 142 | Learning Vision-Guided Quadrupedal Locomotion End-to-End with Cross-Modal Transformers | 7.00 | 7.50 | 0.50 | | Spotlight |
| 143 | Learning the Dynamics of Physical Systems from Sparse Observations with Finite Element Networks | 7.50 | 7.50 | 0.00 | | Spotlight |
| 144 | Vitruvion: A Generative Model of Parametric CAD Sketches | 6.25 | 7.50 | 1.25 | | Poster |
| 145 | Weighted Training for Cross-Task Learning | 7.50 | 7.50 | 0.00 | | Oral |
| 146 | No One Representation to Rule Them All: Overlapping Features of Training Methods | 7.00 | 7.50 | 0.50 | | Poster |
| 147 | UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning | 7.50 | 7.50 | 0.00 | | Poster |
| 148 | Relating transformers to models and neural representations of the hippocampal formation | 5.75 | 7.50 | 1.75 | | Poster |
| 149 | Learnability of convolutional neural networks for infinite dimensional input via mixed and anisotropic smoothness | 8.00 | 7.50 | -0.50 | | Spotlight |
| 150 | Interpretable Unsupervised Diversity Denoising and Artefact Removal | 7.25 | 7.50 | 0.25 | | Spotlight |
| 151 | πBO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization | 6.25 | 7.50 | 1.25 | | Poster |
| 152 | TAPEX: Table Pre-training via Learning a Neural SQL Executor | 8.00 | 7.50 | -0.50 | | Poster |
| 153 | On the Pitfalls of Analyzing Individual Neurons in Language Models | 6.75 | 7.50 | 0.75 | | Poster |
| 154 | Learning Discrete Structured Variational Auto-Encoder using Natural Evolution Strategies | 6.50 | 7.50 | 1.00 | | Poster |
| 155 | Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy | 5.25 | 7.50 | 2.25 | | Spotlight |
| 156 | Creating Training Sets via Weak Indirect Supervision | 6.25 | 7.50 | 1.25 | | Poster |
| 157 | Decoupled Adaptation for Cross-Domain Object Detection | 6.75 | 7.50 | 0.75 | | Poster |
| 158 | InfinityGAN: Towards Infinite-Pixel Image Synthesis | 7.25 | 7.50 | 0.25 | | Poster |
| 159 | Scalable One-Pass Optimisation of High-Dimensional Weight-Update Hyperparameters by Implicit Differentiation | 5.50 | 7.50 | 2.00 | | Spotlight |
| 160 | StyleAlign: Analysis and Applications of Aligned StyleGAN Models | 7.50 | 7.50 | 0.00 | | Oral |
| 161 | Imbedding Deep Neural Networks | 7.00 | 7.50 | 0.50 | | Spotlight |
| 162 | Sparse Communication via Mixed Distributions | 7.25 | 7.50 | 0.25 | | Oral |
| 163 | Constrained Policy Optimization via Bayesian World Models | 6.75 | 7.50 | 0.75 | | Spotlight |
| 164 | Deep Attentive Variational Inference | 5.75 | 7.50 | 1.75 | | Poster |
| 165 | Evading Adversarial Example Detection Defenses with Orthogonal Projected Gradient Descent | 6.50 | 7.50 | 1.00 | | Poster |
| 166 | On Improving Adversarial Transferability of Vision Transformers | 6.00 | 7.50 | 1.50 | | Spotlight |
| 167 | Efficient Sharpness-aware Minimization for Improved Training of Neural Networks | 6.50 | 7.50 | 1.00 | | Poster |
| 168 | Learning Super-Features for Image Retrieval | 7.25 | 7.50 | 0.25 | | Poster |
| 169 | VAE Approximation Error: ELBO and Exponential Families | 7.00 | 7.50 | 0.50 | | Spotlight |
| 170 | Unifying Likelihood-free Inference with Black-box Sequence Design and Beyond | 7.00 | 7.50 | 0.50 | | Spotlight |
| 171 | How to Inject Backdoors with Better Consistency: Logit Anchoring on Clean Data | 7.50 | 7.50 | 0.00 | | Poster |
| 172 | Omni-Dimensional Dynamic Convolution | 7.00 | 7.50 | 0.50 | | Spotlight |
| 173 | Generative Planning for Temporally Coordinated Exploration in Reinforcement Learning | 6.25 | 7.50 | 1.25 | | Spotlight |
| 174 | SOSP: Efficiently Capturing Global Correlations by Second-Order Structured Pruning | 6.25 | 7.50 | 1.25 | | Spotlight |
| 175 | Adversarial Robustness Through the Lens of Causality | 6.25 | 7.50 | 1.25 | | Poster |
| 176 | A Deep Variational Approach to Clustering Survival Data | 7.25 | 7.50 | 0.25 | | Poster |
| 177 | Denoising Likelihood Score Matching for Conditional Score-based Data Generation | 6.75 | 7.50 | 0.75 | | Poster |
| 178 | DEPTS: Deep Expansion Learning for Periodic Time Series Forecasting | 7.50 | 7.50 | 0.00 | | Spotlight |
| 179 | CKConv: Continuous Kernel Convolution For Sequential Data | 6.50 | 7.50 | 1.00 | | Poster |
| 180 | Exploring the Limits of Large Scale Pre-training | 7.50 | 7.50 | 0.00 | | Spotlight |
| 181 | What’s Wrong with Deep Learning in Tree Search for Combinatorial Optimization | 6.00 | 7.50 | 1.50 | | Poster |
| 182 | Strength of Minibatch Noise in SGD | 7.50 | 7.50 | 0.00 | | Spotlight |
| 183 | PAC-Bayes Information Bottleneck | 7.50 | 7.50 | 0.00 | | Spotlight |
| 184 | Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation | 6.75 | 7.50 | 0.75 | | Poster |
| 185 | Policy improvement by planning with Gumbel | 6.25 | 7.50 | 1.25 | | Spotlight |
| 186 | You Mostly Walk Alone: Analyzing Feature Attribution in Trajectory Prediction | 5.60 | 7.40 | 1.80 | | 6, 6, 6, 5, 5 | | 8, 10, 6, 8, 5 |
| Poster |
| 187 | Improving Mutual Information Estimation with Annealed and Energy-Based Bounds | 7.33 | 7.33 | 0.00 | | Poster |
| 188 | Controlling Directions Orthogonal to a Classifier | 6.67 | 7.33 | 0.67 | | Spotlight |
| 189 | Distribution Compression in Near-Linear Time | 6.67 | 7.33 | 0.67 | | Poster |
| 190 | Autoregressive Quantile Flows for Predictive Uncertainty Estimation | 7.00 | 7.33 | 0.33 | | Spotlight |
| 191 | Learning Causal Relationships from Conditional Moment Restrictions by Importance Weighting | 6.67 | 7.33 | 0.67 | | Spotlight |
| 192 | Domino: Discovering Systematic Errors with Cross-Modal Embeddings | 5.67 | 7.33 | 1.67 | | Oral |
| 193 | Distributional Decision Transformer for Hindsight Information Matching | 4.00 | 7.33 | 3.33 | | Spotlight |
| 194 | Generalization of Neural Combinatorial Solvers Through the Lens of Adversarial Robustness | 7.00 | 7.33 | 0.33 | | Poster |
| 195 | Constructing a Good Behavior Basis for Transfer using Generalized Policy Updates | 6.00 | 7.33 | 1.33 | | Poster |
| 196 | GeoDiff: A Geometric Diffusion Model for Molecular Conformation Generation | 6.67 | 7.33 | 0.67 | | Oral |
| 197 | Contact Points Discovery for Soft-Body Manipulations with Differentiable Physics | 6.33 | 7.33 | 1.00 | | Spotlight |
| 198 | ARTEMIS: Attention-based Retrieval with Text-Explicit Matching and Implicit Similarity | 7.00 | 7.33 | 0.33 | | Poster |
| 199 | Superclass-Conditional Gaussian Mixture Model For Learning Fine-Grained Embeddings | 6.67 | 7.33 | 0.67 | | Spotlight |
| 200 | Label-Efficient Semantic Segmentation with Diffusion Models | 5.00 | 7.33 | 2.33 | | Poster |
| 201 | Back2Future: Leveraging Backfill Dynamics for Improving Real-time Predictions in Future | 7.00 | 7.33 | 0.33 | | Poster |
| 202 | Open-Set Recognition: A Good Closed-Set Classifier is All You Need | 6.67 | 7.33 | 0.67 | | Oral |
| 203 | Compositional Training for End-to-End Deep AUC Maximization | 7.33 | 7.33 | 0.00 | | Spotlight |
| 204 | Open-vocabulary Object Detection via Vision and Language Knowledge Distillation | 7.00 | 7.33 | 0.33 | | Poster |
| 205 | Convergent and Efficient Deep Q Learning Algorithm | 5.33 | 7.33 | 2.00 | | Poster |
| 206 | Learning-Augmentedk-means Clustering | 6.00 | 7.33 | 1.33 | | Spotlight |
| 207 | Efficient Self-supervised Vision Transformers for Representation Learning | 6.67 | 7.33 | 0.67 | | Poster |
| 208 | Sound Adversarial Audio-Visual Navigation | 5.67 | 7.33 | 1.67 | | Poster |
| 209 | Actor-critic is implicitly biased towards high entropy optimal policies | 6.33 | 7.33 | 1.00 | | Poster |
| 210 | Boosting Randomized Smoothing with Variance Reduced Classifiers | 6.67 | 7.33 | 0.67 | | Spotlight |
| 211 | Near-Optimal Reward-Free Exploration for Linear Mixture MDPs with Plug-in Solver | 6.33 | 7.33 | 1.00 | | Spotlight |
| 212 | Chunked Autoregressive GAN for Conditional Waveform Synthesis | 7.00 | 7.33 | 0.33 | | Poster |
| 213 | A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion | 7.00 | 7.33 | 0.33 | | Poster |
| 214 | IntSGD: Adaptive Floatless Compression of Stochastic Gradients | 6.67 | 7.33 | 0.67 | | Spotlight |
| 215 | Transition to Linearity of Wide Neural Networks is an Emerging Property of Assembling Weak Models | 7.33 | 7.33 | 0.00 | | Spotlight |
| 216 | Training Structured Neural Networks Through Manifold Identification and Variance Reduction | 5.33 | 7.33 | 2.00 | | Poster |
| 217 | On the approximation properties of recurrent encoder-decoder architectures | 7.00 | 7.33 | 0.33 | | Spotlight |
| 218 | A Johnson-Lindenstrauss Framework for Randomly Initialized CNNs | 6.33 | 7.33 | 1.00 | | Poster |
| 219 | Self-Supervised Graph Neural Networks for Improved Electroencephalographic Seizure Analysis | 6.67 | 7.33 | 0.67 | | Poster |
| 220 | CoBERL: Contrastive BERT for Reinforcement Learning | 6.33 | 7.33 | 1.00 | | Spotlight |
| 221 | Hybrid Random Features | 5.00 | 7.33 | 2.33 | | Poster |
| 222 | Graphon based Clustering and Testing of Networks: Algorithms and Theory | 5.67 | 7.33 | 1.67 | | Poster |
| 223 | Training Data Generating Networks: Shape Reconstruction via Bi-level Optimization | 6.67 | 7.33 | 0.67 | | Poster |
| 224 | Bregman Gradient Policy Optimization | 6.33 | 7.33 | 1.00 | | Poster |
| 225 | Promoting Saliency From Depth: Deep Unsupervised RGB-D Saliency Detection | 6.33 | 7.33 | 1.00 | | Poster |
| 226 | Relational Surrogate Loss Learning | 7.33 | 7.33 | 0.00 | | Poster |
| 227 | Discovering Invariant Rationales for Graph Neural Networks | 6.33 | 7.33 | 1.00 | | Poster |
| 228 | Causal ImageNet: How to discover spurious features in Deep Learning? | 7.00 | 7.33 | 0.33 | | Poster |
| 229 | CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation | 5.67 | 7.33 | 1.67 | | Poster |
| 230 | ProtoRes: Proto-Residual Network for Pose Authoring via Learned Inverse Kinematics | 6.67 | 7.33 | 0.67 | | Oral |
| 231 | Fast topological clustering with Wasserstein distance | 5.33 | 7.33 | 2.00 | | Poster |
| 232 | Critical Points in Quantum Generative Models | 7.00 | 7.33 | 0.33 | | Poster |
| 233 | Delaunay Component Analysis for Evaluation of Data Representations | 7.00 | 7.33 | 0.33 | | Poster |
| 234 | 8-bit Optimizers via Block-wise Quantization | 6.33 | 7.33 | 1.00 | | Spotlight |
| 235 | An Experimental Design Perspective on Exploration in Reinforcement Learning | 5.75 | 7.25 | 1.50 | | Poster |
| 236 | Fixed Neural Network Steganography: Train the images, not the network | 6.25 | 7.25 | 1.00 | | Poster |
| 237 | On Predicting Generalization using GANs | 6.25 | 7.25 | 1.00 | | Spotlight |
| 238 | Self-supervised Learning is More Robust to Dataset Imbalance | 7.25 | 7.25 | 0.00 | | Spotlight |
| 239 | Recycling Model Updates in Federated Learning: Are Gradient Subspaces Low-Rank? | 6.00 | 7.25 | 1.25 | | Poster |
| 240 | Continuously Discovering Novel Strategies via Reward-Switching Policy Optimization | 6.25 | 7.25 | 1.00 | | Poster |
| 241 | Bridging the Gap: Providing Post-Hoc Symbolic Explanations for Sequential Decision-Making Problems with Inscrutable Representations | 6.75 | 7.25 | 0.50 | | Poster |
| 242 | On the Generalization of Models Trained with SGD: Information-Theoretic Bounds and Implications | 7.25 | 7.25 | 0.00 | | Poster |
| 243 | Learning Long-Term Reward Redistribution via Randomized Return Decomposition | 5.33 | 7.25 | 1.92 | | Spotlight |
| 244 | How Do Vision Transformers Work? | 7.25 | 7.25 | 0.00 | | Spotlight |
| 245 | Graph-less Neural Networks: Teaching Old MLPs New Tricks Via Distillation | 6.75 | 7.25 | 0.50 | | Poster |
| 246 | Learning Optimal Conformal Classifiers | 6.50 | 7.25 | 0.75 | | Spotlight |
| 247 | Escaping limit cycles: Global convergence for constrained nonconvex-nonconcave minimax problems | 7.25 | 7.25 | 0.00 | | Spotlight |
| 248 | Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks | 5.67 | 7.25 | 1.58 | | Poster |
| 249 | Hidden Convexity of Wasserstein GANs: Interpretable Generative Models with Closed-Form Solutions | 6.25 | 7.25 | 1.00 | | Poster |
| 250 | Continual Learning with Recursive Gradient Optimization | 6.75 | 7.25 | 0.50 | | Spotlight |
| 251 | Evaluation Metrics for Graph Generative Models: Problems, Pitfalls, and Practical Solutions | 5.75 | 7.25 | 1.50 | | Spotlight |
| 252 | CLEVA-Compass: A Continual Learning Evaluation Assessment Compass to Promote Research Transparency and Comparability | 5.75 | 7.25 | 1.50 | | Poster |
| 253 | POETREE: Interpretable Policy Learning with Adaptive Decision Trees | 5.25 | 7.25 | 2.00 | | Spotlight |
| 254 | Differentiable Scaffolding Tree for Molecule Optimization | 7.25 | 7.25 | 0.00 | | Poster |
| 255 | Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters | 5.50 | 7.25 | 1.75 | | Spotlight |
| 256 | Transformer-based Transform Coding | 7.00 | 7.20 | 0.20 | | 8, 5, 6, 8, 8 | | 8, 6, 6, 8, 8 |
| Poster |
| 257 | Dual Lottery Ticket Hypothesis | 5.00 | 7.20 | 2.20 | | Poster |
| 258 | Reinforcement Learning with Sparse Rewards using Guidance from Offline Demonstration | 6.00 | 7.20 | 1.20 | | 6, 6, 5, 5, 8 | | 8, 6, 6, 8, 8 |
| Spotlight |
| 259 | Pix2seq: A Language Modeling Framework for Object Detection | 6.80 | 7.20 | 0.40 | | 8, 6, 6, 6, 8 | | 8, 6, 8, 6, 8 |
| Poster |
| 260 | SGD Can Converge to Local Maxima | 6.60 | 7.20 | 0.60 | | 8, 6, 8, 8, 3 | | 8, 6, 8, 8, 6 |
| Spotlight |
| 261 | Responsible Disclosure of Generative Models Using Scalable Fingerprinting | 6.40 | 7.20 | 0.80 | | 8, 8, 3, 8, 5 | | 8, 8, 6, 8, 6 |
| Spotlight |
| 262 | Natural Posterior Network: Deep Bayesian Predictive Uncertainty for Exponential Family Distributions | 5.80 | 7.20 | 1.40 | | 5, 6, 6, 6, 6 | | 6, 8, 8, 8, 6 |
| Spotlight |
| 263 | MetaMorph: Learning Universal Controllers with Transformers | 6.20 | 7.20 | 1.00 | | 8, 8, 3, 6, 6 | | 8, 8, 6, 6, 8 |
| Poster |
| 264 | Fairness in Representation for Multilingual NLP: Insights from Controlled Experiments on Conditional Language Modeling | 4.00 | 7.20 | 3.20 | | 3, 3, 6, 5, 3 | | 6, 6, 8, 8, 8 |
| Spotlight |
| 265 | SPIRAL: Self-supervised Perturbation-Invariant Representation Learning for Speech Pre-Training | 6.80 | 7.20 | 0.40 | | 6, 6, 6, 8, 8 | | 6, 6, 8, 8, 8 |
| Poster |
| 266 | Contextualized Scene Imagination for Generative Commonsense Reasoning | 5.75 | 7.00 | 1.25 | | Poster |
| 267 | Phenomenology of Double Descent in Finite-Width Neural Networks | 5.20 | 7.00 | 1.80 | | 3, 3, 6, 6, 8 | | 3, 8, 8, 8, 8 |
| Poster |
| 268 | Machine Learning For Elliptic PDEs: Fast Rate Generalization Bound, Neural Scaling Law and Minimax Optimality | 6.25 | 7.00 | 0.75 | | Poster |
| 269 | On Distributed Adaptive Optimization with Gradient Compression | 7.00 | 7.00 | 0.00 | | Poster |
| 270 | Patch-Fool: Are Vision Transformers Always Robust Against Adversarial Perturbations? | 6.25 | 7.00 | 0.75 | | Poster |
| 271 | Context-Aware Sparse Deep Coordination Graphs | 6.25 | 7.00 | 0.75 | | Spotlight |
| 272 | Robust Learning Meets Generative Models: Can Proxy Distributions Improve Adversarial Robustness? | 6.25 | 7.00 | 0.75 | | Poster |
| 273 | Multi-Stage Episodic Control for Strategic Exploration in Text Games | 6.25 | 7.00 | 0.75 | | Spotlight |
| 274 | Leveraging unlabeled data to predict out-of-distribution performance | 6.20 | 7.00 | 0.80 | | 6, 8, 6, 5, 6 | | 6, 8, 8, 5, 8 |
| Poster |
| 275 | Fortuitous Forgetting in Connectionist Networks | 6.00 | 7.00 | 1.00 | | Poster |
| 276 | A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning | 6.50 | 7.00 | 0.50 | | Poster |
| 277 | On Bridging Generic and Personalized Federated Learning for Image Classification | 5.67 | 7.00 | 1.33 | | Spotlight |
| 278 | Learning Transferable Reward for Query Object Localization with Policy Adaptation | 5.50 | 7.00 | 1.50 | | Poster |
| 279 | CoordX: Accelerating Implicit Neural Representation with a Split MLP Architecture | 6.25 | 7.00 | 0.75 | | Poster |
| 280 | Convergent Boosted Smoothing for Modeling GraphData with Tabular Node Features | 7.00 | 7.00 | 0.00 | | Spotlight |
| 281 | Revisiting Over-smoothing in BERT from the Perspective of Graph | 6.75 | 7.00 | 0.25 | | Spotlight |
| 282 | On the Uncomputability of Partition Functions in Energy-Based Sequence Models | 6.75 | 7.00 | 0.25 | | Spotlight |
| 283 | The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks | 5.75 | 7.00 | 1.25 | | Poster |
| 284 | Should I Run Offline Reinforcement Learning or Behavioral Cloning? | 5.50 | 7.00 | 1.50 | | Poster |
| 285 | Permutation-Based SGD: Is Random Optimal? | 7.00 | 7.00 | 0.00 | | Poster |
| 286 | Hindsight: Posterior-guided training of retrievers for improved open-ended generation | 6.25 | 7.00 | 0.75 | | Poster |
| 287 | Sample and Computation Redistribution for Efficient Face Detection | 7.33 | 7.00 | -0.33 | | Poster |
| 288 | Analyzing and Improving the Optimization Landscape of Noise-Contrastive Estimation | 5.67 | 7.00 | 1.33 | | Spotlight |
| 289 | Chaos is a Ladder: A New Understanding of Contrastive Learning | 5.50 | 7.00 | 1.50 | | Poster |
| 290 | Rethinking Adversarial Transferability from a Data Distribution Perspective | 6.00 | 7.00 | 1.00 | | Poster |
| 291 | High Probability Generalization Bounds for Minimax Problems with Fast Rates | 6.25 | 7.00 | 0.75 | | Poster |
| 292 | Unsupervised Semantic Segmentation by Distilling Feature Correspondences | 6.75 | 7.00 | 0.25 | | Poster |
| 293 | Is High Variance Unavoidable in RL? A Case Study in Continuous Control | 5.50 | 7.00 | 1.50 | | Poster |
| 294 | C-Planning: An Automatic Curriculum for Learning Goal-Reaching Tasks | 6.75 | 7.00 | 0.25 | | Poster |
| 295 | Variational methods for simulation-based inference | 5.50 | 7.00 | 1.50 | | Spotlight |
| 296 | Divisive Feature Normalization Improves Image Recognition Performance in AlexNet | 6.00 | 7.00 | 1.00 | | Poster |
| 297 | An Unconstrained Layer-Peeled Perspective on Neural Collapse | 6.50 | 7.00 | 0.50 | | Poster |
| 298 | Data-Driven Offline Optimization for Architecting Hardware Accelerators | 6.50 | 7.00 | 0.50 | | Poster |
| 299 | cosFormer: Rethinking Softmax In Attention | 6.25 | 7.00 | 0.75 | | Poster |
| 300 | Pessimistic Bootstrapping for Uncertainty-Driven Offline Reinforcement Learning | 6.75 | 7.00 | 0.25 | | Spotlight |
| 301 | Value Gradient weighted Model-Based Reinforcement Learning | 6.00 | 7.00 | 1.00 | | Spotlight |
| 302 | Unsupervised Discovery of Object Radiance Fields | 6.33 | 7.00 | 0.67 | | Poster |
| 303 | MonoDistill: Learning Spatial Features for Monocular 3D Object Detection | 6.40 | 7.00 | 0.60 | | 5, 6, 8, 5, 8 | | 5, 8, 8, 6, 8 |
| Poster |
| 304 | Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction | 7.00 | 7.00 | 0.00 | | Poster |
| 305 | Phase Collapse in Neural Networks | 5.75 | 7.00 | 1.25 | | Poster |
| 306 | Coherence-based Label Propagation over Time Series for Accelerated Active Learning | 7.00 | 7.00 | 0.00 | | Poster |
| 307 | Differentially Private Fractional Frequency Moments Estimation with Polylogarithmic Space | 6.50 | 7.00 | 0.50 | | Poster |
| 308 | MCMC Should Mix: Learning Energy-Based Model with Flow-Based Backbone | 6.00 | 7.00 | 1.00 | | Poster |
| 309 | Spanning Tree-based Graph Generation for Molecules | 5.75 | 7.00 | 1.25 | | Spotlight |
| 310 | COptiDICE: Offline Constrained Reinforcement Learning via Stationary Distribution Correction Estimation | 5.50 | 7.00 | 1.50 | | Spotlight |
| 311 | Gradient Information Matters in Policy Optimization by Back-propagating through Model | 4.50 | 7.00 | 2.50 | | Poster |
| 312 | Multi-objective Optimization by Learning Space Partition | 6.75 | 7.00 | 0.25 | | Poster |
| 313 | Equivariant Subgraph Aggregation Networks | 6.25 | 7.00 | 0.75 | | Spotlight |
| 314 | Churn Reduction via Distillation | 7.00 | 7.00 | 0.00 | | Spotlight |
| 315 | Spherical Message Passing for 3D Molecular Graphs | 5.67 | 7.00 | 1.33 | | Poster |
| 316 | AEVA: Black-box Backdoor Detection Using Adversarial Extreme Value Analysis | 5.75 | 7.00 | 1.25 | | Poster |
| 317 | Improved deterministic l2 robustness on CIFAR-10 and CIFAR-100 | 6.25 | 7.00 | 0.75 | | Spotlight |
| 318 | When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations | 5.50 | 7.00 | 1.50 | | Spotlight |
| 319 | PF-GNN: Differentiable particle filtering based approximation of universal graph representations | 6.25 | 7.00 | 0.75 | | Poster |
| 320 | LoRA: Low-Rank Adaptation of Large Language Models | 6.00 | 7.00 | 1.00 | | Poster |
| 321 | EE-Net: Exploitation-Exploration Neural Networks in Contextual Bandits | 6.25 | 7.00 | 0.75 | | Spotlight |
| 322 | Scarf: Self-Supervised Contrastive Learning using Random Feature Corruption | 6.25 | 7.00 | 0.75 | | Spotlight |
| 323 | Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners | 6.50 | 7.00 | 0.50 | | Poster |
| 324 | Bootstrapping Semantic Segmentation with Regional Contrast | 5.50 | 7.00 | 1.50 | | Poster |
| 325 | Learning with Noisy Labels Revisited: A Study Using Real-World Human Annotations | 6.00 | 7.00 | 1.00 | | Poster |
| 326 | Direct then Diffuse: Incremental Unsupervised Skill Discovery for State Covering and Goal Reaching | 6.75 | 7.00 | 0.25 | | Poster |
| 327 | Message Passing Neural PDE Solvers | 6.25 | 7.00 | 0.75 | | Spotlight |
| 328 | Efficient Active Search for Combinatorial Optimization Problems | 7.00 | 7.00 | 0.00 | | Poster |
| 329 | Pyraformer: Low-Complexity Pyramidal Attention for Long-Range Time Series Modeling and Forecasting | 6.00 | 7.00 | 1.00 | | Oral |
| 330 | The MultiBERTs: BERT Reproductions for Robustness Analysis | 7.33 | 7.00 | -0.33 | | Spotlight |
| 331 | Energy-Based Learning for Cooperative Games, with Applications to Valuation Problems in Machine Learning | 7.00 | 7.00 | 0.00 | | Poster |
| 332 | Minimax Optimization with Smooth Algorithmic Adversaries | 7.00 | 7.00 | 0.00 | | Poster |
| 333 | Compositional Attention: Disentangling Search and Retrieval | 5.67 | 7.00 | 1.33 | | Spotlight |
| 334 | When should agents explore? | 7.00 | 7.00 | 0.00 | | Spotlight |
| 335 | Domain Adversarial Training: A Game Perspective | 7.00 | 7.00 | 0.00 | | Poster |
| 336 | Contrastive Fine-grained Class Clustering via Generative Adversarial Networks | 6.25 | 7.00 | 0.75 | | Spotlight |
| 337 | Conditional Object-Centric Learning from Video | 6.50 | 7.00 | 0.50 | | Poster |
| 338 | Visual Correspondence Hallucination | 7.00 | 7.00 | 0.00 | | Poster |
| 339 | Learning Disentangled Representation by Exploiting Pretrained Generative Models: A Contrastive Learning View | 6.25 | 7.00 | 0.75 | | Poster |
| 340 | NODE-GAM: Neural Generalized Additive Model for Interpretable Deep Learning | 5.33 | 7.00 | 1.67 | | Spotlight |
| 341 | Geometric and Physical Quantities improve E(3) Equivariant Message Passing | 6.33 | 7.00 | 0.67 | | 10, 6, 6, 6, 5, 5 | | 10, 6, 8, 6, 6, 6 |
| Spotlight |
| 342 | GreaseLM: Graph REASoning Enhanced Language Models | 6.00 | 7.00 | 1.00 | | Spotlight |
| 343 | Neural Relational Inference with Node-Specific Information | 6.33 | 7.00 | 0.67 | | Poster |
| 344 | D-CODE: Discovering Closed-form ODEs from Observed Trajectories | 6.50 | 7.00 | 0.50 | | Spotlight |
| 345 | Learned Simulators for Turbulence | 6.00 | 7.00 | 1.00 | | Poster |
| 346 | Active Hierarchical Exploration with Stable Subgoal Representation Learning | 6.25 | 7.00 | 0.75 | | Poster |
| 347 | On the Limitations of Multimodal VAEs | 6.25 | 7.00 | 0.75 | | Poster |
| 348 | Embedded-model flows: Combining the inductive biases of model-free deep learning and explicit probabilistic modeling | 5.50 | 7.00 | 1.50 | | Poster |
| 349 | Filling the G_ap_s: Multivariate Time Series Imputation by Graph Neural Networks | 6.75 | 7.00 | 0.25 | | Poster |
| 350 | Shuffle Private Stochastic Convex Optimization | 6.00 | 7.00 | 1.00 | | Poster |
| 351 | Self-Joint Supervised Learning | 7.00 | 7.00 | 0.00 | | Poster |
| 352 | SO(2)-Equivariant Reinforcement Learning | 6.60 | 7.00 | 0.40 | | 5, 6, 6, 8, 8 | | 5, 6, 8, 8, 8 |
| Spotlight |
| 353 | Anomaly Detection for Tabular Data with Internal Contrastive Learning | 5.67 | 7.00 | 1.33 | | Poster |
| 354 | On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning | 7.00 | 7.00 | 0.00 | | Spotlight |
| 355 | A Reduction-Based Framework for Conservative Bandits and Reinforcement Learning | 5.75 | 7.00 | 1.25 | | Poster |
| 356 | Long Expressive Memory for Sequence Modeling | 6.25 | 7.00 | 0.75 | | Spotlight |
| 357 | Procedural generalization by planning with self-supervised world models | 6.75 | 7.00 | 0.25 | | Poster |
| 358 | Who Is Your Right Mixup Partner in Positive and Unlabeled Learning | 6.75 | 7.00 | 0.25 | | Poster |
| 359 | Ancestral protein sequence reconstruction using a tree-structured Ornstein-Uhlenbeck variational autoencoder | 6.00 | 7.00 | 1.00 | | Poster |
| 360 | Learning Towards The Largest Margins | 6.75 | 7.00 | 0.25 | | Poster |
| 361 | DR3: Value-Based Deep Reinforcement Learning Requires Explicit Regularization | 5.75 | 7.00 | 1.25 | | Spotlight |
| 362 | Graph-Augmented Normalizing Flows for Anomaly Detection of Multiple Time Series | 5.50 | 7.00 | 1.50 | | Spotlight |
| 363 | CURVATURE-GUIDED DYNAMIC SCALE NETWORKS FOR MULTI-VIEW STEREO | 5.00 | 7.00 | 2.00 | | Poster |
| 364 | Stochastic Training is Not Necessary for Generalization | 5.80 | 7.00 | 1.20 | | 5, 3, 8, 8, 5 | | 6, 5, 8, 10, 6 |
| Poster |
| 365 | Sqrt(d) Dimension Dependence of Langevin Monte Carlo | 7.00 | 7.00 | 0.00 | | Poster |
| 366 | The Geometry of Memoryless Stochastic Policy Optimization in Infinite-Horizon POMDPs | 6.50 | 7.00 | 0.50 | | Poster |
| 367 | GiraffeDet: A Heavy-Neck Paradigm for Object Detection | 6.00 | 7.00 | 1.00 | | Poster |
| 368 | Joint Shapley values: a measure of joint feature importance | 7.00 | 7.00 | 0.00 | | Poster |
| 369 | Deep ReLU Networks Preserve Expected Length | 6.25 | 7.00 | 0.75 | | Poster |
| 370 | Resolving Training Biases via Influence-based Data Relabeling | 5.75 | 7.00 | 1.25 | | Oral |
| 371 | Noisy Feature Mixup | 7.00 | 7.00 | 0.00 | | Poster |
| 372 | Neural Collapse Under MSE Loss: Proximity to and Dynamics on the Central Path | 6.00 | 7.00 | 1.00 | | Oral |
| 373 | Online Hyperparameter Meta-Learning with Hypergradient Distillation | 7.00 | 7.00 | 0.00 | | Spotlight |
| 374 | Learning Hierarchical Structures with Differentiable Nondeterministic Stacks | 6.75 | 7.00 | 0.25 | | Spotlight |
| 375 | Random matrices in service of ML footprint: ternary random features with no performance loss | 6.25 | 7.00 | 0.75 | | Poster |
| 376 | Distributionally Robust Models with Parametric Likelihood Ratios | 6.50 | 7.00 | 0.50 | | Poster |
| 377 | You are AllSet: A Multiset Function Framework for Hypergraph Neural Networks | 6.25 | 7.00 | 0.75 | | Poster |
| 378 | NASPY: Automated Extraction of Automated Machine Learning Models | 7.00 | 7.00 | 0.00 | | Spotlight |
| 379 | A generalization of the randomized singular value decomposition | 6.33 | 7.00 | 0.67 | | Poster |
| 380 | Equivariant Transformers for Neural Network based Molecular Potentials | 6.25 | 7.00 | 0.75 | | Spotlight |
| 381 | Generalization of Overparametrized Deep Neural Network Under Noisy Observations | 6.25 | 7.00 | 0.75 | | Poster |
| 382 | Chemical-Reaction-Aware Molecule Representation Learning | 6.00 | 7.00 | 1.00 | | Poster |
| 383 | Offline Reinforcement Learning with Value-based Episodic Memory | 5.25 | 6.83 | 1.58 | | 5, 6, 5, 5 | | 6, 8, 6, 5, 8, 8 |
| Poster |
| 384 | How Does SimSiam Avoid Collapse Without Negative Samples? Towards a Unified Understanding of Progress in SSL | 6.20 | 6.80 | 0.60 | | 8, 5, 5, 5, 8 | | 8, 6, 6, 6, 8 |
| Poster |
| 385 | Tracking the risk of a deployed model and detecting harmful distribution shifts | 5.80 | 6.80 | 1.00 | | 6, 6, 6, 5, 6 | | 6, 8, 6, 6, 8 |
| Poster |
| 386 | Equivariant and Stable Positional Encoding for More Powerful Graph Neural Networks | 6.60 | 6.80 | 0.20 | | 8, 8, 6, 6, 5 | | 8, 8, 6, 6, 6 |
| Poster |
| 387 | Latent Image Animator: Learning to animate image via latent space navigation | 6.80 | 6.80 | 0.00 | | 8, 6, 6, 6, 8 | | 8, 6, 6, 6, 8 |
| Poster |
| 388 | Finite-Time Convergence and Sample Complexity of Multi-Agent Actor-Critic Reinforcement Learning with Average Reward | 5.60 | 6.80 | 1.20 | | 6, 5, 6, 6, 5 | | 6, 6, 8, 8, 6 |
| Spotlight |
| 389 | On the Certified Robustness for Ensemble Models and Beyond | 6.20 | 6.80 | 0.60 | | 5, 6, 6, 6, 8 | | 6, 8, 6, 6, 8 |
| Poster |
| 390 | Multi-Critic Actor Learning: Teaching RL Policies to Act with Style | 5.00 | 6.80 | 1.80 | | 8, 3, 3, 6, 5 | | 8, 6, 6, 8, 6 |
| Poster |
| 391 | Revisiting Design Choices in Offline Model Based Reinforcement Learning | 5.40 | 6.80 | 1.40 | | 8, 5, 6, 3, 5 | | 8, 6, 8, 6, 6 |
| Spotlight |
| 392 | Learning Altruistic Behaviours in Reinforcement Learning without External Rewards | 6.00 | 6.80 | 0.80 | | 8, 6, 6, 5, 5 | | 8, 6, 8, 6, 6 |
| Spotlight |
| 393 | Learning to Generalize across Domains on Single Test Samples | 5.80 | 6.80 | 1.00 | | 5, 5, 6, 5, 8 | | 5, 8, 8, 5, 8 |
| Poster |
| 394 | Reinforcement Learning in Presence of Discrete Markovian Context Evolution | 6.40 | 6.80 | 0.40 | | 5, 6, 5, 8, 8 | | 6, 6, 6, 8, 8 |
| Poster |
| 395 | GNN is a Counter? Revisiting GNN for Question Answering | 6.25 | 6.75 | 0.50 | | Poster |
| 396 | Peek-a-Boo: What (More) is Disguised in a Randomly Weighted Neural Network, and How to Find It Efficiently | 6.50 | 6.75 | 0.25 | | Poster |
| 397 | Pareto Policy Pool for Model-based Offline Reinforcement Learning | 5.25 | 6.75 | 1.50 | | Poster |
| 398 | Sparsity Winning Twice: Better Robust Generalization from More Efficient Training | 5.75 | 6.75 | 1.00 | | Poster |
| 399 | Deep AutoAugment | 5.50 | 6.75 | 1.25 | | Poster |
| 400 | BAM: Bayes Augmented with Memory | 6.50 | 6.75 | 0.25 | | Poster |
| 401 | Large Learning Rate Tames Homogeneity: Convergence and Balancing Effect | 5.25 | 6.75 | 1.50 | | Poster |
| 402 | FALCON: Fast Visual Concept Learning by Integrating Images, Linguistic descriptions, and Conceptual Relations | 6.25 | 6.75 | 0.50 | | Poster |
| 403 | On the Learning of Quasimetrics | 6.25 | 6.75 | 0.50 | | Poster |
| 404 | Synchromesh: Reliable Code Generation from Pre-trained Language Models | 6.25 | 6.75 | 0.50 | | Poster |
| 405 | Adversarial Support Alignment | 6.00 | 6.75 | 0.75 | | Spotlight |
| 406 | Learning Object-Oriented Dynamics for Planning from Text | 6.75 | 6.75 | 0.00 | | Poster |
| 407 | How to Train Your MAML to Excel in Few-Shot Classification | 6.25 | 6.75 | 0.50 | | Poster |
| 408 | A Fine-Tuning Approach to Belief State Modeling | 5.00 | 6.75 | 1.75 | | Poster |
| 409 | Path Integral Sampler: A Stochastic Control Approach For Sampling | 6.75 | 6.75 | 0.00 | | Poster |
| 410 | DIVA: Dataset Derivative of a Learning Task | 7.00 | 6.75 | -0.25 | | Poster |
| 411 | A First-Occupancy Representation for Reinforcement Learning | 6.75 | 6.75 | 0.00 | | Poster |
| 412 | Towards Unknown-aware Learning with Virtual Outlier Synthesis | 5.75 | 6.75 | 1.00 | | Poster |
| 413 | Amortized Tree Generation for Bottom-up Synthesis Planning and Synthesizable Molecular Design | 4.25 | 6.75 | 2.50 | | Spotlight |
| 414 | Improving Non-Autoregressive Translation Models Without Distillation | 6.25 | 6.75 | 0.50 | | Poster |
| 415 | Learning Neural Contextual Bandits through Perturbed Rewards | 5.75 | 6.75 | 1.00 | | Poster |
| 416 | Better Supervisory Signals by Observing Learning Paths | 4.75 | 6.75 | 2.00 | | Poster |
| 417 | Constrained Graph Mechanics Networks | 5.00 | 6.75 | 1.75 | | Poster |
| 418 | Dynamics-Aware Comparison of Learned Reward Functions | 6.00 | 6.75 | 0.75 | | Spotlight |
| 419 | Model-augmented Prioritized Experience Replay | 6.75 | 6.75 | 0.00 | | Poster |
| 420 | Enhancing Cross-lingual Transfer by Manifold Mixup | 5.75 | 6.75 | 1.00 | | Poster |
| 421 | Implicit Bias of Projected Subgradient Method Gives Provable Robust Recovery of Subspaces of Unknown Codimension | 6.75 | 6.75 | 0.00 | | Spotlight |
| 422 | Knowledge Removal in Sampling-based Bayesian Inference | 6.75 | 6.75 | 0.00 | | Poster |
| 423 | Mapping Language Models to Grounded Conceptual Spaces | 6.75 | 6.75 | 0.00 | | Poster |
| 424 | A Unified Contrastive Energy-based Model for Understanding the Generative Ability of Adversarial Training | 6.75 | 6.75 | 0.00 | | Poster |
| 425 | Proving the Lottery Ticket Hypothesis for Convolutional Neural Networks | 5.33 | 6.75 | 1.42 | | Poster |
| 426 | Online Target Q-learning with Reverse Experience Replay: Efficiently finding the Optimal Policy for Linear MDPs | 6.00 | 6.75 | 0.75 | | Poster |
| 427 | Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games | 6.75 | 6.75 | 0.00 | | Poster |
| 428 | Multiset-Equivariant Set Prediction with Approximate Implicit Differentiation | 5.75 | 6.75 | 1.00 | | Poster |
| 429 | SketchODE: Learning neural sketch representation in continuous time | 6.25 | 6.75 | 0.50 | | Poster |
| 430 | Sound and Complete Neural Network Repair with Minimality and Locality Guarantees | 6.00 | 6.75 | 0.75 | | Poster |
| 431 | Scene Transformer: A unified architecture for predicting future trajectories of multiple agents | 6.00 | 6.75 | 0.75 | | Poster |
| 432 | Learning Efficient Image Super-Resolution Networks via Structure-Regularized Pruning | 6.75 | 6.75 | 0.00 | | Poster |
| 433 | ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning | 5.75 | 6.75 | 1.00 | | Poster |
| 434 | Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory | 5.25 | 6.75 | 1.50 | | Poster |
| 435 | Geometry-Consistent Neural Shape Representation with Implicit Displacement Fields | 6.75 | 6.75 | 0.00 | | Poster |
| 436 | Unrolling PALM for Sparse Semi-Blind Source Separation | 4.25 | 6.75 | 2.50 | | Poster |
| 437 | Generalized rectifier wavelet covariance models for texture synthesis | 5.33 | 6.75 | 1.42 | | Poster |
| 438 | Representation Learning for Online and Offline RL in Low-rank MDPs | 5.50 | 6.75 | 1.25 | | Spotlight |
| 439 | Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity | 6.75 | 6.75 | 0.00 | | Poster |
| 440 | Learning to Remember Patterns: Pattern Matching Memory Networks for Traffic Forecasting | 5.50 | 6.75 | 1.25 | | Poster |
| 441 | Leveraging Automated Unit Tests for Unsupervised Code Translation | 6.75 | 6.75 | 0.00 | | Spotlight |
| 442 | Post-Training Detection of Backdoor Attacks for Two-Class and Multi-Attack Scenarios | 6.50 | 6.75 | 0.25 | | Poster |
| 443 | Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning | 5.75 | 6.75 | 1.00 | | Poster |
| 444 | A Loss Curvature Perspective on Training Instabilities of Deep Learning Models | 6.75 | 6.75 | 0.00 | | Poster |
| 445 | Surreal-GAN:Semi-Supervised Representation Learning via GAN for uncovering heterogeneous disease-related imaging patterns | 6.00 | 6.75 | 0.75 | | Poster |
| 446 | Actor-Critic Policy Optimization in a Large-Scale Imperfect-Information Game | 4.50 | 6.75 | 2.25 | | Poster |
| 447 | Adversarially Robust Conformal Prediction | 6.75 | 6.75 | 0.00 | | Poster |
| 448 | Topological Experience Replay | 5.50 | 6.75 | 1.25 | | Poster |
| 449 | Learning 3D Representations of Molecular Chirality with Invariance to Bond Rotations | 5.75 | 6.75 | 1.00 | | Poster |
| 450 | NodePiece: Compositional and Parameter-Efficient Representations of Large Knowledge Graphs | 5.75 | 6.75 | 1.00 | | Poster |
| 451 | Contrastive Clustering to Mine Pseudo Parallel Data for Unsupervised Translation | 6.75 | 6.75 | 0.00 | | Poster |
| 452 | Exploring Memorization in Adversarial Training | 6.33 | 6.75 | 0.42 | | Poster |
| 453 | Learning to Complete Code with Sketches | 6.75 | 6.75 | 0.00 | | Poster |
| 454 | miniF2F: a cross-system benchmark for formal Olympiad-level mathematics | 6.75 | 6.75 | 0.00 | | Poster |
| 455 | On Non-Random Missing Labels in Semi-Supervised Learning | 6.67 | 6.67 | 0.00 | | Poster |
| 456 | Invariant Causal Representation Learning for Out-of-Distribution Generalization | 6.33 | 6.67 | 0.33 | | Poster |
| 457 | Mind the Gap: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks | 6.67 | 6.67 | 0.00 | | Poster |
| 458 | Provably Robust Adversarial Examples | 5.33 | 6.67 | 1.33 | | Poster |
| 459 | Image BERT Pre-training with Online Tokenizer | 6.00 | 6.67 | 0.67 | | Poster |
| 460 | SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations | 5.67 | 6.67 | 1.00 | | Poster |
| 461 | Solving Inverse Problems in Medical Imaging with Score-Based Generative Models | 5.67 | 6.67 | 1.00 | | Poster |
| 462 | TRAIL: Near-Optimal Imitation Learning with Suboptimal Data | 5.67 | 6.67 | 1.00 | | Poster |
| 463 | Automatic Loss Function Search for Predict-Then-Optimize Problems with Strong Ranking Property | 6.00 | 6.67 | 0.67 | | Poster |
| 464 | Toward Faithful Case-based Reasoning through Learning Prototypes in a Nearest Neighbor-friendly Space. | 6.00 | 6.67 | 0.67 | | Poster |
| 465 | The Convex Geometry of Backpropagation: Neural Network Gradient Flows Converge to Extreme Points of the Dual Convex Program | 6.33 | 6.67 | 0.33 | | Poster |
| 466 | Triangle and Four Cycle Counting with Predictions in Graph Streams | 6.00 | 6.67 | 0.67 | | Poster |
| 467 | Sequence Approximation using Feedforward Spiking Neural Network for Spatiotemporal Learning: Theory and Optimization Methods | 4.67 | 6.67 | 2.00 | | Poster |
| 468 | RelViT: Concept-guided Vision Transformer for Visual Relational Reasoning | 6.33 | 6.67 | 0.33 | | Poster |
| 469 | Neural Variational Dropout Processes | 6.67 | 6.67 | 0.00 | | Poster |
| 470 | Efficient Token Mixing for Transformers via Adaptive Fourier Neural Operators | 5.67 | 6.67 | 1.00 | | Poster |
| 471 | Properties from mechanisms: an equivariance perspective on identifiable representation learning | 6.67 | 6.67 | 0.00 | | Spotlight |
| 472 | Safe Neurosymbolic Learning with Differentiable Symbolic Execution | 5.33 | 6.67 | 1.33 | | Poster |
| 473 | Reverse Engineering of Imperceptible Adversarial Image Perturbations | 5.33 | 6.67 | 1.33 | | Poster |
| 474 | VC dimension of partially quantized neural networks in the overparametrized regime | 5.67 | 6.67 | 1.00 | | Poster |
| 475 | Multimeasurement Generative Models | 6.67 | 6.67 | 0.00 | | Poster |
| 476 | Towards Understanding the Robustness Against Evasion Attack on Categorical Data | 5.00 | 6.67 | 1.67 | | Poster |
| 477 | Zero Pixel Directional Boundary by Vector Transform | 6.67 | 6.67 | 0.00 | | Poster |
| 478 | Label Leakage and Protection in Two-party Split Learning | 6.00 | 6.67 | 0.67 | | Poster |
| 479 | BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis | 5.67 | 6.67 | 1.00 | | Poster |
| 480 | Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework | 6.33 | 6.67 | 0.33 | | Poster |
| 481 | Spatial Graph Attention and Curiosity-driven Policy for Antiviral Drug Discovery | 6.00 | 6.67 | 0.67 | | Poster |
| 482 | High Probability Bounds for a Class of Nonconvex Algorithms with AdaGrad Stepsize | 6.50 | 6.67 | 0.17 | | Poster |
| 483 | Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction | 5.67 | 6.67 | 1.00 | | Poster |
| 484 | Omni-Scale CNNs: a simple and effective kernel size configuration for time series classification | 5.67 | 6.67 | 1.00 | | Poster |
| 485 | Practical Conditional Neural Process Via Tractable Dependent Predictions | 6.00 | 6.67 | 0.67 | | Poster |
| 486 | Hybrid Memoised Wake-Sleep: Approximate Inference at the Discrete-Continuous Interface | 6.33 | 6.67 | 0.33 | | Poster |
| 487 | Optimal Transport for Causal Discovery | 6.33 | 6.67 | 0.33 | | Spotlight |
| 488 | Dive Deeper Into Integral Pose Regression | 5.67 | 6.67 | 1.00 | | Poster |
| 489 | Information Bottleneck: Exact Analysis of (Quantized) Neural Networks | 6.33 | 6.67 | 0.33 | | Poster |
| 490 | A Class of Short-term Recurrence Anderson Mixing Methods and Their Applications | 6.00 | 6.67 | 0.67 | | Poster |
| 491 | SimVLM: Simple Visual Language Model Pretraining with Weak Supervision | 6.33 | 6.67 | 0.33 | | Poster |
| 492 | Privacy Implications of Shuffling | 6.67 | 6.67 | 0.00 | | Poster |
| 493 | End-to-End Learning of Probabilistic Hierarchies on Graphs | 7.00 | 6.67 | -0.33 | | Poster |
| 494 | GradSign: Model Performance Inference with Theoretical Insights | 6.00 | 6.67 | 0.67 | | Poster |
| 495 | X-model: Improving Data Efficiency in Deep Learning with A Minimax Model | 6.33 | 6.67 | 0.33 | | Poster |
| 496 | Learning Versatile Neural Architectures by Propagating Network Codes | 6.67 | 6.67 | 0.00 | | Poster |
| 497 | Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph | 6.67 | 6.67 | 0.00 | | Poster |
| 498 | Half-Inverse Gradients for Physical Deep Learning | 6.33 | 6.67 | 0.33 | | Spotlight |
| 499 | Entroformer: A Transformer-based Entropy Model for Learned Image Compression | 6.67 | 6.67 | 0.00 | | Poster |
| 500 | Uncertainty Modeling for Out-of-Distribution Generalization | 6.67 | 6.67 | 0.00 | | Poster |
| 501 | Online Facility Location with Predictions | 6.17 | 6.67 | 0.50 | | 6, 6, 6, 8, 5, 6 | | 6, 6, 6, 8, 6, 8 |
| Poster |
| 502 | PEARL: Data Synthesis via Private Embeddings and Adversarial Reconstruction Learning | 6.33 | 6.67 | 0.33 | | Poster |
| 503 | Do Not Escape From the Manifold: Discovering the Local Coordinates on the Latent Space of GANs | 5.67 | 6.67 | 1.00 | | Poster |
| 504 | When, Why, and Which Pretrained GANs Are Useful? | 6.67 | 6.67 | 0.00 | | Poster |
| 505 | Beyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains | 5.67 | 6.67 | 1.00 | | Poster |
| 506 | Inverse Online Learning: Understanding Non-Stationary and Reactionary Policies | 5.67 | 6.67 | 1.00 | | Poster |
| 507 | Looking Back on Learned Experiences For Class/task Incremental Learning | 5.67 | 6.67 | 1.00 | | Spotlight |
| 508 | Temporal Alignment Prediction for Supervised Representation Learning and Few-Shot Sequence Classification | 5.33 | 6.67 | 1.33 | | Poster |
| 509 | Steerable Partial Differential Operators for Equivariant Neural Networks | 6.33 | 6.67 | 0.33 | | Poster |
| 510 | NETWORK INSENSITIVITY TO PARAMETER NOISE VIA PARAMETER ATTACK DURING TRAINING | 6.33 | 6.67 | 0.33 | | Poster |
| 511 | P-Adapters: Robustly Extracting Factual Information from Language Models with Diverse Prompts | 6.00 | 6.60 | 0.60 | | 5, 8, 3, 6, 8 | | 6, 8, 5, 6, 8 |
| Poster |
| 512 | Learning meta-features for AutoML | 5.00 | 6.60 | 1.60 | | 3, 3, 8, 6, 5 | | 8, 6, 8, 6, 5 |
| Spotlight |
| 513 | A Unified Wasserstein Distributional Robustness Framework for Adversarial Training | 6.60 | 6.60 | 0.00 | | 6, 6, 8, 5, 8 | | 6, 6, 8, 5, 8 |
| Poster |
| 514 | Sample Selection with Uncertainty of Losses for Learning with Noisy Labels | 6.60 | 6.60 | 0.00 | | 6, 8, 6, 8, 5 | | 6, 8, 6, 8, 5 |
| Poster |
| 515 | Towards Better Understanding and Better Generalization of Low-shot Classification in Histology Images with Contrastive Learning | 6.40 | 6.60 | 0.20 | | 5, 8, 8, 5, 6 | | 6, 8, 8, 5, 6 |
| Poster |
| 516 | Trigger Hunting with a Topological Prior for Trojan Detection | 6.00 | 6.50 | 0.50 | | Poster |
| 517 | Optimizing Few-Step Diffusion Samplers by Gradient Descent | 5.50 | 6.50 | 1.00 | | Poster |
| 518 | Fast AdvProp | 6.50 | 6.50 | 0.00 | | Poster |
| 519 | Learning Temporally Latent Causal Processes from General Temporal Data | 5.33 | 6.50 | 1.17 | | Poster |
| 520 | Skill-based Meta-Reinforcement Learning | 5.50 | 6.50 | 1.00 | | Poster |
| 521 | Understanding Intrinsic Robustness Using Label Uncertainty | 6.25 | 6.50 | 0.25 | | Poster |
| 522 | From Stars to Subgraphs: Uplifting Any GNN with Local Structure Awareness | 5.50 | 6.50 | 1.00 | | Poster |
| 523 | Efficient Learning of Safe Driving Policy via Human-AI Copilot Optimization | 6.25 | 6.50 | 0.25 | | Poster |
| 524 | Cross-Domain Imitation Learning via Optimal Transport | 6.25 | 6.50 | 0.25 | | Poster |
| 525 | Particle Stochastic Dual Coordinate Ascent: Exponential convergent algorithm for mean field neural network optimization | 6.00 | 6.50 | 0.50 | | Poster |
| 526 | Bi-linear Value Networks for Multi-goal Reinforcement Learning | 5.50 | 6.50 | 1.00 | | Poster |
| 527 | Explaining Point Processes by Learning Interpretable Temporal Logic Rules | 5.75 | 6.50 | 0.75 | | Poster |
| 528 | β-Intact-VAE: Identifying and Estimating Causal Effects under Limited Overlap | 6.25 | 6.50 | 0.25 | | Poster |
| 529 | Shallow and Deep Networks are Near-Optimal Approximators of Korobov Functions | 6.25 | 6.50 | 0.25 | | Poster |
| 530 | On Evaluation Metrics for Graph Generative Models | 4.75 | 6.50 | 1.75 | | Poster |
| 531 | How Did the Model Change? Efficiently Assessing Machine Learning API Shifts | 6.50 | 6.50 | 0.00 | | Poster |
| 532 | Learning Prototype-oriented Set Representations for Meta-Learning | 6.25 | 6.50 | 0.25 | | Poster |
| 533 | Feature Kernel Distillation | 5.75 | 6.50 | 0.75 | | Poster |
| 534 | The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models | 5.75 | 6.50 | 0.75 | | Poster |
| 535 | What Do We Mean by Generalization in Federated Learning? | 5.00 | 6.50 | 1.50 | | Poster |
| 536 | Learning Curves for Gaussian Process Regression with Power-Law Priors and Targets | 4.75 | 6.50 | 1.75 | | Poster |
| 537 | Few-shot Learning via Dirichlet Tessellation Ensemble | 6.25 | 6.50 | 0.25 | | Poster |
| 538 | Is Fairness Only Metric Deep? Evaluating and Addressing Subgroup Gaps in Deep Metric Learning | 6.00 | 6.50 | 0.50 | | Poster |
| 539 | On the relation between statistical learning and perceptual distances | 5.50 | 6.50 | 1.00 | | Spotlight |
| 540 | A Program to Build E(N)-Equivariant Steerable CNNs | 6.00 | 6.50 | 0.50 | | Poster |
| 541 | Variational Predictive Routing with Nested Subjective Timescales | 5.50 | 6.50 | 1.00 | | Poster |
| 542 | Eigencurve: Optimal Learning Rate Schedule for SGD on Quadratic Objectives with Skewed Hessian Spectrums | 4.75 | 6.50 | 1.75 | | Poster |
| 543 | PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions | 6.00 | 6.50 | 0.50 | | Poster |
| 544 | Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm | 6.00 | 6.50 | 0.50 | | Poster |
| 545 | Equivariant Self-Supervised Learning: Encouraging Equivariance in Representations | 5.25 | 6.50 | 1.25 | | Poster |
| 546 | Map Induction: Compositional spatial submap learning for efficient exploration in novel environments | 5.25 | 6.50 | 1.25 | | Poster |
| 547 | Capacity of Group-invariant Linear Readouts from Equivariant Representations: How Many Objects can be Linearly Classified Under All Possible Views? | 6.25 | 6.50 | 0.25 | | Poster |
| 548 | Surrogate Gap Minimization Improves Sharpness-Aware Training | 5.75 | 6.50 | 0.75 | | Poster |
| 549 | SQuant: On-the-Fly Data-Free Quantization via Diagonal Hessian Approximation | 6.67 | 6.50 | -0.17 | | Poster |
| 550 | Efficient and Differentiable Conformal Prediction with General Function Classes | 6.25 | 6.50 | 0.25 | | Poster |
| 551 | Declarative nets that are equilibrium models | 6.00 | 6.50 | 0.50 | | Poster |
| 552 | Capturing Structural Locality in Non-parametric Language Models | 5.75 | 6.50 | 0.75 | | Poster |
| 553 | IFR-Explore: Learning Inter-object Functional Relationships in 3D Indoor Scenes | 6.67 | 6.50 | -0.17 | | Poster |
| 554 | DEGREE: Decomposition Based Explanation for Graph Neural Networks | 6.00 | 6.50 | 0.50 | | Poster |
| 555 | Modular Lifelong Reinforcement Learning via Neural Composition | 5.25 | 6.50 | 1.25 | | Poster |
| 556 | Anisotropic Random Feature Regression in High Dimensions | 5.00 | 6.50 | 1.50 | | Poster |
| 557 | Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators | 6.17 | 6.50 | 0.33 | | 6, 8, 6, 6, 3, 8 | | 8, 8, 6, 6, 3, 8 |
| Poster |
| 558 | Understanding and Improving Graph Injection Attack by Promoting Unnoticeability | 6.25 | 6.50 | 0.25 | | Poster |
| 559 | Huber Additive Models for Non-stationary Time Series Analysis | 6.00 | 6.50 | 0.50 | | Poster |
| 560 | What Makes Better Augmentation Strategies? Augment Difficult but Not too Different | 5.75 | 6.50 | 0.75 | | Poster |
| 561 | Lipschitz-constrained Unsupervised Skill Discovery | 6.25 | 6.50 | 0.25 | | Poster |
| 562 | Temporal Efficient Training of Spiking Neural Network via Gradient Re-weighting | 5.25 | 6.50 | 1.25 | | Poster |
| 563 | FlexConv: Continuous Kernel Convolutions With Differentiable Kernel Sizes | 5.75 | 6.50 | 0.75 | | Poster |
| 564 | Backdoor Defense via Decoupling the Training Process | 6.25 | 6.50 | 0.25 | | Poster |
| 565 | Bayesian Framework for Gradient Leakage | 5.75 | 6.50 | 0.75 | | Poster |
| 566 | On the Convergence of the Monte Carlo Exploring Starts Algorithm for Reinforcement Learning | 6.50 | 6.50 | 0.00 | | Poster |
| 567 | Parallel Training of GRU Networks with a Multi-Grid Solver for Long Sequences | 6.25 | 6.50 | 0.25 | | Poster |
| 568 | Learning to Annotate Part Segmentation with Gradient Matching | 5.50 | 6.50 | 1.00 | | Poster |
| 569 | Predicting Physics in Mesh-reduced Space with Temporal Attention | 6.00 | 6.50 | 0.50 | | Poster |
| 570 | Online Ad Hoc Teamwork under Partial Observability | 6.50 | 6.50 | 0.00 | | Poster |
| 571 | On Incorporating Inductive Biases into VAEs | 6.25 | 6.50 | 0.25 | | Poster |
| 572 | Understanding the Variance Collapse of SVGD in High Dimensions | 6.50 | 6.50 | 0.00 | | Poster |
| 573 | Optimizing Neural Networks with Gradient Lexicase Selection | 5.25 | 6.50 | 1.25 | | Poster |
| 574 | Confidence Adaptive Anytime Pixel-Level Recognition | 6.00 | 6.50 | 0.50 | | Poster |
| 575 | How many degrees of freedom do we need to train deep networks: a loss landscape perspective | 6.50 | 6.50 | 0.00 | | Poster |
| 576 | Differentially Private Fine-tuning of Language Models | 6.00 | 6.50 | 0.50 | | Poster |
| 577 | Proof Artifact Co-Training for Theorem Proving with Language Models | 6.50 | 6.50 | 0.00 | | Poster |
| 578 | Frequency-aware SGD for Efficient Embedding Learning with Provable Benefits | 6.25 | 6.50 | 0.25 | | Poster |
| 579 | Preference Conditioned Neural Multi-objective Combinatorial Optimization | 6.50 | 6.50 | 0.00 | | Poster |
| 580 | Gradient Step Denoiser for convergent Plug-and-Play | 5.50 | 6.50 | 1.00 | | Poster |
| 581 | Model-Based Offline Meta-Reinforcement Learning with Regularization | 5.50 | 6.50 | 1.00 | | Poster |
| 582 | How to deal with missing data in supervised deep learning? | 6.50 | 6.50 | 0.00 | | Poster |
| 583 | Learning Features with Parameter-Free Layers | 6.25 | 6.50 | 0.25 | | Poster |
| 584 | FedPara: Low-rank Hadamard Product for Communication-Efficient Federated Learning | 6.00 | 6.50 | 0.50 | | Poster |
| 585 | Defending Against Image Corruptions Through Adversarial Augmentations | 5.50 | 6.50 | 1.00 | | Poster |
| 586 | Simple GNN Regularisation for 3D Molecular Property Prediction and Beyond | 6.00 | 6.50 | 0.50 | | Poster |
| 587 | Trivial or Impossible --- dichotomous data difficulty masks model differences (on ImageNet and beyond) | 6.00 | 6.50 | 0.50 | | Poster |
| 588 | Learning to Downsample for Segmentation of Ultra-High Resolution Images | 6.25 | 6.50 | 0.25 | | Poster |
| 589 | Stiffness-aware neural network for learning Hamiltonian systems | 5.75 | 6.50 | 0.75 | | Poster |
| 590 | F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization | 6.25 | 6.50 | 0.25 | | Oral |
| 591 | GraphENS: Neighbor-Aware Ego Network Synthesis for Class-Imbalanced Node Classification | 5.50 | 6.50 | 1.00 | | Poster |
| 592 | Effective Model Sparsification by Scheduled Grow-and-Prune Methods | 5.50 | 6.50 | 1.00 | | Poster |
| 593 | T-WaveNet: A Tree-Structured Wavelet Neural Network for Time Series Signal Analysis | 6.25 | 6.50 | 0.25 | | Poster |
| 594 | Policy Gradients Incorporating the Future | 6.00 | 6.50 | 0.50 | | Poster |
| 595 | Tighter Sparse Approximation Bounds for ReLU Neural Networks | 6.50 | 6.50 | 0.00 | | Spotlight |
| 596 | DeSKO: Stability-Assured Robust Control with a Deep Stochastic Koopman Operator | 6.50 | 6.50 | 0.00 | | Poster |
| 597 | Interacting Contour Stochastic Gradient Langevin Dynamics | 5.75 | 6.50 | 0.75 | | Poster |
| 598 | Differentiable Expectation-Maximization for Set Representation Learning | 6.00 | 6.50 | 0.50 | | Poster |
| 599 | Maximum n-times Coverage for Vaccine Design | 5.50 | 6.50 | 1.00 | | Poster |
| 600 | Efficient Computation of Deep Nonlinear Infinite-Width Neural Networks that Learn Features | 6.00 | 6.50 | 0.50 | | Poster |
| 601 | The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training | 5.50 | 6.50 | 1.00 | | Poster |
| 602 | Discovering Latent Concepts Learned in BERT | 5.00 | 6.50 | 1.50 | | Poster |
| 603 | Self-Supervised Inference in State-Space Models | 6.00 | 6.50 | 0.50 | | Poster |
| 604 | Bag of Instances Aggregation Boosts Self-supervised Distillation | 5.75 | 6.50 | 0.75 | | Poster |
| 605 | Reducing Excessive Margin to Achieve a Better Accuracy vs. Robustness Trade-off | 5.75 | 6.50 | 0.75 | | Poster |
| 606 | HTLM: Hyper-Text Pre-Training and Prompting of Language Models | 6.25 | 6.50 | 0.25 | | Poster |
| 607 | Evaluating Model-Based Planning and Planner Amortization for Continuous Control | 6.25 | 6.50 | 0.25 | | Poster |
| 608 | On the Existence of Universal Lottery Tickets | 5.25 | 6.50 | 1.25 | | Poster |
| 609 | Reliable Adversarial Distillation with Unreliable Teachers | 6.25 | 6.50 | 0.25 | | Poster |
| 610 | Spread Spurious Attribute: Improving Worst-group Accuracy with Spurious Attribute Estimation | 6.00 | 6.50 | 0.50 | | Poster |
| 611 | Optimal ANN-SNN Conversion for High-accuracy and Ultra-low-latency Spiking Neural Networks | 5.50 | 6.50 | 1.00 | | Poster |
| 612 | Bundle Networks: Fiber Bundles, Local Trivializations, and a Generative Approach to Exploring Many-to-one Maps | 5.50 | 6.50 | 1.00 | | Poster |
| 613 | No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models | 6.50 | 6.50 | 0.00 | | Poster |
| 614 | Prototypical Contrastive Predictive Coding | 6.25 | 6.50 | 0.25 | | Poster |
| 615 | How unlabeled data improve generalization in self-training? A one-hidden-layer theoretical analysis | 5.00 | 6.50 | 1.50 | | Poster |
| 616 | Effect of scale on catastrophic forgetting in neural networks | 5.00 | 6.50 | 1.50 | | Poster |
| 617 | Low-Budget Active Learning via Wasserstein Distance: An Integer Programming Approach | 6.50 | 6.50 | 0.00 | | Poster |
| 618 | Improving the Accuracy of Learning Example Weights for Imbalance Classification | 6.25 | 6.50 | 0.25 | | Poster |
| 619 | Fast Generic Interaction Detection for Model Interpretability and Compression | 5.75 | 6.50 | 0.75 | | Poster |
| 620 | AlphaZero-based Proof Cost Network to Aid Game Solving | 5.50 | 6.50 | 1.00 | | Poster |
| 621 | Implicit Bias of Adversarial Training for Deep Neural Networks | 6.50 | 6.50 | 0.00 | | Poster |
| 622 | Boosted Curriculum Reinforcement Learning | 6.67 | 6.50 | -0.17 | | Poster |
| 623 | NASI: Label- and Data-agnostic Neural Architecture Search at Initialization | 5.75 | 6.50 | 0.75 | | Poster |
| 624 | Gradient Importance Learning for Incomplete Observations | 5.50 | 6.50 | 1.00 | | Poster |
| 625 | PAC Prediction Sets Under Covariate Shift | 6.50 | 6.50 | 0.00 | | Poster |
| 626 | Hierarchical Few-Shot Imitation with Skill Transition Models | 6.25 | 6.50 | 0.25 | | Poster |
| 627 | The Uncanny Similarity of Recurrence and Depth | 5.75 | 6.50 | 0.75 | | Poster |
| 628 | Objects in Semantic Topology | 5.75 | 6.50 | 0.75 | | Poster |
| 629 | EigenGame Unloaded: When playing games is better than optimizing | 6.50 | 6.50 | 0.00 | | Poster |
| 630 | Trust Region Policy Optimisation in Multi-Agent Reinforcement Learning | 6.50 | 6.50 | 0.00 | | Poster |
| 631 | AdaAug: Learning Class- and Instance-adaptive Data Augmentation Policies | 5.50 | 6.50 | 1.00 | | Poster |
| 632 | Dealing with Non-Stationarity in MARL via Trust-Region Decomposition | 5.50 | 6.50 | 1.00 | | Poster |
| 633 | ViTGAN: Training GANs with Vision Transformers | 5.40 | 6.40 | 1.00 | | 5, 5, 5, 6, 6 | | 6, 6, 6, 8, 6 |
| Spotlight |
| 634 | Predictive Modeling in the Presence of Nuisance-Induced Spurious Correlations | 5.50 | 6.40 | 0.90 | | Poster |
| 635 | GRAND++: Graph Neural Diffusion with A Source Term | 5.40 | 6.40 | 1.00 | | 8, 6, 5, 5, 3 | | 8, 6, 6, 6, 6 |
| Poster |
| 636 | On the Role of Neural Collapse in Transfer Learning | 5.80 | 6.40 | 0.60 | | 6, 6, 6, 5, 6 | | 6, 6, 8, 6, 6 |
| Poster |
| 637 | Learning to Schedule Learning rate with Graph Neural Networks | 5.60 | 6.40 | 0.80 | | 6, 8, 6, 5, 3 | | 6, 8, 6, 6, 6 |
| Poster |
| 638 | It Takes Two to Tango: Mixup for Deep Metric Learning | 6.20 | 6.40 | 0.20 | | 6, 5, 6, 6, 8 | | 6, 6, 6, 6, 8 |
| Poster |
| 639 | WeakM3D: Towards Weakly Supervised Monocular 3D Object Detection | 5.20 | 6.40 | 1.20 | | 3, 6, 6, 6, 5 | | 6, 6, 6, 8, 6 |
| Poster |
| 640 | Gradient Matching for Domain Generalization | 5.80 | 6.40 | 0.60 | | 6, 6, 5, 6, 6 | | 6, 6, 6, 8, 6 |
| Poster |
| 641 | Graph Neural Networks with Learnable Structural and Positional Representations | 5.60 | 6.40 | 0.80 | | 5, 8, 5, 5, 5 | | 6, 8, 8, 5, 5 |
| Poster |
| 642 | On the Convergence of Certified Robust Training with Interval Bound Propagation | 5.67 | 6.33 | 0.67 | | Poster |
| 643 | Learning Distributionally Robust Models at Scale via Composite Optimization | 5.67 | 6.33 | 0.67 | | Poster |
| 644 | MaGNET: Uniform Sampling from Deep Generative Network Manifolds Without Retraining | 5.33 | 6.33 | 1.00 | | Poster |
| 645 | Clean Images are Hard to Reblur: Exploiting the Ill-Posed Inverse Task for Dynamic Scene Deblurring | 5.67 | 6.33 | 0.67 | | Poster |
| 646 | Non-Autoregressive Models are Better Multilingual Translators | 6.33 | 6.33 | 0.00 | | Poster |
| 647 | Unified Visual Transformer Compression | 5.33 | 6.33 | 1.00 | | Poster |
| 648 | Bridging Recommendation and Marketing via Recurrent Intensity Modeling | 5.67 | 6.33 | 0.67 | | Poster |
| 649 | Language-driven Semantic Segmentation | 5.67 | 6.33 | 0.67 | | Poster |
| 650 | Optimal Representations for Covariate Shift | 6.33 | 6.33 | 0.00 | | Poster |
| 651 | Eliminating Sharp Minima from SGD with Truncated Heavy-tailed Noise | 5.33 | 6.33 | 1.00 | | Poster |
| 652 | CrowdPlay: Crowdsourcing human demonstration data for offline learning in Atari games | 6.33 | 6.33 | 0.00 | | Poster |
| 653 | Which Shortcut Cues Will DNNs Choose? A Study from the Parameter-Space Perspective | 6.00 | 6.33 | 0.33 | | Poster |
| 654 | Pseudo-Labeled Auto-Curriculum Learning for Semi-Supervised Keypoint Localization | 6.33 | 6.33 | 0.00 | | Poster |
| 655 | Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift | 5.33 | 6.33 | 1.00 | | Poster |
| 656 | Distilling GANs with Style-Mixed Triplets for X2I Translation with Limited Data | 5.67 | 6.33 | 0.67 | | Poster |
| 657 | Neural Networks as Kernel Learners: The Silent Alignment Effect | 6.00 | 6.33 | 0.33 | | Poster |
| 658 | Hierarchical Variational Memory for Few-shot Learning Across Domains | 5.67 | 6.33 | 0.67 | | Poster |
| 659 | Learning to Map for Active Semantic Goal Navigation | 6.00 | 6.33 | 0.33 | | Poster |
| 660 | Sparse Attention with Learning to Hash | 5.33 | 6.33 | 1.00 | | Poster |
| 661 | Auto-scaling Vision Transformers without Training | 6.00 | 6.33 | 0.33 | | Poster |
| 662 | Autonomous Learning of Object-Centric Abstractions for High-Level Planning | 6.33 | 6.33 | 0.00 | | Poster |
| 663 | Concurrent Adversarial Learning for Large-Batch Training | 6.33 | 6.33 | 0.00 | | Poster |
| 664 | Fine-grained Differentiable Physics: A Yarn-level Model for Fabrics | 5.83 | 6.33 | 0.50 | | 6, 6, 6, 6, 5, 6 | | 6, 6, 6, 6, 8, 6 |
| Poster |
| 665 | Counterfactual Plans under Distributional Ambiguity | 6.00 | 6.33 | 0.33 | | Poster |
| 666 | Pareto Policy Adaptation | 5.33 | 6.33 | 1.00 | | Poster |
| 667 | Mapping conditional distributions for domain adaptation under generalized target shift | 6.33 | 6.33 | 0.00 | | Poster |
| 668 | Anti-Concentrated Confidence Bonuses For Scalable Exploration | 6.33 | 6.33 | 0.00 | | Poster |
| 669 | ViDT: An Efficient and Effective Fully Transformer-based Object Detector | 6.00 | 6.33 | 0.33 | | Poster |
| 670 | Information-theoretic Online Memory Selection for Continual Learning | 5.67 | 6.33 | 0.67 | | Poster |
| 671 | Transformers Can Do Bayesian Inference | 6.33 | 6.33 | 0.00 | | Poster |
| 672 | Neural Models for Output-Space Invariance in Combinatorial Problems | 6.33 | 6.33 | 0.00 | | Poster |
| 673 | Neural Solvers for Fast and Accurate Numerical Optimal Control | 5.33 | 6.33 | 1.00 | | Poster |
| 674 | Doubly Adaptive Scaled Algorithm for Machine Learning Using Second-Order Information | 5.33 | 6.33 | 1.00 | | Poster |
| 675 | Using Graph Representation Learning with Schema Encoders to Measure the Severity of Depressive Symptoms | 5.33 | 6.33 | 1.00 | | Poster |
| 676 | Generative Principal Component Analysis | 5.33 | 6.33 | 1.00 | | Poster |
| 677 | Rethinking Goal-Conditioned Supervised Learning and Its Connection to Offline RL | 6.00 | 6.33 | 0.33 | | Poster |
| 678 | DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR | 5.33 | 6.33 | 1.00 | | Poster |
| 679 | MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer | 6.33 | 6.33 | 0.00 | | Poster |
| 680 | Incremental False Negative Detection for Contrastive Learning | 5.00 | 6.33 | 1.33 | | Poster |
| 681 | A Neural Tangent Kernel Perspective of Infinite Tree Ensembles | 6.33 | 6.33 | 0.00 | | Poster |
| 682 | Fairness Guarantees under Demographic Shift | 5.75 | 6.25 | 0.50 | | Poster |
| 683 | Connectome-constrained Latent Variable Model of Whole-Brain Neural Activity | 5.00 | 6.25 | 1.25 | | Poster |
| 684 | Automated Self-Supervised Learning for Graphs | 6.00 | 6.25 | 0.25 | | Poster |
| 685 | Knowledge Infused Decoding | 6.00 | 6.25 | 0.25 | | Poster |
| 686 | Learning Pruning-Friendly Networks via Frank-Wolfe: One-Shot, Any-Sparsity, And No Retraining | 6.00 | 6.25 | 0.25 | | Spotlight |
| 687 | Distributional Reinforcement Learning with Monotonic Splines | 6.00 | 6.25 | 0.25 | | Poster |
| 688 | AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation | 6.25 | 6.25 | 0.00 | | Poster |
| 689 | Multitask Prompted Training Enables Zero-Shot Task Generalization | 6.25 | 6.25 | 0.00 | | Spotlight |
| 690 | Learning Value Functions from Undirected State-only Experience | 6.00 | 6.25 | 0.25 | | Poster |
| 691 | Finding an Unsupervised Image Segmenter in each of your Deep Generative Models | 6.25 | 6.25 | 0.00 | | Poster |
| 692 | Neural Processes with Stochastic Attention: Paying more attention to the context dataset | 5.50 | 6.25 | 0.75 | | Poster |
| 693 | SUMNAS: Supernet with Unbiased Meta-Features for Neural Architecture Search | 5.75 | 6.25 | 0.50 | | Poster |
| 694 | Variational Inference for Discriminative Learning with Generative Modeling of Feature Incompletion | 6.25 | 6.25 | 0.00 | | Oral |
| 695 | Semi-relaxed Gromov-Wasserstein divergence and applications on graphs | 6.25 | 6.25 | 0.00 | | Poster |
| 696 | Implicit Bias of MSE Gradient Optimization in Underparameterized Neural Networks | 5.50 | 6.25 | 0.75 | | Poster |
| 697 | Neural Link Prediction with Walk Pooling | 5.75 | 6.25 | 0.50 | | Poster |
| 698 | Online Continual Learning on Class Incremental Blurry Task Configuration with Anytime Inference | 5.00 | 6.25 | 1.25 | | Poster |
| 699 | Adversarial Retriever-Ranker for Dense Text Retrieval | 6.00 | 6.25 | 0.25 | | Poster |
| 700 | Provable Learning-based Algorithm For Sparse Recovery | 5.00 | 6.25 | 1.25 | | Poster |
| 701 | Goal-Directed Planning via Hindsight Experience Replay | 5.50 | 6.25 | 0.75 | | Poster |
| 702 | GDA-AM: ON THE EFFECTIVENESS OF SOLVING MIN-IMAX OPTIMIZATION VIA ANDERSON MIXING | 4.75 | 6.25 | 1.50 | | Poster |
| 703 | Increasing the Cost of Model Extraction with Calibrated Proof of Work | 5.75 | 6.25 | 0.50 | | Spotlight |
| 704 | The Essential Elements of Offline RL via Supervised Learning | 4.75 | 6.25 | 1.50 | | Poster |
| 705 | Near-optimal Offline Reinforcement Learning with Linear Representation: Leveraging Variance Information with Pessimism | 6.25 | 6.25 | 0.00 | | Poster |
| 706 | Conditional Contrastive Learning with Kernel | 5.50 | 6.25 | 0.75 | | Poster |
| 707 | Differentiable Gradient Sampling for Learning Implicit 3D Scene Reconstructions from a Single Image | 5.75 | 6.25 | 0.50 | | Poster |
| 708 | The Three Stages of Learning Dynamics in High-dimensional Kernel Methods | 6.25 | 6.25 | 0.00 | | Poster |
| 709 | FedBABU: Toward Enhanced Representation for Federated Image Classification | 6.00 | 6.25 | 0.25 | | Poster |
| 710 | Curriculum learning as a tool to uncover learning principles in the brain | 5.00 | 6.25 | 1.25 | | Poster |
| 711 | Model Zoo: A Growing Brain That Learns Continually | 6.25 | 6.25 | 0.00 | | Poster |
| 712 | Heteroscedastic Temporal Variational Autoencoder For Irregularly Sampled Time Series | 5.50 | 6.25 | 0.75 | | Poster |
| 713 | Fast Model Editing at Scale | 6.33 | 6.25 | -0.08 | | Poster |
| 714 | Memorizing Transformers | 5.75 | 6.25 | 0.50 | | Spotlight |
| 715 | TAda! Temporally-Adaptive Convolutions for Video Understanding | 5.50 | 6.25 | 0.75 | | Poster |
| 716 | Blaschke Product Neural Networks (BPNN): A Physics-Infused Neural Network for Phase Retrieval of Meromorphic Functions | 5.00 | 6.25 | 1.25 | | Poster |
| 717 | Step-unrolled Denoising Autoencoders for Text Generation | 5.50 | 6.25 | 0.75 | | Poster |
| 718 | Who Is the Strongest Enemy? Towards Optimal and Efficient Evasion Attacks in Deep RL | 6.25 | 6.25 | 0.00 | | Poster |
| 719 | Lossless Compression with Probabilistic Circuits | 5.50 | 6.25 | 0.75 | | Spotlight |
| 720 | Neural Parameter Allocation Search | 5.00 | 6.25 | 1.25 | | Poster |
| 721 | Generalized Kernel Thinning | 6.25 | 6.25 | 0.00 | | Poster |
| 722 | Linking Emergent and Natural Languages via Corpus Transfer | 6.25 | 6.25 | 0.00 | | Spotlight |
| 723 | Do deep networks transfer invariances across classes? | 5.25 | 6.25 | 1.00 | | Poster |
| 724 | Transferable Visual Control Policies Through Robot-Awareness | 5.50 | 6.25 | 0.75 | | Poster |
| 725 | Deep Point Cloud Reconstruction | 6.25 | 6.25 | 0.00 | | Poster |
| 726 | Learning curves for continual learning in neural networks: Self-knowledge transfer and forgetting | 6.25 | 6.25 | 0.00 | | Poster |
| 727 | Collapse by Conditioning: Training Class-conditional GANs with Limited Data | 6.00 | 6.25 | 0.25 | | Poster |
| 728 | Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients | 6.00 | 6.25 | 0.25 | | Poster |
| 729 | Is Importance Weighting Incompatible with Interpolating Classifiers? | 5.67 | 6.25 | 0.58 | | Poster |
| 730 | Exposing the Implicit Energy Networks behind Masked Language Models via Metropolis--Hastings | 6.25 | 6.25 | 0.00 | | Poster |
| 731 | How Much Can CLIP Benefit Vision-and-Language Tasks? | 5.75 | 6.25 | 0.50 | | Poster |
| 732 | It Takes Four to Tango: Multiagent Self Play for Automatic Curriculum Generation | 5.00 | 6.25 | 1.25 | | Poster |
| 733 | Large-Scale Representation Learning on Graphs via Bootstrapping | 6.00 | 6.25 | 0.25 | | Poster |
| 734 | TRGP: Trust Region Gradient Projection for Continual Learning | 6.00 | 6.25 | 0.25 | | Spotlight |
| 735 | Neural Contextual Bandits with Deep Representation and Shallow Exploration | 6.75 | 6.25 | -0.50 | | Poster |
| 736 | Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models | 6.25 | 6.25 | 0.00 | | Poster |
| 737 | Discriminative Similarity for Data Clustering | 6.25 | 6.25 | 0.00 | | Poster |
| 738 | CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting | 6.00 | 6.25 | 0.25 | | Poster |
| 739 | The Evolution of Uncertainty of Learning in Games | 5.75 | 6.25 | 0.50 | | Poster |
| 740 | Enabling Arbitrary Translation Objectives with Adaptive Tree Search | 6.00 | 6.25 | 0.25 | | Poster |
| 741 | CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention | 5.75 | 6.25 | 0.50 | | Poster |
| 742 | Subspace Regularizers for Few-Shot Class Incremental Learning | 5.75 | 6.25 | 0.50 | | Poster |
| 743 | Explainable GNN-Based Models over Knowledge Graphs | 5.25 | 6.25 | 1.00 | | Poster |
| 744 | Evolutionary Diversity Optimization with Clustering-based Selection for Reinforcement Learning | 4.67 | 6.25 | 1.58 | | Poster |
| 745 | R4D: Utilizing Reference Objects for Long-Range Distance Estimation | 6.25 | 6.25 | 0.00 | | Poster |
| 746 | Relational Multi-Task Learning: Modeling Relations between Data and Tasks | 6.25 | 6.25 | 0.00 | | Spotlight |
| 747 | A Biologically Interpretable Graph Convolutional Network to Link Genetic Risk Pathways and Imaging Phenotypes of Disease | 5.75 | 6.25 | 0.50 | | Poster |
| 748 | CADDA: Class-wise Automatic Differentiable Data Augmentation for EEG Signals | 6.00 | 6.25 | 0.25 | | Poster |
| 749 | How Low Can We Go: Trading Memory for Error in Low-Precision Training | 5.75 | 6.25 | 0.50 | | Poster |
| 750 | Boosting the Certified Robustness of L-infinity Distance Nets | 5.75 | 6.25 | 0.50 | | Poster |
| 751 | Memory Augmented Optimizers for Deep Learning | 6.25 | 6.25 | 0.00 | | Poster |
| 752 | Gaussian Mixture Convolution Networks | 6.33 | 6.25 | -0.08 | | Poster |
| 753 | Evidential Turing Processes | 5.50 | 6.25 | 0.75 | | Poster |
| 754 | A global convergence theory for deep ReLU implicit networks via over-parameterization | 6.25 | 6.25 | 0.00 | | Poster |
| 755 | How Well Does Self-Supervised Pre-Training Perform with Streaming Data? | 6.00 | 6.25 | 0.25 | | Poster |
| 756 | Understanding and Preventing Capacity Loss in Reinforcement Learning | 5.50 | 6.25 | 0.75 | | Spotlight |
| 757 | Scale Efficiently: Insights from Pretraining and Finetuning Transformers | 6.25 | 6.25 | 0.00 | | Poster |
| 758 | Learning to Extend Molecular Scaffolds with Structural Motifs | 6.25 | 6.25 | 0.00 | | Poster |
| 759 | Group-based Interleaved Pipeline Parallelism for Large-scale DNN Training | 6.25 | 6.25 | 0.00 | | Poster |
| 760 | Switch to Generalize: Domain-Switch Learning for Cross-Domain Few-Shot Classification | 5.75 | 6.25 | 0.50 | | Poster |
| 761 | DriPP: Driven Point Processes to Model Stimuli Induced Patterns in M/EEG Signals | 5.00 | 6.25 | 1.25 | | Poster |
| 762 | Taming Sparsely Activated Transformer with Stochastic Experts | 5.75 | 6.25 | 0.50 | | Poster |
| 763 | Quantitative Performance Assessment of CNN Units via Topological Entropy Calculation | 5.50 | 6.25 | 0.75 | | Poster |
| 764 | Unsupervised Disentanglement with Tensor Product Representations on the Torus | 6.25 | 6.25 | 0.00 | | Poster |
| 765 | Multi-Agent MDP Homomorphic Networks | 6.00 | 6.25 | 0.25 | | Poster |
| 766 | DARA: Dynamics-Aware Reward Augmentation in Offline Reinforcement Learning | 6.00 | 6.25 | 0.25 | | Poster |
| 767 | Online Coreset Selection for Rehearsal-based Continual Learning | 5.75 | 6.25 | 0.50 | | Poster |
| 768 | Mirror Descent Policy Optimization | 5.75 | 6.25 | 0.50 | | Poster |
| 769 | On-Policy Model Errors in Reinforcement Learning | 6.00 | 6.25 | 0.25 | | Poster |
| 770 | Learning Multimodal VAEs through Mutual Supervision | 6.00 | 6.25 | 0.25 | | Spotlight |
| 771 | In a Nutshell, the Human Asked for This: Latent Goals for Following Temporal Specifications | 4.75 | 6.25 | 1.50 | | Poster |
| 772 | Multi-Mode Deep Matrix and Tensor Factorization | 6.33 | 6.25 | -0.08 | | Poster |
| 773 | Pessimistic Model-based Offline Reinforcement Learning under Partial Coverage | 6.25 | 6.25 | 0.00 | | Poster |
| 774 | Scale Mixtures of Neural Network Gaussian Processes | 6.00 | 6.25 | 0.25 | | Poster |
| 775 | Monotonic Differentiable Sorting Networks | 6.00 | 6.25 | 0.25 | | Poster |
| 776 | Target-Side Data Augmentation for Sequence Generation | 4.75 | 6.25 | 1.50 | | Poster |
| 777 | Quadtree Attention for Vision Transformers | 6.25 | 6.25 | 0.00 | | Poster |
| 778 | Igeood: An Information Geometry Approach to Out-of-Distribution Detection | 5.00 | 6.25 | 1.25 | | Poster |
| 779 | Continual Normalization: Rethinking Batch Normalization for Online Continual Learning | 5.50 | 6.25 | 0.75 | | Poster |
| 780 | On feature learning in shallow and multi-layer neural networks with global convergence guarantees | 5.50 | 6.25 | 0.75 | | Poster |
| 781 | Resonance in Weight Space: Covariate Shift Can Drive Divergence of SGD with Momentum | 6.25 | 6.25 | 0.00 | | Poster |
| 782 | Generative Modeling with Optimal Transport Maps | 6.00 | 6.25 | 0.25 | | Poster |
| 783 | Multi-Task Processes | 6.00 | 6.25 | 0.25 | | Poster |
| 784 | Expressivity of Emergent Languages is a Trade-off between Contextual Complexity and Unpredictability | 5.50 | 6.25 | 0.75 | | Poster |
| 785 | Zero-CL: Instance and Feature decorrelation for negative-free symmetric contrastive learning | 6.25 | 6.25 | 0.00 | | Poster |
| 786 | GATSBI: Generative Adversarial Training for Simulation-Based Inference | 6.00 | 6.25 | 0.25 | | Poster |
| 787 | Encoding Weights of Irregular Sparsity for Fixed-to-Fixed Model Compression | 6.00 | 6.25 | 0.25 | | Poster |
| 788 | Rethinking Class-Prior Estimation for Positive-Unlabeled Learning | 6.00 | 6.25 | 0.25 | | Poster |
| 789 | Top-N: Equivariant Set and Graph Generation without Exchangeability | 5.00 | 6.25 | 1.25 | | Poster |
| 790 | FastSHAP: Real-Time Shapley Value Estimation | 5.00 | 6.25 | 1.25 | | Poster |
| 791 | Autoregressive Diffusion Models | 6.25 | 6.25 | 0.00 | | Poster |
| 792 | Maximum Entropy RL (Provably) Solves Some Robust RL Problems | 5.75 | 6.25 | 0.50 | | Poster |
| 793 | Constraining Linear-chain CRFs to Regular Languages | 5.75 | 6.25 | 0.50 | | Poster |
| 794 | Neural Markov Controlled SDE: Stochastic Optimization for Continuous-Time Data | 6.25 | 6.25 | 0.00 | | Poster |
| 795 | Disentanglement Analysis with Partial Information Decomposition | 5.50 | 6.25 | 0.75 | | Poster |
| 796 | Hindsight Foresight Relabeling for Meta-Reinforcement Learning | 5.00 | 6.25 | 1.25 | | Poster |
| 797 | Graph Auto-Encoder via Neighborhood Wasserstein Reconstruction | 6.25 | 6.25 | 0.00 | | Poster |
| 798 | Self-ensemble Adversarial Training for Improved Robustness | 5.00 | 6.25 | 1.25 | | Poster |
| 799 | An Autoregressive Flow Model for 3D Molecular Geometry Generation from Scratch | 6.25 | 6.25 | 0.00 | | Poster |
| 800 | Learning Fast, Learning Slow: A General Continual Learning Method based on Complementary Learning System | 6.25 | 6.25 | 0.00 | | Poster |
| 801 | Non-Parallel Text Style Transfer with Self-Parallel Supervision | 5.00 | 6.20 | 1.20 | | 6, 6, 5, 3, 5 | | 8, 6, 8, 3, 6 |
| Poster |
| 802 | Cross-Domain Lossy Compression as Optimal Transport with an Entropy Bottleneck | 6.20 | 6.20 | 0.00 | | 3, 8, 6, 6, 8 | | 3, 8, 6, 6, 8 |
| Poster |
| 803 | NASViT: Neural Architecture Search for Efficient Vision Transformers with Gradient Conflict aware Supernet Training | 6.20 | 6.20 | 0.00 | | 6, 5, 6, 8, 6 | | 6, 5, 6, 8, 6 |
| Poster |
| 804 | Policy Smoothing for Provably Robust Reinforcement Learning | 5.40 | 6.20 | 0.80 | | 6, 6, 6, 6, 3 | | 6, 8, 6, 6, 5 |
| Poster |
| 805 | The Spectral Bias of Polynomial Neural Networks | 5.40 | 6.20 | 0.80 | | 3, 6, 6, 6, 6 | | 5, 6, 6, 8, 6 |
| Poster |
| 806 | Fair Normalizing Flows | 5.00 | 6.20 | 1.20 | | 6, 3, 5, 5, 6 | | 6, 5, 8, 6, 6 |
| Poster |
| 807 | Understanding Dimensional Collapse in Contrastive Self-supervised Learning | 5.60 | 6.20 | 0.60 | | 6, 3, 8, 6, 5 | | 6, 6, 8, 6, 5 |
| Poster |
| 808 | A Theoretical Analysis on Feature Learning in Neural Networks: Emergence from Inputs and Advantage over Fixed Features | 6.00 | 6.20 | 0.20 | | 5, 8, 6, 6, 5 | | 5, 8, 6, 6, 6 |
| Poster |
| 809 | BiBERT: Accurate Fully Binarized BERT | 6.00 | 6.20 | 0.20 | | 5, 6, 5, 6, 8 | | 6, 6, 5, 6, 8 |
| Poster |
| 810 | Towards Deepening Graph Neural Networks: A GNTK-based Optimization Perspective | 5.80 | 6.20 | 0.40 | | 5, 5, 6, 5, 8 | | 6, 5, 6, 6, 8 |
| Poster |
| 811 | OBJECT DYNAMICS DISTILLATION FOR SCENE DECOMPOSITION AND REPRESENTATION | 6.00 | 6.20 | 0.20 | | 5, 5, 8, 6, 6 | | 6, 5, 8, 6, 6 |
| Poster |
| 812 | On Redundancy and Diversity in Cell-based Neural Architecture Search | 6.00 | 6.20 | 0.20 | | 5, 5, 8, 6, 6 | | 5, 6, 8, 6, 6 |
| Poster |
| 813 | Efficient Neural Causal Discovery without Acyclicity Constraints | 6.00 | 6.20 | 0.20 | | 6, 6, 5, 8, 5 | | 6, 6, 5, 8, 6 |
| Poster |
| 814 | Top-label calibration and multiclass-to-binary reductions | 5.50 | 6.00 | 0.50 | | Poster |
| 815 | PipeGCN: Efficient Full-Graph Training of Graph Convolutional Networks with Pipelined Feature Communication | 5.75 | 6.00 | 0.25 | | Poster |
| 816 | Auto-Transfer: Learning to Route Transferable Representations | 5.00 | 6.00 | 1.00 | | Poster |
| 817 | FILM: Following Instructions in Language with Modular Methods | 6.25 | 6.00 | -0.25 | | Poster |
| 818 | Deep Learning without Shortcuts: Shaping the Kernel with Tailored Rectifiers | 6.00 | 6.00 | 0.00 | | Poster |
| 819 | Language model compression with weighted low-rank factorization | 5.33 | 6.00 | 0.67 | | Poster |
| 820 | The Effects of Invertibility on the Representational Complexity of Encoders in Variational Autoencoders | 4.67 | 6.00 | 1.33 | | Poster |
| 821 | Prototype memory and attention mechanisms for few shot image generation | 6.00 | 6.00 | 0.00 | | Poster |
| 822 | LEARNING GUARANTEES FOR GRAPH CONVOLUTIONAL NETWORKS ON THE STOCHASTIC BLOCK MODEL | 5.50 | 6.00 | 0.50 | | Poster |
| 823 | CrossMatch: Cross-Classifier Consistency Regularization for Open-Set Single Domain Generalization | 5.50 | 6.00 | 0.50 | | Poster |
| 824 | LIGS: Learnable Intrinsic-Reward Generation Selection for Multi-Agent Learning | 5.25 | 6.00 | 0.75 | | Poster |
| 825 | Cold Brew: Distilling Graph Node Representations with Incomplete or Missing Neighborhoods | 5.25 | 6.00 | 0.75 | | Poster |
| 826 | Learning Representation from Neural Fisher Kernel with Low-rank Approximation | 6.00 | 6.00 | 0.00 | | Poster |
| 827 | Discrete Representations Strengthen Vision Transformer Robustness | 5.33 | 6.00 | 0.67 | | Poster |
| 828 | Modeling Label Space Interactions in Multi-label Classification using Box Embeddings | 6.00 | 6.00 | 0.00 | | Poster |
| 829 | Graph-Guided Network for Irregularly Sampled Multivariate Time Series | 5.33 | 6.00 | 0.67 | | Poster |
| 830 | Learning to Dequantise with Truncated Flows | 5.33 | 6.00 | 0.67 | | Poster |
| 831 | Axiomatic Explanations for Visual Search, Retrieval, and Similarity Learning | 5.00 | 6.00 | 1.00 | | Poster |
| 832 | Autonomous Reinforcement Learning: Formalism and Benchmarking | 6.00 | 6.00 | 0.00 | | Poster |
| 833 | VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects | 5.00 | 6.00 | 1.00 | | Poster |
| 834 | An Agnostic Approach to Federated Learning with Class Imbalance | 5.50 | 6.00 | 0.50 | | Poster |
| 835 | Generalization Through the Lens of Leave-One-Out Error | 4.67 | 6.00 | 1.33 | | Poster |
| 836 | Complete Verification via Multi-Neuron Relaxation Guided Branch-and-Bound | 4.80 | 6.00 | 1.20 | | 5, 5, 5, 6, 3 | | 6, 6, 6, 6, 6 |
| Poster |
| 837 | Augmented Sliced Wasserstein Distances | 6.00 | 6.00 | 0.00 | | Poster |
| 838 | W-CTC: a Connectionist Temporal Classification Loss with Wild Cards | 5.75 | 6.00 | 0.25 | | Poster |
| 839 | DictFormer: Tiny Transformer with Shared Dictionary | 5.25 | 6.00 | 0.75 | | Poster |
| 840 | Nonlinear ICA Using Volume-Preserving Transformations | 5.80 | 6.00 | 0.20 | | 6, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
| Poster |
| 841 | Post hoc Explanations may be Ineffective for Detecting Unknown Spurious Correlation | 4.67 | 6.00 | 1.33 | | Poster |
| 842 | PoNet: Pooling Network for Efficient Token Mixing in Long Sequences | 5.75 | 6.00 | 0.25 | | Poster |
| 843 | DISSECT: Disentangled Simultaneous Explanations via Concept Traversals | 5.75 | 6.00 | 0.25 | | Poster |
| 844 | Is Homophily a Necessity for Graph Neural Networks? | 5.25 | 6.00 | 0.75 | | Poster |
| 845 | Query Embedding on Hyper-Relational Knowledge Graphs | 6.00 | 6.00 | 0.00 | | 8, 5, 5, 6, 6 | | 8, 5, 5, 6, 6 |
| Poster |
| 846 | Wish you were here: Hindsight Goal Selection for long-horizon dexterous manipulation | 5.00 | 6.00 | 1.00 | | Poster |
| 847 | Selective Ensembles for Consistent Predictions | 5.50 | 6.00 | 0.50 | | Poster |
| 848 | Open-World Semi-Supervised Learning | 5.80 | 6.00 | 0.20 | | 6, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
| Poster |
| 849 | On the benefits of maximum likelihood estimation for Regression and Forecasting | 5.33 | 6.00 | 0.67 | | Poster |
| 850 | An Explanation of In-context Learning as Implicit Bayesian Inference | 5.50 | 6.00 | 0.50 | | Poster |
| 851 | Stein Latent Optimization for Generative Adversarial Networks | 5.50 | 6.00 | 0.50 | | Poster |
| 852 | Pseudo Numerical Methods for Diffusion Models on Manifolds | 6.00 | 6.00 | 0.00 | | Poster |
| 853 | Discrepancy-Based Active Learning for Domain Adaptation | 5.75 | 6.00 | 0.25 | | Poster |
| 854 | Adversarial Unlearning of Backdoors via Implicit Hypergradient | 5.25 | 6.00 | 0.75 | | Poster |
| 855 | Surrogate NAS Benchmarks: Going Beyond the Limited Search Spaces of Tabular NAS Benchmarks | 5.50 | 6.00 | 0.50 | | Poster |
| 856 | Offline Reinforcement Learning for Large Scale Language Action Spaces | 5.00 | 6.00 | 1.00 | | Poster |
| 857 | Generalized Natural Gradient Flows in Hidden Convex-Concave Games and GANs | 5.25 | 6.00 | 0.75 | | Poster |
| 858 | Learning Weakly-supervised Contrastive Representations | 5.50 | 6.00 | 0.50 | | Poster |
| 859 | Generalizing Few-Shot NAS with Gradient Matching | 5.75 | 6.00 | 0.25 | | Poster |
| 860 | THOMAS: Trajectory Heatmap Output with learned Multi-Agent Sampling | 5.00 | 6.00 | 1.00 | | Poster |
| 861 | SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning | 5.33 | 6.00 | 0.67 | | Poster |
| 862 | Scaling the Depth of Vision Transformers via the Fourier Domain Analysis | 5.33 | 6.00 | 0.67 | | Poster |
| 863 | Illiterate DALL⋅E Learns to Compose | 5.33 | 6.00 | 0.67 | | Poster |
| 864 | Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning | 4.75 | 6.00 | 1.25 | | Poster |
| 865 | Variational autoencoders in the presence of low-dimensional data: landscape and implicit bias | 5.00 | 6.00 | 1.00 | | Poster |
| 866 | Online Adversarial Attacks | 5.25 | 6.00 | 0.75 | | Poster |
| 867 | Provably convergent quasistatic dynamics for mean-field two-player zero-sum games | 5.75 | 6.00 | 0.25 | | Poster |
| 868 | Space-Time Graph Neural Networks | 6.00 | 6.00 | 0.00 | | Poster |
| 869 | IGLU: Efficient GCN Training via Lazy Updates | 5.67 | 6.00 | 0.33 | | Poster |
| 870 | On the Pitfalls of Heteroscedastic Uncertainty Estimation with Probabilistic Neural Networks | 4.33 | 6.00 | 1.67 | | Poster |
| 871 | RegionViT: Regional-to-Local Attention for Vision Transformers | 6.00 | 6.00 | 0.00 | | Poster |
| 872 | Group equivariant neural posterior estimation | 5.25 | 6.00 | 0.75 | | Poster |
| 873 | GeneDisco: A Benchmark for Experimental Design in Drug Discovery | 4.67 | 6.00 | 1.33 | | Poster |
| 874 | One After Another: Learning Incremental Skills for a Changing World | 4.75 | 6.00 | 1.25 | | Poster |
| 875 | Hidden Parameter Recurrent State Space Models For Changing Dynamics Scenarios | 5.00 | 6.00 | 1.00 | | Poster |
| 876 | Universalizing Weak Supervision | 5.25 | 6.00 | 0.75 | | Poster |
| 877 | Toward Efficient Low-Precision Training: Data Format Optimization and Hysteresis Quantization | 4.67 | 6.00 | 1.33 | | Poster |
| 878 | The Rich Get Richer: Disparate Impact of Semi-Supervised Learning | 5.50 | 6.00 | 0.50 | | Poster |
| 879 | On the role of population heterogeneity in emergent communication | 5.00 | 6.00 | 1.00 | | Poster |
| 880 | MoReL: Multi-omics Relational Learning | 6.00 | 6.00 | 0.00 | | Poster |
| 881 | Topological Graph Neural Networks | 5.75 | 6.00 | 0.25 | | Poster |
| 882 | Measuring CLEVRness: Black-box Testing of Visual Reasoning Models | 5.67 | 6.00 | 0.33 | | Poster |
| 883 | TPU-GAN: Learning temporal coherence from dynamic point cloud sequences | 5.80 | 6.00 | 0.20 | | 6, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
| Poster |
| 884 | OntoProtein: Protein Pretraining With Gene Ontology Embedding | 5.67 | 6.00 | 0.33 | | Poster |
| 885 | Orchestrated Value Mapping for Reinforcement Learning | 5.67 | 6.00 | 0.33 | | Poster |
| 886 | Offline Neural Contextual Bandits: Pessimism, Optimization and Generalization | 5.50 | 6.00 | 0.50 | | Poster |
| 887 | Do Users Benefit From Interpretable Vision? A User Study, Baseline, And Dataset | 5.25 | 6.00 | 0.75 | | Poster |
| 888 | Communication-Efficient Actor-Critic Methods for Homogeneous Markov Games | 5.25 | 6.00 | 0.75 | | Poster |
| 889 | Training Transition Policies via Distribution Matching for Complex Tasks | 6.00 | 6.00 | 0.00 | | Poster |
| 890 | On Robust Prefix-Tuning for Text Classification | 5.50 | 6.00 | 0.50 | | Poster |
| 891 | The Efficiency Misnomer | 4.75 | 6.00 | 1.25 | | Poster |
| 892 | Towards Training Billion Parameter Graph Neural Networks for Atomic Simulations | 5.75 | 6.00 | 0.25 | | Poster |
| 893 | Neural Methods for Logical Reasoning over Knowledge Graphs | 5.25 | 6.00 | 0.75 | | Poster |
| 894 | Givens Coordinate Descent Methods for Rotation Matrix Learning in Trainable Embedding Indexes | 5.75 | 6.00 | 0.25 | | Poster |
| 895 | Charformer: Fast Character Transformers via Gradient-based Subword Tokenization | 6.00 | 6.00 | 0.00 | | 6, 8, 6, 5, 5 | | 6, 8, 6, 5, 5 |
| Poster |
| 896 | Signing the Supermask: Keep, Hide, Invert | 5.00 | 6.00 | 1.00 | | Poster |
| 897 | Attention-based Interpretability with Concept Transformers | 5.25 | 6.00 | 0.75 | | Poster |
| 898 | Normalization of Language Embeddings for Cross-Lingual Alignment | 5.60 | 6.00 | 0.40 | | 8, 6, 5, 3, 6 | | 8, 6, 5, 3, 8 |
| Poster |
| 899 | Offline Reinforcement Learning with In-sample Q-Learning | 5.50 | 6.00 | 0.50 | | Poster |
| 900 | Differentiable DAG Sampling | 6.00 | 6.00 | 0.00 | | Poster |
| 901 | On the Convergence of mSGD and AdaGrad for Stochastic Optimization | 5.67 | 6.00 | 0.33 | | Poster |
| 902 | Neural Stochastic Dual Dynamic Programming | 5.75 | 6.00 | 0.25 | | Poster |
| 903 | ToM2C: Target-oriented Multi-agent Communication and Cooperation with Theory of Mind | 5.33 | 6.00 | 0.67 | | Poster |
| 904 | Learning Invariant Representations on Multilingual Language Models for Unsupervised Cross-Lingual Transfer | 5.50 | 6.00 | 0.50 | | Poster |
| 905 | Learning Curves for SGD on Structured Features | 5.75 | 6.00 | 0.25 | | Poster |
| 906 | Learning Scenario Representation for Solving Two-stage Stochastic Integer Programs | 4.33 | 6.00 | 1.67 | | Poster |
| 907 | Recursive Disentanglement Network | 5.25 | 6.00 | 0.75 | | Poster |
| 908 | MAML is a Noisy Contrastive Learner | 5.33 | 6.00 | 0.67 | | Poster |
| 909 | L0-Sparse Canonical Correlation Analysis | 6.00 | 6.00 | 0.00 | | Poster |
| 910 | Hot-Refresh Model Upgrades with Regression-Free Compatible Training in Image Retrieval | 5.75 | 6.00 | 0.25 | | Poster |
| 911 | A Statistical Framework for Efficient Out of Distribution Detection in Deep Neural Networks | 5.50 | 6.00 | 0.50 | | Poster |
| 912 | Transfer RL across Observation Feature Spaces via Model-Based Regularization | 5.25 | 6.00 | 0.75 | | Poster |
| 913 | A Theory of Tournament Representations | 5.25 | 6.00 | 0.75 | | Poster |
| 914 | Graph-Enhanced Exploration for Goal-oriented Reinforcement Learning | 5.50 | 6.00 | 0.50 | | Poster |
| 915 | Conditioning Sequence-to-sequence Networks with Learned Activations | 5.67 | 6.00 | 0.33 | | Poster |
| 916 | PSA-GAN: Progressive Self Attention GANs for Synthetic Time Series | 5.50 | 6.00 | 0.50 | | Poster |
| 917 | Controlling the Complexity and Lipschitz Constant improves Polynomial Nets | 6.00 | 6.00 | 0.00 | | Poster |
| 918 | Vector-quantized Image Modeling with Improved VQGAN | 5.50 | 6.00 | 0.50 | | Poster |
| 919 | Sample Efficient Stochastic Policy Extragradient Algorithm for Zero-Sum Markov Game | 5.60 | 6.00 | 0.40 | | 5, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
| Poster |
| 920 | Optimal Transport for Long-Tailed Recognition with Learnable Cost Matrix | 5.33 | 6.00 | 0.67 | | Poster |
| 921 | BadPre: Task-agnostic Backdoor Attacks to Pre-trained NLP Foundation Models | 6.00 | 6.00 | 0.00 | | Poster |
| 922 | Partial Wasserstein Adversarial Network for Non-rigid Point Set Registration | 5.80 | 6.00 | 0.20 | | 6, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
| Poster |
| 923 | Few-Shot Backdoor Attacks on Visual Object Tracking | 5.33 | 6.00 | 0.67 | | Poster |
| 924 | Generative Pseudo-Inverse Memory | 6.00 | 6.00 | 0.00 | | Poster |
| 925 | PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior | 5.00 | 6.00 | 1.00 | | Poster |
| 926 | How Attentive are Graph Attention Networks? | 6.00 | 6.00 | 0.00 | | Poster |
| 927 | Dropout Q-Functions for Doubly Efficient Reinforcement Learning | 4.67 | 6.00 | 1.33 | | Poster |
| 928 | Evaluating Disentanglement of Structured Latent Representations | 5.67 | 6.00 | 0.33 | | Poster |
| 929 | MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts | 5.67 | 6.00 | 0.33 | | Poster |
| 930 | iFlood: A Stable and Effective Regularizer | 5.25 | 6.00 | 0.75 | | Poster |
| 931 | An Operator Theoretic View On Pruning Deep Neural Networks | 6.25 | 6.00 | -0.25 | | Poster |
| 932 | Optimizer Amalgamation | 5.75 | 6.00 | 0.25 | | Poster |
| 933 | Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models | 5.33 | 6.00 | 0.67 | | Poster |
| 934 | Neural graphical modelling in continuous-time: consistency guarantees and algorithms | 6.50 | 6.00 | -0.50 | | Poster |
| 935 | Adaptive Wavelet Transformer Network for 3D Shape Representation Learning | 5.75 | 6.00 | 0.25 | | Poster |
| 936 | Transferable Adversarial Attack based on Integrated Gradients | 5.75 | 6.00 | 0.25 | | Poster |
| 937 | Learning Graphon Mean Field Games and Approximate Nash Equilibria | 6.00 | 6.00 | 0.00 | | Poster |
| 938 | Benchmarking the Spectrum of Agent Capabilities | 5.75 | 6.00 | 0.25 | | Poster |
| 939 | Generalisation in Lifelong Reinforcement Learning through Logical Composition | 4.67 | 5.83 | 1.17 | | 5, 3, 3, 6, 6, 5 | | 5, 5, 5, 8, 6, 6 |
| Poster |
| 940 | Graph-based Nearest Neighbor Search in Hyperbolic Spaces | 7.00 | 5.80 | -1.20 | | Poster |
| 941 | Why Propagate Alone? Parallel Use of Labels and Features on Graphs | 5.40 | 5.80 | 0.40 | | 5, 5, 3, 6, 8 | | 5, 5, 5, 6, 8 |
| Poster |
| 942 | Symbolic Learning to Optimize: Towards Interpretability and Scalability | 4.80 | 5.80 | 1.00 | | 6, 5, 3, 5, 5 | | 6, 6, 5, 6, 6 |
| Poster |
| 943 | Regularized Autoencoders for Isometric Representation Learning | 5.80 | 5.80 | 0.00 | | 6, 5, 5, 8, 5 | | 6, 5, 5, 8, 5 |
| Poster |
| 944 | Data Efficient Language-Supervised Zero-Shot Recognition with Optimal Transport Distillation | 5.40 | 5.80 | 0.40 | | 5, 5, 6, 5, 6 | | 5, 6, 6, 6, 6 |
| Poster |
| 945 | Relational Learning with Variational Bayes | 5.60 | 5.80 | 0.20 | | 5, 6, 5, 6, 6 | | 5, 6, 6, 6, 6 |
| Poster |
| 946 | Amortized Implicit Differentiation for Stochastic Bilevel Optimization | 5.60 | 5.80 | 0.20 | | 3, 6, 5, 8, 6 | | 3, 6, 6, 8, 6 |
| Poster |
| 947 | A Generalized Weighted Optimization Method for Computational Learning and Inversion | 5.25 | 5.80 | 0.55 | | Poster |
| 948 | Towards Empirical Sandwich Bounds on the Rate-Distortion Function | 4.25 | 5.75 | 1.50 | | Poster |
| 949 | Network Augmentation for Tiny Deep Learning | 5.25 | 5.75 | 0.50 | | Poster |
| 950 | QUERY-EFFICIENT DECISION-BASED SPARSE ATTACKS AGAINST BLACK-BOX MACHINE LEARNING MODELS | 5.75 | 5.75 | 0.00 | | Poster |
| 951 | Graph Condensation for Graph Neural Networks | 5.25 | 5.75 | 0.50 | | Poster |
| 952 | A Tale of Two Flows: Cooperative Learning of Langevin Flow and Normalizing Flow Toward Energy-Based Model | 5.50 | 5.75 | 0.25 | | Poster |
| 953 | An Information Fusion Approach to Learning with Instance-Dependent Label Noise | 5.50 | 5.75 | 0.25 | | Poster |
| 954 | From Intervention to Domain Transportation: A Novel Perspective to Optimize Recommendation | 5.67 | 5.75 | 0.08 | | Poster |
| 955 | GradMax: Growing Neural Networks using Gradient Information | 5.00 | 5.75 | 0.75 | | Poster |
| 956 | Provable Adaptation across Multiway Domains via Representation Learning | 5.25 | 5.75 | 0.50 | | Poster |
| 957 | Learning Efficient Online 3D Bin Packing on Packing Configuration Trees | 5.25 | 5.75 | 0.50 | | Poster |
| 958 | Bandit Learning with Joint Effect of Incentivized Sampling, Delayed Sampling Feedback, and Self-Reinforcing User Preferences | 5.00 | 5.75 | 0.75 | | Poster |
| 959 | A Comparison of Variable Selection Methods for Blockwise Diagonal Designs | 5.50 | 5.75 | 0.25 | | Poster |
| 960 | A Zest of LIME: Towards Architecture-Independent Model Distances | 5.25 | 5.75 | 0.50 | | Poster |
| 961 | Learn Locally, Correct Globally: A Distributed Algorithm for Training Graph Neural Networks | 5.50 | 5.75 | 0.25 | | Poster |
| 962 | Task-Induced Representation Learning | 4.75 | 5.75 | 1.00 | | Poster |
| 963 | Constructing Orthogonal Convolutions in an Explicit Manner | 5.33 | 5.75 | 0.42 | | Poster |
| 964 | Structure-Aware Transformer Policy for Inhomogeneous Multi-Task Reinforcement Learning | 5.50 | 5.75 | 0.25 | | Poster |
| 965 | FP-DETR: Detection Transformer Advanced by Fully Pre-training | 5.50 | 5.75 | 0.25 | | Poster |
| 966 | Reward Uncertainty for Exploration in Preference-based Reinforcement Learning | 4.00 | 5.75 | 1.75 | | Poster |
| 967 | Robust Unlearnable Examples: Protecting Data Privacy Against Adversarial Learning | 5.00 | 5.75 | 0.75 | | Poster |
| 968 | Rethinking Supervised Pre-Training for Better Downstream Transferring | 5.00 | 5.75 | 0.75 | | Poster |
| 969 | Geometric Transformers for Protein Interface Contact Prediction | 5.00 | 5.75 | 0.75 | | Poster |
| 970 | Should We Be Pre-training? An Argument for End-task Aware Training as an Alternative | 6.25 | 5.75 | -0.50 | | Poster |
| 971 | Diverse Client Selection for Federated Learning via Submodular Maximization | 5.75 | 5.75 | 0.00 | | Poster |
| 972 | Neural Energy Minimization for Molecular Conformation Optimization | 4.25 | 5.75 | 1.50 | | Poster |
| 973 | Towards Continual Knowledge Learning of Language Models | 5.75 | 5.75 | 0.00 | | Poster |
| 974 | Learning Generalizable Representations for Reinforcement Learning via Adaptive Meta-learner of Behavioral Similarities | 5.00 | 5.75 | 0.75 | | Poster |
| 975 | KL Guided Domain Adaptation | 5.25 | 5.75 | 0.50 | | Poster |
| 976 | CodeTrek: Flexible Modeling of Code using an Extensible Relational Representation | 5.00 | 5.75 | 0.75 | | Poster |
| 977 | Generalized Demographic Parity for Group Fairness | 4.75 | 5.75 | 1.00 | | Poster |
| 978 | Evaluating Language-biased image classification based on semantic compositionality | 5.75 | 5.75 | 0.00 | | Poster |
| 979 | ConFeSS: A Framework for Single Source Cross-Domain Few-Shot Learning | 5.75 | 5.75 | 0.00 | | Poster |
| 980 | Permutation Compressors for Provably Faster Distributed Nonconvex Optimization | 5.50 | 5.75 | 0.25 | | Poster |
| 981 | Distributionally Robust Fair Principal Components via Geodesic Descents | 5.75 | 5.75 | 0.00 | | Poster |
| 982 | DKM: Differentiable k-Means Clustering Layer for Neural Network Compression | 5.25 | 5.75 | 0.50 | | Poster |
| 983 | Variational Neural Cellular Automata | 4.75 | 5.75 | 1.00 | | Poster |
| 984 | On Covariate Shift of Latent Confounders in Imitation and Reinforcement Learning | 5.75 | 5.75 | 0.00 | | Poster |
| 985 | Towards Model Agnostic Federated Learning Using Knowledge Distillation | 5.25 | 5.75 | 0.50 | | Poster |
| 986 | Towards Building A Group-based Unsupervised Representation Disentanglement Framework | 5.50 | 5.75 | 0.25 | | Poster |
| 987 | Demystifying Limited Adversarial Transferability in Automatic Speech Recognition Systems | 5.75 | 5.75 | 0.00 | | Poster |
| 988 | Learning a subspace of policies for online adaptation in Reinforcement Learning | 5.00 | 5.75 | 0.75 | | Poster |
| 989 | Focus on the Common Good: Group Distributional Robustness Follows | 5.75 | 5.75 | 0.00 | | Poster |
| 990 | Adaptive Filters for Low-Latency and Memory-Efficient Graph Neural Networks | 5.75 | 5.75 | 0.00 | | Poster |
| 991 | GLASS: GNN with Labeling Tricks for Subgraph Representation Learning | 5.25 | 5.75 | 0.50 | | Poster |
| 992 | Data Poisoning Won’t Save You From Facial Recognition | 5.50 | 5.75 | 0.25 | | Poster |
| 993 | FILIP: Fine-grained Interactive Language-Image Pre-Training | 5.50 | 5.75 | 0.25 | | Poster |
| 994 | Deep Ensembling with No Overhead for either Training or Testing: The All-Round Blessings of Dynamic Sparsity | 5.25 | 5.75 | 0.50 | | Poster |
| 995 | Understanding approximate and unrolled dictionary learning for pattern recovery | 4.75 | 5.75 | 1.00 | | Poster |
| 996 | Variational oracle guiding for reinforcement learning | 5.50 | 5.75 | 0.25 | | Poster |
| 997 | HyperDQN: A Randomized Exploration Method for Deep Reinforcement Learning | 5.50 | 5.75 | 0.25 | | Poster |
| 998 | Towards Distribution Shift of Node-Level Prediction on Graphs: An Invariance Perspective | 4.75 | 5.75 | 1.00 | | Poster |
| 999 | Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space | 5.75 | 5.75 | 0.00 | | Poster |
| 1000 | Optimization inspired Multi-Branch Equilibrium Models | 5.50 | 5.75 | 0.25 | | Poster |
| 1001 | Constrained Physical-Statistics Models for Dynamical System Identification and Prediction | 5.50 | 5.75 | 0.25 | | Poster |
| 1002 | Imitation Learning by Reinforcement Learning | 5.75 | 5.75 | 0.00 | | Poster |
| 1003 | Exploring extreme parameter compression for pre-trained language models | 4.75 | 5.75 | 1.00 | | Poster |
| 1004 | Almost Tight L0-norm Certified Robustness of Top-k Predictions against Adversarial Perturbations | 6.50 | 5.75 | -0.75 | | Poster |
| 1005 | On the Importance of Difficulty Calibration in Membership Inference Attacks | 5.75 | 5.75 | 0.00 | | Poster |
| 1006 | Audio Lottery: Speech Recognition Made Ultra-Lightweight, Noise-Robust, and Transferable | 4.67 | 5.75 | 1.08 | | Poster |
| 1007 | Acceleration of Federated Learning with Alleviated Forgetting in Local Training | 5.25 | 5.75 | 0.50 | | Poster |
| 1008 | Learning Synthetic Environments and Reward Networks for Reinforcement Learning | 5.25 | 5.75 | 0.50 | | Poster |
| 1009 | Decentralized Learning for Overparameterized Problems: A Multi-Agent Kernel Approximation Approach | 4.67 | 5.67 | 1.00 | | Poster |
| 1010 | Graph-Relational Domain Adaptation | 5.33 | 5.67 | 0.33 | | Poster |
| 1011 | Imitation Learning from Observations under Transition Model Disparity | 5.00 | 5.67 | 0.67 | | Poster |
| 1012 | Meta Learning Low Rank Covariance Factors for Energy Based Deterministic Uncertainty | 5.00 | 5.67 | 0.67 | | Poster |
| 1013 | ZeroFL: Efficient On-Device Training for Federated Learning with Local Sparsity | 4.33 | 5.67 | 1.33 | | Poster |
| 1014 | EXACT: Scalable Graph Neural Networks Training via Extreme Activation Compression | 5.67 | 5.67 | 0.00 | | Poster |
| 1015 | Iterated Reasoning with Mutual Information in Cooperative and Byzantine Decentralized Teaming | 5.33 | 5.67 | 0.33 | | Poster |
| 1016 | Task Affinity with Maximum Bipartite Matching in Few-Shot Learning | 5.33 | 5.67 | 0.33 | | Poster |
| 1017 | Neural Spectral Marked Point Processes | 5.67 | 5.67 | 0.00 | | Poster |
| 1018 | Exploiting Class Activation Value for Partial-Label Learning | 5.33 | 5.67 | 0.33 | | Poster |
| 1019 | Towards Understanding the Data Dependency of Mixup-style Training | 5.67 | 5.67 | 0.00 | | Spotlight |
| 1020 | R5: Rule Discovery with Reinforced and Recurrent Relational Reasoning | 5.67 | 5.67 | 0.00 | | Spotlight |
| 1021 | Demystifying Batch Normalization in ReLU Networks: Equivalent Convex Optimization Models and Implicit Regularization | 5.67 | 5.67 | 0.00 | | Poster |
| 1022 | Closed-form Sample Probing for Learning Generative Models in Zero-shot Learning | 5.20 | 5.60 | 0.40 | | 6, 5, 5, 5, 5 | | 6, 6, 5, 6, 5 |
| Poster |
| 1023 | Graph Neural Network Guided Local Search for the Traveling Salesperson Problem | 5.40 | 5.60 | 0.20 | | 3, 8, 5, 3, 8 | | 3, 8, 6, 3, 8 |
| Poster |
| 1024 | Plant 'n' Seek: Can You Find the Winning Ticket? | 4.80 | 5.60 | 0.80 | | 3, 6, 5, 5, 5 | | 5, 6, 6, 5, 6 |
| Poster |
| 1025 | Pretrained Language Model in Continual Learning: A Comparative Study | 5.50 | 5.50 | 0.00 | | Poster |
| 1026 | Pre-training Molecular Graph Representation with 3D Geometry | 5.00 | 5.50 | 0.50 | | Poster |
| 1027 | Measuring the Interpretability of Unsupervised Representations via Quantized Reversed Probing | 5.25 | 5.50 | 0.25 | | Poster |
| 1028 | COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks | 5.00 | 5.50 | 0.50 | | Poster |
| 1029 | Diurnal or Nocturnal? Federated Learning of Multi-branch Networks from Periodically Shifting Distributions | 5.00 | 5.50 | 0.50 | | Poster |
| 1030 | PI3NN: Out-of-distribution-aware Prediction Intervals from Three Neural Networks | 5.00 | 5.50 | 0.50 | | Poster |
| 1031 | Towards Evaluating the Robustness of Neural Networks Learned by Transduction | 5.25 | 5.50 | 0.25 | | Poster |
| 1032 | Attacking deep networks with surrogate-based adversarial black-box methods is easy | 5.25 | 5.50 | 0.25 | | Poster |
| 1033 | Crystal Diffusion Variational Autoencoder for Periodic Material Generation | 5.50 | 5.50 | 0.00 | | Poster |
| 1034 | New Insights on Reducing Abrupt Representation Change in Online Continual Learning | 5.50 | 5.50 | 0.00 | | Poster |
| 1035 | Object Pursuit: Building a Space of Objects via Discriminative Weight Generation | 5.25 | 5.50 | 0.25 | | Poster |
| 1036 | Learning State Representations via Retracing in Reinforcement Learning | 5.00 | 5.50 | 0.50 | | Poster |
| 1037 | Understanding and Leveraging Overparameterization in Recursive Value Estimation | 4.75 | 5.50 | 0.75 | | Poster |
| 1038 | The Role of Pretrained Representations for the OOD Generalization of RL Agents | 4.50 | 5.50 | 1.00 | | Poster |
| 1039 | Contrastive Learning is Just Meta-Learning | 5.50 | 5.50 | 0.00 | | Poster |
| 1040 | Non-Linear Operator Approximations for Initial Value Problems | 5.00 | 5.50 | 0.50 | | Poster |
| 1041 | Tuformer: Data-Driven Design of Expressive Transformer by Tucker Tensor Representation | 5.25 | 5.50 | 0.25 | | Poster |
| 1042 | Bayesian Modeling and Uncertainty Quantification for Learning to Optimize: What, Why, and How | 4.75 | 5.50 | 0.75 | | Poster |
| 1043 | Reducing the Communication Cost of Federated Learning through Multistage Optimization | 5.75 | 5.50 | -0.25 | | Poster |
| 1044 | Scattering Networks on the Sphere for Scalable and Rotationally Equivariant Spherical CNNs | 5.00 | 5.50 | 0.50 | | Poster |
| 1045 | Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations | 5.50 | 5.50 | 0.00 | | Poster |
| 1046 | Causal Contextual Bandits with Targeted Interventions | 5.50 | 5.50 | 0.00 | | Poster |
| 1047 | LFPT5: A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5 | 5.00 | 5.50 | 0.50 | | Poster |
| 1048 | Stability Regularization for Discrete Representation Learning | 5.50 | 5.50 | 0.00 | | Poster |
| 1049 | Divergence-aware Federated Self-Supervised Learning | 5.00 | 5.50 | 0.50 | | Poster |
| 1050 | Learning to Guide and to be Guided in the Architect-Builder Problem | 5.50 | 5.50 | 0.00 | | Poster |
| 1051 | Dynamic Token Normalization improves Vision Transformers | 5.25 | 5.50 | 0.25 | | Poster |
| 1052 | Associated Learning: an Alternative to End-to-End Backpropagation that Works on CNN, RNN, and Transformer | 5.25 | 5.50 | 0.25 | | Poster |
| 1053 | ADAVI: Automatic Dual Amortized Variational Inference Applied To Pyramidal Bayesian Models | 5.25 | 5.50 | 0.25 | | Poster |
| 1054 | Bayesian Neural Network Priors Revisited | 5.50 | 5.50 | 0.00 | | Poster |
| 1055 | Certified Robustness for Deep Equilibrium Models via Interval Bound Propagation | 6.00 | 5.50 | -0.50 | | Poster |
| 1056 | Representation-Agnostic Shape Fields | 5.50 | 5.50 | 0.00 | | Poster |
| 1057 | Revisit Kernel Pruning with Lottery Regulated Grouped Convolutions | 4.80 | 5.40 | 0.60 | | 5, 6, 5, 3, 5 | | 5, 6, 5, 5, 6 |
| Poster |
| 1058 | Minimax Optimality (Probably) Doesn't Imply Distribution Learning for GANs | 5.20 | 5.40 | 0.20 | | 6, 3, 5, 6, 6 | | 6, 3, 6, 6, 6 |
| Poster |
| 1059 | Discovering Nonlinear PDEs from Scarce Data with Physics-encoded Learning | 5.00 | 5.40 | 0.40 | | 3, 3, 8, 5, 6 | | 5, 5, 6, 5, 6 |
| Poster |
| 1060 | Unraveling Model-Agnostic Meta-Learning via The Adaptation Learning Rate | 5.20 | 5.40 | 0.20 | | 6, 5, 5, 5, 5 | | 6, 6, 5, 5, 5 |
| Poster |
| 1061 | Missingness Bias in Model Debugging | 5.33 | 5.33 | 0.00 | | Poster |
| 1062 | Unsupervised Learning of Full-Waveform Inversion: Connecting CNN and Partial Differential Equation in a Loop | 5.33 | 5.33 | 0.00 | | Poster |
| 1063 | Fooling Explanations in Text Classifiers | 5.33 | 5.33 | 0.00 | | Poster |
| 1064 | ClimateGAN: Raising Climate Change Awareness by Generating Images of Floods | 4.67 | 5.33 | 0.67 | | Poster |
| 1065 | Robust and Scalable SDE Learning: A Functional Perspective | 5.33 | 5.33 | 0.00 | | Poster |
| 1066 | AS-MLP: An Axial Shifted MLP Architecture for Vision | 5.00 | 5.33 | 0.33 | | Poster |
| 1067 | Zero-Shot Self-Supervised Learning for MRI Reconstruction | 5.33 | 5.33 | 0.00 | | Poster |
| 1068 | Representing Mixtures of Word Embeddings with Mixtures of Topic Embeddings | 5.25 | 5.25 | 0.00 | | Poster |
| 1069 | A fast and accurate splitting method for optimal transport: analysis and implementation | 5.25 | 5.25 | 0.00 | | Poster |
| 1070 | Cross-Trajectory Representation Learning for Zero-Shot Generalization in RL | 5.00 | 5.25 | 0.25 | | Poster |
| 1071 | Visual hyperacuity with moving sensor and recurrent neural computations | 4.75 | 5.25 | 0.50 | | Poster |
| 1072 | Consistent Counterfactuals for Deep Models | 5.00 | 5.25 | 0.25 | | Poster |
| 1073 | Neural Network Approximation based on Hausdorff distance of Zonotopes | 5.25 | 5.25 | 0.00 | | Poster |
| 1074 | Practical Integration via Separable Bijective Networks | 5.00 | 5.25 | 0.25 | | Poster |
| 1075 | VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning | 5.00 | 5.25 | 0.25 | | Poster |
| 1076 | Maximizing Ensemble Diversity in Deep Reinforcement Learning | 5.00 | 5.25 | 0.25 | | Poster |
| 1077 | Memory Replay with Data Compression for Continual Learning | 5.25 | 5.25 | 0.00 | | Poster |
| 1078 | Model Agnostic Interpretability for Multiple Instance Learning | 3.50 | 5.25 | 1.75 | | Poster |
| 1079 | Towards General Function Approximation in Zero-Sum Markov Games | 5.25 | 5.25 | 0.00 | | Poster |
| 1080 | Visual Representation Learning over Latent Domains | 5.25 | 5.25 | 0.00 | | Poster |
| 1081 | Sequential Reptile: Inter-Task Gradient Alignment for Multilingual Learning | 5.25 | 5.25 | 0.00 | | Poster |
| 1082 | Overcoming The Spectral Bias of Neural Value Approximation | 4.00 | 5.00 | 1.00 | | Poster |
| 1083 | FairCal: Fairness Calibration for Face Verification | 4.67 | 5.00 | 0.33 | | Poster |
| 1084 | CROP: Certifying Robust Policies for Reinforcement Learning through Functional Smoothing | 4.25 | 5.00 | 0.75 | | Poster |
| 1085 | Efficient Split-Mix Federated Learning for On-Demand and In-Situ Customization | 5.00 | 5.00 | 0.00 | | Poster |
| 1086 | Information Gain Propagation: a New Way to Graph Active Learning with Soft Labels | 5.50 | 5.00 | -0.50 | | Poster |
| 1087 | CoMPS: Continual Meta Policy Search | 4.80 | 5.00 | 0.20 | | 3, 5, 8, 5, 3 | | 3, 5, 6, 5, 6 |
| Poster |
| 1088 | Learning Continuous Environment Fields via Implicit Functions | 5.00 | 5.00 | 0.00 | | Poster |
| 1089 | Towards Understanding Generalization via Decomposing Excess Risk Dynamics | 5.00 | 5.00 | 0.00 | | Poster |
| 1090 | Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation | 5.00 | 5.00 | 0.00 | | Oral |
| 1091 | ComPhy: Compositional Physical Reasoning of Objects and Events from Videos | 4.75 | 5.00 | 0.25 | | Poster |
| 1092 | Transformer Embeddings of Irregularly Spaced Events and Their Participants | 4.25 | 4.75 | 0.50 | | Poster |
| 1093 | Topologically Regularized Data Embeddings | 4.75 | 4.75 | 0.00 | | Poster |
| 1094 | Neural Program Synthesis with Query | 4.00 | 4.67 | 0.67 | | Poster |
| 1095 | Learning by Directional Gradient Descent | 4.00 | 4.50 | 0.50 | | Poster |
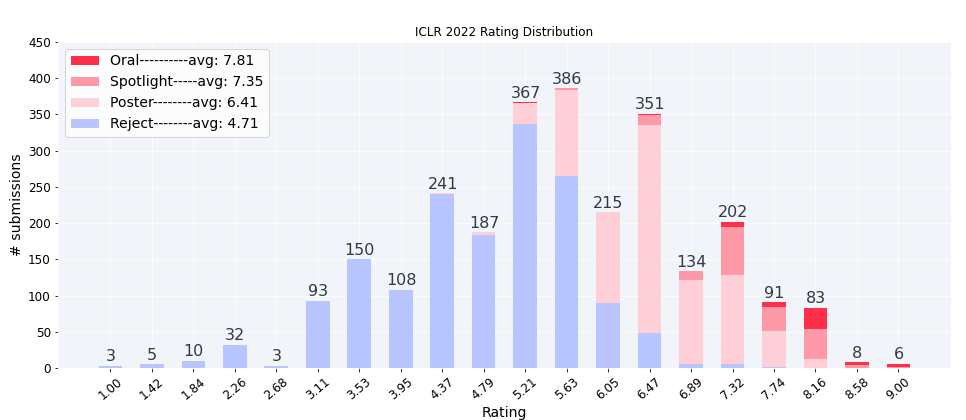
 /
/ ) to get submission info quickly.
) to get submission info quickly.