| 1 | Meta Continual Learning Revisited: Implicitly Enhancing Online Hessian Approximation via Variance Reduction | 6.67 | 8.67 | 0.94 | 2.00 | |
| 2 | BooookScore: A systematic exploration of book-length summarization in the era of LLMs | 7.50 | 8.50 | 0.87 | 1.00 | |
| 3 | Generalization in diffusion models arises from geometry-adaptive harmonic representation | 8.50 | 8.50 | 0.87 | 0.00 | |
| 4 | Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness | 7.50 | 8.50 | 0.87 | 1.00 | |
| 5 | Privileged Sensing Scaffolds Reinforcement Learning | 7.75 | 8.50 | 0.87 | 0.75 | |
| 6 | Monte Carlo guided Denoising Diffusion models for Bayesian linear inverse problems. | 8.50 | 8.50 | 1.66 | 0.00 | |
| 7 | LRM: Large Reconstruction Model for Single Image to 3D | 7.50 | 8.50 | 0.87 | 1.00 | |
| 8 | The mechanistic basis of data dependence and abrupt learning in an in-context classification task | 8.25 | 9.00 | 1.00 | 0.75 | |
| 9 | Test-time Adaption against Multi-modal Reliability Bias | 7.00 | 8.00 | 0.00 | 1.00 | |
| 10 | Generalization error of spectral algorithms | 8.00 | 8.00 | 0.00 | 0.00 | |
| 11 | Learning to Relax: Setting Solver Parameters Across a Sequence of Linear System Instances | 7.50 | 8.00 | 0.00 | 0.50 | |
| 12 | A Benchmark on Robust Semi-Supervised Learning in Open Environments | 8.00 | 8.00 | 0.00 | 0.00 | |
| 13 | Predictive auxiliary objectives in deep RL mimic learning in the brain | 6.33 | 8.00 | 0.00 | 1.67 | |
| 14 | Large Language Models to Enhance Bayesian Optimization | 5.75 | 8.00 | 0.00 | 2.25 | |
| 15 | Distributionally Robust Optimization with Bias & Variance Reduced Gradients | 7.00 | 8.00 | 0.00 | 1.00 | |
| 16 | Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors | 6.50 | 8.00 | 0.00 | 1.50 | |
| 17 | A Policy Gradient Method for Confounded POMDPs | 6.50 | 8.00 | 0.00 | 1.50 | |
| 18 | GraphGuard: Provably Robust Graph Classification against Adversarial Attacks | 6.33 | 8.00 | 0.00 | 1.67 | |
| 19 | Identifying Representations for Intervention Extrapolation | 7.50 | 8.00 | 0.00 | 0.50 | |
| 20 | Deep Orthogonal Hypersphere Compression for Anomaly Detection | 8.00 | 8.00 | 0.00 | 0.00 | |
| 21 | ClimODE: Climate Forecasting With Physics-informed Neural ODEs | 7.00 | 8.00 | 0.00 | 1.00 | |
| 22 | CAS: A Probability-Based Approach for Universal Condition Alignment Score | 5.67 | 8.00 | 0.00 | 2.33 | |
| 23 | Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement | 7.00 | 8.00 | 0.00 | 1.00 | |
| 24 | Language Model Beats Diffusion - Tokenizer is key to visual generation | 8.00 | 8.00 | 0.00 | 0.00 | |
| 25 | Online GNN Evaluation Under Test-time Graph Distribution Shifts | 7.50 | 8.00 | 0.00 | 0.50 | |
| 26 | Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks | 6.75 | 8.50 | 0.87 | 1.75 | |
| 27 | Learning Hierarchical Image Segmentation For Recognition and By Recognition | 7.50 | 8.00 | 1.41 | 0.50 | |
| 28 | Protein Discovery with Discrete Walk-Jump Sampling | 7.33 | 8.00 | 0.00 | 0.67 | |
| 29 | Batched Low-Rank Adaptation of Foundation Models | 7.50 | 8.00 | 0.00 | 0.50 | |
| 30 | One-shot Empirical Privacy Estimation for Federated Learning | 5.67 | 8.00 | 0.00 | 2.33 | |
| 31 | Learning to Reject for Balanced Error and Beyond | 7.50 | 8.00 | 0.00 | 0.50 | |
| 32 | Curiosity-driven Red-teaming for Large Language Models | 5.75 | 8.00 | 0.00 | 2.25 | |
| 33 | Topological data analysis on noisy quantum computers | 7.25 | 8.00 | 0.00 | 0.75 | |
| 34 | Generative Modeling with Phase Stochastic Bridge | 7.50 | 8.00 | 0.00 | 0.50 | |
| 35 | EQA-MX: Embodied Question Answering using Multimodal Expression | 6.25 | 8.00 | 0.00 | 1.75 | |
| 36 | Latent Representation and Simulation of Markov Processes via Time-Lagged Information Bottleneck | 6.67 | 8.00 | 0.00 | 1.33 | |
| 37 | Solving Multiobjective Combinatorial Optimization via Learn to Improve Method | 5.50 | 7.50 | 0.87 | 2.00 | |
| 38 | Q-TAPE: A Task-Agnostic Pre-Trained Approach for Quantum Properties Estimation | 5.75 | 8.00 | 0.00 | 2.25 | |
| 39 | Magnushammer: A Transformer-Based Approach to Premise Selection | 7.50 | 8.00 | 0.00 | 0.50 | |
| 40 | ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis | 7.00 | 8.00 | 0.00 | 1.00 | |
| 41 | Algorithms for Caching and MTS with reduced number of predictions | 8.00 | 8.00 | 0.00 | 0.00 | |
| 42 | Turning large language models into cognitive models | 6.75 | 8.00 | 0.00 | 1.25 | |
| 43 | Exploring the Common Appearance-Boundary Adaptation for Nighttime Optical Flow | 8.00 | 8.00 | 1.63 | 0.00 | |
| 44 | Knowledge Card: Filling LLMs' Knowledge Gaps with Plug-in Specialized Language Models | 6.33 | 8.00 | 0.00 | 1.67 | |
| 45 | FITS: Modeling Time Series with $10k$ Parameters | 6.50 | 8.00 | 0.00 | 1.50 | |
| 46 | MOFDiff: Coarse-grained Diffusion for Metal-Organic Framework Design | 6.75 | 8.00 | 0.00 | 1.25 | |
| 47 | Large Language Models are Efficient Learners of Noise-Robust Speech Recognition | 8.00 | 8.00 | 1.41 | 0.00 | |
| 48 | Sample-Efficient Quality-Diversity by Cooperative Coevolution | 4.67 | 8.00 | 0.00 | 3.33 | |
| 49 | Flow Matching on General Geometries | 7.33 | 8.00 | 0.00 | 0.67 | |
| 50 | Dynamic Discounted Counterfactual Regret Minimization | 7.50 | 8.00 | 0.00 | 0.50 | |
| 51 | GenSim: Generating Robotic Simulation Tasks via Large Language Models | 7.50 | 8.00 | 0.00 | 0.50 | |
| 52 | Small-scale proxies for large-scale Transformer training instabilities | 7.25 | 8.00 | 0.00 | 0.75 | |
| 53 | Vision Transformers Need Registers | 8.00 | 8.00 | 0.00 | 0.00 | |
| 54 | Beyond Linear Spherical Interpolation: Noise Correction for Image Interpolation with Diffusion Models | 6.33 | 8.00 | 0.00 | 1.67 | |
| 55 | SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis | 8.00 | 8.00 | 0.00 | 0.00 | |
| 56 | Inherently Interpretable Time Series Classification via Multiple Instance Learning | 7.50 | 8.00 | 0.00 | 0.50 | |
| 57 | Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation | 7.25 | 8.00 | 0.00 | 0.75 | |
| 58 | Learning Energy Decompositions for Partial Inference of GFlowNets | 6.25 | 8.00 | 0.00 | 1.75 | |
| 59 | Approximating Nash Equilibria in Normal-Form Games via Stochastic Optimization | 8.00 | 8.00 | 0.00 | 0.00 | |
| 60 | Multi-Source Diffusion Models for Simultaneous Music Generation and Separation | 8.00 | 8.00 | 0.00 | 0.00 | |
| 61 | How Over-Parameterization Slows Down Gradient Descent in Matrix Sensing: The Curses of Symmetry and Initialization | 6.75 | 8.00 | 0.00 | 1.25 | |
| 62 | Mastering Memory Tasks with World Models | 6.33 | 8.00 | 1.63 | 1.67 | |
| 63 | Self-Alignment with Instruction Backtranslation | 8.00 | 8.00 | 0.00 | 0.00 | |
| 64 | Universal Graph Random Features | 5.75 | 8.00 | 0.00 | 2.25 | |
| 65 | Scaling Laws of RoPE-based Extrapolation | 6.00 | 8.00 | 1.63 | 2.00 | |
| 66 | CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling | 7.33 | 8.00 | 0.00 | 0.67 | |
| 67 | MovingParts: Motion-based 3D Part Discovery in Dynamic Radiance Field | 5.50 | 8.00 | 0.00 | 2.50 | |
| 68 | Diffusion Model for Dense Matching | 6.50 | 8.00 | 0.00 | 1.50 | |
| 69 | Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models | 6.67 | 8.00 | 0.00 | 1.33 | |
| 70 | PTaRL: Prototype-based Tabular Representation Learning via Space Calibration | 6.67 | 8.00 | 0.00 | 1.33 | |
| 71 | Latent Trajectory Learning for Limited Timestamps under Distribution Shift over Time | 6.75 | 8.00 | 0.00 | 1.25 | |
| 72 | Flexible Residual Binarization for Image Super-Resolution | 6.50 | 8.00 | 0.00 | 1.50 | |
| 73 | Detecting, Explaining, and Mitigating Memorization in Diffusion Models | 7.50 | 8.00 | 0.00 | 0.50 | |
| 74 | Quick-Tune: Quickly Learning Which Pretrained Model to Finetune and How | 7.50 | 8.00 | 0.00 | 0.50 | |
| 75 | How to Capture Higher-order Correlations? Generalizing Matrix Softmax Attention to Kronecker Computation | 7.33 | 8.00 | 0.00 | 0.67 | |
| 76 | GIM: Learning Generalizable Image Matcher From Internet Videos | 8.00 | 8.00 | 1.41 | 0.00 | |
| 77 | SyncDreamer: Generating Multiview-consistent Images from a Single-view Image | 7.60 | 8.00 | 1.26 | 0.40 | | 8, 10, 8, 6, 6 | | 8, 10, 8, 8, 6 |
|
| 78 | Interpreting CLIP's Image Representation via Text-Based Decomposition | 7.00 | 8.00 | 0.00 | 1.00 | |
| 79 | Noisy Interpolation Learning with Shallow Univariate ReLU Networks | 8.00 | 8.00 | 0.00 | 0.00 | |
| 80 | DMV3D: Denoising Multi-view Diffusion Using 3D Large Reconstruction Model | 6.75 | 8.00 | 1.41 | 1.25 | |
| 81 | PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction | 5.50 | 8.00 | 0.00 | 2.50 | |
| 82 | TD-MPC2: Scalable, Robust World Models for Continuous Control | 7.00 | 8.00 | 0.00 | 1.00 | |
| 83 | Stochastic Controlled Averaging for Federated Learning with Communication Compression | 6.67 | 8.00 | 0.00 | 1.33 | |
| 84 | Universal Humanoid Motion Representations for Physics-Based Control | 7.33 | 8.00 | 0.00 | 0.67 | |
| 85 | CrIBo: Self-Supervised Learning via Cross-Image Object-Level Bootstrapping | 7.25 | 8.00 | 1.41 | 0.75 | |
| 86 | Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis | 6.25 | 8.00 | 0.00 | 1.75 | |
| 87 | Robust Classification via a Single Diffusion Model | 6.67 | 8.00 | 0.00 | 1.33 | |
| 88 | Multi-granularity Correspondence Learning from Noisy Instructional Videos | 7.50 | 8.00 | 0.00 | 0.50 | |
| 89 | Variational Bayesian Last Layers | 6.50 | 8.00 | 1.41 | 1.50 | |
| 90 | Implicit bias of SGD in $L_2$-regularized linear DNNs: One-way jumps from high to low rank | 7.25 | 7.75 | 1.79 | 0.50 | |
| 91 | Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs | 7.25 | 7.75 | 1.79 | 0.50 | |
| 92 | Towards a statistical theory of data selection under weak supervision | 7.25 | 7.75 | 1.79 | 0.50 | |
| 93 | Differentiable Trajectory Optimization as a Policy Class for Reinforcement and Imitation Learning | 7.75 | 8.00 | 1.41 | 0.25 | |
| 94 | Amortizing intractable inference in large language models | 7.25 | 7.75 | 1.79 | 0.50 | |
| 95 | Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs | 6.83 | 7.67 | 0.75 | 0.83 | | 5, 6, 8, 6, 8, 8 | | 8, 6, 8, 8, 8, 8 |
|
| 96 | High-dimensional SGD aligns with emerging outlier eigenspaces | 7.50 | 7.67 | 1.37 | 0.17 | | 10, 8, 8, 6, 8, 5 | | 10, 8, 8, 6, 8, 6 |
|
| 97 | Spectrally Transformed Kernel Regression | 6.80 | 8.00 | 0.00 | 1.20 | | 6, 6, 8, 6, 8 | | 8, 8, 8, 8, 8 |
|
| 98 | When can transformers reason with abstract symbols? | 6.60 | 7.60 | 0.80 | 1.00 | | 8, 5, 8, 6, 6 | | 8, 6, 8, 8, 8 |
|
| 99 | Scaling Laws for Associative Memories | 7.00 | 7.60 | 0.80 | 0.60 | | 8, 8, 3, 8, 8 | | 8, 8, 6, 8, 8 |
|
| 100 | Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video | 6.40 | 7.60 | 0.80 | 1.20 | | 5, 8, 8, 5, 6 | | 8, 8, 8, 6, 8 |
|
| 101 | Space and time continuous physics simulation from partial observations | 7.00 | 7.60 | 0.80 | 0.60 | | 8, 5, 8, 6, 8 | | 8, 8, 8, 6, 8 |
|
| 102 | Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning | 6.50 | 7.50 | 0.87 | 1.00 | |
| 103 | Improving Generalization of Alignment with Human Preferences through Group Invariant Learning | 6.50 | 7.50 | 1.66 | 1.00 | |
| 104 | Policy Rehearsing: Training Generalizable Policies for Reinforcement Learning | 6.25 | 7.50 | 0.87 | 1.25 | |
| 105 | PINNACLE: PINN Adaptive ColLocation and Experimental points selection | 6.75 | 7.50 | 0.87 | 0.75 | |
| 106 | Generative Adversarial Inverse Multiagent Learning | 6.75 | 7.50 | 1.66 | 0.75 | |
| 107 | AMAGO: Scalable In-Context Reinforcement Learning for Adaptive Agents | 6.50 | 7.50 | 0.87 | 1.00 | |
| 108 | Memorization Capacity of Multi-Head Attention in Transformers | 6.75 | 7.50 | 0.87 | 0.75 | |
| 109 | Jointly-Learned Exit and Inference for a Dynamic Neural Network | 5.75 | 7.50 | 0.87 | 1.75 | |
| 110 | In-Context Pretraining: Language Modeling Beyond Document Boundaries | 7.00 | 7.50 | 0.87 | 0.50 | |
| 111 | Sparse MoE with Language Guided Routing for Multilingual Machine Translation | 6.50 | 7.50 | 0.87 | 1.00 | |
| 112 | Role of Locality and Weight Sharing in Image-Based Tasks: A Sample Complexity Separation between CNNs, LCNs, and FCNs | 5.50 | 7.50 | 0.87 | 2.00 | |
| 113 | Estimating Shape Distances on Neural Representations with Limited Samples | 6.75 | 7.50 | 1.66 | 0.75 | |
| 114 | Closing the Curious Case of Neural Text Degeneration | 7.00 | 7.50 | 0.87 | 0.50 | |
| 115 | Consistent algorithms for multi-label classification with macro-at-$k$ metrics | 6.50 | 7.50 | 0.87 | 1.00 | |
| 116 | Towards Optimal Regret in Adversarial Linear MDPs with Bandit Feedback | 7.00 | 7.50 | 0.87 | 0.50 | |
| 117 | CABINET: Content Relevance-based Noise Reduction for Table Question Answering | 6.25 | 8.00 | 0.00 | 1.75 | |
| 118 | Safe RLHF: Safe Reinforcement Learning from Human Feedback | 5.75 | 7.50 | 0.87 | 1.75 | |
| 119 | Feasibility-Guided Safe Offline Reinforcement Learning | 6.25 | 7.50 | 0.87 | 1.25 | |
| 120 | Querying Easily Flip-flopped Samples for Deep Active Learning | 6.25 | 7.50 | 1.66 | 1.25 | |
| 121 | Asymptotically Free Sketched Ridge Ensembles: Risks, Cross-Validation, and Tuning | 7.50 | 7.50 | 0.87 | 0.00 | |
| 122 | COLLIE: Systematic Construction of Constrained Text Generation Tasks | 7.25 | 7.50 | 1.66 | 0.25 | |
| 123 | Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training | 7.50 | 7.50 | 0.87 | 0.00 | |
| 124 | A Probabilistic Framework for Modular Continual Learning | 6.50 | 7.50 | 0.87 | 1.00 | |
| 125 | Massively Scalable Inverse Reinforcement Learning for Route Optimization | 6.50 | 7.50 | 1.66 | 1.00 | |
| 126 | On the Joint Interaction of Models, Data, and Features | 6.75 | 7.50 | 0.87 | 0.75 | |
| 127 | Understanding prompt engineering may not require rethinking generalization | 6.00 | 7.50 | 0.87 | 1.50 | |
| 128 | Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection | 7.50 | 7.50 | 0.87 | 0.00 | |
| 129 | Privacy Amplification for Matrix Mechanisms | 7.00 | 7.50 | 0.87 | 0.50 | |
| 130 | Exploiting Causal Graph Priors with Posterior Sampling for Reinforcement Learning | 7.00 | 7.50 | 0.87 | 0.50 | |
| 131 | Revitalizing Channel-dimension Fourier Transform for Image Enhancement | 8.50 | 7.50 | 1.66 | -1.00 | |
| 132 | Optimal Sample Complexity of Contrastive Learning | 7.50 | 7.50 | 0.87 | 0.00 | |
| 133 | Post-hoc bias scoring is optimal for fair classification | 6.75 | 7.50 | 0.87 | 0.75 | |
| 134 | Diffusion Generative Flow Samplers: Improving learning signals through partial trajectory optimization | 6.25 | 7.50 | 0.87 | 1.25 | |
| 135 | CAMIL: Context-Aware Multiple Instance Learning for Cancer Detection and Subtyping in Whole Slide Images | 6.00 | 7.50 | 0.87 | 1.50 | |
| 136 | Zipformer: A faster and better encoder for automatic speech recognition | 7.50 | 7.50 | 0.87 | 0.00 | |
| 137 | Faster Approximation of Probabilistic and Distributional Values via Least Squares | 6.25 | 7.50 | 0.87 | 1.25 | |
| 138 | Maximum Entropy Heterogeneous-Agent Reinforcement Learning | 6.75 | 7.50 | 0.87 | 0.75 | |
| 139 | The Curse of Diversity in Ensemble-Based Exploration | 7.25 | 7.50 | 0.87 | 0.25 | |
| 140 | DisenBooth: Identity-Preserving Disentangled Tuning for Subject-Driven Text-to-Image Generation | 6.25 | 7.50 | 0.87 | 1.25 | |
| 141 | Revealing the Mystery of Distribution Correction Estimation via Orthogonal-gradient Update | 7.00 | 7.50 | 0.87 | 0.50 | |
| 142 | Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning | 6.75 | 7.50 | 0.87 | 0.75 | |
| 143 | Negative Label Guided OOD Detection with Pretrained Vision-Language Models | 6.50 | 7.50 | 0.87 | 1.00 | |
| 144 | On Double-Descent in Reinforcement Learning with LSTD and Random Features | 7.00 | 7.50 | 1.66 | 0.50 | |
| 145 | Bounding Box Stability against Feature Dropout Reflects Detector Generalization across Environments | 7.25 | 7.50 | 1.66 | 0.25 | |
| 146 | NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers | 7.00 | 7.50 | 0.87 | 0.50 | |
| 147 | A representation-learning game for classes of prediction tasks | 6.75 | 7.50 | 0.87 | 0.75 | |
| 148 | Neuron-Enhanced AutoEncoder Matrix Completion: Theory and Practice | 6.75 | 7.50 | 0.87 | 0.75 | |
| 149 | Sample-Efficient Linear Representation Learning from Non-IID Non-Isotropic Data | 6.25 | 7.50 | 0.87 | 1.25 | |
| 150 | An Efficient Membership Inference Attack for the Diffusion Model by Proximal Initialization | 7.50 | 7.50 | 0.87 | 0.00 | |
| 151 | METRA: Scalable Unsupervised RL with Metric-Aware Abstraction | 7.00 | 7.50 | 0.87 | 0.50 | |
| 152 | From Graphs to Hypergraphs: Hypergraph Projection and its Remediation | 6.75 | 7.50 | 0.87 | 0.75 | |
| 153 | Distort, Distract, Decode: Instruction-Tuned Model Can Refine its Response from Noisy Instructions | 5.75 | 7.50 | 0.87 | 1.75 | |
| 154 | Towards Non-Asymptotic Convergence for Diffusion-Based Generative Models | 7.00 | 7.50 | 0.87 | 0.50 | |
| 155 | Improving Convergence and Generalization Using Parameter Symmetries | 7.25 | 7.50 | 0.87 | 0.25 | |
| 156 | A Versatile Causal Discovery Framework to Allow Causally-Related Hidden Variables | 7.50 | 7.50 | 0.87 | 0.00 | |
| 157 | Provable Offline Preference-Based Reinforcement Learning | 6.25 | 7.50 | 0.87 | 1.25 | |
| 158 | Provable Reward-Agnostic Preference-Based Reinforcement Learning | 6.75 | 7.50 | 0.87 | 0.75 | |
| 159 | Unleashing the Potential of Fractional Calculus in Graph Neural Networks with FROND | 5.75 | 7.50 | 0.87 | 1.75 | |
| 160 | On Error Propagation of Diffusion Models | 6.25 | 7.50 | 0.87 | 1.25 | |
| 161 | Evaluating the Zero-shot Robustness of Instruction-tuned Language Models | 6.75 | 7.50 | 0.87 | 0.75 | |
| 162 | MOTOR: A Time-To-Event Foundation Model For Structured Medical Records | 7.50 | 7.50 | 0.87 | 0.00 | |
| 163 | SE(3)-Stochastic Flow Matching for Protein Backbone Generation | 6.75 | 7.50 | 0.87 | 0.75 | |
| 164 | DP-OPT: Make Large Language Model Your Differentially-Private Prompt Engineer | 5.50 | 7.50 | 0.87 | 2.00 | |
| 165 | Depthwise Hyperparameter Transfer in Residual Networks: Dynamics and Scaling Limit | 7.50 | 7.50 | 0.87 | 0.00 | |
| 166 | How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models | 7.50 | 7.50 | 0.87 | 0.00 | |
| 167 | From Sparse to Soft Mixtures of Experts | 7.50 | 7.50 | 0.87 | 0.00 | |
| 168 | Entity-Centric Reinforcement Learning for Object Manipulation from Pixels | 6.00 | 7.50 | 0.87 | 1.50 | |
| 169 | MMD Graph Kernel: Effective Metric Learning for Graphs via Maximum Mean Discrepancy | 6.25 | 7.50 | 0.87 | 1.25 | |
| 170 | SGD Finds then Tunes Features in Two-Layer Neural Networks with near-Optimal Sample Complexity: A Case Study in the XOR problem | 7.25 | 7.50 | 0.87 | 0.25 | |
| 171 | LEGO-Prover: Neural Theorem Proving with Growing Libraries | 5.50 | 7.50 | 0.87 | 2.00 | |
| 172 | SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores | 6.75 | 7.50 | 0.87 | 0.75 | |
| 173 | RealChat-1M: A Large-Scale Real-World LLM Conversation Dataset | 7.50 | 7.50 | 0.87 | 0.00 | |
| 174 | Fast Imitation via Behavior Foundation Models | 7.33 | 7.50 | 0.87 | 0.17 | |
| 175 | Learning Interactive Real-World Simulators | 6.75 | 7.50 | 0.87 | 0.75 | |
| 176 | Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement Learning | 6.75 | 7.50 | 0.87 | 0.75 | |
| 177 | Candidate Label Set Pruning: A Data-centric Perspective for Deep Partial-label Learning | 7.00 | 7.50 | 0.87 | 0.50 | |
| 178 | NuwaDynamics: Discovering and Updating in Causal Spatio-Temporal Modeling | 6.50 | 7.50 | 1.66 | 1.00 | |
| 179 | Robust agents learn causal world models | 7.00 | 8.00 | 1.41 | 1.00 | |
| 180 | Image2Sentence based Asymmetrical Zero-shot Composed Image Retrieval | 5.25 | 7.50 | 0.87 | 2.25 | |
| 181 | Fast and unified path gradient estimators for normalizing flows | 6.00 | 7.50 | 0.87 | 1.50 | |
| 182 | Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction | 7.00 | 8.00 | 0.00 | 1.00 | |
| 183 | Towards Reliable and Efficient Backdoor Trigger Inversion via Decoupling Benign Features | 5.75 | 7.50 | 0.87 | 1.75 | |
| 184 | Less is More: Fewer Interpretable Region via Submodular Subset Selection | 6.00 | 7.50 | 0.87 | 1.50 | |
| 185 | Training-free Linear Image Inversion via Flows | 6.25 | 7.50 | 0.87 | 1.25 | |
| 186 | $mathcal{B}$-Coder: On Value-Based Deep Reinforcement Learning for Program Synthesis | 6.75 | 7.50 | 0.87 | 0.75 | |
| 187 | InstructScene: Instruction-Driven 3D Indoor Scene Synthesis with Semantic Graph Prior | 6.75 | 7.50 | 0.87 | 0.75 | |
| 188 | A Simple Romance Between Multi-Exit Vision Transformer and Token Reduction | 7.00 | 7.50 | 0.87 | 0.50 | |
| 189 | Single Motion Diffusion | 6.75 | 7.50 | 0.87 | 0.75 | |
| 190 | Physics-Regulated Deep Reinforcement Learning: Invariant Embeddings | 5.75 | 7.50 | 0.87 | 1.75 | |
| 191 | SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation | 7.00 | 7.50 | 0.87 | 0.50 | |
| 192 | Learning to Act from Actionless Videos through Dense Correspondences | 5.75 | 7.50 | 1.66 | 1.75 | |
| 193 | The Expressive Power of Transformers with Chain of Thought | 7.50 | 7.50 | 0.87 | 0.00 | |
| 194 | Deep Reinforcement Learning Guided Improvement Heuristic for Job Shop Scheduling | 7.50 | 7.50 | 0.87 | 0.00 | |
| 195 | Facing the Elephant in the Room: Visual Prompt Tuning or Full finetuning? | 5.75 | 7.50 | 0.87 | 1.75 | |
| 196 | Lipschitz Singularities in Diffusion Models | 7.50 | 7.50 | 0.87 | 0.00 | |
| 197 | RTFS-Net: Recurrent time-frequency modelling for efficient audio-visual speech separation | 7.00 | 7.50 | 0.87 | 0.50 | |
| 198 | Idempotence and Perceptual Image Compression | 6.25 | 7.50 | 0.87 | 1.25 | |
| 199 | Multisize Dataset Condensation | 7.50 | 7.50 | 0.87 | 0.00 | |
| 200 | Influencer Backdoor Attack on Semantic Segmentation | 6.00 | 7.50 | 0.87 | 1.50 | |
| 201 | iTransformer: Inverted Transformers Are Effective for Time Series Forecasting | 7.00 | 7.50 | 0.87 | 0.50 | |
| 202 | HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion | 6.75 | 7.50 | 1.66 | 0.75 | |
| 203 | CLAP: Collaborative Adaptation for Checkerboard Learning | 6.75 | 7.50 | 0.87 | 0.75 | |
| 204 | Recursive Generalization Transformer for Image Super-Resolution | 7.50 | 7.50 | 0.87 | 0.00 | |
| 205 | Thin-Shell Object Manipulations With Differentiable Physics Simulations | 7.00 | 8.00 | 0.00 | 1.00 | | 8, 8, 8, 6, 5 | | 8, 8, 8, 8, 8 |
|
| 206 | Faithful and Efficient Explanations for Neural Networks via Neural Tangent Kernel Surrogate Models | 6.40 | 7.40 | 1.20 | 1.00 | | 8, 5, 6, 5, 8 | | 8, 8, 8, 5, 8 |
|
| 207 | Separating common from salient patterns with Contrastive Representation Learning | 7.00 | 7.40 | 1.20 | 0.40 | | 8, 5, 6, 8, 8 | | 8, 5, 8, 8, 8 |
|
| 208 | $t^3$-Variational Autoencoder: Learning Heavy-tailed Data with Student's t and Power Divergence | 7.33 | 7.33 | 0.94 | 0.00 | |
| 209 | Safe Collaborative Filtering | 7.00 | 7.33 | 0.94 | 0.33 | |
| 210 | FlashFFTConv: Efficient Convolutions for Long Sequences with Tensor Cores | 7.00 | 7.33 | 0.94 | 0.33 | |
| 211 | Transformer-VQ: Linear-Time Transformers via Vector Quantization | 6.33 | 7.33 | 0.94 | 1.00 | |
| 212 | Maximum Entropy Model Correction in Reinforcement Learning | 7.33 | 7.33 | 0.94 | 0.00 | |
| 213 | LiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures | 6.67 | 7.33 | 1.89 | 0.67 | |
| 214 | Overthinking the Truth: Understanding how Language Models Process False Demonstrations | 7.33 | 7.33 | 0.94 | 0.00 | |
| 215 | Provable Compositional Generalization for Object-Centric Learning | 7.33 | 7.33 | 0.94 | 0.00 | |
| 216 | Pre-Training Goal-based Models for Sample-Efficient Reinforcement Learning | 5.00 | 7.33 | 0.94 | 2.33 | |
| 217 | A Benchmark for Learning to Translate a New Language from One Grammar Book | 7.00 | 7.33 | 0.94 | 0.33 | |
| 218 | Tool-Augmented Reward Modeling | 5.33 | 7.33 | 0.94 | 2.00 | |
| 219 | Minimax optimality of convolutional neural networks for infinite dimensional input-output problems and separation from kernel methods | 7.33 | 7.33 | 0.94 | 0.00 | |
| 220 | LoftQ: LoRA-Fine-Tuning-aware Quantization for Large Language Models | 8.00 | 7.33 | 0.94 | -0.67 | |
| 221 | Graph Neural Networks for Learning Equivariant Representations of Neural Networks | 7.33 | 7.33 | 0.94 | 0.00 | |
| 222 | Implicit Gaussian process representation of vector fields over arbitrary latent manifolds | 6.67 | 7.33 | 0.94 | 0.67 | |
| 223 | DOS: Diverse Outlier Sampling for Out-of-Distribution Detection | 5.67 | 7.33 | 0.94 | 1.67 | |
| 224 | Denoising Task Routing for Diffusion Models | 6.00 | 7.33 | 0.94 | 1.33 | |
| 225 | H-GAP: Humanoid Control with a Generalist Planner | 5.67 | 7.33 | 0.94 | 1.67 | |
| 226 | Unlocking the Power of Representations in Long-term Novelty-based Exploration | 6.33 | 7.33 | 0.94 | 1.00 | |
| 227 | Evaluating Large Language Models at Evaluating Instruction Following | 7.33 | 7.33 | 0.94 | 0.00 | |
| 228 | Adversarial AutoMixup | 5.67 | 7.33 | 0.94 | 1.67 | |
| 229 | Grounding Language Plans in Demonstrations Through Counter-Factual Perturbations | 5.67 | 7.33 | 0.94 | 1.67 | |
| 230 | Deep Temporal Graph Clustering | 7.00 | 7.33 | 0.94 | 0.33 | |
| 231 | Tackling the Data Heterogeneity in Asynchronous Federated Learning with Cached Update Calibration | 5.67 | 7.33 | 0.94 | 1.67 | |
| 232 | ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models | 5.67 | 7.33 | 0.94 | 1.67 | |
| 233 | Plugin estimators for selective classification with out-of-distribution detection | 6.67 | 7.33 | 0.94 | 0.67 | |
| 234 | Towards Diverse Behaviors: A Benchmark for Imitation Learning with Human Demonstrations | 6.33 | 7.33 | 0.94 | 1.00 | |
| 235 | Estimating Conditional Mutual Information for Dynamic Feature Selection | 6.00 | 7.33 | 0.94 | 1.33 | |
| 236 | Lagrangian Flow Networks for Conservation Laws | 5.67 | 7.33 | 0.94 | 1.67 | |
| 237 | Beyond Stationarity: Convergence Analysis of Stochastic Softmax Policy Gradient Methods | 6.67 | 7.33 | 0.94 | 0.67 | |
| 238 | DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines | 6.67 | 7.33 | 0.94 | 0.67 | |
| 239 | Neural Architecture Retrieval | 7.33 | 7.33 | 0.94 | 0.00 | |
| 240 | Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI | 7.33 | 7.33 | 0.94 | 0.00 | |
| 241 | Dictionary Contrastive Forward Learning via Adaptive Label Embeddings | 5.67 | 7.33 | 0.94 | 1.67 | |
| 242 | Finetuning Text-to-Image Diffusion Models for Fairness | 7.33 | 7.33 | 1.89 | 0.00 | |
| 243 | Mayfly: a Neural Data Structure for Graph Stream Summarization | 7.00 | 7.33 | 0.94 | 0.33 | |
| 244 | On the Vulnerability of Adversarially Trained Models Against Two-faced Attacks | 7.00 | 7.33 | 0.94 | 0.33 | |
| 245 | Generative Learning for Financial Time Series with Irregular and Scale-Invariant Patterns | 5.33 | 7.33 | 0.94 | 2.00 | |
| 246 | On the Parameterization of Second-Order Optimization Effective towards the Infinite Width | 6.67 | 7.33 | 0.94 | 0.67 | |
| 247 | Identifying the Risks of LM Agents with an LM-Emulated Sandbox | 7.33 | 7.33 | 0.94 | 0.00 | |
| 248 | A Study of Bayesian Neural Network Surrogates for Bayesian Optimization | 6.33 | 7.33 | 0.94 | 1.00 | |
| 249 | Kernel Metric Learning for In-Sample Off-Policy Evaluation of Deterministic RL Policies | 6.00 | 7.33 | 0.94 | 1.33 | |
| 250 | Federated Recommendation with Additive Personalization | 6.33 | 7.33 | 0.94 | 1.00 | |
| 251 | Is Self-Repair a Silver Bullet for Code Generation? | 6.33 | 7.33 | 0.94 | 1.00 | |
| 252 | A path-norm toolkit for modern networks: consequences, promises and challenges | 7.00 | 7.33 | 0.94 | 0.33 | |
| 253 | An Analytical Solution to Gauss-Newton Loss for Direct Image Alignment | 7.33 | 7.33 | 0.94 | 0.00 | |
| 254 | From Posterior Sampling to Meaningful Diversity in Image Restoration | 7.00 | 7.33 | 0.94 | 0.33 | |
| 255 | Illusory Attacks: Detectability Matters in Adversarial Attacks on Sequential Decision-Makers | 6.67 | 7.33 | 0.94 | 0.67 | |
| 256 | Space Group Constrained Crystal Generation | 7.33 | 7.33 | 0.94 | 0.00 | |
| 257 | Dynamic Neighborhood Construction for Structured Large Discrete Action Spaces | 6.67 | 7.33 | 0.94 | 0.67 | |
| 258 | Interpretable Sparse System Identification: Beyond Recent Deep Learning Techniques on Time-Series Prediction | 7.00 | 7.33 | 0.94 | 0.33 | |
| 259 | Combining Axes Preconditioners through Kronecker Approximation for Deep Learning | 7.33 | 7.33 | 0.94 | 0.00 | |
| 260 | On the hardness of learning under symmetries | 8.00 | 7.33 | 0.94 | -0.67 | |
| 261 | Masked Audio Generative Modeling | 6.33 | 7.33 | 0.94 | 1.00 | |
| 262 | Demystifying Local & Global Fairness Trade-offs in Federated Learning Using Partial Information Decomposition | 5.67 | 7.33 | 0.94 | 1.67 | |
| 263 | MUSTARD: Mastering Uniform Synthesis of Theorem and Proof Data | 5.67 | 7.33 | 0.94 | 1.67 | |
| 264 | GLD: Generative Latent Dynamics for Structured Motion Representation and Learning | 6.33 | 7.33 | 0.94 | 1.00 | |
| 265 | Poisoned Forgery Face: Towards Backdoor Attacks on Face Forgery Detection | 6.33 | 7.33 | 0.94 | 1.00 | |
| 266 | What does the Knowledge Neuron Thesis Have to do with Knowledge? | 7.00 | 7.33 | 0.94 | 0.33 | |
| 267 | SaProt: Protein Language Modeling with Structure-aware Vocabulary | 6.67 | 7.33 | 0.94 | 0.67 | |
| 268 | Simplifying Transformer Blocks | 7.33 | 7.33 | 0.94 | 0.00 | |
| 269 | Linear Convergence Bounds for Diffusion Models via Stochastic Localization | 6.67 | 7.33 | 0.94 | 0.67 | | 8, 8, 6, 6, 6, 6 | | 8, 8, 8, 6, 6, 8 |
|
| 270 | Uni3D: Exploring Unified 3D Representation at Scale | 6.00 | 7.33 | 0.94 | 1.33 | |
| 271 | Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control | 6.67 | 7.33 | 0.94 | 0.67 | |
| 272 | CivRealm: A Learning and Reasoning Odyssey for Decision-Making Agents | 7.00 | 7.33 | 0.94 | 0.33 | |
| 273 | Ultra-sparse network advantage in deep learning via Cannistraci-Hebb brain-inspired training with hyperbolic meta-deep community-layered epitopology | 6.33 | 7.33 | 0.94 | 1.00 | |
| 274 | Decodable and Sample Invariance Continuous Object Encoder | 7.33 | 7.33 | 0.94 | 0.00 | |
| 275 | NetInfoF Framework: Measuring and Exploiting Network Usable Information | 5.67 | 7.33 | 0.94 | 1.67 | |
| 276 | BarLeRIa: An Efficient Tuning Framework for Referring Image Segmentation | 6.67 | 7.33 | 0.94 | 0.67 | |
| 277 | Enabling Efficient Equivariant Operations in the Fourier Basis via Gaunt Tensor Products | 6.67 | 7.33 | 0.94 | 0.67 | |
| 278 | InsertNeRF: Instilling Generalizability into NeRF with HyperNet Modules | 6.67 | 7.33 | 1.89 | 0.67 | |
| 279 | OctoPack: Instruction Tuning Code Large Language Models | 7.33 | 7.33 | 0.94 | 0.00 | |
| 280 | Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision | 6.67 | 7.33 | 0.94 | 0.67 | |
| 281 | Prompt Gradient Projection for Continual Learning | 5.00 | 7.33 | 0.94 | 2.33 | |
| 282 | ResFields: Residual Neural Fields for Spatiotemporal Signals | 6.67 | 8.00 | 0.00 | 1.33 | |
| 283 | Gene Regulatory Network Inference in the Presence of Dropouts: a Causal View | 7.33 | 7.33 | 0.94 | 0.00 | |
| 284 | Learning No-Regret Sparse Generalized Linear Models with Varying Observation(s) | 6.00 | 7.33 | 0.94 | 1.33 | |
| 285 | Path Choice Matters for Clear Attributions in Path Methods | 6.67 | 7.33 | 0.94 | 0.67 | |
| 286 | Proving Test Set Contamination for Black-Box Language Models | 6.75 | 7.50 | 0.87 | 0.75 | |
| 287 | Likelihood Training of Cascaded Diffusion Models via Hierarchical Volume-preserving Maps | 4.25 | 7.25 | 1.30 | 3.00 | |
| 288 | Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation | 6.00 | 7.25 | 1.30 | 1.25 | |
| 289 | REFACTOR: Learning to Extract Theorems from Proofs | 5.50 | 7.25 | 1.30 | 1.75 | |
| 290 | Lion Secretly Solves a Constrained Optimization: As Lyapunov Predicts | 7.25 | 7.50 | 0.87 | 0.25 | |
| 291 | PolyGCL: GRAPH CONTRASTIVE LEARNING via Learnable Spectral Polynomial Filters | 6.50 | 7.25 | 1.30 | 0.75 | |
| 292 | Stabilizing Contrastive RL: Techniques for Robotic Goal Reaching from Offline Data | 6.25 | 7.25 | 1.30 | 1.00 | |
| 293 | Blending Imitation and Reinforcement Learning for Robust Policy Improvement | 5.50 | 7.25 | 1.30 | 1.75 | |
| 294 | Adaptive Regret for Bandits Made Possible: Two Queries Suffice | 6.00 | 7.25 | 1.30 | 1.25 | |
| 295 | MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts | 6.75 | 7.25 | 1.30 | 0.50 | |
| 296 | Neural SDF Flow for 3D Reconstruction of Dynamic Scenes | 6.00 | 8.00 | 0.00 | 2.00 | |
| 297 | Towards Principled Representation Learning from Videos for Reinforcement Learning | 6.00 | 7.25 | 1.30 | 1.25 | |
| 298 | Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding | 6.00 | 7.50 | 0.87 | 1.50 | |
| 299 | Adversarial Adaptive Sampling: Unify PINN and Optimal Transport for the Approximation of PDEs | 6.00 | 7.25 | 1.92 | 1.25 | |
| 300 | MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models | 7.25 | 8.00 | 0.00 | 0.75 | |
| 301 | Inverse Approximation Theory for Nonlinear Recurrent Neural Networks | 5.50 | 7.25 | 1.30 | 1.75 | |
| 302 | SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore | 7.25 | 7.25 | 1.30 | 0.00 | |
| 303 | Ghost on the Shell: An Expressive Representation of General 3D Shapes | 7.25 | 7.25 | 1.30 | 0.00 | |
| 304 | FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning | 7.25 | 7.25 | 1.92 | 0.00 | |
| 305 | Würstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models | 6.75 | 7.25 | 1.30 | 0.50 | |
| 306 | Motif: Intrinsic Motivation from Artificial Intelligence Feedback | 6.75 | 7.25 | 1.30 | 0.50 | |
| 307 | Fantastic Gains and Where to Find Them: On the Existence and Prospect of General Knowledge Transfer between Any Pretrained Model | 7.25 | 7.25 | 1.30 | 0.00 | |
| 308 | Whole-song Hierarchical Generation of Symbolic Music Using Cascaded Diffusion Models | 6.25 | 7.25 | 1.30 | 1.00 | |
| 309 | Polynomial Width is Sufficient for Set Representation with High-dimensional Features | 6.75 | 7.25 | 1.30 | 0.50 | |
| 310 | Unified Generative Modeling of 3D Molecules with Bayesian Flow Networks | 6.50 | 8.00 | 0.00 | 1.50 | |
| 311 | Efficient-3Dim: Learning a Generalizable Single-image Novel-view Synthesizer in One Day | 6.75 | 7.25 | 1.30 | 0.50 | |
| 312 | At Which Training Stage Does Code Data Help LLMs Reasoning? | 5.75 | 7.25 | 1.30 | 1.50 | |
| 313 | Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior | 7.25 | 7.25 | 1.92 | 0.00 | |
| 314 | Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints | 7.25 | 7.25 | 1.30 | 0.00 | |
| 315 | Crystalformer: Infinitely Connected Attention for Periodic Structure Encoding | 6.00 | 7.25 | 1.30 | 1.25 | |
| 316 | Learning Performance-Improving Code Edits | 6.75 | 7.25 | 1.30 | 0.50 | |
| 317 | FedHyper: A Universal and Robust Learning Rate Scheduler for Federated Learning with Hypergradient Descent | 6.75 | 7.25 | 1.30 | 0.50 | |
| 318 | Unified Human-Scene Interaction via Prompted Chain-of-Contacts | 7.25 | 7.25 | 1.92 | 0.00 | |
| 319 | Domain constraints improve risk prediction when outcome data is missing | 6.25 | 7.25 | 1.30 | 1.00 | |
| 320 | AffineQuant: Affine Transformation Quantization for Large Language Models | 4.25 | 7.25 | 1.30 | 3.00 | |
| 321 | In-context Exploration-Exploitation for Reinforcement Learning | 6.00 | 7.25 | 1.30 | 1.25 | |
| 322 | Towards Seamless Adaptation of Pre-trained Models for Visual Place Recognition | 7.25 | 7.25 | 1.30 | 0.00 | |
| 323 | DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models | 6.50 | 7.25 | 1.30 | 0.75 | |
| 324 | GROOT: Learning to Follow Instructions by Watching Gameplay Videos | 6.25 | 7.25 | 1.30 | 1.00 | |
| 325 | Large Language Models Are Not Robust Multiple Choice Selectors | 6.75 | 7.25 | 1.30 | 0.50 | |
| 326 | Beyond Memorization: Violating Privacy via Inference with Large Language Models | 7.20 | 7.20 | 0.98 | 0.00 | | 8, 8, 8, 6, 6 | | 8, 8, 8, 6, 6 |
|
| 327 | L2MAC: Large Language Model Automatic Computer for Unbounded Code Generation | 6.60 | 7.20 | 0.98 | 0.60 | | 8, 6, 6, 5, 8 | | 8, 8, 6, 6, 8 |
|
| 328 | Improved Active Learning via Dependent Leverage Score Sampling | 6.80 | 7.20 | 0.98 | 0.40 | | 8, 8, 6, 6, 6 | | 8, 8, 6, 6, 8 |
|
| 329 | Subtractive Mixture Models via Squaring: Representation and Learning | 6.80 | 7.20 | 0.98 | 0.40 | | 8, 6, 6, 8, 6 | | 8, 8, 6, 8, 6 |
|
| 330 | BrainPy: a differentiable brain simulator bridging brain simulation and brain-inspired computing | 6.80 | 7.20 | 1.60 | 0.40 | | 6, 10, 8, 5, 5 | | 6, 10, 8, 6, 6 |
|
| 331 | Information Retention via Learning Supplemental Features | 5.40 | 7.20 | 0.98 | 1.80 | | 6, 6, 6, 3, 6 | | 8, 8, 6, 6, 8 |
|
| 332 | Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion | 6.80 | 7.20 | 1.60 | 0.40 | | 6, 6, 6, 10, 6 | | 6, 8, 6, 10, 6 |
|
| 333 | Transport meets Variational Inference: Controlled Monte Carlo Diffusions | 5.60 | 7.20 | 0.98 | 1.60 | | 5, 8, 6, 6, 3 | | 6, 8, 6, 8, 8 |
|
| 334 | What does automatic differentiation compute for neural networks? | 6.20 | 7.20 | 0.98 | 1.00 | | 1, 8, 8, 8, 6 | | 6, 8, 8, 8, 6 |
|
| 335 | Free Lunches in Auxiliary Learning: Exploiting Auxiliary Labels with Negligibly Extra Inference Cost | 7.20 | 7.20 | 0.98 | 0.00 | | 8, 8, 6, 8, 6 | | 8, 8, 6, 8, 6 |
|
| 336 | MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning | 7.00 | 7.20 | 0.98 | 0.20 | |
| 337 | R-EDL: Relaxing Nonessential Settings of Evidential Deep Learning | 6.60 | 7.20 | 0.98 | 0.60 | | 5, 6, 8, 8, 6 | | 6, 6, 8, 8, 8 |
|
| 338 | Boosting Vanilla Lightweight Vision Transformers via Re-parameterization | 6.20 | 7.20 | 0.98 | 1.00 | | 6, 8, 8, 6, 3 | | 6, 8, 8, 6, 8 |
|
| 339 | Mask-based modeling for Neural Radiance Fields | 6.57 | 7.14 | 0.99 | 0.57 | | 8, 6, 6, 8, 6, 6, 6 | | 8, 6, 8, 8, 6, 8, 6 |
|
| 340 | SaNN: Simple Yet Powerful Simplicial-aware Neural Networks | 6.00 | 7.00 | 1.00 | 1.00 | |
| 341 | Controlled Text Generation via Language Model Arithmetic | 6.00 | 7.00 | 1.26 | 1.00 | | 6, 6, 5, 8, 5 | | 8, 8, 6, 8, 5 |
|
| 342 | Consistency Training with Learnable Data Augmentation for Graph Anomaly Detection with Limited Supervision | 5.67 | 7.00 | 1.41 | 1.33 | |
| 343 | Generalized Policy Iteration using Tensor Approximation for Hybrid Control | 6.75 | 7.50 | 0.87 | 0.75 | |
| 344 | CORN: Contact-based Object Representation for Nonprehensile Manipulation of General Unseen Objects | 6.00 | 7.00 | 2.12 | 1.00 | |
| 345 | Efficient Denoising Diffusion via Probabilistic Masking | 6.00 | 7.00 | 1.00 | 1.00 | |
| 346 | RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval | 6.00 | 7.00 | 1.00 | 1.00 | |
| 347 | Chain of Hindsight aligns Language Models with Feedback | 7.00 | 7.00 | 1.00 | 0.00 | |
| 348 | Retrieval meets Long Context Large Language Models | 6.83 | 7.00 | 1.00 | 0.17 | | 8, 5, 8, 6, 8, 6 | | 8, 6, 8, 6, 8, 6 |
|
| 349 | Selective Visual Representations Improve Convergence and Generalization for Embodied AI | 6.50 | 7.50 | 0.87 | 1.00 | |
| 350 | Deceptive Fairness Attacks on Graphs via Meta Learning | 6.75 | 7.00 | 1.00 | 0.25 | |
| 351 | RECOMP: Improving Retrieval-Augmented LMs with Context Compression and Selective Augmentation | 6.33 | 7.00 | 1.00 | 0.67 | |
| 352 | On the Role of Discrete Tokenization in Visual Representation Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 353 | The Consensus Game: Language Model Generation via Equilibrium Search | 7.00 | 7.50 | 1.66 | 0.50 | |
| 354 | Reverse Diffusion Monte Carlo | 4.50 | 7.00 | 1.00 | 2.50 | |
| 355 | Pre-training LiDAR-based 3D Object Detectors through Colorization | 6.75 | 7.00 | 1.00 | 0.25 | |
| 356 | PILOT: An $mathcal{O}(1/T)$-Convergent Approach for Policy Evaluation with Nonlinear Function Approximation | 7.00 | 7.00 | 1.00 | 0.00 | |
| 357 | Confronting Reward Model Overoptimization with Constrained RLHF | 6.25 | 7.00 | 1.00 | 0.75 | |
| 358 | Improved Efficiency Based on Learned Saccade and Continuous Scene Reconstruction From Foveated Visual Sampling | 5.75 | 7.00 | 1.00 | 1.25 | |
| 359 | Feature Learning in Infinite Depth Neural Networks | 6.00 | 7.00 | 1.26 | 1.00 | | 6, 8, 5, 3, 8 | | 8, 8, 5, 6, 8 |
|
| 360 | Improved Techniques for Training Consistency Models | 7.00 | 7.00 | 1.00 | 0.00 | |
| 361 | A Unified Approach for Online Continuous DR-Submodular Maximization | 7.00 | 7.00 | 2.16 | 0.00 | |
| 362 | Unsupervised Federated Graph Matching with Graphlet Feature Extraction and Separate Trust Region | 6.00 | 7.00 | 1.00 | 1.00 | |
| 363 | Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 364 | Diffeomorphic Mesh Deformation via Efficient Optimal Transport for Cortical Surface Reconstruction | 6.75 | 7.00 | 1.00 | 0.25 | |
| 365 | What's In My Big Data? | 7.00 | 7.00 | 2.12 | 0.00 | |
| 366 | Learning Adaptive Multiresolution Transforms via Meta-Framelet-based Graph Convolutional Network | 5.75 | 7.00 | 1.00 | 1.25 | |
| 367 | Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! | 6.50 | 7.00 | 1.73 | 0.50 | |
| 368 | Explaining Kernel Clustering via Decision Trees | 6.75 | 7.00 | 1.00 | 0.25 | |
| 369 | Decision ConvFormer: Local Filtering in MetaFormer is Sufficient for Decision Making | 7.00 | 7.00 | 1.41 | 0.00 | |
| 370 | Dual RL: Unification and New Methods for Reinforcement and Imitation Learning | 6.67 | 7.50 | 1.66 | 0.83 | |
| 371 | Contrastive Difference Predictive Coding | 6.25 | 7.00 | 1.00 | 0.75 | |
| 372 | Effective Data Augmentation With Diffusion Models | 6.50 | 7.00 | 1.00 | 0.50 | |
| 373 | Out-Of-Domain Unlabeled Data Improves Generalization | 5.75 | 7.00 | 1.00 | 1.25 | |
| 374 | A Fast and Provable Algorithm for Sparse Phase Retrieval | 6.50 | 7.00 | 1.00 | 0.50 | |
| 375 | Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation | 6.50 | 7.00 | 1.00 | 0.50 | |
| 376 | FairSeg: A Large-scale Medical Image Segmentation Dataset for Fairness Learning with Fair Error-Bound Scaling | 7.00 | 7.00 | 1.00 | 0.00 | |
| 377 | Greedy Sequential Execution: Solving Homogeneous and Heterogeneous Cooperative Tasks with a Unified Framework | 6.25 | 7.00 | 1.00 | 0.75 | |
| 378 | Multi-View Causal Representation Learning with Partial Observability | 7.00 | 7.00 | 1.00 | 0.00 | |
| 379 | Benchmarking Algorithms for Federated Domain Generalization | 7.00 | 6.67 | 0.94 | -0.33 | |
| 380 | Cross$Q$: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity | 5.25 | 7.00 | 1.00 | 1.75 | |
| 381 | Zero Bubble Pipeline Parallelism | 5.75 | 7.00 | 1.00 | 1.25 | |
| 382 | Accelerating Data Generation for Neural Operators via Krylov Subspace Recycling | 6.25 | 7.00 | 1.00 | 0.75 | |
| 383 | Analyzing Feed-Forward Blocks in Transformers through the Lens of Attention Map | 6.75 | 7.00 | 1.00 | 0.25 | |
| 384 | Beating Price of Anarchy and Gradient Descent without Regret in Potential Games | 7.00 | 7.00 | 1.00 | 0.00 | |
| 385 | PARL: A Unified Framework for Policy Alignment in Reinforcement Learning | 6.00 | 7.00 | 1.00 | 1.00 | |
| 386 | MetaCoCo: A New Few-Shot Classification Benchmark with Spurious Correlation | 6.33 | 7.00 | 1.41 | 0.67 | |
| 387 | Sum-Product-Set Networks: Deep Tractable Models for Tree-Structured Graphs | 6.00 | 7.50 | 0.87 | 1.50 | |
| 388 | Understanding Length Generalization by Thinking Like Transformers | 5.00 | 7.00 | 1.00 | 2.00 | |
| 389 | On Bias-Variance Alignment in Deep Models | 6.75 | 7.00 | 1.00 | 0.25 | |
| 390 | A unique M-pattern for micro-expreesion spotting in long videos | 6.20 | 7.00 | 1.26 | 0.80 | | 6, 3, 8, 8, 6 | | 6, 5, 8, 8, 8 |
|
| 391 | PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization | 7.00 | 7.00 | 1.41 | 0.00 | |
| 392 | Accurate Link Prediction via PU Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 393 | ExeDec: Execution Decomposition for Compositional Generalization in Neural Program Synthesis | 7.00 | 7.00 | 1.00 | 0.00 | |
| 394 | Contrastive Preference Learning: Learning from Human Feedback without Reinforcement Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 395 | Visual Data-Type Understanding does not emerge from scaling Vision-Language Models | 7.00 | 8.00 | 0.00 | 1.00 | |
| 396 | Learning to Act without Actions | 6.00 | 7.50 | 0.87 | 1.50 | |
| 397 | Constrained Decoding for Cross-lingual Label Projection | 6.25 | 7.00 | 1.00 | 0.75 | |
| 398 | Dropout Enhanced Bilevel Training | 5.50 | 7.00 | 1.00 | 1.50 | |
| 399 | Bandits Meet Mechanism Design to Combat Clickbait in Online Recommendation | 6.25 | 7.00 | 1.00 | 0.75 | |
| 400 | Searching for High-Value Molecules Using Reinforcement Learning and Transformers | 5.75 | 7.00 | 1.00 | 1.25 | |
| 401 | Learning Polynomial Problems with $SL(2, mathbb{R})$-Equivariance | 6.00 | 7.00 | 1.41 | 1.00 | |
| 402 | A Characterization Theorem for Equivariant Networks with Point-wise Activations | 6.00 | 7.00 | 1.00 | 1.00 | |
| 403 | Accelerating Sinkhorn algorithm with sparse Newton iterations | 5.50 | 7.00 | 1.00 | 1.50 | |
| 404 | Chain of Log-Concave Markov Chains | 7.00 | 7.00 | 1.00 | 0.00 | |
| 405 | VBH-GNN: Variational Bayesian Heterogeneous Graph Neural Networks for Cross-subject Emotion Recognition | 6.67 | 7.00 | 1.00 | 0.33 | |
| 406 | Don't trust your eyes: on the (un)reliability of feature visualizations | 6.25 | 7.00 | 1.00 | 0.75 | |
| 407 | On the Provable Advantage of Unsupervised Pretraining | 7.00 | 7.00 | 1.00 | 0.00 | |
| 408 | A Plug-and-Play Image Registration Network | 5.50 | 7.00 | 1.00 | 1.50 | |
| 409 | Incentivized Truthful Communication for Federated Bandits | 4.75 | 7.00 | 1.00 | 2.25 | |
| 410 | Chain-of-Experts: When LLMs Meet Complex Operations Research Problems | 5.50 | 7.00 | 1.00 | 1.50 | |
| 411 | Brain decoding: toward real-time reconstruction of visual perception | 6.00 | 7.00 | 1.00 | 1.00 | |
| 412 | Impact of Computation in Integral Reinforcement Learning for Continuous-Time Control | 6.25 | 7.00 | 1.00 | 0.75 | |
| 413 | TAB: Temporal Accumulated Batch Normalization in Spiking Neural Networks | 5.00 | 7.00 | 1.00 | 2.00 | |
| 414 | Catch the Shadow: Automatic Shadow Variables Generation for Treatment Effect Estimation under Collider Bias | 6.25 | 7.00 | 1.00 | 0.75 | |
| 415 | Hybrid Directional Graph Neural Network for Molecules | 5.33 | 7.33 | 0.94 | 2.00 | |
| 416 | General Stability Analysis for Zeroth-Order Optimization Algorithms | 6.25 | 7.00 | 1.00 | 0.75 | |
| 417 | Neural structure learning with stochastic differential equations | 6.75 | 7.00 | 1.00 | 0.25 | |
| 418 | CLIPSelf: Vision Transformer Distills Itself for Open-Vocabulary Dense Prediction | 6.75 | 7.00 | 1.00 | 0.25 | |
| 419 | Discovering Temporally-Aware Reinforcement Learning Algorithms | 6.33 | 7.00 | 1.41 | 0.67 | |
| 420 | Towards Eliminating Hard Label Constraints in Gradient Inversion Attacks | 5.75 | 7.00 | 1.00 | 1.25 | |
| 421 | Guiding Masked Representation Learning to Capture Spatio-Temporal Relationship of Electrocardiogram | 6.50 | 7.00 | 1.00 | 0.50 | |
| 422 | A Structured Matrix Method for Nonequispaced Neural Operators | 5.67 | 7.00 | 1.41 | 1.33 | |
| 423 | Generalization of Deep ResNets in the Mean-Field Regime | 6.33 | 7.00 | 1.41 | 0.67 | |
| 424 | Structural Inference with Dynamics Encoding and Partial Correlation Coefficients | 6.00 | 7.33 | 1.89 | 1.33 | |
| 425 | Neural Fourier Transform: A General Approach to Equivariant Representation Learning | 7.00 | 7.00 | 1.00 | 0.00 | |
| 426 | Efficient Algorithms for the CCA Family: Unconstrained Objectives with Unbiased Gradients | 6.33 | 7.00 | 1.41 | 0.67 | |
| 427 | Text2Reward: Dense Reward Generation with Language Models for Reinforcement Learning | 5.00 | 7.00 | 1.00 | 2.00 | |
| 428 | Two-timescale Extragradient for Finding Local Minimax Points | 7.00 | 7.00 | 1.00 | 0.00 | |
| 429 | Provable Memory Efficient Self-Play Algorithm for Model-free Reinforcement Learning | 5.00 | 7.00 | 1.00 | 2.00 | |
| 430 | InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation | 6.00 | 7.00 | 1.00 | 1.00 | |
| 431 | Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization | 6.25 | 7.00 | 1.00 | 0.75 | |
| 432 | SWAP-NAS: Sample-Wise Activation Patterns for Ultra-fast NAS | 6.50 | 7.50 | 0.87 | 1.00 | |
| 433 | Robotic Task Generalization via Hindsight Trajectory Sketches | 7.00 | 7.00 | 1.41 | 0.00 | |
| 434 | Submodular Reinforcement Learning | 6.75 | 7.00 | 1.00 | 0.25 | |
| 435 | $infty$-Diff: Infinite Resolution Diffusion with Subsampled Mollified States | 5.50 | 7.00 | 1.00 | 1.50 | |
| 436 | Solving Inverse Problems with Latent Diffusion Models via Hard Data Consistency | 6.50 | 7.50 | 0.87 | 1.00 | |
| 437 | The False Promise of Imitating Proprietary Language Models | 6.50 | 7.00 | 1.00 | 0.50 | |
| 438 | Video Language Planning | 7.00 | 7.00 | 1.00 | 0.00 | |
| 439 | Mol-Instructions - A Large-Scale Biomolecular Instruction Dataset for Large Language Models | 6.75 | 7.00 | 1.00 | 0.25 | |
| 440 | Provably Robust Conformal Prediction with Improved Efficiency | 6.25 | 7.00 | 1.00 | 0.75 | |
| 441 | FedImpro: Measuring and Improving Client Update in Federated Learning | 5.75 | 7.00 | 1.00 | 1.25 | |
| 442 | Enhancing Group Fairness in Online Settings Using Oblique Decision Forests | 5.80 | 7.00 | 1.26 | 1.20 | | 6, 3, 8, 6, 6 | | 6, 5, 8, 8, 8 |
|
| 443 | AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model | 6.75 | 7.00 | 1.00 | 0.25 | |
| 444 | Rethinking Complex Queries on Knowledge Graphs with Neural Link Predictors | 7.00 | 7.00 | 1.00 | 0.00 | |
| 445 | Teach LLMs to Phish: Stealing Private Information from Language Models | 6.00 | 7.00 | 1.41 | 1.00 | |
| 446 | Fleet Policy Learning via Weight Merging and An Application to Robotic Tool-Use | 6.00 | 7.00 | 1.41 | 1.00 | |
| 447 | InfoCon: Concept Discovery with Generative and Discriminative Informativeness | 6.25 | 7.00 | 1.00 | 0.75 | |
| 448 | Meta-Learning Priors Using Unrolled Proximal Neural Networks | 6.75 | 7.00 | 1.00 | 0.25 | |
| 449 | Time-LLM: Time Series Forecasting by Reprogramming Large Language Models | 5.40 | 7.00 | 2.00 | 1.60 | | 8, 5, 5, 6, 3 | | 8, 8, 8, 8, 3 |
|
| 450 | Offline Data Enhanced On-Policy Policy Gradient with Provable Guarantees | 6.75 | 7.00 | 1.00 | 0.25 | |
| 451 | Zero and Few-shot Semantic Parsing with Ambiguous Inputs | 6.75 | 7.00 | 1.00 | 0.25 | |
| 452 | FedRC: Tackling Diverse Distribution Shifts Challenge in Federated Learning by Robust Clustering | 7.00 | 7.00 | 1.41 | 0.00 | |
| 453 | RETSim: Resilient and Efficient Text Similarity | 6.25 | 7.00 | 1.00 | 0.75 | |
| 454 | Future Language Modeling from Temporal Document History | 7.00 | 7.33 | 0.94 | 0.33 | |
| 455 | GIO: Gradient Information Optimization for Training Dataset Selection | 5.50 | 7.00 | 1.00 | 1.50 | |
| 456 | SNIP: Bridging Mathematical Symbolic and Numeric Realms with Unified Pre-training | 7.00 | 7.00 | 1.00 | 0.00 | |
| 457 | Guess & Sketch: Language Model Guided Transpilation | 6.33 | 7.00 | 1.41 | 0.67 | |
| 458 | On Differentially Private Federated Linear Contextual Bandits | 7.00 | 7.00 | 1.00 | 0.00 | |
| 459 | The Truth Is In There: Improving Reasoning with Layer-Selective Rank Reduction | 6.33 | 7.00 | 2.94 | 0.67 | |
| 460 | Listen, Think, and Understand | 6.25 | 7.00 | 1.00 | 0.75 | |
| 461 | The Optimal Constant Solution: Predictable Extrapolation in Deep Neural Networks | 6.75 | 7.00 | 1.00 | 0.25 | |
| 462 | Project and Probe: Sample-Efficient Adaptation by Interpolating Orthogonal Features | 5.67 | 7.00 | 1.41 | 1.33 | |
| 463 | Provable Robust Watermarking for AI-Generated Text | 7.00 | 7.00 | 1.00 | 0.00 | |
| 464 | Reward Design for Justifiable Sequential Decision-Making | 6.25 | 7.00 | 1.00 | 0.75 | |
| 465 | LILO: Learning Interpretable Libraries by Compressing and Documenting Code | 6.00 | 7.00 | 1.00 | 1.00 | |
| 466 | Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models | 6.25 | 7.00 | 1.00 | 0.75 | |
| 467 | Generalized Schrödinger Bridge Matching | 6.75 | 7.00 | 1.00 | 0.25 | |
| 468 | Lemur: Harmonizing Natural Language and Code for Language Agents | 6.75 | 7.00 | 1.00 | 0.25 | |
| 469 | SEPT: Towards Efficient Scene Representation Learning for Motion Prediction | 6.50 | 7.00 | 1.00 | 0.50 | |
| 470 | Selective Mixup Fine-Tuning for Optimizing Non-Decomposable Metrics | 6.50 | 7.00 | 1.00 | 0.50 | |
| 471 | One Forward is Enough for Neural Network Training via Likelihood Ratio Method | 6.25 | 7.00 | 1.00 | 0.75 | |
| 472 | Fixed-Budget Differentially Private Best Arm Identification | 6.75 | 7.00 | 1.26 | 0.25 | |
| 473 | FedInverse: Evaluating Privacy Leakage in Federated Learning | 5.50 | 7.00 | 1.00 | 1.50 | |
| 474 | TokenFlow: Consistent Diffusion Features for Consistent Video Editing | 7.00 | 7.00 | 1.00 | 0.00 | |
| 475 | Learning Multi-Agent Communication from Graph Modeling Perspective | 6.75 | 7.00 | 1.00 | 0.25 | |
| 476 | Minimum width for universal approximation using ReLU networks on compact domain | 6.33 | 7.00 | 1.41 | 0.67 | |
| 477 | Coordinate-Aware Modulation for Neural Fields | 6.50 | 7.00 | 1.00 | 0.50 | |
| 478 | Efficient ConvBN Blocks for Transfer Learning and Beyond | 6.50 | 7.50 | 0.87 | 1.00 | |
| 479 | SLiMe: Segment Like Me | 6.75 | 7.00 | 1.00 | 0.25 | |
| 480 | Efficiently Computing Similarities to Private Datasets | 7.00 | 7.00 | 1.00 | 0.00 | |
| 481 | Where We Have Arrived in Proving the Emergence of Sparse Interaction Primitives in AI Models | 5.50 | 7.00 | 1.00 | 1.50 | |
| 482 | SocioDojo: Building Lifelong Analytical Agents with Real-world Text and Time Series | 6.33 | 7.00 | 1.41 | 0.67 | |
| 483 | Quasi-Monte Carlo for 3D Sliced Wasserstein | 6.50 | 7.50 | 0.87 | 1.00 | |
| 484 | A Poincaré Inequality and Consistency Results for Signal Sampling on Large Graphs | 7.00 | 7.00 | 1.00 | 0.00 | |
| 485 | Cascading Reinforcement Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 486 | One For All: Towards Training One Graph Model For All Classification Tasks | 6.50 | 7.00 | 1.73 | 0.50 | |
| 487 | Classification with Conceptual Safeguards | 6.25 | 7.00 | 1.00 | 0.75 | |
| 488 | Feature emergence via margin maximization: case studies in algebraic tasks | 7.00 | 7.00 | 1.00 | 0.00 | |
| 489 | Parameter-Efficient Multi-Task Model Fusion with Partial Linearizeation | 6.50 | 7.00 | 1.00 | 0.50 | |
| 490 | Learning in reverse causal strategic environments with ramifications on two sided markets | 5.50 | 7.00 | 1.00 | 1.50 | |
| 491 | Enhancing Kernel Flexibility via Learning Asymmetric Locally-Adaptive Kernels | 5.33 | 7.00 | 1.41 | 1.67 | |
| 492 | Efficient Streaming Language Models with Attention Sinks | 7.00 | 7.50 | 0.87 | 0.50 | |
| 493 | DMBP: Diffusion model based predictor for robust offline reinforcement learning against state observation perturbations | 6.75 | 7.00 | 1.00 | 0.25 | |
| 494 | Alignment as Reward-Guided Search | 5.50 | 7.00 | 1.00 | 1.50 | |
| 495 | Pre-Training and Fine-Tuning Generative Flow Networks | 6.25 | 7.00 | 1.00 | 0.75 | |
| 496 | Efficient Distributed Training with Full Communication-Computation Overlap | 6.00 | 7.00 | 1.00 | 1.00 | | 8, 3, 6, 5, 6, 8 | | 8, 6, 6, 8, 6, 8 |
|
| 497 | Fantastic Generalization Measures are Nowhere to be Found | 5.75 | 7.00 | 1.00 | 1.25 | |
| 498 | Bespoke Solvers for Generative Flow Models | 6.80 | 7.20 | 0.98 | 0.40 | | 5, 8, 8, 8, 5 | | 6, 8, 8, 8, 6 |
|
| 499 | Decongestion by Representation: Learning to Improve Economic Welfare in Marketplaces | 7.00 | 7.00 | 1.00 | 0.00 | |
| 500 | Leveraging augmented-Lagrangian techniques for differentiating over infeasible quadratic programs in machine learning | 7.00 | 7.00 | 1.00 | 0.00 | |
| 501 | BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation | 7.00 | 7.00 | 1.00 | 0.00 | |
| 502 | Self-Supervised High Dynamic Range Imaging with Multi-Exposure Images in Dynamic Scenes | 7.00 | 7.00 | 1.00 | 0.00 | |
| 503 | Multi-Armed Bandits with Abstention | 6.75 | 7.00 | 1.00 | 0.25 | |
| 504 | M3C: A Framework towards Convergent, Flexible, and Unsupervised Learning of Mixture Graph Matching and Clustering | 5.50 | 7.00 | 1.00 | 1.50 | |
| 505 | Input-gradient space particle inference for neural network ensembles | 6.50 | 7.00 | 1.00 | 0.50 | |
| 506 | Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph | 7.00 | 7.00 | 1.00 | 0.00 | |
| 507 | Self-supervised Heterogeneous Graph Learning: a Homogeneity and Heterogeneity Perspective | 6.50 | 7.00 | 1.00 | 0.50 | | 6, 8, 8, 6, 3, 8 | | 6, 8, 8, 6, 6, 8 |
|
| 508 | Prototypical Information Bottlenecking and Disentangling for Multimodal Cancer Survival Prediction | 7.00 | 7.75 | 1.79 | 0.75 | |
| 509 | Domain-Agnostic Molecular Generation with Self-feedback | 5.50 | 7.00 | 1.00 | 1.50 | |
| 510 | LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Generative Language Models | 6.25 | 7.00 | 1.00 | 0.75 | |
| 511 | The Generative AI Paradox: “What It Can Create, It May Not Understand” | 6.25 | 7.00 | 1.00 | 0.75 | |
| 512 | Denoising Diffusion Bridge Models | 6.00 | 7.00 | 1.00 | 1.00 | |
| 513 | Accelerating Distributed Stochastic Optimization via Self-Repellent Random Walks | 6.25 | 7.00 | 1.00 | 0.75 | |
| 514 | Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts | 7.00 | 7.00 | 1.00 | 0.00 | |
| 515 | Discovering Failure Modes of Text-guided Diffusion Models via Adversarial Search | 6.75 | 7.00 | 1.73 | 0.25 | |
| 516 | Conformal Risk Control | 6.33 | 7.00 | 1.00 | 0.67 | | 8, 6, 6, 8, 5, 5 | | 8, 6, 8, 8, 6, 6 |
|
| 517 | Mitigating the Curse of Dimensionality for Certified Robustness via Dual Randomized Smoothing | 6.25 | 7.00 | 1.00 | 0.75 | |
| 518 | BatteryML:An Open-source platform for Machine Learning on Battery Degradation | 6.50 | 7.00 | 1.00 | 0.50 | |
| 519 | Improving Code Style for Accurate Code Generation | 5.67 | 7.00 | 1.41 | 1.33 | |
| 520 | PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis | 6.75 | 7.00 | 1.00 | 0.25 | |
| 521 | SEABO: A Simple Search-Based Method for Offline Imitation Learning | 6.00 | 7.00 | 1.00 | 1.00 | |
| 522 | Zero-Shot Robustification of Zero-Shot Models | 6.50 | 7.00 | 1.00 | 0.50 | |
| 523 | LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models | 6.67 | 7.00 | 1.00 | 0.33 | |
| 524 | Meaning Representations from Trajectories in Autoregressive Models | 6.50 | 7.00 | 1.00 | 0.50 | |
| 525 | The Effect of Intrinsic Dataset Properties on Generalization: Unraveling Learning Differences Between Natural and Medical Images | 5.50 | 7.00 | 1.00 | 1.50 | |
| 526 | Scaling Laws for Sparsely-Connected Foundation Models | 6.50 | 7.00 | 1.00 | 0.50 | |
| 527 | Elastic Feature Consolidation For Cold Start Exemplar-Free Incremental Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 528 | Accurate Forgetting for Heterogeneous Federated Continual Learning | 5.40 | 7.00 | 1.26 | 1.60 | | 5, 5, 6, 5, 6 | | 6, 8, 8, 5, 8 |
|
| 529 | Spurious Feature Diversification Improves Out-of-distribution Generalization | 7.00 | 7.00 | 1.41 | 0.00 | |
| 530 | Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy | 7.00 | 7.00 | 1.41 | 0.00 | |
| 531 | Self-Supervised Speech Quality Estimation and Enhancement Using Only Clean Speech | 5.00 | 7.00 | 1.00 | 2.00 | |
| 532 | Grounding Multimodal Large Language Models to the World | 6.75 | 7.00 | 1.00 | 0.25 | |
| 533 | Enhanced Face Recognition using Intra-class Incoherence Constraint | 6.50 | 7.00 | 1.00 | 0.50 | |
| 534 | Entropy is not Enough for Test-time Adaptation: From the Perspective of Disentangled Factors | 6.00 | 7.00 | 1.00 | 1.00 | |
| 535 | SEAL: A Framework for Systematic Evaluation of Real-World Super-Resolution | 7.00 | 7.00 | 1.00 | 0.00 | |
| 536 | Structuring Representation Geometry with Rotationally Equivariant Contrastive Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 537 | Time Travel in LLMs: Tracing Data Contamination in Large Language Models | 5.75 | 7.00 | 1.00 | 1.25 | |
| 538 | BioBridge: Bridging Biomedical Foundation Models via Knowledge Graph | 5.75 | 7.00 | 1.00 | 1.25 | |
| 539 | ReTaSA: A Nonparametric Functional Estimation Approach for Addressing Continuous Target Shift | 5.75 | 7.00 | 1.00 | 1.25 | |
| 540 | Implicit regularization of deep residual networks towards neural ODEs | 7.00 | 7.00 | 1.00 | 0.00 | |
| 541 | PanoDiffusion: 360-degree Panorama Outpainting via Diffusion | 6.25 | 7.00 | 1.00 | 0.75 | |
| 542 | Connect, Collapse, Corrupt: Learning Cross-Modal Tasks with Uni-Modal Data | 6.75 | 7.00 | 1.00 | 0.25 | |
| 543 | Instant3D: Fast Text-to-3D with Sparse-view Generation and Large Reconstruction Model | 7.00 | 7.33 | 0.94 | 0.33 | |
| 544 | Progressive Fourier Neural Representation for Sequential Video Compilation | 6.00 | 7.00 | 1.00 | 1.00 | |
| 545 | AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning | 7.00 | 7.00 | 1.00 | 0.00 | |
| 546 | Guiding Instruction-based Image Editing via Multimodal Large Language Models | 7.00 | 7.00 | 1.00 | 0.00 | |
| 547 | Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning | 7.00 | 7.00 | 1.00 | 0.00 | |
| 548 | Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game | 6.33 | 7.00 | 1.41 | 0.67 | |
| 549 | DreamClean: Restoring Clean Image Using Deep Diffusion Prior | 7.00 | 7.00 | 1.00 | 0.00 | |
| 550 | End-to-End (Instance)-Image Goal Navigation through Correspondence as an Emergent Phenomenon | 7.00 | 7.00 | 1.00 | 0.00 | |
| 551 | Deep Stochastic Mechanics | 6.75 | 7.00 | 1.00 | 0.25 | |
| 552 | BrainSCUBA: Fine-Grained Natural Language Captions of Visual Cortex Selectivity | 6.00 | 7.00 | 1.00 | 1.00 | |
| 553 | Towards Lossless Dataset Distillation via Difficulty-Aligned Trajectory Matching | 6.50 | 7.00 | 1.00 | 0.50 | |
| 554 | InfoBatch: Lossless Training Speed Up by Unbiased Dynamic Data Pruning | 6.00 | 7.00 | 1.00 | 1.00 | |
| 555 | Fine-tuning Multimodal LLMs to Follow Zero-shot Demonstrative Instructions | 6.75 | 7.00 | 1.00 | 0.25 | |
| 556 | Online Stabilization of Spiking Neural Networks | 6.00 | 7.00 | 1.00 | 1.00 | |
| 557 | Threaten Spiking Neural Networks through Combining Rate and Temporal Information | 6.50 | 7.00 | 1.00 | 0.50 | |
| 558 | Rethinking Model Ensemble in Transfer-based Adversarial Attacks | 7.00 | 7.00 | 1.00 | 0.00 | |
| 559 | Lie Group Decompositions for Equivariant Neural Networks | 6.00 | 6.83 | 1.21 | 0.83 | | 6, 3, 5, 6, 8, 8 | | 8, 5, 6, 6, 8, 8 |
|
| 560 | Symmetric Mean-field Langevin Dynamics for Distributional Minimax Problems | 6.60 | 6.80 | 0.98 | 0.20 | | 8, 6, 6, 8, 5 | | 8, 6, 6, 8, 6 |
|
| 561 | GraphChef: Decision-Tree Recipes to Explain Graph Neural Networks | 6.60 | 6.80 | 0.98 | 0.20 | | 5, 8, 6, 8, 6 | | 6, 8, 6, 8, 6 |
|
| 562 | Provable Benefits of Multi-task RL under Non-Markovian Decision Making Processes | 6.20 | 6.80 | 0.98 | 0.60 | | 5, 6, 6, 6, 8 | | 6, 6, 8, 6, 8 |
|
| 563 | On the Role of General Function Approximation in Offline Reinforcement Learning | 5.80 | 6.80 | 0.98 | 1.00 | | 3, 8, 6, 6, 6 | | 8, 8, 6, 6, 6 |
|
| 564 | The Devil is in the Neurons: Interpreting and Mitigating Social Biases in Language Models | 6.80 | 6.80 | 0.98 | 0.00 | | 8, 8, 6, 6, 6 | | 8, 8, 6, 6, 6 |
|
| 565 | On the Foundations of Shortcut Learning | 6.40 | 6.80 | 0.98 | 0.40 | | 6, 8, 6, 6, 6 | | 6, 8, 8, 6, 6 |
|
| 566 | On the Markov Property of Neural Algorithmic Reasoning: Analyses and Methods | 6.80 | 6.80 | 0.98 | 0.00 | | 6, 8, 8, 6, 6 | | 6, 8, 8, 6, 6 |
|
| 567 | Bilevel Optimization under Unbounded Smoothness: A New Algorithm and Convergence Analysis | 5.40 | 6.80 | 0.98 | 1.40 | | 5, 5, 3, 6, 8 | | 6, 6, 6, 8, 8 |
|
| 568 | ODE Discovery for Longitudinal Heterogeneous Treatment Effects Inference | 6.40 | 6.80 | 1.47 | 0.40 | | 5, 8, 5, 6, 8 | | 5, 8, 5, 8, 8 |
|
| 569 | Light Schrödinger Bridge | 5.80 | 6.80 | 1.47 | 1.00 | | 8, 5, 3, 8, 5 | | 8, 5, 5, 8, 8 |
|
| 570 | Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video | 6.60 | 6.80 | 1.60 | 0.20 | | 10, 5, 6, 6, 6 | | 10, 6, 6, 6, 6 |
|
| 571 | Towards Meta-Pruning via Optimal Transport | 6.20 | 7.20 | 0.98 | 1.00 | | 8, 8, 6, 6, 3 | | 8, 8, 6, 8, 6 |
|
| 572 | An Image Is Worth 1000 Lies: Transferability of Adversarial Images across Prompts on Vision-Language Models | 6.00 | 6.80 | 0.98 | 0.80 | | 5, 6, 5, 8, 6 | | 6, 8, 6, 8, 6 |
|
| 573 | LLMCarbon: Modeling the End-to-End Carbon Footprint of Large Language Models | 6.00 | 6.80 | 1.94 | 0.80 | | 10, 3, 6, 5, 6 | | 10, 5, 6, 5, 8 |
|
| 574 | Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood | 5.60 | 6.80 | 0.98 | 1.20 | | 6, 5, 6, 6, 5 | | 8, 6, 6, 6, 8 |
|
| 575 | Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature | 5.80 | 6.80 | 0.98 | 1.00 | | 8, 6, 8, 6, 1 | | 8, 6, 8, 6, 6 |
|
| 576 | How Well Do Supervised Models Transfer to 3D Image Segmentation? | 6.20 | 6.80 | 0.98 | 0.60 | | 6, 8, 3, 6, 8 | | 6, 8, 6, 6, 8 |
|
| 577 | Cooperative Hardware-Prompt Learning for Snapshot Compressive Imaging | 6.50 | 7.00 | 1.00 | 0.50 | |
| 578 | KoLA: Carefully Benchmarking World Knowledge of Large Language Models | 6.75 | 6.75 | 1.30 | 0.00 | |
| 579 | In-context Autoencoder for Context Compression in a Large Language Model | 6.50 | 6.75 | 1.30 | 0.25 | |
| 580 | A Good Learner can Teach Better: Teacher-Student Collaborative Knowledge Distillation | 6.25 | 6.75 | 1.30 | 0.50 | |
| 581 | Neural Spectral Methods | 5.25 | 6.75 | 2.17 | 1.50 | |
| 582 | Canonpipe: Data Debugging with Shapley Importance over Machine Learning Pipelines | 6.25 | 6.75 | 1.30 | 0.50 | |
| 583 | A Quadratic Synchronization Rule for Distributed Deep Learning | 6.00 | 6.75 | 1.30 | 0.75 | |
| 584 | On Local Equilibrium in Non-Concave Games | 6.75 | 6.75 | 2.59 | 0.00 | |
| 585 | Generative Adversarial Equilibrium Solvers | 6.75 | 6.75 | 1.92 | 0.00 | |
| 586 | Optimal Sketching for Residual Error Estimation for Matrix and Vector Norms | 6.75 | 6.75 | 1.30 | 0.00 | |
| 587 | Cycle Consistency Driven Object Discovery | 6.00 | 6.75 | 1.30 | 0.75 | |
| 588 | When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method | 6.50 | 6.75 | 1.30 | 0.25 | |
| 589 | MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning | 6.00 | 6.75 | 1.30 | 0.75 | |
| 590 | MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training | 6.50 | 7.50 | 0.87 | 1.00 | |
| 591 | Task structure and nonlinearity jointly determine learned representational geometry | 6.00 | 6.75 | 1.30 | 0.75 | |
| 592 | Predictive, scalable and interpretable knowledge tracing on structured domains | 5.00 | 6.75 | 1.30 | 1.75 | |
| 593 | Designing Skill-Compatible AI: Methodologies and Frameworks in Chess | 5.75 | 6.75 | 1.30 | 1.00 | |
| 594 | Optimistic Bayesian Optimization with Unknown Constraints | 6.00 | 6.75 | 1.30 | 0.75 | |
| 595 | Two-stage LLM Fine-tuning with Less Specialization and More Generalization | 6.25 | 6.75 | 1.30 | 0.50 | |
| 596 | Improving Offline RL by Blending Heuristics | 5.50 | 7.25 | 1.30 | 1.75 | |
| 597 | Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity | 5.75 | 6.75 | 2.17 | 1.00 | |
| 598 | Generating Stealthy Jailbreak Prompts on Aligned Large Language Models | 5.50 | 7.00 | 1.00 | 1.50 | |
| 599 | How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression? | 6.25 | 6.75 | 1.30 | 0.50 | |
| 600 | Accurate Retraining-free Pruning for Pretrained Encoder-based Language Models | 6.25 | 6.75 | 1.30 | 0.50 | |
| 601 | Follow-the-Perturbed-Leader for Adversarial Bandits: Heavy Tails, Robustness, and Privacy | 6.75 | 6.75 | 1.30 | 0.00 | |
| 602 | Dynamic Layer Tying for Parameter-Efficient Transformers | 6.25 | 6.75 | 1.92 | 0.50 | |
| 603 | Bounding the Expected Robustness of Graph Neural Networks Subject to Node Feature Attacks | 6.33 | 6.75 | 1.30 | 0.42 | |
| 604 | Achieving Fairness in Multi-Agent MDP Using Reinforcement Learning | 5.75 | 6.75 | 2.17 | 1.00 | |
| 605 | Kernelised Normalising Flows | 6.00 | 6.75 | 1.30 | 0.75 | |
| 606 | Tackling Byzantine Clients in Federated Learning | 6.75 | 6.75 | 1.30 | 0.00 | |
| 607 | Training Graph Transformers via Curriculum-Enhanced Attention Distillation | 6.25 | 6.75 | 1.30 | 0.50 | |
| 608 | Kill Two Birds with One Stone: Rethinking Data Augmentation for Deep Long-tailed Learning | 6.50 | 6.75 | 1.30 | 0.25 | |
| 609 | Demystifying CLIP Data | 6.00 | 6.75 | 1.30 | 0.75 | |
| 610 | Certified Adversarial Robustness for Rate Encoded Spiking Neural Networks | 4.75 | 6.75 | 1.30 | 2.00 | |
| 611 | Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space | 6.00 | 6.75 | 1.30 | 0.75 | |
| 612 | Spatially-Aware Transformers for Embodied Agents | 6.75 | 6.75 | 1.30 | 0.00 | |
| 613 | ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search | 6.75 | 6.75 | 1.30 | 0.00 | |
| 614 | LQ-LoRA: Low-rank plus Quantized Matrix Decomposition for Efficient Language Model Finetuning | 6.50 | 6.75 | 1.30 | 0.25 | |
| 615 | An Efficient Tester-Learner for Halfspaces | 6.25 | 6.75 | 1.30 | 0.50 | |
| 616 | Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment | 6.75 | 7.00 | 1.00 | 0.25 | |
| 617 | Massive Editing for Large Language Model via Meta Learning | 6.75 | 6.75 | 1.92 | 0.00 | |
| 618 | Defining Expertise: Applications to Treatment Effect Estimation | 6.50 | 6.75 | 1.30 | 0.25 | |
| 619 | Class Probability Matching with Calibrated Networks for Label Shift Adaption | 6.75 | 6.75 | 1.30 | 0.00 | |
| 620 | Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks | 6.75 | 7.50 | 0.87 | 0.75 | |
| 621 | PhyloGFN: Phylogenetic inference with generative flow networks | 5.75 | 6.75 | 1.30 | 1.00 | |
| 622 | Faster Sampling from Log-Concave Densities over Polytopes via Efficient Linear Solvers | 6.33 | 6.75 | 2.17 | 0.42 | |
| 623 | Language Model Cascades: Token-Level Uncertainty And Beyond | 5.75 | 7.00 | 1.00 | 1.25 | |
| 624 | Learning from Sparse Offline Datasets via Conservative Density Estimation | 6.75 | 6.75 | 1.30 | 0.00 | |
| 625 | On the Expressivity of Objective-Specification Formalisms in Reinforcement Learning | 6.50 | 6.75 | 2.59 | 0.25 | |
| 626 | TRAM: Bridging Trust Regions and Sharpness Aware Minimization | 5.75 | 6.75 | 1.30 | 1.00 | |
| 627 | The Expressive Leaky Memory Neuron: an Efficient and Expressive Phenomenological Neuron Model Can Solve Long-Horizon Tasks. | 6.00 | 6.75 | 1.30 | 0.75 | |
| 628 | Large-scale training of foundation models for wearable biosignals | 6.75 | 6.75 | 1.30 | 0.00 | |
| 629 | Off-Policy Primal-Dual Safe Reinforcement Learning | 6.00 | 6.75 | 1.30 | 0.75 | |
| 630 | GAIA: a benchmark for General AI Assistants | 6.75 | 6.75 | 2.17 | 0.00 | |
| 631 | From Zero to Turbulence: Generative Modeling for 3D Flow Simulation | 6.75 | 6.75 | 1.30 | 0.00 | |
| 632 | Beam Enumeration: Probabilistic Explainability For Sample Efficient Self-conditioned Molecular Design | 5.33 | 6.75 | 2.17 | 1.42 | |
| 633 | How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions | 6.25 | 6.75 | 1.30 | 0.50 | |
| 634 | Online Information Acquisition: Hiring Multiple Agents | 6.25 | 6.75 | 1.30 | 0.50 | |
| 635 | Out-of-Variable Generalisation for Discriminative Models | 6.25 | 6.75 | 1.30 | 0.50 | |
| 636 | Sparsistency for inverse optimal transport | 6.75 | 6.75 | 1.30 | 0.00 | |
| 637 | ValUES: A Framework for Systematic Validation of Uncertainty Estimation in Semantic Segmentation | 6.00 | 6.75 | 2.17 | 0.75 | |
| 638 | Diverse Projection Ensembles for Distributional Reinforcement Learning | 5.50 | 6.75 | 2.17 | 1.25 | |
| 639 | Retrieval is Accurate Generation | 6.75 | 7.00 | 1.00 | 0.25 | |
| 640 | The Wasserstein Believer: Learning Belief Updates for Partially Observable Environments through Reliable Latent Space Models | 6.75 | 6.75 | 1.92 | 0.00 | |
| 641 | FFB: A Fair Fairness Benchmark for In-Processing Group Fairness Methods | 6.00 | 6.75 | 1.30 | 0.75 | |
| 642 | Graphical Multioutput Gaussian Process with Attention | 5.50 | 6.75 | 2.17 | 1.25 | |
| 643 | A Lightweight Method for Tackling Unknown Participation Statistics in Federated Averaging | 6.00 | 6.75 | 1.92 | 0.75 | |
| 644 | Active Test-Time Adaptation: Theoretical Analyses and An Algorithm | 6.50 | 6.75 | 1.30 | 0.25 | |
| 645 | Coeditor: Leveraging Repo-level Diffs for Code Auto-editing | 6.00 | 6.25 | 1.09 | 0.25 | |
| 646 | A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models | 6.25 | 6.75 | 1.30 | 0.50 | |
| 647 | Masked Distillation Advances Self-Supervised Transformer Architecture Search | 5.75 | 6.75 | 1.30 | 1.00 | |
| 648 | Towards Foundation Models for Knowledge Graph Reasoning | 6.75 | 6.75 | 1.30 | 0.00 | |
| 649 | Faithful Rule Extraction for Differentiable Rule Learning Models | 6.50 | 6.75 | 1.30 | 0.25 | |
| 650 | Score-based generative models break the curse of dimensionality in learning a family of sub-Gaussian distributions | 6.75 | 6.75 | 1.30 | 0.00 | |
| 651 | Soft Mixture Denoising: Beyond the Expressive Bottleneck of Diffusion Models | 6.00 | 6.75 | 1.30 | 0.75 | |
| 652 | MetaPhysiCa: Improving OOD Robustness in Physics-informed Machine Learning | 6.25 | 7.00 | 1.00 | 0.75 | |
| 653 | Critical Learning Periods Emerge Even in Deep Linear Networks | 5.75 | 7.25 | 1.92 | 1.50 | |
| 654 | Representation Deficiency in Masked Language Modeling | 6.50 | 6.75 | 2.59 | 0.25 | |
| 655 | SAFLEX: Self-Adaptive Augmentation via Feature Label Extrapolation | 6.75 | 6.75 | 2.17 | 0.00 | |
| 656 | Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks | 6.00 | 6.75 | 1.30 | 0.75 | |
| 657 | Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition | 6.75 | 7.00 | 1.00 | 0.25 | |
| 658 | A General Framework for User-Guided Bayesian Optimization | 6.00 | 6.75 | 1.30 | 0.75 | |
| 659 | Compressing LLMs: The Truth is Rarely Pure and Never Simple | 6.25 | 6.75 | 1.30 | 0.50 | |
| 660 | Networked Inequality: Preferential Attachment Bias in Graph Neural Network Link Prediction | 6.25 | 6.00 | 1.22 | -0.25 | |
| 661 | PB-LLM: Partially Binarized Large Language Models | 6.00 | 6.75 | 1.30 | 0.75 | |
| 662 | Intelligent Switching for Reset-Free RL | 6.25 | 6.75 | 1.30 | 0.50 | |
| 663 | Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning | 5.75 | 6.75 | 1.30 | 1.00 | |
| 664 | Successor Heads: Recurring, Interpretable Attention Heads In The Wild | 6.50 | 6.75 | 2.17 | 0.25 | |
| 665 | Towards Faithful XAI Evaluation via Generalization-Limited Backdoor Watermark | 5.75 | 6.75 | 1.30 | 1.00 | |
| 666 | NeRM: Learning Neural Representations for High-Framerate Human Motion Synthesis | 6.75 | 7.25 | 1.30 | 0.50 | |
| 667 | Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models | 6.75 | 6.75 | 1.30 | 0.00 | |
| 668 | InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation | 6.00 | 7.00 | 1.00 | 1.00 | |
| 669 | Is Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today? | 5.25 | 6.75 | 2.17 | 1.50 | |
| 670 | ITPNet: Towards Instantaneous Trajectory Prediction for Autonomous Driving | 6.50 | 6.75 | 1.30 | 0.25 | |
| 671 | SetCSE: Set Operations using Contrastive Learning of Sentence Embeddings | 5.75 | 6.75 | 1.30 | 1.00 | |
| 672 | Demystifying Embedding Spaces using Large Language Models | 6.50 | 6.75 | 1.30 | 0.25 | |
| 673 | Robustness Over Time: Understanding Adversarial Examples’ Effectiveness on Longitudinal Versions of Large Language Models | 6.25 | 6.75 | 1.30 | 0.50 | |
| 674 | Robust Similarity Learning with Difference Alignment Regularization | 6.25 | 6.75 | 1.30 | 0.50 | |
| 675 | Large Language Models Cannot Self-Correct Reasoning Yet | 6.00 | 6.75 | 1.30 | 0.75 | |
| 676 | MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback | 6.25 | 6.75 | 1.30 | 0.50 | |
| 677 | On the Stability of Iterative Retraining of Generative Models on their own Data | 6.25 | 6.75 | 1.30 | 0.50 | |
| 678 | Masked Completion via Structured Diffusion with White-Box Transformers | 5.67 | 6.75 | 1.30 | 1.08 | |
| 679 | Stabilizing Backpropagation Through Time to Learn Complex Physics | 5.50 | 6.75 | 2.17 | 1.25 | |
| 680 | Data Filtering Networks | 6.25 | 6.75 | 1.30 | 0.50 | |
| 681 | Neural Rate Control for Learned Video Compression | 6.00 | 6.75 | 1.30 | 0.75 | |
| 682 | Unveiling the Pitfalls of Knowledge Editing for Large Language Models | 6.50 | 6.75 | 1.30 | 0.25 | |
| 683 | ACRF: Compressing Explicit Neural Radiance Fields via Attribute Compression | 6.75 | 7.00 | 1.00 | 0.25 | |
| 684 | Periodicity Decoupling Framework for Long-term Series Forecasting | 6.75 | 6.75 | 2.17 | 0.00 | |
| 685 | ImagenHub: Standardizing the evaluation of conditional image generation models | 6.00 | 6.75 | 1.30 | 0.75 | |
| 686 | Graphpulse: Topological representations for temporal graph property prediction | 5.50 | 7.00 | 1.00 | 1.50 | |
| 687 | Point2SSM: Learning Morphological Variations of Anatomies from Point Clouds | 6.25 | 7.25 | 1.30 | 1.00 | |
| 688 | On gauge freedom, conservativity and intrinsic dimensionality estimation in diffusion models | 6.00 | 6.75 | 1.30 | 0.75 | |
| 689 | DoraemonGPT: Toward Solving Real-world Tasks with Large Language Models | 5.00 | 6.75 | 1.30 | 1.75 | |
| 690 | Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM | 6.75 | 6.75 | 1.30 | 0.00 | |
| 691 | RetroBridge: Modeling Retrosynthesis with Markov Bridges | 6.50 | 6.75 | 1.30 | 0.25 | |
| 692 | FreeDyG: Frequency Enhanced Continuous-Time Dynamic Graph Model for Link Prediction | 6.50 | 6.75 | 1.30 | 0.25 | |
| 693 | A Cognitive Model for Learning Abstract Relational Structures from Memory-based Decision-Making Tasks | 6.75 | 6.75 | 1.30 | 0.00 | |
| 694 | Rethinking Label Poisoning for GNNs: Pitfalls and Attacks | 6.00 | 6.75 | 1.30 | 0.75 | |
| 695 | Bridging State and History Representations: Understanding Self-Predictive RL | 6.00 | 6.75 | 2.17 | 0.75 | |
| 696 | Text-to-3D with Classifier Score Distillation | 6.75 | 6.75 | 1.30 | 0.00 | |
| 697 | A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis | 6.25 | 7.25 | 1.30 | 1.00 | |
| 698 | GPT-4 Is Too Smart To Be Safe: Stealthy Chat with LLMs via Cipher | 6.50 | 6.75 | 1.30 | 0.25 | |
| 699 | Contrastive Learning is Spectral Clustering on Similarity Graph | 6.00 | 6.75 | 1.92 | 0.75 | |
| 700 | Embodied Active Defense: Leveraging Recurrent Feedback to Counter Adversarial Patches | 6.25 | 6.75 | 1.30 | 0.50 | |
| 701 | ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs | 5.50 | 7.00 | 1.00 | 1.50 | |
| 702 | Efficient Planning with Latent Diffusion | 6.25 | 6.75 | 1.30 | 0.50 | |
| 703 | Neural Snowflakes: Universal Latent Graph Inference via Trainable Latent Geometries | 6.33 | 6.75 | 1.30 | 0.42 | |
| 704 | Variational Inference for SDEs Driven by Fractional Noise | 6.25 | 6.75 | 1.30 | 0.50 | |
| 705 | Xformer: Hybrid X-Shaped Transformer for Image Denoising | 6.50 | 6.75 | 1.30 | 0.25 | |
| 706 | Forward $chi^2$ Divergence Based Variational Importane Sampling | 5.50 | 6.75 | 1.30 | 1.25 | |
| 707 | Neuron Activation Coverage: Rethinking Out-of-distribution Detection and Generalization | 5.50 | 6.75 | 1.30 | 1.25 | |
| 708 | How connectivity structure shapes rich and lazy learning in neural circuits | 5.25 | 6.75 | 1.30 | 1.50 | |
| 709 | Adaptive Rational Activations to Boost Deep Reinforcement Learning | 4.75 | 7.50 | 0.87 | 2.75 | |
| 710 | Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency | 6.75 | 7.00 | 1.00 | 0.25 | |
| 711 | Statistically Optimal $K$-means Clustering via Nonnegative Low-rank Semidefinite Programming | 6.75 | 6.75 | 2.17 | 0.00 | |
| 712 | Large Language Models as Optimizers | 5.50 | 6.75 | 1.30 | 1.25 | |
| 713 | Unprocessing Seven Years of Algorithmic Fairness | 6.25 | 7.00 | 1.00 | 0.75 | |
| 714 | ToRA: A Tool-Integrated Reasoning Agent for Mathematical Problem Solving | 6.75 | 6.75 | 1.30 | 0.00 | |
| 715 | Guaranteed Approximation Bounds for Mixed-Precision Neural Operators | 6.75 | 6.75 | 1.30 | 0.00 | |
| 716 | Divide and not forget: Ensemble of selectively trained experts in Continual Learning | 6.00 | 7.00 | 1.00 | 1.00 | |
| 717 | Locality Sensitive Sparse Encoding for Learning World Models Online | 6.00 | 6.67 | 0.94 | 0.67 | |
| 718 | Learning model uncertainty as variance-minimizing instance weights | 5.33 | 6.67 | 0.94 | 1.33 | |
| 719 | Adaptive Causal Balancing for Collaborative Filtering | 5.67 | 6.67 | 0.94 | 1.00 | |
| 720 | Diagnosing Transformers: Illuminating Feature Spaces for Clinical Decision-Making | 6.67 | 6.67 | 0.94 | 0.00 | |
| 721 | Certified Robustness on Visual Graph Matching via Searching Optimal Smoothing Range | 6.00 | 6.67 | 0.94 | 0.67 | |
| 722 | Leveraging Previous Tasks in Optimizing Risk Measures with Gaussian Processes | 6.50 | 6.67 | 0.94 | 0.17 | |
| 723 | Are Bert Family Good Instruction Followers? A Study on Their Potential And Limitations | 6.33 | 6.67 | 0.94 | 0.33 | |
| 724 | Tractable MCMC for Private Learning with Pure and Gaussian Differential Privacy | 6.00 | 6.67 | 0.94 | 0.67 | |
| 725 | Doubly Robust Instance-Reweighted Adversarial Training | 6.00 | 6.67 | 0.94 | 0.67 | |
| 726 | SpaCE: The Spatial Confounding Environment | 6.33 | 6.67 | 0.94 | 0.33 | |
| 727 | Revisiting the Last-Iterative Convergence of Stochastic Gradient Methods | 6.33 | 6.67 | 0.94 | 0.33 | |
| 728 | Instilling Inductive Biases with Subnetworks | 6.67 | 6.67 | 0.94 | 0.00 | |
| 729 | Harnessing Density Ratios for Online Reinforcement Learning | 6.67 | 6.67 | 0.94 | 0.00 | |
| 730 | Llemma: An Open Language Model for Mathematics | 6.67 | 6.67 | 0.94 | 0.00 | |
| 731 | Anisotropy helps: improved statistical and computational complexity of the mean-field Langevin dynamics under structured data | 6.33 | 6.67 | 0.94 | 0.33 | |
| 732 | Confidential-DPproof: Confidential Proof of Differentially Private Training | 6.67 | 6.33 | 1.25 | -0.33 | |
| 733 | Fiber Monte Carlo | 5.67 | 6.67 | 0.94 | 1.00 | |
| 734 | MCM: Masked Cell Modeling for Anomaly Detection in Tabular Data | 6.67 | 6.67 | 0.94 | 0.00 | |
| 735 | Nemesis: Normalizing the soft-prompt vectors of vision-language models | 5.67 | 6.67 | 0.94 | 1.00 | |
| 736 | Are Transformers with One Layer Self-Attention Using Low-Rank Weight Matrices Universal Approximators? | 6.33 | 6.67 | 0.94 | 0.33 | |
| 737 | Generalized Activation via Multivariate Projection | 5.33 | 6.67 | 0.94 | 1.33 | |
| 738 | Bayes Conditional Distribution Estimation for Knowledge Distillation Based on Conditional Mutual Information | 5.33 | 6.67 | 0.94 | 1.33 | |
| 739 | Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting | 6.33 | 6.67 | 0.94 | 0.33 | |
| 740 | CrossLoco: Human Motion Driven Control of Legged Robots via Guided Unsupervised Reinforcement Learning | 6.67 | 6.67 | 0.94 | 0.00 | |
| 741 | Understanding Reconstruction Attacks with the Neural Tangent Kernel and Dataset Distillation | 5.67 | 6.67 | 0.94 | 1.00 | |
| 742 | Behaviour Distillation | 5.67 | 6.67 | 0.94 | 1.00 | |
| 743 | Bayesian Optimization through Gaussian Cox Process Models for Spatio-temporal Data | 6.00 | 6.67 | 0.94 | 0.67 | |
| 744 | Privately Aligning Language Models with Reinforcement Learning | 6.33 | 6.67 | 0.94 | 0.33 | |
| 745 | Junk DNA Hypothesis: A Task-Centric Angle of LLM Pre-trained Weights through Sparsity | 6.67 | 6.67 | 0.94 | 0.00 | |
| 746 | Functional Interpolation for Relative Positions improves Long Context Transformers | 6.33 | 6.67 | 0.94 | 0.33 | |
| 747 | Pre-training with Random Orthogonal Projection Image Modeling | 6.67 | 6.67 | 0.94 | 0.00 | |
| 748 | Implicit Maximum a Posteriori Filtering via Adaptive Optimization | 6.33 | 6.67 | 0.94 | 0.33 | |
| 749 | TextField3D: Towards Enhancing Open-Vocabulary 3D Generation with Noisy Text Fields | 6.00 | 6.67 | 0.94 | 0.67 | |
| 750 | Multilinear Operator Networks | 4.67 | 6.67 | 0.94 | 2.00 | |
| 751 | Learning Mean Field Games on Sparse Graphs: A Hybrid Graphex Approach | 6.67 | 6.67 | 0.94 | 0.00 | |
| 752 | Deep Generative Clustering with Multimodal Diffusion Variational Autoencoders | 6.33 | 6.67 | 0.94 | 0.33 | |
| 753 | Learning Hierarchical World Models with Adaptive Temporal Abstractions from Discrete Latent Dynamics | 6.67 | 6.67 | 0.94 | 0.00 | |
| 754 | SALMONN: Towards Generic Hearing Abilities for Large Language Models | 5.67 | 6.67 | 0.94 | 1.00 | |
| 755 | Improving Non-Transferable Representation Learning by Harnessing Content and Style | 6.67 | 6.67 | 0.94 | 0.00 | |
| 756 | Provable and Practical: Efficient Exploration in Reinforcement Learning via Langevin Monte Carlo | 6.33 | 6.67 | 0.94 | 0.33 | |
| 757 | Rethinking Branching on Exact Combinatorial Optimization Solver: The First Deep Symbolic Discovery Framework | 6.67 | 6.67 | 0.94 | 0.00 | |
| 758 | Probabilistically Rewired Message-Passing Neural Networks | 5.67 | 6.67 | 0.94 | 1.00 | |
| 759 | Skip-Attention: Improving Vision Transformers by Paying Less Attention | 6.33 | 6.67 | 0.94 | 0.33 | |
| 760 | Benchmarking and Improving Generator-Validator Consistency of Language Models | 6.00 | 6.67 | 0.94 | 0.67 | |
| 761 | Transferring Learning Trajectories of Neural Networks | 6.00 | 6.67 | 0.94 | 0.67 | |
| 762 | VQ-TR: Vector Quantized Attention for Time Series Forecasting | 5.00 | 6.67 | 0.94 | 1.67 | |
| 763 | MaGIC: Multi-modality Guided Image Completion | 6.00 | 6.67 | 0.94 | 0.67 | |
| 764 | Solving Diffusion ODEs with Optimal Boundary Conditions for Better Image Super-Resolution | 6.00 | 6.67 | 0.94 | 0.67 | |
| 765 | DNA-GPT: Divergent N-Gram Analysis for Training-Free Detection of GPT-Generated Text | 6.33 | 6.67 | 0.94 | 0.33 | |
| 766 | Compose and Conquer: Diffusion-Based 3D Depth Aware Composable Image Synthesis | 6.00 | 6.67 | 0.94 | 0.67 | |
| 767 | Doubly Robust Proximal Causal Learning for Continuous Treatments | 6.00 | 6.67 | 0.94 | 0.67 | |
| 768 | SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning | 6.00 | 6.67 | 0.94 | 0.67 | |
| 769 | Query-Policy Misalignment in Preference-Based Reinforcement Learning | 5.50 | 6.67 | 0.94 | 1.17 | |
| 770 | Feature-aligned N-BEATS with Sinkhorn divergence | 6.33 | 6.67 | 0.94 | 0.33 | |
| 771 | Large Language Model Cascades with Mixture of Thought Representations for Cost-Efficient Reasoning | 6.67 | 6.67 | 0.94 | 0.00 | |
| 772 | Revisit and Outstrip Entity Alignment: A Perspective of Generative Models | 5.33 | 6.67 | 0.94 | 1.33 | |
| 773 | More is Better: when Infinite Overparameterization is Optimal and Overfitting is Obligatory | 6.33 | 6.67 | 0.94 | 0.33 | |
| 774 | Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models | 6.33 | 6.67 | 0.94 | 0.33 | |
| 775 | Quantifying Interactions in Semi-supervised Multimodal Learning: Guarantees and Applications | 6.33 | 6.67 | 0.94 | 0.33 | |
| 776 | Time Fairness in Online Knapsack Problems | 6.33 | 6.67 | 0.94 | 0.33 | |
| 777 | Causal-StoNet: Causal Inference for High-Dimensional Complex Data | 5.67 | 6.67 | 0.94 | 1.00 | |
| 778 | OpenTab: Advancing Large Language Models as Open-domain Table Reasoners | 6.67 | 6.67 | 0.94 | 0.00 | |
| 779 | Self-Consuming Generative Models Go MAD | 6.67 | 6.67 | 0.94 | 0.00 | |
| 780 | Non-Asymptotic Analysis for Single-Loop (Natural) Actor-Critic with Compatible Function Approximation | 6.33 | 6.67 | 0.94 | 0.33 | | 8, 6, 6, 6, 6, 6 | | 8, 8, 6, 6, 6, 6 |
|
| 781 | CALICO: Self-Supervised Camera-LiDAR Contrastive Pre-training for BEV Perception | 6.00 | 6.67 | 0.94 | 0.67 | |
| 782 | Learning dynamic representations of the functional connectome in neurobiological networks | 6.33 | 6.67 | 0.94 | 0.33 | |
| 783 | Improved Probabilistic Image-Text Representations | 6.00 | 6.67 | 0.94 | 0.67 | |
| 784 | Learning Stackable and Skippable LEGO Bricks for Efficient, Reconfigurable, and Variable-Resolution Diffusion Modeling | 5.67 | 6.67 | 0.94 | 1.00 | |
| 785 | Long-range Neural Atom Learning for Molecular Graphs | 5.00 | 6.67 | 0.94 | 1.67 | |
| 786 | On the Limitations of Temperature Scaling for Distributions with Overlaps | 6.67 | 6.67 | 0.94 | 0.00 | |
| 787 | A Variational Framework for Estimating Continuous Treatment Effects with Measurement Error | 5.00 | 7.33 | 0.94 | 2.33 | |
| 788 | CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets | 6.67 | 6.67 | 0.94 | 0.00 | |
| 789 | FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets | 6.67 | 6.67 | 0.94 | 0.00 | |
| 790 | Towards Category Unification of 3D Single Object Tracking on Point Clouds | 6.67 | 6.67 | 0.94 | 0.00 | |
| 791 | You Only Query Once: An Efficient Label-Only Membership Inference Attack | 5.67 | 6.67 | 0.94 | 1.00 | |
| 792 | NeurRev: Train Better Sparse Neural Network Practically via Neuron Revitalization | 6.33 | 6.67 | 0.94 | 0.33 | |
| 793 | Manifold Diffusion Fields | 6.00 | 6.67 | 0.94 | 0.67 | |
| 794 | Neur2RO: Neural Two-Stage Robust Optimization | 6.00 | 6.67 | 0.94 | 0.67 | |
| 795 | Speed Limits for Deep Learning | 5.67 | 6.67 | 0.94 | 1.00 | |
| 796 | Habitat 3.0: A Co-Habitat for Humans, Avatars, and Robots | 6.67 | 6.67 | 0.94 | 0.00 | |
| 797 | RECOMBINER: Robust and Enhanced Compression with Bayesian Implicit Neural Representations | 5.33 | 6.67 | 0.94 | 1.33 | |
| 798 | On the Humanity of Conversational AI: Evaluating the Psychological Portrayal of LLMs | 6.67 | 6.67 | 0.94 | 0.00 | |
| 799 | Accelerated Sampling with Stacked Restricted Boltzmann Machines | 6.00 | 6.67 | 0.94 | 0.67 | |
| 800 | Neural Fine-Tuning Search for Few-Shot Learning | 6.33 | 7.33 | 0.94 | 1.00 | |
| 801 | Noise Map Guidance: Inversion with Spatial Context for Real Image Editing | 6.67 | 6.67 | 0.94 | 0.00 | |
| 802 | Output-Domain Focused Inductive Bias on Latent Feature Clusters in Visual Classification | 6.00 | 6.67 | 0.94 | 0.67 | |
| 803 | Personalize Segment Anything Model with One Shot | 6.67 | 6.67 | 0.94 | 0.00 | |
| 804 | Deep Reinforcement Learning for Efficient and Fair Allocation of Health Care Resources | 6.00 | 6.67 | 2.36 | 0.67 | |
| 805 | Towards Best Practices of Activation Patching in Language Models: Metrics and Methods | 5.67 | 6.67 | 0.94 | 1.00 | |
| 806 | FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators | 6.33 | 6.67 | 0.94 | 0.33 | |
| 807 | Stable Neural Stochastic Differential Equations in Analyzing Irregular Time Series Data | 6.00 | 6.67 | 0.94 | 0.67 | |
| 808 | Improving Out-of-Domain Generalization with Domain Relations | 6.17 | 6.67 | 0.94 | 0.50 | | 6, 6, 3, 8, 8, 6 | | 6, 6, 6, 8, 8, 6 |
|
| 809 | Sample Relationship from Learning Dynamics Matters for Generalisation | 6.00 | 6.67 | 0.94 | 0.67 | |
| 810 | FARS: FSM-Augmentation to Make LLMs Hallucinate the Right APIs | 6.00 | 6.67 | 0.94 | 0.67 | |
| 811 | A Hierarchical Bayesian Model for Few-Shot Meta Learning | 6.50 | 6.67 | 0.94 | 0.17 | | 6, 5, 8, 6, 6, 8 | | 6, 6, 8, 6, 6, 8 |
|
| 812 | Interventional Fairness on Partially Known Causal Graphs: A Constrained Optimization Approach | 6.67 | 6.67 | 0.94 | 0.00 | |
| 813 | Sentence-level Prompts Benefit Composed Image Retrieval | 6.00 | 6.67 | 0.94 | 0.67 | |
| 814 | THOUGHT PROPAGATION: AN ANALOGICAL APPROACH TO COMPLEX REASONING WITH LARGE LANGUAGE MODELS | 6.33 | 6.67 | 0.94 | 0.33 | |
| 815 | HIFA: High-fidelity Text-to-3D Generation with Advanced Diffusion Guidance | 6.67 | 6.67 | 0.94 | 0.00 | |
| 816 | Delta-AI: Local objectives for amortized inference in sparse graphical models | 6.67 | 6.67 | 0.94 | 0.00 | |
| 817 | DreamLLM: Synergistic Multimodal Comprehension and Creation | 6.33 | 6.67 | 0.94 | 0.33 | |
| 818 | Function-space Parameterization of Neural Networks for Sequential Learning | 5.33 | 6.67 | 0.94 | 1.33 | |
| 819 | G$^2$N$^2$ : Weisfeiler and Lehman go grammatical | 6.33 | 6.67 | 0.94 | 0.33 | |
| 820 | Mind Your Augmentation: The Key to Decoupling Dense Self-Supervised Learning | 6.67 | 6.67 | 0.94 | 0.00 | |
| 821 | Local Search GFlowNets | 6.33 | 6.67 | 0.94 | 0.33 | |
| 822 | Revisiting Deep Audio-Text Retrieval Through the Lens of Transportation | 6.67 | 6.67 | 0.94 | 0.00 | |
| 823 | Data-independent Module-aware Pruning for Hierarchical Vision Transformers | 7.00 | 6.67 | 0.94 | -0.33 | |
| 824 | Continuous-Multiple Image Outpainting in One-Step via Positional Query and A Diffusion-based Approach | 6.33 | 6.67 | 0.94 | 0.33 | |
| 825 | De novo Protein Design Using Geometric Vector Field Networks | 5.33 | 6.67 | 0.94 | 1.33 | |
| 826 | Inducing High Energy-Latency of Large Vision-Language Models with Verbose Images | 6.00 | 6.67 | 0.94 | 0.67 | |
| 827 | Approximately Piecewise E(3) Equivariant Point Networks | 6.33 | 6.67 | 0.94 | 0.33 | |
| 828 | Weakly-supervised Audio Separation via Bi-modal Semantic Similarity | 6.00 | 6.67 | 0.94 | 0.67 | |
| 829 | Learning with a Mole: Transferable latent spatial representations for navigation without reconstruction | 6.33 | 6.67 | 0.94 | 0.33 | |
| 830 | Tailoring Retrieval Representations to Long-term Visual Localization | 6.33 | 6.67 | 0.94 | 0.33 | |
| 831 | Real-time Photorealistic Dynamic Scene Representation and Rendering with 4D Gaussian Splatting | 6.67 | 6.67 | 0.94 | 0.00 | |
| 832 | Bayesian Bi-clustering of Neural Spiking Activity with Latent Structures | 5.67 | 6.67 | 0.94 | 1.00 | |
| 833 | Rethinking and Extending the Probabilistic Inference Capacity of GNNs | 6.60 | 6.60 | 1.20 | 0.00 | | 6, 5, 8, 6, 8 | | 5, 6, 8, 6, 8 |
|
| 834 | Parsing neural dynamics with infinite recurrent switching linear dynamical systems | 6.00 | 6.60 | 1.20 | 0.60 | | 6, 5, 8, 6, 5 | | 6, 6, 8, 8, 5 |
|
| 835 | Scaling Convex Neural Networks with Burer-Monteiro Factorization | 6.00 | 6.60 | 1.20 | 0.60 | | 8, 5, 3, 6, 8 | | 8, 5, 6, 6, 8 |
|
| 836 | Fast Hyperboloid Decision Tree Algorithms | 6.60 | 6.60 | 1.20 | 0.00 | | 5, 6, 8, 6, 8 | | 5, 6, 8, 6, 8 |
|
| 837 | Discrete Diffusion Language Modeling by Estimating the Ratios of the Data Distribution | 5.20 | 6.60 | 1.20 | 1.40 | | 3, 5, 8, 5, 5 | | 8, 6, 8, 5, 6 |
|
| 838 | Transformers can optimally learn regression mixture models | 5.20 | 6.80 | 0.98 | 1.60 | | 5, 6, 5, 5, 5 | | 6, 8, 6, 6, 8 |
|
| 839 | Non-Vacuous Generalization Bounds for Large Language Models | 6.40 | 6.60 | 1.20 | 0.20 | | 5, 8, 6, 5, 8 | | 6, 8, 6, 5, 8 |
|
| 840 | Unbiased Watermark for Large Language Models | 6.20 | 6.60 | 1.20 | 0.40 | | 6, 6, 6, 8, 5 | | 6, 8, 6, 8, 5 |
|
| 841 | Consistent Multi-Class Classification from Multiple Unlabeled Datasets | 5.40 | 6.60 | 1.20 | 1.20 | | 5, 8, 6, 5, 3 | | 6, 8, 8, 5, 6 |
|
| 842 | Uncertainty Quantification via Stable Distribution Propagation | 6.00 | 6.60 | 1.20 | 0.60 | | 8, 5, 6, 6, 5 | | 8, 6, 6, 8, 5 |
|
| 843 | Parametric Augmentation for Time Series Contrastive Learning | 5.00 | 6.60 | 1.20 | 1.60 | | 5, 1, 5, 8, 6 | | 6, 5, 6, 8, 8 |
|
| 844 | It's Never Too Late: Fusing Acoustic Information into Large Language Models for Automatic Speech Recognition | 6.40 | 6.60 | 1.74 | 0.20 | | 10, 5, 6, 6, 5 | | 10, 6, 6, 6, 5 |
|
| 845 | Rethinking Moreau Envelope for Nonconvex Bi-Level Optimization: A Single-loop and Hessian-free Solution Strategy | 6.60 | 6.60 | 1.20 | 0.00 | | 6, 5, 8, 6, 8 | | 6, 5, 8, 6, 8 |
|
| 846 | Fast Ensembling with Diffusion Schr'odinger Bridge | 5.40 | 6.60 | 1.20 | 1.20 | | 5, 6, 5, 8, 3 | | 6, 8, 6, 8, 5 |
|
| 847 | Learning Implicit Representation for Reconstructing Articulated Objects | 6.20 | 6.60 | 1.20 | 0.40 | | 5, 5, 8, 5, 8 | | 5, 6, 8, 6, 8 |
|
| 848 | Vibroacoustic Frequency Response Prediction with Query-based Operator Networks | 6.20 | 6.00 | 1.10 | -0.20 | | 6, 6, 8, 5, 6 | | 8, 6, 5, 5, 6 |
|
| 849 | LEAP: Liberate Sparse-View 3D Modeling from Camera Poses | 6.60 | 6.60 | 1.74 | 0.00 | | 6, 10, 5, 6, 6 | | 6, 10, 5, 6, 6 |
|
| 850 | TVTSv2: Learning Out-of-the-box Spatiotemporal Visual Representations at Scale | 6.50 | 6.50 | 1.50 | 0.00 | |
| 851 | Forward Learning with Top-Down Feedback: Empirical and Analytical Characterization | 6.00 | 6.50 | 1.50 | 0.50 | |
| 852 | Demonstration-Regularized RL | 5.25 | 6.50 | 0.87 | 1.25 | |
| 853 | Fair and Efficient Contribution Valuation for Vertical Federated Learning | 5.25 | 6.50 | 0.87 | 1.25 | |
| 854 | sRGB Real Noise Modeling via Noise-Aware Sampling with Normalizing Flows | 5.75 | 6.50 | 0.87 | 0.75 | |
| 855 | UNR-Explainer: Counterfactual Explanations for Unsupervised Node Representation Learning Models | 5.75 | 6.50 | 0.87 | 0.75 | |
| 856 | Exploring the Promise and Limits of Real-Time Recurrent Learning | 6.00 | 6.50 | 0.87 | 0.50 | |
| 857 | PlaSma: Procedural Knowledge Models for Language-based Planning and Re-Planning | 6.00 | 6.50 | 0.87 | 0.50 | |
| 858 | Understanding In-Context Learning in Transformers and LLMs by Learning to Learn Discrete Functions | 5.50 | 7.00 | 1.00 | 1.50 | |
| 859 | Abstractors and relational cross-attention: An inductive bias for explicit relational reasoning in Transformers | 6.25 | 6.50 | 0.87 | 0.25 | |
| 860 | An Emulator for Fine-tuning Large Language Models using Small Language Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 861 | Regularized Robust MDPs and Risk-Sensitive MDPs: Equivalence, Policy Gradient, and Sample Complexity | 5.75 | 6.50 | 0.87 | 0.75 | |
| 862 | Circuit Component Reuse Across Tasks in Transformer Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 863 | SineNet: Learning Temporal Dynamics in Time-Dependent Partial Differential Equations | 4.50 | 6.50 | 0.87 | 2.00 | |
| 864 | GNNBoundary: Towards Explaining Graph Neural Networks through the Lens of Decision Boundaries | 6.00 | 6.50 | 0.87 | 0.50 | |
| 865 | Optimization without retraction on the random generalized Stiefel manifold for canonical correlation analysis | 6.50 | 6.50 | 2.06 | 0.00 | |
| 866 | Expressive Losses for Verified Robustness via Convex Combinations | 5.25 | 6.75 | 1.30 | 1.50 | |
| 867 | On Diffusion Modeling for Anomaly Detection | 6.25 | 7.00 | 1.00 | 0.75 | |
| 868 | AutomaTikZ: Text-Guided Synthesis of Scientific Vector Graphics with TikZ | 6.25 | 6.50 | 0.87 | 0.25 | |
| 869 | 3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining | 5.75 | 6.50 | 0.87 | 0.75 | |
| 870 | Efficient Subgraph GNNs by Learning Effective Selection Policies | 5.75 | 6.50 | 0.87 | 0.75 | |
| 871 | Active Retrosynthetic Planning Aware of Route Quality | 6.00 | 6.50 | 0.87 | 0.50 | |
| 872 | Object-Centric Semantic Vector Quantization | 5.50 | 6.50 | 0.87 | 1.00 | |
| 873 | Data Imputation by Pursuing Better Classification: A Supervised Learning Approach | 5.50 | 6.50 | 1.50 | 1.00 | |
| 874 | An Agnostic View on the Cost of Overfitting in (Kernel) Ridge Regression | 7.00 | 6.50 | 0.87 | -0.50 | |
| 875 | Scalable Monotonic Neural Networks | 5.25 | 6.50 | 1.50 | 1.25 | |
| 876 | A Differentially Private Clustering Algorithm for Well-Clustered Graphs | 6.50 | 6.50 | 0.87 | 0.00 | |
| 877 | Reward-Consistent Dynamics Models are Strongly Generalizable for Offline Reinforcement Learning | 6.00 | 6.50 | 0.87 | 0.50 | |
| 878 | Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion | 6.25 | 6.50 | 0.87 | 0.25 | |
| 879 | CompA: Addressing the Gap in Compositional Reasoning in Audio-Language Models | 4.75 | 6.50 | 0.87 | 1.75 | |
| 880 | Beyond Imitation: Leveraging Fine-grained Quality Signals for Alignment | 5.50 | 6.50 | 0.87 | 1.00 | |
| 881 | CLEX: Continuous Length Extrapolation for Large Language Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 882 | Mitigating Severe Robustness Degradation on Graphs | 6.25 | 6.50 | 0.87 | 0.25 | |
| 883 | Scalabale AI Safety via Doubly-Efficient Debate | 6.50 | 6.50 | 0.87 | 0.00 | |
| 884 | PlatoLM: Teaching LLMs via a Socratic Questioning User Simulator | 6.00 | 6.50 | 0.87 | 0.50 | |
| 885 | Leveraging Hyperbolic Embeddings for Coarse-to-Fine Robot Design | 6.00 | 6.50 | 0.87 | 0.50 | |
| 886 | A New Type of Associative Memory Network with Exponential Storage Capacity | 6.50 | 6.50 | 1.50 | 0.00 | |
| 887 | Exploring Weight Balancing on Long-Tailed Recognition Problem | 6.25 | 6.50 | 0.87 | 0.25 | |
| 888 | Differentiable Sensor Layouts for End-to-End Learning of Task-Specific Camera Parameters | 6.50 | 6.50 | 1.50 | 0.00 | |
| 889 | PAE: Reinforcement Learning from External Knowledge for Efficient Exploration | 5.50 | 6.50 | 0.87 | 1.00 | |
| 890 | BroGNet: Momentum-Conserving Graph Neural Stochastic Differential Equation for Learning Brownian Dynamics | 5.00 | 6.50 | 0.87 | 1.50 | |
| 891 | Making Retrieval-Augmented Language Models Robust to Irrelevant Context | 5.75 | 6.50 | 0.87 | 0.75 | |
| 892 | Identifying Policy Gradient Subspaces | 5.00 | 6.50 | 0.87 | 1.50 | |
| 893 | Training-free Multi-objective Diffusion Model for 3D Molecule Generation | 6.25 | 6.50 | 0.87 | 0.25 | |
| 894 | Two Heads are Better than One: Towards Better Adversarial Robustness by Combining Transduction and Rejection | 6.00 | 6.50 | 0.87 | 0.50 | |
| 895 | Generating Pragmatic Examples to Train Neural Program Synthesizers | 6.00 | 6.50 | 0.87 | 0.50 | |
| 896 | Conformal Prediction for Deep Classifier via Label Ranking | 6.50 | 6.50 | 1.50 | 0.00 | |
| 897 | BayesDiff: Estimating Pixel-wise Uncertainty in Diffusion via Bayesian Inference | 5.00 | 6.50 | 0.87 | 1.50 | |
| 898 | Towards Aligned Layout Generation via Diffusion Model with Aesthetic Constraints | 6.25 | 6.50 | 0.87 | 0.25 | |
| 899 | On the Fairness ROAD: Robust Optimization for Adversarial Debiasing | 6.25 | 6.50 | 0.87 | 0.25 | |
| 900 | The Lipschitz-Variance-Margin Tradeoff for Enhanced Randomized Smoothing | 4.75 | 6.50 | 0.87 | 1.75 | |
| 901 | Building Cooperative Embodied Agents Modularly with Large Language Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 902 | Poly-View Contrastive Learning | 6.25 | 6.50 | 0.87 | 0.25 | |
| 903 | Efficient Score Matching with Deep Equilibrium Layers | 5.25 | 6.50 | 0.87 | 1.25 | |
| 904 | Rethinking the Benefits of Steerable Features in 3D Equivariant Graph Neural Networks | 5.25 | 6.50 | 0.87 | 1.25 | |
| 905 | Prompt Risk Control: A Rigorous Framework for Responsible Deployment of Large Language Models | 6.50 | 6.50 | 0.87 | 0.00 | |
| 906 | A Primal-Dual Approach to Solving Variational Inequalities with General Constraints | 6.50 | 6.50 | 0.87 | 0.00 | |
| 907 | Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words | 6.00 | 6.50 | 1.50 | 0.50 | |
| 908 | Improved sampling via learned diffusions | 6.25 | 6.50 | 0.87 | 0.25 | |
| 909 | T-MARS: Improving Visual Representations by Circumventing Text Feature Learning | 6.25 | 6.50 | 0.87 | 0.25 | |
| 910 | Nougat: Neural Optical Understanding for Academic Documents | 6.50 | 6.50 | 2.69 | 0.00 | |
| 911 | Towards Generative Abstract Reasoning: Completing Raven’s Progressive Matrix via Rule Abstraction and Selection | 6.50 | 6.50 | 0.87 | 0.00 | |
| 912 | Replay across Experiments: A Natural Extension of Off-Policy RL | 5.25 | 6.50 | 0.87 | 1.25 | |
| 913 | TorchRL: A data-driven decision-making library for PyTorch | 6.25 | 6.50 | 0.87 | 0.25 | |
| 914 | Towards Robust Offline Reinforcement Learning under Diverse Data Corruption | 6.50 | 7.00 | 1.00 | 0.50 | |
| 915 | Constrained Variational Generation for Generalizable Graph Learning | 5.50 | 6.50 | 0.87 | 1.00 | |
| 916 | Lifting Architectural Constraints of Injective Flows | 5.00 | 6.50 | 1.50 | 1.50 | |
| 917 | Federated Wasserstein Distance | 5.00 | 6.50 | 0.87 | 1.50 | |
| 918 | Transformers vs. Message Passing GNNs: Distinguished in Uniform | 5.75 | 6.50 | 0.87 | 0.75 | |
| 919 | Gradual Domain Adaptation via Gradient Flow | 6.00 | 6.50 | 0.87 | 0.50 | |
| 920 | Removing Biases from Molecular Representations via Information Maximization | 5.50 | 6.50 | 0.87 | 1.00 | |
| 921 | On Adversarial Training without Perturbing all Examples | 5.75 | 6.50 | 0.87 | 0.75 | |
| 922 | On the Power of the Weisfeiler-Leman Test for Graph Motif Parameters | 6.25 | 6.50 | 0.87 | 0.25 | |
| 923 | Memorization in Self-Supervised Learning Improves Downstream Generalization | 6.00 | 6.50 | 0.87 | 0.50 | |
| 924 | Leveraging Generative Models for Unsupervised Alignment of Neural Time Series Data | 6.50 | 6.50 | 0.87 | 0.00 | |
| 925 | Neural Eigenfunctions Are Structured Representation Learners | 6.25 | 6.50 | 0.87 | 0.25 | |
| 926 | STARC: A General Framework For Quantifying Differences Between Reward Functions | 6.25 | 6.50 | 0.87 | 0.25 | |
| 927 | Beyond Concept Bottleneck Models: How to Make Black Boxes Intervenable? | 5.50 | 6.50 | 1.50 | 1.00 | |
| 928 | INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection | 6.25 | 6.50 | 0.87 | 0.25 | |
| 929 | The Convergence of Variance Exploding Diffusion Models under the Manifold Hypothesis | 5.25 | 6.50 | 0.87 | 1.25 | |
| 930 | Babel-ImageNet: Massively Multilingual Evaluation of Vision-and-Language Representations | 6.25 | 6.50 | 0.87 | 0.25 | |
| 931 | Human Feedback is not Gold Standard | 5.75 | 6.50 | 0.87 | 0.75 | |
| 932 | RODEO: Robust Out-of-Distribution Detection Via Exposing Adaptive Outliers | 6.00 | 6.50 | 0.87 | 0.50 | |
| 933 | On Harmonizing Implicit Subpopulations | 5.75 | 6.50 | 0.87 | 0.75 | |
| 934 | Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors | 6.50 | 6.50 | 1.50 | 0.00 | |
| 935 | A Study of Generalization in Offline Reinforcement Learning | 6.25 | 6.50 | 0.87 | 0.25 | |
| 936 | Emergent mechanisms for long timescales depend on training curriculum and affect performance in memory tasks | 5.50 | 6.75 | 1.30 | 1.25 | |
| 937 | Noise-free Score Distillation | 6.25 | 6.50 | 0.87 | 0.25 | |
| 938 | MIntRec2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations | 6.67 | 6.50 | 0.87 | -0.17 | |
| 939 | RLIF: Interactive Imitation Learning as Reinforcement Learning | 5.00 | 6.50 | 0.87 | 1.50 | |
| 940 | Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation | 6.50 | 6.50 | 1.50 | 0.00 | |
| 941 | Stochastic Modified Equations and Dynamics of Dropout Algorithm | 5.00 | 6.50 | 0.87 | 1.50 | |
| 942 | EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision | 6.50 | 6.50 | 1.50 | 0.00 | |
| 943 | How Do Transformers Learn In-Context Beyond Simple Functions? A Case Study on Learning with Representations | 6.25 | 6.50 | 0.87 | 0.25 | |
| 944 | Alice Benchmarks: Connecting Real World Object Re-Identification with the Synthetic | 5.50 | 6.50 | 0.87 | 1.00 | |
| 945 | LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment | 5.25 | 6.50 | 0.87 | 1.25 | |
| 946 | On the Hardness of Online Nonconvex Optimization with Single Oracle Feedback | 6.25 | 6.50 | 0.87 | 0.25 | |
| 947 | Soft Contrastive Learning for Time Series | 6.00 | 6.50 | 0.87 | 0.50 | |
| 948 | Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers | 5.25 | 6.50 | 0.87 | 1.25 | |
| 949 | Measuring Information in Text Explanations | 5.50 | 6.50 | 1.50 | 1.00 | |
| 950 | Neural Active Learning Beyond Bandits | 6.25 | 6.50 | 0.87 | 0.25 | |
| 951 | Synergistic Patch Pruning for Vision Transformer: Unifying Intra- & Inter-Layer Patch Importance | 6.25 | 6.50 | 0.87 | 0.25 | |
| 952 | Unpaired Image-to-Image Translation via Neural Schrödinger Bridge | 6.00 | 6.50 | 0.87 | 0.50 | |
| 953 | Bidirectional Temporal Diffusion Model for Temporally Consistent Human Animation | 5.75 | 6.50 | 0.87 | 0.75 | |
| 954 | L2P-MIP: Learning to Presolve for Mixed Integer Programming | 5.50 | 6.50 | 0.87 | 1.00 | |
| 955 | Graph Generation with $K^2$-trees | 6.50 | 6.50 | 1.50 | 0.00 | |
| 956 | Latent Intuitive Physics: Learning to Transfer Hidden Physics from a 3D Video | 6.50 | 6.50 | 0.87 | 0.00 | |
| 957 | Manifold Preserving Guided Diffusion | 6.00 | 6.50 | 0.87 | 0.50 | |
| 958 | Privacy-Preserving In-Context Learning for Large Language Models | 5.50 | 6.50 | 0.87 | 1.00 | |
| 959 | Topo-Diffusion: Topological Diffusion Model for Image and Point Cloud Generation | 6.50 | 6.50 | 0.87 | 0.00 | |
| 960 | HyperRep: Hypergraph-Based Self-Supervised Multimodal Representation Learning | 6.25 | 6.50 | 0.87 | 0.25 | |
| 961 | Smooth ECE: Principled Reliability Diagrams via Kernel Smoothing | 6.00 | 6.50 | 0.87 | 0.50 | |
| 962 | A General Single-Cell Analysis Framework via Conditional Diffusion Generative Models | 5.25 | 6.50 | 0.87 | 1.25 | |
| 963 | Robustifying State-space Models for Long Sequences via Approximate Diagonalization | 5.75 | 6.50 | 0.87 | 0.75 | |
| 964 | On-Policy Policy Gradient Reinforcement Learning Without On-Policy Sampling | 5.25 | 6.50 | 1.50 | 1.25 | |
| 965 | Fair Classifiers that Abstain without Harm | 6.50 | 6.50 | 0.87 | 0.00 | |
| 966 | Carrying over Algorithm in Transformers | 6.00 | 6.50 | 2.06 | 0.50 | |
| 967 | Conditional Information Bottleneck Approach for Time Series Imputation | 6.25 | 6.50 | 0.87 | 0.25 | |
| 968 | Zero redundancy distributed learning with differential privacy | 6.50 | 6.50 | 1.50 | 0.00 | |
| 969 | Principled Architecture-aware Scaling of Hyperparameters | 6.00 | 6.50 | 0.87 | 0.50 | |
| 970 | SmartPlay : A Benchmark for LLMs as Intelligent Agents | 6.00 | 6.75 | 1.30 | 0.75 | |
| 971 | Look, Remember and Reason: Grounded Reasoning in Videos with Language Models | 5.75 | 6.50 | 0.87 | 0.75 | |
| 972 | Prediction Error-based Classification for Class-Incremental Learning | 5.00 | 6.50 | 1.50 | 1.50 | |
| 973 | SCHEMA: State CHangEs MAtter for Procedure Planning in Instructional Videos | 6.25 | 6.50 | 0.87 | 0.25 | |
| 974 | MgNO: Efficient Parameterization of Linear Operators via Multigrid | 6.25 | 6.50 | 0.87 | 0.25 | |
| 975 | DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genomes | 6.00 | 6.50 | 0.87 | 0.50 | |
| 976 | Scalable Neural Network Kernels | 6.50 | 6.50 | 1.50 | 0.00 | |
| 977 | FairVLM: Mitigating Bias In Pre-Trained Vision-Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 978 | Learning 3D Particle-based Simulators from RGB-D Videos | 6.50 | 6.50 | 0.87 | 0.00 | |
| 979 | Random Sparse Lifts: Construction, Analysis and Convergence of finite sparse networks | 5.75 | 6.50 | 1.50 | 0.75 | |
| 980 | Enhancing Neural Training via a Correlated Dynamics Model | 6.50 | 6.50 | 2.69 | 0.00 | |
| 981 | DyVal: Graph-informed Dynamic Evaluation of Large Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 982 | A Neural Framework for Generalized Causal Sensitivity Analysis | 6.50 | 6.50 | 0.87 | 0.00 | |
| 983 | Unveiling and Manipulating Prompt Influence in Large Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 984 | HoloNets: Spectral Convolutions do extend to Directed Graphs | 6.50 | 6.50 | 0.87 | 0.00 | |
| 985 | Reinforcement Symbolic Regression Machine | 5.75 | 6.50 | 0.87 | 0.75 | |
| 986 | ScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 987 | DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization | 5.50 | 6.50 | 0.87 | 1.00 | |
| 988 | Efficient Multi-agent Reinforcement Learning by Planning | 5.50 | 6.50 | 0.87 | 1.00 | |
| 989 | AnyText: Multilingual Visual Text Generation and Editing | 5.75 | 6.50 | 0.87 | 0.75 | |
| 990 | Efficient Backpropagation with Variance Controlled Adaptive Sampling | 5.00 | 6.50 | 0.87 | 1.50 | |
| 991 | Dual Associated Encoder for Face Restoration | 6.50 | 6.80 | 1.47 | 0.30 | |
| 992 | AFDGCF: Adaptive Feature De-correlation Graph Collaborative Filtering for Recommendations | 6.50 | 6.50 | 1.50 | 0.00 | |
| 993 | Sliced Denoising: A Physics-Informed Molecular Pre-Training Method | 6.00 | 6.50 | 1.50 | 0.50 | |
| 994 | EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models | 6.50 | 6.50 | 0.87 | 0.00 | |
| 995 | BTR: Binary Token Representations for Efficient Retrieval Augmented Language Models | 6.50 | 6.50 | 0.87 | 0.00 | |
| 996 | The Expressive Power of Low-Rank Adaptation | 5.75 | 6.50 | 0.87 | 0.75 | |
| 997 | Frozen Transformers in Language Models Are Effective Visual Encoder Layers | 5.25 | 6.50 | 0.87 | 1.25 | |
| 998 | Bridging Neural and Symbolic Representations with Transitional Dictionary Learning | 6.50 | 6.50 | 1.50 | 0.00 | |
| 999 | AirPhyNet: Harnessing Physics-Guided Neural Networks for Air Quality Prediction | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1000 | ConR: Contrastive Regularizer for Deep Imbalanced Regression | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1001 | Branch-GAN: Improving Text Generation with (not so) Large Language Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1002 | Linear attention is (maybe) all you need (to understand Transformer optimization) | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1003 | MVDream: Multi-view Diffusion for 3D Generation | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1004 | Robust Model Based Reinforcement Learning Using $mathcal{L}_1$ Adaptive Control | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1005 | Headless Language Models: Learning without Predicting with Contrastive Weight Tying | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1006 | $texttt{NAISR}$: A 3D Neural Additive Model for Interpretable Shape Representation | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1007 | Leveraging Optimization for Adaptive Attacks on Image Watermarks | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1008 | GenCorres: Consistent Shape Matching via Coupled Implicit-Explicit Shape Generative Models | 6.00 | 6.75 | 1.30 | 0.75 | |
| 1009 | Decomposed Diffusion Sampler for Accelerating Large-Scale Inverse Problems | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1010 | A Branching Decoder for Set Generation | 6.00 | 7.00 | 1.00 | 1.00 | |
| 1011 | Label-free Node Classification on Graphs with Large Language Models (LLMs) | 4.75 | 6.50 | 0.87 | 1.75 | |
| 1012 | Sliced Wasserstein Estimation with Control Variates | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1013 | EControl: Fast Distributed Optimization with Compression and Error Control | 7.00 | 6.50 | 0.87 | -0.50 | |
| 1014 | Convergence of Bayesian Bilevel Optimization | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1015 | AdaMerging: Adaptive Model Merging for Multi-Task Learning | 5.25 | 6.50 | 0.87 | 1.25 | |
| 1016 | Imitation Learning from Observation with Automatic Discount Scheduling | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1017 | TopoMLP: An Simple yet Strong Pipeline for Driving Topology Reasoning | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1018 | Adapting Large Language Models via Reading Comprehension | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1019 | DIAGNOSIS: Detecting Unauthorized Data Usages in Text-to-image Diffusion Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1020 | The importance of feature preprocessing for differentially private linear optimization | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1021 | Tree Cross Attention | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1022 | Rethinking Adversarial Policies: A Generalized Attack Formulation and Provable Defense in RL | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1023 | Cameras as Rays: Sparse-view Pose Estimation via Ray Diffusion | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1024 | ADoPD: A Large-Scale Document Page Decomposition Dataset | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1025 | Learning Robust Generalizable Radiance Field with Visibility and Feature Augmented Point Representation | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1026 | Finite Scalar Quantization: VQ-VAE Made Simple | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1027 | Fast Equilibrium of SGD in Generic Situations | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1028 | CIFAR-10-Warehouse: Broad and More Realistic Testbeds in Model Generalization Analysis | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1029 | Optimal Sample Complexity for Average Reward Markov Decision Processes | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1030 | Spatio-Temporal Approximation: A Training-Free SNN Conversion for Transformers | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1031 | When Do Prompting and Prefix-Tuning Work? A Theory of Capabilities and Limitations | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1032 | Rethinking Information-theoretic Generalization: Loss Entropy Induced PAC Bounds | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1033 | MINDE: Mutual Information Neural Diffusion Estimation | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1034 | Seer: Language Instructed Video Prediction with Latent Diffusion Models | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1035 | Compositional Generative Inverse Design | 5.75 | 7.00 | 1.00 | 1.25 | |
| 1036 | Sampling is as easy as keeping the consistency: convergence guarantee for Consistency Models | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1037 | Generalized Knowledge Distillation for Auto-regressive Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1038 | How Does Wild Data Provably Help OOD Detection? | 5.25 | 6.50 | 0.87 | 1.25 | |
| 1039 | Structural Estimation of Partially Observed Linear Non-Gaussian Acyclic Model: A Practical Approach with Identifiability | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1040 | Bayesian low-rank adaptation for large language models | 6.33 | 6.50 | 0.87 | 0.17 | |
| 1041 | DENEVIL: TOWARDS DECIPHERING AND NAVIGATING THE ETHICAL VALUES OF LARGE LANGUAGE MODELS VIA INSTRUCTION LEARNING | 6.50 | 6.50 | 2.06 | 0.00 | |
| 1042 | Diff-Privacy: Diffusion-based Face Privacy Protection | 6.50 | 6.75 | 1.30 | 0.25 | |
| 1043 | TapMo: Shape-aware Motion Generation of Skeleton-free Characters | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1044 | Scalable Language Model with Generalized Continual Learning | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1045 | VertiBench: Advancing Feature Distribution Diversity in Vertical Federated Learning Benchmarks | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1046 | Language Model Agents Suffer from Compositional Decision Making | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1047 | Towards the Fundamental Limits of Knowledge Transfer over Finite Domains | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1048 | Internal Cross-layer Gradients for Extending Homogeneity to Heterogeneity in Federated Learning | 6.50 | 7.25 | 1.30 | 0.75 | |
| 1049 | Plug-and-Play: An Efficient Post-training Pruning Method for Large Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1050 | Neural Field Classifiers via Target Encoding and Classification Loss | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1051 | Continuous Invariance Learning | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1052 | Stylized Offline Reinforcement Learning: Extracting Diverse High-Quality Behaviors from Heterogeneous Datasets | 5.25 | 6.50 | 0.87 | 1.25 | |
| 1053 | Beyond One-Preference-for-All: Multi-Objective Direct Preference Optimization | 6.50 | 6.50 | 2.06 | 0.00 | |
| 1054 | Diving Deep into Regions: Exploiting Regional information Transformer for Single Image Deraining | 6.50 | 6.50 | 1.50 | 0.00 | |
| 1055 | Detecting Machine-Generated Texts by Multi-Population Aware Optimization for Maximum Mean Discrepancy | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1056 | Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1057 | PINNsFormer: A Transformer-Based Framework For Physics-Informed Neural Networks | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1058 | Context is Environment | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1059 | Awakening Collective Wisdom: Elevating Super-Resolution Network Generalization through Cooperative Game Theory | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1060 | Quantifying the Sensitivity of Inverse Reinforcement Learning to Misspecification | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1061 | ViDA: Homeostatic Visual Domain Adapter for Continual Test Time Adaptation | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1062 | DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation | 6.50 | 7.50 | 1.66 | 1.00 | |
| 1063 | Detecting Generated Text via Rewriting | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1064 | Vision-Language Foundation Models as Effective Robot Imitators | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1065 | STanHop: Sparse Tandem Hopfield Model for Memory-Enhanced Time Series Prediction | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1066 | Adaptive deep spiking neural network with global-local learning via balanced excitatory and inhibitory mechanism | 5.50 | 6.50 | 1.50 | 1.00 | |
| 1067 | Denoising Diffusion Step-aware Models | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1068 | Structured Video-Language Modeling with Temporal Grouping and Spatial Grounding | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1069 | Efficacy of Dual-Encoders for Extreme Multi-label Classification | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1070 | ImageNet-OOD: Deciphering Modern Out-of-Distribution Detection Algorithms | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1071 | DAM: A Foundation Model for Forecasting | 5.50 | 7.00 | 1.00 | 1.50 | |
| 1072 | Denoising Diffusion via Image-Based Rendering | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1073 | Generalized Neural Collapse for a Large Number of Classes | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1074 | Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects | 6.50 | 6.50 | 1.50 | 0.00 | |
| 1075 | Localizing and Editing Knowledge In Text-to-Image Generative Models | 6.50 | 6.50 | 1.50 | 0.00 | |
| 1076 | GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1077 | Less or More From Teacher: Exploiting Trilateral Geometry For Knowledge Distillation | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1078 | GRANDE: Gradient-Based Decision Tree Ensembles | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1079 | SYMBOL: Generating Flexible Black-Box Optimizers through Symbolic Equation Learning | 6.50 | 6.50 | 0.87 | 0.00 | |
| 1080 | Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1081 | OmniControl: Control Any Joint at Any Time for Human Motion Generation | 5.75 | 6.50 | 0.87 | 0.75 | |
| 1082 | Learning Epipolar Feature Fields for Multi-Image Super-Resolution | 6.50 | 6.75 | 2.59 | 0.25 | |
| 1083 | GeoDiffusion: Text-Prompted Geometric Control for Object Detection Data Generation | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1084 | Un-Mixing Test-Time Normalization Statistics: Combatting Label Temporal Correlation | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1085 | TUVF: Learning Generalizable Texture UV Radiance Fields | 5.50 | 7.00 | 1.00 | 1.50 | |
| 1086 | Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1087 | I-PHYRE: Interactive Physical Reasoning | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1088 | Boosting of Thoughts: Trial-and-Error Problem Solving with Large Language Models | 6.40 | 6.40 | 1.36 | 0.00 | | 8, 5, 6, 8, 5 | | 8, 5, 6, 8, 5 |
|
| 1089 | Multilingual Jailbreak Challenges in Large Language Models | 5.20 | 6.40 | 0.80 | 1.20 | | 3, 6, 6, 5, 6 | | 6, 6, 6, 6, 8 |
|
| 1090 | SuRe: Improving Open-domain Question Answering of LLMs via Summarized Retrieval | 6.20 | 6.40 | 0.80 | 0.20 | | 5, 8, 6, 6, 6 | | 6, 8, 6, 6, 6 |
|
| 1091 | CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech | 6.40 | 6.40 | 2.06 | 0.00 | | 8, 8, 5, 3, 8 | | 8, 8, 5, 3, 8 |
|
| 1092 | Stochastic Gradient Descent for Gaussian Processes Done Right | 5.80 | 6.40 | 1.36 | 0.60 | | 8, 5, 6, 5, 5 | | 8, 6, 8, 5, 5 |
|
| 1093 | Implicit Neural Representations and the Algebra of Complex Wavelets | 5.20 | 6.40 | 0.80 | 1.20 | | 8, 3, 6, 3, 6 | | 8, 6, 6, 6, 6 |
|
| 1094 | COLEP: Certifiably Robust Learning-Reasoning Conformal Prediction via Probabilistic Circuits | 5.60 | 6.40 | 0.80 | 0.80 | | 6, 6, 6, 5, 5 | | 8, 6, 6, 6, 6 |
|
| 1095 | HiGen: Hierarchical Graph Generative Networks | 6.20 | 6.40 | 0.80 | 0.20 | | 5, 6, 6, 6, 8 | | 6, 6, 6, 6, 8 |
|
| 1096 | Matrix-wise Class Imbalance Matters: On the Generalization of Micro-AUC in Multi-label Learning | 6.40 | 6.40 | 1.36 | 0.00 | | 8, 5, 5, 8, 6 | | 8, 5, 5, 8, 6 |
|
| 1097 | Attention-based Iterative Decomposition for Tensor Product Representation | 5.80 | 6.40 | 1.36 | 0.60 | | 8, 6, 5, 5, 5 | | 8, 6, 5, 5, 8 |
|
| 1098 | Spectral learning of shared dynamics between generalized-linear processes | 5.60 | 6.80 | 0.98 | 1.20 | | 6, 6, 6, 5, 5 | | 6, 8, 8, 6, 6 |
|
| 1099 | Beyond Vanilla Variational Autoencoders: Detecting Posterior Collapse in Conditional and Hierarchical Variational Autoencoders | 5.60 | 6.40 | 0.80 | 0.80 | | 3, 6, 6, 5, 8 | | 6, 6, 6, 6, 8 |
|
| 1100 | 'What Data Benefits My Classifier?' Enhancing Model Performance and Interpretability through Influence-Based Data Selection | 5.20 | 6.40 | 0.80 | 1.20 | | 3, 6, 5, 6, 6 | | 6, 8, 6, 6, 6 |
|
| 1101 | PAC Prediction Sets Under Label Shift | 5.80 | 6.40 | 0.80 | 0.60 | | 8, 5, 5, 5, 6 | | 8, 6, 6, 6, 6 |
|
| 1102 | Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning | 5.80 | 6.40 | 0.80 | 0.60 | | 5, 5, 6, 8, 5 | | 6, 6, 6, 8, 6 |
|
| 1103 | Constrained Bi-Level Optimization: Proximal Lagrangian Value function Approach and Hessian-free Algorithm | 6.75 | 6.40 | 1.36 | -0.35 | |
| 1104 | Brain-inspired $L_p$-Convolution benefits large kernels and aligns better with visual cortex | 6.40 | 6.40 | 2.06 | 0.00 | | 5, 8, 8, 8, 3 | | 5, 8, 8, 8, 3 |
|
| 1105 | Theoretical Analysis of Robust Overfitting for Wide DNNs: An NTK Approach | 5.40 | 6.40 | 0.80 | 1.00 | | 5, 6, 5, 6, 5 | | 6, 8, 6, 6, 6 |
|
| 1106 | Can Transformers Capture Spatial Relations between Objects? | 6.20 | 6.40 | 1.36 | 0.20 | | 8, 5, 5, 8, 5 | | 8, 5, 6, 8, 5 |
|
| 1107 | OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models | 5.20 | 6.40 | 0.80 | 1.20 | | 5, 6, 3, 6, 6 | | 6, 8, 6, 6, 6 |
|
| 1108 | Robust Network Pruning With Sparse Entropic Wasserstein Regression | 6.00 | 6.40 | 0.80 | 0.40 | | 6, 6, 6, 6, 6 | | 6, 6, 6, 8, 6 |
|
| 1109 | GRAPH-CONSTRAINED DIFFUSION FOR END-TO-END PATH PLANNING | 6.00 | 6.40 | 0.80 | 0.40 | | 6, 6, 6, 6, 6 | | 6, 6, 8, 6, 6 |
|
| 1110 | VQGraph: Rethinking Graph Representation Space for Bridging GNNs and MLPs | 5.40 | 6.40 | 1.36 | 1.00 | | 5, 6, 6, 5, 5 | | 5, 8, 8, 6, 5 |
|
| 1111 | Order-Preserving GFlowNets | 6.00 | 6.40 | 0.80 | 0.40 | | 5, 6, 8, 6, 5 | | 6, 6, 8, 6, 6 |
|
| 1112 | Energy-Based Concept Bottleneck Models | 5.00 | 6.40 | 0.80 | 1.40 | | 6, 3, 6, 5, 5 | | 6, 8, 6, 6, 6 |
|
| 1113 | Is This the Subspace You Are Looking for? An Interpretability Illusion for Subspace Activation Patching | 6.33 | 6.33 | 2.36 | 0.00 | |
| 1114 | Bayesian Coreset Optimization for Personalized Federated Learning | 5.00 | 6.33 | 1.25 | 1.33 | |
| 1115 | In-Context Learning through the Bayesian Prism | 5.67 | 6.67 | 0.94 | 1.00 | |
| 1116 | RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1117 | Seeking Neural Nuggets: Knowledge Transfer in Large Language Models from a Parametric Perspective | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1118 | G2PTL: A Pre-trained Model for Delivery Address and its Applications in Logistics System | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1119 | Skill-Mix: a Flexible and Expandable Family of Evaluations for AI Models | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1120 | TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1121 | Chain of Thought Empowers Transformers to Solve Inherently Serial Problems | 6.33 | 6.33 | 1.89 | 0.00 | | 8, 6, 8, 3, 8, 5 | | 8, 6, 8, 3, 8, 5 |
|
| 1122 | The Hedgehog & the Porcupine: Expressive Linear Attentions with Softmax Mimicry | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1123 | FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1124 | An operator preconditioning perspective on training in physics-informed machine learning | 5.67 | 6.33 | 1.25 | 0.67 | | 5, 5, 5, 5, 8, 6 | | 5, 6, 5, 6, 8, 8 |
|
| 1125 | LayerAct: Advancing CNNs with BatchNorm through Layer-direction Normalization | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1126 | Explaining black box text modules in natural language with language models | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1127 | Preventing Model Collapse in Deep Canonical Correlation Analysis by Noise Regularization | 6.33 | 5.50 | 2.87 | -0.83 | |
| 1128 | UniTabE: A Universal Pretraining Protocol for Tabular Foundation Model in Data Science | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1129 | Expressivity of ReLU-Networks under Convex Relaxations | 4.33 | 6.33 | 1.25 | 2.00 | |
| 1130 | Hindsight PRIORs for Reward Learning from Human Preferences | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1131 | Seeing Video Through Optical Scattering Media using Spatio-Temporal Diffusion Models | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1132 | Unsupervised Detection of Recurrent Patterns in Neural Recordings with Constrained Filters | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1133 | CMMLU: Measuring massive multitask language understanding in Chinese | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1134 | Curated LLM: Synergy of LLMs and Data Curation for tabular augmentation in ultra low-data regimes | 3.33 | 6.33 | 1.25 | 3.00 | |
| 1135 | Plug-and-Play Policy Planner for Large Language Model Powered Dialogue Agents | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1136 | Looped Transformers are Better at Learning Learning Algorithms | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1137 | Merge, Then Compress: Demystify Efficient SMoE with Hints from Its Routing Policy | 5.67 | 6.33 | 2.36 | 0.67 | |
| 1138 | Improving Generalization in Equivariant Graph Neural Networks with Physical Inductive Biases | 6.33 | 6.67 | 0.94 | 0.33 | |
| 1139 | Compositional VLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1140 | Treatment Effects Estimation By Uniform Transformer | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1141 | CLIP-MUSED: CLIP-Guided Multi-Subject Visual Neural Information Semantic | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1142 | Stack Attention: Improving the Ability of Transformers to Model Hierarchical Patterns | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1143 | SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1144 | Data Distillation Can Be Like Vodka: Distilling More Times For Better Quality | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1145 | Object centric architectures enable efficient causal representation learning | 6.33 | 6.67 | 0.94 | 0.33 | |
| 1146 | On input-dependence and recall in convolutional language models | 5.67 | 6.33 | 2.36 | 0.67 | |
| 1147 | Reconciling Spatial and Temporal Abstractions for Goal Representation | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1148 | Linearity of Relation Decoding in Transformer Language Models | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1149 | Breaking Neural Network Scaling Laws with Modularity | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1150 | AUGCAL: Improving Sim2Real Adaptation by Uncertainty Calibration on Augmented Synthetic Images | 7.00 | 6.67 | 0.94 | -0.33 | |
| 1151 | From Latent Graph to Latent Topology Inference: Differentiable Cell Complex Module | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1152 | Time-Efficient Reinforcement Learning with Stochastic Stateful Policies | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1153 | Retrieval-based Disentangled Representation Learning with Natural Language Supervision | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1154 | Emergent Communication with Conversational Repair | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1155 | DyST: Towards Dynamic Neural Scene Representations on Real-World Videos | 6.33 | 6.67 | 0.94 | 0.33 | |
| 1156 | Leave-one-out Distinguishability in Machine Learning | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1157 | Increasing Model Capacity for Free: A Simple Strategy for Parameter Efficient Fine-tuning | 5.33 | 6.67 | 0.94 | 1.33 | |
| 1158 | Learning Semantic Proxies from Visual Prompts for Parameter-Efficient Fine-Tuning in Deep Metric Learning | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1159 | Learning Decentralized Partially Observable Mean Field Control for Artificial Collective Behavior | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1160 | Sample-Efficiency in Multi-Batch Reinforcement Learning: The Need for Dimension-Dependent Adaptivity | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1161 | MetaGPT: Meta Programming for Multi-Agent Collaborative Framework | 6.50 | 6.33 | 2.36 | -0.17 | |
| 1162 | Learning Scalar Fields for Molecular Docking with Fast Fourier Transforms | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1163 | GTMGC: Using Graph Transformer to Predict Molecule’s Ground-State Conformation | 6.33 | 6.33 | 2.36 | 0.00 | |
| 1164 | Improved Analysis of Sparse Linear Regression in Local Differential Privacy Model | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1165 | PeFLL: Personalized Federated Learning by Learning to Learn | 4.67 | 6.33 | 1.25 | 1.67 | |
| 1166 | DP-SGD Without Clipping: The Lipschitz Neural Network Way | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1167 | High-dimensional robust regression under heavy-tailed data: Asymptotics and Universality | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1168 | Learning Multi-Faceted Prototypical User Interests | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1169 | Neural Contractive Dynamical Systems | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1170 | Interpretable Deep Clustering | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1171 | AutoChunk: Automated Activation Chunk for Memory-Efficient Deep Learning Inference | 6.50 | 6.33 | 1.25 | -0.17 | |
| 1172 | Barycentric Alignment of Mutually Disentangled Modalities | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1173 | Deep Geodesic Canonical Correlation Analysis for Covariance-Based Neuroimaging Data | 5.67 | 7.33 | 0.94 | 1.67 | |
| 1174 | Masked Structural Growth for 2x Faster Language Model Pre-training | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1175 | Foundation Model-oriented Robustness: Robust Image Model Evaluation with Pretrained Models | 5.33 | 6.67 | 0.94 | 1.33 | |
| 1176 | Decoupled Marked Temporal Point Process using Neural Ordinary Differential Equations | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1177 | Polynomial-based Self-Attention for Table Representation learning | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1178 | SpikeBERT: A Language Spikformer Learned from BERT with Knowledge Distillation | 5.67 | 6.33 | 2.36 | 0.67 | |
| 1179 | Learning Over Molecular Conformer Ensembles: Datasets and Benchmarks | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1180 | WebArena: A Realistic Web Environment for Building Autonomous Agents | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1181 | One-hot Generalized Linear Model for Switching Brain State Discovery | 6.33 | 6.33 | 2.36 | 0.00 | |
| 1182 | The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1183 | ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1184 | Prompt Learning with Quaternion Networks | 6.50 | 6.33 | 1.25 | -0.17 | |
| 1185 | Adaptive Self-training Framework for Fine-grained Scene Graph Generation | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1186 | Compositional Image Decomposition with Diffusion Models | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1187 | ReMasker: Imputing Tabular Data with Masked Autoencoding | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1188 | Federated Orthogonal Training: Mitigating Global Catastrophic Forgetting in Continual Federated Learning | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1189 | Reasoning with Latent Diffusion in Offline Reinforcement Learning | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1190 | Decomposing the Enigma: Subgoal-based Demonstration Learning for Formal Theorem Proving | 7.00 | 6.33 | 1.25 | -0.67 | |
| 1191 | An Investigation of Representation and Allocation Harms in Contrastive Learning | 6.50 | 6.33 | 1.25 | -0.17 | |
| 1192 | Understanding AI Cognition: A Neural Module for Inference Inspired by Human Memory Mechanisms | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1193 | A Mutual Information Perspective on Federated Contrastive Learning | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1194 | Fast, Expressive $mathrm{SE}(n)$ Equivariant Networks through Weight-Sharing in Position-Orientation Space | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1195 | Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1196 | Towards human-like spoken dialogue generation between AI agents from written dialogue | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1197 | Vulnerable Region Discovery through Diverse Adversarial Examples | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1198 | EventRPG: Event Data Augmentation with Relevance Propagation Guidance | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1199 | Drug Discovery with Dynamic Goal-aware Fragments | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1200 | Heterogeneous Personalized Federated Learning by Local-Global Updates Mixing via Convergence Rate | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1201 | SPDER: Semiperiodic Damping-Enabled Object Representation | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1202 | Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1203 | Diffusion-TS: Interpretable Diffusion for General Time Series Generation | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1204 | Effectively Leveraging Capacity for Improved Deterministic Robustness Certification | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1205 | Intriguing Properties of Generative Classifiers | 6.33 | 8.00 | 0.00 | 1.67 | |
| 1206 | Democratizing Fine-grained Visual Recognition with Large Language Models | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1207 | Network Memory Footprint Compression Through Jointly Learnable Codebooks and Mappings | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1208 | InstructPix2NeRF: Instructed 3D Portrait Editing from a Single Image | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1209 | ODEFormer: Symbolic Regression of Dynamical Systems with Transformers | 4.67 | 6.33 | 2.36 | 1.67 | |
| 1210 | State Representation Learning Using an Unbalanced Atlas | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1211 | Equivariant Matrix Function Neural Networks | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1212 | QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1213 | How Graph Neural Networks Learn: Lessons from Training Dynamics in Function Space | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1214 | Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1215 | Composed Image Retrieval with Text Feedback via Multi-grained Uncertainty Regularization | 5.67 | 6.33 | 2.36 | 0.67 | |
| 1216 | LLaMA-Adapter: Efficient Fine-tuning of Large Language Models with Zero-initialized Attention | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1217 | Stable Anisotropic Regularization | 6.33 | 6.33 | 2.36 | 0.00 | |
| 1218 | Threshold-Consistent Margin Loss for Open-World Deep Metric Learning | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1219 | Semantic Flow: Learning Semantic Fields of Dynamic Scenes from Monocular Videos | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1220 | Interpretable Meta-Learning of Physical Systems | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1221 | Analysis of Learning a Flow-based Generative Model from Limited Sample Complexity | 6.33 | 6.33 | 2.36 | 0.00 | |
| 1222 | Few-shot Hybrid Domain Adaptation of Image Generator | 5.67 | 7.00 | 1.41 | 1.33 | |
| 1223 | Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1224 | ETGraph: A Pioneering Dataset Bridging Ethereum and Twitter | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1225 | Directional Distance Field for Modeling the Difference between 3D Point Clouds | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1226 | Planting a SEED of Vision in Large Language Model | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1227 | Ferret: Refer and Ground Anything Anywhere at Any Granularity | 6.33 | 6.67 | 0.94 | 0.33 | |
| 1228 | On the Generalization and Approximation Capacities of Neural Controlled Differential Equations | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1229 | VFLAIR: A Research Library and Benchmark for Vertical Federated Learning | 5.67 | 6.33 | 2.36 | 0.67 | |
| 1230 | Decentralized Riemannian Conjugate Gradient Method on the Stiefel Manifold | 5.67 | 6.33 | 1.25 | 0.67 | |
| 1231 | Sub-token ViT Embedding via Stochastic Resonance Transformers | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1232 | Byzantine Robust Cooperative Multi-Agent Reinforcement Learning as a Bayesian Game | 5.00 | 6.33 | 1.25 | 1.33 | |
| 1233 | Defining and extracting generalizable interaction primitives from DNNs | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1234 | Warped Convolutional Neural Networks For Large Homography Transformation with $mathfrak{sl}(3)$ Algebra | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1235 | Welfare Diplomacy: Benchmarking Language Model Cooperation | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1236 | Reverse Forward Curriculum Learning for Extreme Sample and Demo Efficiency | 6.00 | 5.67 | 2.05 | -0.33 | |
| 1237 | Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1238 | Koopman-based generalization bound: New aspect for full-rank weights | 6.33 | 6.33 | 1.25 | 0.00 | |
| 1239 | MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object Detection | 4.67 | 6.33 | 1.25 | 1.67 | |
| 1240 | Enhancing Tail Performance in Extreme Classifiers by Label Variance Reduction | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1241 | Improving SAM Requires Rethinking its Optimization Formulation | 6.00 | 6.25 | 2.49 | 0.25 | |
| 1242 | DAME: A Distillation Based Approach For Model-agnostic Local Explainability | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1243 | Pessimistic Nonlinear Least-Squares Value Iteration for Offline Reinforcement Learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1244 | Improving Language Models with Advantage-based Offline Policy Gradients | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1245 | Be Aware of the Neighborhood Effect: Modeling Selection Bias under Interference for Recommendation | 6.25 | 6.75 | 1.30 | 0.50 | |
| 1246 | On the Scalability and Memory Efficiency of Semidefinite Programs for Lipschitz Constant Estimation of Neural Networks | 5.67 | 6.25 | 1.09 | 0.58 | |
| 1247 | Unveiling the Unseen: Identifiable Clusters in Trained Depthwise Convolutional Kernels | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1248 | Neural-Symbolic Recursive Machine for Systematic Generalization | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1249 | Training Diffusion Models with Reinforcement Learning | 4.75 | 6.25 | 1.09 | 1.50 | |
| 1250 | Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1251 | Language Models Represent Space and Time | 5.75 | 6.25 | 2.05 | 0.50 | |
| 1252 | Causal Modelling Agents: Causal Graph Discovery through Synergising Metadata- and Data-driven Reasoning | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1253 | Benchmarking Cognitive Biases in Large Language Models as Evaluators | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1254 | Zero-Shot Robotic Manipulation with Pre-Trained Image-Editing Diffusion Models | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1255 | On the Role of Edge Dependency in Graph Generative Models | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1256 | COMPARATOR: Reference-free machine translation evaluation by inter-system comparison | 6.00 | 6.75 | 1.30 | 0.75 | |
| 1257 | Out of the Ordinary: Spectrally Adapting Regression for Covariate Shift | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1258 | An Inexact Conditional Gradient Method for Constrained Bilevel Optimization | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1259 | Maximum Likelihood Estimation is All You Need for Well-Specified Covariate Shift | 6.75 | 6.25 | 2.05 | -0.50 | |
| 1260 | Beyond Accuracy: Evaluating Self-Consistency of Code LLMs | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1261 | Modeling Boundedly Rational Agents with Latent Inference Budgets | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1262 | Towards Identifiable Unsupervised Domain Translation: A Diversified Distribution Matching Approach | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1263 | Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization | 5.75 | 6.25 | 2.05 | 0.50 | |
| 1264 | Social Reward: Evaluating and Enhancing Generative AI through Million-User Feedback from an Online Creative Community | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1265 | Eureka: Human-Level Reward Design via Coding Large Language Models | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1266 | Generative Entropic Neural Optimal Transport To Map Within and Across Space | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1267 | Offline Imitation Learning without Auxiliary High-quality Behavior Data | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1268 | Error Feedback Shines when Features are Rare | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1269 | Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1270 | Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generation | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1271 | Traveling Waves Encode The Recent Past and Enhance Sequence Learning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1272 | Value function estimation using conditional diffusion models for control | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1273 | GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1274 | Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1275 | Efficient Instance-Optimal Finite-Sum Minimization | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1276 | Differentially Private Synthetic Data via Foundation Model APIs 1: Images | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1277 | Be Your Own Neighborhood: Detecting Adversarial Example by the Neighborhood Relations Built on Self-Supervised Learning | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1278 | SafeDreamer: Safe Reinforcement Learning with World Models | 5.25 | 6.50 | 0.87 | 1.25 | |
| 1279 | Understanding Expressivity of Neural KG Reasoning from Rule Structure Learning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1280 | Vanishing Gradients in Reinforcement Finetuning of Language Models | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1281 | Goodhart's Law in Reinforcement Learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1282 | Score Regularized Policy Optimization through Diffusion Behavior | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1283 | MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction Following | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1284 | Beyond Worst-case Attacks: Robust RL with Adaptive Defense via Non-dominated Policies | 5.50 | 7.00 | 1.00 | 1.50 | |
| 1285 | Generative Modeling of Regular and Irregular Time Series Data via Koopman VAEs | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1286 | Making RL with Preference-based Feedback Efficient via Randomization | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1287 | Towards Fair Graph Anomaly Detection: Problem, New Datasets, and Evaluation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 1288 | AutoDAN: Automatic and Interpretable Adversarial Attacks on Large Language Models | 5.75 | 6.25 | 2.17 | 0.50 | |
| 1289 | DAG-Based Column Generation for Adversarial Team Games | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1290 | (InThe)WildChat: 570K ChatGPT Interaction Logs In The Wild | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1291 | Jailbreak in pieces: Compositional Adversarial Attacks on Multi-Modal Language Models | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1292 | DreamFlow: High-quality text-to-3D generation by Approximating Probability Flow | 5.00 | 6.25 | 1.09 | 1.25 | |
| 1293 | Time-Varying Propensity Score to Bridge the Gap between the Past and Present | 5.00 | 6.25 | 1.09 | 1.25 | |
| 1294 | RA-DIT: Retrieval-Augmented Dual Instruction Tuning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1295 | Private Zeroth-Order Nonsmooth Nonconvex Optimization | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1296 | SWE-bench: Can Language Models Resolve Real-world Github Issues? | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1297 | Sampling Multimodal Distributions with the Vanilla Score: Benefits of Data-Based Initialization | 5.75 | 6.25 | 2.05 | 0.50 | |
| 1298 | TiC-CLIP: Continual Training of CLIP Models | 4.50 | 6.25 | 1.09 | 1.75 | |
| 1299 | Multimodal Patient Representation Learning with Missing Modalities and Labels | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1300 | FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1301 | Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1302 | Catapults in SGD: spikes in the training loss and their impact on generalization through feature learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1303 | LLM Augmented LLMs: Expanding Capabilities through Composition | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1304 | Evaluating Representation Learning on the Protein Structure Universe | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1305 | YaRN: Efficient Context Window Extension of Large Language Models | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1306 | A Newborn Embodied Turing Test for Comparing Object Segmentation Across Animals and Machines | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1307 | Robust Model-Based Optimization for Challenging Fitness Landscapes | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1308 | Hierarchically branched diffusion models leverage dataset structure for class-conditional generation | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1309 | Revisiting DeepFool: generalization and improvement | 4.75 | 6.25 | 1.09 | 1.50 | |
| 1310 | Optimal criterion for feature learning of two-layer linear neural network in high dimensional interpolation regime | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1311 | Provably Efficient UCB-type Algorithms For Learning Predictive State Representations | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1312 | Towards Universal Multi-Modal Personalization: A Language Model Empowered Generative Paradigm | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1313 | Orbit-Equivariant Graph Neural Networks | 6.25 | 7.00 | 1.00 | 0.75 | |
| 1314 | Object-Centric Learning with Slot Mixture Module | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1315 | ELoRA: Efficient Low-Rank Adaptation with Random Matrices | 6.25 | 7.25 | 1.30 | 1.00 | |
| 1316 | Fourier Transporter: Bi-Equivariant Robotic Manipulation in 3D | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1317 | IDEA: Invariant Causal Defense for Graph Adversarial Robustness | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1318 | Symmetric Single Index Learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1319 | Leveraging Low-Rank and Sparse Recurrent Connectivity for Robust Closed-Loop Control | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1320 | Neuroformer: Multimodal and Multitask Generative Pretraining for Brain Data | 4.75 | 6.25 | 1.09 | 1.50 | |
| 1321 | An Extensible Framework for Open Heterogeneous Collaborative Perception | 5.75 | 6.75 | 1.30 | 1.00 | |
| 1322 | TopoFR: A Closer Look at Topology Alignment on Face Recognition | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1323 | FOSI: Hybrid First and Second Order Optimization | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1324 | Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1325 | How Realistic Is Your Synthetic Data? Constraining Deep Generative Models for Tabular Data | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1326 | Slingshot Perturbation to Learning in Monotone Games | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1327 | Energy-Guided Continuous Entropic Barycenter Estimation for General Costs | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1328 | Improving equilibrium propagation without weight symmetry through Jacobian homeostasis | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1329 | Learning to Compose: Improving Object Centric Learning by Injecting Compositionality | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1330 | Reward-Free Curricula for Training Robust World Models | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1331 | DEEP NEURAL NETWORK INITIALIZATION WITH SPARSITY INDUCING ACTIVATIONS | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1332 | CPPO: Continual Learning for Reinforcement Learning with Human Feedback | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1333 | Can Class-Priors Help Single-Positive Multi-Label Learning? | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1334 | Continual Learning in the Presence of Spurious Correlations: Analyses and a Simple Baseline | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1335 | Bongard-OpenWorld: Few-Shot Reasoning for Free-form Visual Concepts in the Real World | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1336 | COSA: Concatenated Sample Pretrained Vision-Language Foundation Model | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1337 | Characterizing ResNet's Universal Approximation Capability | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1338 | How Large Language Models Implement Chain-of-Thought? | 6.25 | 6.25 | 2.49 | 0.00 | |
| 1339 | ConjNorm: Tractable Density Estimation for Out-of-Distribution Detection | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1340 | HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments | 6.25 | 6.75 | 1.30 | 0.50 | |
| 1341 | Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1342 | MOFI: Learning Image Representations from Noisy Entity Annotated Images | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1343 | Efficient Integrators for Diffusion Generative Models | 5.67 | 6.25 | 1.09 | 0.58 | |
| 1344 | WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space | 5.75 | 7.00 | 1.00 | 1.25 | |
| 1345 | Diffusion Sampling with Momentum for Mitigating Divergence Artifacts | 6.25 | 6.75 | 1.30 | 0.50 | |
| 1346 | CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1347 | Scaling Supervised Local Learning with Augmented Auxiliary Networks | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1348 | Long-Short-Range Message-Passing: A Fragmentation-Based Framework to Capture Non-Local Atomistic Interactions | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1349 | BayesPrompt: Prompting Large-Scale Pre-Trained Language Models on Few-shot Inference via Debiased Domain Abstraction | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1350 | H2O-SDF: Two-phase Learning for 3D Indoor Reconstruction using Object Surface Fields | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1351 | Exploring Effective Stimulus Encoding via Vision System Modeling for Visual Prostheses | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1352 | SALMON: Self-Alignment with Principle-Following Reward Models | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1353 | Fusing Models with Complementary Expertise | 5.25 | 6.50 | 0.87 | 1.25 | |
| 1354 | Magnitude Invariant Parametrizations Improve Hypernetwork Learning | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1355 | SciRE-Solver: Accelerating Diffusion Models Sampling by Score-integrand Solver with Recursive Difference | 6.00 | 5.75 | 0.43 | -0.25 | |
| 1356 | LDReg: Local Dimensionality Regularized Self-Supervised Learning | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1357 | Mamba: Linear-Time Sequence Modeling with Selective State Spaces | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1358 | Probabilistic Adaptation of Black-Box Text-to-Video Models | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1359 | Horizon-Free Regret for Linear Markov Decision Processes | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1360 | Scalable Diffusion for Materials Generation | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1361 | Sample Efficient Myopic Exploration Through Multitask Reinforcement Learning with Diverse Tasks | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1362 | Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1363 | Adaptive Retrieval and Scalable Indexing for k-NN Search with Cross-Encoders | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1364 | Multi-Resolution Diffusion Models for Time Series Forecasting | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1365 | Learning Reusable Dense Rewards for Multi-Stage Tasks | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1366 | Aligning Relational Learning with Lipschitz Fairness | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1367 | Entropy Coding of Unordered Data Structures | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1368 | CellPLM: Pre-training of Cell Language Model Beyond Single Cells | 6.33 | 6.50 | 0.87 | 0.17 | |
| 1369 | Skill or Luck? Return Decomposition via Advantage Functions | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1370 | Belief-Enriched Pessimistic Q-Learning against Adversarial State Perturbations | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1371 | Conditional Instrumental Variable Regression with Representation Learning for Causal Inference | 6.25 | 6.75 | 1.30 | 0.50 | |
| 1372 | Conformal Language Modeling | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1373 | Understanding Augmentation-based Self-Supervised Representation Learning via RKHS Approximation and Regression | 5.75 | 6.75 | 1.30 | 1.00 | |
| 1374 | BaDExpert: Extracting Backdoor Functionality for Accurate Backdoor Input Detection | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1375 | A Restoration Network as an Implicit Prior | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1376 | Oracle Efficient Algorithms for Groupwise Regret | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1377 | A Simple and Scalable Representation for Graph Generation | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1378 | Accelerated Convergence of Stochastic Heavy Ball Method under Anisotropic Gradient Noise | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1379 | Skill Machines: Temporal Logic Skill Composition in Reinforcement Learning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1380 | Relay Diffusion: Unifying diffusion process across resolutions for image synthesis | 5.50 | 7.00 | 1.00 | 1.50 | |
| 1381 | Fast Updating of Truncated SVD for Representation Learning in Sparse Matrix | 5.00 | 6.25 | 1.09 | 1.25 | |
| 1382 | TransLLaMa: LLM-based Simultaneous Translation System | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1383 | Fundamental Limitation of Alignment in Large Language Models | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1384 | Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1385 | DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1386 | Rethinking the symmetry-preserving circuits for constrained variational quantum algorithms | 5.75 | 6.75 | 1.30 | 1.00 | |
| 1387 | Language Model Decoding as Direct Metrics Optimization | 6.33 | 6.25 | 1.09 | -0.08 | |
| 1388 | Solving Challenging Math Word Problems Using GPT-4 Code Interpreter with Code-based Self-Verification | 5.25 | 6.25 | 2.05 | 1.00 | |
| 1389 | DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1390 | Graph Generation with Destination-Predicting Diffusion Mixture | 5.33 | 6.25 | 1.09 | 0.92 | |
| 1391 | CausalTime: Realistically Generated Time-series for Benchmarking of Causal Discovery | 5.50 | 6.75 | 1.30 | 1.25 | |
| 1392 | Effective Generation of Feasible Solutions for Integer Programming via Guided Diffusion | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1393 | When Is Multilinguality a Curse? Language Modeling for 252 High- and Low-Resource Languages | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1394 | Rational Decision-Making Agent with Internalized Utility Judgment | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1395 | ASID: Active Exploration for System Identification and Reconstruction in Robotic Manipulation | 6.00 | 6.25 | 2.05 | 0.25 | |
| 1396 | Bag of Tricks to Boost Adversarial Transferability | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1397 | OMNI: Open-endedness via Models of human Notions of Interestingness | 5.00 | 6.25 | 2.05 | 1.25 | |
| 1398 | MEND: Meta Demonstration Distillation for Efficient and Effective In-Context Learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1399 | SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1400 | Towards Understanding Sycophancy in Language Models | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1401 | Cross-Modal Contextualized Diffusion Models for Text-Guided Visual Generation and Editing | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1402 | Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1403 | IS SYNTHETIC DATA USEFUL FOR TRANSFER LEARNING? AN INVESTIGATION INTO DATA GENERATION, VOLUME, AND UTILIZATION | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1404 | Image Inpainting via Iteratively Decoupled Probabilistic Modeling | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1405 | MetaTool Benchmark: Deciding Whether to Use Tools and Which to Use | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1406 | Cross-domain Few-shot Classification via Maximization Optimized Kernel Dependence | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1407 | Protein-Ligand Interaction Prior for Binding-aware 3D Molecule Diffusion Models | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1408 | UltraFeedback: Boosting Language Models with High-quality Feedback | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1409 | Integrating Planning and Deep Reinforcement Learning via Automatic Induction of Task Substructures | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1410 | Long-Term Typhoon Trajectory Prediction: A Physics-Conditioned Approach Without Reanalysis Data | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1411 | LEMON: Lossless model expansion | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1412 | MiniLLM: Knowledge Distillation of Large Language Models | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1413 | Revisiting Link Prediction: a data perspective | 5.00 | 6.25 | 1.09 | 1.25 | |
| 1414 | PRIME: Prioritizing Interpretability in Failure Mode Extraction | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1415 | Automatic Functional Differentiation in JAX | 4.75 | 6.25 | 1.09 | 1.50 | |
| 1416 | FedCompass: Efficient Cross-Silo Federated Learning on Heterogeneous Client Devices Using a Computing Power-Aware Scheduler | 4.75 | 6.25 | 1.09 | 1.50 | |
| 1417 | Navigating Text-To-Image Customization: From LyCORIS Fine-Tuning to Model Evaluation | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1418 | A Data-Driven Measure of Relative Uncertainty for Misclassification Detection | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1419 | A primal-dual perspective for distributed TD-learning | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1420 | Self-Supervised Contrastive Forecasting | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1421 | DAFA: Distance-Aware Fair Adversarial Training | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1422 | SF(DA)$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation | 5.00 | 6.25 | 1.09 | 1.25 | |
| 1423 | Out-of-Distribution Detection with Negative Prompts | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1424 | #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1425 | Towards Robust and Efficient Cloud-Edge Model Adaptation via Selective Entropy Distillation | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1426 | KITAB: Evaluating LLMs on Constraint Satisfaction for Information Retrieval | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1427 | Continual Momentum Filtering on Parameter Space for Online Test-time Adaptation | 5.75 | 6.25 | 2.05 | 0.50 | |
| 1428 | A Foundation Model for Error Correction Codes | 6.25 | 6.25 | 2.05 | 0.00 | |
| 1429 | HumanTOMATO: Text-aligned Whole-body Motion Generation | 6.25 | 6.00 | 1.22 | -0.25 | |
| 1430 | Enhancing Sample Efficiency in Black-box Combinatorial Optimization via Symmetric Replay Training | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1431 | Unified Static and Dynamic: Temporal Filtering Network for Efficient Video Grounding | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1432 | Motion Guidance: Diffusion-Based Image Editing with Differentiable Motion Estimators | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1433 | Balancing Act: Sparse Models with Constrained Disparate Impact | 6.33 | 6.25 | 1.09 | -0.08 | |
| 1434 | Domain-Inspired Sharpness Aware Minimization Under Domain Shifts | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1435 | On Causal Discovery in the Presence of Deterministic Relations | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1436 | Pooling Image Datasets with Multiple Covariate Shift and Imbalance | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1437 | Symphony: Symmetry-Equivariant Point-Centered Spherical Harmonics for Molecule Generation | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1438 | Set Learning for Accurate and Calibrated Models | 5.00 | 6.25 | 2.05 | 1.25 | |
| 1439 | Communication-Efficient Gradient Descent-Accent Methods for Distributed Variational Inequalities: Unified Analysis and Local Updates | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1440 | Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1441 | BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1442 | Fusion is Not Enough: Single Modal Attack on Fusion Models for 3D Object Detection | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1443 | IRAD: Implicit Representation-driven Image Resampling against Adversarial Attacks | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1444 | Conformal Prediction via Regression-as-Classification | 6.00 | 6.25 | 2.05 | 0.25 | |
| 1445 | Pixel Reweighted Adversarial Training | 4.75 | 6.25 | 1.09 | 1.50 | |
| 1446 | Learning to Embed Time Series Patches Independently | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1447 | TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1448 | LayoutNUWA: Revealing the Hidden Layout Expertise of Large Language Models | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1449 | Hebbian Learning based Orthogonal Projection for Continual Learning of Spiking Neural Networks | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1450 | Scaling for Training Time and Post-hoc Out-of-distribution Detection Enhancement | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1451 | A Simple and Effective Pruning Approach for Large Language Models | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1452 | Weight Selection for Model Initialization | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1453 | Knowledge Distillation Based on Transformed Teacher Matching | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1454 | A Generative Pre-Training Framework for Spatio-Temporal Graph Transfer Learning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1455 | Mastering Symbolic Operations: Augmenting Language Models with Compiled Neural Networks | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1456 | AutoLoRa: A Parameter-Free Automated Robust Fine-Tuning Framework | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1457 | WizardCoder: Empowering Code Large Language Models with Evol-Instruct | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1458 | Feature Collapse | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1459 | CausalLM is not optimal for in-context learning | 6.25 | 6.50 | 0.87 | 0.25 | |
| 1460 | GTA: A Geometry-Aware Attention Mechanism for Multi-View Transformers | 6.25 | 6.25 | 1.09 | 0.00 | |
| 1461 | Towards Energy Efficient Spiking Neural Networks: An Unstructured Pruning Framework | 5.50 | 6.25 | 2.05 | 0.75 | |
| 1462 | Robust Angular Synchronization via Directed Graph Neural Networks | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1463 | A Progressive Training Framework for Spiking Neural Networks with Learnable Multi-hierarchical Model | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1464 | Langevin Monte Carlo for strongly log-concave distributions: Randomized midpoint revisited | 6.50 | 6.25 | 1.09 | -0.25 | |
| 1465 | To the Cutoff... and Beyond? A Longitudinal Perspective on LLM Data Contamination | 5.75 | 6.75 | 1.30 | 1.00 | |
| 1466 | Recursive Score Estimation Accelerates Diffusion-Based Monte Carlo | 6.00 | 5.80 | 1.94 | -0.20 | | 8, 3, 8, 6, 5 | | 8, 5, 8, 5, 3 |
|
| 1467 | Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets | 6.00 | 6.20 | 1.83 | 0.20 | | 8, 5, 8, 6, 3 | | 8, 6, 8, 6, 3 |
|
| 1468 | Model-based Reinforcement Learning for Parameterized Action Spaces | 5.60 | 6.20 | 1.94 | 0.60 | | 5, 3, 5, 10, 5 | | 5, 5, 5, 10, 6 |
|
| 1469 | Scaling Laws for Imitation Learning in Single-Agent Games | 6.00 | 6.20 | 1.83 | 0.20 | | 8, 5, 6, 8, 3 | | 8, 6, 6, 8, 3 |
|
| 1470 | Latent Noise Segmentation: How Neural Noise Leads to the Emergence of Segmentation and Grouping | 5.20 | 6.60 | 1.96 | 1.40 | | 3, 6, 3, 6, 8 | | 6, 8, 3, 8, 8 |
|
| 1471 | Yet Another ICU Benchmark: A Flexible Multi-Center Framework for Clinical ML | 5.40 | 6.20 | 0.98 | 0.80 | | 5, 8, 3, 6, 5 | | 6, 8, 5, 6, 6 |
|
| 1472 | AgentBench: Evaluating LLMs as Agents | 6.00 | 6.20 | 1.83 | 0.20 | | 5, 8, 6, 8, 3 | | 6, 8, 6, 8, 3 |
|
| 1473 | How to Fine-Tune Vision Models with SGD | 6.60 | 6.40 | 0.80 | -0.20 | | 6, 5, 6, 8, 8 | | 6, 6, 6, 6, 8 |
|
| 1474 | Ensemble Distillation for Unsupervised Constituency Parsing | 6.20 | 6.60 | 1.96 | 0.40 | | 6, 6, 8, 3, 8 | | 6, 8, 8, 3, 8 |
|
| 1475 | Tailoring Self-Rationalizers with Multi-Reward Distillation | 6.00 | 6.40 | 0.80 | 0.40 | | 6, 5, 8, 6, 5 | | 6, 6, 8, 6, 6 |
|
| 1476 | Dynamic Sparse Training with Structured Sparsity | 5.40 | 6.20 | 0.98 | 0.80 | | 5, 6, 5, 5, 6 | | 6, 6, 6, 5, 8 |
|
| 1477 | Do LLMs exhibit human-like response biases? A case study in survey design | 5.40 | 6.20 | 1.47 | 0.80 | | 5, 3, 5, 8, 6 | | 5, 5, 5, 8, 8 |
|
| 1478 | TAIL: Task-specific Adapters for Imitation Learning with Large Pretrained Models | 5.80 | 6.20 | 0.98 | 0.40 | | 8, 5, 5, 6, 5 | | 8, 6, 5, 6, 6 |
|
| 1479 | Federated Causal Discovery from Heterogeneous Data | 6.20 | 6.20 | 1.47 | 0.00 | | 5, 5, 8, 5, 8 | | 5, 5, 8, 5, 8 |
|
| 1480 | Multilingual Visual Speech Recognition with a Single Model using Visual Speech Unit | 6.00 | 6.20 | 0.98 | 0.20 | | 5, 6, 8, 5, 6 | | 6, 6, 8, 5, 6 |
|
| 1481 | Elucidating the Exposure Bias in Diffusion Models | 6.20 | 6.20 | 0.98 | 0.00 | | 8, 6, 6, 5, 6 | | 8, 6, 6, 5, 6 |
|
| 1482 | Learning to solve Class-Constrained Bin Packing Problems via Encoder-Decoder Model | 6.00 | 6.40 | 0.80 | 0.40 | | 5, 6, 8, 5, 6 | | 6, 6, 8, 6, 6 |
|
| 1483 | Who to imitate: Imitating desired behavior from divserse multi-agent datasets | 6.00 | 7.00 | 1.26 | 1.00 | | 5, 8, 6, 6, 5 | | 6, 8, 8, 8, 5 |
|
| 1484 | Augmented Bayesian Policy Search | 6.00 | 6.20 | 0.98 | 0.20 | | 6, 6, 8, 5, 5 | | 6, 6, 8, 6, 5 |
|
| 1485 | DV-3DLane: End-to-end Multi-modal 3D Lane Detection with Dual-view Representation | 6.00 | 6.20 | 2.23 | 0.20 | | 10, 3, 6, 5 | | 10, 3, 6, 6, 6 |
|
| 1486 | Explore Outworld Knowledge in Large Language Models: A Case Study in Pokemon Game | 5.60 | 6.20 | 0.98 | 0.60 | | 6, 6, 5, 6, 5 | | 6, 6, 8, 6, 5 |
|
| 1487 | DecompOpt: Controllable and Decomposed Diffusion Models for Structure-based Molecular Optimization | 5.00 | 6.20 | 0.98 | 1.20 | | 5, 3, 5, 6, 6 | | 6, 5, 6, 8, 6 |
|
| 1488 | Towards Generalizable Multi-Camera 3D Object Detection via Perspective Debiasing | 5.60 | 6.20 | 0.98 | 0.60 | | 6, 5, 8, 3, 6 | | 6, 5, 8, 6, 6 |
|
| 1489 | On Penalty Methods for Nonconvex Bilevel Optimization and First-Order Stochastic Approximation | 6.20 | 6.20 | 0.98 | 0.00 | | 6, 6, 6, 5, 8 | | 6, 6, 6, 5, 8 |
|
| 1490 | Performance Gaps in Multi-view Clustering under the Nested Matrix-Tensor Model | 6.00 | 6.20 | 0.98 | 0.20 | | 6, 5, 6, 8, 5 | | 6, 5, 6, 8, 6 |
|
| 1491 | Lightweight Image Super-Resolution via Flexible Meta Pruning | 5.80 | 6.20 | 0.98 | 0.40 | | 5, 5, 8, 5, 6 | | 6, 5, 8, 6, 6 |
|
| 1492 | Entropy-MCMC: Sampling from Flat Basins with Ease | 6.20 | 6.20 | 0.98 | 0.00 | | 5, 6, 6, 8, 6 | | 5, 6, 6, 8, 6 |
|
| 1493 | The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models | 6.20 | 6.20 | 1.83 | 0.00 | | 6, 3, 8, 6, 8 | | 6, 3, 8, 6, 8 |
|
| 1494 | Self-supervised Representation Learning from Random Data Projectors | 5.80 | 6.20 | 0.98 | 0.40 | | 5, 5, 6, 8, 5 | | 6, 6, 6, 8, 5 |
|
| 1495 | AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection | 6.17 | 6.17 | 1.34 | 0.00 | | 8, 5, 6, 5, 8, 5 | | 8, 5, 6, 5, 8, 5 |
|
| 1496 | Improving Generalization and Safety of Deep Neural Networks with Masked Anchoring | 5.80 | 6.17 | 0.90 | 0.37 | | 6, 8, 6, 3, 6 | | 6, 8, 6, 5, 6, 6 |
|
| 1497 | Improving Gradient-guided Nested Sampling for Posterior Inference | 5.17 | 6.17 | 1.34 | 1.00 | | 6, 8, 5, 3, 3, 6 | | 6, 8, 5, 5, 5, 8 |
|
| 1498 | The Dark Side of the Hyperbolic Moon | 6.00 | 6.33 | 0.75 | 0.33 | | 6, 8, 6, 6, 5, 5 | | 6, 8, 6, 6, 6, 6 |
|
| 1499 | PBADet: A One-Stage Anchor-Free Approach for Part-Body Association | 5.67 | 6.17 | 0.90 | 0.50 | | 3, 6, 5, 6, 8, 6 | | 5, 6, 6, 6, 8, 6 |
|
| 1500 | Unified Language Model Alignment with Demonstration and Point-wise Human Preference | 4.75 | 6.00 | 1.22 | 1.25 | |
| 1501 | Mirage: Model-agnostic Graph Distillation for Graph Classification | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1502 | GPT Can Solve Mathematical Problems Without a Calculator | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1503 | Graph Parsing Networks | 5.50 | 6.00 | 2.12 | 0.50 | |
| 1504 | LUM-ViT: Learnable Under-sampling Mask Vision Transformer for Bandwidth Limited Optical Signal Acquisition | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1505 | Learning From Simplicial Data Based on Random Walks and 1D Convolutions | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1506 | Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1507 | Manipulating dropout reveals an optimal balance of efficiency and robustness in biological and machine visual systems | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1508 | Domain-agnostic Latent Diffusion Models for Synthesizing High-Quality Implicit Neural Representations | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1509 | Multimarginal Generative Modeling with Stochastic Interpolants | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1510 | Rethinking Channel Dependence for Multivariate Time Series Forecasting: Learning from Leading Indicators | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1511 | On Representation Complexity of Model-based and Model-free Reinforcement Learning | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1512 | Harnessing Discrete Representations for Continual Reinforcement Learning | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1513 | Generating Images in Context with Multimodal Large Language Models | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1514 | Lightweight Language Model Calibration for Open-ended Question Answering with Varied Answer Lengths | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1515 | Chain-of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1516 | Correct and speak: accent reduction with minimum supervision | 4.75 | 6.00 | 1.22 | 1.25 | |
| 1517 | FedDA: Faster Adaptive Gradient Methods for Federated Constrained Optimization | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1518 | Cost Adaptive Recourse Recommendation by Adaptive Preference Elicitation | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1519 | In-Context Learning Dynamics with Random Binary Sequences | 4.00 | 6.00 | 0.00 | 2.00 | |
| 1520 | Zero-shot Human-Object Interaction Detection via Conditional Multi-Modal Prompts | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1521 | Graph Transformers on EHRs: Better Representation Improves Downstream Performance | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1522 | Large Language Models as Automated Aligners for benchmarking Vision-Language Models | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1523 | Scaling physics-informed hard constraints with mixture-of-experts | 5.80 | 6.00 | 0.00 | 0.20 | | 6, 6, 5, 6, 6 | | 6, 6, 6, 6, 6 |
|
| 1524 | Simplicity Bias of SGD via Sharpness Minimization | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1525 | Davidsonian Scene Graph: Improving Reliability in Fine-grained Evaluation for Text-Image Generation | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1526 | Counting Graph Substructures with Graph Neural Networks | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1527 | Improving Branching in Neural Network Verification with Bound Implication Graph | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1528 | Dynamic Mode Decomposition-inspired Autoencoders for Reduced-order Modeling and Control of PDEs : Theory and Design | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1529 | Relational Convolutional Networks: A framework for learning representations of hierarchical relations | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1530 | Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1531 | Efficient Modulation for Vision Networks | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1532 | Fast-ELECTRA for Efficient Pre-training | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1533 | Language Model Detectors Are Easily Optimized Against | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1534 | iHyperTime: Interpretable Time Series Generation with Implicit Neural Representations | 4.75 | 6.00 | 1.22 | 1.25 | |
| 1535 | Beyond Spatio-Temporal Representations: Evolving Fourier Transform for Temporal Graphs | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1536 | NeuroBack: Improving CDCL SAT Solving using Graph Neural Networks | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1537 | ENHANCING MULTIVARIATE TIME SERIES FORECAST- ING WITH MUTUAL INFORMATION-DRIVEN CROSS- VARIABLE AND TEMPORAL MODELING | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1538 | Stability Analysis of Various Symbolic Rule Extraction Methods from Recurrent Neural Network | 6.50 | 6.00 | 1.41 | -0.50 | |
| 1539 | Variance-aware Regret Bounds for Stochastic Contextual Dueling Bandits | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1540 | Fine-grained Local Sensitivity Analysis of Standard Dot-Product Self-Attention | 4.67 | 6.00 | 1.41 | 1.33 | |
| 1541 | Directly Fine-Tuning Diffusion Models on Differentiable Rewards | 5.50 | 6.00 | 2.12 | 0.50 | |
| 1542 | A simple and interpretable model of grokking modular arithmetic tasks | 5.80 | 6.00 | 1.10 | 0.20 | | 5, 8, 6, 5, 5 | | 5, 8, 6, 5, 6 |
|
| 1543 | Robustness of Deep Learning for Accelerated MRI: Benefits of Diverse Training Data | 6.00 | 6.80 | 1.94 | 0.80 | | 3, 3, 10, 8 | | 5, 5, 10, 8, 6 |
|
| 1544 | From Bricks to Bridges: Product of Invariances to Enhance Latent Space Communication | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1545 | The Effectiveness of Random Forgetting for Robust Generalization | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1546 | Efficient Heterogeneous Meta-Learning via Channel Shuffling Modulation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1547 | To Grok or not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1548 | Hypernymy Understanding Evaluation of Text-to-Image Models via WordNet Hierarchy | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1549 | DRSM: De-Randomized Smoothing on Malware Classifier Providing Certified Robustness | 5.00 | 6.20 | 0.98 | 1.20 | | 6, 6, 3, 5, 5 | | 8, 6, 6, 6, 5 |
|
| 1550 | Calibrated Chaos: Variance Between Runs of Neural Network Training is Harmless and Inevitable | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1551 | Graph Neural Tangent Kernel and Graph Neural Network Gaussian Processes for Node Classification/ Regression | 4.00 | 5.67 | 0.47 | 1.67 | |
| 1552 | A Long Way To Go: Investigating Length Correlations in RLHF | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1553 | Can Large Language Models Infer Causation from Correlation? | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1554 | AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1555 | SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1556 | Layer-wise linear mode connectivity | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1557 | Detecting Pretraining Data from Large Language Models | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1558 | Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning | 5.50 | 6.00 | 0.00 | 0.50 | | 6, 3, 6, 6, 6, 6 | | 6, 6, 6, 6, 6, 6 |
|
| 1559 | Sharp results for NIEP and NMF | 5.80 | 6.00 | 1.10 | 0.20 | | 8, 5, 8, 5, 3 | | 8, 5, 6, 5, 6 |
|
| 1560 | AgentTuning: Enabling Generalized Agent Abilities for LLMs | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1561 | f-FERM: A Scalable Framework for Robust Fair Empirical Risk Minimization | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1562 | Source-Free and Image-Only Unsupervised Domain Adaptation for Category Level Object Pose Estimation | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1563 | Mediator Interpretation and Faster Learning Algorithms for Linear Correlated Equilibria in General Sequential Games | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1564 | Steering No-Regret Learners to Optimal Equilibria | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1565 | Unbalancedness in Neural Monge Maps Improves Unpaired Domain Translation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1566 | Is Inverse Reinforcement Learning Harder than Standard Reinforcement Learning? | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1567 | Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization | 5.60 | 6.20 | 0.98 | 0.60 | | 8, 6, 5, 3, 6 | | 8, 6, 6, 5, 6 |
|
| 1568 | Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1569 | The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1570 | From Matching to Mixing: A Graph Interpolation Approach for SAT Instance Generation | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1571 | Generative Marginalization Models | 5.60 | 6.00 | 1.10 | 0.40 | | 6, 6, 3, 5, 8 | | 6, 6, 5, 5, 8 |
|
| 1572 | Exploiting Negative Samples: A Catalyst for Cohort Discovery in Healthcare Analytics | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1573 | PROGRAM: PROtotype GRAph Model based Pseudo-Label Learning for Test-Time Adaptation | 5.80 | 6.20 | 0.98 | 0.40 | | 5, 5, 6, 5, 8 | | 6, 5, 6, 6, 8 |
|
| 1574 | Dissecting sample hardness: Fine-grained analysis of Hardness Characterization Methods | 5.40 | 6.20 | 2.71 | 0.80 | | 8, 5, 8, 1, 5 | | 8, 6, 8, 1, 8 |
|
| 1575 | ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1576 | Score Models for Offline Goal-Conditioned Reinforcement Learning | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1577 | Retrieval-Based Reconstruction For Time-series Contrastive Learning | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1578 | BackBench: Are Vision Language Models Resilient to Object-to-Background Context? | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1579 | PolyVoice: Language Models for Speech to Speech Translation | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1580 | Emerging Pixel-level Semantic Knowledge in Diffusion Models | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1581 | Customizable Combination of Parameter-Efficient Modules for Multi-Task Learning | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1582 | How Sparse Can We Prune A Deep Network: A Geometric Viewpoint | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1583 | Effortless Cross-Platform Video Codec: A Codebook-Based Method | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1584 | Can We Evaluate Domain Adaptation Models Without Target-Domain Labels? | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1585 | Towards Dynamic Trend Filtering through Trend Points Detection with Reinforcement Learning | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1586 | Reward Model Ensembles Help Mitigate Overoptimization | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1587 | Frequency-Aware Transformer for Learned Image Compression | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1588 | Efficient Episodic Memory Utilization of Cooperative Multi-Agent Reinforcement Learning | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1589 | Emergence of Equivariance in Deep Ensembles | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1590 | Time Series Continuous Modeling for Imputation and Forecasting with Implicit Neural Representations | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1591 | Flow to Better: Offline Preference-based Reinforcement Learning via Preferred Trajectory Generation | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1592 | Topic modeling as multi-objective optimization with Setwise Contrastive Learning | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1593 | One Step of Gradient Descent is Provably the Optimal In-Context Learner with One Layer of Linear Self-Attention | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1594 | Rethinking the Effectiveness of Graph Classification Datasets in Benchmarks for Assessing GNNs | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1595 | Label-Agnostic Forgetting: A Supervision-Free Unlearning in Deep Models | 5.50 | 6.00 | 2.12 | 0.50 | |
| 1596 | A bi-objective perspective on controllable language models: reward dropout improves off-policy control performance | 4.33 | 6.00 | 1.41 | 1.67 | |
| 1597 | EGraFFBench: Evaluation of Equivariant Graph Neural Network Force Fields for Atomistic Simulations | 4.67 | 6.00 | 1.41 | 1.33 | |
| 1598 | Guaranteed Trust Region Optimization via Two-Phase KL Penalization | 6.00 | 6.00 | 2.55 | 0.00 | |
| 1599 | Privacy at Interpolation: Precise Analysis for Random and NTK Features | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1600 | Do Large Language Models Know about Facts? | 4.75 | 6.75 | 1.30 | 2.00 | |
| 1601 | Abstractive Summarization through the PRISM of Decoding Strategies | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1602 | Offline RL for Online RL: Decoupled Policy Learning for Mitigating Exploration Bias | 6.33 | 6.00 | 1.22 | -0.33 | |
| 1603 | Contextual Bandits with Online Neural Regression | 6.00 | 6.00 | 1.10 | 0.00 | | 8, 6, 5, 5, 6 | | 8, 6, 5, 5, 6 |
|
| 1604 | Offline Reward Inference on Graph: A New Thinking | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1605 | Language-Interfaced Tabular Oversampling via Progressive Imputation and Self-Authentication | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1606 | Fake It Till Make It: Federated Learning with Consensus-Oriented Generation | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1607 | Provably Doubly Accelerated Federated Learning: The First Theoretically Successful Combination of Local Training and Communication Compression | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1608 | Grounded Object-Centric Learning | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1609 | On the Stability of Expressive Positional Encodings for Graph Neural Networks | 5.00 | 6.00 | 1.10 | 1.00 | | 6, 5, 3, 5, 6 | | 6, 5, 6, 5, 8 |
|
| 1610 | Low-Cost High-Power Membership Inference by Boosting Relativity | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1611 | Confidence-aware Reward Optimization for Fine-tuning Text-to-Image Models | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1612 | Statistical Perspective of Top-K Sparse Softmax Gating Mixture of Experts | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1613 | Enhancing Transfer Learning with Flexible Nonparametric Posterior Sampling | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1614 | Exploit Gradient Skew to Circumvent Byzantine Defenses for Federated Learning | 5.50 | 6.00 | 2.55 | 0.50 | |
| 1615 | Flag Aggregator: Scalable Distributed Training under Failures and Augmented Losses using Convex Optimization | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1616 | Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning | 5.80 | 6.00 | 1.10 | 0.20 | | 6, 5, 5, 5, 8 | | 6, 6, 5, 5, 8 |
|
| 1617 | CLIP as Multi-Task Multi-Kernel Learning | 4.50 | 5.00 | 1.41 | 0.50 | |
| 1618 | GraphCare: Enhancing Healthcare Predictions with Personalized Knowledge Graphs | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1619 | The Human-AI Substitution game: active learning from a strategic labeler | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1620 | Graph Convolutions Enrich the Self-Attention in Transformers! | 5.50 | 6.00 | 2.55 | 0.50 | |
| 1621 | Communication-Efficient Federated Non-Linear Bandit Optimization | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1622 | Waxing-and-Waning: a Generic Similarity-based Framework for Efficient Self-Supervised Learning | 4.75 | 6.50 | 0.87 | 1.75 | |
| 1623 | PatchMixer: A Patch-Mixing Architecture for Long-Term Time Series Forecasting | 4.75 | 6.00 | 1.22 | 1.25 | |
| 1624 | Neural Network-Based Score Estimation in Diffusion Models: Optimization and Generalization | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1625 | Soft Merging of Experts with Adaptive Routing | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1626 | CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1627 | Error Norm Truncation: Robust Training in the Presence of Data Noise for Text Generation Models | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1628 | Alt-Text with Context: Improving Accessibility for Images on Twitter | 4.67 | 6.00 | 1.41 | 1.33 | |
| 1629 | Alleviating Exposure Bias in Diffusion Models through Sampling with Shifted Time Steps | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1630 | DIFFTACTILE: A Physics-based Differentiable Tactile Simulator for Contact-rich Robotic Manipulation | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1631 | Tangent Transformers for Composition,Privacy and Removal | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1632 | Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1633 | A Black-box Approach for Non-stationary Multi-agent Reinforcement Learning | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1634 | Adaptive Federated Learning with Auto-Tuned Clients | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1635 | Neural Tangent Kernels Motivate Graph Neural Networks with Cross-Covariance Graphs | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1636 | Towards Training Without Depth Limits: Batch Normalization Without Gradient Explosion | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1637 | Tight Rates in Supervised Outlier Transfer Learning | 6.00 | 6.33 | 1.25 | 0.33 | |
| 1638 | MGDC-UNet: Multi-group Deformable Convolution for Medical Image Segmentation | 5.33 | 6.00 | 1.22 | 0.67 | |
| 1639 | Unsupervised Fact Verification by Language Model Distillation | 5.20 | 6.00 | 1.10 | 0.80 | | 5, 3, 5, 8, 5 | | 6, 6, 5, 8, 5 |
|
| 1640 | TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1641 | A ROBUST DIFFERENTIAL NEURAL ODE OPTIMIZER | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1642 | Graph Metanetworks for Processing Diverse Neural Architectures | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1643 | ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1644 | ECoFLaP: Efficient Coarse-to-Fine Layer-Wise Pruning for Vision-Language Models | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1645 | Adapting to Distribution Shift by Visual Domain Prompt Generation | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1646 | TIGERScore: Building Explainable Metric for All Text Generation Task | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1647 | Towards Establishing Guaranteed Error for Learned Database Operations | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1648 | Grokking as the transition from lazy to rich training dynamics | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1649 | Mixture of Weak and Strong Experts on Graphs | 5.33 | 6.00 | 1.00 | 0.67 | | 5, 5, 8, 6, 5, 3 | | 5, 6, 8, 6, 5, 6 |
|
| 1650 | Meta-Learning Strategies through Value Maximization in Neural Networks | 5.25 | 6.25 | 1.09 | 1.00 | |
| 1651 | Variational quantization for state space models | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1652 | Unlocking Tuning-free Generalization: Minimizing the PAC-Bayes Bound with Trainable Priors | 5.40 | 6.00 | 1.10 | 0.60 | | 5, 3, 5, 8, 6 | | 6, 5, 5, 8, 6 |
|
| 1653 | Talk like a Graph: Encoding Graphs for Large Language Models | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1654 | Toward Optimal Policy Population Growth in Two-Player Zero-Sum Games | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1655 | Connecting NTK and NNGP: A Unified Theoretical Framework for Neural Network Learning Dynamics in the Kernel Regime | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1656 | The HIM Solution for Legged Locomotion: Minimal Sensors, Efficient Learning, and Substantial Agility | 4.75 | 6.00 | 1.22 | 1.25 | |
| 1657 | OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1658 | Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1659 | Better Neural PDE Solvers Through Data-Free Mesh Movers | 4.00 | 6.00 | 0.00 | 2.00 | |
| 1660 | Towards Robust Fidelity for Evaluating Explainability of Graph Neural Networks | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1661 | Adapt and Diffuse: Sample-adaptive Reconstruction via Latent Diffusion Models | 4.50 | 6.00 | 1.22 | 1.50 | |
| 1662 | Neural Optimal Transport with General Cost Functionals | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1663 | MI-NeRF: Learning a Single Face NeRF from Multiple Identities | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1664 | Efficient Network Embedding in the Exponentially Large Quantum Hilbert Space: A High-Dimensional Perspective on Embedding | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1665 | Non-Exchangeable Conformal Risk Control | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1666 | More Context, Less Distraction: Zero-shot Visual Classification by Inferring and Conditioning on Contextual Attributes | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1667 | AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos? | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1668 | BENO: Boundary-embedded Neural Operators for Elliptic PDEs | 5.20 | 6.60 | 1.20 | 1.40 | | 3, 8, 3, 6, 6 | | 6, 8, 5, 6, 8 |
|
| 1669 | 3D Interacting Hands Diffusion Model | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1670 | On Trajectory Augmentations for Off-Policy Evaluation | 4.33 | 6.00 | 0.00 | 1.67 | |
| 1671 | A Note on Some Statistical Properties of Signature Transform Under Stochastic Integrals | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1672 | Fit Like You Sample: Sample-Efficient Generalized Score Matching from Fast Mixing Diffusions | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1673 | Injecting a Structural Inductive Bias into a Seq2Seq Model by Simulation | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1674 | Clifford Group Equivariant Simplicial Message Passing Networks | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1675 | SMPE: A Framework for Multi-Dimensional Permutation Equivariance | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1676 | Targeted Model Inversion: Distilling Style Encoded in Predictions | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1677 | Equivariant Quantum Graph Neural Network for Mixed-Integer Linear Programming | 4.25 | 6.00 | 1.22 | 1.75 | |
| 1678 | T-Rep: Representation Learning for Time Series using Time-Embeddings | 5.00 | 6.00 | 1.10 | 1.00 | | 3, 6, 5, 6, 5 | | 6, 8, 5, 6, 5 |
|
| 1679 | Experimental Design for Multi-Channel Imaging via Task-Driven Feature Selection | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1680 | Subword embedding from bytes against embedding-based attacks | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1681 | On the Reliability of Watermarks for Large Language Models | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1682 | NaviFormer: A Deep Reinforcement Learning Transformer-like Model to Holistically Solve the Navigation Problem | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1683 | EHI: End-to-end learning of Hierarchical Index for Efficient Dense Retrieval | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1684 | Linear Log-Normal Attention with Unbiased Concentration | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1685 | Energy-guided Entropic Neural Optimal Transport | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1686 | ZeroI2V: Zero-Cost Adaptation of Pre-Trained Transformers from Image to Video | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1687 | Masks, Signs, And Learning Rate Rewinding | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1688 | GlucoBench: Curated List of Continuous Glucose Monitoring Datasets with Prediction Benchmarks | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1689 | Quantifying and Enhancing Multi-modal Robustness with Modality Preference | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1690 | Rigid Protein-Protein Docking via Equivariant Elliptic-Paraboloid Interface Prediction | 6.33 | 6.00 | 2.12 | -0.33 | |
| 1691 | Early Neuron Alignment in Two-layer ReLU Networks with Small Initialization | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1692 | Rethinking the Uniformity Metric in Self-Supervised Learning | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1693 | Evaluating model bias requires characterizing model mistakes | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1694 | Diving Segmentation Model into Pixels | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1695 | Particle Guidance: non-I.I.D. Diverse Sampling with Diffusion Models | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1696 | Hybrid Sharing for Multi-Label Image Classification | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1697 | On convex decision regions in deep network representations | 4.50 | 6.00 | 1.22 | 1.50 | |
| 1698 | An improved analysis of per-sample and per-update clipping in federated learning | 5.40 | 6.00 | 1.10 | 0.60 | | 6, 6, 5, 5, 5 | | 6, 6, 8, 5, 5 |
|
| 1699 | Understanding and Mitigating Extrapolation Failures in Physics-Informed Neural Networks | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1700 | Expected Probabilistic Hierarchies | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1701 | MuseCoco: Generating Symbolic Music from Text | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1702 | Towards Provably Efficient Learning of Extensive-Form Games with Imperfect Information and Linear Function Approximation | 5.00 | 5.75 | 0.43 | 0.75 | |
| 1703 | Prediction without Preclusion: Recourse Verification with Reachable Sets | 4.50 | 6.00 | 1.22 | 1.50 | |
| 1704 | Revisiting Data Augmentation in Deep Reinforcement Learning | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1705 | Simplicial Representation Learning with Neural $k$-Forms | 5.80 | 6.00 | 1.10 | 0.20 | | 6, 5, 5, 8, 5 | | 8, 6, 5, 6, 5 |
|
| 1706 | TextBind: Multi-turn Interleaved Multimodal Instruction-following in the Wild | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1707 | Kalman Filter Online Learning from non-Stationary Data | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1708 | Local Vs. Global Interpretability: A Computational Perspective | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1709 | Post-Nonlinear Causal Relationship with Finite Samples: A Maximal Correlation Perspective | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1710 | Neural Networks Trained by Weight Permutation are Universal Approximators | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1711 | Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1712 | Posterior Sampling Based on Gradient Flows of the MMD with Negative Distance Kernel | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1713 | First-order ANIL provably learns representations despite overparametrisation | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1714 | Semi-supervised batch learning from logged data | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1715 | Towards Robust Out-of-Distribution Generalization Bounds via Sharpness | 5.50 | 6.50 | 1.50 | 1.00 | |
| 1716 | Data Prediction Denoising Models: The Pupil Outdoes the Master | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1717 | Robust Training of Federated Models with Extremely Label Deficiency | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1718 | On Accelerating Diffusion-Based Sampling Processes via Improved Integration Approximation | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1719 | OPTIMAL ROBUST MEMORIZATION WITH RELU NEURAL NETWORKS | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1720 | Scalable Modular Network: A Framework for Adaptive Learning via Agreement Routing | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1721 | Near-Optimal Quantum Algorithm for Minimizing the Maximal Loss | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1722 | Intriguing Properties of Data Attribution on Diffusion Models | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1723 | SoftTreeMax: Exponential Variance Reduction in Policy Gradient via Tree Expansion | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1724 | Fully Hyperbolic Convolutional Neural Networks for Computer Vision | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1725 | An interpretable error correction method for enhancing code-to-code translation | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1726 | Seizing Serendipity: Exploiting the Value of Past Success in Off-Policy Actor Critic | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1727 | Constructing Adversarial Examples for Vertical Federated Learning: Optimal Client Corruption through Multi-Armed Bandit | 5.00 | 6.00 | 1.22 | 1.00 | |
| 1728 | Interpretable Diffusion via Information Decomposition | 5.00 | 6.00 | 0.00 | 1.00 | | 6, 3, 3, 6, 6, 6 | | 6, 6, 6, 6, 6, 6 |
|
| 1729 | Distributional Distance Classifiers for Goal-Conditioned Reinforcement Learning | 5.80 | 6.00 | 1.90 | 0.20 | | 8, 3, 5, 8, 5 | | 8, 3, 5, 8, 6 |
|
| 1730 | Decoupling Weighing and Selecting for Integrating Multiple Graph Pre-training Tasks | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1731 | MAP IT to Visualize Representations | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1732 | Measuring Vision-Language STEM Skills of Neural Models | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1733 | Transformer Fusion with Optimal Transport | 6.00 | 6.50 | 0.87 | 0.50 | |
| 1734 | Phrase Grounding-based Style Transfer for Single-Domain Generalized Object Detection | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1735 | LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1736 | Learning Flexible Body Collision Dynamics with Hierarchical Contact Mesh Transformer | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1737 | Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1738 | EasyTPP: Towards Open Benchmarking Temporal Point Processes | 5.50 | 6.00 | 3.08 | 0.50 | |
| 1739 | A unified sampling framework for solver searching of Diffusion Probabilistic Models | 5.60 | 6.00 | 0.00 | 0.40 | | 5, 6, 6, 6, 5 | | 6, 6, 6, 6, 6 |
|
| 1740 | What Will My Model Forget? Forecasting Forgotten Examples in Language Model Refinement | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1741 | Collaborating Heterogeneous Natural Language Processing Tasks via Federated Learning | 7.00 | 6.00 | 1.22 | -1.00 | |
| 1742 | Combinatorial Bandits for Maximum Value Reward Function under Value-Index Feedback | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1743 | Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks | 6.00 | 5.50 | 1.80 | -0.50 | |
| 1744 | Confident Sinkhorn Allocation for Pseudo-Labeling | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1745 | Learning from Aggregate responses: Instance Level versus Bag Level Loss Functions | 5.60 | 6.00 | 0.00 | 0.40 | | 5, 6, 5, 6, 6 | | 6, 6, 6, 6, 6 |
|
| 1746 | Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1747 | Divide and Orthogonalize: Efficient Continual Learning with Local Model Space Projection | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1748 | Benchmarking Deletion Metrics with the Principled Explanations | 5.50 | 6.00 | 2.12 | 0.50 | |
| 1749 | Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1750 | FedSKU: Defending Backdoors in Federated Learning Through Selective Knowledge Unlearning | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1751 | On the Effect of Batch Size in Byzantine-Robust Distributed Learning | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1752 | Revisiting Plasticity in Visual Reinforcement Learning: Data, Modules and Training Stages | 4.75 | 6.00 | 0.00 | 1.25 | |
| 1753 | Ins-DetCLIP: Aligning Detection Model to Follow Human-Language Instruction | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1754 | Sample-efficient Learning of Infinite-horizon Average-reward MDPs with General Function Approximation | 5.75 | 6.25 | 1.09 | 0.50 | |
| 1755 | Last-Iterate Convergence Properties of Regret-Matching Algorithms in Games | 5.80 | 6.00 | 1.90 | 0.20 | | 8, 8, 5, 3, 5 | | 8, 8, 5, 3, 6 |
|
| 1756 | Boosting Dataset Distillation with the Assistance of Crucial Samples | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1757 | FedWon: Triumphing Multi-domain Federated Learning Without Normalization | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1758 | Learning Causal Dynamics Models in Object-Oriented Environments | 5.20 | 6.00 | 0.00 | 0.80 | | 5, 5, 5, 6, 5 | | 6, 6, 6, 6, 6 |
|
| 1759 | Exploring the cloud of feature interaction scores in a Rashomon set | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1760 | Annealing Self-Distillation Rectification Improves Adversarial Training | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1761 | Differentially Private Latent Diffusion Models | 4.75 | 6.00 | 1.22 | 1.25 | |
| 1762 | Incentivized Black-Box Model Sharing | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1763 | Resource Efficient Test-Time Training with Slimmable Network | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1764 | Embarrassingly Simple Dataset Distillation | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1765 | CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing | 6.00 | 6.50 | 1.50 | 0.50 | |
| 1766 | Hardware-Friendly Post-Training Quantization: Input- and Output-Channelwise Scale and Offset | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1767 | Efficient Identification of Direct Causal Parents via Invariance and Minimum Error Testing | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1768 | Certified Deductive Reasoning with Language Models | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1769 | Teaching Large Language Models to Self-Debug | 4.50 | 6.00 | 0.00 | 1.50 | |
| 1770 | MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1771 | SemiReward: A General Reward Model for Semi-supervised Learning | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1772 | Modulate Your Spectrum in Self-Supervised Learning | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1773 | A Computational Framework for Solving Wasserstein Lagrangian Flows | 5.40 | 6.00 | 1.90 | 0.60 | | 6, 8, 3, 5, 5 | | 6, 8, 3, 8, 5 |
|
| 1774 | Improving Factuality and Reasoning in Language Models through Multiagent Debate | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1775 | Towards Optimal Feature-Shaping Methods for Out-of-Distribution Detection | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1776 | Teaching Language Models to Hallucinate Less with Synthetic Tasks | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1777 | Enable Lanuguage Models to Implicitly Learn Self-Improvement From Data | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1778 | Multimodal Molecular Pretraining via Modality Blending | 5.00 | 6.00 | 1.22 | 1.00 | |
| 1779 | Understanding when Dynamics-Invariant Data Augmentations Benefit Model-free Reinforcement Learning Updates | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1780 | DeepZero: Scaling Up Zeroth-Order Optimization for Deep Model Training | 5.67 | 6.00 | 1.73 | 0.33 | | 5, 3, 6, 6, 8, 6 | | 5, 3, 6, 8, 8, 6 |
|
| 1781 | CLIP the Bias: How Useful is Balancing Data in Multimodal Learning? | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1782 | Teaching Arithmetic to Small Transformers | 4.20 | 6.00 | 1.10 | 1.80 | | 3, 5, 3, 5, 5 | | 6, 5, 6, 5, 8 |
|
| 1783 | GOAt: Explaining Graph Neural Networks via Graph Output Attribution | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1784 | Views Can Be Deceiving: Improved SSL Through Feature Space Augmentation | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1785 | PAGER: A Framework for Failure Analysis of Deep Regression Models | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1786 | Fisher-aware Quantization for DETR Detectors with Critical-category Objectives | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1787 | FLIRT: Feedback Loop In-context Red Teaming | 5.00 | 6.00 | 1.22 | 1.00 | |
| 1788 | Zeroth-Order Optimization Meets Human Feedback: Provable Learning via Ranking Oracles | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1789 | Neurosymbolic Grounding for Compositional Generalization | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1790 | Towards More Robust NLP System Evaluation: Handling Missing Scores in Benchmarks | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1791 | Adaptive Sharpness-Aware Pruning for Robust Sparse Networks | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1792 | MBR and QE Finetuning: Training-time Distillation of the Best and Most Expensive Decoding Methods | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1793 | The Hidden Language of Diffusion Models | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1794 | Low Rank Matrix Completion via Robust Alternating Minimization in Nearly Linear Time | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1795 | Imprecise Label Learning: A Unified Framework for Learning with Various Imprecise Label Configurations | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1796 | Str2Str: A Score-based Framework for Zero-shot Protein Conformation Sampling | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1797 | Memory-Consistent Neural Networks for Imitation Learning | 4.75 | 6.00 | 0.00 | 1.25 | |
| 1798 | FedGT: Federated Node Classification with Scalable Graph Transformer | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1799 | SOHES: Self-supervised Open-world Hierarchical Entity Segmentation | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1800 | EquiformerV2: Improved Equivariant Transformer for Scaling to Higher-Degree Representations | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1801 | DOMINO: A Dual-System for Multi-step Visual Language Reasoning | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1802 | Dissecting Neural Network Robustness Proofs | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1803 | Matryoshka Diffusion Models | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1804 | $alpha$TC-VAE: On the relationship between Disentanglement and Diversity | 4.67 | 6.00 | 1.41 | 1.33 | |
| 1805 | MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1806 | Robust multimodal models have outlier features and encode more concepts | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1807 | Efficient and Scalable Graph Generation by Spectrum Preserving Local Expansion | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1808 | NExT-GPT: Any-to-Any Multimodal LLM | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1809 | FacTool: Factuality Detection in Generative AI - A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1810 | Auto-Regressive Next-Token Predictors are Universal Learners | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1811 | ALAM: Averaged Low-Precision Activation for Memory-Efficient Training of Transformer Models | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1812 | Conformal Inductive Graph Neural Networks | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1813 | Adversarial Supervision Makes Layout-to-Image Diffusion Models Thrive | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1814 | Separate and Diffuse: Using a Pretrained Diffusion Model for Better Source Separation | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1815 | Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1816 | AuG-KD: Anchor-Based Mixup Generation for Out-of-Domain Knowledge Distillation | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1817 | The Cost of Scaling Down Large Language Models: Reducing Model Size Affects Memory before In-context Learning | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1818 | TOSS: High-quality Text-guided Novel View Synthesis from a Single Image | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1819 | BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing | 5.00 | 6.25 | 1.09 | 1.25 | |
| 1820 | Just-in-Time Security Patch Detection - LLM At the Rescue for Data Augmentation | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1821 | Fair Off-Policy Learning from Observational Data | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1822 | SMAAT: Scalable Manifold-Aware Adversarial Training for Large Language Models | 4.80 | 6.00 | 1.10 | 1.20 | | 5, 6, 3, 5, 5 | | 5, 6, 5, 8, 6 |
|
| 1823 | FedTrans: Client-Transparent Utility Estimation for Robust Federated Learning | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1824 | Idempotent Generative Network | 5.50 | 6.00 | 2.12 | 0.50 | |
| 1825 | SparseDFF: Sparse-View Feature Distillation for One-Shot Dexterous Manipulation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1826 | Improve Temporal Consistency In Diffusion Models through Noise Correlations | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1827 | Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1828 | Respect the model: Fine-grained and Robust Explanation with Sharing Ratio Decomposition | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1829 | SweetDreamer: Aligning Geometric Priors in 2D diffusion for Consistent Text-to-3D | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1830 | Exploring Diffusion Time-steps for Unsupervised Representation Learning | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1831 | Hypergraph Dynamic System | 4.25 | 6.00 | 1.22 | 1.75 | |
| 1832 | Emu: Generative Pretraining in Multimodality | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1833 | CLIP-Guided Reinforcement Learning for Open-Vocabulary Tasks | 5.60 | 6.00 | 1.10 | 0.40 | | 6, 5, 8, 3, 6 | | 6, 5, 8, 5, 6 |
|
| 1834 | Feature Normalization Prevents Collapse of Non-contrastive Learning Dynamics | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1835 | Equivariant Deep Weight Space Alignment | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1836 | IGTO: Individual Global Transform Optimization for Multi-Agent Reinforcement Learning | 6.00 | 6.00 | 1.10 | 0.00 | | 8, 5, 6, 5, 6 | | 8, 5, 6, 5, 6 |
|
| 1837 | PAC-FNO: Parallel-Structured All-Component Fourier Neural Operators for Recognizing Low-Quality Images | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1838 | Object-Aware Inversion and Reassembly for Image Editing | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1839 | Peering Through Preferences: Unraveling Feedback Acquisition for Aligning Large Language Models | 5.50 | 6.50 | 0.87 | 1.00 | |
| 1840 | Sample-Efficient Multi-Agent RL: An Optimization Perspective | 5.80 | 6.00 | 0.00 | 0.20 | | 6, 6, 5, 6, 6 | | 6, 6, 6, 6, 6 |
|
| 1841 | Self-Supervised Dataset Distillation for Transfer Learning | 5.60 | 6.20 | 0.98 | 0.60 | | 6, 6, 5, 5, 6 | | 6, 8, 6, 5, 6 |
|
| 1842 | SAN: Inducing Metrizability of GAN with Discriminative Normalized Linear Layer | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1843 | On the Theoretical Analysis of Dense Contrastive Learning | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1844 | Prompt Tuning with Diffusion for Few-Shot Pre-trained Policy Generalization | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1845 | Functional Bayesian Tucker Decomposition for Continuous-indexed Tensor Data | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1846 | Successor Features for Efficient Multi-Subject Controlled Text Generation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1847 | Adversarial Attacks on Fairness of Graph Neural Networks | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1848 | Faithful Vision-Language Interpretation via Concept Bottleneck Models | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1849 | P$^2$OT: Progressive Partial Optimal Transport for Deep Imbalanced Clustering | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1850 | Accelerating Non-IID Federated Learning via Heterogeneity-Guided Client Sampling | 4.67 | 6.00 | 1.41 | 1.33 | |
| 1851 | Polynormer: Polynomial-Expressive Graph Transformer in Linear Time | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1852 | Shifting Attention to Relevance: Towards the Uncertainty Estimation of Large Language Models | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1853 | Continuous Field Reconstruction from Sparse Observations with Implicit Neural Networks | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1854 | Weaker MVI Condition: Extragradient Methods with Multi-Step Exploration | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1855 | Towards Precise Prediction Uncertainty in GNNs: Refining GNNs with Topology-grouping Strategy | 4.33 | 6.00 | 0.00 | 1.67 | |
| 1856 | Teaching wiser, Learning smarter: Multi-stage Decoupled Relational Knowledge Distillation with Adaptive Stage Selection | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1857 | Morphological Maze: Control Reconfigurable Soft Robots with Fine-grained Morphology Change | 5.00 | 6.00 | 1.22 | 1.00 | |
| 1858 | ROSA: Random Orthogonal Subspace Adaptation | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1859 | PRES: Toward Scalable Memory-Based Dynamic Graph Neural Networks | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1860 | TEDDY: Trimming Edges with Degree-based Graph Diffusion Strategy | 5.60 | 6.00 | 1.10 | 0.40 | | 5, 8, 6, 6, 3 | | 5, 8, 6, 6, 5 |
|
| 1861 | Learning to Jointly Understand Visual and Tactile Signals | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1862 | The Unreasonable Effectiveness of Linear Prediction as a Perceptual Metric | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1863 | Overcoming the Pitfalls of Vision-Language Model Finetuning for OOD Generalization | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1864 | ARM: Refining Multivariate Forecasting with Adaptive Temporal-Contextual Learning | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1865 | Copula Conformal prediction for multi-step time series prediction | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1866 | Domain Randomization via Entropy Maximization | 5.33 | 6.00 | 1.00 | 0.67 | | 3, 6, 6, 6, 3, 8 | | 5, 6, 6, 6, 5, 8 |
|
| 1867 | Machine Unlearning for Image-to-Image Generative Models | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1868 | Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1869 | Fast Explanation of RBF-Kernel SVM Models Using Activation Patterns | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1870 | Compressing Latent Space via Least Volume | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1871 | Repelling Random Walks | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1872 | Horizon-free Reinforcement Learning in Adversarial Linear Mixture MDPs | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1873 | Backdoor Federated Learning by Poisoning Backdoor-Critical Layers | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1874 | Towards image compression with perfect realism at ultra-low bitrates | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1875 | V-DETR: DETR with Vertex Relative Position Encoding for 3D Object Detection | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1876 | Multi-task Learning with 3D-Aware Regularization | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1877 | Generative Sliced MMD Flows with Riesz Kernels | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1878 | Convolutions Through the Lens of Tensor Networks | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1879 | Towards Poisoning Fair Representations | 5.60 | 6.00 | 1.90 | 0.40 | | 6, 6, 8, 5, 3 | | 8, 6, 8, 5, 3 |
|
| 1880 | Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework | 5.50 | 6.75 | 1.30 | 1.25 | |
| 1881 | LCOT: Linear Circular Optimal Transport | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1882 | Learning invariant representations of time-homogeneous stochastic dynamical systems | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1883 | Exploration and Anti-Exploration with Distributional Random Network Distillation | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1884 | Learning Nash equilibria in Rank-1 games: Going beyond the Minty Property | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1885 | Towards Realistic Unsupervised Fine-tuning with Vision-Language Models | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1886 | Guaranteed Out-Of-Distribution Detection with Diverse Auxiliary Set | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1887 | Retro-fallback: retrosynthetic planning in an uncertain world | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1888 | LiDAR-PTQ: Post-Training Quantization for Point Cloud 3D Object Detection | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1889 | Duolando: Follower GPT with Off-Policy Reinforcement Learning for Dance Accompaniment | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1890 | Expressive Modeling is Insufficient for Offline RL: A Tractable Inference Perspective | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1891 | Unified Uncertainty Estimation | 6.00 | 6.00 | 2.12 | 0.00 | |
| 1892 | OpenChat: Advancing Open-source Language Models with Mixed-Quality Data | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1893 | LATEC — A benchmark for large-scale attribution & attention evaluation in computer vision | 6.00 | 5.60 | 1.62 | -0.40 | | 3, 6, 8, 5, 8 | | 3, 6, 8, 5, 6 |
|
| 1894 | Human Motion Diffusion as a Generative Prior | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1895 | AdjointDPM: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1896 | Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1897 | SparseFormer: Sparse Visual Recognition via Limited Latent Tokens | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1898 | Distribution Shift-Aware Prediction Refinement for Test-Time Adaptation | 5.67 | 5.67 | 0.47 | 0.00 | |
| 1899 | LLM-grounded Video Diffusion Models | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1900 | PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1901 | LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1902 | Equivariant Graph Neural Operator for Modeling 3D Dynamics | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1903 | Improving Diffusion Models for Inverse Problems Using Optimal Posterior Covariance | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1904 | AVOID: Alleviating VAE's Overestimation in Unsupervised OOD Detection | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1905 | A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1906 | Incremental Randomized Smoothing Certification | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1907 | Where have you been? A Study of Privacy Risk for Point-of-Interest Recommendation | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1908 | Learning Multi-Agent Communication with Contrastive Learning | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1909 | Adding 3D Geometry Control to Diffusion Models | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1910 | LegoNet: Piecing Together and Breaking Apart Sub-Networks for Scalable Multi-task Learning | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1911 | Provably Efficient CVaR RL in Low-rank MDPs | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1912 | On the Disconnect Between Theory and Practice of Overparametrized Neural Networks | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1913 | COPlanner: Plan to Roll Out Conservatively but to Explore Optimistically for Model-Based RL | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1914 | Rationality of Thought Improves Reasoning in Large Language Models | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1915 | The Devil is in the Object Boundary: Towards Annotation-free Instance Segmentation using Foundation Models | 5.40 | 6.00 | 1.10 | 0.60 | | 5, 6, 5, 6, 5 | | 5, 6, 8, 6, 5 |
|
| 1916 | RegQ: Convergent Q-Learning with Linear Function Approximation using Regularization | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1917 | Faithful Explanations of Black-box NLP Models Using LLM-generated Counterfactuals | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1918 | Noise-Aware Algorithm for Heterogeneous Differentially Private Federated Learning | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1919 | L-Eval: Instituting Standardized Evaluation for Long Context Language Models | 6.33 | 6.00 | 1.22 | -0.33 | |
| 1920 | Robust Stereo Matching by Risk Minimization | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1921 | FROSTER: Frozen CLIP is A Strong Teacher for Open-Vocabulary Action Recognition | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1922 | TASK PLANNING FOR VISUAL ROOM REARRANGEMENT UNDER PARTIAL OBSERVABILITY | 5.00 | 6.67 | 0.94 | 1.67 | |
| 1923 | Parallelizing non-linear sequential models over the sequence length | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1924 | Long-tailed Diffusion Models with Oriented Calibration | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1925 | NfgTransformer: Equivariant Representation Learning for Normal-form Games | 4.25 | 6.00 | 2.12 | 1.75 | |
| 1926 | No learning rates needed: Introducing SaLSa - Stable Armijo Line Search Adaptation | 6.00 | 5.00 | 2.12 | -1.00 | |
| 1927 | fairret: a Framework for Differentiable Fairness Regularization Terms | 4.75 | 6.00 | 2.12 | 1.25 | |
| 1928 | GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest | 6.00 | 5.50 | 1.80 | -0.50 | |
| 1929 | Two Time-Slices Help Topological Ordering for Learning Directed Acyclic Graphs | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1930 | Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs | 5.67 | 6.00 | 0.00 | 0.33 | |
| 1931 | Predicting masked tokens in stochastic locations improves masked image modeling | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1932 | Continual Learning in Open-vocabulary Classification with Complementary Memory Systems | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1933 | HypeBoy: Generative Self-Supervised Representation Learning on Hypergraphs | 5.25 | 6.00 | 1.22 | 0.75 | |
| 1934 | LightHGNN: Distilling Hypergraph Neural Networks into MLPs for 100x Faster Inference | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1935 | Lewis's Signaling Game as beta-VAE For Natural Word Lengths and Segments | 5.25 | 6.00 | 2.12 | 0.75 | |
| 1936 | Tuning-Free Accountable Intervention for LLM Deployment - A Metacognitive Approach | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1937 | TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1938 | Prior Mismatch and Adaptation in PnP-ADMM with a Nonconvex Convergence Analysis | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1939 | Bridging the Gap Between Foundation Models and Heterogeneous Federated Learning | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1940 | MatFormer: Nested Transformer for Elastic Inference | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1941 | Trajeglish: Learning the Language of Driving Scenarios | 4.67 | 6.00 | 0.00 | 1.33 | |
| 1942 | SPLITZ: Certifiable Robustness via Split Lipschitz Randomized Smoothing | 5.00 | 6.00 | 2.12 | 1.00 | |
| 1943 | Graph2Tac: Learning hierarchical representations of math concepts in theorem proving | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1944 | Exploring Modality Collaboration with Modality-Agnostic Transformers in Multi-Modal Federated Learning | 6.00 | 5.50 | 2.50 | -0.50 | |
| 1945 | Towards Causal Foundation Model: on Duality between Causal Inference and Attention | 6.00 | 6.00 | 2.55 | 0.00 | |
| 1946 | Unveiling Options with Neural Network Decomposition | 5.33 | 6.00 | 0.00 | 0.67 | |
| 1947 | BECLR: Batch Enhanced Contrastive Unsupervised Few-Shot Learning | 5.33 | 6.67 | 0.94 | 1.33 | |
| 1948 | Meta Inverse Constrained Reinforcement Learning: Convergence Guarantee and Generalization Analysis | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1949 | Decision Transformer is a Robust Contender for Offline Reinforcement Learning | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1950 | RAIN: Your Language Models Can Align Themselves without Finetuning | 5.80 | 6.00 | 1.10 | 0.20 | | 5, 6, 5, 8, 5 | | 5, 6, 6, 8, 5 |
|
| 1951 | Batch normalization is sufficient for universal function approximation in CNNs | 5.25 | 6.00 | 2.12 | 0.75 | |
| 1952 | GNeRP: Gaussian-guided Neural Reconstruction of Reflective Objects with Noisy Polarization Priors | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1953 | PORF: POSE RESIDUAL FIELD FOR ACCURATE NEURAL SURFACE RECONSTRUCTION | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1954 | AvatarStudio: High-fidelity and Animatable 3D Avatar Creation from Text | 5.33 | 6.00 | 1.41 | 0.67 | |
| 1955 | Multimodal Web Navigation with Instruction-Finetuned Foundation Models | 6.50 | 6.00 | 1.41 | -0.50 | |
| 1956 | Real-Fake: Effective Training Data Synthesis Through Distribution Matching | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1957 | Learning Conditional Invariances through Non-Commutativity | 5.33 | 6.33 | 1.25 | 1.00 | |
| 1958 | Information Flow in Self-Supervised Learning | 5.00 | 6.00 | 1.22 | 1.00 | |
| 1959 | LipVoicer: Generating Speech from Silent Videos Guided by Lip Reading | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1960 | Window Attention is Bugged: How not to Interpolate Position Embeddings | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1961 | Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion Attacks | 5.20 | 6.20 | 0.98 | 1.00 | | 5, 6, 6, 3, 6 | | 5, 8, 6, 6, 6 |
|
| 1962 | Finite-State Autoregressive Entropy Coding for Efficient Learned Lossless Compression | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1963 | Sample-Efficient Learning of POMDPs with Multiple Observations In Hindsight | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1964 | AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1965 | Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1966 | Class Incremental Learning via Likelihood Ratio Based Task Prediction | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1967 | Re-Reading Improves Reasoning in Language Models | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1968 | Discriminatively Matched Part Tokens for Pointly Supervised Instance Segmentation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1969 | Improved Regret Bounds for Non-Convex Online-Within-Online Meta Learning | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1970 | Isometric Representation Learning for Disentangled Latent Space of Diffusion Models | 5.50 | 6.25 | 1.09 | 0.75 | |
| 1971 | A Statistical Analysis of Wasserstein Autoencoders for Intrinsically Low-dimensional Data | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1972 | Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1973 | Generalized Neural Sorting Networks with Error-Free Differentiable Swap Functions | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1974 | Self-Guided Masked Autoencoders for Domain-Agnostic Self-Supervised Learning | 5.20 | 6.00 | 0.00 | 0.80 | | 5, 5, 5, 6, 5 | | 6, 6, 6, 6, 6 |
|
| 1975 | Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL | 5.50 | 6.00 | 0.00 | 0.50 | |
| 1976 | Towards Few-Shot Adaptation of Foundation Models via Multitask Finetuning | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1977 | GPAvatar: Generalizable and Precise Head Avatar from Image(s) | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1978 | Unleashing the power of Neural Collapse for Transferability Estimation | 5.80 | 5.60 | 0.49 | -0.20 | | 5, 5, 6, 5, 8 | | 6, 5, 6, 5, 6 |
|
| 1979 | LLCP: Learning Latent Causal Processes for Reasoning-based Video Question Answer | 5.80 | 6.00 | 1.90 | 0.20 | | 8, 3, 5, 5, 8 | | 8, 3, 6, 5, 8 |
|
| 1980 | VoiceGen: Describing and Generating Voices with Text Prompt | 5.00 | 6.00 | 0.00 | 1.00 | |
| 1981 | Consistent Video-to-Video Transfer Using Synthetic Dataset | 6.50 | 6.00 | 1.22 | -0.50 | |
| 1982 | Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1983 | Symmetry Leads to Structured Constraint of Learning | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1984 | Analyzing and Mitigating Object Hallucination in Large Vision-Language Models | 6.00 | 6.25 | 1.09 | 0.25 | |
| 1985 | IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models | 5.60 | 6.00 | 1.90 | 0.40 | | 6, 6, 3, 5, 8 | | 8, 6, 3, 5, 8 |
|
| 1986 | Effective and Efficient Federated Tree Learning on Hybrid Data | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1987 | Image Translation as Diffusion Visual Programmers | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1988 | Knowledge Storage and Extraction in Language Models (Part A) | 6.40 | 6.00 | 1.90 | -0.40 | | 5, 8, 5, 6, 8 | | 3, 8, 5, 6, 8 |
|
| 1989 | Procedural Fairness Through Decoupling Objectionable Data Generating Components | 4.67 | 6.67 | 0.94 | 2.00 | |
| 1990 | Graph as Point Set | 5.75 | 6.00 | 1.22 | 0.25 | |
| 1991 | DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning | 5.25 | 6.00 | 0.00 | 0.75 | |
| 1992 | Multi-View Representation is What You Need for Point-Cloud Pre-Training | 5.75 | 6.00 | 0.00 | 0.25 | |
| 1993 | RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets | 6.00 | 6.00 | 1.41 | 0.00 | |
| 1994 | VDT: General-purpose Video Diffusion Transformers via Mask Modeling | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1995 | Augmenting transformers with recursively composed multi-grained representations | 5.50 | 6.00 | 1.22 | 0.50 | |
| 1996 | A Light-robust Reconstruction Method for Spike Camera | 6.00 | 6.00 | 1.22 | 0.00 | |
| 1997 | Learning Pseudo 3D Representation for Ego-centric 2D Multiple Object Tracking | 5.00 | 6.00 | 1.22 | 1.00 | |
| 1998 | Efficient Sharpness-Aware Minimization for Molecular Graph Transformer Models | 6.00 | 6.00 | 0.00 | 0.00 | |
| 1999 | MVSFormer++: Revealing the Devil in the Transformer's Details for Multi-View Stereo | 6.00 | 6.00 | 1.10 | 0.00 | | 6, 5, 5, 8, 6 | | 6, 5, 5, 8, 6 |
|
| 2000 | Graph Lottery Ticket Automated | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2001 | Inner Classifier-Free Guidance and Its Taylor Expansion for Diffusion Models | 4.25 | 6.00 | 1.22 | 1.75 | |
| 2002 | RoDyn-SLAM: Robust Dynamic Dense RGB-D SLAM with Neural Radiance Fields | 6.33 | 6.00 | 1.22 | -0.33 | |
| 2003 | InterpGNN: Understand and Improve Generalization Ability of Transdutive GNNs through the Lens of Interplay between Train and Test Nodes | 5.40 | 6.00 | 0.00 | 0.60 | | 5, 6, 5, 5, 6 | | 6, 6, 6, 6, 6 |
|
| 2004 | SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis | 6.00 | 6.00 | 1.22 | 0.00 | |
| 2005 | Diffusion Posterior Sampling for Linear Inverse Problem Solving: A Filtering Perspective | 6.00 | 6.00 | 2.55 | 0.00 | |
| 2006 | Causal Structure Recovery with Latent Variables under Milder Distributional and Graphical Assumptions | 5.50 | 6.00 | 1.22 | 0.50 | |
| 2007 | LLMs Represent Contextual Tasks as Compact Function Vectors | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2008 | Neural Polynomial Gabor Fields for Macro Motion Analysis | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2009 | Language Modeling Is Compression | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2010 | OpenNerf: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2011 | BatchPrompt: Accomplish more with less | 6.00 | 6.00 | 1.22 | 0.00 | |
| 2012 | ContextRef: Evaluating Referenceless Metrics for Image Description Generation | 6.00 | 6.00 | 0.00 | 0.00 | |
| 2013 | ZeroFlow: Scalable Scene Flow via Distillation | 6.00 | 6.00 | 1.41 | 0.00 | |
| 2014 | R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2015 | Translating Labels to Solve Annotation Mismatches Across Object Detection Datasets | 5.00 | 6.00 | 0.00 | 1.00 | |
| 2016 | Variational Learning of Gaussian Process Latent Variable Models through Stochastic Gradient Annealed Importance Sampling | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2017 | Online Continual Learning for Interactive Instruction Following Agents | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2018 | Get What You Want, Not What You Don't: Image Content Suppression for Text-to-Image Diffusion Models | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2019 | Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation | 5.40 | 6.00 | 1.10 | 0.60 | | 5, 3, 6, 8, 5 | | 5, 6, 6, 8, 5 |
|
| 2020 | Meta-Evolve: Continuous Robot Evolution for One-to-many Policy Transfer | 6.00 | 6.00 | 1.22 | 0.00 | |
| 2021 | VDC: Versatile Data Cleanser for Detecting Dirty Samples via Visual-Linguistic Inconsistency | 5.00 | 6.00 | 0.00 | 1.00 | |
| 2022 | Zero-Mean Regularized Spectral Contrastive Learning | 6.00 | 6.00 | 0.00 | 0.00 | |
| 2023 | Variance-enlarged Poisson Learning for Graph-based Semi-Supervised Learning with Extremely Sparse Labeled Data | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2024 | Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis | 6.00 | 6.00 | 1.22 | 0.00 | |
| 2025 | MagicDrive: Street View Generation with Diverse 3D Geometry Control | 6.00 | 6.00 | 1.22 | 0.00 | |
| 2026 | MogaNet: Multi-order Gated Aggregation Network | 5.50 | 6.50 | 0.87 | 1.00 | |
| 2027 | FedP3: Federated Personalized and Privacy-friendly Network Pruning under Model Heterogeneity | 6.00 | 6.00 | 1.73 | 0.00 | | 8, 3, 6, 5, 8 | | 8, 3, 6, 5, 8, 6 |
|
| 2028 | Large-Vocabulary 3D Diffusion Model with Transformer | 6.00 | 6.00 | 0.00 | 0.00 | |
| 2029 | SAS: Structured Activation Sparsification | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2030 | Through the Dual-Prism: A Spectral Perspective on Graph Data Augmentation for Graph Classification | 5.50 | 6.00 | 1.22 | 0.50 | |
| 2031 | 3D-Aware Hypothesis & Verification for Generalizable Relative Object Pose Estimation | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2032 | Language Model Self-improvement by Reinforcement Learning Contemplation | 5.40 | 6.00 | 1.90 | 0.60 | | 5, 6, 3, 8, 5 | | 5, 8, 3, 8, 6 |
|
| 2033 | QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models | 5.25 | 6.00 | 0.00 | 0.75 | |
| 2034 | EXPOSING TEXT-IMAGE INCONSISTENCY USING DIFFUSION MODELS | 6.00 | 6.00 | 1.22 | 0.00 | |
| 2035 | HyperSINDy: Deep Generative Modeling of Nonlinear Stochastic Governing Equations | 5.33 | 6.00 | 1.00 | 0.67 | | 5, 6, 5, 8, 5, 3 | | 6, 6, 6, 8, 5, 5 |
|
| 2036 | LASER: Linear Compression in Wireless Distributed Optimization | 6.00 | 5.83 | 1.46 | -0.17 | | 5, 6, 6, 5, 8 | | 6, 6, 6, 6, 8, 3 |
|
| 2037 | Sharpness-Aware Data Poisoning Attack | 5.50 | 5.83 | 0.37 | 0.33 | | 6, 6, 6, 6, 6, 3 | | 6, 6, 6, 6, 6, 5 |
|
| 2038 | On the Hardness of Constrained Cooperative Multi-Agent Reinforcement Learning | 5.83 | 5.83 | 0.37 | 0.00 | | 5, 6, 6, 6, 6, 6 | | 5, 6, 6, 6, 6, 6 |
|
| 2039 | Latent 3D Graph Diffusion | 5.40 | 6.17 | 0.90 | 0.77 | | 6, 5, 5, 5, 6 | | 6, 6, 6, 5, 6, 8 |
|
| 2040 | Dirichlet-based Per-Sample Weighting by Transition Matrix for Noisy Label Learning | 5.33 | 5.83 | 0.37 | 0.50 | | 5, 5, 5, 5, 6, 6 | | 6, 6, 6, 5, 6, 6 |
|
| 2041 | The Role of Representation Transfer in Multitask Imitation Learning | 5.17 | 5.83 | 1.07 | 0.67 | | 6, 6, 6, 3, 5, 5 | | 8, 6, 6, 5, 5, 5 |
|
| 2042 | KernelWarehouse: Rethinking the Design of Dynamic Convolution | 5.83 | 5.83 | 1.07 | 0.00 | | 6, 5, 5, 8, 6, 5 | | 6, 5, 5, 8, 6, 5 |
|
| 2043 | Bridging Vision and Language Spaces with Assignment Prediction | 5.80 | 5.80 | 1.17 | 0.00 | | 5, 5, 6, 5, 8 | | 5, 5, 6, 5, 8 |
|
| 2044 | GAFormer: Enhancing Timeseries Transformers Through Group-Aware Embeddings | 5.80 | 6.00 | 0.00 | 0.20 | | 6, 6, 6, 5, 6 | | 6, 6, 6, 6, 6 |
|
| 2045 | CNN Kernels Can Be the Best Shapelets | 5.40 | 5.80 | 1.17 | 0.40 | | 5, 5, 8, 6, 3 | | 5, 5, 8, 6, 5 |
|
| 2046 | Learning to design protein-protein interactions with enhanced generalization | 6.20 | 5.80 | 1.60 | -0.40 | | 6, 6, 6, 8, 5 | | 3, 6, 6, 8, 6 |
|
| 2047 | Learning from Label Proportions: Bootstrapping Supervised Learners via Belief Propagation | 5.80 | 5.80 | 1.17 | 0.00 | | 5, 6, 5, 8, 5 | | 5, 6, 5, 8, 5 |
|
| 2048 | Understanding Heterophily for Graph Neural Networks | 5.80 | 5.80 | 1.60 | 0.00 | | 6, 6, 3, 6, 8 | | 6, 6, 3, 6, 8 |
|
| 2049 | Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game | 4.40 | 5.80 | 1.17 | 1.40 | | 3, 3, 3, 5, 8 | | 5, 6, 5, 5, 8 |
|
| 2050 | Hiding in Plain Sight: Disguising Data Stealing Attacks in Federated Learning | 5.80 | 6.20 | 0.98 | 0.40 | | 3, 8, 6, 6, 6 | | 5, 8, 6, 6, 6 |
|
| 2051 | LLM-CXR: Instruction-Finetuned LLM for CXR Image Understanding and Generation | 5.40 | 5.80 | 1.60 | 0.40 | | 3, 8, 5, 5, 6 | | 3, 8, 6, 6, 6 |
|
| 2052 | On the Recoverability of Causal Relations from Temporally Aggregated I.I.D Data | 5.00 | 5.80 | 0.40 | 0.80 | | 6, 5, 3, 6, 5 | | 6, 6, 6, 6, 5 |
|
| 2053 | The Discovery of Binding Modes Requires Rethinking Docking Generalization | 5.80 | 6.00 | 1.10 | 0.20 | | 6, 5, 5, 8, 5 | | 6, 5, 5, 8, 6 |
|
| 2054 | LLMs Meet VLMs: Boost Open Vocabulary Object Detection with Fine-grained Descriptors | 5.80 | 5.80 | 0.40 | 0.00 | | 6, 6, 5, 6, 6 | | 6, 6, 5, 6, 6 |
|
| 2055 | On the Inadequacy of Similarity-based Privacy Metrics: Reconstruction Attacks against ``Truly Anonymous Synthetic Data'' | 5.20 | 6.00 | 1.90 | 0.80 | | 5, 3, 5, 5, 8 | | 5, 3, 6, 8, 8 |
|
| 2056 | Conditional Variational Diffusion Models | 5.20 | 5.80 | 1.94 | 0.60 | | 5, 8, 5, 5, 3 | | 5, 8, 8, 5, 3 |
|
| 2057 | Image Clustering via the Principle of Rate Reduction in the Age of Pretrained Models | 5.40 | 5.80 | 1.94 | 0.40 | | 5, 8, 3, 8, 3 | | 5, 8, 3, 8, 5 |
|
| 2058 | Training Socially Aligned Language Models on Simulated Social Interactions | 5.80 | 6.20 | 0.98 | 0.40 | | 6, 6, 6, 6, 5 | | 6, 8, 6, 6, 5 |
|
| 2059 | Adaptive Knowledge Transfer for Generalized Category Discovery | 5.80 | 5.80 | 1.17 | 0.00 | | 5, 5, 6, 5, 8 | | 5, 5, 6, 5, 8 |
|
| 2060 | Off-the-Grid MARL: Datasets with Baselines for Offline Multi-Agent Reinforcement Learning | 5.00 | 5.80 | 0.40 | 0.80 | |
| 2061 | Near-Optimal Solutions of Constrained Learning Problems | 5.20 | 5.80 | 1.60 | 0.60 | | 5, 6, 6, 3, 6 | | 6, 8, 6, 3, 6 |
|
| 2062 | Perfect Alignment May be Poisonous to Graph Contrastive Learning | 5.60 | 5.80 | 1.60 | 0.20 | | 3, 6, 6, 8, 5 | | 3, 6, 6, 8, 6 |
|
| 2063 | Cauchy-Schwarz Divergence Information Bottleneck for Regression | 5.20 | 5.80 | 0.40 | 0.60 | | 5, 6, 3, 6, 6 | | 6, 6, 5, 6, 6 |
|
| 2064 | Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution | 5.60 | 5.80 | 1.17 | 0.20 | | 5, 8, 5, 5, 5 | | 5, 8, 6, 5, 5 |
|
| 2065 | Temporal Generalization Estimation in Evolving Graphs | 5.80 | 5.80 | 1.17 | 0.00 | | 5, 8, 5, 5, 6 | | 5, 8, 5, 5, 6 |
|
| 2066 | The Phase Transition Phenomenon of Shuffled Regression | 5.80 | 5.80 | 1.17 | 0.00 | | 8, 5, 5, 5, 6 | | 8, 5, 5, 5, 6 |
|
| 2067 | Elucidating the design space of classifier-guided diffusion generation | 4.20 | 6.00 | 1.10 | 1.80 | | 5, 5, 3, 5, 3 | | 5, 6, 5, 6, 8 |
|
| 2068 | Multi-modal Gaussian Process Variational Autoencoders for Neural and Behavioral Data | 5.40 | 5.80 | 1.94 | 0.40 | | 8, 3, 6, 5, 5 | | 8, 3, 8, 5, 5 |
|
| 2069 | RLCD: Reinforcement Learning from Contrastive Distillation for LM Alignment | 5.20 | 5.80 | 0.40 | 0.60 | | 5, 3, 6, 6, 6 | | 6, 5, 6, 6, 6 |
|
| 2070 | Course Correcting Koopman Representations | 5.40 | 6.60 | 1.20 | 1.20 | | 3, 8, 5, 5, 6 | | 6, 8, 5, 6, 8 |
|
| 2071 | Droplets of Good Representations: Grokking as a First Order Phase Transition in Two Layer Networks | 4.60 | 5.80 | 1.60 | 1.20 | | 5, 3, 6, 6, 3 | | 6, 6, 8, 6, 3 |
|
| 2072 | Functional Wasserstein Bridge Inference for Bayesian Deep Learning | 5.80 | 5.80 | 1.60 | 0.00 | | 3, 6, 6, 6, 8 | | 3, 6, 6, 6, 8 |
|
| 2073 | LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression | 5.80 | 5.80 | 0.40 | 0.00 | | 6, 6, 6, 5, 6 | | 6, 6, 6, 5, 6 |
|
| 2074 | TRAM: Benchmarking Temporal Reasoning for Large Language Models | 5.60 | 5.80 | 1.60 | 0.20 | | 3, 6, 8, 5, 6 | | 3, 6, 8, 6, 6 |
|
| 2075 | Model-Free, Regret-Optimal Best Policy Identification in Online CMDPs | 5.80 | 5.20 | 1.17 | -0.60 | | 6, 6, 6, 6, 5 | | 6, 3, 6, 6, 5 |
|
| 2076 | BELT-2: Bootstrapping EEG-to-Language representation alignment for multi-task brain decoding | 5.00 | 5.00 | 2.28 | 0.00 | |
| 2077 | CoBIT: A Contrastive Bi-directional Image-Text Generation Model | 5.40 | 6.60 | 1.20 | 1.20 | | 6, 5, 6, 5, 5 | | 6, 5, 8, 8, 6 |
|
| 2078 | iGraphMix: Input Graph Mixup Method for Node Classification | 5.80 | 5.80 | 1.60 | 0.00 | | 6, 3, 6, 8, 6 | | 6, 3, 6, 8, 6 |
|
| 2079 | UC-NERF: Neural Radiance Field for under-calibrated multi-view cameras | 5.60 | 5.80 | 0.40 | 0.20 | | 6, 6, 5, 5, 6 | | 6, 6, 5, 6, 6 |
|
| 2080 | Octavius: Mitigating Task Interference in MLLMs via MoE | 5.80 | 6.40 | 1.36 | 0.60 | | 5, 5, 3, 8, 8 | | 5, 5, 6, 8, 8 |
|
| 2081 | Circumventing Concept Erasure Methods For Text-To-Image Generative Models | 5.80 | 5.80 | 1.60 | 0.00 | | 8, 6, 6, 3, 6 | | 8, 6, 6, 3, 6 |
|
| 2082 | DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models | 5.40 | 5.80 | 0.40 | 0.40 | | 5, 5, 5, 6, 6 | | 6, 6, 5, 6, 6 |
|
| 2083 | Distribution-Free Fair Federated Learning with Small Samples | 5.20 | 5.80 | 1.17 | 0.60 | | 5, 8, 5, 5, 3 | | 5, 8, 5, 5, 6 |
|
| 2084 | Only Pay for What Is Uncertain: Variance-Adaptive Thompson Sampling | 5.60 | 5.80 | 0.40 | 0.20 | | 6, 6, 6, 5, 5 | | 6, 6, 6, 6, 5 |
|
| 2085 | P2Seg: Pointly-supervised Segmentation via Mutual Distillation | 5.40 | 5.80 | 1.60 | 0.40 | | 3, 5, 6, 8, 5 | | 3, 6, 6, 8, 6 |
|
| 2086 | Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields | 5.80 | 5.60 | 1.20 | -0.20 | | 8, 6, 5, 5, 5 | | 8, 5, 5, 5, 5 |
|
| 2087 | Perceptual Group Tokenizer: Building Perception with Iterative Grouping | 5.40 | 6.20 | 1.47 | 0.80 | | 5, 6, 3, 5, 8 | | 5, 8, 5, 5, 8 |
|
| 2088 | Towards domain-invariant Self-Supervised Learning with Batch Styles Standardization | 5.00 | 5.80 | 0.40 | 0.80 | | 6, 5, 3, 5, 6 | | 6, 6, 5, 6, 6 |
|
| 2089 | When, Why and How Much? Adaptive Learning Rate Scheduling by Refinement | 5.80 | 5.80 | 1.17 | 0.00 | | 5, 6, 5, 5, 8 | | 5, 6, 5, 5, 8 |
|
| 2090 | Enhancing Contrastive Learning for Ordinal Regression via Ordinal Content Preserved Data Augmentation | 4.80 | 5.80 | 0.40 | 1.00 | | 3, 5, 5, 6, 5 | | 5, 6, 6, 6, 6 |
|
| 2091 | TabR: Tabular Deep Learning Meets Nearest Neighbors in 2023 | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2092 | Amplifying Training Data Exposure through Fine-Tuning with Pseudo-Labeled Memberships | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2093 | Chain-of-Symbol Prompting for Spatial Relationships in Large Language Models | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2094 | Towards Cross Domain Generalization of Hamiltonian Representation via Meta Learning | 4.25 | 5.75 | 0.43 | 1.50 | |
| 2095 | Dissecting learning and forgetting in language model finetuning | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2096 | Diffusion with Synthetic Features: Feature Imputation for Graphs with Partially Observed Features | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2097 | Fixed-Budget Best Arm Identification with Variance-Dependent Regret Bounds | 6.00 | 5.75 | 0.43 | -0.25 | |
| 2098 | Gradual Optimization Learning for Conformational Energy Minimization | 5.75 | 6.50 | 0.87 | 0.75 | |
| 2099 | Observer Uncertainty of Learning in Games from a Covariance Perspective | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2100 | Symmetric Neural-Collapse Representations with Supervised Contrastive Loss: The Impact of ReLU and Batching | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2101 | Fewer is More: Trojan Attacks on Parameter-Efficient Fine-Tuning | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2102 | A Theoretical Explanation of Deep RL Performance in Stochastic Environments | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2103 | Reinforced UI Instruction Grounding: Towards a Generic UI Task Automation API | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2104 | Knowledge-Infused Prompting: Assessing and Advancing Clinical Text Data Generation with Large Language Models | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2105 | Efficient Point Cloud Matching for 3D Geometric Shape Assembly | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2106 | Gen-Z: Generative Zero-Shot Text Classification with Contextualized Label Descriptions | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2107 | PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2108 | Structural Fairness-aware Active Learning for Graph Neural Networks | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2109 | Decoupled Actor-Critic | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2110 | From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2111 | SHINE: Shielding Backdoors in Deep Reinforcement Learning | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2112 | Can adversarial samples benefit few-shot unsupervised implicit neural shape representation learning ? | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2113 | Setting the Record Straight on Transformer Oversmoothing | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2114 | Predicting the Performance of Foundation Models via Agreement-on-the-line | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2115 | Fine-Tuning Language Models for Factuality | 4.50 | 5.75 | 0.43 | 1.25 | |
| 2116 | Demystifying Poisoning Backdoor Attacks from a Statistical Perspective | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2117 | Sufficient conditions for offline reactivation in recurrent neural networks | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2118 | Forward Learning of Graph Neural Networks | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2119 | Does CLIP’s generalization performance mainly stem from high train-test similarity? | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2120 | Linear programming using diagonal linear networks | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2121 | Scalable Normalizing Flows Enable Boltzmann Generators for Macromolecules | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2122 | OODRobustBench: benchmarking and analyzing adversarial robustness under distribution shift | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2123 | Tree Search-Based Policy Optimization under Stochastic Execution Delay | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2124 | NEFTune: Noisy Embeddings Improve Instruction Finetuning | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2125 | Neural functional a posteriori error estimates | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2126 | Defending Against Transfer Attacks From Public Models | 4.50 | 5.75 | 1.79 | 1.25 | |
| 2127 | Improved algorithm and bounds for successive projection | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2128 | A Distributional Analogue to the Successor Representation | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2129 | Understanding Hidden Context in Preference Learning: Consequences for RLHF | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2130 | Learning semilinear neural operators: A unified recursive framework for prediction and data assimilation. | 5.00 | 5.75 | 1.30 | 0.75 | |
| 2131 | Understanding Catastrophic Forgetting in Language Models via Implicit Inference | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2132 | ArtWhisperer: A Dataset for Characterizing Human-AI Interactions in Artistic Creations | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2133 | Enhancing Small Medical Learners with Privacy-preserving Contextual Prompting | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2134 | Differentiable Tree Search in Latent State Space | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2135 | Learning Delays in Spiking Neural Networks using Dilated Convolutions with Learnable Spacings | 5.00 | 5.75 | 1.79 | 0.75 | |
| 2136 | Generalist Equivariant Transformer Towards 3D Molecular Interaction Learning | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2137 | Reweighted Solutions for Weighted Low Rank Approximation | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2138 | Error Feedback Reloaded: From Quadratic to Arithmetic Mean of Smoothness Constants | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2139 | Relevance-based embeddings for efficient relevance retrieval | 6.25 | 5.75 | 0.43 | -0.50 | |
| 2140 | Lemur: Integrating Large Language Models in Automated Program Verification | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2141 | A Precise Characterization of SGD Stability Using Loss Surface Geometry | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2142 | Towards Transparent Time Series Forecasting | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2143 | Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2144 | GeoMFormer: A General Architecture for Geometric Molecular Representation Learning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 2145 | Simple mechanisms for representing, indexing and manipulating concepts | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2146 | Causal analysis of social bias in CLIP | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2147 | Understanding the Robustness of Randomized Feature Defense Against Query-Based Adversarial Attacks | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2148 | Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2149 | CoRe-GD: A Hierarchical Framework for Scalable Graph Visualization with GNNs | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2150 | Interpretable and Generalizable Graph Neural Networks via Subgraph Multilinear Extension | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2151 | Multi-Task Learning for Routing Problem with Zero-Shot Generalization | 5.00 | 5.75 | 1.79 | 0.75 | |
| 2152 | Adaptive Stochastic Gradient Algorithm for Black-box Multi-Objective Learning | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2153 | Beyond IID weights: sparse and low-rank deep Neural Networks are also Gaussian Processes | 5.50 | 6.25 | 1.09 | 0.75 | |
| 2154 | Backdoor Contrastive Learning via Bi-level Trigger Optimization | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2155 | Learning Thresholds with Latent Values and Censored Feedback | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2156 | GnnX-Bench: Unravelling the Utility of Perturbation-based GNN Explainers through In-depth Benchmarking | 5.00 | 5.75 | 1.79 | 0.75 | |
| 2157 | The Power of Minimalism in Long Sequence Time-series Forecasting | 5.00 | 5.75 | 1.79 | 0.75 | |
| 2158 | Representation Matching Information Bottleneck for Text Matching in Asymmetrical Domains | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2159 | Non-negative Contrastive Learning | 4.50 | 5.75 | 0.43 | 1.25 | |
| 2160 | Unmasking and Improving Data Credibility: A Study with Datasets for Training Harmless Language Models | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2161 | Generative Neuro-Symbolic Visual Reasoning by Growing and Reusing Modules | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2162 | Concept Bottleneck Generative Models | 4.50 | 6.00 | 0.00 | 1.50 | |
| 2163 | Lipsum-FT: Robust Fine-Tuning of Zero-Shot Models Using Random Text Guidance | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2164 | Negatively Correlated Ensemble Reinforcement Learning for Online Diverse Game Level Generation | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2165 | Achieving Sample and Computational Efficient Reinforcement Learning by Action Space Reduction via Grouping | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2166 | Learning Hierarchical Polynomials with Three-Layer Neural Networks | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2167 | Pre-training Sequence, Structure, and Surface Features for Comprehensive Protein Representation Learning | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2168 | Dynamic Demonstrations Controller for In-Context Learning | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2169 | In-context Convergence of Transformers | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2170 | A Sublinear Adversarial Training Algorithm | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2171 | Proper Laplacian Representation Learning | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2172 | HyperFields: Towards Zero-Shot Generation of NeRFs from Text | 4.75 | 5.75 | 1.30 | 1.00 | |
| 2173 | Debiasing Attention Mechanism in Transformer without Demographics | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2174 | GeRA: Label-Efficient Geometrically Regularized Alignment | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2175 | Boundary Denoising for Video Activity Localization | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2176 | Safe and Robust Watermark Injection with a Single OoD Image | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2177 | Adaptivity and Modularity for Efficient Generalization Over Task Complexity | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2178 | ($texttt{PASS}$) Visual Prompt Locates Good Structure Sparisty through a Recurent HyperNetwork | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2179 | If there is no underfitting, there is no Cold Posterior Effect | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2180 | Learning interpretable control inputs and dynamics underlying animal locomotion | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2181 | Adversarial Imitation Learning via Boosting | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2182 | Directed Graph Generation with Heat Kernels | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2183 | Does Progress On Object Recognition Benchmarks Improve Generalization on Crowdsourced, Global Data? | 5.50 | 6.25 | 1.09 | 0.75 | |
| 2184 | Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2185 | Alignment-Enhancing Parallel Code Generation for Semi-Supervised Code Translation | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2186 | Bringing robotics taxonomies to continuous domains via GPLVM on hyperbolic manifolds | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2187 | SpaFL: Communication-Efficient Federated Learning with Sparse Models and Low Computational Overhead | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2188 | Differentiable Euler Characteristic Transforms for Shape Classification | 5.75 | 6.25 | 1.09 | 0.50 | |
| 2189 | How to fix a broken confidence estimator: Evaluating post-hoc methods for selective classification with deep neural networks | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2190 | RINGER: Conformer Ensemble Generation of Macrocyclic Peptides with Sequence-Conditioned Internal Coordinate Diffusion | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2191 | Rethinking Backdoor Attacks on Dataset Distillation: A Kernel Method Perspective | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2192 | Sensitivity Sampling for Coreset-Based Data Selection | 4.50 | 5.75 | 0.43 | 1.25 | |
| 2193 | The Journey, Not the Destination: How Data Guides Diffusion Models | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2194 | Quality-Diversity through AI Feedback | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2195 | Automatic Calibration and Error Correction for Generative Large Language Models via Pareto Optimal Self-Supervision | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2196 | Solving High Frequency and Multi-Scale PDEs with Gaussian Processes | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2197 | GradSkip: Communication-Accelerated Local Gradient Methods with Better Computational Complexity | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2198 | Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2199 | Piecewise Linear Parametrization of Policies: Towards Interpretable Deep Reinforcement Learning | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2200 | Dissecting Language Models: Machine Unlearning via Selective Pruning | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2201 | Bayesian Neural Controlled Differential Equations for Treatment Effect Estimation | 5.50 | 6.50 | 0.87 | 1.00 | |
| 2202 | Theoretical Hardness and Tractability of POMDPs in RL with Partial Online State Information | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2203 | GAIA: Data-driven Zero-shot Talking Avatar Generation | 5.75 | 6.50 | 0.87 | 0.75 | |
| 2204 | Bounds on Representation-Induced Confounding Bias for Treatment Effect Estimation | 5.75 | 6.50 | 1.50 | 0.75 | |
| 2205 | Convolutional Deep Kernel Machines | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2206 | Diffusion Models for Tabular Data Imputation and Synthetic Data Generation | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2207 | CodeIt: Abstract Reasoning with Iterative Policy-Guided Program Synthesis | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2208 | AttributionLab: Faithfulness of Feature Attribution Under Controllable Environments | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2209 | Unraveling the Key Components of OOD Generalization via Diversification | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2210 | Analytic DAG Constraints for Differentiable DAG Learning | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2211 | LDINet: Latent Decomposition and Interpolation for Single Image FMO Deblatting | 5.75 | 5.50 | 1.80 | -0.25 | |
| 2212 | Toward effective protection against diffusion-based mimicry through score distillation | 4.25 | 5.75 | 0.43 | 1.50 | |
| 2213 | Tree-based Action-Manipulation Attack Against Continuous Reinforcement Learning with Provably Efficient Support | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2214 | Stochastic Subgoal Representation for Hierarchical Reinforcement Learning | 4.75 | 5.75 | 2.86 | 1.00 | |
| 2215 | Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2216 | Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2217 | A Multi-Level Framework for Accelerating Training Transformer Models | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2218 | Bandits with Replenishable Knapsacks: the Best of both Worlds | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2219 | Towards Cheaper Inference in Deep Networks with Lower Bit-Width Accumulators | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2220 | Towards 3D Molecule-Text Interpretation in Language Models | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2221 | AttEXplore: Attribution for Explanation with model parameters eXploration | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2222 | Win-Win: Training High-Resolution Vision Transformers from Two Windows | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2223 | Generative Learning for Solving Non-Convex Problem with Multi-Valued Input-Solution Mapping | 5.50 | 6.25 | 2.05 | 0.75 | |
| 2224 | Uncertainty-aware Constraint Inference in Inverse Constrained Reinforcement Learning | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2225 | Scalable and Effective Implicit Graph Neural Networks on Large Graphs | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2226 | $sigma$-zero: Gradient-based Optimization of $ell_0$-norm Adversarial Examples | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2227 | On the Posterior Distribution in Denoising: Application to Uncertainty Quantification | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2228 | Federated Optimization Algorithms with Random Reshuffling and Gradient Compression | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2229 | Efficient Transfer Learning in Diffusion Models via Adversarial Noise | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2230 | MissDiff: Training Diffusion Models on Tabular Data with Missing Values | 6.25 | 5.75 | 0.43 | -0.50 | |
| 2231 | Advancing Test-Time Adaptation for Acoustic Foundation Models in Open-World Shifts | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2232 | Making Pre-trained Language Models Great on Tabular Prediction | 5.25 | 7.00 | 1.00 | 1.75 | |
| 2233 | SSCBench: Monocular 3D Semantic Scene Completion Benchmark in Street Views | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2234 | AmortizedPeriod: Attention-based Amortized Inference for Periodicity Identification | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2235 | Large Language Models as Generalizable Policies for Embodied Tasks | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2236 | InfoNet: An Efficient Feed-Forward Neural Estimator for Mutual Information | 5.00 | 5.75 | 1.79 | 0.75 | |
| 2237 | Multiscale Positive-Unlabeled Detection of AI-Generated Texts | 5.75 | 6.50 | 0.87 | 0.75 | |
| 2238 | Boosting the Adversarial Robustness of Graph Neural Networks: An OOD Perspective | 4.75 | 5.75 | 1.79 | 1.00 | |
| 2239 | DQ-LoRe: Dual Queries with Low Rank Approximation Re-ranking for In-Context Learning | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2240 | DeepDRK: Deep Dependency Regularized Knockoff for Feature Selection | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2241 | Towards Out-of-federation Generalization in Federated Learning | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2242 | CO-MOT: Boosting End-to-end Transformer-based Multi-Object Tracking via Coopetition Label Assignment and Shadow Sets | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2243 | SpikePoint: An Efficient Point-based Spiking Neural Network for Event Cameras Action Recognition | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2244 | DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment | 5.50 | 6.25 | 1.09 | 0.75 | |
| 2245 | Enhancing Parameter Efficiency in Summarization via Expertise Separation | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2246 | Large Language Models as Analogical Reasoners | 6.00 | 5.75 | 1.30 | -0.25 | |
| 2247 | UniAdapter: Unified Parameter-Efficient Transfer Learning for Cross-modal Modeling | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2248 | NeuralFuse: Learning to Recover the Accuracy of Access-Limited Neural Network Inference in Low-Voltage Regimes | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2249 | Don't Judge by the Look: A Motion Coherent Augmentation for Video Recognition | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2250 | Geometrically Aligned Transfer Encoder for Inductive Transfer in Regression Tasks | 4.50 | 6.25 | 1.09 | 1.75 | |
| 2251 | LayerNAS: Neural Architecture Search in Polynomial Complexity | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2252 | Trainable Transformer in Transformer | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2253 | Improving Intrinsic Exploration by Creating Stationary Objectives | 4.50 | 5.75 | 1.30 | 1.25 | |
| 2254 | Fisher Information Guided Backdoor Purification Via Naive Exploitation of Smoothness | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2255 | LLark: A Multimodal Foundation Model for Music | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2256 | Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2257 | Generative Human Motion Stylization in Latent Space | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2258 | Learning Personalized Story Evaluation | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2259 | Training-free Deep Concept Injection Enables Language Models for Crossmodal Tasks | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2260 | JoMA: Demystifying Multilayer Transformers via Joint Dynamics of MLP and Attention | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2261 | LabelDP-Pro: Learning with Label Differential Privacy via Projections | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2262 | AUC-CL: A Batchsize-Robust Framework for Self-Supervised Contrastive Representation Learning | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2263 | Maestro: Uncovering Low-Rank Structures via Trainable Decomposition | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2264 | Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2265 | Text-driven Prompt Generation for Vision-Language Models in Federated Learning | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2266 | DiffusionNAG: Predictor-guided Neural Architecture Generation with Diffusion Models | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2267 | Language Control Diffusion: Efficiently Scaling through Space, Time, and Tasks | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2268 | Learning Multiplex Embeddings on Text-rich Networks with One Text Encoder | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2269 | CCIL: Continuity-Based Data Augmentation for Corrective Imitation Learning | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2270 | Robustness Guarantees for Adversarial Training on Non-Separable Data | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2271 | Microenvironment Probability Flows as Proficient Protein Engineers | 5.75 | 5.25 | 0.43 | -0.50 | |
| 2272 | Shape-aware Graph Spectral Learning | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2273 | Differentially Private SGD Without Clipping Bias: An Error-Feedback Approach | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2274 | Model Merging by Uncertainty-Based Gradient Matching | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2275 | The Reasonableness Behind Unreasonable Translation Capability of Large Language Model | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2276 | RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2277 | CODE REPRESENTATION LEARNING AT SCALE | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2278 | Relaxing the Additivity Constraints in Decentralized No-Regret High-Dimensional Bayesian Optimization | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2279 | Capture Concept through Comparison: Vision-and-Language Representation Learning with Intrinsic Information Mining | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2280 | Discovering modular solutions that generalize compositionally | 4.75 | 6.50 | 0.87 | 1.75 | |
| 2281 | A 2-Dimensional State Space Layer for Spatial Inductive Bias | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2282 | CAMBranch: Contrastive Learning with Augmented MILPs for Branching | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2283 | Counterfactual Density Estimation using Kernel Stein Discrepancies | 5.50 | 6.25 | 1.09 | 0.75 | |
| 2284 | Unknown Domain Inconsistency Minimization for Domain Generalization | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2285 | True Knowledge Comes from Practice: Aligning Large Language Models with Embodied Environments via Reinforcement Learning | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2286 | Informed POMDP: Leveraging Additional Information in Model-Based RL | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2287 | Improved Operator Learning by Orthogonal Attention | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2288 | Learning Large DAGs is Harder than you Think: Many Losses are Minimal for the Wrong DAG | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2289 | SPI-GAN: Denoising Diffusion GANs with Straight-Path Interpolations | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2290 | Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2291 | Continual Contrastive Spoken Language Understanding | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2292 | A Bias-Variance-Covariance Decomposition of Kernel Scores for Generative Models | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2293 | Improving Natural Language Understanding with Computation-Efficient Retrieval Augmentation | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2294 | FedCDA: Federated Learning with Cross-rounds Divergence-aware Aggregation | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2295 | A Unified Framework for Reinforcement Learning under Policy and Dynamic Shifts | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2296 | TransNormerLLM: A Faster and Better Large Language Model with Improved TransNormer | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2297 | Addressing Signal Delay in Deep Reinforcement Learning | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2298 | On the Optimality of Activations in Implicit Neural Representations | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2299 | CogVLM: Visual Expert for Large Language Models | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2300 | DreamTime: An Improved Optimization Strategy for Diffusion-Guided 3D Generation | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2301 | CARD: Channel Aligned Robust Blend Transformer for Time Series Forecasting | 5.25 | 6.25 | 1.09 | 1.00 | |
| 2302 | ScaLearn: Simple and Highly Parameter-Efficient Task Transfer by Learning to Scale | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2303 | Domain Generalization via Content Factors Isolation: A Two-level Latent Variable Modeling Approach | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2304 | TABLEYE: SEEING SMALL TABLES THROUGH THE LENS OF IMAGES | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2305 | Correlated Attention in Transformers for Multivariate Time Series | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2306 | Bayesian Offline-to-Online Reinforcement Learning : A Realist Approach | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2307 | Self-supervised Pocket Pretraining via Protein Fragment-Surroundings Alignment | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2308 | MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2309 | Mitigating Simplicity Bias in Deep Learning for Improved OOD Generalization and Robustness | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2310 | Generative Pre-training for Speech with Flow Matching | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2311 | Neural Probabilistic Protein-Protein Docking via a Differentiable Energy Model | 4.75 | 5.75 | 1.79 | 1.00 | |
| 2312 | Rethinking Adversarial Robustness in the Context of the Right to be Forgotten | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2313 | Parameter-Efficient Detoxification with Contrastive Decoding | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2314 | Attribute Recognition with Image-Conditioned Prefix Language Modeling | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2315 | Distributional off-policy evaluation with Bellman residual minimization | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2316 | Dropout-Based Rashomon Set Exploration for Efficient Predictive Multiplicity Estimation | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2317 | Effective Structural Encodings via Local Curvature Profiles | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2318 | Towards Zero Memory Footprint Spiking Neural Network Training | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2319 | MUBen: Benchmarking the Uncertainty of Molecular Representation Models | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2320 | Learning to Plan and Generate Text with Citations | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2321 | Foundation Reinforcement Learning: towards Embodied Generalist Agents with Foundation Prior Assistance | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2322 | Factored-NeuS: Reconstructing Surfaces, Illumination, and Materials of Possibly Glossy Objects | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2323 | Compositional Preference Models for Aligning LMs | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2324 | Vision-based Discovery of Nonlinear Dynamics for 3D Moving Target | 6.00 | 5.75 | 1.30 | -0.25 | |
| 2325 | Fast Inverse Rendering by Unified Voxelization of Scene Representation | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2326 | NIR-Assisted Image Denoising: A Selective Fusion Approach and A Real-World Benchmark Dataset | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2327 | In-Context Learning Learns Label Relationships but Is Not Conventional Learning | 5.50 | 6.50 | 0.87 | 1.00 | |
| 2328 | Implicit Neural Representation Inference for Low-Dimensional Bayesian Deep Learning | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2329 | Going Beyond Neural Network Feature Similarity: The Network Feature Complexity and Its Interpretation Using Category Theory | 5.00 | 5.75 | 1.79 | 0.75 | |
| 2330 | Data geometry and topology dependent bounds on network widths in deep ReLU networks | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2331 | Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2332 | Discovering Logic-Informed Intrinsic Rewards to Explain Human Policies | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2333 | Hybrid Kernel Stein Variational Gradient Descent | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2334 | Deep graph kernel point processes | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2335 | On the Over-Memorization During Natural, Robust and Catastrophic Overfitting | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2336 | TextGenSHAP: Scalable Post-hoc Explanations in Text Generation with Long Documents | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2337 | Local Graph Clustering with Noisy Labels | 6.67 | 5.75 | 1.79 | -0.92 | |
| 2338 | Principled Federated Domain Adaptation: Gradient Projection and Auto-Weighting | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2339 | Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2340 | Continual Learning on a Diet: Learning from Sparsely Labeled Streams Under Constrained Computation | 5.75 | 6.75 | 1.30 | 1.00 | |
| 2341 | Momentum Particle Maximum Likelihood | 5.00 | 5.75 | 1.30 | 0.75 | |
| 2342 | Video Decomposition Prior: Editing Videos Layer by Layer | 4.50 | 5.75 | 0.43 | 1.25 | |
| 2343 | Binary Hyperbolic Embeddings | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2344 | CIM: Constrained Intrinsic Motivation for Reinforcement Learning | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2345 | Skill-Conditioned Policy Optimization with Successor Features Representations | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2346 | Generative Adversarial Policy Network for Modelling Protein Complexes | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2347 | EMO: EARTH MOVER DISTANCE OPTIMIZATION FOR AUTO-REGRESSIVE LANGUAGE MODELING | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2348 | DreamSmooth: Improving Model-based Reinforcement Learning via Reward Smoothing | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2349 | ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2350 | P2P: Transforming from Point Supervision to Explicit Visual Prompt for Object Detection and Segmentation | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2351 | NECO: NEural Collapse Based Out-of-distribution detection | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2352 | Sin3DM: Learning a Diffusion Model from a Single 3D Textured Shape | 5.75 | 6.00 | 1.22 | 0.25 | |
| 2353 | On the Implicit Bias of Adam | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2354 | Equivariant Graph Network Approximations of High-Degree Polynomials for Force Field Prediction | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2355 | NOLA: Networks as Linear Combination of Low Rank Random Basis | 5.75 | 6.00 | 0.00 | 0.25 | |
| 2356 | Visual Prompting Reimagined: The Power of Activation Prompts | 5.25 | 5.75 | 1.30 | 0.50 | |
| 2357 | Adversarial Causal Bayesian Optimization | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2358 | Editing Personality for Large Language Models | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2359 | ProFITi: Probabilistic Forecasting of Irregular Time Series via Conditional Flows | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2360 | MindGPT: Interpreting What You See with Non-invasive Brain Recordings | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2361 | Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2362 | Symmetric Basis Convolutions for Learning Lagrangian Fluid Mechanics | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2363 | An Image is Worth Multiple Words: Learning Object Level Concepts using Multi-Concepts Prompts Learning | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2364 | BOWLL: A DECEPTIVELY SIMPLE OPEN WORLD LIFELONG LEARNER | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2365 | Purify Perturbative Availability Poisons via Rate-Constrained Variational Autoencoders | 4.50 | 5.75 | 1.30 | 1.25 | |
| 2366 | Generalizing to New Dynamical Systems via Frequency Domain Adaptation | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2367 | ZipIt! Merging Models from Different Tasks without Training | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2368 | The Effects of Overparameterization on Sharpness-aware Minimization: An Empirical and Theoretical Analysis | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2369 | Lyra: Orchestrating Dual Correction in Automated Theorem Proving | 5.00 | 6.00 | 0.00 | 1.00 | |
| 2370 | Enhancing Human-AI Collaboration Through Logic-Guided Reasoning | 5.75 | 6.25 | 1.09 | 0.50 | |
| 2371 | Learning with Mixture of Prototypes for Out-of-Distribution Detection | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2372 | IMPUS: Image Morphing with Perceptually-Uniform Sampling Using Diffusion Models | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2373 | Adaptive Instrument Design for Indirect Experiments | 5.75 | 6.50 | 0.87 | 0.75 | |
| 2374 | IPR-NeRF: Ownership Verification Meets Neural Radiance Field | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2375 | Understanding Convergence and Generalization in Federated Learning through Feature Learning Theory | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2376 | Rethinking CNN’s Generalization to Backdoor Attack from Frequency Domain | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2377 | CosPGD: an efficient white-box adversarial attack for pixel-wise prediction tasks | 4.75 | 5.75 | 1.30 | 1.00 | |
| 2378 | Scale-Adaptive Diffusion Model for Complex Sketch Synthesis | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2379 | LeCO-NeRF: Learning Compact Occupancy for Large-scale Neural Radiance Fields | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2380 | Key-Graph Transformer for Image Restoration | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2381 | ADDP: Learning General Representations for Image Recognition and Generation with Alternating Denoising Diffusion Process | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2382 | SqueezeLLM: Dense and Sparse Quantization | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2383 | LMUFormer: Low Complexity Yet Powerful Spiking Model With Legendre Memory Units | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2384 | Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2385 | Matrix Information Theory for Self-Supervised Learning | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2386 | FasterViT: Fast Vision Transformers with Hierarchical Attention | 5.75 | 5.75 | 0.43 | 0.00 | |
| 2387 | Learning the greatest common divisor: explaining transformer predictions | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2388 | Clearer Frames, Anytime: Resolving Velocity Ambiguity in Video Frame Interpolation | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2389 | Consistency-guided Prompt Learning for Vision-Language Models | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2390 | MM-LDM: Multi-Modal Latent Diffusion Model for Sounding Video Generation | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2391 | Think Before You Act: Decision Transformers with Internal Memory | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2392 | SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2393 | Towards Faster and Stronger Deep Earth Mover's Distance for Few-Shot Learning | 5.67 | 5.75 | 0.43 | 0.08 | |
| 2394 | ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2395 | Pure Message Passing Can Estimate Common Neighbor for Link Prediction | 5.75 | 5.75 | 1.30 | 0.00 | |
| 2396 | Efficient Fully Single-Loop Variance Reduced Methods for Stochastic Bilevel Optimization | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2397 | PROTO: Iterative Policy Regularizied Offline-to-Online Reinforcement Learning | 5.75 | 5.75 | 1.79 | 0.00 | |
| 2398 | Towards Offline Opponent Modeling with In-context Learning | 4.25 | 5.75 | 0.43 | 1.50 | |
| 2399 | Early Stopping Against Label Noise Without Validation Data | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2400 | S$2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic | 5.71 | 5.71 | 1.39 | 0.00 | | 5, 6, 6, 8, 6, 6, 3 | | 5, 6, 6, 8, 6, 6, 3 |
|
| 2401 | Ask Again, Then Fail: Large Language Models’ Vacillations in Judgement | 6.00 | 5.67 | 0.47 | -0.33 | |
| 2402 | Enhancing Neural Subset Selection: Integrating Background Information into Set Representations | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2403 | ReLiK: Retrieve, Read and LinK: Fast and Accurate Entity Linking and Relation Extraction on an Academic Budget | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2404 | What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning | 4.67 | 6.33 | 1.25 | 1.67 | |
| 2405 | NeFL: Nested Federated Learning for Heterogeneous Clients | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2406 | Learning Predictive Checklists with Probabilistic Logic Programming | 4.67 | 5.67 | 2.05 | 1.00 | |
| 2407 | Few Heads are Enough | 4.00 | 5.67 | 0.47 | 1.67 | |
| 2408 | Learning to Reject with a Fixed Predictor: Application to Decontextualization | 4.33 | 6.00 | 0.00 | 1.67 | |
| 2409 | From Random to Relevant: Harnessing Salient Masks in Non-IID Federated Learning | 5.00 | 5.67 | 2.05 | 0.67 | |
| 2410 | MedJourney: Counterfactual Medical Image Generation by Instruction-Learning from Multimodal Patient Journeys | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2411 | Stochastic interpolants with data-dependent couplings | 4.33 | 5.67 | 0.47 | 1.33 | |
| 2412 | What happens when you fine-tuning your model? Mechanistic analysis of procedurally generated tasks. | 4.33 | 6.67 | 0.94 | 2.33 | |
| 2413 | Harnessing Explanations: LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2414 | NP-GL: Extending Power of Nature from Binary Problems to Real-World Graph Learning | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2415 | Posterior Sampling via Langevin Monte Carlo for Offline Reinforcement Learning | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2416 | From Deterministic to Probabilistic World: Balancing Enhanced Doubly Robust Learning for Debiased Recommendation | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2417 | Towards Better Evaluation of GNN Expressiveness with BREC Dataset | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2418 | Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking | 5.67 | 6.00 | 0.00 | 0.33 | |
| 2419 | Enhancing Instance-Level Image Classification with Set-Level Labels | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2420 | Enhancing Neural Network Transparency through Representation Analysis | 4.00 | 5.67 | 0.47 | 1.67 | |
| 2421 | Discrimination-free Pricing with Privatized Sensitive Attributes | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2422 | Understanding and Robustifying Sub-domain Alignment for Domain Adaptation | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2423 | Explaining the Out-of-Distribution Detection Paradox through Likelihood Peaks | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2424 | Group Preference Optimization: Few-Shot Alignment of Large Language Models | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2425 | Risk Bounds of Accelerated SGD for Overparameterized Linear Regression | 5.67 | 6.00 | 0.00 | 0.33 | |
| 2426 | Differentiable Learning of Generalized Structured Matrices for Efficient Deep Neural Networks | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2427 | Ito Diffusion Approximation of Universal Ito Chains for Sampling, Optimization and Boosting | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2428 | MemStranding: Adversarial attacks on temporal graph neural networks | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2429 | Disentangling Time Series Representations via Contrastive based $l$-Variational Inference | 5.67 | 5.67 | 3.30 | 0.00 | |
| 2430 | Biological Sequence Editing with Generative Flow Networks | 4.33 | 5.67 | 0.47 | 1.33 | |
| 2431 | Implicit regularization of multi-task learning and finetuning in overparameterized neural networks | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2432 | Novel Quadratic Constraints for Extending LipSDP beyond Slope-Restricted Activations | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2433 | Learning the Hidden Set Locally | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2434 | Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain | 5.67 | 6.00 | 0.00 | 0.33 | |
| 2435 | AST-T5: Structure-Aware Pretraining for Code Generation and Understanding | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2436 | Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2437 | Bayesian Exploration Networks | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2438 | CoLiDE: Concomitant Linear DAG Estimation | 4.67 | 5.67 | 2.05 | 1.00 | |
| 2439 | GDL-DS: A Benchmark for Geometric Deep Learning under Distribution Shifts | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2440 | Object-level Data Augmentation for Visual 3D Object Detection in Autonomous Driving | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2441 | Unlocking the Transferability of Tokens in Deep Models for Tabular Data | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2442 | ASMR: Activation-Sharing Multi-Resolution Coordinate Networks for Efficient Inference | 5.33 | 6.33 | 1.25 | 1.00 | |
| 2443 | Compositional Conservatism: A Transductive Approach in Offline Reinforcement Learning | 5.67 | 6.33 | 1.25 | 0.67 | |
| 2444 | A Unified Causal View of Instruction Tuning | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2445 | PaLI-3 Vision Language Models: Smaller, Faster, Stronger | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2446 | Provably Efficient Iterated CVaR Reinforcement Learning with Function Approximation and Human Feedback | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2447 | Visual Transformer with Differentiable Channel Selection: An Information Bottleneck Inspired Approach | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2448 | Correlated Noise Provably Beats Independent Noise for Differentially Private Learning | 4.33 | 5.67 | 3.30 | 1.33 | |
| 2449 | Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding | 5.33 | 5.67 | 1.49 | 0.33 | | 6, 6, 6, 6, 5, 3 | | 6, 6, 6, 8, 5, 3 |
|
| 2450 | URLOST: Unsupervised Representation Learning without Stationarity or Topology | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2451 | Adapt On-the-Go: Behavior Modulation for Single-Life Robot Deployment | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2452 | Stochastic Unrolled Federated Learning | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2453 | Conversational Drug Editing Using Retrieval and Domain Feedback | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2454 | Encodings for Prediction-based Neural Architecture Search | 5.33 | 5.67 | 2.05 | 0.33 | |
| 2455 | Training Bayesian Neural Networks with Sparse Subspace Variational Inference | 4.67 | 6.67 | 0.94 | 2.00 | |
| 2456 | Enhancing Compositional Generalization via Compositional Feature Alignment | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2457 | Confidence-driven Sampling for Backdoor Attacks | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2458 | OVOR: OnePrompt with Virtual Outlier Regularization for Rehearsal-Free Class-Incremental Learning | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2459 | Benign Overfitting and Grokking in ReLU Networks for XOR Cluster Data | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2460 | High-Dimensional Geometric Streaming for Nearly Low Rank Data | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2461 | Topological Expressive Power of ReLU Neural Networks | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2462 | Bridging the Gap between Binary Neural Networks and Spiking Neural Networks for Efficient Computer Vision | 4.33 | 5.67 | 0.47 | 1.33 | |
| 2463 | Pi-DUAL: Using privileged information to distinguish clean from noisy labels | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2464 | Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2465 | Understanding the Effects of RLHF on LLM Generalisation and Diversity | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2466 | Probabilistic Self-supervised Representation Learning via Scoring Rules Minimization | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2467 | Sparse Cocktail: Every Sparse Pattern Every Sparse Ratio All At Once | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2468 | Enhancing the Cross-Size Generalization for Solving Vehicle Routing Problems via Continual Learning | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2469 | Understanding Parameter Saliency via Extreme Value Theory | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2470 | Prioritized Soft Q-Decomposition for Lexicographic Reinforcement Learning | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2471 | Fine-Tuned Language Models Generate Stable Inorganic Materials as Text | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2472 | SCALE: Synergized Collaboration of Asymmetric Language Translation Engines | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2473 | How the Level Sampling Process impacts Zero-Shot Generalisation in Deep Reinforcement Learning | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2474 | UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition | 5.33 | 5.67 | 2.05 | 0.33 | |
| 2475 | Retrieval-augmented Vision-Language Representation for Fine-grained Recognition | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2476 | Learning Optimal Contracts: How to Exploit Small Action Spaces | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2477 | Continual Supervised Anomaly Detection | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2478 | FL-GNN: A Fuzzy-logic Graph Neural Network | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2479 | MAPE-PPI: Towards Effective and Efficient Protein-Protein Interaction Prediction via Microenvironment-Aware Protein Embedding | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2480 | RGLA: Reverse Gradient Leakage Attack using Inverted Cross-Entropy Loss Function | 4.67 | 5.67 | 2.05 | 1.00 | |
| 2481 | Enhancing One-Shot Pruned Generative Pre-training Language Models through Sparse-Dense-Sparse Mechanism | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2482 | The Need for Speed: Pruning Transformers with One Recipe | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2483 | Efficient Action Robust Reinforcement Learning with Probabilistic Policy Execution Uncertainty | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2484 | Towards Imitation Learning to Branch for MIP: A Hybrid Reinforcement Learning based Sample Augmentation Approach | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2485 | Modulated Phase Diffusor: Content-Oriented Feature Synthesis for Detecting Unknown Objects | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2486 | Exact Mean Square Linear Stability Analysis for SGD | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2487 | Refining Corpora from a Model Calibration Perspective for Chinese Spelling Correction | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2488 | Adversarial Training on Purification (AToP): Advancing Both Robustness and Generalization | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2489 | FFCA-Net: Stereo Image Compression via Fast Cascade Alignment of Side Information | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2490 | Adaptive Window Pruning for Efficient Local Motion Deblurring | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2491 | What If You Were Not There? Learning Causally-Aware Representations of Multi-Agent Interactions | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2492 | Resolving Knowledge Conflicts in Large Language Models | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2493 | Posterior Probability-Based Label Recovery Attack in Federated Learning | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2494 | SiT: Symmetry-invariant Transformers for Generalisation in Reinforcement Learning | 4.67 | 5.67 | 2.05 | 1.00 | |
| 2495 | Conditional Support Alignment for Domain Adaptation with Label Shift | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2496 | LRR: Language-Driven Resamplable Continuous Representation against Adversarial Tracking Attacks | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2497 | UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2498 | Multi-Agent Interpolated Policy Gradients | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2499 | Neural Common Neighbor with Completion for Link Prediction | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2500 | COCO-Periph: Bridging the Gap Between Human and Machine Perception in the Periphery | 4.00 | 5.67 | 2.05 | 1.67 | |
| 2501 | DATS: Difficulty-Aware Task Sampler for Meta-Learning Physics-Informed Neural Networks | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2502 | Delving into LLMs’ visual understanding ability using SVG to bridge image and text | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2503 | Learning with Language-Guided State Abstractions | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2504 | Interpreting and improving diffusion models using the Euclidean distance function | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2505 | SiBBlInGS: Similarity-driven Building Block Inference using Graphs across States | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2506 | MSA Generation with Seqs2Seqs Pretraining: Advancing Protein Structure Predictions | 3.67 | 5.67 | 0.47 | 2.00 | |
| 2507 | Harnessing the Power of Large Language Models for Natural Language to First-Order Logic Translation | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2508 | InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models | 5.33 | 5.67 | 2.05 | 0.33 | |
| 2509 | GInX-Eval: Towards In-Distribution Evaluation of Graph Neural Networks Explanations | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2510 | Internal-Coordinate Density Modelling of Protein Structure: Covariance Matters | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2511 | CustomNet: Zero-shot Object Customization with Variable-Viewpoints in Text-to-Image Diffusion Models | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2512 | Causal Fairness under Unobserved Confounding: A Neural Sensitivity Framework | 4.50 | 5.67 | 0.47 | 1.17 | |
| 2513 | Does Writing with Language Models Reduce Content Diversity? | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2514 | Flat Minima in Linear Estimation and an Extended Gauss Markov Theorem | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2515 | DualAug: Exploiting Additional Heavy Augmentation with OOD Data Rejection | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2516 | DeepSPF: Spherical SO(3)-Equivariant Patches for Scan-to-CAD Estimation | 5.00 | 6.33 | 1.25 | 1.33 | |
| 2517 | Multimodal Distillation of Protein Sequence, Structure, and Function | 4.33 | 5.67 | 0.47 | 1.33 | |
| 2518 | An Inexact Regularized Adaptive Algorithm with Manifold Identification for Training Structured Neural Networks | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2519 | Distribution Aware Active Learning via Gaussian Mixtures | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2520 | Generative Modeling on Manifolds Through Mixture of Riemannian Diffusion Processes | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2521 | Protein-ligand binding representation learning from fine-grained interactions | 4.33 | 5.67 | 0.47 | 1.33 | |
| 2522 | Rayleigh Quotient Graph Neural Networks for Graph-level Anomaly Detection | 4.67 | 6.00 | 0.00 | 1.33 | |
| 2523 | MG-TSD: Multi-Granularity Time Series Diffusion Models with Guided Learning Process | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2524 | Understanding Inter-Session Intentions via Complex Logical Reasoning | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2525 | Trustless Audits without Revealing Data or Models | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2526 | Towards the Characterization of Representations Learned via Capsule-based Network Architectures | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2527 | The Joint Effect of Task Similarity and Overparameterization on Catastrophic Forgetting - An Analytical Model | 5.17 | 5.67 | 2.05 | 0.50 | | 3, 8, 6, 6, 3, 5 | | 3, 8, 8, 6, 3, 6 |
|
| 2528 | Efficient local linearity regularization to overcome catastrophic overfitting | 4.33 | 5.67 | 0.47 | 1.33 | |
| 2529 | Cultural and Linguistic Diversity Improves Visual Representations | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2530 | LUMEN-PRO: Automating Multi-Task Learning on Optical Neural Networks with Weight Sharing and Physical Rotation | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2531 | Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2532 | Model Selection of Anomaly Detectors in the Absence of Labeled Validation Data | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2533 | Alpagasus: Training a Better Alpaca Model with Fewer Data | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2534 | RIME: Robust Preference-based Reinforcement Learning with Noisy Human Preferences | 4.67 | 5.67 | 2.05 | 1.00 | |
| 2535 | Self-Tuning Self-Supervised Anomaly Detection | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2536 | Open-Source Can Be Dangerous: On the Vulnerability of Value Alignment in Open-Source LLMs | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2537 | Learning to Compute Gröbner Bases | 5.00 | 5.67 | 2.05 | 0.67 | |
| 2538 | Learning to Intervene on Concept Bottlenecks | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2539 | Can Agent Learn Robust Locomotion Skills without Modeling Environmental Observation Noise? | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2540 | R-MAE: Regions Meet Masked Autoencoders | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2541 | Textbooks Are All You Need | 5.67 | 6.00 | 1.00 | 0.33 | | 6, 6, 6, 5, 6, 5 | | 6, 6, 6, 5, 8, 5 |
|
| 2542 | Musketeer: Joint Training/Inference for Multi-task Vision-Language Model with Task Explanation Prompts | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2543 | On Stationary Point Convergence of PPO-Clip | 5.00 | 5.67 | 2.05 | 0.67 | |
| 2544 | FABRIC: Personalizing Diffusion Models with Iterative Feedback | 6.33 | 5.67 | 0.47 | -0.67 | |
| 2545 | Statistical Rejection Sampling Improves Preference Optimization | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2546 | On the generalization capacity of neural networks during generic multimodal reasoning | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2547 | Active Procedure Planning with Uncertainty-awareness in Instructional Videos | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2548 | Biased Temporal Convolution Graph Network for Time Series Forecasting with Missing Values. | 5.67 | 6.00 | 0.00 | 0.33 | |
| 2549 | Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight Quantization of Large Language Models | 4.33 | 6.00 | 0.00 | 1.67 | |
| 2550 | Feature Accompaniment: Is It Feasible to Learn Out-of-Distribution Generalizable Representations with In-Distribution Data? | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2551 | Learning Label Shift Correction for Test-Agnostic Long-Tailed Recognition | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2552 | Debiasing Algorithm through Model Adaptation | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2553 | Learning without Forgetting for Vision-Language Models | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2554 | From generalization analysis to optimization designs for state space models | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2555 | A Stochastic Centering Framework for Improving Calibration in Graph Neural Networks | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2556 | Towards Understanding the Effect of Pretraining Label Granularity | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2557 | Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization | 5.00 | 5.67 | 2.05 | 0.67 | |
| 2558 | Stabilizing Policy Gradients for Stochastic Differential Equations by enforcing Consistency with Perturbation Process | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2559 | Democratizing LLMs for Low-Resource Languages by Leveraging their English Dominant Abilities with Linguistically-Diverse Prompts | 4.67 | 5.67 | 0.47 | 1.00 | |
| 2560 | SelfEval: Leveraging the discriminative nature of generative models for evaluation | 5.00 | 5.67 | 0.47 | 0.67 | |
| 2561 | Hyperbolic Visual-Semantic Alignment for Structural Visual Recognition | 5.50 | 5.67 | 0.47 | 0.17 | |
| 2562 | REVISITING LARS FOR LARGE BATCH TRAINING GENERALIZATION OF NEURAL NETWORKS | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2563 | Modelling complex vector drawings with stroke-clouds | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2564 | Pre-training with Synthetic Data Helps Offline Reinforcement Learning | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2565 | Federated Learning Empowered by Generative Content | 3.67 | 5.67 | 2.05 | 2.00 | |
| 2566 | StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2567 | Unlocking the Potential of Knowledge Distillation: The Role of Teacher Calibration | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2568 | Latent Space Symmetry Discovery | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2569 | Empowering Active Learning for 3D Molecular Graphs with Geometric Graph Isomorphism | 5.33 | 6.00 | 0.00 | 0.67 | |
| 2570 | Knowledge Manipulation in Language Models (Part B) | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2571 | TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting | 5.33 | 5.67 | 2.05 | 0.33 | |
| 2572 | Rep-Adapter: Parameter-free Automatic Adaptation of Pre-trained ConvNets via Re-parameterization | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2573 | Scaling Sentence Embeddings with Large Language Models | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2574 | Score Propagation as a Catalyst for Graph Out-of-distribution Detection: A Theoretical and Empirical Study | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2575 | AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval | 4.33 | 5.67 | 2.05 | 1.33 | |
| 2576 | Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2577 | Tractable Probabilistic Graph Representation Learning with Graph-Induced Sum-Product Networks | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2578 | Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2579 | Encoding Expert Knowledge into Federated Learning using Weak Supervision | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2580 | DFormer: Rethinking RGBD Representation Learning for Semantic Segmentation | 4.67 | 5.67 | 2.05 | 1.00 | |
| 2581 | Contraction and Alienation: Towards Theoretical Understanding of Non-Contrastive Learning with Neighbor-Averaging Dynamics | 5.67 | 5.67 | 0.47 | 0.00 | |
| 2582 | Pareto Deep Long-Tailed Recognition: A Conflict-Averse Solution | 5.33 | 5.67 | 0.47 | 0.33 | |
| 2583 | PPTSER: A Plug-and-Play Tag-guided Method for Few-shot Semantic Entity Recognition on Visually-rich Documents | 5.67 | 5.67 | 2.05 | 0.00 | |
| 2584 | Learning Dynamical Systems with Helmholtz-Hodge Decomposition and Gaussian Processes | 5.60 | 5.80 | 1.60 | 0.20 | | 8, 5, 6, 3, 6 | | 8, 6, 6, 3, 6 |
|
| 2585 | KBFormer: A Transformer-based Diffusion Model of Structured Entities with Heterogeneous Properties | 5.00 | 5.60 | 0.49 | 0.60 | | 3, 5, 6, 5, 6 | | 6, 5, 6, 5, 6 |
|
| 2586 | Curriculum reinforcement learning for quantum architecture search under hardware errors | 5.20 | 5.60 | 0.49 | 0.40 | | 5, 3, 6, 6, 6 | | 5, 5, 6, 6, 6 |
|
| 2587 | Complexity of Formal Explainability for Sequential Models | 5.60 | 5.20 | 1.17 | -0.40 | | 5, 8, 3, 6, 6 | | 5, 6, 3, 6, 6 |
|
| 2588 | On Feature Diversity in Energy-based Models | 5.60 | 5.80 | 0.40 | 0.20 | | 6, 5, 5, 6, 6 | | 6, 6, 5, 6, 6 |
|
| 2589 | Modeling state-dependent communication between brain regions with switching nonlinear dynamical systems | 4.60 | 5.60 | 0.49 | 1.00 | | 3, 3, 6, 5, 6 | | 5, 6, 6, 5, 6 |
|
| 2590 | ProbTS: A Unified Toolkit to Probe Deep Time-series Forecasting | 5.60 | 6.00 | 1.90 | 0.40 | | 3, 6, 8, 5, 6 | | 3, 6, 8, 5, 8 |
|
| 2591 | Logical Languages Accepted by Transformer Encoders with Hard Attention | 5.60 | 5.60 | 2.24 | 0.00 | | 8, 8, 3, 3, 6 | | 8, 8, 3, 3, 6 |
|
| 2592 | Do Generated Data Always Help Contrastive Learning? | 5.20 | 5.60 | 1.62 | 0.40 | | 6, 6, 3, 3, 8 | | 6, 6, 5, 3, 8 |
|
| 2593 | Benign Overfitting in Two-Layer ReLU Convolutional Neural Networks for XOR Data | 5.20 | 5.60 | 0.49 | 0.40 | | 6, 6, 3, 6, 5 | | 6, 6, 5, 6, 5 |
|
| 2594 | EraseDiff: Erasing Data Influence in Diffusion Models | 5.60 | 5.60 | 1.62 | 0.00 | | 5, 8, 3, 6, 6 | | 5, 8, 3, 6, 6 |
|
| 2595 | Learning Grounded Action Abstractions from Language | 5.20 | 5.60 | 0.49 | 0.40 | | 6, 5, 6, 3, 6 | | 6, 5, 6, 5, 6 |
|
| 2596 | $mathbb{D}^2$ Pruning: Message Passing for Balancing Diversity & Difficulty in Data Pruning | 4.80 | 5.60 | 0.49 | 0.80 | | 6, 5, 5, 3, 5 | | 6, 6, 6, 5, 5 |
|
| 2597 | DREAM: Dual Structured Exploration with Mixup for Open-set Graph Domain Adaption | 5.60 | 6.40 | 2.06 | 0.80 | | 6, 5, 3, 6, 8 | | 8, 5, 3, 8, 8 |
|
| 2598 | Interpretability Illusions in the Generalization of Simplified Models | 4.60 | 5.60 | 1.62 | 1.00 | | 3, 6, 3, 6, 5 | | 3, 6, 6, 8, 5 |
|
| 2599 | Quadratic models for understanding neural network dynamics | 5.40 | 6.00 | 1.10 | 0.60 | | 3, 6, 5, 8, 5 | | 5, 6, 5, 8, 6 |
|
| 2600 | SliceGPT: Compress Large Language Models by Deleting Rows and Columns | 5.00 | 5.60 | 0.49 | 0.60 | | 3, 6, 6, 5, 5 | | 6, 6, 6, 5, 5 |
|
| 2601 | Mutual Information Estimation via $f$-Divergence and Data Derangement Based Learning Models | 4.80 | 5.60 | 0.49 | 0.80 | | 5, 5, 5, 3, 6 | | 5, 5, 6, 6, 6 |
|
| 2602 | BadEdit: Backdooring Large Language Models by Model Editing | 5.60 | 5.60 | 1.62 | 0.00 | | 3, 6, 5, 6, 8 | | 3, 6, 5, 6, 8 |
|
| 2603 | SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models | 6.20 | 5.60 | 1.62 | -0.60 | | 6, 8, 5, 6, 6 | | 6, 8, 5, 3, 6 |
|
| 2604 | Memoria: Hebbian Memory Architecture for Human-Like Sequential Processing | 5.60 | 5.60 | 1.62 | 0.00 | | 5, 6, 6, 3, 8 | | 5, 6, 6, 3, 8 |
|
| 2605 | Co-Learning Empirical Games & World Models | 5.00 | 5.60 | 1.62 | 0.60 | | 6, 3, 8, 5, 3 | | 6, 5, 8, 6, 3 |
|
| 2606 | Long-range Meta-path Search through Progressive Sampling on Large-scale Heterogeneous Information Networks | 5.60 | 5.60 | 1.20 | 0.00 | | 5, 5, 5, 5, 8 | | 5, 5, 5, 5, 8 |
|
| 2607 | Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning | 5.60 | 5.60 | 2.24 | 0.00 | | 6, 3, 3, 8, 8 | | 6, 3, 3, 8, 8 |
|
| 2608 | Regularization is Enough for Last-Iterate Convergence in Zero-Sum Games | 5.60 | 5.60 | 1.20 | 0.00 | | 5, 5, 5, 5, 8 | | 5, 5, 5, 5, 8 |
|
| 2609 | BayOTIDE: Bayesian Online Multivariate Time series Imputation with functional decomposition | 4.80 | 5.60 | 1.20 | 0.80 | | 5, 3, 5, 3, 8 | | 5, 5, 5, 5, 8 |
|
| 2610 | Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts | 5.20 | 5.60 | 0.49 | 0.40 | | 6, 6, 6, 3, 5 | | 6, 6, 6, 5, 5 |
|
| 2611 | Optimal transport based adversarial patch to leverage large scale attack transferability | 5.60 | 6.20 | 0.98 | 0.60 | | 8, 3, 6, 6, 5 | | 8, 6, 6, 6, 5 |
|
| 2612 | BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences | 5.20 | 5.60 | 0.49 | 0.40 | | 6, 5, 6, 6, 3 | | 6, 5, 6, 6, 5 |
|
| 2613 | Analyzing and Improving OT-based Adversarial Networks | 5.60 | 5.60 | 0.49 | 0.00 | | 6, 6, 6, 5, 5 | | 6, 6, 6, 5, 5 |
|
| 2614 | ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate | 5.20 | 5.60 | 0.49 | 0.40 | | 3, 6, 5, 6, 6 | | 5, 6, 5, 6, 6 |
|
| 2615 | Tag2Text: Guiding Vision-Language Model via Image Tagging | 5.60 | 5.60 | 1.62 | 0.00 | | 8, 6, 3, 6, 5 | | 8, 6, 3, 6, 5 |
|
| 2616 | A Symmetry-Aware Exploration of Bayesian Neural Network Posteriors | 4.80 | 5.60 | 1.62 | 0.80 | | 5, 3, 5, 3, 8 | | 6, 3, 5, 6, 8 |
|
| 2617 | Understanding Large Language Models Through the Lens of Dataset Generation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2618 | Towards Relaxing the Unbiasedness Condition of Doubly Robust Estimators for Debiased Recommendation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2619 | Causality-Inspired Spatial-Temporal Explanations for Dynamic Graph Neural Networks | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2620 | On the Learnability of Watermarks for Language Models | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2621 | Prompt Sketching for Large Language Models | 4.25 | 5.50 | 0.50 | 1.25 | |
| 2622 | Parrot: Enhancing Multi-Turn Chat Models by Learning to Ask Questions | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2623 | Chain-of-Thought Predictive Control | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2624 | TESTAM: A Time-Enhanced Spatio-Temporal Attention Model with Mixture of Experts | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2625 | TILDE-Q: A Transformation Invariant Loss Function for Time-Series Forecasting | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2626 | Robust Classification via Regression-Based Loss Reweighting and Label Correction | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2627 | Dynamics-Informed Protein Design with Structure Conditioning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2628 | Partitioning Message Passing for Graph Fraud Detection | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2629 | ProFeAT: Projected Feature Adversarial Training for Self-Supervised Learning of Robust Representations | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2630 | Fill in the Blank: Exploring and Enhancing LLM Capabilities for Backward Reasoning in Math Word Problems | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2631 | Fooling the Textual Fooler via Randomizing Latent Representations | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2632 | Harnessing Overlap in Blockwise Transformers for Near-Infinite Context | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2633 | Use Your INSTINCT: INSTruction optimization usIng Neural bandits Coupled with Transformers | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2634 | Adaptive Expansion for Hypergraph Learning | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2635 | PolyFormer: Scalable Graph Transformer via Polynomial Attention | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2636 | Pushing Boundaries: Mixup's Influence on Neural Collapse | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2637 | Optimizing Interpersonal Communication by Simulating Audiences with Large Language Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2638 | Imitation Bootstrapped Reinforcement Learning | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2639 | Talking Models: Distill Pre-trained Knowledge to Downstream Models via Interactive Communication | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2640 | Generalization Guarantees of Gradient Descent for Multi-Layer Neural Networks | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2641 | Independent-Set Design of Experiments for Estimating Treatment and Spillover Effects under Network Interference | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2642 | Federated Q-Learning: Linear Regret Speedup with Low Communication Cost | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2643 | LUMOS: Towards Language Agents that are Unified, Modular, and Open Source | 5.00 | 6.00 | 1.22 | 1.00 | |
| 2644 | Gradient descent for matrix factorization: Understanding large initialization | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2645 | Learning transferrable and interpretable representation for brain network | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2646 | Score-Based Multimodal Autoencoders | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2647 | Gradient Descent Provably Solves Nonlinear Tomographic Reconstruction | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2648 | A Theory of Non-Linear Feature Learning with One Gradient Step in Two-Layer Neural Networks | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2649 | Context-Aware Meta-Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2650 | CoarsenConf: Equivariant Coarsening with Aggregated Attention for Molecular Conformer Generation | 4.50 | 6.00 | 1.22 | 1.50 | |
| 2651 | Improving Generalization for Small Datasets with Data-Aware Dynamic Reinitialization | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2652 | VCR-Graphormer: A Mini-batch Graph Transformer via Virtual Connections | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2653 | Emergence of Surprise and Predictive Signals from Local Contrastive Learning | 4.75 | 5.50 | 2.50 | 0.75 | |
| 2654 | Sparse Spiking Neural Network: Exploiting Heterogeneity in Timescales for Pruning Recurrent SNN | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2655 | HashOrder: Accelerating Graph Processing Through Hashing-based Reordering | 5.33 | 5.50 | 1.50 | 0.17 | | 8, 3, 5, 6, 5, 5 | | 8, 3, 5, 6, 5, 6 |
|
| 2656 | ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews | 5.50 | 5.50 | 2.50 | 0.00 | |
| 2657 | Network Alignment with Transferable Graph Autoencoders | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2658 | Understanding the Robustness of Multi-modal Contrastive Learning to Distribution Shift | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2659 | Double Equivariance for Inductive Link Prediction for Both New Nodes and New Relation Types | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2660 | Graph-based Virtual Sensing from Sparse and Partial Multivariate Observations | 5.67 | 5.50 | 1.80 | -0.17 | |
| 2661 | Sparse Refinement for Efficient High-Resolution Semantic Segmentation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2662 | A Topology-aware Graph Coarsening Framework for Continual Graph Learning | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2663 | A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2664 | Rethinking the Buyer’s Inspection Paradox in Information Markets with Language Agents | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2665 | Not Just Pretty Pictures: Toward Interventional Data Augmentation Using Text-to-Image Generators | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2666 | How do Language Models Bind Entities in Context? | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2667 | High-dimensional Bayesian Optimization with Group Testing | 4.50 | 5.50 | 0.50 | 1.00 | |
| 2668 | EXPLEME: A Study in Meme Interpretability, Diving Beyond Input Attribution | 5.50 | 5.50 | 2.50 | 0.00 | |
| 2669 | CAMMARL: Conformal Action Modeling in Multi Agent Reinforcement Learning | 4.50 | 5.50 | 0.50 | 1.00 | |
| 2670 | Cooperative Graph Neural Networks | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2671 | Navigating Dataset Documentations in AI: A Large-Scale Analysis of Dataset Cards on HuggingFace | 5.50 | 6.50 | 1.50 | 1.00 | |
| 2672 | Wigner kernels: body-ordered equivariant machine learning without a basis | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2673 | USB-NeRF: Unrolling Shutter Bundle Adjusted Neural Radiance Fields | 5.50 | 5.50 | 2.50 | 0.00 | |
| 2674 | INRet: A General Framework for Accurate Retrieval of INRs for Shapes | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2675 | WASA: WAtermark-based Source Attribution for Large Language Model-Generated Data | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2676 | Provably Efficient Policy Optimization with Rare Policy Switches | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2677 | InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2678 | Communication-Efficient Algorithm for Asynchronous Multi-Agent Bandits | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2679 | Sinkhorn Output Perturbations: Structured Pseudo-Label Noise in Semi-Supervised Segmentation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2680 | SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2681 | Learning Object-Centric Representation via Reverse Hierarchy Guidance | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2682 | ConvFormer: Revisiting Token-mixers for Sequential User Modeling | 5.50 | 4.67 | 1.25 | -0.83 | |
| 2683 | Generalized Temporal Difference Learning Models for Supervised Learning | 5.50 | 6.00 | 2.12 | 0.50 | |
| 2684 | Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization | 5.50 | 5.50 | 1.50 | 0.00 | | 5, 6, 6, 8, 3, 5 | | 5, 6, 6, 8, 3, 5 |
|
| 2685 | Bio-RFX: Refining Biomedical Extraction via Advanced Relation Classification and Structural Constraints | 5.75 | 5.50 | 0.50 | -0.25 | |
| 2686 | Towards Perpetually Trainable Neural Networks | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2687 | Pairwise Proximal Policy Optimization: Harnessing Relative Feedback for LLM Alignment | 5.33 | 5.50 | 0.50 | 0.17 | |
| 2688 | Some Intriguing Aspects about Lipschitz Continuity of Neural Networks | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2689 | Federated Offline Policy Learning with Heterogeneous Observational Data | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2690 | Decomposition Ascribed Synergistic Learning for Unified Image Restoration | 5.50 | 6.00 | 2.12 | 0.50 | |
| 2691 | Eye Fairness: A Large-Scale 3D Imaging Dataset for Equitable Eye Diseases Screening and Fair Identity Scaling | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2692 | DIFFNAT: IMPROVING DIFFUSION IMAGE QUALITY USING NATURAL IMAGE STATISTICS | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2693 | Simple CNN for Vision | 5.50 | 5.00 | 1.22 | -0.50 | |
| 2694 | Efficient Meshy Neural Fields for Animatable Human Avatars | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2695 | Black-Box Gradient Matching for Reliable Offline Black-Box Optimization | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2696 | Understanding Addition in Transformers | 5.50 | 5.50 | 2.50 | 0.00 | |
| 2697 | In defense of parameter sharing for model-compression | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2698 | Bootstrapping Variational Information Pursuit with Foundation Models for Interpretable Image Classification | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2699 | JsonTuning: Towards Generalizable, Robust, and Controllable Instruction Tuning | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2700 | Making Large Language Models Better Reasoners with Alignment | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2701 | Exploring the Relationship Between Model Architecture and In-Context Learning Ability | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2702 | When Does Bias Transfer in Transfer Learning? | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2703 | Noise Robust Graph Learning under Feature-Dependent Graph-Noise | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2704 | Dynamic Neural Response Tuning | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2705 | Black-Box Privacy Attacks Against GANs via Detector Networks | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2706 | Hyper Evidential Deep Learning to Quantify Composite Classification Uncertainty | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2707 | Weakly Supervised Graph Contrastive Learning | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2708 | User Inference Attacks on Large Language Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2709 | Efficient Stagewise Pretraining via Progressive Subnetworks | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2710 | TaskBench: Benchmarking Large Language Models for Task Automation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2711 | CityGPT: Generative Transformer for City Layout of Arbitrary Building Shape | 6.00 | 5.00 | 1.22 | -1.00 | |
| 2712 | Enhanced Visual Instruction Tuning for Text-Rich Image Understanding | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2713 | RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2714 | Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2715 | Extracting Post-Treatment Covariates for Heterogeneous Treatment Effect Estimation | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2716 | WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2717 | DASFormer: Self-supervised Pretraining for Earthquake Monitoring | 5.50 | 5.25 | 0.43 | -0.25 | |
| 2718 | Vision-Language Models Provide Promptable Representations for Reinforcement Learning | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2719 | Language Reward Modulation for Pretraining Reinforcement Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2720 | Like Oil and Water: Group Robustness Methods and Poisoning Defenses Don't Mix | 5.50 | 6.00 | 1.22 | 0.50 | |
| 2721 | Re-evaluating Retrosynthesis Algorithms with Syntheseus | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2722 | Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2723 | Monsters in the Dark: Sanitizing Hidden Threats with Diffusion Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2724 | Energy-conserving equivariant GNN for elasticity of lattice architected metamaterials | 3.75 | 5.50 | 1.80 | 1.75 | |
| 2725 | GenBot: Generative Simulation Empowers Automated Robotic Skill Learning at Scale | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2726 | ToolDec: Syntax Error-Free and Generalizable Tool Use for LLMs via Finite-State Decoding | 5.50 | 6.00 | 1.22 | 0.50 | |
| 2727 | Diffusion Models With Learned Adaptive Noise Processes | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2728 | Efficient Dynamics Modeling in Interactive Environments with Koopman Theory | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2729 | BaFTA: Backprop-Free Test-Time Adaptation for Zero-shot Vision Language Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2730 | Synaptic Weight Distributions Depend on the Geometry of Plasticity | 4.50 | 5.50 | 2.87 | 1.00 | |
| 2731 | Chunk, Align, Select: A Simple Long-sequence Processing Method for Transformers | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2732 | Improving LoRA in Privacy-preserving Federated Learning | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2733 | Locality-Aware Graph Rewiring in GNNs | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2734 | MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2735 | Quantifying the Plausibility of Context Reliance in Neural Machine Translation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2736 | Transforming Transformers for Resilient Lifelong Learning | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2737 | Causally Aligned Curriculum Learning | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2738 | Towards Characterizing Domain Counterfactuals for Invertible Latent Causal Models | 4.50 | 5.50 | 0.50 | 1.00 | |
| 2739 | Frequency-Aware Masked Autoencoders for Multimodal Pretraining on Biosignals | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2740 | The Marginal Value of Momentum for Small Learning Rate SGD | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2741 | Think before you speak: Training Language Models With Pause Tokens | 5.50 | 5.50 | 2.50 | 0.00 | |
| 2742 | Reinforcement Learning of Diverse Skills using Mixture of Deep Experts | 4.50 | 5.50 | 0.50 | 1.00 | |
| 2743 | Task-to-Instance Prompt Learning for Vision-Language Models at Test Time | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2744 | Automatically Eliciting Toxic Outputs from Pre-trained Language Models | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2745 | Bridging Autoregressive and Masked Modeling for Enhanced Visual Representation Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2746 | FigCaps-HF: A Figure-to-Caption Generative Framework and Benchmark with Human Feedback | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2747 | Understanding and Tackling Over-Dilution in Graph Neural Networks | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2748 | Learning Deep O($n$)-Equivariant Hyperspheres | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2749 | Distributional Bellman Operators over Mean Embeddings | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2750 | Slicing Mutual Information Generalization Bounds for Neural Networks | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2751 | On the Identifiability of Switching Dynamical Systems | 5.67 | 5.50 | 0.50 | -0.17 | |
| 2752 | DiracDiffusion: Denoising and Incremental Reconstruction with Assured Data-Consistency | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2753 | Scalable Long Range Propagation on Continuous-Time Dynamic Graphs | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2754 | Coresets for Clustering with Noisy Data | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2755 | From Interpolation to Extrapolation: Complete Length Generalization for Arithmetic Transformers | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2756 | Contractive Systems Improve Graph Neural Networks Against Adversarial Attacks | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2757 | Rethinking the Noise Schedule of Diffusion-Based Generative Models | 5.50 | 5.50 | 1.50 | 0.00 | | 6, 5, 5, 8, 6, 3 | | 6, 5, 5, 8, 6, 3 |
|
| 2758 | Efficient Certification of Physics-Informed Neural Networks | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2759 | Meta-Referential Games to Learn Compositional Learning Behaviours | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2760 | Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2761 | Vision-by-Language for Training-Free Compositional Image Retrieval | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2762 | RobustTSF: Towards Theory and Design of Robust Time Series Forecasting with Anomalies | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2763 | Typing to Listen at the Cocktail Party: Text-Guided Target Speaker Extraction | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2764 | DORSal: Diffusion for Object-centric Representations of Scenes $textit{et al.}$ | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2765 | SummaryMixing: A Linear-Complexity Alternative to Self-Attention for Speech Recognition and Understanding | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2766 | Variational Inference with Singularity-Free Planar Flows | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2767 | LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents | 5.00 | 5.50 | 2.87 | 0.50 | |
| 2768 | Ada-Instruct: Adapting Instruction Generators For Complex Reasoning | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2769 | Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2770 | A Reparameterized Discrete Diffusion Model for Text Generation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2771 | Adversarial Attacks as Near-Zero Eigenvalues in The Empirical Kernel of Neural Networks | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2772 | ExoViP: Step-by-step Verification and Exploration with Exoskeleton Modules for Compositional Visual Reasoning | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2773 | Benchmarking Diffusion Based Text-Guided Image Editing Methods | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2774 | Enhancing Mutual Information Estimation in Self-Interpretable Graph Neural Networks | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2775 | FedNovel: Federated Novel Class Learning | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2776 | Implicit Neural Representations for Joint Sparse-View CT Reconstruction | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2777 | Lagrangian Proximal Gradient Descent for Learning Convex Optimization Models | 4.50 | 5.50 | 1.80 | 1.00 | |
| 2778 | GPT as Visual Explainer | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2779 | Value Factorization for Asynchronous Multi-Agent Reinforcement Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2780 | Sign2GPT: Leveraging Large Language Models for Gloss-Free Sign Language Translation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2781 | Large-Batch, Iteration-Efficient Neural Bayesian Design Optimization | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2782 | Gated recurrent neural networks discover attention | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2783 | C-TPT: Calibrated Test-Time Prompt Tuning for Vision-Language Models via Text Feature Dispersion | 5.25 | 6.00 | 0.00 | 0.75 | |
| 2784 | DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2785 | AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2786 | LMEye: An Interactive Perception Network for Large Language Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2787 | ARB: Advanced Reasoning Benchmark for Large Language Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2788 | Training Unbiased Diffusion Models From Biased Dataset | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2789 | The optimality of kernel classifiers in Sobolev space | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2790 | Mastering Robot Manipulation with Multimodal Prompts through Pretraining and Multi-task Fine-tuning | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2791 | Accelerating Federated Learning with Quick Distributed Mean Estimation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2792 | Feature Map Matters in Out-of-distribution Detection | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2793 | Benchmarking Structural Inference Methods for Interacting Dynamical Systems with Synthetic Data | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2794 | Fairness Through Matching for better group fairness | 5.50 | 5.67 | 0.47 | 0.17 | |
| 2795 | FedLoGe: Joint Local and Generic Federated Learning under Long-tailed Data | 5.00 | 6.00 | 1.22 | 1.00 | |
| 2796 | LIMANS: Linear Model of the Adversarial Noise Space | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2797 | Invariance-based Learning of Latent Dynamics | 4.50 | 5.75 | 0.43 | 1.25 | |
| 2798 | Label-Noise Robust Diffusion Models | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2799 | Contrastive Positive Unlabeled Learning | 5.50 | 5.75 | 1.79 | 0.25 | |
| 2800 | Best Possible Q-Learning | 4.25 | 5.50 | 1.80 | 1.25 | |
| 2801 | Unsupervised Order Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2802 | ResolvNet: A Graph Convolutional Network with multi-scale Consistency | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2803 | NanoLM: An Affordable LLM Study Benchmark via Accurate Loss Prediction Across Scales | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2804 | Rethinking Label Smoothing as a Tool for Embedding Perturbation Uncertainty | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2805 | A Unified Framework for Bayesian Optimization under Contextual Uncertainty | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2806 | Free from Bellman Completeness: Trajectory Stitching via Model-based Return-conditioned Supervised Learning | 5.00 | 6.00 | 1.22 | 1.00 | |
| 2807 | Diffusion Models for Multi-Task Generative Modeling | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2808 | $textbf{textit{M}}^textbf{textit{3}}$: Towards Robust Multi-Modal Reasoning via Model Selection | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2809 | Split and Merge Proxy: pre-training protein inter-chain contact prediction by mining rich information from monomer data | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2810 | Gradient norm as a powerful proxy to out-of-distribution error estimation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2811 | Investigating Uncertainty Calibration of Aligned Language Models under the Multiple-Choice Setting | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2812 | Rethinking Spectral Graph Neural Networks with Spatially Adaptive Filtering | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2813 | Spatial-Temporal Mutual Distillation for Lightweight Sleep Stage Classification | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2814 | Alphazero-like Tree-Search can guide large language model decoding and training | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2815 | LAURAGPT: LISTEN, ATTEND, UNDERSTAND, AND REGENERATE AUDIO WITH GPT | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2816 | Vocabulary for Universal Approximation: A Linguistic Perspective of Mapping Compositions | 6.33 | 5.50 | 1.80 | -0.83 | |
| 2817 | Learning to Model the World with Language | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2818 | Domain Generalization Deep Graph Transformation | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2819 | Memory-Assisted Sub-Prototype Mining for Universal Domain Adaptation | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2820 | IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2821 | TimelyGPT: Recurrent Convolutional Transformer for Long Time-series Representation | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2822 | ControlVideo: Training-free Controllable Text-to-video Generation | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2823 | KW-Design: Pushing the Limit of Protein Deign via Knowledge Refinement | 5.50 | 6.00 | 0.00 | 0.50 | |
| 2824 | ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2825 | Towards general neural surrogate PDE solvers with specialized neural accelerators | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2826 | Generative modeling for RNA splicing code predictions and design | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2827 | TpopT: Efficient Trainable Template Optimization on Low-Dimensional Manifolds | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2828 | Curvature Explains Loss of Plasticity | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2829 | Language Models as Semantic Indexers | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2830 | Personalized Federated Learning of Probabilistic Models: A PAC-Bayesian Approach | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2831 | A Local Graph Limits Perspective on Sampling-Based GNNs | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2832 | Structured Inverse-Free Natural Gradient: Memory-Efficient & Numerically-Stable KFAC for Large Neural Nets | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2833 | LETI: Learning to Generate from Textual Interactions | 5.20 | 5.17 | 0.37 | -0.03 | | 3, 8, 5, 5, 5 | | 5, 6, 5, 5, 5, 5 |
|
| 2834 | $lambda$-AC: Effective decision-aware reinforcement learning with latent models | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2835 | Evaluating the Robustness of Text-to-image Diffusion Models against Real-world Attacks | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2836 | The Entity-Deduction Arena: A playground for probing the conversational reasoning and planning capabilities of LLMs | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2837 | ELEGANT: Certified Defense on the Fairness of Graph Neural Networks | 4.25 | 5.50 | 0.50 | 1.25 | |
| 2838 | FairTune: Optimizing Parameter Efficient Fine Tuning for Fairness in Medical Image Analysis | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2839 | Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2840 | Out-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2841 | Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2842 | Rethinking the Starting Point: Enhancing Performance and Fairness of Federated Learning via Collaborative Pre-Training | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2843 | Biological Sequence Analysis Using B ́ezier Curve | 5.50 | 5.00 | 1.22 | -0.50 | |
| 2844 | MotionDirector: Motion Customization of Text-to-Video Diffusion Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2845 | JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2846 | LIFT: Efficient Layer-wise Fine-tuning for Large Model Models | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2847 | Knowledge Fusion of Large Language Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2848 | Video Deblurring with Adaptive High-frequency Extraction | 5.50 | 5.50 | 2.50 | 0.00 | |
| 2849 | Efficient Human-AI Coordination via Preparatory Language-based Convention | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2850 | Climate-sensitive Urban Planning through Optimization of Tree Placements | 4.25 | 5.50 | 1.80 | 1.25 | |
| 2851 | Improving the Convergence of Dynamic NeRFs via Optimal Transport | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2852 | Addressing Real-Time Fragmentary Interaction Control Problems via Muti-step Representation Reinforcement Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2853 | Tailoring Mixup to Data using Kernel Warping functions | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2854 | A Spitting Image: Superpixel Transformers | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2855 | Visual Evidence Prompting Mitigates Hallucinations in Multimodal Large Language Models | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2856 | HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision-Language Models for Detailed Caption | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2857 | Exploiting the Potential of Seq2Seq Models as Robust Few-Shot Learners | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2858 | Zero-Sum Positional Differential Games as a Framework for Robust Reinforcement Learning: Deep Q-Learning Approach | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2859 | DiffusionSat: A Generative Foundation Model for Satellite Imagery | 4.75 | 6.25 | 2.05 | 1.50 | |
| 2860 | FragSel: Fragmented Selection for Noisy Label Regression | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2861 | Follow-Up Differential Descriptions: Language Models Resolve Ambiguities for Image Classification | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2862 | A Curriculum View of Robust Loss Functions | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2863 | Partitioned-Learned Count-Min Sketch | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2864 | Mathematical Justification of Hard Negative Mining via Isometric Approximation Theorem | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2865 | Adversarial Training Should Be Cast as a Non-Zero-Sum Game | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2866 | Complex priors and flexible inference in recurrent circuits with dendritic nonlinearities | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2867 | Multilingual Mathematical Autoformalization | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2868 | The Implicit Bias of Stochastic AdaGrad-Norm on Separable Data | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2869 | Estimating Fréchet bounds for validating programmatic weak supervision | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2870 | The Emergence of Reproducibility and Consistency in Diffusion Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2871 | Codebook Features: Sparse and Discrete Interpretability for Neural Networks | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2872 | Universal Backdoor Attacks | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2873 | Eliciting Human Preferences with Language Models | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2874 | Let's Verify Step by Step | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2875 | Language Model Inversion | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2876 | Multi-Group Tri-plane Based Local Occupancy Estimation for Object Grasping | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2877 | Concise and Organized Perception Facilitates Large Language Models for Deductive Reasoning | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2878 | OWL: A Large Language Model for IT Operations | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2879 | Towards Control-Centric Representations in Reinforcement Learning from Images | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2880 | DiffusionShield: A Watermark for Data Copyright Protection against Generative Diffusion Models | 5.75 | 5.50 | 1.80 | -0.25 | |
| 2881 | Enhanced Label Propagation through Affinity Matrix Fusion for Source-Free Domain Adaptation | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2882 | IRGen: Generative Modeling for Image Retrieval | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2883 | Decoding Natural Images from EEG for Object Recognition | 5.50 | 6.75 | 2.17 | 1.25 | |
| 2884 | DiffEnc: Variational Diffusion with a Learned Encoder | 5.25 | 5.75 | 0.43 | 0.50 | |
| 2885 | Boolformer: Symbolic Regression of Logic Functions with Transformers | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2886 | Amortized Network Intervention to Steer the Excitatory Point Processes | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2887 | Investigating the Impact of Data Distribution Shifts on Cross-Modal Knowledge Distillation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2888 | Revisiting Knowledge Tracing: A Simple and Powerful Model | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2889 | End-to-End Spatio-Temporal Action Localisation with Video Transformers | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2890 | Image Inpainting via Tractable Steering of Diffusion Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2891 | mBLIP: Efficient Bootstrapping of Multilingual Vision-LLMs | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2892 | Knowledge Distillation for Closed-Source Language Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2893 | SoftHash: High-dimensional Hashing with A Soft Winner-Take-All Mechanism | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2894 | One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2895 | Momentum-accelerated Diffusion Process for Faster Training and Sampling | 5.50 | 6.00 | 1.22 | 0.50 | |
| 2896 | Rethinking RGB Color Representation for Image Restoration Models | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2897 | Deepfake Caricatures: Amplifying attention to artifacts increases deepfake detection by humans and machines | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2898 | Towards Green AI in Fine-tuning Large Language Models via Adaptive Backpropagation | 4.50 | 5.50 | 0.50 | 1.00 | |
| 2899 | Outliers with Opposing Signals Have an Outsized Effect on Neural Network Optimization | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2900 | Jointly Training Large Autoregressive Multimodal Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2901 | Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2902 | Learning Temporal Causal Representation under Non-Invertible Generation Process | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2903 | Guided Decoupled Exploration for Offline Reinforcement Learning Fine-tuning | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2904 | Compressed Online Sinkhorn | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2905 | Closing the Gap between TD Learning and Supervised Learning - A Generalisation Point of View. | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2906 | Beyond task performance: evaluating and reducing the flaws of large multimodal models with in-context-learning | 5.00 | 5.50 | 2.50 | 0.50 | |
| 2907 | Visual Grounding with attention-driven constraint balancing | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2908 | Consistent123: Improve Consistency for One Image to 3D Object Synthesis | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2909 | CSI: Enhancing the Robustness of 3D Point Cloud Recognition against Corruption | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2910 | Plug-and-Play Posterior Sampling under Mismatched Measurement and Prior Models | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2911 | Grokking in Linear Estimators -- A Solvable Model that Groks without Understanding | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2912 | EquiPocket: an E(3)-Equivariant Geometric Graph Neural Network for Ligand Binding Site Prediction | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2913 | Maximally discriminative stimuli for functional cell type identification | 4.50 | 5.50 | 0.50 | 1.00 | |
| 2914 | Provably Efficient Exploration in Quantum Reinforcement Learning with Logarithmic Worst-Case Regret | 5.67 | 5.50 | 0.50 | -0.17 | |
| 2915 | A Semantic Invariant Robust Watermark for Large Language Models | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2916 | Out-Of-Distribution Detection With Smooth Training | 5.00 | 5.75 | 0.43 | 0.75 | |
| 2917 | BiLoRA: A Bi-level Optimization Framework for Low-rank Adapters | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2918 | The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World | 5.50 | 5.67 | 0.47 | 0.17 | |
| 2919 | Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2920 | Point Neighborhood Embeddings | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2921 | Law of Balance and Stationary Distribution of Stochastic Gradient Descent | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2922 | Mixup Your Own Pairs | 4.67 | 5.50 | 1.80 | 0.83 | |
| 2923 | Overcoming Data Inequality across Domains with Semi-Supervised Domain Generalization | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2924 | Sparse Mask Representation for Human-Scene Interaction | 5.50 | 5.00 | 1.22 | -0.50 | |
| 2925 | VONET: ADVANCING UNSUPERVISED VIDEO OBJECT LEARNING | 6.00 | 5.50 | 0.50 | -0.50 | |
| 2926 | Boosting Semi-Supervised Learning via Variational Confidence Calibration and Unlabeled Sample Elimination | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2927 | 3D Point Cloud Sequences as 2D Videos | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2928 | Nearest neighbor-based out-of-distribution detection via label smoothing | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2929 | Adaptive Regularization of Representation Rank as an Implicit Constraint of Bellman Equation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2930 | ReLU to the Rescue: Improve Your On-Policy Actor-Critic with Positive Advantages | 4.75 | 5.50 | 0.50 | 0.75 | |
| 2931 | MANGO: A Benchmark for Evaluating Mapping and Navigation Abilities of Large Language Models | 4.75 | 6.25 | 1.09 | 1.50 | |
| 2932 | Near-optimal algorithms for private estimation and sequential testing of collision probability | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2933 | Patched Denoising Diffusion Models For High-Resolution Image Synthesis | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2934 | One-stage Prompt-based Continual Learning | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2935 | FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing | 5.50 | 6.50 | 1.50 | 1.00 | |
| 2936 | Combining Spatial and Temporal Abstraction in Planning for Better Generalization | 5.50 | 5.75 | 0.43 | 0.25 | |
| 2937 | InstructDET: Diversifying Referring Object Detection with Generalized Instructions | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2938 | Training-time Neuron Alignment for Improving Linear Mode Connectivity and Model Fusion | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2939 | Universal Jailbreak Backdoors from Poisoned Human Feedback | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2940 | NeRFuser: Diffusion Guided Multi-Task 3D Policy Learning | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2941 | Hybrid Distillation: Connecting Masked Autoencoders with Contrastive Learners | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2942 | Re-imagine the Negative Prompt Algorithm for 2D/3D Diffusion | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2943 | SAIR: LEARNING SEMANTIC-AWARE IMPLICIT REPRESENTATION | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2944 | Dense Representation Learning for a Joint-Embedding Predictive Architecture | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2945 | Don't Paint Everyone with the Same Brush: Adaptive Prompt Prototype Learning for Vision-Language Models | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2946 | Compact Text-to-SDF via Latent Modeling | 5.75 | 5.50 | 1.80 | -0.25 | |
| 2947 | Neural Tangent Kernels for Axis-Aligned Tree Ensembles | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2948 | On the Generalization of Temporal Graph Learning with Theoretical Insights | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2949 | T-Stitch: Accelerating Sampling in Pre-Trained Diffusion Models with Trajectory Stitching | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2950 | Causal Unsupervised Semantic Segmentation | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2951 | EFFL: Egalitarian Fairness in Federated Learning for Mitigating Matthew Effect | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2952 | Dual-level Adaptive Self-Labeling for Novel Class Discovery in Point Cloud Segmentation | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2953 | It HAS to be Subjective: Human Annotator Simulation via Zero-shot Density Estimation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2954 | Completing Visual Objects via Bridging Generation and Segmentation | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2955 | Covariance-corrected Whitening Alleviates Network Degeneration on Imbalanced Classification | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2956 | Theoretical Understanding of Learning from Adversarial Perturbations | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2957 | UniPAD: A Universal Pre-training Paradigm for Autonomous Driving | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2958 | Federated Virtual Learning on Heterogeneous Data with Local-global Distillation | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2959 | Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2960 | Cumulative Reasoning with Large Language Models | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2961 | Pseudo-Calibration: Improving Predictive Uncertainty Estimation in Domain Adaptation | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2962 | AutoVP: An Automated Visual Prompting Framework and Benchmark | 4.75 | 5.50 | 1.80 | 0.75 | |
| 2963 | Vision-Language Dataset Distillation | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2964 | Adversarially Robust Deep Learning with Optimal-Transport-Regularized Divergences | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2965 | CODA: Temporal Domain Generalization via Concept Drift Simulator | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2966 | Mining Patents with Large Language Models Demonstrates Congruence of Functional Labels and Chemical Structures | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2967 | Expected flow networks in stochastic environments and two-player zero-sum games | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2968 | Reliable Test-Time Adaptation via Agreement-on-the-Line | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2969 | SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models | 5.25 | 5.75 | 1.79 | 0.50 | |
| 2970 | Detect Every Thing with Few Examples | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2971 | LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2972 | Hard View Selection for Contrastive Learning | 5.25 | 5.50 | 1.80 | 0.25 | |
| 2973 | Boosting Backdoor Attack with A Learnable Poisoning Sample Selection Strategy | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2974 | SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning | 5.00 | 6.00 | 1.22 | 1.00 | |
| 2975 | Robust prediction under missingness shifts | 5.00 | 5.50 | 1.80 | 0.50 | |
| 2976 | Dataset Distillation in Large Data Era | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2977 | Geometry-Aware Projective Mapping for Unbounded Neural Radiance Fields | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2978 | Collaboration! Towards Robust Neural Methods for Vehicle Routing Problems | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2979 | Parameter-Efficient Long-Tailed Recognition | 5.50 | 5.50 | 0.50 | 0.00 | |
| 2980 | RepCodec: A Speech Representation Codec for Speech Tokenization | 5.00 | 5.50 | 0.50 | 0.50 | |
| 2981 | Multi-Scale Representations by Varing Window Attention for Semantic Segmentation | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2982 | AutoAgents: A Framework for Automatic Agent Generation | 4.75 | 5.75 | 0.43 | 1.00 | |
| 2983 | Neural Processing of Tri-Plane Hybrid Neural Fields | 5.50 | 5.50 | 1.80 | 0.00 | |
| 2984 | Unsupervised Discovery of Object-Centric Neural Fields | 6.00 | 5.75 | 1.79 | -0.25 | |
| 2985 | Less is More: On the Feature Redundancy of Pretrained Models When Transferring to Few-shot Tasks | 4.25 | 5.50 | 1.80 | 1.25 | |
| 2986 | Training Adversarially Robust SNNs with Gradient Sparsity Regularization | 5.00 | 5.50 | 2.87 | 0.50 | |
| 2987 | A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization | 5.25 | 5.50 | 0.50 | 0.25 | |
| 2988 | Model-Agnostic Shift-Equivariant Downsampling | 5.40 | 5.00 | 1.90 | -0.40 | | 6, 5, 5, 3, 8 | | 6, 3, 5, 3, 8 |
|
| 2989 | FedLoRA: When Personalized Federated Learning Meets Low-Rank Adaptation | 5.40 | 5.40 | 1.62 | 0.00 | | 6, 3, 8, 5, 5 | | 6, 3, 8, 5, 5 |
|
| 2990 | Energy-based Automated Model Evaluation | 5.40 | 6.00 | 1.90 | 0.60 | | 8, 8, 3, 3, 5 | | 8, 8, 3, 6, 5 |
|
| 2991 | Rotation has two sides: Evaluating Data Augmentation for Deep One-class Classification | 5.40 | 5.40 | 1.20 | 0.00 | | 6, 3, 6, 6, 6 | | 6, 3, 6, 6, 6 |
|
| 2992 | Uncertainty-aware Graph-based Hyperspectral Image Classification | 5.40 | 5.60 | 0.49 | 0.20 | | 5, 5, 6, 5, 6 | | 5, 6, 6, 5, 6 |
|
| 2993 | The Trickle-down Impact of Reward Inconsistency on RLHF | 4.80 | 5.60 | 0.49 | 0.80 | | 5, 3, 5, 6, 5 | | 6, 5, 5, 6, 6 |
|
| 2994 | GATE: How to Keep Out Intrusive Neighbors | 5.20 | 5.40 | 0.49 | 0.20 | | 5, 5, 5, 5, 6 | | 6, 5, 5, 5, 6 |
|
| 2995 | Endowing Protein Language Models with Structural Knowledge | 4.80 | 5.40 | 0.49 | 0.60 | | 5, 5, 6, 5, 3 | | 6, 5, 6, 5, 5 |
|
| 2996 | Perturb and Learn: Energy-Based Modelling in Discrete Spaces without MCMC | 5.40 | 5.40 | 1.62 | 0.00 | | 8, 5, 3, 6, 5 | | 8, 5, 3, 6, 5 |
|
| 2997 | Few and Fewer: Learning Better from Few Examples Using Fewer Base Classes | 5.40 | 5.40 | 0.49 | 0.00 | | 6, 5, 5, 5, 6 | | 6, 5, 5, 5, 6 |
|
| 2998 | Demystifying Linear MDPs and Novel Dynamics Aggregation Framework | 5.20 | 5.40 | 1.20 | 0.20 | | 6, 5, 6, 3, 6 | | 6, 6, 6, 3, 6 |
|
| 2999 | Topology-aware Embedding Memory for Learning on Expanding Graphs | 5.40 | 5.40 | 1.20 | 0.00 | | 6, 6, 3, 6, 6 | | 6, 6, 3, 6, 6 |
|
| 3000 | LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models | 5.40 | 5.40 | 0.49 | 0.00 | | 6, 5, 5, 6, 5 | | 6, 5, 5, 6, 5 |
|
| 3001 | Differentially Private Bias-Term Fine-tuning of Foundation Models | 5.40 | 5.40 | 1.62 | 0.00 | | 5, 6, 5, 3, 8 | | 5, 6, 5, 3, 8 |
|
| 3002 | Harmonic Prior Flow Matching for Multi-Ligand Docking and Binding Site Design | 5.00 | 5.40 | 0.49 | 0.40 | | 6, 5, 6, 3, 5 | | 6, 5, 6, 5, 5 |
|
| 3003 | ($texttt{PEEP}$) $textbf{P}$redicting $textbf{E}$nzym$textbf{e}$ $textbf{P}$romiscuity with its Molecule Mate – an Attentive Metric Learning Solution | 5.40 | 5.40 | 0.49 | 0.00 | | 5, 6, 5, 5, 6 | | 5, 6, 5, 5, 6 |
|
| 3004 | Spectral Neural Networks: Approximation Theory and Optimization Landscape | 5.00 | 5.40 | 1.62 | 0.40 | | 6, 5, 3, 8, 3 | | 6, 5, 3, 8, 5 |
|
| 3005 | PolySketchFormer: Fast Transformers via Sketches for Polynomial Kernels | 5.40 | 5.00 | 1.90 | -0.40 | | 8, 5, 8, 3, 3 | | 8, 5, 6, 3, 3 |
|
| 3006 | SoundStorm: Efficient Parallel Audio Generation | 5.40 | 5.40 | 1.62 | 0.00 | | 5, 6, 5, 3, 8 | | 5, 6, 5, 3, 8 |
|
| 3007 | Explaining Emergent In-Context Learning as Kernel Regression | 4.80 | 5.60 | 0.49 | 0.80 | | 5, 6, 5, 3, 5 | | 6, 6, 6, 5, 5 |
|
| 3008 | On Using Admissible Bounds for Learning Forward Search Heuristics | 5.00 | 5.40 | 1.62 | 0.40 | | 3, 3, 8, 6, 5 | | 5, 3, 8, 6, 5 |
|
| 3009 | The Fundamental Limits of Least-Privilege Learning | 5.40 | 5.40 | 0.49 | 0.00 | | 6, 5, 5, 6, 5 | | 6, 5, 5, 6, 5 |
|
| 3010 | Quantized Local Independence Discovery for Fine-Grained Causal Dynamics Learning in Reinforcement Learning | 5.00 | 5.80 | 0.40 | 0.80 | | 6, 5, 6, 3, 5 | | 6, 6, 6, 5, 6 |
|
| 3011 | Efficient Long Sequence Modeling via State Space Augmented Transformer | 5.40 | 5.40 | 1.62 | 0.00 | | 3, 5, 8, 5, 6 | | 3, 5, 8, 5, 6 |
|
| 3012 | Neural Sinkhorn Gradient Flow | 4.20 | 5.40 | 0.49 | 1.20 | | 3, 3, 6, 3, 6 | | 5, 5, 6, 5, 6 |
|
| 3013 | GENERATIVE TIME SERIES LEARNING WITH TIME-FREQUENCY FUSED ENERGY-BASED MODEL | 5.40 | 5.40 | 0.49 | 0.00 | | 5, 6, 5, 6, 5 | | 5, 6, 5, 6, 5 |
|
| 3014 | Dual-Balancing for Multi-Task Learning | 5.40 | 5.40 | 1.62 | 0.00 | | 8, 6, 3, 5, 5 | | 8, 6, 3, 5, 5 |
|
| 3015 | HiCBridge: Resolution Enhancement of Hi-C Data Using Direct Diffusion Bridge | 5.20 | 5.40 | 1.20 | 0.20 | | 6, 5, 6, 6, 3 | | 6, 6, 6, 6, 3 |
|
| 3016 | ZeRO++: Extremely Efficient Collective Communication for Large Model Training | 4.67 | 5.40 | 0.49 | 0.73 | |
| 3017 | ViFu: Visible Part Fusion for Multiple Scene Radiance Fields | 5.40 | 5.40 | 0.49 | 0.00 | | 5, 5, 6, 5, 6 | | 5, 5, 6, 5, 6 |
|
| 3018 | Fair Text-to-Image Diffusion via Fair Mapping | 5.40 | 5.40 | 0.49 | 0.00 | | 6, 5, 6, 5, 5 | | 6, 5, 6, 5, 5 |
|
| 3019 | Mean Field Theory in Deep Metric Learning | 5.40 | 5.40 | 1.62 | 0.00 | | 5, 6, 8, 3, 5 | | 5, 6, 8, 3, 5 |
|
| 3020 | Adversarial Data Robustness via Implicit Neural Representation | 5.40 | 4.40 | 1.96 | -1.00 | | 8, 8, 3, 3, 5 | | 3, 8, 3, 3, 5 |
|
| 3021 | Understanding MLP-Mixer as a wide and sparse MLP | 5.40 | 5.80 | 0.40 | 0.40 | | 6, 6, 5, 5, 5 | | 6, 6, 5, 6, 6 |
|
| 3022 | A Discrete and Variational Approach to Speech Representation Learning | 5.40 | 5.40 | 2.24 | 0.00 | | 5, 3, 8, 3, 8 | | 5, 3, 8, 3, 8 |
|
| 3023 | DBRNet: Advancing Individual-Level Continuous Treatment Estimation through Disentangled and Balanced Representation | 5.00 | 5.40 | 1.62 | 0.40 | | 6, 3, 5, 5, 6 | | 8, 3, 5, 5, 6 |
|
| 3024 | GeoLLM: Extracting Geospatial Knowledge from Large Language Models | 5.40 | 5.60 | 1.62 | 0.20 | | 5, 5, 8, 6, 3 | | 6, 5, 8, 6, 3 |
|
| 3025 | 3D Reconstruction with Generalizable Neural Fields using Scene Priors | 5.40 | 6.00 | 1.10 | 0.60 | | 6, 5, 5, 5, 6 | | 6, 5, 5, 8, 6 |
|
| 3026 | SELECTFORMER: PRIVATE AND PRACTICAL DATA SELECTION FOR TRANSFORMERS | 5.40 | 5.40 | 1.62 | 0.00 | | 8, 5, 5, 6, 3 | | 8, 5, 5, 6, 3 |
|
| 3027 | A Wasserstein-2 Distance for Efficient Reconstruction of Stochastic Differential Equations | 4.80 | 5.40 | 1.20 | 0.60 | | 3, 5, 6, 5, 5 | | 3, 6, 6, 6, 6 |
|
| 3028 | ReBaR: Reference-Based Reasoning for Robust Human Pose and Shape Estimation from Monocular Images | 5.40 | 5.20 | 0.40 | -0.20 | | 6, 5, 6, 5, 5 | | 5, 5, 6, 5, 5 |
|
| 3029 | CLIP Exhibits Improved Compositional Generalization Through Representation Disentanglement | 4.33 | 5.33 | 0.47 | 1.00 | |
| 3030 | Generative Judge for Evaluating Alignment | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3031 | Lightweight Graph Neural Network Search with Graph Sparsification | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3032 | Bellman Optimal Step-size Straightening of Flow-Matching Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3033 | RedMotion: Motion Prediction via Redundancy Reduction | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3034 | Automating Continual Learning | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3035 | Knowledge Distillation with Perturbed Loss: From a Vanilla Teacher to a Proxy Teacher | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3036 | 2D-Supervised Monocular 3D Object Detection by Global-to-Local Reconstruction | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3037 | Non-Autoregressive Machine Translation as Constrained HMM | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3038 | Assessing Uncertainty in Similarity Scoring: Performance & Fairness in Face Recognition | 5.33 | 6.33 | 1.25 | 1.00 | |
| 3039 | Explanation-aware Soft Ensemble Empowers Large Language Model In-context Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3040 | Nuisance-Robust Weighting Network for End-to-End Causal Effect Estimation | 5.50 | 6.00 | 1.41 | 0.50 | |
| 3041 | Efficient Recomputation of Marginal Likelihood upon Adding Training Data in Gaussian Processes and Simulator Fusion | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3042 | InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining | 5.33 | 6.33 | 1.25 | 1.00 | |
| 3043 | Stochastic Vision Transformers with Wasserstein Distance-Aware Attention | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3044 | MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3045 | GlycoNMR: A Carbohydrate-Specific NMR Chemical Shift Dataset for Machine Learning Research | 5.33 | 5.67 | 0.47 | 0.33 | |
| 3046 | Constrained Parameter Regularization | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3047 | Generate to Discriminate: Expert Routing for Continual Learning | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3048 | Detecting Deepfakes Without Seeing Any | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3049 | Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3050 | M-BioBERTa: Modular RoBERTa-based Model for Biobank-scale Unified Representations | 4.67 | 5.33 | 2.05 | 0.67 | |
| 3051 | Instance Segmentation with Supervoxel Based Topological Loss Function | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3052 | Towards Complete Expressiveness Capacity of Mixed Multi-Agent Q Value Function | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3053 | Quantum Speedups in Linear Programming via Sublinear Multi-Gibbs Sampling | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3054 | Simplifying Referred Visual Search with Conditional Contrastive Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3055 | Exposing the Silent Hidden Impact of Certified Training in Reinforcement Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3056 | Analyzing the Effects of Emulating on the Reinforcement Learning Manifold | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3057 | HART: Efficient Adaptation via Regularized Autoregressive Parameter Generation | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3058 | Adversarial Feature Map Pruning for Backdoor | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3059 | Two Heads Are Better Than One: Exploiting Both Sequence and Graph Models in AMR-To-Text Generation | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3060 | Generative Modeling of Individual Behavior at Scale | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3061 | Programmable Synthetic Data Generation | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3062 | HFDream: Improving 3D Generation via Human-Assisted Multi-view Text-to-Image Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3063 | Variable resolution: improving scene visual question answering with a limited pixel budget | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3064 | Evaluating Language Models Through Negotiations | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3065 | Effective and Parameter-Efficient Reusing Fine-Tuned Models | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3066 | Image Background Serves as Good Proxy for Out-of-distribution Data | 5.17 | 5.33 | 1.80 | 0.17 | | 3, 3, 5, 6, 6, 8 | | 3, 3, 6, 6, 6, 8 |
|
| 3067 | Whittle Index with Multiple Actions and State Constraint for Inventory Management | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3068 | OfflineLight: An Offline Reinforcement Learning Model for Traffic Signal Control | 3.67 | 5.33 | 0.47 | 1.67 | |
| 3069 | Learning to Extrapolate and Adjust: Two-Stage Meta-Learning for Concept Drift in Online Time Series Forecasting | 4.67 | 5.33 | 1.49 | 0.67 | | 3, 6, 3, 6, 5, 5 | | 5, 6, 3, 8, 5, 5 |
|
| 3070 | Provable Representation with Efficient Planning for Partially Observable Reinforcement Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3071 | Interactive Model Correction with Natural Language | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3072 | Robustifying and Boosting Training-Free Neural Architecture Search | 4.67 | 5.33 | 2.05 | 0.67 | |
| 3073 | Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3074 | Clip21: Error Feedback for Gradient Clipping | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3075 | What and How does In-Context Learning Learn? Bayesian Model Averaging, Parameterization, and Generalization | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3076 | SpecFormer: Guarding Vision Transformer Robustness via Maximum Singular Value Penalization | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3077 | Escaping Saddle Point Efficiently in Minimax and Bilevel Optimizations | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3078 | Adversarial Machine Unlearning: A Stackelberg Game Approach | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3079 | LMCC-MBC: Metric-Constrained Model-Based Clustering with Wasserstein-2 Distance of Gaussian Markov Random Fields | 4.67 | 5.67 | 0.47 | 1.00 | |
| 3080 | Who Leaked the Model? Tracking IP Infringers in Accountable Federated Learning | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3081 | LipSim: A Provably Robust Perceptual Similarity Metric | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3082 | Wording Image for Domain-Invariant Representation in Domain Generalization | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3083 | Locally Adaptive Federated Learning | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3084 | Smoothing for exponential family dynamical systems | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3085 | Routing with Rich Text Queries via Next-Vertex Prediction Models | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3086 | GIST: Generating Image-Specific Text for Fine-grained Object Representations | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3087 | Best Arm Identification for Stochastic Rising Bandits | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3088 | On the Generalization of Training-based ChatGPT Detection Methods | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3089 | PROSE: Predicting Operators and Symbolic Expressions using Multimodal Transformers | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3090 | Stateless Mean-Field Games: A Framework for Independent Learning with Large Populations | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3091 | When Witnesses Defend: A Witness Graph Topological Layer for Adversarial Graph Learning | 4.33 | 5.33 | 0.47 | 1.00 | |
| 3092 | Beyond Implicit Bias: The Insignificance of SGD Noise in Online Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3093 | Planning to Go Out-of-Distribution in Offline-to-Online Reinforcement Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3094 | What Makes for Good Visual Tokenizers for Large Language Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3095 | DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3096 | Adversarial Imitation Learning from Visual Observations using Latent Information | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3097 | Graph layouts and graph contrastive learning via neighbour embeddings | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3098 | Unified Anomaly Detection via Multi-Scale Contrasted Memory | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3099 | HAICO-CN: Human-AI Collaboration By Cluster-wise Noisy-Label Augmentation | 4.67 | 6.00 | 1.41 | 1.33 | |
| 3100 | Game-Theoretic Robust Reinforcement Learning Handles Temporally-Coupled Perturbations | 4.00 | 5.33 | 0.47 | 1.33 | |
| 3101 | Is Training Necessary for Representation Learning | 4.67 | 5.67 | 0.47 | 1.00 | |
| 3102 | A Recipe for Watermarking Diffusion Models | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3103 | Enhancing Transferable Adversarial Attacks on Vision Transformers through Gradient Normalization Scaling and High-Frequency Adaptation | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3104 | Bidirectional-Reachable Hierarchical RL with Mutually Responsive Policies | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3105 | FedEBA+: Towards Fair and Effective Federated Learning via Entropy-based Model | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3106 | Attribute Based Interpretable Evaluation Metrics for Generative Models | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3107 | Dynamic Continuous Hyperparameter Tuning for Generalized Linear Contextual Bandits | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3108 | Sparser, Better, Deeper, Stronger: Improving Sparse Training with Exact Orthogonal Initialization | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3109 | AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3110 | 3D-GOI: 3D GAN Omni-Inversion for Multifaceted and Multi-object Editing | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3111 | Sequential Bayesian Continual Learning with Meta-Learned Neural Networks | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3112 | Extending to New Domains without Visual and Textual Oracles | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3113 | Rethinking the OoD Generalization for Deep Neural Network: A Frequency Domain Perspective | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3114 | LCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3115 | Physics-infused Intention Network for Crowd Simulation | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3116 | Towards Faithful Neural Network Intrinsic Interpretation with Shapley Additive Self-Attribution | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3117 | Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models | 5.50 | 5.33 | 0.47 | -0.17 | |
| 3118 | A Latent Generative Model for Closed-set and Open-set Recognition | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3119 | Structural Knowledge Informed Continual Multivariate Time Series Forecasting | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3120 | AED: Adaptable Error Detection for Few-shot Imitation Policy | 4.00 | 5.33 | 0.47 | 1.33 | |
| 3121 | Prediction Risk and Estimation Risk of the Ridgeless Least Squares Estimator under General Assumptions on Regression Errors | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3122 | GPS-SSL: Guided Positive Sampling to Inject Prior into Self-Supervised Learning | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3123 | Stoichiometry Representation Learning with Polymorphic Crystal Structures | 5.33 | 5.67 | 2.05 | 0.33 | |
| 3124 | Learning Guarantees for Non-convex Pairwise SGD with Heavy Tails | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3125 | Momentum-driven Noise-free Guided Conditional Sampling for Denoising Diffusion Probabilistic Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3126 | Achieving Human Parity in Content-Grounded Datasets Generation | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3127 | Enhancing Length Extrapolation in Sequential Models with Pointer-Augmented Neural Memory | 5.33 | 5.67 | 2.05 | 0.33 | |
| 3128 | LaMPP: Language Models as Probabilistic Priors for Perception and Action | 5.33 | 5.67 | 0.47 | 0.33 | |
| 3129 | In-Context Learning with Retrieval Augmented Encoder-Decoder Language Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3130 | Variance Reduced Halpern Iteration for Finite-Sum Monotone Inclusions | 4.33 | 6.00 | 0.00 | 1.67 | |
| 3131 | Bi-Level Optimization for Pseudo-Labeling Based Semi-Supervised Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3132 | Confidence-Based Model Selection: When to Take Shortcuts in Spurious Settings | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3133 | Natural Counterfactuals With Necessary Backtracking | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3134 | Graph Representation Learning with Multi-granular Semantic Ensemble | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3135 | Augmenting Negative Representation for Continual Self-Supervised Learning | 4.33 | 5.33 | 0.47 | 1.00 | |
| 3136 | Chameleon: Increasing Label-Only Membership Leakage with Adaptive Poisoning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3137 | Robust NAS benchmark under adversarial training: assessment, theory, and beyond | 5.33 | 5.67 | 0.47 | 0.33 | |
| 3138 | Reward Collapse in Aligning Large Language Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3139 | Efficient Detection of LLM-generated Texts with a Bayesian Surrogate Model | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3140 | Towards 4D Human Video Stylization | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3141 | Guided Evolution with Binary Discriminators for ML Program Search | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3142 | Enriching Time Series Representation: Integrating a Noise-Resilient Sampling Strategy with an Efficient Encoder Architecture | 5.00 | 5.33 | 1.11 | 0.33 | | 6, 6, 3, 3, 6, 6 | | 6, 6, 5, 3, 6, 6 |
|
| 3143 | LoRA-FA: Memory-efficient Low-rank Adaptation for Large Language Models Fine-tuning | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3144 | CONFIDE: CONtextual FInite DifferencE modelling of PDEs | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3145 | Calibration Bottleneck: What Makes Neural Networks less Calibratable? | 4.67 | 5.33 | 2.05 | 0.67 | |
| 3146 | Evaluating Hallucinations in Chinese Large Language Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3147 | BWS: Best Window Selection Based on Sample Scores for Data Pruning across Broad Ranges | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3148 | SITReg: Multi-resolution architecture for symmetric, inverse consistent, and topology preserving image registration using deformation inversion layers | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3149 | On the Robustness of Latent Diffusion Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3150 | Reinforcement Learning with Human Feedback: Learning Dynamic Choices via Pessimism | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3151 | Pretrained deep models outperform GBDTs in Learning-To-Rank under label scarcity | 4.00 | 5.33 | 0.47 | 1.33 | |
| 3152 | Behind the Myth of Exploration in Policy Gradients | 6.00 | 5.33 | 0.47 | -0.67 | |
| 3153 | HyperAttention: Long-context Attention in Near-Linear Time | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3154 | Unsupervised Feature Selection using a Basis of Feature Space and Self-Representation Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3155 | Large Language Models Are Not Strong Abstract Reasoners | 5.50 | 5.33 | 0.47 | -0.17 | |
| 3156 | Efficient Precision and Recall Metrics for Assessing Generative Models using Hubness-aware Sampling | 5.67 | 5.33 | 0.47 | -0.33 | |
| 3157 | Subgraph-To-Node Translation for Efficient Representation Learning of Subgraphs | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3158 | WI3D: Weakly Incremental 3D Detection via Visual Prompts | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3159 | RTMPose: Real-Time Models for Multi-Person Pose Estimation | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3160 | New Insight of Variance reduce in Zero-Order Hard-Thresholding: Mitigating Gradient Error and Expansivity Contradictions | 5.33 | 5.33 | 1.11 | 0.00 | | 6, 6, 3, 6, 5, 6 | | 6, 6, 3, 6, 5, 6 |
|
| 3161 | ROBUST SPARSE AND DENSE MATCHING | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3162 | End-to-End Neural Network Compression via $frac{ell_1}{ell_2}$ Regularized Latency Surrogates | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3163 | HYBRID GRANULARITY DISTRIBUTION ESTIMATION FOR FEW-SHOT LEARNING: STATISTICS TRANSFER FROM CATEGORIES AND INSTANCES | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3164 | TENSORIZED ATTENTION MODEL | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3165 | TriSAM: Tri-Plane SAM for zero-shot cortical blood vessel segmentation in VEM images | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3166 | LMDX: Language Model-based Document Information Extraction and Localization | 4.33 | 5.67 | 0.47 | 1.33 | |
| 3167 | Anarchic Federated Bilevel Optimization | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3168 | Butterfly Effects of SGD Noise: Error Amplification in Behavior Cloning and Autoregression | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3169 | Curriculum Reinforcement Learning via Morphology-Environment Co-Evolution | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3170 | Interpreting Equivariant Representations | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3171 | Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3172 | Ratio-Residual Diffusion Model for Image Restoration | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3173 | Rethinking the Temporal Modeling for Time Series Forecasting with Hybrid Modeling | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3174 | AniHead: Efficient and Animatable 3D Head Avatars Generation | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3175 | Ditto: Quantization-Aware Secure Inference of Transformers upon MPC | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3176 | Matrix Manifold Neural Networks++ | 5.33 | 5.67 | 2.05 | 0.33 | |
| 3177 | Probability-dependent gradient decay in large margin softmax | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3178 | Partial Optimal Transport for Open-set Semi-supervised Learning | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3179 | Search-Adaptor: Text Embedding Customization for Information Retrieval | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3180 | FlexCap: Generating Rich, Localized, and Flexible Captions in Images | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3181 | SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3182 | EZ-CLIP: EFFICIENT ZERO-SHOT VIDEO ACTION RECOGNITION | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3183 | DiffCPS: Diffusion Model based Constrained Policy Search for Offline Reinforcement Learning | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3184 | The Best Defense is Attack: Repairing Semantics in Textual Adversarial Examples | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3185 | Grouplane: End-to-End 3D Lane Detection with Channel-Wise Grouping | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3186 | Careful at Estimation and Bold at Exploration for Deterministic Policy Gradient Algorithm | 4.33 | 5.33 | 0.47 | 1.00 | |
| 3187 | ShareFormer: Share Attention for Efficient Image Restoration | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3188 | SemiAugIR: Semi-supervised Infrared Small Target Detection via Thermodynamics-Inspired Data Augmentation | 5.33 | 6.00 | 2.94 | 0.67 | |
| 3189 | SEEKER: Semi-Supervised Knowledge Transfer for Query-Efficient Model Extraction | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3190 | Stay on Topic with Classifier-Free Guidance | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3191 | Query-Efficient Offline Preference-Based Reinforcement Learning via In-Dataset Exploration | 4.67 | 5.33 | 2.05 | 0.67 | |
| 3192 | NLPBench: Evaluating Large Language Models on Solving NLP Problems | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3193 | FTA: Stealthy and Adaptive Backdoor Attack with Flexible Triggers on Federated Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3194 | EVEREST: Efficient Masked Video Autoencoder by Removing Redundant Spatiotemporal Tokens | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3195 | TransCues: Boundary and Reflection-empowered Pyramid Vision Transformer for Semantic Transparent Object Segmentation | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3196 | Flatness-aware Adversarial Attack | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3197 | When Semantic Segmentation Meets Frequency Aliasing | 5.33 | 6.00 | 1.41 | 0.67 | |
| 3198 | UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3199 | An LLM can Fool Itself: A Prompt-Based Adversarial Attack | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3200 | Exploring the Impact of Information Entropy Change in Learning Systems | 5.33 | 5.33 | 2.05 | 0.00 | |
| 3201 | Deceptive-NeRF: Enhancing NeRF Reconstruction using Pseudo-Observations from Diffusion Models | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3202 | Hyperbolic Active Learning for Semantic Segmentation under Domain Shift | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3203 | EcoAssistant: Using LLM Assistant More Affordably and Accurately | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3204 | Independently-prepared Query-efficient Model Selection | 4.67 | 5.33 | 2.05 | 0.67 | |
| 3205 | KITS: Inductive Spatio-Temporal Kriging with Increment Training Strategy | 5.50 | 5.67 | 0.47 | 0.17 | |
| 3206 | Multiple Positive Views in Self-Supervised Learning | 5.33 | 5.33 | 0.47 | 0.00 | |
| 3207 | Knowledge Distillation via Flow Matching | 5.33 | 4.50 | 0.87 | -0.83 | |
| 3208 | LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition | 4.67 | 5.33 | 0.47 | 0.67 | |
| 3209 | Adversarial Latent Feature Augmentation for Fairness | 5.17 | 5.29 | 1.03 | 0.12 | | 6, 3, 6, 5, 5, 6 | | 6, 3, 6, 5, 5, 6, 6 |
|
| 3210 | Beyond Disentanglement: On the Orthogonality of Learned Representations | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3211 | Directional Rank Reduction for Backdoor Defense | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3212 | Recurrent Distance-Encoding Neural Networks for Graph Representation Learning | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3213 | MetaFormer with Holistic Attention Modelling Improves Few-Shot Classification | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3214 | TinyTrain: Deep Neural Network Training at the Extreme Edge | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3215 | Personalized Language Generation via Bayesian Metric Augmented Retrieval | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3216 | Time2Image: A Unified Image Representation Framework for Time Series Classification | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3217 | Summing Up the Facts: Additive Mechanisms behind Factual Recall in LLMs | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3218 | Knowledge Graph Completion by Intermediate Variables Regularization | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3219 | GatedMTL: Learning to Share, Specialize, and Prune Representations for Multi-task Learning | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3220 | Chat Vector: A Simple Approach to Equip LLMs With New Language Chat Capabilities | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3221 | Bayesian Vector Optimization with Gaussian Processes | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3222 | Meta- (out-of-context) learning in neural networks | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3223 | Gandalf: Learning label correlations in Extreme Multi-label Classification via Label Features | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3224 | $gamma$-Orthogonalized Tensor Deflation: Towards Robust & Interpretable Tensor Decomposition in the Presence of Correlated Components | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3225 | DfPO: Degeneration-free Policy Optimization via Action Masking in Natural Language Action Spaces | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3226 | Semi-Anchored Gradient Methods for Nonconvex-Nonconcave Minimax Problems | 4.25 | 5.25 | 1.30 | 1.00 | |
| 3227 | Fast Conditional Intervention in Algorithmic Recourse with Reinforcement Learning | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3228 | TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3229 | MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3230 | Understanding Multimodal Instruction Format for In-context Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3231 | Addressing Catastrophic Forgetting and Loss of Plasticity in Neural Networks | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3232 | Generalization Error Analysis of Deep Physical Models With Latent Variables Trained on Trajectory Data | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3233 | Understanding Retrieval Augmentation for Long-Form Question Answering | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3234 | Bias Runs Deep: Implicit Reasoning Biases in Persona-Assigned LLMs | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3235 | Are Models Biased on Text without Gender-related Language? | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3236 | UniAudio: An Audio Foundation Model Toward Universal Audio Generation | 5.25 | 5.25 | 3.19 | 0.00 | |
| 3237 | Stochastic two points method for deep model gradient free optimization | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3238 | Toward Student-oriented Teacher Network Training for Knowledge Distillation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3239 | DiffDock-Pocket: Diffusion for Pocket-Level Docking with Sidechain Flexibility | 5.25 | 5.50 | 1.80 | 0.25 | |
| 3240 | Learning Diverse Quadruped Locomotion Gaits via Reward Machines | 5.33 | 5.25 | 1.79 | -0.08 | |
| 3241 | Simple Hierarchical Planning with Diffusion | 5.00 | 5.75 | 0.43 | 0.75 | |
| 3242 | Fine-Tuning Language Models with Advantage-Induced Policy Alignment | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3243 | Estimating Unknown Population Sizes Using Hypergeometric Maximum Likelihood | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3244 | Two Facets of SDE Under an Information-Theoretic Lens: Generalization of SGD via Training Trajectories and via Terminal States | 4.75 | 5.75 | 0.43 | 1.00 | |
| 3245 | Rectifying Group Irregularities in Explanations for Distribution Shift | 4.25 | 5.25 | 0.43 | 1.00 | |
| 3246 | BadChain: Backdoor Chain-of-Thought Prompting for Large Language Models | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3247 | LayoutDETR: Detection Transformer Is a Good Multimodal Layout Designer | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3248 | Explore, Establish, Exploit: Red Teaming Language Models from Scratch | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3249 | CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3250 | RL Algorithms are Information-State Policies in the Bayes-Adaptive MDP | 4.25 | 5.25 | 1.79 | 1.00 | |
| 3251 | Investigating the Benefits of Projection Head for Representation Learning | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3252 | A Variational Perspective on Solving Inverse Problems with Diffusion Models | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3253 | Baseline Defenses for Adversarial Attacks Against Aligned Language Models | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3254 | Deep Unlearning: Fast and Efficient Training-free Approach to Controlled Forgetting | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3255 | Let's do the time-warp-attend: Learning topological invariants of dynamical systems | 4.50 | 5.25 | 1.30 | 0.75 | |
| 3256 | One-shot Active Learning Based on Lewis Weight Sampling for Multiple Deep Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3257 | Towards Reliable Evaluation and Fast Training of Robust Semantic Segmentation Models | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3258 | Neural Diffusion Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3259 | A Stable, Fast, and Fully Automatic Learning Algorithm for Predictive Coding Networks | 4.00 | 5.25 | 1.30 | 1.25 | |
| 3260 | Prospector: Improving LLM Agents with Self-Asking and Trajectory Ranking | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3261 | A Theory of Unimodal Bias in Multimodal Learning | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3262 | How well does Persistent Homology generalize on graphs? | 4.25 | 5.25 | 1.30 | 1.00 | |
| 3263 | Backdoor Secrets Unveiled: Identifying Backdoor Data with Optimized Scaled Prediction Consistency | 4.25 | 5.25 | 1.30 | 1.00 | |
| 3264 | CUS3D: A New Comprehensive Urban-Scale Semantic Segmentation 3D Benchmark Dataset | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3265 | Improved Invariant Learning for Node-level Out-of-distribution Generalization on Graphs | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3266 | LaDe: The First Comprehensive Last-mile Express Dataset from Industry | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3267 | Toward a Mechanistic Understanding of Stepwise Inference in Transformers: A Synthetic Graph Navigation Model | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3268 | Learning HJB Viscosity Solutions with PINNs for Continuous-Time Reinforcement Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3269 | Active Domain Adaptation Of Medical Images Using Feature Disentanglement | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3270 | Are Spiking Neural Networks more expressive than Artificial Neural Networks? | 4.25 | 5.25 | 1.30 | 1.00 | |
| 3271 | HiFi-123: Towards High-fidelity One Image to 3D Content Generation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3272 | EWoK: Tackling Robust Markov Decision Processes via Estimating Worst Kernel | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3273 | Improving Prompt-based Continual Learning with Key-Query Orthogonal Projection and Prototype-based One-Versus-All | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3274 | Learn to Achieve Out-of-the-Box Imitation Ability from Only One Demonstration | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3275 | ED-NeRF: Efficient Text-Guided Editing of 3D Scene With Latent Space NeRF | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3276 | Rethinking Decision Transformer via Hierarchical Reinforcement Learning | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3277 | Online Feature Updates Improve Online (Generalized) Label Shift Adaptation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3278 | VersVideo: Leveraging Enhanced Temporal Diffusion Models for Versatile Video Generation | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3279 | Controlling Vision-Language Models for Universal Image Restoration | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3280 | Personalized Facial Expressions and Head Poses for Speech-Driven 3D Facial Animation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3281 | SENSITIVITY-INFORMED REGULARIZATION FOR OFFLINE BLACK-BOX OPTIMIZATION | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3282 | Double-I Watermark: Protecting Model Copyright for LLM Fine-tuning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3283 | Generative Pre-Trained Speech Language Model with Efficient Hierarchical Transformer | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3284 | Benchmarking Smoothness and Reducing High-Frequency Oscillations in Continuous Control Policies | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3285 | Explaining Time Series via Contrastive and Locally Sparse Perturbations | 4.75 | 5.75 | 0.43 | 1.00 | |
| 3286 | DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3287 | G4SATBench: Benchmarking and Advancing SAT Solving with Graph Neural Networks | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3288 | Latent Consistency Models: Synthesizing High-Resolution Images with Few-step Inference | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3289 | Deep Equilibrium Multimodal Fusion | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3290 | Making Batch Normalization Great in Federated Deep Learning | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3291 | AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3292 | Does resistance to style-transfer equal Shape Bias? Evaluating shape bias by distorted shape | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3293 | Self-Specialization: Uncovering Latent Expertise within Large Language Models | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3294 | MaSS: Multi-attribute Selective Suppression for Utility-preserving Data Transformation from an Information-theoretic Perspective | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3295 | BrainLM: A foundation model for brain activity recordings | 5.25 | 6.00 | 0.00 | 0.75 | |
| 3296 | Improving Prototypical Part Networks with Reward Reweighing, Reselection, and Retraining | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3297 | Making Predictors More Reliable with Selective Recalibration | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3298 | Learning to reason iteratively and parallelly for complex visual reasoning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3299 | A Neural-preconditioned Poisson Solver for Mixed Dirichlet and Neumann Boundary Conditions | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3300 | Multitask Contrastive Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3301 | A Prefrontal Cortex-inspired Architecture for Planning in Large Language Models | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3302 | Performance Bounds for Active Binary Testing with Information Maximization | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3303 | Learning from Integral Losses in Physics Informed Neural Networks | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3304 | On the Tool Manipulation Capability of Open-sourced Large Language Models | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3305 | What Improves the Generalization of Graph Transformer? A Theoretical Dive into Self-attention and Positional Encoding | 5.67 | 5.25 | 2.59 | -0.42 | |
| 3306 | Hypergraph Neural Networks through the Lens of Message Passing: A Common Perspective to Homophily and Architecture Design | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3307 | Masked Autoencoders with Multi-Window Local-Global Attention Are Better Audio Learners | 4.00 | 5.25 | 1.30 | 1.25 | |
| 3308 | Efficiency Pentathlon: A Standardized Benchmark for Efficiency Evaluation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3309 | How Robust Are Energy-Based Models Trained With Equilibrium Propagation? | 5.25 | 6.00 | 0.00 | 0.75 | |
| 3310 | Formal Verification for Neural Networks with General Nonlinearities via Branch-and-Bound | 5.50 | 5.25 | 0.43 | -0.25 | |
| 3311 | Contextual Molecule Representation Learning from Chemical Reaction Knowledge | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3312 | Convex and Bilevel Optimization for Neuro-Symbolic Inference and Learning | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3313 | A Topological Perspective on Demystifying GNN-Based Link Prediction Performance | 4.00 | 5.25 | 1.30 | 1.25 | |
| 3314 | Open the Black Box: Step-based Policy Updates for Temporally-Correlated Episodic Reinforcement Learning | 4.00 | 6.00 | 0.00 | 2.00 | |
| 3315 | Contextual Vision Transformers for Robust Representation Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3316 | LM-Switch: Transforming Word Embedding Space for Flexible Language Model Steering | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3317 | VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3318 | Ring-A-Bell! How Reliable are Concept Removal Methods For Diffusion Models? | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3319 | Joint Representations for Reinforcement Learning with Multiple Sensors | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3320 | Variance-Reduced Meta-Learning via Laplace Approximation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3321 | Mark My Words: Repurposing LLMs for Specialized Domains via Ability Tokens | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3322 | Fool Your Large (Vision and) Language Models with Embarrassingly Simple Permutations | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3323 | Sparse MoE as a New Treatment: Addressing Forgetting, Fitting, Learning Issues in Multi-Modal Multi-Task Learning | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3324 | Improving Sample Efficiency of Model-Free Algorithms for Zero-Sum Markov Games | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3325 | Closed-Form Diffusion Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3326 | On partial prototype collapse in clustering-based self-supervised learning | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3327 | Weakly Supervised Virus Capsid Detection with Image-Level Annotations in Electron Microscopy Images | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3328 | VIDEOPROMPTER: AN ENSEMBLE OF FOUNDATIONAL MODELS FOR ZERO-SHOT VIDEO UNDERSTANDING | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3329 | A Demon at Work: Leveraging Neuron Death for Efficient Neural Network Pruning | 4.00 | 5.50 | 0.50 | 1.50 | |
| 3330 | Block-local learning with probabilistic latent representations | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3331 | UniVis: A Universal Framework for Computer Vision Tasks | 5.75 | 5.25 | 1.79 | -0.50 | |
| 3332 | Multimodal Chain-of-Thought Reasoning in Language Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3333 | Advancing the Lower Bounds: an Accelerated, Stochastic, Second-order Method with Optimal Adaptation to Inexactness | 4.75 | 5.25 | 2.59 | 0.50 | |
| 3334 | Spatio-Temporal Graph Knowledge Distillation | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3335 | Sequential Condition Evolved Interaction Knowledge Graph for Traditional Chinese Medicine Recommendation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3336 | StructComp: Substituting propagation with Structural Compression in Training Graph Contrastive Learning | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3337 | Implicit Intermediate Supervision for Learning Complex Functions | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3338 | JudgeLM : Fine-tuned Large Language Models are Scalable Judges | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3339 | The Alignment Problem from a Deep Learning Perspective: A Position Paper | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3340 | Emergent Language based Dialog for Collaborative Multi-agent Navigation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3341 | Dispatching Ambulances using Deep Reinforcement Learning | 5.33 | 5.25 | 1.79 | -0.08 | |
| 3342 | Proximal Curriculum with Task Correlations for Deep Reinforcement Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3343 | MMPareto: Innocent Uni-modal Assistance for Enhanced Multi-modal Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3344 | Eureka-Moments in Transformers: Multi-Step Tasks Reveal Softmax Induced Optimization Problems | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3345 | LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3346 | Stealthy Imitation: Reward-guided Environment-free Policy Stealing | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3347 | Perturb-and-Compare Approach for Detecting Out-of-Distribution Samples in Constrained Access Environments | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3348 | FARSE-CNN: Fully Asynchronous, Recurrent and Sparse Event-Based CNN | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3349 | Learning Embeddings for Sequential Tasks Using Population of Agents | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3350 | Improved Variational Bayesian Phylogenetic Inference using Mixtures | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3351 | Periodic and Random Sparsity for Multivariate Long-Term Time-Series Forecasting | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3352 | Towards a Better Theoretical Understanding of Independent Subnetwork Training | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3353 | An Instance-Level Framework for Multi-tasking Graph Self-Supervised Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3354 | Segment Anything Model is a Good Teacher for Local Feature Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3355 | Rotation Invariant Quantization for Model Compression | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3356 | A Private Watermark for Large Language Models | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3357 | Improving Neural Program Induction by Reflecting on Failures | 3.75 | 5.25 | 1.79 | 1.50 | |
| 3358 | BTBS-LNS: A Binarized-Tightening, Branch and Search Approach of Learning Large Neighborhood Search Policies for MIP | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3359 | Stability and Generalization in Free Adversarial Training | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3360 | Unified Medical Image Pre-training in Language-Guided Common Semantic Space | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3361 | Reliable Classifications with Guaranteed Confidence using the Dempster-Shafer Theory of Evidence | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3362 | Large Language Models Can Be Good Privacy Protection Learners | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3363 | Weakly Supervised Fine-grained Scene Graph Generation via Large Language Model | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3364 | LLM Blueprint: Enabling Text-to-Image Generation with Complex and Detailed Prompts | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3365 | AUTOPARLLM: GNN-Guided Automatic Code Parallelization using Large Language Models | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3366 | A Simple Data Augmentation for Feature Distribution Skewed Federated Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3367 | Data-Efficient Molecular Generation with Hierarchical Textual Inversion | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3368 | Fixed Non-negative Orthogonal Classifier: Inducing Zero-mean Neural Collapse with Feature Dimension Separation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3369 | LLM-driven Hateful Meme Detection via Cross-modal Memorizing and Self-rejection Training | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3370 | Don't Play Favorites: Minority Guidance for Diffusion Models | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3371 | ObjectNet Captions: Models are not superhuman captioners | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3372 | Visual Semantic Learning via Early Stopping in Inverse Scale Space | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3373 | Non-Visible Light Data Synthesis: A Case Study for Synthetic Aperture Radar Imagery | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3374 | Neural Auto-designer for Enhanced Quantum Kernels | 4.25 | 5.25 | 1.30 | 1.00 | |
| 3375 | The Blessings of Multiple Treatments and Outcomes in Treatment Effect Estimation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3376 | Enhancing Neural Network Performance with Leader-Follower Architecture and Local Error Signals | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3377 | On Formal Feature Attribution and Its Approximation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3378 | Optimum Shifting to Stabilize Training and Improve Generalization of Deep Neural Networks | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3379 | Reshape and Adapt for Output Quantization (RAOQ): Quantization-aware Training for In-memory Computing Systems | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3380 | Learning Scalable Causal Discovery Policies with Adversarial Reinforcement Learning | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3381 | What Makes ImageNet Look Unlike LAION | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3382 | A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Actively Validating Low-Confidence Generation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3383 | Active Teacher Selection for Reinforcement Learning from Human Feedback | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3384 | Mildly Constrained Evaluation Policy for Offline Reinforcement Learning | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3385 | Constructing Semantics-Aware Adversarial Examples with Probabilistic Perspective | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3386 | Neural Neighborhood Search for Multi-agent Path Finding | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3387 | UpFusion: Novel View Diffusion from Unposed Sparse View Observations | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3388 | Efficient Continual Pre-training for Building Domain Specific Large Language Models | 5.50 | 5.25 | 0.43 | -0.25 | |
| 3389 | Density Ratio Estimation-based Bayesian Optimization with Semi-Supervised Learning | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3390 | Borda Regret Minimization for Generalized Linear Dueling Bandits | 5.75 | 5.25 | 0.43 | -0.50 | |
| 3391 | Pricing with Contextual Elasticity and Heteroscedastic Valuation | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3392 | Learning Sequence Attractors in Recurrent Networks with Hidden Neurons | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3393 | Gradient-free Proxy for Efficient Language Model Search | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3394 | Learning with Temporal Label Noise | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3395 | Illuminating Protein Function Prediction through Inter-Protein Similarity Modeling | 4.50 | 5.25 | 0.97 | 0.75 | | 6, 5, 3, 6, 5, 5, 3, 3 | | 6, 6, 6, 6, 5, 5, 3, 5 |
|
| 3396 | Neural Network Expressive Power Analysis Via Manifold Topology | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3397 | Test-Time Training on Nearest Neighbors for Large Language Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3398 | Task adaptation by biologically inspired stochastic comodulation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3399 | System Identification of Neural Systems: Going Beyond Images to Modelling Dynamics | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3400 | Prompting Language-Informed Distribution for Compositional Zero-Shot Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3401 | A Linear Algebraic Framework for Counterfactual Generation | 4.50 | 5.25 | 1.30 | 0.75 | |
| 3402 | High-Dimensional Safe Exploration via Optimistic Local Latent Safe Optimization | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3403 | Tree-Planner: Efficient Close-loop Task Planning with Large Language Models | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3404 | Unsupervised open-vocabulary action recognition with an autoregressive model | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3405 | Extending Multi-modal Contrastive Representations | 5.00 | 6.00 | 0.00 | 1.00 | |
| 3406 | Memoization-Aware Bayesian Optimization for AI Pipelines with Unknown Costs | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3407 | Interpreting Adaptive Gradient Methods by Parameter Scaling for Learning-Rate-Free Optimization | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3408 | TeLLMe what you see: Using LLMs to Explain Neurons in Vision Models | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3409 | Model guidance via explanations turns image classifiers into segmentation models | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3410 | SASSL: Enhancing Self-Supervised Learning via Neural Style Transfer | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3411 | Why not both? Combining Bellman losses in deep reinforcement learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3412 | Breadth First Exploration in Grid-based Reinforcement Learning | 3.75 | 5.25 | 0.43 | 1.50 | |
| 3413 | AMPipe: Accelerating MoE Model Training with Intra-Block Pipelining | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3414 | Overcoming Distribution Mismatch in Quantizing Image Super-Resolution Networks | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3415 | Long-term Time Series Forecasting with Vision Transformer | 4.25 | 5.25 | 0.43 | 1.00 | |
| 3416 | Beyond Language: Empowering Unsupervised Machine Translation with Cross-modal Alignment | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3417 | Support Vector-based Shapley Value Estimation for Feature Selection and Explanation | 5.75 | 5.25 | 0.43 | -0.50 | |
| 3418 | Generative Retrieval with Large Language Models | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3419 | Interpreting the Inner Mechanisms of Large Language Models in Mathematical Addition | 5.75 | 5.25 | 1.30 | -0.50 | |
| 3420 | Bad Habits: Policy Confounding and Out-of-Trajectory Generalization in Reinforcement Learning | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3421 | Evaluating the Instruction-Following Robustness of Large Language Models to Prompt Injection | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3422 | LSP: Low-Power Semi-structured Pruning for Vision Transformers | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3423 | The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3424 | Multi-Prompt Denoised Self-Training for Open-Vocabulary Model Adaptation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3425 | Model Based Inference of Synaptic Plasticity Rules | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3426 | Class-Imbalanced Graph Learning without Class Rebalancing | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3427 | A Unified and General Framework for Continual Learning | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3428 | Debiased Machine Learning and Network Cohesion for Doubly-Robust Differential Reward Models in Contextual Bandits | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3429 | Differentially Private Vision-Language Foundation Models via Image Captioning | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3430 | Scaff-PD: Communication Efficient Fair and Robust Federated Learning | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3431 | Online Speculative Decoding | 4.75 | 6.00 | 0.00 | 1.25 | |
| 3432 | Non-targeted Adversarial Attacks on Vision-Language Models via Maximizing Information Entropy | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3433 | Data Overfitting for On-Device Super-Resolution with Dynamic Algorithm and Compiler Co-Design | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3434 | ADOPT: Modified Adam Can Converge with the Optimal Rate with Any Hyperparameters | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3435 | A Multi-resolution Dataset of Self-consistent Cloth Drapes for Physics-based Upsampling | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3436 | Perceptual Measurements, Distances and Metrics | 4.50 | 5.25 | 1.79 | 0.75 | |
| 3437 | Prompt-tuning Latent Diffusion Models for Inverse Problems | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3438 | Label Privacy Source Coding in Vertical Federated Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3439 | Disentangled Acoustic Fields For Multimodal Physical Scene Understanding | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3440 | What's in a Prior? Learned Proximal Networks for Inverse Problems | 4.75 | 5.25 | 1.79 | 0.50 | |
| 3441 | You Only Look at Screens: Multimodal Chain-of-Action Agents | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3442 | Variational Federated Continual Learning | 5.25 | 5.75 | 1.79 | 0.50 | |
| 3443 | PATHS: Parameter-wise Adaptive Two-Stage Training Harnessing Scene Transition Mask Adapters for Video Retrieval | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3444 | P+: Extended Textual Conditioning in Text-to-Image Generation | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3445 | Learning with Complementary Labels Revisited: A Consistent Approach via Negative-Unlabeled Learning | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3446 | Multi-label Learning with Random Circular Vectors | 5.75 | 5.25 | 0.43 | -0.50 | |
| 3447 | STREAM: Spatio-TempoRal Evaluation and Analysis Metric for Video Generative Models | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3448 | Video2StyleGAN: Disentangling Local and Global Variations in a Video | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3449 | Protein Multimer Structure Prediction via PPI-guided Prompt Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3450 | Contrastive Graph Autoencoder for Geometric Polygon Retrieval from Building Datasets | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3451 | On Task Description of In-context Learning: A Study from Information Perspective | 4.25 | 5.25 | 1.79 | 1.00 | |
| 3452 | Masked Dual-Temporal Autoencoders for Semi-Supervised Time-Series Classification | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3453 | FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Object Detection | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3454 | Big Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3455 | KDGCN: A Kernel-based Double-level Graph Convolution Network for Semi-supervised Graph Classification with Scarce Labels | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3456 | A Consistent Lebesgue Measure for Multi-label Learning | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3457 | FourierAugment: Frequency-Based Image Encoding for Resource-Constrained Vision Tasks | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3458 | Make a Donut: Language-Guided Hierarchical EMD-Space Planning for Zero-shot Deformable Object Manipulation | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3459 | Hierarchical Side-Tuning for Vision Transformers | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3460 | AlignCLIP: Enhancing Stable Representations in Vision-Language Pretraining Models through Attention and Prediction Alignment | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3461 | Bootstrapping Audio-Visual Segmentation by Strengthening Audio Cues | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3462 | $pi$2vec: Policy Representation with Successor Features | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3463 | Orthogonal Function Representations for Continuous Armed Bandits | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3464 | Compresso: Structured Pruning with Collaborative Prompting Learns Compact Large Language Models | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3465 | Revealing the Illusion of Joint Multimodal Understanding in VideoQA Models | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3466 | Learning Identifiable Balanced Prognostic Score for Treatment Effect Estimation Under Limited Overlap | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3467 | Efficient Diversified Attack: Multiple Diversification Strategies Lead to the Efficient Adversarial Attacks | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3468 | TSGM: Regular and Irregular Time-series Generation using Score-based Generative Models | 5.25 | 5.75 | 1.30 | 0.50 | |
| 3469 | Boosting Graph Anomaly Detection with Adaptive Message Passing | 5.00 | 5.75 | 0.43 | 0.75 | |
| 3470 | Semi-Supervised Semantic Segmentation via Marginal Contextual Information | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3471 | Corex: Pushing the Boundaries of Complex Reasoning through Multi-Model Collaboration | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3472 | Are Human-generated Demonstrations Necessary for In-context Learning? | 4.50 | 6.50 | 0.87 | 2.00 | |
| 3473 | DEER: A Delay-Resilient Framework for Reinforcement Learning with Variable Delays | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3474 | CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3475 | Enhancing One-Shot Federated Learning Through Data and Ensemble Co-Boosting | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3476 | MoLE: Human-centric Text-to-image Diffusion with Mixture of Low-rank Experts | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3477 | FedSecurity: A Benchmark for Attacks and Defenses in Federated Learning and Federated LLMs | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3478 | Residual Denoising Diffusion Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3479 | DynaVol: Unsupervised Learning for Dynamic Scenes through Object-Centric Voxelization | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3480 | Surface Representation in LiDAR Scenes | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3481 | Interpreting and Controlling Vision Foundation Models via Text Explanations | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3482 | Skills-in-Context Prompting: Unlocking Compositionality in Large Language Models | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3483 | OpenIns3D: Snap and Lookup for 3D Open-vocabulary Instance Segmentation | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3484 | Generalizable Cross-Modality Distillation with Contrastive Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3485 | Improving protein optimization with smoothed fitness landscapes | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3486 | Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3487 | Iterated Deep $Q$-Network: Efficient Learning of Bellman Iterations for Deep Reinforcement Learning | 5.25 | 4.75 | 2.05 | -0.50 | |
| 3488 | MaskedKD: Efficient Distillation of Vision Transformers with Masked Images | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3489 | Unlock Predictable Scaling from Emergent Abilities | 5.25 | 6.00 | 1.22 | 0.75 | |
| 3490 | Scaling Relationship on Learning Mathematical Reasoning with Large Language Models | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3491 | SEAL: Simultaneous Label Hierarchy Exploration And Learning | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3492 | Dreamix: Video Diffusion Models are General Video Editors | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3493 | Explanation Shift: How Did the Distribution Shift Impact the Model? | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3494 | Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3495 | BSPA: Exploring Black-box Stealthy Prompt Attacks against Image Generators | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3496 | Towards Mitigating Architecture Overfitting in Dataset Distillation | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3497 | LISA: Reasoning Segmentation via Large Language Model | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3498 | Momentum Benefits Non-iid Federated Learning Simply and Provably | 3.50 | 5.75 | 1.30 | 2.25 | |
| 3499 | Dissecting Arbitrary-scale Super-resolution Capability from Pre-trained Diffusion Generative Models | 5.50 | 5.25 | 0.43 | -0.25 | |
| 3500 | Anytime Neural Architecture Search on Tabular Data | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3501 | TaCA: Hot-Plugging Upgrades for Foundation Model with Task-agnostic Compatible Adapter | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3502 | Divided Attention: Unsupervised Multiple-object Discovery and Segmentation with Interpretable Contextually Separated Slots | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3503 | Finding Adversarially Robust Graph Lottery Tickets | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3504 | Expert Proximity as Surrogate Rewards for Single Demonstration Imitation Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3505 | Leveraging Task Structures for Improved Identifiability in Neural Network Representations | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3506 | General-purpose Pre-trained Model Towards Cross-domain Molecule Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3507 | ConceptHash: Interpretable Fine-Grained Hashing with Concept Discovery | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3508 | LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3509 | SemPLeS: Semantic Prompt Learning for Weakly-Supervised Semantic Segmentation | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3510 | Adversarial Robust Representation Learning via Contrast and Alignment | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3511 | Causality-Based Black-Box Backdoor Detection | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3512 | Unifying Feature and Cost Aggregation with Transformers for Dense Correspondence | 5.25 | 5.50 | 0.50 | 0.25 | |
| 3513 | Benchmarking Large Language Models as AI Research Agents | 5.25 | 5.25 | 2.86 | 0.00 | |
| 3514 | A Coefficient Makes SVRG Effective | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3515 | Active Learning for Image Segmentation with Binary User Feedback | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3516 | OmniInput: A Model-centric Evaluation Framework through Output Distribution | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3517 | ReBotNet: Fast Real-time Video Enhancement | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3518 | Revisiting the Role of Language Priors in Vision-Language Models | 4.75 | 5.75 | 1.30 | 1.00 | |
| 3519 | Sparsity-Aware Grouped Reinforcement Learning for Designated Driver Dispatch | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3520 | Better Imitation Learning in Discounted Linear MDP | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3521 | FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling | 5.75 | 5.75 | 0.43 | 0.00 | |
| 3522 | Realistic Human Motion Generation with Cross-Diffusion Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3523 | RelationMatch: Matching In-batch Relationships for Semi-supervised Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3524 | Taming Encoder for Zero Fine-tuning Image Customization with Text-to-Image Diffusion Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3525 | Contrastive Diffuser: Planning Towards High Return States via Contrastive Learning | 5.25 | 5.25 | 2.86 | 0.00 | |
| 3526 | MMBench: Is Your Multi-modal Model an All-around Player? | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3527 | Composing Recurrent Spiking Neural Networks using Locally-Recurrent Motifs and Risk-Mitigating Architectural Optimization | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3528 | Large-Scale Public Data Improves Differentially Private Image Generation Quality | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3529 | Dynamic Adapter Merging for Continual Video Question-Answering Learning | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3530 | Temporal Causal Mechanism Transfer for Few-shot Action Recognition | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3531 | Language-Informed Visual Concept Learning | 5.25 | 6.00 | 1.22 | 0.75 | |
| 3532 | DeCUR: decoupling common & unique representations for multimodal self-supervision | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3533 | Angle-optimized Text Embeddings | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3534 | Med-Tuning: Parameter-Efficient Transfer Learning with Fine-Grained Feature Enhancement for Medical Volumetric Segmentation | 4.75 | 5.25 | 0.43 | 0.50 | |
| 3535 | Exploring Target Representations for Masked Autoencoders | 5.25 | 5.25 | 1.30 | 0.00 | |
| 3536 | OpenMixup: A Comprehensive Mixup Benchmark for Visual Classification | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3537 | Unitention: Attend a sample to the dataset | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3538 | Bounded Loss Robustness: Enhancing the MAE Loss for Large-Scale Noisy Data Learning | 5.25 | 5.25 | 1.79 | 0.00 | |
| 3539 | Compressed Context Memory for Online Language Model Interaction | 5.25 | 5.75 | 0.43 | 0.50 | |
| 3540 | Federated Generative Learning with Foundation Models | 5.25 | 5.25 | 0.43 | 0.00 | |
| 3541 | Farzi Data: Autoregressive Data Distillation | 5.20 | 5.00 | 1.10 | -0.20 | | 3, 5, 6, 6, 6 | | 3, 5, 6, 5, 6 |
|
| 3542 | An Intuitive Multi-Frequency Feature Representation for SO(3)-Equivariant Networks | 5.20 | 5.20 | 1.17 | 0.00 | | 3, 6, 6, 6, 5 | | 3, 6, 6, 6, 5 |
|
| 3543 | Interpretable and Convergent Graph Neural Network Layers at Scale | 5.20 | 5.20 | 1.94 | 0.00 | | 8, 3, 6, 6, 3 | | 8, 3, 6, 6, 3 |
|
| 3544 | GraphECL: Towards Efficient Contrastive Learning for Graphs | 5.00 | 5.20 | 1.17 | 0.20 | | 5, 6, 3, 6, 5 | | 5, 6, 3, 6, 6 |
|
| 3545 | Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning | 5.00 | 5.20 | 1.94 | 0.20 | |
| 3546 | Identifying Latent State Transition Processes for Individualized Reinforcement Learning | 4.00 | 5.20 | 1.17 | 1.20 | | 6, 3, 3, 5, 3 | | 6, 5, 3, 6, 6 |
|
| 3547 | The Representation Jensen-Shannon Divergence | 4.60 | 5.00 | 1.10 | 0.40 | | 5, 3, 6, 6, 3 | | 5, 6, 5, 6, 3 |
|
| 3548 | A Flexible Generative Model for Heterogeneous Tabular EHR with Missing Modality | 5.00 | 5.40 | 0.49 | 0.40 | | 6, 3, 6, 5, 5 | | 6, 5, 5, 5, 6 |
|
| 3549 | Topoformer: brain-like topographic organization in Transformer language models through spatial querying and reweighting | 5.20 | 5.20 | 1.60 | 0.00 | | 5, 8, 5, 3, 5 | | 5, 8, 5, 3, 5 |
|
| 3550 | Large Multimodal Model for Real-World Radiology Report Generation | 5.25 | 5.20 | 1.60 | -0.05 | |
| 3551 | Maximally Expressive GNNs for Outerplanar Graphs | 5.20 | 5.00 | 1.10 | -0.20 | | 6, 3, 6, 6, 5 | | 6, 3, 6, 5, 5 |
|
| 3552 | Domain Adaptation for Large-Vocabulary Object Detectors | 5.20 | 5.20 | 0.40 | 0.00 | | 5, 5, 6, 5, 5 | | 5, 5, 6, 5, 5 |
|
| 3553 | Toward Generalizability of Graph-based Imputation on Bio-Medical Missing Data | 4.60 | 5.20 | 1.17 | 0.60 | | 3, 3, 6, 6, 5 | | 3, 6, 6, 6, 5 |
|
| 3554 | EXPLORING RAIN-/DETAIL-AWARE REPRESENTATION FOR INSTANCE-SPECIFIC IMAGE DE-RAINING | 5.00 | 5.20 | 0.40 | 0.20 | | 5, 5, 5, 5, 5 | | 5, 5, 6, 5, 5 |
|
| 3555 | Mean Field Langevin Actor-Critic: Faster Convergence and Global Optimality beyond Lazy Learning | 4.80 | 5.20 | 0.40 | 0.40 | | 3, 5, 5, 5, 6 | | 5, 5, 5, 5, 6 |
|
| 3556 | Meta-Value Learning: a General Framework for Learning with Learning Awareness | 5.20 | 5.20 | 0.40 | 0.00 | | 5, 5, 5, 5, 6 | | 5, 5, 5, 5, 6 |
|
| 3557 | Graph-PDE: Coupled ODE Structure for Graph Neural Networks | 5.20 | 5.20 | 1.94 | 0.00 | | 8, 6, 3, 3, 6 | | 8, 6, 3, 3, 6 |
|
| 3558 | The (co)limit of metabeliefs | 5.20 | 5.20 | 1.60 | 0.00 | | 5, 5, 5, 3, 8 | | 5, 5, 5, 3, 8 |
|
| 3559 | Adversarial Machine Learning in Latent Representations of Neural Networks | 4.40 | 5.80 | 1.60 | 1.40 | | 3, 5, 6, 5, 3 | | 3, 8, 6, 6, 6 |
|
| 3560 | A Parallel Multi-compartment Spiking Neuron For Multi-scale Sequential Modeling | 4.80 | 5.20 | 1.17 | 0.40 | | 5, 3, 5, 5, 6 | | 6, 3, 6, 5, 6 |
|
| 3561 | Estimation of Concept Explanations Should be Uncertainty Aware | 4.80 | 5.20 | 1.17 | 0.40 | | 3, 6, 3, 6, 6 | | 3, 6, 5, 6, 6 |
|
| 3562 | Efficient Differentiable Approximation of the Generalized Low-rank Regularization | 5.20 | 5.20 | 1.60 | 0.00 | | 5, 5, 8, 3, 5 | | 5, 5, 8, 3, 5 |
|
| 3563 | Fair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach | 4.60 | 5.20 | 0.40 | 0.60 | | 5, 5, 3, 5, 5 | | 5, 5, 5, 6, 5 |
|
| 3564 | MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning | 5.20 | 5.20 | 1.94 | 0.00 | | 3, 8, 6, 6, 3 | | 3, 8, 6, 6, 3 |
|
| 3565 | Vec-Tok Speech: Speech Vectorization and Tokenization for Neural Speech Generation | 4.80 | 5.20 | 1.60 | 0.40 | | 3, 5, 3, 8, 5 | | 3, 5, 5, 8, 5 |
|
| 3566 | Investigating Human-Identifiable Features Hidden in Adversarial Perturbations | 4.80 | 5.60 | 2.33 | 0.80 | | 10, 1, 5, 3, 5 | | 10, 3, 5, 5, 5 |
|
| 3567 | Understanding In-context Learning with a Pelican Soup Hypothesis | 5.20 | 5.20 | 1.17 | 0.00 | | 6, 6, 3, 5, 6 | | 6, 6, 3, 5, 6 |
|
| 3568 | MADiff: Offline Multi-agent Learning with Diffusion Models | 4.80 | 5.20 | 0.40 | 0.40 | | 3, 5, 6, 5, 5 | | 5, 5, 6, 5, 5 |
|
| 3569 | A Lie Group Approach to Riemannian Normalization for SPD Neural Networks | 4.50 | 5.20 | 2.79 | 0.70 | |
| 3570 | Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity | 5.20 | 5.20 | 1.94 | 0.00 | | 8, 3, 3, 6, 6 | | 8, 3, 3, 6, 6 |
|
| 3571 | Exposure Bias Mitigation for Self Information Updating of Large Language Models | 5.00 | 5.20 | 1.17 | 0.20 | |
| 3572 | Multi-fidelity Deep Symbolic Optimization | 5.20 | 5.20 | 1.60 | 0.00 | | 5, 5, 8, 5, 3 | | 5, 5, 8, 5, 3 |
|
| 3573 | Adaptive Visual Scene Understanding: Incremental Scene Graph Generation | 5.00 | 5.20 | 1.17 | 0.20 | |
| 3574 | A Theoretical Analysis of In-context Task Retrieval and Learning | 5.20 | 5.20 | 1.17 | 0.00 | | 3, 6, 5, 6, 6 | | 3, 6, 5, 6, 6 |
|
| 3575 | Multiple Physics Pretraining for Physical Surrogate Models | 5.20 | 5.20 | 1.17 | 0.00 | | 6, 3, 5, 6, 6 | | 6, 3, 5, 6, 6 |
|
| 3576 | Memorization Through the Lens of Curvature of Loss Function Around Samples | 5.20 | 5.20 | 0.40 | 0.00 | | 5, 5, 5, 5, 6 | | 5, 5, 5, 5, 6 |
|
| 3577 | Beyond the training set: an intuitive method for detecting distribution shift in model-based optimization | 4.60 | 5.20 | 1.17 | 0.60 | | 3, 3, 6, 5, 6 | | 6, 3, 6, 5, 6 |
|
| 3578 | Single-Trajectory Distributionally Robust Reinforcement Learning | 4.60 | 5.20 | 1.94 | 0.60 | | 3, 3, 5, 6, 6 | | 3, 3, 6, 8, 6 |
|
| 3579 | Removing Multiple Shortcuts through the Lens of Multi-task Learning | 5.00 | 5.20 | 1.17 | 0.20 | | 5, 6, 6, 5, 3 | | 6, 6, 6, 5, 3 |
|
| 3580 | Enhancing Large Language Models in Coding Through Multi-Perspective Self-Consistency | 5.20 | 5.20 | 0.40 | 0.00 | | 5, 5, 5, 6, 5 | | 5, 5, 5, 6, 5 |
|
| 3581 | Efficient Personalized Text-to-image Generation by Leveraging Textual Subspace | 5.00 | 5.40 | 1.20 | 0.40 | | 6, 5, 5, 3, 6 | | 6, 6, 6, 3, 6 |
|
| 3582 | LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning | 4.80 | 5.20 | 0.40 | 0.40 | | 6, 5, 3, 5, 5 | | 6, 5, 5, 5, 5 |
|
| 3583 | IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs | 5.00 | 5.20 | 1.17 | 0.20 | | 6, 5, 3, 5, 6 | | 6, 6, 3, 5, 6 |
|
| 3584 | Differential Model Scaling using Differential Topk | 5.00 | 5.20 | 1.17 | 0.20 | | 5, 5, 6, 3, 6 | | 5, 6, 6, 3, 6 |
|
| 3585 | UniPredict: Large Language Models are Universal Tabular Predictors | 4.80 | 5.20 | 1.60 | 0.40 | | 5, 8, 3, 3, 5 | | 5, 8, 5, 3, 5 |
|
| 3586 | Incorporating Domain Knowledge in VAE Learning via Exponential Dissimilarity-Dispersion Family | 4.80 | 5.20 | 0.40 | 0.40 | | 5, 5, 5, 6, 3 | | 5, 5, 5, 6, 5 |
|
| 3587 | LIRE: Listwise Reward Enhancement for Preference Alignment | 5.20 | 5.20 | 0.40 | 0.00 | | 5, 6, 5, 5, 5 | | 5, 6, 5, 5, 5 |
|
| 3588 | Amicable Perturbations | 4.50 | 5.20 | 1.60 | 0.70 | |
| 3589 | Constraint-Free Structure Learning with Smooth Acyclic Orientations | 5.00 | 5.20 | 1.17 | 0.20 | | 5, 3, 6, 6, 5 | | 6, 3, 6, 6, 5 |
|
| 3590 | MuSc : Zero-Shot Anomaly Classification and Segmentation by Mutual Scoring of the Unlabeled Images | 5.20 | 5.20 | 1.17 | 0.00 | | 6, 5, 6, 3, 6 | | 6, 5, 6, 3, 6 |
|
| 3591 | New recipes for graph anomaly detection: Forward diffusion dynamics and graph generation | 5.17 | 5.17 | 0.37 | 0.00 | | 5, 5, 6, 5, 5, 5 | | 5, 5, 6, 5, 5, 5 |
|
| 3592 | Enhancing Adversarial Robustness on Categorical Data via Attribution Smoothing | 5.17 | 5.17 | 1.07 | 0.00 | | 6, 6, 5, 6, 5, 3 | | 6, 6, 5, 6, 5, 3 |
|
| 3593 | Spectral Greedy Coresets for Graph Neural Networks | 5.14 | 5.14 | 1.64 | 0.00 | | 5, 6, 5, 3, 3, 8, 6 | | 5, 6, 5, 3, 3, 8, 6 |
|
| 3594 | PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3595 | Instruct2Act: Mapping Multi-modality Instructions to Robotic Arm Actions with Large Language Model | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3596 | Disentanglement Learning via Topology | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3597 | Do not Start with Trembling Hands: Improving Multi-agent Reinforcement Learning with Stable Prefix Policy | 3.67 | 5.00 | 0.00 | 1.33 | |
| 3598 | Fully Identical Initialization | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3599 | Distributional Structured Pruning by Lower bounding the Total Variation Distance using Witness functions | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3600 | Understanding the Mechanics and Dynamics of Memorisation in Large Language Models: A Case Study with Random Strings | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 5, 3, 6, 5 | | 6, 5, 3, 6, 5 |
|
| 3601 | ProtChatGPT: Towards Understanding Proteins with Large Language Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3602 | Efficient architectural aspects for text-to-video generation pipeline | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3603 | Subject-specific Deep Neural Networks for Count Data with High-cardinality Categorical Features | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3604 | DAS$^2$C: A Distributed Adaptive Minimax Method with Near-Optimal Convergence | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3605 | Thin-Thick Adapter: Segmenting Thin Scans Using Thick Annotations | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3606 | Efficient Unsupervised Knowledge Distillation with Space Similarity | 4.80 | 5.00 | 1.10 | 0.20 | | 5, 3, 5, 6, 5 | | 5, 3, 6, 6, 5 |
|
| 3607 | Where is the Invisible: Spatial-Temporal Reasoning with Object Permanence | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3608 | Exploring Active Learning in Meta-Learning: Enhancing Context Set Labeling | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3609 | Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling | 5.00 | 5.40 | 0.49 | 0.40 | | 3, 6, 5, 5, 6 | | 5, 6, 5, 5, 6 |
|
| 3610 | Creative Robot Tool Use with Large Language Models | 5.25 | 5.00 | 2.55 | -0.25 | |
| 3611 | Unsupervised Representation Learning of Brain Activity via Bridging Voxel Activity and Functional Connectivity | 4.33 | 5.00 | 1.41 | 0.67 | |
| 3612 | SMILE: Audio-Visual Speech Recognition with Siamese Masked Interaction Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3613 | Diffusion Language Models Can Perform Many Tasks with Scaling and Instruction-Finetuning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3614 | What Matters to You? Towards Visual Representation Alignment for Robot Learning | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3615 | A Differentiable Physical Simulation Framework for Soft Robots on Multiple-Task Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3616 | Instructing Large Language Models to Identify and Ignore Irrelevant Conditions | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3617 | LLMZip: Lossless Text Compression using Large Language Models | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3618 | VMFTransformer: An Angle-Preserving and Auto-Scaling Machine for Multi-horizon Probabilistic Forecasting | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3619 | ArchLock: Locking DNN Transferability at the Architecture Level with a Zero-Cost Binary Predictor | 5.00 | 5.67 | 2.05 | 0.67 | |
| 3620 | Exploiting Code Symmetries for Learning Program Semantics | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3621 | Robust Graph Neural Networks via Unbiased Aggregation | 4.60 | 5.00 | 0.00 | 0.40 | | 3, 5, 5, 5, 5 | | 5, 5, 5, 5, 5 |
|
| 3622 | On the Power of Multitask Representation Learning with Gradient Descent | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3623 | Pick and Adapt: An Iterative Approach for Source-Free Domain Adaptation | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3624 | Rethinking Test-time Likelihood: The Likelihood Path Principle and Its Application to OOD Detection | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3625 | Do Pre-trained Transformers Really Learn In-context by Gradient Descent? | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3626 | O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3627 | Preconditioning for Physics-Informed Neural Networks | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3628 | STRUCTDROP: A STRUCTURED RANDOM ALGORITHM TOWARDS EFFICIENT LARGE-SCALE GRAPH TRAINING | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3629 | MIMIC: Masked Image Modeling with Image Correspondences | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3630 | Ceci n'est pas une pomme: Adversarial Illusions in Multi-Modal Embeddings | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3631 | Causal Estimation of Exposure Shifts with Neural Networks: Evaluating the Health Benefits of Stricter Air Quality Standards in the US | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3632 | Efficient Transfer Learning from Arbitrary Pre-Trained Models | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3633 | How Capable Can a Transformer Become? A Study on Synthetic, Interpretable Tasks | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3634 | Improved order analysis and design of exponential integrator for diffusion models sampling | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3635 | Bridging Sequence and Structure: Latent Diffusion for Conditional Protein Generation | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3636 | Why is SAM Robust to Label Noise? | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3637 | How FaR Are Large Language Models From Agents with Theory-of-Mind? | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3638 | Approaching an unknown communication system by latent space exploration and causal inference | 4.75 | 5.00 | 2.12 | 0.25 | |
| 3639 | Language Models Linearly Represent Sentiment | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3640 | Learning to make adherence-aware advice | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3641 | RoCA: A Robust Method to Discover Causal or Anticausal Relation by Noise Injection | 4.00 | 5.00 | 1.41 | 1.00 | |
| 3642 | Size Generalization of Graph Neural Networks on Biological Data: Insights and Practices from the Spectral Perspective | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3643 | SwapTransformer: Highway Overtaking Tactical Planner Model via Imitation Learning on OSHA Dataset | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3644 | Multisensory Geospatial Models via Cross-Sensor Pretraining | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3645 | Fast Sampling via De-randomization for Discrete Diffusion Models | 4.25 | 5.50 | 0.50 | 1.25 | |
| 3646 | A Discretization Framework for Robust Contextual Stochastic Optimization | 3.50 | 5.00 | 2.12 | 1.50 | |
| 3647 | The Distributional Reward Critic Architecture for Reinforcement Learning Under Confusion Matrix Reward Perturbations | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3648 | Efficient Offline Reinforcement Learning: The Critic is Critical | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3649 | Flatter, Faster: Scaling Momentum for Optimal Speedup of SGD | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3650 | Lie Neurons: A General Adjoint-Equivariant Neural Network for Semisimple Lie Algebras | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3651 | Guiding Language Models Reasoning with Planning Tokens | 5.00 | 5.00 | 2.55 | 0.00 | |
| 3652 | TimewarpVAE: Simultaneous Time-Warping and Representation Learning of Trajectories | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3653 | SPADE: Sparsity-Guided Debugging for Deep Neural Networks | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3654 | Understanding Certified Training with Interval Bound Propagation | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3655 | Offline RL with Observation Histories: Analyzing and Improving Sample Complexity | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3656 | (Dynamic) Prompting might be all you need to repair Compressed LLMs | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3657 | Explicitly Disentangled Representations in Object-Centric Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3658 | Resource Efficient Self-Supervised Learning for Speech Embeddings | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3659 | Fair Adversarial Training: on the Adversarial Attack and Defense of Fairness | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3660 | Tweedie Moment Projected Diffusions for Inverse Problems | 4.00 | 5.00 | 2.12 | 1.00 | |
| 3661 | Robustness via learned Bregman divergence | 4.75 | 5.00 | 2.12 | 0.25 | |
| 3662 | Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading | 4.75 | 5.50 | 1.80 | 0.75 | |
| 3663 | What Makes a Good Prune? Optimal Unstructured Pruning for Maximal Cosine Similarity | 5.50 | 5.00 | 2.55 | -0.50 | |
| 3664 | Evaluating Robustness to Unforeseen Adversarial Attacks | 4.50 | 5.00 | 2.12 | 0.50 | |
| 3665 | Where Does In-context Machine Translation Happen in Large Language Models? | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3666 | A Language-Agent Approach to Formal Theorem-Proving | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3667 | Unlearning via Sparse Representations | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3668 | Resonator-Gated RNNs | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3669 | S-TLLR: STDP-inspired Temporal Local Learning Rule for Spiking Neural Networks | 4.25 | 5.00 | 1.22 | 0.75 | |
| 3670 | Supervised Knowledge Makes Large Language Models Better In-context Learners | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3671 | Convexifying Transformers: Improving optimization and understanding of transformer networks | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3672 | Video Caching at Data-drifting Network Edge: A KD-based Cross-domain Collaborative Solution | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3673 | WavJourney: Compositional Audio Creation with Large Language Models | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 5, 5, 3, 6 | | 6, 5, 5, 3, 6 |
|
| 3674 | Conserve-Update-Revise to Cure Generalization and Robustness Trade-off in Adversarial Training | 5.50 | 5.50 | 0.50 | 0.00 | |
| 3675 | Perturbed examples reveal invariances shared by language models | 4.50 | 5.00 | 2.12 | 0.50 | |
| 3676 | Meta-Guided Diffusion Models for Zero-Shot Medical Imaging Inverse Problems | 5.25 | 5.00 | 1.22 | -0.25 | |
| 3677 | Mildly Overparameterized ReLU Networks Have a Favorable Loss Landscape | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3678 | CDGraph: Dual Conditional Social Graph Synthesizing via Diffusion Model | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3679 | Exploring the Combined Power of Covariance and Hessian Matrices Eigenanalysis for Binary Classification | 4.25 | 5.00 | 1.22 | 0.75 | |
| 3680 | Double Rounding Quantization for Flexible Deep Neural Network Compression | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3681 | CircuitNet 2.0: An Advanced Dataset for Promoting Machine Learning Innovations in Realistic Chip Design Environment | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3682 | Weight-Based Performance Estimation for Diverse Domains | 5.00 | 4.67 | 1.25 | -0.33 | |
| 3683 | Forget-Me-Not: Making Backdoor Hard to be Forgotten in Fine-tuning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3684 | You Only Submit One Image to Find the Most Suitable Generative Model | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3685 | Semantic-Enhanced Prototypical Network for Universal Novel Category Discovery | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3686 | MetroGNN: Metro Network Expansion with Deep Reinforcement Learning | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3687 | Synergistic Information Retrieval: Interplay between Search and Large Language Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3688 | Learning Personalized Causally Invariant Representations for Heterogeneous Federated Clients | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3689 | LeanFlex-GKP: Advancing Hassle-Free Structured Pruning with Simple Flexible Group Count | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3690 | Classifiers are Forgetful! Balancing the Mutual Causal Effects in Class-Incremental Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3691 | Investigating the Ability of PINNs To Solve Burgers' PDE Near Finite-Time BlowUp | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3692 | Exploring Pointwise Similarity of Representations | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3693 | Bayesian Domain Invariant Learning via Posterior Generalization of Parameter Distributions | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3694 | Sparse hyperbolic representation learning | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3695 | Multi-Scale Protein Language Model for Unified Molecular Modeling | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3696 | Feasible Algorithmic Recourse Without Explicit Structure Prior | 5.00 | 5.00 | 1.90 | 0.00 | | 8, 5, 3, 3, 6 | | 8, 5, 3, 3, 6 |
|
| 3697 | The Role of Forgetting in Fine-Tuning Reinforcement Learning Models | 4.75 | 5.00 | 2.12 | 0.25 | |
| 3698 | Towards robust unlearnable examples via deep hiding | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3699 | Deep Backtracking Counterfactuals for Causally Compliant Explanations | 4.60 | 5.00 | 1.10 | 0.40 | | 5, 5, 3, 5, 5 | | 6, 6, 3, 5, 5 |
|
| 3700 | A First-Order Multi-Gradient Algorithm for Multi-Objective Bi-Level Optimization | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3701 | Homeomorphic Model Transformation for Boosting Performance and Efficiency in Object Detection Networks | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3702 | Learn What You Need in Personalized Federated Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3703 | Ask more, know better: Reinforce-Learned Prompt Questions for Decision Making with Large Language Models | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3704 | Generalization or Specificity? Spectral Meta Estimation and Ensemble (SMEE) with Domain-specific Experts | 5.50 | 5.00 | 2.55 | -0.50 | |
| 3705 | HP$^3$-NS: Hybrid Perovskite Property Prediction Using Nested Subgraph | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3706 | Language-driven Open-Vocabulary Keypoint Detection for Animal Body and Face | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 5, 5, 3, 6 | | 6, 5, 5, 3, 6 |
|
| 3707 | An old dog can learn (some) new tricks: A tale of a three-decade old architecture | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3708 | Human-oriented Representation Learning for Robotic Manipulation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3709 | Exploring the Generalization Capabilities of AID-based Bi-level Optimization | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3710 | A Nearly Optimal and Low-Switching Algorithm for Reinforcement Learning with General Function Approximation | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3711 | GenCO: Generating Diverse Solutions to Design Problems with Combinatorial Nature | 4.25 | 5.50 | 0.50 | 1.25 | |
| 3712 | A Change of Heart: Backdoor Attacks on Security-Centric Diffusion Models | 4.75 | 5.50 | 0.50 | 0.75 | |
| 3713 | Adversarial Attacks on Combinatorial Multi-Armed Bandits | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3714 | Semi-HyperGraph Benchmark: Enhancing Flexibility of Hypergraph Learning with Datasets and Benchmarks | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3715 | Fast Multipole Attention: A Divide-and-Conquer Attention Mechanism for Long Sequences | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3716 | Harnessing the Power of Neural Operators with Automatically Encoded Conservation Laws | 4.50 | 5.00 | 1.10 | 0.50 | |
| 3717 | Pivotal Prompt Tuning for Video Dynamic Editing | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3718 | Defying Multi-model Forgetting: Orthogonal Gradient Learning to One-shot Neural Architecture Search | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3719 | Can Differentiable Decision Trees Learn Interpretable Reward Functions? | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3720 | Image Clustering Conditioned on Text Criteria | 5.00 | 6.25 | 2.05 | 1.25 | |
| 3721 | SoftPhy: Soft-Body Physical Concept Learning and Reasoning from Videos | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3722 | XTSFormer: Cross-Temporal-Scale Transformer for Irregular Time Event Prediction | 4.50 | 5.00 | 2.12 | 0.50 | |
| 3723 | The Closeness of In-Context Learning and Weight Shifting for Softmax Regression | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3724 | Universal Off-Policy Selection for Human-Centric Systems via Participant Sub-grouping | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3725 | AudoFormer: An Efficient Transformer with Consistent Auxiliary Domain for Source-free Domain Adaptation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3726 | Revisiting Subsampling and Mixup for WSI Classification: A Slot-Attention-Based Approach | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3727 | GFLOWNET TRAINING BY POLICY GRADIENTS | 4.20 | 5.00 | 0.00 | 0.80 | | 3, 5, 5, 5, 3 | | 5, 5, 5, 5, 5 |
|
| 3728 | Attacking for Inspection and Instruction: Debiasing Self-explaining Text Classification | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 5, 6, 5, 3 | | 6, 5, 6, 5, 3 |
|
| 3729 | Sample-Efficient Training for Score-Based Diffusion | 5.00 | 5.25 | 0.43 | 0.25 | |
| 3730 | Debias your VLM with Counterfactuals: A Unified Approach | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3731 | Can Language Models be Instructed to Protect Personal Information? | 5.75 | 5.00 | 1.22 | -0.75 | |
| 3732 | Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3733 | Accurate Differential Operators for Neural Fields | 4.75 | 5.00 | 2.12 | 0.25 | |
| 3734 | Revisiting Familiar Places in an Infinite World: Continuing RL in Unbounded State Spaces | 4.25 | 5.00 | 1.22 | 0.75 | |
| 3735 | Memory Efficient Neural Processes via Constant Memory Attention Block | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3736 | LumiNet: The Bright Side of Perceptual Knowledge Distillation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3737 | Learning Planning Abstractions from Language | 4.75 | 5.50 | 1.80 | 0.75 | |
| 3738 | Sweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3739 | A simple connection from loss flatness to compressed representations in neural networks | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3740 | End-Effector-Elbow: A New Action Space for Robot Learning | 5.33 | 5.00 | 2.12 | -0.33 | |
| 3741 | Universal Guidance for Diffusion Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3742 | Supermodular Rank: Set Function Decomposition and Optimization | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3743 | Weighted Risk Invariance for Density-Aware Domain Generalization | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3744 | Sinkhorn Distributional Reinforcement Learning | 5.00 | 5.00 | 1.90 | 0.00 | | 3, 6, 5, 8, 3 | | 3, 6, 5, 8, 3 |
|
| 3745 | Let Models Speak Ciphers: Multiagent Debate through Embeddings | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3746 | Plug-And-Play Controllable Graph Generation With Diffusion Models | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3747 | Actions-to-Action: Inductive Attention for Egocentric Video Action Anticipation | 5.00 | 4.40 | 1.20 | -0.60 | | 6, 3, 3, 8, 5 | | 5, 3, 3, 6, 5 |
|
| 3748 | Primal-Dual Continual Learning: Stability and Plasticity through Lagrange Multipliers | 4.50 | 5.00 | 2.12 | 0.50 | |
| 3749 | Addressing Sample Inefficiency in Multi-View Representation Learning | 4.75 | 5.00 | 2.12 | 0.25 | |
| 3750 | Deep Variational Multivariate Information Bottleneck - A Framework for Variational Losses | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3751 | VideoGLUE: Video General Understanding Evaluation of Foundation Models | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3752 | AlignDiff: Aligning Diffusion Models for General Few-Shot Segmentation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3753 | Complete and continuous representations of Euclidean graphs | 5.00 | 5.00 | 1.90 | 0.00 | | 3, 8, 5, 3, 6 | | 3, 8, 5, 3, 6 |
|
| 3754 | Risk-Sensitive Variational Model-Based Policy Optimization | 5.33 | 5.00 | 1.41 | -0.33 | |
| 3755 | Label-efficient Training of Small Task-specific Models by Leveraging Vision Foundation Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3756 | Avoiding Pitfalls for Privacy Accounting of Subsampled Mechanisms under Composition | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3757 | Assessing Visually-Continuous Corruption Robustness of Neural Networks Relative to Human Performance | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3758 | Counterfactual Fairness on Graphs: Augmentations, Hidden Confounders, and Identifiability | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3759 | Detecting Language Model Attacks With Perplexity | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3760 | Debiasing Language Models Using Energy-Guided Ordinary Differential Equations | 3.50 | 5.00 | 0.00 | 1.50 | |
| 3761 | BIRB: A Generalization Benchmark for Information Retrieval in Bioacoustics | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3762 | UGC: UNIVERSAL GRAPH COARSENING | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3763 | FeatUp: A Model-Agnostic Framework for Features at Any Resolution | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3764 | Algorithm and Hardness for Dynamic Attention Maintenance in Large Language Models | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3765 | Demonstrating the capacity of a Path-Based variational inference formulation for robust hidden Markov modelling of complex and noisy binary trees | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3766 | Federated contrastive GFlowNets | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3767 | Rethinking Optimal Transport in Offline Reinforcement Learning | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3768 | BEND: Benchmarking DNA Language Models on Biologically Meaningful Tasks | 4.25 | 5.00 | 1.22 | 0.75 | |
| 3769 | Bandits with Ranking Feedback | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3770 | Constrained Reinforcement Learning as Wasserstein Variational Inference: Formal Methods for Interpretability | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3771 | Large Trajectory Models are Scalable Motion Predictors and Planners | 5.25 | 5.00 | 0.00 | -0.25 | |
| 3772 | Unsupervised ASR via Cross-Lingual Pseudo-Labeling | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3773 | Federated Ensemble-Directed Offline Reinforcement Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3774 | Explaining grokking through circuit efficiency | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3775 | Sparkles: Unlocking Chats Across Multiple Images for Multimodal Instruction-Following Models | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3776 | Language Conditioned Equivariant Grasp | 4.60 | 5.00 | 1.10 | 0.40 | | 3, 6, 6, 3, 5 | | 5, 6, 6, 3, 5 |
|
| 3777 | DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3778 | Efficient calibration as a binary top-versus-all problem for classifiers with many classes | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3779 | Clustering with Geometric Modularity | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3780 | Diffusion Models for Open-Vocabulary Segmentation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3781 | ParFam - Symbolic Regression Based on Continuous Global Optimization | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3782 | Counterfactual Fairness for Predictions using Generative Adversarial Networks | 4.00 | 5.00 | 0.00 | 1.00 | |
| 3783 | Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3784 | Model Explanation Disparities as a Fairness Diagnostic | 5.00 | 5.40 | 1.62 | 0.40 | | 5, 3, 5, 6, 6 | | 5, 3, 5, 6, 8 |
|
| 3785 | From Categories to Classifier: Name-Only Continual Learning by Exploring the Web | 5.00 | 5.00 | 1.10 | 0.00 | | 3, 5, 6, 5, 6 | | 3, 5, 6, 5, 6 |
|
| 3786 | Multi-Fidelity Active Learning with GFlowNets | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3787 | Enhancing Offline Reinforcement Learning with an Optimal Supported Dataset | 5.00 | 5.00 | 1.73 | 0.00 | | 3, 5, 5, 6, 8, 3 | | 3, 5, 5, 6, 8, 3 |
|
| 3788 | FedGP: Buffer-based Gradient Projection for Continual Federated Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3789 | A Bayesian Framework for Clustered Federated Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3790 | HIPODE: Enhancing Offline Reinforcement Learning with High-Quality Synthetic Data from a Policy-Decoupled Approach | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3791 | Incentive-Aware Federated Learning with Training-Time Model Rewards | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3792 | DiffFlow: A Unified SDE for Score-Based Diffusion Models and Generative Adversarial Networks | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3793 | URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3794 | Communication-Efficient Heterogeneous Federated Learning with Generalized Heavy-Ball Momentum | 4.50 | 5.00 | 2.12 | 0.50 | |
| 3795 | Collaborative Prompt Tuning for Black-Box Vision-Language Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3796 | Understanding Community Bias Amplification in Graph Representation Learning | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3797 | Quantum Architecture Search with Unsupervised Representation Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3798 | GML-NeRF: Gate-guided Mutual Learning Framework for Neural Rendering | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3799 | Convergence of SVGD in KL divergence via approximate gradient flow | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3800 | Multi-modal Latent Diffusion | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3801 | PolyNet: Learning Diverse Solution Strategies for Neural Combinatorial Optimization | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3802 | An Efficient Multi-Task Transformer for 3D Face Alignment | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3803 | Learning energy-based models by self-normalising the likelihood | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3804 | SEGO: Sequential Subgoal Optimization for Mathematical Problem-Solving | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3805 | The Trifecta: Three simple techniques for training deeper Forward-Forward networks | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3806 | A Best-of-Both-Worlds Algorithm for MDPs with Long-Term Constraints | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3807 | MACCA: Offline Multi-agent Reinforcement Learning with Causal Credit Assignment | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3808 | Learning Good Interventions in Causal Contextual Bandits with Adaptive Context | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3809 | Copy Suppression: Comprehensively Understanding an Attention Head | 5.50 | 5.00 | 1.22 | -0.50 | |
| 3810 | In-context Prompt Learning for Test-time Vision Recognition with Frozen Vision-Language Model | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3811 | Uncertainty Quantification Using a Codebook of Encoders | 4.25 | 5.00 | 2.55 | 0.75 | |
| 3812 | Label-encoding Risk Minimization under Label Insufficient Scenarios | 5.50 | 5.00 | 1.10 | -0.50 | |
| 3813 | FINE-GRAINED AUDIO-VISUAL JOINT REPRESENTATIONS FOR MULTIMODAL LARGE LANGUAGE MODELS | 4.00 | 5.00 | 1.22 | 1.00 | |
| 3814 | Leveraging characteristics of the output distribution for identifying adversarial audio examples | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3815 | Leveraging Uncertainty Estimates To Improve Classifier Performance | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3816 | Advantage-Aware Policy Optimization for Offline Reinforcement Learning | 4.80 | 5.00 | 1.10 | 0.20 | | 3, 5, 5, 6, 5 | | 3, 5, 5, 6, 6 |
|
| 3817 | Multilingual Code Retrieval Without Paired Data: New Datasets and Benchmarks | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3818 | Unsupervised motion segmentation in one go: Smooth long-term model over a video | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3819 | High-Probability Convergence for Composite and Distributed Stochastic Minimization and Variational Inequalities with Heavy-Tailed Noise | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3820 | $texttt{PREMIER-TACO}$ is a Few-Shot Policy Learner: Pretraining Multitask Representation via Temporal Action-Driven Contrastive Loss | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3821 | Autonomous Catheterization with Open-source Simulator and Expert Trajectory | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3822 | Multi-Objective Reinforcement Learning for Forward-Backward Markov Decision Processes | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3823 | HGMD: Rethinking Hard Sample Distillation for GNN-to-MLP Knowledge Distillation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3824 | Dilated convolution neural operator for multiscale partial differential equations | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3825 | Temporal Flexibility in Spiking Neural Networks: A Novel Training Method for Enhanced Generalization Across Time Steps | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3826 | DECENTRALIZED MULTI-AGENT REINFORCEMENT LEARNING VIA ANTICIPATION SHARING | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3827 | DINAR: Fine-Grained Privacy Preserving Federated Learning | 4.00 | 5.00 | 0.00 | 1.00 | |
| 3828 | Small Variance, Big Fairness: A Path to Harmless Fairness without Demographics | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3829 | Towards Interpretable Controllability in Object-Centric Learning | 4.33 | 5.00 | 2.94 | 0.67 | |
| 3830 | SOInter: A Novel Deep Energy-Based Interpretation Method for Explaining Structured Output Models | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3831 | Conceptual Graph Counterfactuals | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3832 | Latent Diffusion Counterfactual Explanations | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3833 | Optimal Multiple Transport with Applications to Visual Matching, Model Fusion and Beyond | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3834 | MoLE: Mixture of LoRA Experts | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3835 | Provable Domain Generalization via Information Theory Guided Distribution Matching | 5.50 | 5.00 | 2.55 | -0.50 | |
| 3836 | LogoRA: Local-Global Representation Alignment for Robust Time Series Classification | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 5, 5, 6, 3 | | 6, 5, 5, 6, 3 |
|
| 3837 | Soft iEP: On the Exploration Inefficacy of Gradient Based Strong Lottery Exploration | 5.00 | 5.00 | 1.10 | 0.00 | | 3, 5, 6, 6, 5 | | 3, 5, 6, 6, 5 |
|
| 3838 | L2B: Learning to Bootstrap Robust Models for Combating Label Noise | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3839 | Learning to Optimize for Reinforcement Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3840 | Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3841 | Fair Attribute Classification via Distance Covariance | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3842 | PyTrial: Machine Learning Software and Benchmark for Clinical Trial Applications | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3843 | Reinforcement Learning-based Layer-wise Aggregation for Personalized Federated Learning | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3844 | A Game-theoretic Approach to Personalized Federated Learning Based on Target Interpolation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3845 | YoooP: You Only Optimize One Prototype per Class for Non-Exemplar Incremental Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3846 | How to Guess a Gradient | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3847 | Causal Inference with Conditional Front-Door Adjustment and Identifiable Variational Autoencoder | 4.67 | 5.75 | 0.43 | 1.08 | |
| 3848 | ZegOT: Zero-shot Segmentation Through Optimal Transport of Pixels to Text Prompts | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3849 | DistillSpec: Improving Speculative Decoding via Knowledge Distillation | 5.00 | 6.00 | 0.00 | 1.00 | |
| 3850 | Leveraging Human Revisions for Improving Text-to-Layout Models | 4.50 | 5.25 | 0.43 | 0.75 | |
| 3851 | PUMA: Secure Inference of LLaMA-7B in Five Minutes | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3852 | Patch-Prompt Aligned Bayesian Prompt Tuning for Vision-Language Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3853 | CrossTVR: Multi-Grained Re-Ranker for Text Video Retrieval with Frozen Image Encoders | 5.00 | 5.33 | 0.47 | 0.33 | |
| 3854 | ImplicitSLIM and How it Improves Embedding-based Collaborative Filtering | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3855 | Align before Adapt: Efficient and Generalizable Video Action Recognition with Text Corpus | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 6, 5, 5, 3 | | 6, 6, 5, 5, 3 |
|
| 3856 | BOSS: Diversity-Difficulty Balanced One-Shot Subset Selection for Data-Efficient Deep Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3857 | Stochastic Adaptive Sequential Black-box Optimization for Diffusion Targeted Generation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3858 | Forward Gradient Training of Spiking Neural Networks | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3859 | Towards Fair Knowledge Distillation using Student Feedback | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3860 | Neural Characteristic Activation Value Analysis for Improved ReLU Network Feature Learning | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3861 | RFold: RNA Secondary Structure Prediction with Decoupled Optimization | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3862 | DPFormer: Learning Differentially Private Transformer on Long-Tailed Data | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3863 | Aligning Large Multimodal Models with Factually Augmented RLHF | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3864 | NPEFF: Non-Negative Per-Example Fisher Factorization | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3865 | Investigating Feature Alignment Under An Infant-Inspired Visual Distribution Shift | 5.00 | 5.00 | 1.10 | 0.00 | | 3, 5, 6, 5, 6 | | 3, 5, 6, 5, 6 |
|
| 3866 | Empirical Likelihood for Fair Classification | 5.00 | 5.67 | 0.47 | 0.67 | |
| 3867 | The No Free Lunch Theorem, Kolmogorov Complexity, and the Role of Inductive Biases in Machine Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3868 | FedJETs: Efficient Just-In-Time Personalization with Federated Mixture of Experts | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3869 | ALMANACS: A Simulatability Benchmark for Language Model Explainability | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3870 | Space-Time Attention with Shifted Non-Local Search | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3871 | ReLoRA: High-Rank Training Through Low-Rank Updates | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3872 | Image as First-Order Norm+Linear Autoregression: Unveiling Mathematical Invariance | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3873 | FedBPT: Efficient Federated Black-box Prompt Tuning for Large Language Models | 5.00 | 5.00 | 1.00 | 0.00 | | 5, 5, 3, 5, 6, 6 | | 5, 5, 3, 5, 6, 6 |
|
| 3874 | Graph Neural Networks Provably Benefit from Structural Information: A Feature Learning Perspective | 5.00 | 5.00 | 1.10 | 0.00 | | 3, 6, 6, 5, 5 | | 3, 6, 6, 5, 5 |
|
| 3875 | Provable Knowledge Transfer using Successor Feature for Deep Reinforcement Learning | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3876 | Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3877 | Instruction Mining: Instruction Data Selection for Tuning Large Language Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3878 | A Dynamical View of the Question of Why | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3879 | Rethinking the Smoothness of Node Features Learned by Graph Convolutional Networks | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3880 | Det-CGD: Compressed Gradient Descent with Matrix Stepsizes for Non-Convex Optimization | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3881 | Intrinsic Riemannian Classifiers on the Deformed SPD Manifolds: A Unified Framework | 4.25 | 5.00 | 1.22 | 0.75 | |
| 3882 | InCo: Enhance Domain Generalization in Noisy Environments | 5.00 | 5.00 | 1.10 | 0.00 | | 5, 6, 5, 6, 3 | | 5, 6, 5, 6, 3 |
|
| 3883 | Revisiting GNNs for Boolean Satisfiability | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3884 | Augmentation-aware Self-Supervised Learning with Conditioned Projector | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3885 | DPO-Diff: On Discrete Prompt Optimization of Text-to-Image Diffusion Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3886 | IBCL: Zero-shot Model Generation for Task Trade-offs in Continual Learning | 4.00 | 5.00 | 2.12 | 1.00 | |
| 3887 | Neural varifolds: an aggregate representation for quantifying geometry of point clouds | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3888 | Learning Variational Neighbor Labels for Test-Time Domain Generalization | 5.25 | 5.00 | 0.00 | -0.25 | |
| 3889 | READ: Recurrent Adaptation of Large Transformers | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3890 | Securing Deep Generative Models with Universal Adversarial Signature | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3891 | DUDE: Deep Unsupervised Domain adaptation using variable nEighbors for physiological time series analysis | 4.75 | 5.75 | 0.43 | 1.00 | |
| 3892 | Calibrated Dataset Condensation for Faster Hyperparameter Search | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3893 | VIMEX: A Memory-Centered Task Description Framework for Vision-Based Robotics | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3894 | Optimized Tradeoffs for Private Majority Ensembling | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3895 | PlugVFL: Robust and IP-Protecting Vertical Federated Learning against Unexpected Quitting of Parties | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3896 | Differentially Private Model Compression via Selective Pretraining | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3897 | HowToCaption: Prompting LLMs to Transform Video Annotations at Scale | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3898 | Spectral-Bias and Kernel-Task Alignment in Physically Informed Neural Networks | 4.00 | 5.00 | 1.41 | 1.00 | |
| 3899 | GREAT Score: Global Robustness Evaluation of Adversarial Perturbation using Generative Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3900 | Time Series Anomaly Detection using Reconstruction and RBF Similarity Scores | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3901 | Evaluating the Evaluators: Are Current Few-Shot Learning Benchmarks Fit for Purpose? | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3902 | RASP Quadratures: Efficient Numerical Integration for High-Dimensional Mean-Field Variational Inference | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3903 | A Multi-Grained Group Symmetric Framework for Learning Protein-Ligand Binding Dynamics | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3904 | Rethinking pseudo-labeling: Data-centric insights improve semi-supervised learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3905 | LLM Performance Predictors are good initializers for Architecture Search | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3906 | DOS: Dreaming Outlier Semantics for Out-of-distribution Detection | 4.50 | 5.00 | 2.12 | 0.50 | |
| 3907 | Physics-aware Hand Object Interaction Denoising | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3908 | ReForm-Eval: Evaluating Large Vision Language Models via Unified Re-Formulation of Task-Oriented Benchmarks | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3909 | Graph Transformers for Large Graphs | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3910 | LangProp: A code optimization framework using Language Models applied to driving | 4.50 | 5.00 | 2.31 | 0.50 | | 3, 6, 8, 6, 3, 1 | | 3, 6, 8, 6, 6, 1 |
|
| 3911 | Uncertainty-Aware Decision Transformer for Stochastic Driving Environments | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3912 | LOVECon: Text-driven Training-free Long Video Editing with ControlNet | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3913 | Hybrid Retrieval-Augmented Generation for Real-time Composition Assistance | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3914 | RAPPER: Reinforced Rationale-Prompted Paradigm for Natural Language Explanation in Visual Question Answering | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3915 | ZEST: ZEROSHOT SPARSE FINE-TUNING | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3916 | Optimization Dynamics of Equivariant and Augmented Neural Networks | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3917 | Universal Sleep Decoder: Aligning awake and sleep neural representation across subjects | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3918 | Double Momentum Method for Lower-Level Constrained Bilevel Optimization | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3919 | ISCUTE: Instance Segmentation of Cables Using Text Embedding | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3920 | P-MapNet: Far-seeing Map Constructer Enhanced by both SDMap and HDMap Priors | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3921 | Combinatorial Optimization via Memory Metropolis: Template Networks for Proposal Distributions in Simulated Annealing applied to Nanophotonic Inverse Design | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3922 | Divide-and-Conquer Time Series Forecasting with Auto-Frequency-Correlation via Cross-Channel Attention | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3923 | Optimization over Sparse Restricted Convex Sets via Two Steps Projection | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3924 | Stealthy Targeted Backdoor Attack Against Image Captioning | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3925 | Subject-Diffusion: Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3926 | Client-centric Federated Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3927 | Functional Classification Under Local Differential Privacy with Model Reversal and Model Average | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3928 | Classifier Guidance Enhances Diffusion-based Adversarial Purification by Preserving Predictive Information | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3929 | A Unified Framework for Consistency Generative Modeling | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3930 | InstructProtein: Aligning Human and Protein Language via Knowledge Instruction | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3931 | Language Models Struggle to Explain Themselves | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3932 | Generating Transferable and Stealthy Adversarial Patch via Attention-guided Adversarial Inpainting | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3933 | Predicated Diffusion: Predicate Logic-Based Attention Guidance for Text-to-Image Diffusion Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3934 | Multi-label Cluster Discrimination for Visual Representation Learning | 5.33 | 5.00 | 0.00 | -0.33 | |
| 3935 | Text-to-3D Generation with Bidirectional Diffusion using both 3D and 2D priors | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3936 | An Information Theoretic Approach to Interaction Grounded Learning | 5.00 | 5.00 | 1.10 | 0.00 | | 6, 3, 5, 5, 6 | | 6, 3, 5, 5, 6 |
|
| 3937 | SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3938 | Tactics of Robust Deep Reinforcement Learning with Randomized Smoothing | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3939 | Towards Codable Text Watermarking for Large Language Models | 5.00 | 5.75 | 0.43 | 0.75 | |
| 3940 | GAN-based Vertical Federated Learning for Label Protection | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3941 | Dataset Distillation via Adversarial Prediction Matching | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3942 | On the Hidden Waves of Image | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3943 | Spectral Contrastive Regression | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3944 | CAT-LLM: Context-Aware Training enhanced Large Language Models for multi-modal contextual image retrieval | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3945 | Object2Scene: Putting Objects in Context for Open-Vocabulary 3D Detection | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3946 | MindAgent: Emergent Gaming Interaction | 5.00 | 5.00 | 2.45 | 0.00 | | 3, 8, 3, 3, 8 | | 3, 8, 3, 3, 8 |
|
| 3947 | Learning to Prompt Segmentation Foundation Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3948 | SAM-guided Unsupervised Domain Adaptation for 3D Segmentation | 5.00 | 5.00 | 1.10 | 0.00 | | 3, 6, 5, 6, 5 | | 3, 6, 5, 6, 5 |
|
| 3949 | LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3950 | Transitional Uncertainty with Intermediate Neural Gaussian Processes | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3951 | Graph-Relational Federated Learning: Enhanced Personalization and Robustness | 5.33 | 5.00 | 0.00 | -0.33 | |
| 3952 | Score-based Conditional Generation with Fewer Labeled Data by Self-calibrating Classifier Guidance | 5.00 | 5.00 | 0.00 | 0.00 | | 5, 5, 5, 5, 5 | | 5, 5, 5, 5, 5 |
|
| 3953 | MagicRemover: Tuning-free Text-guided Image Inpainting with Diffusion Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3954 | Abductive Logical Reasoning on Knowledge Graphs | 4.80 | 5.00 | 1.10 | 0.20 | | 3, 6, 5, 5, 5 | | 3, 6, 6, 5, 5 |
|
| 3955 | How Language Models Learn Context-Free Grammars | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3956 | ResPrompt: Residual Connection Prompting Advances Multi-Step Reasoning in Large Language Models | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3957 | Unsupervised Lifelong Learning with Sustained Representation Fairness | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3958 | Decoupling regularization from the action space | 4.50 | 5.67 | 0.47 | 1.17 | |
| 3959 | Enhancing Temporal Knowledge Graph Completion with Global Similarity and Weighted Sampling | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3960 | The Role of Counterfactual Explanations in Model Extraction Attacks | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3961 | Efficient Redundancy-Free Graph Networks: Higher Expressiveness and Less Over-Squashing | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3962 | Statistical Inference for Deep Learning via Stochastic Modeling | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3963 | STExplainer: Global Explainability of GNNs via Frequent SubTree Mining | 5.00 | 4.75 | 1.09 | -0.25 | |
| 3964 | Learning to Solve Bilevel Programs with Binary Tender | 4.33 | 5.00 | 1.41 | 0.67 | |
| 3965 | Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning | 4.75 | 5.00 | 1.22 | 0.25 | |
| 3966 | Removing Spurious Concepts from Neural Network Representations via Joint Subspace Estimation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3967 | LaVie: High-Quality Video Generation with Cascaded Latent Diffusion Models | 5.00 | 5.50 | 0.50 | 0.50 | |
| 3968 | Retrosynthesis Prediction via Search in (Hyper) Graph | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3969 | The LLM Surgeon | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3970 | SelfVC: Voice Conversion With Iterative Refinement using Self Transformations | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3971 | Going beyond familiar features for deep anomaly detection | 5.00 | 4.67 | 1.25 | -0.33 | |
| 3972 | PAPM: A Physics-aware Proxy Model for Process Systems | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3973 | Light-MILPopt: Solving Large-scale Mixed Integer Linear Programs with Small-scale Optimizer and Small Training Dataset | 4.50 | 5.00 | 1.22 | 0.50 | |
| 3974 | Rethinking the bert-like pretraining for dna sequences | 5.00 | 5.25 | 1.30 | 0.25 | |
| 3975 | Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View | 5.50 | 5.00 | 3.08 | -0.50 | |
| 3976 | Uncovering hidden geometry in Transformers via disentangling position and context | 4.33 | 5.33 | 0.47 | 1.00 | |
| 3977 | ImAD: An End-to-End Method for Unsupervised Anomaly Detection in the Presence of Missing Values | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3978 | SimSCOOD: Systematic Analysis of Out-of-Distribution Generalization in Fine-tuned Source Code Models | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3979 | Optimal Action Abstraction for Imperfect Information Extensive-Form Games | 4.75 | 5.25 | 1.30 | 0.50 | |
| 3980 | Text to Image for Multi-Label Image Recognition with Joint Prompt-Adapter Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3981 | No Wrong Turns: The Simple Geometry Of Neural Networks Optimization Paths | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3982 | Spatio-temporal Twins with A Cache for Modeling Long-term System Dynamics | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3983 | Semantic Parsing with Candidate Expressions for Knowledge Base Question Answering | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3984 | DECOUPLE QUANTIZATION STEP AND OUTLIER-MIGRATED RECONSTRUCTION FOR PTQ | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3985 | Retrieval-augmented Text-to-3D Generation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3986 | Amazing Combinatorial Creation: Acceptable Swap-Sampling for Combinatorial Text-to-Image Generation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3987 | A Graph-Theoretic Framework for Joint OOD Generalization and Detection | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3988 | Fast Neural Architecture Search with Random Neural Tangent Kernel | 5.00 | 5.00 | 1.41 | 0.00 | |
| 3989 | RAVL: Reach-Aware Value Learning for the Edge-of-Reach Problem in Offline Model-Based Reinforcement Learning | 5.00 | 5.00 | 2.12 | 0.00 | |
| 3990 | Simple Minimax Optimal Byzantine Robust Algorithm for Nonconvex Objectives with Uniform Gradient Heterogeneity | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3991 | Overcoming bias towards base sessions in few-shot class-incremental learning (FSCIL) | 4.33 | 5.00 | 0.00 | 0.67 | |
| 3992 | Urial: Aligning Untuned LLMs with Just the 'Write' Amount of In-Context Learning | 4.25 | 5.00 | 1.22 | 0.75 | |
| 3993 | Swift Sampler: Efficient Learning of Sampler by 10 parameters | 5.00 | 5.00 | 0.00 | 0.00 | |
| 3994 | On the Analysis of GAN-based Image-to-Image Translation with Gaussian Noise Injection | 4.67 | 5.00 | 1.41 | 0.33 | |
| 3995 | CITING: Large Language Models Create Curriculum for Instruction Tuning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 3996 | A Fast Framework for Post-training Structured Pruning Without Retraining | 4.50 | 5.00 | 0.00 | 0.50 | |
| 3997 | Multi-scale Transformers with Adaptive Pathways for Time Series Forecasting | 4.67 | 6.67 | 0.94 | 2.00 | |
| 3998 | Bridging the gap between offline and online continual learning | 3.75 | 5.00 | 1.22 | 1.25 | |
| 3999 | Dual Prompt Tuning for Domain-Aware Federated Learning | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4000 | Preventing Reward Hacking with Occupancy Measure Regularization | 4.80 | 5.00 | 1.10 | 0.20 | | 3, 5, 6, 5, 5 | | 3, 5, 6, 6, 5 |
|
| 4001 | Task-Guided Biased Diffusion Models for Point Localization | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4002 | Exploiting Open-World Data for Adaptive Continual Learning | 4.50 | 5.00 | 1.22 | 0.50 | |
| 4003 | ReFACT: Updating Text-to-Image Models by Editing the Text Encoder | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4004 | VTruST : Controllable value function based subset selection for Data-Centric Trustworthy AI | 5.00 | 5.33 | 0.47 | 0.33 | |
| 4005 | ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation | 5.00 | 5.00 | 2.12 | 0.00 | |
| 4006 | Image Hijacks: Adversarial Images can Control Generative Models at Runtime | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4007 | 3D Object Representation Learning for Robust Classification and Pose estimation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4008 | From Language to 3D Worlds: Adapting Language Models for Point Cloud Perception | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4009 | Mitigating Backdoor Attacks in Federated Learning through Noise-Guided Aggregation | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4010 | Adaptive Slot Attention: Object Discovery with Dynamic Slot Number | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4011 | Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4012 | On progressive sharpening, flat minima and generalisation | 5.00 | 5.00 | 2.12 | 0.00 | |
| 4013 | Split and Merge: Aligning Position Biases in Large Language Model based Evaluators | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4014 | Understanding In-Context Learning from Repetitions | 4.75 | 5.50 | 0.50 | 0.75 | |
| 4015 | Federated Learning, Lessons from Generalization Study: Communicate Less, Learn More | 3.67 | 5.00 | 0.00 | 1.33 | |
| 4016 | Boosting Temporal Graph Learning From Global and Local Perspectives | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4017 | NF-ICP: Neural Field ICP for Robust 3D Human Registration | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4018 | Multi-Agent Bayesian Optimization with Coupled Black-box and Affine Constraints | 4.67 | 5.00 | 1.41 | 0.33 | |
| 4019 | Revisiting Long-term Time Series Forecasting: An Investigation on Affine Mapping | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4020 | Provable Out-of-Distribution Generalization in Hypersphere | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4021 | Unsupervised combinatorial optimization under complex conditions: Principled objectives and incremental greedy derandomization | 4.67 | 5.00 | 1.41 | 0.33 | |
| 4022 | Connection Strength-Based Optimization for Multi-Task Learning | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4023 | Distribution Shift Resilient GNN via Mixture of Aligned Experts | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4024 | Adaptive Softmax Trees for many-class classification | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4025 | CorruptEncoder: Data Poisoning based Backdoor Attacks to Contrastive Learning | 5.00 | 5.00 | 2.12 | 0.00 | |
| 4026 | Quantifying Zero-shot Coordination Capability with Behavior Preferring Partners | 3.67 | 5.00 | 1.22 | 1.33 | |
| 4027 | VideoClusterNet: Self-Supervised and Adaptive Face Clustering for Videos | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4028 | PriViT: Vision Transformers for Fast Private Inference | 5.00 | 5.25 | 0.43 | 0.25 | |
| 4029 | Pose Modulated Avatars from Video | 4.67 | 5.00 | 1.41 | 0.33 | |
| 4030 | PEAR: Primitive enabled Adaptive Relabeling for boosting Hierarchical Reinforcement Learning | 4.25 | 5.00 | 1.22 | 0.75 | |
| 4031 | Complete and Efficient Graph Transformers for Crystal Material Property Prediction | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4032 | Trust Regions for Explanations via Black-Box Probabilistic Certification | 4.60 | 5.00 | 1.90 | 0.40 | | 5, 3, 6, 3, 6 | | 5, 3, 6, 3, 8 |
|
| 4033 | What Makes Pre-Trained Visual Representations Successful for Robust Manipulation? | 4.33 | 5.00 | 0.00 | 0.67 | |
| 4034 | LLM-QAT: Data-Free Quantization Aware Training for Large Language Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4035 | Gradient Constrained Sharpness-aware Prompt Learning for Vision-Language Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4036 | Cross-domain Adaptation for Few-shot 3D Shape Generation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4037 | Motion PointNet: Solving Dynamic Capture in Point Cloud Video Human Action | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4038 | LEO: Generative Latent Image Animator for Human Video Synthesis | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4039 | Adapting LLM Agents Through Communication | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4040 | LightSeq: Sequence Level Parallelism for Distributed Training of Long Context Transformers | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4041 | Voila-A: Aligning Vision-Language Models with User's Gaze Attention | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4042 | TADA: Timestep-Aware Data Augmentation for Diffusion Models | 5.00 | 5.00 | 2.12 | 0.00 | |
| 4043 | Visual Category Discovery via Linguistic Anchoring | 5.00 | 5.00 | 2.12 | 0.00 | |
| 4044 | Robust Reinforcement Learning with Structured Adversarial Ensemble | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4045 | Semantically Aligned Task Decomposition in Multi-Agent Reinforcement Learning | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4046 | Mixing Corrupted Preferences for Robust and Feedback-Efficient Preference-Based Reinforcement Learning | 4.33 | 5.00 | 1.41 | 0.67 | |
| 4047 | Vector-valued Representation is the Key: A Study on Disentanglement and Compositional Generalization | 4.25 | 5.75 | 0.43 | 1.50 | |
| 4048 | Defect Spectrum: A Granular Look of Large-Scale Defect Datasets with Rich Semantics | 5.50 | 5.00 | 2.55 | -0.50 | |
| 4049 | Semantic Memory Guided Diffusion Networks for Image-to-Long Text Generation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4050 | A Benchmark Study on Calibration | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4051 | UniINR: Unifying Spatial-Temporal INR for RS Video Correction, Deblur, and Interpolation with an Event Camera | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4052 | Advancing Beyond Identification: Multi-bit Watermark for Large Language Models | 4.80 | 5.20 | 1.17 | 0.40 | | 3, 5, 5, 6, 5 | | 3, 6, 6, 6, 5 |
|
| 4053 | UniPose: Detecting Any Keypoints | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4054 | Graph ODE with Factorized Prototypes for Modeling Complicated Interacting Dynamics | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4055 | Bridge-TTS: Text-to-Speech Synthesis with Schrodinger Bridge | 4.25 | 5.00 | 0.00 | 0.75 | |
| 4056 | Silencer: Pruning-aware Backdoor Defense for Decentralized Federated Learning | 4.50 | 5.00 | 1.22 | 0.50 | |
| 4057 | MediTab: Scaling Medical Tabular Data Predictors via Data Consolidation, Enrichment, and Refinement | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4058 | MaXTron: Mask Transformer with Trajectory Attention for Video Panoptic Segmentation | 4.50 | 5.00 | 1.22 | 0.50 | |
| 4059 | Integrating View Conditions for Image Synthesis | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4060 | Spiking Hybrid Attentive Mechanism with Decoupled Layer Normalization for Joint Sound Localization and Classification | 5.00 | 5.00 | 2.55 | 0.00 | |
| 4061 | Open Sesame! Universal Black Box Jailbreaking of Large Language Models | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4062 | Which pre-trained model is effective for speech separation ? | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4063 | A Study of Unsupervised Evaluation Metrics for Practical and Automatic Domain Adaptation | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4064 | Unified Interpretation of Smoothing Methods for Negative Sampling Loss Functions in Knowledge Graph Embedding | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4065 | DGTAT: DECOUPLED GRAPH TRIPLE ATTENTION NETWORKS | 4.33 | 5.00 | 0.00 | 0.67 | |
| 4066 | Uncertainty-aware Distributional Offline Reinforcement Learning | 4.67 | 5.00 | 1.41 | 0.33 | |
| 4067 | DomainStudio: Fine-Tuning Diffusion Models for Domain-Driven Image Generation using Limited Data | 4.50 | 5.00 | 2.12 | 0.50 | |
| 4068 | Modeling Knowledge as Functionals for Knowledge Reasoning | 5.00 | 5.00 | 2.28 | 0.00 | | 5, 5, 8, 1, 6 | | 5, 5, 8, 1, 6 |
|
| 4069 | APD: Boosting Adversarial Transferability via Perturbation Dropout | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4070 | Why do Features of Multi-Layer Perceptrons Condense in Training? | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4071 | Rethinking Audiovisual Segmentation with Semantic Quantization and Decomposition | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4072 | LangNav: Language as a Perceptual Representation for Navigation | 5.00 | 5.00 | 1.90 | 0.00 | | 6, 8, 3, 5, 3 | | 6, 8, 3, 5, 3 |
|
| 4073 | RelationVLM: Making Large Vision-Language Models Understand Visual Relations | 5.00 | 5.00 | 1.00 | 0.00 | | 6, 5, 3, 5, 5, 6 | | 6, 5, 3, 5, 5, 6 |
|
| 4074 | Towards Architecture-Insensitive Untrained Network Priors for Accelerated MRI | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4075 | Delta-LoRA: Fine-Tuning High-Rank Parameters with the Delta of Low-Rank Matrices | 4.50 | 5.00 | 1.22 | 0.50 | |
| 4076 | Distance Estimation for High-Dimensional Distributions | 5.50 | 5.00 | 2.55 | -0.50 | |
| 4077 | Beyond Demographic Parity: Redefining Equal Treatment | 4.75 | 5.00 | 1.90 | 0.25 | |
| 4078 | Subgraph Diffusion for 3D Molecular Representation Learning: Combining Continuous and Discrete | 4.50 | 5.00 | 1.22 | 0.50 | |
| 4079 | A Effective Variance Change Detection Method under constantly Changing Mean | 4.33 | 5.00 | 0.00 | 0.67 | |
| 4080 | HelmSim: Learning Helmholtz Dynamics for Interpretable Fluid Simulation | 3.50 | 5.00 | 1.22 | 1.50 | |
| 4081 | Weakly-supervised Camera Localization by Ground-to-satellite Image Registration | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4082 | TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4083 | DiffiT: Diffusion Vision Transformers for Image Generation | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4084 | Improving Language Models via Plug-and-Play Retrieval Feedback | 5.00 | 5.50 | 0.50 | 0.50 | |
| 4085 | Masked Diffusion as Self-supervised Representation Learner | 4.25 | 5.00 | 1.22 | 0.75 | |
| 4086 | Q-Tuning: Continual Queue-based Prompt Tuning for Language Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4087 | TiG-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning | 5.00 | 5.00 | 1.90 | 0.00 | | 3, 3, 5, 6, 8 | | 3, 3, 5, 6, 8 |
|
| 4088 | SCoRe: Submodular Combinatorial Representation Learning for Real-World Class-Imbalanced Settings | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4089 | Enhancing High-Resolution 3D Generation through Pixel-wise Gradient Clipping | 5.00 | 6.00 | 0.00 | 1.00 | |
| 4090 | From Trojan Horses To Castle Walls: Revealing Bilateral Backdoor Effects In Diffision Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4091 | Towards Text-guided 3D Scene Composition | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4092 | Unseen Image Synthesis with Diffusion Models | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4093 | SEA: Sparse Linear Attention with Estimated Attention Mask | 5.00 | 5.00 | 1.41 | 0.00 | |
| 4094 | Turbulent Flow Simulation using Autoregressive Conditional Diffusion Models | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4095 | Self-Distilled Disentanglement for Counterfactual Prediction | 5.00 | 4.50 | 1.50 | -0.50 | |
| 4096 | Continual Learning via Winning Subnetworks That Arise Through Stochastic Local Competition | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4097 | LINK PREDICTION USING NEUMANN EIGENVALUES | 4.00 | 5.00 | 2.12 | 1.00 | |
| 4098 | REValueD: Regularised Ensemble Value-Decomposition for Factorisable Markov Decision Processes | 5.00 | 5.67 | 0.47 | 0.67 | |
| 4099 | Exploring Unified Perspective For Fast Shapley Value Estimation | 5.50 | 5.00 | 1.41 | -0.50 | |
| 4100 | Understanding deep neural networks through the lens of their non-linearity | 5.00 | 5.00 | 0.00 | 0.00 | |
| 4101 | SheAttack: A Silhouette Score Motivated Restricted Black-Box Attack on Graphs | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4102 | Improving Knowledge Distillation via Regularizing Feature Direction and Norm | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4103 | AdaRec: Adaptive Sequential Recommendation for Reinforcing Long-term User Engagement | 4.67 | 5.00 | 1.41 | 0.33 | |
| 4104 | GeONet: a neural operator for learning the Wasserstein geodesic | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4105 | Improving the efficiency of conformal predictors via test-time augmentation | 4.00 | 4.83 | 1.34 | 0.83 | | 3, 3, 6, 6, 3, 3 | | 3, 3, 6, 6, 5, 6 |
|
| 4106 | Risk Assessment and Statistical Significance in the Age of Foundation Models | 4.83 | 4.83 | 1.34 | 0.00 | | 3, 6, 5, 6, 3, 6 | | 3, 6, 5, 6, 3, 6 |
|
| 4107 | Uncovering the Spectrum of Graph Generative Models: From One-Shot to Sequential | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 5, 6, 3, 5 | | 5, 5, 6, 3, 5 |
|
| 4108 | X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 5, 6, 3, 5 | | 5, 5, 6, 3, 5 |
|
| 4109 | Self-Supervised Learning with the Matching Gap | 4.80 | 4.80 | 2.23 | 0.00 | | 5, 3, 3, 8, 5 | | 5, 5, 1, 8, 5 |
|
| 4110 | FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation | 5.00 | 4.80 | 0.98 | -0.20 | | 5, 6, 3, 6, 5 | | 5, 6, 3, 5, 5 |
|
| 4111 | Plausibly Deniable Encryption with Large Language Models | 6.50 | 4.80 | 1.83 | -1.70 | |
| 4112 | Quantifying Classification Performance through Combinatorial Geometry and Localized Data Analysis | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 5, 3, 6, 5 | | 5, 5, 3, 6, 5 |
|
| 4113 | Why Clean Generalization and Robust Overfitting Both Happen in Adversarial Training | 4.80 | 4.80 | 0.98 | 0.00 | | 3, 6, 5, 5, 5 | | 3, 6, 5, 5, 5 |
|
| 4114 | Exploring the Relationship between In-Context Learning and Instruction Tuning | 4.80 | 4.80 | 1.83 | 0.00 | | 5, 3, 8, 5, 3 | | 5, 3, 8, 5, 3 |
|
| 4115 | Leveraging Behavioral Cloning for Representation Alignment in Cross-Domain Policy Transfer | 4.80 | 4.20 | 0.98 | -0.60 | | 5, 5, 3, 8, 3 | | 5, 5, 3, 5, 3 |
|
| 4116 | On Memorization in Diffusion Models | 4.80 | 4.80 | 0.98 | 0.00 | | 3, 5, 6, 5, 5 | | 3, 5, 6, 5, 5 |
|
| 4117 | Structured Fine-Tuning Enables Data-Efficient Adaptation of Code Language Models | 4.80 | 4.80 | 1.83 | 0.00 | | 5, 8, 3, 5, 3 | | 5, 8, 3, 5, 3 |
|
| 4118 | Reward Centering | 4.40 | 4.80 | 0.98 | 0.40 | | 5, 3, 5, 6, 3 | | 5, 5, 5, 6, 3 |
|
| 4119 | Sum-of-Parts Models: Faithful Attributions for Groups of Features | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 5, 3, 5, 6 | | 5, 5, 3, 5, 6 |
|
| 4120 | Open-Domain Text Evaluation via Contrastive Distribution Methods | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 5, 6, 5, 3 | | 5, 5, 6, 5, 3 |
|
| 4121 | Revealing Vision-Language Integration in the Brain with Multimodal Networks | 4.20 | 4.80 | 1.47 | 0.60 | | 3, 3, 6, 6, 3 | | 6, 3, 6, 6, 3 |
|
| 4122 | Sparse Autoencoders Find Highly Interpretable Features in Language Models | 4.80 | 4.80 | 1.94 | 0.00 | | 5, 6, 1, 6, 6 | | 5, 6, 1, 6, 6 |
|
| 4123 | A Semi-smooth, Self-shifting, and Singular Newton Method for Sparse Optimal Transport | 4.60 | 4.80 | 1.47 | 0.20 | | 6, 3, 6, 5, 3 | | 6, 3, 6, 6, 3 |
|
| 4124 | Learning to Branch with Offline Reinforcement Learning | 4.80 | 4.80 | 1.83 | 0.00 | | 5, 3, 3, 8, 5 | | 5, 3, 3, 8, 5 |
|
| 4125 | Identifiable Latent Polynomial Causal Models through the Lens of Change | 4.60 | 4.80 | 1.47 | 0.20 | | 6, 3, 6, 5, 3 | | 6, 3, 6, 6, 3 |
|
| 4126 | Selective Prediction via Training Dynamics | 4.80 | 5.00 | 1.10 | 0.20 | | 5, 3, 5, 6, 5 | | 5, 5, 6, 6, 3 |
|
| 4127 | Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 6, 3, 5, 5 | | 5, 6, 3, 5, 5 |
|
| 4128 | KLIP: Keyword-Guided Language-Image Pretraining for Data-Efficient Domain-Specific Image Captioning | 4.60 | 4.80 | 0.98 | 0.20 | | 5, 5, 5, 3, 5 | | 5, 5, 5, 3, 6 |
|
| 4129 | Linguistically-Inspired and Explainable Demonstration Retrieval for In-Context Learning | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 3, 5, 6, 5 | | 5, 3, 5, 6, 5 |
|
| 4130 | FedPop: Federated Population-based Hyperparameter Tuning | 4.80 | 4.80 | 1.83 | 0.00 | | 8, 5, 3, 3, 5 | | 8, 5, 3, 3, 5 |
|
| 4131 | BEEF: Building a BridgE from Event to Frame | 4.80 | 4.80 | 0.98 | 0.00 | | 6, 5, 5, 3, 5 | | 6, 5, 5, 3, 5 |
|
| 4132 | Neuro-Causal Factor Analysis | 4.80 | 4.80 | 0.98 | 0.00 | | 6, 3, 5, 5, 5 | | 6, 3, 5, 5, 5 |
|
| 4133 | All for One and One for All: A Collaborative FL Framework for Generic Federated Learning with Personalized Plug-ins | 4.40 | 4.80 | 0.98 | 0.40 | | 5, 3, 6, 3, 5 | | 5, 5, 6, 3, 5 |
|
| 4134 | Rethinking Multi-domain Generalization with A General Learning Objective | 4.80 | 4.80 | 0.98 | 0.00 | | 6, 3, 5, 5, 5 | | 6, 3, 5, 5, 5 |
|
| 4135 | CAST: Cluster-Aware Self-Training for Tabular Data | 4.40 | 4.80 | 0.98 | 0.40 | | 6, 5, 3, 3, 5 | | 6, 5, 3, 5, 5 |
|
| 4136 | IMP: Benchmarking Image Polysemy in Vision-Language Models | 4.80 | 4.80 | 1.83 | 0.00 | | 3, 5, 8, 5, 3 | | 3, 5, 8, 5, 3 |
|
| 4137 | Prototypical Influence Function for Fully Test-time Adaptation | 5.00 | 4.60 | 0.80 | -0.40 | | 6, 5, 3, 6, 5 | | 5, 5, 3, 5, 5 |
|
| 4138 | Learning SO(3)-Invariant Correspondence via Point-wise Local Shape Transform | 4.80 | 4.80 | 0.98 | 0.00 | | 6, 5, 3, 5, 5 | | 6, 5, 3, 5, 5 |
|
| 4139 | Power Characterization of Noisy Quantum Kernels | 4.80 | 4.80 | 0.98 | 0.00 | | 5, 6, 5, 5, 3 | | 5, 6, 5, 5, 3 |
|
| 4140 | Continual Test-Time Adaptation by Leveraging Source Prototypes and Exponential Moving Average Target Prototypes | 4.80 | 4.80 | 0.98 | 0.00 | | 3, 5, 5, 6, 5 | | 3, 5, 5, 6, 5 |
|
| 4141 | RegCLIP: A Label-Efficient Coarse-to-Fine Learner for Ordinal Regression | 4.80 | 4.80 | 1.83 | 0.00 | | 3, 5, 5, 8, 3 | | 3, 5, 5, 8, 3 |
|
| 4142 | PAIR Diffusion: A Comprehensive Multimodal Object-Level Image Editor | 4.80 | 4.80 | 1.47 | 0.00 | | 6, 6, 6, 3, 3 | | 6, 6, 6, 3, 3 |
|
| 4143 | Lifelong Audio-video Masked Autoencoder with Forget-robust Localized Alignments | 4.80 | 5.20 | 0.40 | 0.40 | | 5, 5, 6, 5, 3 | | 5, 5, 6, 5, 5 |
|
| 4144 | Overcoming Data and Model heterogeneities in Decentralized Federated Learning via Synthetic Anchors | 4.80 | 4.80 | 1.47 | 0.00 | | 3, 6, 3, 6, 6 | | 3, 6, 3, 6, 6 |
|
| 4145 | Doubly Robust Structure Identification from Temporal Data | 4.80 | 4.80 | 1.47 | 0.00 | | 3, 3, 6, 6, 6 | | 3, 3, 6, 6, 6 |
|
| 4146 | Linear diffusion models meet contextual bandits with large action spaces | 4.80 | 4.80 | 1.47 | 0.00 | | 1, 6, 6, 5, 6 | | 3, 6, 6, 3, 6 |
|
| 4147 | RLP: A reinforcement learning benchmark for neural algorithmic reasoning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4148 | FruitBin: A tunable large-scale dataset for advancing 6D Pose estimation in fruit bin picking automation | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4149 | Task-Oriented Multi-View Representation Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4150 | Negative-prompt Inversion: Fast Image Inversion for Editing with Text-guided Diffusion Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4151 | Differentiable Optimization in Plane-Wave Density Functional Theory for Solid States | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4152 | LMExplainer: A Knowledge-Enhanced Explainer for Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4153 | Social-Transmotion: Promptable Human Trajectory Prediction | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4154 | Cross-Lingual Transfer with Large Language Models via Adaptive Adapter Merging | 4.25 | 4.75 | 2.05 | 0.50 | |
| 4155 | On Synthetic Data and Iterative Magnitude Pruning: a Linear Mode Connectivity Study | 3.75 | 4.75 | 1.09 | 1.00 | |
| 4156 | Antibody DomainBed: Out-of-Distribution Generalization in Therapeutic Protein Design | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4157 | FILI: Syntax Repair By Learning From Own Mistakes | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4158 | Structured Graph Reduction for Efficient GNN | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4159 | Learning to Explore for Stochastic Gradient MCMC | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4160 | PACIA: Parameter-Efficient Adapter for Few-Shot Molecular Property Prediction | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4161 | Group Robustness via Adaptive Class-Specific Scaling | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4162 | Efficient Large Language Models Fine-Tuning on Graphs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4163 | Multi-Method Self-Training: Improving Code Generation With Text, And Vice Versa | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4164 | Robustness Evaluation of Proxy Models against Adversarial Optimization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4165 | How do skip connections affect Graph Convolutional networks with graph sampling? A theoretical analysis on generalization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4166 | Understanding Contrastive Learning Through the Lens of Margins | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4167 | Cross-modality debiasing: using language to mitigate sub-population shifts in imaging | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4168 | Graph neural processes and their application to molecular functions | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4169 | Limited-Memory Greedy Quasi-Newton Method with Non-asymptotic Superlinear Convergence Rate | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4170 | Malcom-PSGD: Inexact Proximal Stochastic Gradient Descent for Communication Efficient Decentralized Machine Learning | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4171 | RF-POLICY: Rectified Flows are Adaptive Decision Makers | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4172 | GUARD: A Safe Reinforcement Learning Benchmark | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4173 | Clarify When Necessary: Resolving Ambiguity with Language Models | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4174 | Deep Independent Vector Analysis | 4.25 | 4.50 | 0.87 | 0.25 | |
| 4175 | Neural Rankers for Code Generation via Inter-Cluster Modeling | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4176 | Analyzing Neural Network Based Generative Diffusion Models via Convexification | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4177 | Training Diffusion Classifiers with Denoising Assistance | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4178 | DEXR: A Unified Approach Towards Environment Agnostic Exploration | 3.75 | 4.75 | 1.09 | 1.00 | |
| 4179 | Task Generalization in Decision-Focused Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4180 | Basis Function Encoding of Numerical Features in Factorization Machines for Improved Accuracy | 5.29 | 4.75 | 1.09 | -0.54 | | 6, 5, 8, 5, 5, 5, 3 | | 6, 5, 6, 5, 5, 5, 3, 3 |
|
| 4181 | Fourier Ordinary Differential Equations | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4182 | NEURAL ADDITIVE TENSOR DECOMPOSITION FOR SPARSE TENSORS | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4183 | Effective Graph Representation Learning via Smoothed Contrastive Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4184 | Understanding of Server-Assisted Federated Learning with Incomplete Client Participation | 3.67 | 4.75 | 2.05 | 1.08 | |
| 4185 | Explaining Contrastive Models using Exemplars: Explanation, Confidence, and Knowledge Limits | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4186 | Proximal Preference Optimization for Diffusion Models | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4187 | Modular Learning of Deep Causal Generative Models for High-dimensional Causal Inference | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4188 | Class-Wise Generalization Error: An Information-Theoretic Analysis | 4.75 | 5.25 | 0.43 | 0.50 | |
| 4189 | Can LLM-Generated Misinformation Be Detected? | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4190 | Molecule Relaxation by Reverse Diffusion with Time Step Prediction | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4191 | Balancing Stability and Plasticity in Continual Learning: the readout-decomposition of activation change (RDAC) framework | 4.75 | 5.25 | 0.43 | 0.50 | |
| 4192 | Reduced-Rank Online Gaussian Process Modeling With Uncertain Inputs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4193 | Beyond Differentiability: Neurosymbolic Learning with Black-Box Programs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4194 | FedDRO: Federated Compositional Optimization for Distributionally Robust Learning | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4195 | SOI: Scaling down computational complexity by estimating partial states of the model | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4196 | IMPROVING ADVERSARIAL TRAINING WITH MARGIN- WEIGHTED PERTURBATION BUDGET | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4197 | Elephants Never Forget: Testing Language Models for Memorization of Tabular Data | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4198 | Learning the Latent Noisy Data Generative Process for Label-Noise Learning | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4199 | Jailbreaking Black Box Large Language Models in Twenty Queries | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4200 | Assessing Robustness via Score-based Adversarial Image Generation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4201 | Improving Robustness in Vision Transformers with Nullspace Noise Augmented Finetuning | 4.75 | 4.75 | 2.49 | 0.00 | |
| 4202 | Subspace Grid-sweep: ML Defense Evaluation via Constrained Brute-force Search | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4203 | Gaussian Process-Based Corruption-resilience Forecasting Models | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4204 | An Extensive Analysis on the Underlying Premises Behind Deep Reinforcement Learning Algorithm Design | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4205 | Vlearn: Off-Policy Learning with Efficient State-Value Function Estimation | 4.25 | 5.00 | 1.22 | 0.75 | |
| 4206 | CL-Calib: Enhancing Post-training Quantization Calibration through Contrastive Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4207 | Rethinking the Solution to Curse of Dimensionality on Randomized Smoothing | 4.75 | 4.75 | 2.49 | 0.00 | |
| 4208 | Predictive Coding beyond Correlations | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4209 | Parameter-Free Molecular Classification and Regression with Gzip | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4210 | From Fourier to Neural ODEs: Flow matching for modeling complex systems | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4211 | GraphDeepONet: Learning to simulate time-dependent partial differential equations using graph neural network and deep operator network | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4212 | Theoretical Analysis on the Generalization Power of Overfitted Transfer Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4213 | Representation Disentanglement via Regularization by Causal Identification | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4214 | Escaping the Sample Trap: Fast and Accurate Epistemic Uncertainty Estimation with Pairwise-Distance Estimators | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4215 | Multimodal Question Answering for Unified Information Extraction | 4.67 | 4.75 | 2.05 | 0.08 | |
| 4216 | Autonomous Tree-search Ability of Large Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4217 | ZOOPFL: EXPLORING BLACK-BOX FOUNDATION MODELS FOR PERSONALIZED FEDERATED LEARNING | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4218 | Navigating the Design Space of Equivariant Diffusion-Based Generative Models for De Novo 3D Molecule Generation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4219 | DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4220 | Geometry-Guided Conditional Adaption for Surrogate Models of Large-Scale 3D PDEs on Arbitrary Geometries | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4221 | Graph Neural Networks on Symmetric Positive Definite Manifold | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4222 | Pruning Attention Heads with Almost-sure Sparsity Targets | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4223 | Flood and Echo: Algorithmic Alignment of GNNs with Distributed Computing | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4224 | L(M)V-IQL: Multiple Intention Inverse Reinforcement Learning for Animal Behavior Characterization | 4.00 | 5.25 | 0.43 | 1.25 | |
| 4225 | ProtoReg: Prioritizing Discriminative Information for Fine-grained Transfer Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4226 | Generative Semantic Communication: Diffusion Models Beyond Bit Recovery | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4227 | State Chrono Representation for Enhancing Generalization in Reinforcement Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4228 | SuperPos-Prompt: Enhancing Soft Prompt Tuning of Language Models with Superposition of Multi Token Embeddings | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4229 | Mixture-of-Experts in Prompt Optimization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4230 | Physics Informed Distillation for Diffusion Models | 4.25 | 5.00 | 1.22 | 0.75 | |
| 4231 | Learning to Explore with In-Context Policy for Fast Peer Adaptation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4232 | What do vision transformers learn? A visual exploration | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4233 | A Neural Tangent Kernel Approach for Constrained Policy Gradient Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4234 | Generalizing Poincaré Policy Representations in Multi-agent Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4235 | Analyzing Deep Transformer Models for Time Series Forecasting via Manifold Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4236 | SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction | 4.75 | 5.50 | 0.50 | 0.75 | |
| 4237 | In Search of the Long-Tail: Systematic Generation of Long-Tail Knowledge via Logical Rule Induced Search | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4238 | LMO-DP: Accurately Fine-Tuning Language Models with Stronger Differential Privacy | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4239 | Small Visual Language Models can also be Open-Ended Few-Shot Learners | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4240 | Communication Bounds for the Distributed Experts Problem | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4241 | Enhancing Detail Preservation for Customized Text-to-Image Generation: A Regularization-Free Approach | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4242 | Counterfactual Data Augmentation with Contrastive Learning | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4243 | Describe-and-Dissect: Interpreting Neurons in Vision Networks with Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4244 | Learning UI-to-Code Reverse Generator Using Visual Critic Without Rendering | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4245 | Understanding Domain Generalization: A Noise Robustness Perspective | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4246 | Federated Natural Policy Gradient Methods for Multi-task Reinforcement Learning | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4247 | A Bayesian Approach for Personalized Federated Learning in Heterogeneous Settings | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4248 | Hierarchical Graph Latent Diffusion Model for Molecule Generation | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4249 | Conservative Prediction via Data-Driven Confidence Minimization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4250 | Sparse-Guard: Sparse Coding-Based Defense against Model Inversion Attacks | 3.75 | 4.75 | 1.09 | 1.00 | |
| 4251 | On the Possibilities of AI-Generated Text Detection: A Sample Complexity Analysis | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4252 | Reflective Policy Optimization | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4253 | On Transferring Expert Knowledge from Tabular Data to Images | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4254 | Provable Benefit of Adaptivity in Adam | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4255 | FedBiOT: a solution for federated large language model fine-tuning with intellectual property protection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4256 | Value Bonuses using Ensemble Errors for Exploration in Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4257 | The Impact of Depth and Width on Transformer Language Model Generalization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4258 | PostRainBench: A Comprehensive Benchmark and A New Model for Precipitation Forecasting | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4259 | Implicit Neural Network on Dynamic Graphs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4260 | Learning-Retrieval-Revision For Large Language Model Domain Adaptation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4261 | Fast Post-training Analysis of NeRFs Using A Simple Visibility Prediction Network | 4.75 | 4.00 | 1.00 | -0.75 | |
| 4262 | MATT: Random Local Implicit Purification for Defending Query-based Attacks | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4263 | Text Descriptions are Compressive and Invariant Representations for Visual Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4264 | X-SHOT: A Single System to Handle Frequent, Few-shot and Zero-shot Labels in Classification | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4265 | Can Large Language Models be Good Path Planners? A Benchmark and Investigation on Spatial-Temporal Reasoning | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4266 | JoinGym: An Efficient Query Optimization Environment for Reinforcement Learning | 3.50 | 4.75 | 1.09 | 1.25 | |
| 4267 | Towards Neural Architecture Search through Hierarchical Generative Modeling | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4268 | OptiMUS: Optimization Modeling Using mip Solvers and large language models | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4269 | Few-Shot Detection of Machine-Generated Text using Style Representations | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4270 | Recurrent Linear Transformers | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4271 | Counterfactual Generative Models for Time-Varying Treatments | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4272 | Simplicial SMOTE: Oversampling Solution to the Imbalanced Learning Problem | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4273 | Prompt Engineering a Prompt Engineer | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4274 | A Competition Winning Deep Reinforcement Learning Agent in microRTS | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4275 | Adaptive Invariant Representation Learning for Non-stationary Domain Generalization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4276 | Aligning Text-to-Image Diffusion Models with Reward Backpropagation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4277 | MoReDrop: Dropout Without Dropping | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4278 | Learning to Generate Better than your Large Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4279 | Towards Minimal Targeted Updates of Language Models with Targeted Negative Training | 4.75 | 5.25 | 0.43 | 0.50 | |
| 4280 | Multi-Image Zero-Shot Subject Generation for Visual Storytelling | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4281 | Personalized Residuals for Concept-Driven Text-to-Image Generation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4282 | Multi-modality Adversarial Attacks on Latent Diffusion Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4283 | A Structured Pruning Algorithm for Model-based Deep Learning | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4284 | CrossGET: Cross-Guided Ensemble of Tokens for Accelerating Vision-Language Transformers | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4285 | Translating cognitive models into neural and statistical descriptions of real-world multi-agent foraging behavior | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4286 | Characterizing Long-Tail Categories on Graphs via A Theory-Driven Framework | 4.25 | 4.75 | 2.05 | 0.50 | |
| 4287 | Tree-based Ensemble Learning for Out-of-distribution Detection | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4288 | Masked AutoDecoder is Effective Multi-Task Vision Generalist | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4289 | PEMs: Pre-trained Epidemic Time-Series Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4290 | Loci-Segmented: Improving Scene Segmentation Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4291 | Hierarchical Empowerment: Towards Tractable Empowerment-Based Skill Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4292 | Learning Abstract World Models for Value-preserving Planning with Options | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4293 | Lookahead Sharpness-Aware Minimization | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4294 | DisCo-DSO: Coupling Discrete and Continuous Optimization for Efficient Generative Design in Hybrid Spaces | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4295 | MapLearn: Indoor Mapping using Audio | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4296 | Disentangling the Link Between Image Statistics and Human Perception | 5.25 | 5.25 | 0.43 | 0.00 | |
| 4297 | Distributed DPHelmet: Differentially Private Non-interactive Convex Blind Averaging | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4298 | Learning Graph Representations via Graph Entropy Maximization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4299 | The Central Spanning Tree Problem | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4300 | Model-Decoupling-Based Federated Learning with Consistency via Knowledge Distillation Using Conditional Generator | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4301 | Multi-Level Contrastive Learning for Dense Prediction Task | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4302 | Adaptive Learning of Quantum Hamiltonians | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4303 | Radar Spectra-language Model for Automotive Scene Parsing | 3.75 | 4.75 | 1.09 | 1.00 | |
| 4304 | Quantifying and Defending against the Privacy Risk in Logit-based Federated Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4305 | WEAR: An Outdoor Sports Dataset for Wearable and Egocentric Activity Recognition | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4306 | When Treatment Effect Estimation Meets Collider Bias: A Dual Counterfactual Generative Approach | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4307 | 4D Tensor Multi-task Continual Learning for Disease Dynamic Prediction | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4308 | Identifiability Matters: Revealing the Hidden Recoverable Condition in Unbiased Learning to Rank | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4309 | Benchmarking Multimodal Variational Autoencoders: CdSprites+ Dataset and Toolkit | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4310 | FLea: Improving federated learning on scarce and label-skewed data via privacy-preserving feature augmentation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4311 | Fine-tuning can cripple foundation models; preserving features may be the solution | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4312 | Denoising Graph Dissipation Model Improves Graph Representation Learning | 5.25 | 4.75 | 1.09 | -0.50 | |
| 4313 | MeMo: Meaningful, Modular Controllers Via Information Bottlenecks | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4314 | Molecule Generation by Heterophilious Triple Flows | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4315 | It's About Time: Temporal References in Emergent Communication | 3.75 | 4.75 | 1.09 | 1.00 | |
| 4316 | SelfClean: A Self-Supervised Data Cleaning Strategy | 4.75 | 4.75 | 2.17 | 0.00 | |
| 4317 | PreCoT: Problem Representation Enhances Reasoning in Large Language Models | 4.25 | 4.75 | 2.05 | 0.50 | |
| 4318 | Assessing Large Language Models on Climate Information | 4.25 | 5.25 | 1.79 | 1.00 | |
| 4319 | Split-and-Denoise: Protect large language model inference with local differential privacy | 4.00 | 4.75 | 2.05 | 0.75 | |
| 4320 | M$^4$LE: A Multi-Ability Multi-Range Long Context Evaluation Benchmark for Large Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4321 | Algorithmic Stability Unleashed: Generalization Bounds with Unbounded Losses | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4322 | AROID: Improving Adversarial Robustness through Online Instance-wise Data Augmentation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4323 | $R^2$: Range Regularization for Model Compression and Quantization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4324 | Conservative World Models | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4325 | Scalable Lipschitz Estimation for CNNs | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4326 | Constructive Large Language Model Alignment with Diverse Feedback | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4327 | Momentum-SAM: Sharpness Aware Minimization without Computational Overhead | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4328 | May the Forgetting Be with You: Alternate Replay for Learning with Noisy Labels | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4329 | PowerGraph: A power grid benchmark dataset for graph neural networks | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4330 | Effective pruning of web-scale datasets based on complexity of concept clusters | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4331 | BRUSLEATTACK: QUERY-EFFICIENT SCORE-BASED SPARSE ADVERSARIAL ATTACK | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4332 | Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4333 | Zero-Shot Visual Classification with Guided Cropping | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4334 | Generalized Convergence Analysis of Tsetlin Machines: A Probabilistic Approach to Concept Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4335 | NaturalSigner: Diffusion Models are Natural Sign Language Generator | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4336 | Query and Response Augmentation Cannot Help Out-of-domain Math Reasoning Generalization | 5.50 | 4.75 | 1.09 | -0.75 | |
| 4337 | Multiple Object Stitching for Unsupervised Representation Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4338 | Large Language Models can Learn Rules | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4339 | Improving MLP Module in Vision Transformer | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4340 | Unleash Data Generation for Efficient and Effective Data-free Knowledge Distillation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4341 | Calibrated on Average, but not Within Each Slice: Few-shot Calibration for All Slices of a Distribution | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4342 | Memory-Modular Classification: Learning to Generalize with Memory Replacement | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4343 | Learning to Generate Predictor for Long-Term Time Series Forecasting | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4344 | xCodeEval: An Execution based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval | 4.67 | 4.75 | 1.09 | 0.08 | |
| 4345 | In-Context Learning with Iterative Demonstration Selection | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4346 | Graph Representation Learning enhanced Semi-supervised Feature Selection | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4347 | Linear Attention via Orthogonal Memory | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4348 | Coreset Selection For Object Detection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4349 | ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4350 | Reduce, Reuse, and Recycle: Navigating Test-Time Adaptation with OOD-Contaminated Streams | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4351 | FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4352 | Model Inversion Robustness: Can Transfer Learning Help? | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4353 | Enhancing Personal Decentralized Federated Learning through Model Decoupling | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4354 | A New Theoretical Perspective on Data Heterogeneity in Federated Averaging | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4355 | STAGE Net: Spatio-Temporal Attention-based Graph Encoding for Learning Multi-Agent Interactions in the presence of Hidden Agents | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4356 | RetroDiff: Retrosynthesis as Multi-stage Distribution Interpolation | 4.67 | 4.25 | 1.30 | -0.42 | |
| 4357 | Graph Structure and Feature Extrapolation for Out-of-Distribution Generalization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4358 | Complex-valued Scattering Representations | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4359 | Rotation-Equivariance and Position Encodings for Enhancing Local Descriptors | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4360 | Set-based Neural Network Encoding | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4361 | AutoJoin: Efficient Adversarial Training against Gradient-Free Perturbations for Ro- bust Maneuvering via Denoising Autoencoder and Joint Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4362 | Text-Free Federated Transformers Knowledge Distillation Without GAN | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4363 | Continual Learning Knowledge Graph Embeddings for Dynamic Knowledge Graphs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4364 | Unsupervised Event Outlier Detection in Continuous Time | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4365 | CoMNet: Where Biology Meets ConvNets | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4366 | Large Language Models as Tool Makers | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4367 | Neural implicit mapping via nested neighborhoods: real-time rendering of neural SDFs with textures | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4368 | Active Continual Learning: On Balancing Knowledge Retention and Learnability | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4369 | A LOCAL POLYAK-ŁOJASIEWICZ AND DESCENT LEMMA OF GRADIENT DESCENT FOR OVERPARAMETERIZED LINEAR MODELS | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4370 | Identifiable Latent Causal Content for Domain Adaptation under Latent Covariate Shift | 4.75 | 4.25 | 1.92 | -0.50 | |
| 4371 | Taming Self-Training for Open-Vocabulary Object Detection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4372 | Sparse Backpropagation for MoE Training | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4373 | Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4374 | Larger language models do in-context learning differently | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4375 | Chain-of-Thought Reasoning is a Policy Improvement Operator | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4376 | MMToM-QA: Multimodal Theory of Mind Question Answering | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4377 | Coarse-Tuning Models of Code with Reinforcement Learning Feedback | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4378 | On the efficacy of group-wise clipping in differentially private optimization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4379 | Optimisation-Based Multi-Modal Semantic Image Editing | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4380 | Token Alignment via Character Matching for Subword Completion | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4381 | Exponentially Expanding the Compiler Phase-Ordering Problem's Search Space through the Learning of Dormant Information | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4382 | Alignment and Outer Shell Isotropy for Hyperbolic Graph Contrastive Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4383 | Risk-Controlling Model Selection via Guided Bayesian Optimization | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4384 | On the Hyperparameter Loss Landscapes of Machine Learning Algorithms | 4.00 | 5.75 | 1.30 | 1.75 | |
| 4385 | Spaced Scheduling Enhances Instruction-Prompted Reasoning in Large Language Models | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4386 | Searching for Parameter-Efficient Tuning Architecture for Text-to-image Diffusion Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4387 | ICE: Image-Caption Encoding for Improved Out-Of-Distribution Generalization In Vision-Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4388 | Trading-off Multiple Properties for Molecular Optimization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4389 | Best Response Shaping | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4390 | Last One Standing: A Comparative Analysis of Security and Privacy of Soft Prompt Tuning, LoRA, and In-Context Learning | 3.75 | 4.75 | 2.49 | 1.00 | |
| 4391 | Efficient Gradient Estimation via Adaptive and Importance Sampling | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4392 | Change Point Detection via Variational Time-Varying Hidden Markov Model | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4393 | Promoting Exploration in Memory-Augmented Adam using Critical Momenta | 4.67 | 4.75 | 1.09 | 0.08 | |
| 4394 | S(^{2})-DMs: Skip-Step Diffusion Models | 5.25 | 4.75 | 2.05 | -0.50 | |
| 4395 | Query Efficient Black-Box Adversarial Attack with Automatic Region Selection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4396 | OKR-Agent: An Object and Key Results Driven Agent System with Hierarchical Self-Collaboration and Self-Evaluation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4397 | HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4398 | Generation of Geodesics with Actor-Critic Reinforcement Learning to Predict Midpoints | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4399 | MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4400 | NSM4D: Neural Scene Model Based Online 4D Point Cloud Sequence Understanding | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4401 | An Efficient Subgraph GNN with Provable Substructure Counting Power | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4402 | Con4m: Unleashing the Power of Consistency and Context in Classification for Blurred-Segmented Time Series | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4403 | Prediction Tasks in Graphs: a Framework to Control the Interpretability-Performance Trade-off | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4404 | Taming Mode Collapse in Score Distillation for Text-to-3D Generation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4405 | Task-Distributionally Robust Data-Free Meta-Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4406 | RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4407 | Factual and Personalized Recommendation Language Modeling with Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4408 | InfoGround: Ground Manipulation Concepts with Maximal Information Boost | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4409 | Large Language Models can be Guided to Evade AI-generated Text Detection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4410 | Fine-grained Text-to-Image Synthesis with Semantic Refinement | 5.25 | 4.75 | 1.09 | -0.50 | |
| 4411 | Curriculum metric learning for robust image retrieval | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4412 | ON LEARNABILITY AND EXPERIENCE REPLAY METHODS FOR GRAPH INCREMENTAL LEARNING ON EVOLVING GRAPHS | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4413 | Improving Private Training via In-distribution Public Data Synthesis and Generalization | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4414 | RegionSpot: Unleashing the Power of Frozen Foundation Models for Open-World Region Understanding | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4415 | A Graph is Worth 1-bit Spikes: When Graph Contrastive Learning Meets Spiking Neural Networks | 4.75 | 5.25 | 1.30 | 0.50 | |
| 4416 | Scaling up Trustless DNN Inference with Zero-Knowledge Proofs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4417 | ZeroNVS: Zero-shot 360-degree View Synthesis from a Single Real Image | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4418 | Multitask Image-to-Image Diffusion Models with Fine-Grained Control | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4419 | Deepfake Detection with Contrastive Learning in Curved Spaces | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4420 | Open-world Instance Segmentation: Top-down Learning with Bottom-up Supervision | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4421 | Growing Tiny Networks: Spotting Expressivity Bottlenecks and Fixing Them Optimally | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4422 | Optimization and Generalizability: Fair Benchmarking for Stochastic Algorithms | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4423 | Chain-of-Verification Reduces Hallucination in Large Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4424 | Visual Prompting Upgrades Neural Network Sparsification: A Data-Model Perspective | 5.25 | 4.50 | 0.87 | -0.75 | |
| 4425 | Lightweight, Pre-trained Transformers for Remote Sensing Timeseries | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4426 | Constructing Informative Subtask Representations for Multi-Agent Coordination | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4427 | Feature Accentuation: Explaining 'what' features respond to in natural images | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4428 | GraphText: Graph Learning in Text Space | 4.25 | 4.75 | 2.05 | 0.50 | |
| 4429 | Bag of Features: New Baselines for GNNs for Link Prediction | 4.25 | 4.75 | 2.05 | 0.50 | |
| 4430 | Temporal Spiking Generative Adversarial Networks for Heading Direction Decoding | 4.75 | 4.75 | 2.49 | 0.00 | |
| 4431 | Retrieval-Based Video Language Model for Efficient Long Video Question Answering | 4.00 | 4.75 | 1.09 | 0.75 | |
| 4432 | AutoM3L: Automated Multimodal Machine Learning with Large Language Model | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4433 | MultiReAct: Multimodal Tools Augmented Reasoning-Acting Traces for Embodied Agent Planning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4434 | Nonparametric Classification on Low Dimensional Manifolds using Overparameterized Convolutional Residual Networks | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4435 | Slightly Harmonizing Certified Robust Radius and Accuracy | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4436 | LL-VQ-VAE: Learnable Lattice Vector-Quantization For Efficient Representations | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4437 | LLM-Deliberation: Evaluating LLMs with Interactive Multi-Agent Negotiation Game | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4438 | A New Tensor Network: Tubal Tensor Train Network and its Applications | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4439 | GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks | 4.75 | 5.00 | 2.12 | 0.25 | |
| 4440 | Catastrophic Negative Transfer: An Overlooked Problem in Continual Reinforcement Learning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4441 | Forgedit: Text Guided Image Editing via Learning and Forgetting | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4442 | How Temporal Unrolling Supports Neural Physics Simulators | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4443 | Learning variable-length skills through Novelty-based Decision Point Identification | 5.33 | 4.75 | 2.05 | -0.58 | |
| 4444 | ReX: A Framework for Incorporating Temporal Information in Model-Agnostic Local Explanation Techniques | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4445 | On the Role of Momentum in the Implicit Bias of Gradient Descent for Diagonal Linear Networks | 3.75 | 4.75 | 1.09 | 1.00 | |
| 4446 | Chat-UniVi: A Unified Vision-Language Model for Image and Video Understanding | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4447 | SERA: Sample Efficient Reward Augmentation in offline-to-online Reinforcement Learning | 3.00 | 4.75 | 1.09 | 1.75 | |
| 4448 | Spatio-Temporal Graph Learning with Large Language Model | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4449 | Out-of-Distribution Detection with Hyperspherical Energy | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4450 | Exploring the Effectiveness of Diffusion Models in One-Shot Federated Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4451 | Sapling: $underline{S}$uccessive $underline{A}$daptation and Com$underline{p}$ression with $underline{L}$ayer Dropp$underline{ing}$ for LLMs | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4452 | A Collaborative Perspective on Exploration in Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4453 | Natural Language Embedded Programs for Hybrid Language Symbolic Reasoning | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4454 | Neighborhood-Informed Diffusion Model for Source-Free Domain Adaptation: Retrieving Source Ground Truth from Target Query's Neighbors | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4455 | LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models | 4.00 | 5.50 | 0.50 | 1.50 | |
| 4456 | Distill Gold from Massive Ores: Efficient Dataset Distillation via Critical Samples Selection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4457 | Generative Pretrained Embedding and Hierarchical Representation to Unlock Human Rhythm in Activities of Daily Living | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4458 | Lookbehind Optimizer: k steps back, 1 step forward | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4459 | The Uncertainty-Perception Tradeoff | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4460 | Hierarchical Concept Discovery Models: A Concept Pyramid Scheme | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4461 | Unifying Diverse Decision-Making Scenarios with Learned Discrete Actions | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4462 | SimVAE: Narrowing the gap between Discriminative & Generative Self-Supervised Representation Learning | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4463 | Knowledge Accumulating Contrastive Prompt for Continual Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4464 | Modeling Complex Mathematical Reasoning via Large Language Model based MathAgent | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4465 | The Snowflake Hypothesis: Training Deep GNN with One Node One Receptive field | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4466 | Revisiting Class-Incremental Learning with Pre-Trained Models: Generalizability and Adaptivity are All You Need | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4467 | Improving Robustness and Accuracy with Retrospective Online Adversarial Distillation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4468 | Conditional MAE: An Empirical Study of Multiple Masking in Masked Autoencoder | 4.25 | 4.75 | 2.05 | 0.50 | |
| 4469 | Coloring Deep CNN Layers with Activation Hue Loss | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4470 | Bi-level Contrastive Learning for Knowledge Enhanced Molecule Representations | 5.25 | 4.75 | 2.05 | -0.50 | |
| 4471 | Is margin all you need? An extensive empirical study of deep active learning on tabular data | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4472 | How Does Message Passing Improve Collaborative Filtering? | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4473 | On the Viability of Monocular Depth Pre-training for Semantic Segmentation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4474 | Policy Gradient without Boostrapping via Truncated Value Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4475 | PromptCCD: Learning Gaussian Mixture Prompt Pool for Continual Category Discovery | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4476 | Retentive Network: A Successor to Transformer for Large Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4477 | Efficient Training of Multi-task Combinarotial Neural Solver with Multi-armed Bandits | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4478 | Hierarchical Long-tailed Classification with Visual Language Models | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4479 | AutoNeRF: Training Implicit Scene Representations with Autonomous Agents | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4480 | Learning Informative Latent Representation for Quantum State Tomography | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4481 | Collapsing the Learning: Crafting Broadly Transferable Unlearnable Examples | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4482 | Mitigating Label Noise on Graphs via Topological Curriculum Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4483 | Learning Coverage Paths in Unknown Environments with Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4484 | Fairness Metric Impossibility: Investigating and Addressing Conflicts | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4485 | An Embodied Generalist Agent in 3D World | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4486 | MIND: Masked and Inverse Dynamics Modeling for Data-Efficient Deep Reinforcement Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4487 | Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4488 | Valley: Video Assistant with Large Language model Enhanced abilitY | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4489 | Attention-Guided Contrastive Role Representations for Multi-agent Reinforcement Learning | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4490 | Knowledge Distillation for Predicting Varying Environment Maps from Single Images | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4491 | Self-Evolving Neural Radiance Fields | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4492 | Vision-Language Subspace Prompting | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4493 | LSPT: Long-term Spatial Prompt Tuning for Visual Representation Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4494 | Harnessing large-language models to generate private synthetic text | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4495 | GPT-FL: Generative Pre-trained Model-Assisted Federated Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4496 | Non-negative Probabilistic Factorization | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4497 | Can pre-trained models assist in dataset distillation? | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4498 | ChatSearch: a Dataset and a Generative Retrieval Model for General Conversational Image Retrieval | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4499 | Harmony World Models: Boosting Sample Efficiency for Model-based Reinforcement Learning | 4.75 | 5.00 | 1.22 | 0.25 | |
| 4500 | Elucidating the Solution Space of Extended Reverse-Time SDE for Diffusion Models | 5.00 | 4.75 | 1.09 | -0.25 | |
| 4501 | Rotative Factorization Machines | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4502 | Alleviating the Effect of Data Imbalance on Adversarial Training | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4503 | SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4504 | DySTreSS: Dynamically Scaled Temperature in Self-Supervised Contrastive Learning | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4505 | Code Representation Pre-training with Complements from Program Executions | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4506 | A/B testing under Identity Fragmentation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4507 | Adv3D: Generating 3D Adversarial Examples for 3D Object Detection in Driving Scenarios with NeRF | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4508 | Selective Mixup Helps with Distribution Shifts, But Not (Only) because of Mixup | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4509 | CryoFormer: Continuous Heterogeneous Cryo-EM Reconstruction using Transformer-based Neural Representations | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4510 | Video Generation Beyond a Single Clip | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4511 | Emerging Semantic Segmentation from Positive and Negative Coarse Label Learning | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4512 | Unleashing the Creative Mind: Language Model As Hierarchical Policy For Improved Exploration on Challenging Problem Solving | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4513 | Timesteps meet Bits: Low-Latency, Accurate, & Energy-Efficient Spiking Neural Networks with ANN-to-SNN Conversion | 4.25 | 4.75 | 1.09 | 0.50 | |
| 4514 | MOESART: An Effective Sampling-based Router for Sparse Mixture of Experts | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4515 | A Comprehensive Study of Privacy Risks in Curriculum Learning | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4516 | Programmatic Evaluation of Rule-Following Behavior | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4517 | CTRL: Graph condensation via crafting rational trajectory matching | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4518 | Self-Supervised Detection of Perfect and Partial Input-Dependent Symmetries | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4519 | Implicit NNs are Almost Equivalent to Not-so-deep Explicit NNs for High-dimensional Gaussian Mixtures | 5.00 | 4.75 | 2.05 | -0.25 | |
| 4520 | IW-GAE: Importance weighted group accuracy estimation for improved calibration and model selection in unsupervised domain adaptation | 4.25 | 4.50 | 0.87 | 0.25 | |
| 4521 | αMax-B-CUBED: A Supervised Metric for Addressing Completeness and Uncertainty in Cluster Evaluation | 4.75 | 4.75 | 2.05 | 0.00 | |
| 4522 | Accelerated Policy Gradient: On the Nesterov Momentum for Reinforcement Learning | 4.75 | 5.50 | 0.50 | 0.75 | |
| 4523 | LeRaC: Learning Rate Curriculum | 4.75 | 5.25 | 0.43 | 0.50 | |
| 4524 | Boosting Discriminative Visual Representation Learning with Scenario-Agnostic Mixup | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4525 | BRIDGING THE GAP BETWEEN HUMAN MOTION AND ACTION SEMANTICS VIA KINEMATIC PHRASES | 4.75 | 6.00 | 0.00 | 1.25 | |
| 4526 | Clover: Closed-Loop Verifiable Code Generation | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4527 | Roadside Monocular 3D Detection via 2D-Detection Prompting | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4528 | How many views does your deep neural network use for prediction? | 4.50 | 4.75 | 1.09 | 0.25 | |
| 4529 | Detection-Oriented Image-Text Pretraining for Open-Vocabulary Detection | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4530 | PPT: Token Pruning and Pooling for Efficient Vision Transformers | 4.75 | 4.75 | 1.09 | 0.00 | |
| 4531 | Regulation Games for Trustworthy Machine Learning | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4532 | Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4533 | Boosting Selective Rationalization with Shortcuts Discovery | 4.67 | 5.67 | 0.47 | 1.00 | |
| 4534 | S4G: Breaking the Bottleneck on Graphs with Structured State Spaces | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4535 | Disentangled Heterogeneous Collaborative Filtering | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4536 | HuRef: HUman-REadable Fingerprint for Large Language Models | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4537 | Learning to Play Atari in a World of Tokens | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4538 | Counterfactual Fairness from Partially DAGs: A General Min-Max Optimization Framework | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4539 | Reinforcement Learning for Large Group Systems using Hierarchical Kernel Representations | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4540 | Multi-Resolution Learning with DeepONets and Long Short-Term Memory Neural Networks | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4541 | Deep probabilistic 3D angular regression for directional dark matter detectors | 4.50 | 5.33 | 2.05 | 0.83 | |
| 4542 | State-wise Constrained Policy Optimization | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4543 | A Linearly Convergent GAN Inversion-based Algorithm for Reverse Engineering of Deceptions | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4544 | Stabilized E(n)-Equivariant Graph Neural Networks-assisted Generative Models | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4545 | TROJFAIR: TROJAN FAIRNESS ATTACKS | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4546 | Revisiting Non-separable Binary Classification and its Applications in Anomaly Detection | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4547 | Kick Bad Guys Out! Zero-Knowledge-Proof-Based Anomaly Detection in Federated Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4548 | Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4549 | H-Rockmate: Hierarchical Approach for Efficient Re-materialization of Large Neural Networks | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4550 | Multimodal Procedural Planning via Dual Text-Image Prompting | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4551 | In-Context Unlearning: Language Models as Few Shot Unlearners | 5.00 | 4.67 | 1.25 | -0.33 | |
| 4552 | DeepROCK: Error-controlled interaction detection in deep neural networks | 4.50 | 5.00 | 1.41 | 0.50 | |
| 4553 | Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4554 | Progressive Pseudo Bag Augmentation with Instance Importance Estimation for Whole Slide Image Classification | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4555 | MAST: A Sparse Training Framework for Multi-agent Reinforcement Learning | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4556 | REAL: Rectified Adversarial Sample via Max-Min Entropy for Test-Time Defense | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4557 | Duality of Information Flow: Insights in Graphical Models and Neural Networks | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4558 | A Novel Approach for Micro-Expression Recognition Incorporating Vertical Attention and Position Localization | 4.67 | 4.75 | 1.09 | 0.08 | |
| 4559 | Exploring the State and Action Space in Reinforcement Learning with Infinite-Dimensional Confidence Balls | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4560 | DiffMaSIF: Score-Based Diffusion Models for Protein Surfaces | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4561 | PEPNet: A Lightweight Point-based Event Camera 6-DOFs Pose Relocalization Network | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4562 | Towards Global Interaction Efficiency of Graph Networks | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4563 | Prototype Generation: Robust Feature Visualisation for Data Independent Interpretability | 4.67 | 4.67 | 2.87 | 0.00 | |
| 4564 | Federated Learning under Label Shifts with Guarantees | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4565 | GraSP: Simple yet Effective Graph Similarity Predictions | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4566 | Signed-Binarization: Unlocking Efficiency Through Repetition-Sparsity Trade-Off | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4567 | Thermodynamics-inspired Structure Hallucination for Protein-protein Interaction Modeling | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4568 | Achieving Margin Maximization Exponentially Fast via Progressive Norm Rescaling | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4569 | A Dataset and Benchmark for Copyright Protection from Text-to-Image Diffusion Models | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4570 | Put on your detective hat: What’s wrong in this video? | 4.67 | 4.33 | 0.94 | -0.33 | |
| 4571 | Can AI-Generated Text be Reliably Detected? | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4572 | Minimizing Chebyshev Risk Magically Mitigates the Perils of Overfitting | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4573 | GENIU: A Restricted Data Access Unlearning for Imbalanced Data | 4.67 | 4.67 | 2.87 | 0.00 | |
| 4574 | Bias A-head? Analyzing Bias in Transformer-Based Language Model Attention Heads | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4575 | Aligning Brains into a Shared Space Improves Their Alignment to Large Language Model | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4576 | Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4577 | RECURSIVE NEURAL ORDINARY DIFFERENTIAL EQUATIONS FOR PARTIALLY OBSERVED SYSTEM | 5.00 | 4.67 | 1.25 | -0.33 | |
| 4578 | Graph is All You Need? Lightweight Data-agnostic Neural Architecture Search without Training | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4579 | COINs: Model-based Accelerated Inference for Knowledge Graphs | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4580 | HeteroSFL: Split Federated Learning with heterogeneous clients and non-IID data | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4581 | Adder: Adapted Dense Retrieval | 4.67 | 4.67 | 1.25 | 0.00 | | 3, 6, 5, 3, 6, 5 | | 3, 6, 5, 3, 6, 5 |
|
| 4582 | Feedback-guided Data Synthesis for Imbalanced Classification | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4583 | A Fast and Effective Alternative to Graph Transformers | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4584 | Fast Stochastic Kernel Approximation by Dual Wasserstein Distance Method | 4.00 | 4.67 | 2.87 | 0.67 | |
| 4585 | When Do MLPs Excel in Node Classification? An Information-Theoretic Perspective | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4586 | realSEUDO for real-time calcium imaging analysis | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4587 | Mechanistic Neural Networks | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4588 | Combine and Conquer: A Meta-Analysis on Data Shift and Out-of-Distribution Detection | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4589 | Training Binary Neural Networks in a Binary Weight Space | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4590 | Training and inference of large language models using 8-bit floating point | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4591 | Segmenting the Unknown: Discrete Diffusion Models for Non-Deterministic Segmentation | 3.67 | 4.67 | 1.25 | 1.00 | |
| 4592 | MorphGrower: A Synchronized Layer-by-layer Growing Approach for Plausible and Diverse Neuronal Morphology Generation | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4593 | Copyright Plug-in Market for The Text-to-Image Copyright Protection | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4594 | Efficient Hyperparameter Optimization with Adaptive Fidelity Identification | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4595 | Hieros: Hierarchical Imagination on Structured State Space Sequence World Models | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4596 | FLAIM: AIM-based Synthetic Data Generation in the Federated Setting | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4597 | Mitigating Uni-modal Sensory Bias in Multimodal Object Detection with Counterfactual Intervention and Causal Mode Multiplexing | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4598 | Explaining the Complex Task Reasoning of Large Language Models with Template-Content Structure | 5.50 | 4.67 | 1.25 | -0.83 | |
| 4599 | Stochastic Extragradient with Flip-Flop Shuffling & Anchoring: Provable Improvements | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4600 | A qualitative theory of dynamical systems for assessing stability in ResNets | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4601 | MATLABER: Material-Aware Text-to-3D via LAtent BRDF auto-EncodeR | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4602 | Forward-Backward Reasoning in Large Language Models for Mathematical Verification | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4603 | Super Floating-Point (SuFP): Efficient To All. Multi-Region Piecewise Quantization using Scalable Bias with Hardware Optimization | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4604 | Go beyond End-to-End Training: Boosting Greedy Local Learning with Context Supply | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4605 | Hierarchical Classification by Training to Diffuse on the Manifold | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4606 | Towards Interpretable Continual Learning Through Controlling Concepts | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4607 | Learning Unorthogonalized Matrices for Rotation Estimation | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4608 | How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4609 | SimTeG: A Frustratingly Simple Approach Improves Textual Graph Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4610 | LegoMT2: Non-Blocking Federated Learning for Massive Multilingual Machine Translation | 5.33 | 4.67 | 1.25 | -0.67 | |
| 4611 | PAGAR: Taming Reward Misalignment in Inverse Reinforcement Learning-Based Imitation Learning with Protagonist Antagonist Guided Adversarial Reward | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4612 | Learning Directed Graphical Models with Optimal Transport | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4613 | On Learning with a Concurrent Verifier: Convexity, Improving Bounds, and Complex Requirements | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4614 | TPE: Towards Better Compositional Reasoning over Conceptual Tools with Multi-persona Collaboration | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4615 | TROJFSL: TROJAN INSERTION IN FEW SHOT PROMPT LEARNING | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4616 | Symmetrization of Loss Functions for Robust Training of Neural Networks in the Presence of Noisy Labels and the Multi-class Unhinged Loss Function | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4617 | Stochastic Gradient Discrete Langevin Dynamics | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4618 | Hierarchical Gaussian Mixture Normalizing Flows Modeling for Multi-Class Anomaly Detection | 4.50 | 4.67 | 1.25 | 0.17 | |
| 4619 | One by One, Continual Coordinating with Humans via Hyper-Teammate Identification | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4620 | Just How Flexible are Neural Networks in Practice? | 4.33 | 5.00 | 1.41 | 0.67 | |
| 4621 | SYRAC: Synthesize, Rank, and Count | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4622 | High-dimensional Bayesian Optimization via Semi-supervised Learning with Optimized Unlabeled Data Sampling | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4623 | COMPRESSION AND ACCELERATION OF DEEP NEURAL NETWORKS: A VECTOR QUANTIZATION APPROACH | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4624 | Computing Low-Entropy Couplings for Large-Support Distributions | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4625 | RCOT: Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4626 | Toward $textbf{F}$aithfulness-guided $textbf{E}$nsemble $textbf{I}$nterpretation of Neural Network | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4627 | Understanding Unfairness via Training Concept Influence | 4.00 | 5.33 | 0.47 | 1.33 | |
| 4628 | On the Stochasticity in Graph Neural Networks | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4629 | BenthIQ: a Transformer-Based Benthic Classification Model for Coral Restoration | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4630 | Fast Value Tracking for Deep Reinforcement Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4631 | Efficient and Quantization-Friendly Ternary Fourier Convolution Algorithms | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4632 | Organ-DETR: 3D Organ Detection Transfomer with Multiscale Attention and Dense Query Matching | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4633 | Meta-Learning Universal Priors Using Non-Injective Normalizing Flows | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4634 | Bridging Indexing Structure and Graph Learning: Expressive and Scalable Graph Neural Network via Core-Fringe | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4635 | Measuring Fairness Using Probable Segmentation for Continuous Sensitive Attributes | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4636 | Less is More: One-shot Subgraph Reasoning on Large-scale Knowledge Graphs | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4637 | FedGSE:Gradient-based Sub-model Extraction for Resource-constrained Federated Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4638 | Hierarchical-Latent Generative Models are Robust View Generators for Contrastive Representation Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4639 | MSfusion: Enabling Collaborative Training of Large Models over Resource-Constraint Participants | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4640 | Neuroexplicit Diffusion Models for Inpainting of Optical Flow Fields | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4641 | ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models | 4.67 | 5.67 | 0.47 | 1.00 | |
| 4642 | Hypothesis Search: Inductive Reasoning with Language Models | 4.67 | 4.67 | 1.25 | 0.00 | | 6, 3, 5, 5, 3, 6 | | 6, 3, 5, 5, 3, 6 |
|
| 4643 | Video-CSR: Complex Video Digest Creation for Visual-Language Models | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4644 | ColA: Collaborative Adaptation with Gradient Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4645 | STABLE ESTIMATION OF SURVIVAL CAUSAL EFFECTS | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4646 | Gaussian Mutual Information Maximization for Graph Self-supervised Learning: Bridging Contrastive-based to Decorrelation-based | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4647 | DipDNN: Decomposed Invertible Pathway Deep Neural Networks | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4648 | From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4649 | Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4650 | LLM-Codebook for Extreme Compression of Large Language Models | 4.67 | 4.75 | 1.09 | 0.08 | |
| 4651 | VTranM: Vision Transformer Explainability with Vector Transformations Measurement | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4652 | Embracing Diversity: Zero-shot Classification Beyond a Single Vector per Class | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4653 | Align after Pre-train: Improving Multilingual Generative Models with Cross-lingual Alignment | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4654 | Class-Incremental Learning with Parameter-Efficient Cross-Task Prompts | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4655 | Discovering Environments with XRM | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4656 | SimPLR: A Simple and Plain Transformer for Object Detection and Segmentation | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4657 | SHARCS: SHARed Concept Space forExplainable Multimodal Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4658 | MacDC: Masking-augmented Collaborative Domain Congregation for Multi-target Domain Adaptation in Semantic Segmentation | 4.67 | 3.67 | 0.94 | -1.00 | |
| 4659 | Structural Pruning of Large Language Models via Neural Architecture Search | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4660 | 3DiffTection: 3D Object Detection with Geometry-Aware Diffusion Features | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4661 | Applying language models to algebraic topology: generating simplicial cycles using multi-labeling in Wu's formula | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4662 | ViP: A Differentially Private Foundation Model for Computer Vision | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4663 | Diffusion Models for Imperceptible and Transferable Adversarial Attack | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4664 | Invariance as A Necessary Condition for Online Continual Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4665 | D2T2: Decision Transformer with Temporal Difference via Steering Guidance | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4666 | On Provable Benefits of Policy Learning from Human Preferences in Contextual Bandit Problems | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4667 | SCOT: Improved Temporal Counterfactual Estimation with Self-Supervised Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4668 | Byzantine Robustness and Partial Participation Can Be Achieved Simultaneously: Just Clip Gradient Differences | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4669 | Critique Ability of Large Language Models | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4670 | Desigen: A Pipeline for Controllable Design Template Generation | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4671 | SubDiff: Subgraph Latent Diffusion Model | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4672 | Towards Unified and Effective Domain Generalization | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4673 | RLLTE: Long-Term Evolution Project of Reinforcement Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4674 | Improving Accelerated Federated Learning with Compression and Importance Sampling | 5.50 | 4.67 | 2.36 | -0.83 | |
| 4675 | Representation Bottleneck of Graph Neural Networks for Scientific Problems | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4676 | UPAR: A Kantian-Inspired Prompting Framework for Enhancing Large Language Model Capabilities | 4.67 | 5.00 | 1.41 | 0.33 | |
| 4677 | On Convergence Rates of Deep Nonparametric Regression under Covariate Shift | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4678 | Symbol as Points: Panoptic Symbol Spotting via Point-based Representation | 4.67 | 5.33 | 2.05 | 0.67 | |
| 4679 | Continuous Indeterminate Probability Neural Network | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4680 | Cosine Similarity Knowledge Distillation for Individual Class Information Transfer | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4681 | LatticeGen: A Cooperative Framework Which Hides Generated Text in A Lattice For Privacy-Aware Generation on Cloud | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4682 | When Hard Negative Sampling Meets Supervised Contrastive Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4683 | DEEP UNSUPERVISED DOMAIN ADAPTATION FOR TIME SERIES CLASSIFICATION: A BENCHMARK | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4684 | Structured Evaluation of Synthetic Tabular Data | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4685 | BLG: BALANCED LANGUAGE DISTRIBUTION AS GUIDANCE FOR ROBUST LONG-TAILED VISION CLASSIFICATION | 4.33 | 4.67 | 1.25 | 0.33 | |
| 4686 | Universal Metric Learning with Parameter-Efficient Transfer Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4687 | Harmonized Learning with Concurrent Arbitration: A Brain-inspired Motion Planning Approach | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4688 | Probabilistic Neural Transfer Function Estimation with Bayesian System Identification | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4689 | Advancing Counterfactual Inference through Quantile Regression | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4690 | Dynamic Electroencephalography Representation Learning for Improved Epileptic Seizure Detection | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4691 | Does Calibration Affect Human Actions? | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4692 | A SYSTEMATIC STUDY ON EARLY STOPPING CRITERIA IN HPO AND THE IMPLICATIONS OF UNCERTAINTY | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4693 | Reverse Stable Diffusion: What prompt was used to generate this image? | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4694 | SIEVE: Multimodal Dataset Pruning using Image-Captioning Models | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4695 | SELF: Language-Driven Self-Evolution for Large Language Model | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4696 | Rethinking Independent Cross-Entropy Loss For Graph-Structured Data | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4697 | Graph Learning with Distributional Edge Layouts | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4698 | On the Evaluation of Generative Models in Distributed Learning Tasks | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4699 | SSL Framework for Causal Inconsistency between Structures and Representations | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4700 | LAMDA: Unified Language-Driven Multi-Task Domain Adaption | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4701 | SPOT: Scalable 3D Pre-training via Occupancy Prediction for Autonomous Driving | 4.00 | 4.67 | 1.25 | 0.67 | |
| 4702 | Elevating Augmentation: Boosting Performance via Sub-Model Training | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4703 | Impact of Agent Behavior in Distributed SGD and Federated Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4704 | Sequential Data Generation with Groupwise Diffusion Process | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4705 | SAIF: Sparse Adversarial and Imperceptible Attack Framework | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4706 | One-Versus-Others Attention: Scalable Multimodal Integration | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4707 | DRMGuard: Defending Deep Regression Models against Backdoor Attacks | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4708 | StableSSM: Alleviating the Curse of Memory in State-space Models through Stable Reparameterization | 4.67 | 5.33 | 0.47 | 0.67 | |
| 4709 | Brain2Music: Reconstructing Music from Human Brain Activity | 4.67 | 4.67 | 2.36 | 0.00 | |
| 4710 | Test like you Train in Implicit Deep Learning | 4.67 | 4.67 | 1.25 | 0.00 | |
| 4711 | Retrieving Texts by Abstract Descriptions | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 3, 5, 5, 5 | | 5, 3, 5, 5, 5 |
|
| 4712 | Let's reward step by step: Step-Level reward model as the Navigators for Reasoning | 4.60 | 4.60 | 0.80 | 0.00 | | 3, 5, 5, 5, 5 | | 3, 5, 5, 5, 5 |
|
| 4713 | What's the Magic Word? A Control Theory of LLM Prompting | 4.60 | 4.60 | 0.80 | 0.00 | | 3, 5, 5, 5, 5 | | 3, 5, 5, 5, 5 |
|
| 4714 | A Theoretical Study of the Jacobian Matrix in Deep Neural Networks | 4.60 | 4.60 | 0.80 | 0.00 | | 3, 5, 5, 5, 5 | | 3, 5, 5, 5, 5 |
|
| 4715 | Amortized Bayesian Inference with Hybrid Expert-in-the-Loop and Learnable Summary Statistics | 4.60 | 4.60 | 1.36 | 0.00 | | 3, 3, 6, 5, 6 | | 3, 3, 6, 5, 6 |
|
| 4716 | Class-Conditional Conformal Prediction for Imbalanced Data via Top-$k$ Classes | 4.00 | 4.60 | 1.36 | 0.60 | | 3, 3, 6, 5, 3 | | 3, 6, 6, 5, 3 |
|
| 4717 | On Memorization and Privacy Risks of Sharpness Aware Minimization | 4.60 | 4.40 | 1.20 | -0.20 | | 5, 3, 6, 3, 6 | | 5, 3, 6, 3, 5 |
|
| 4718 | Fairness-aware Message Passing for Graph Neural Networks | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 5, 3, 5, 5 | | 5, 5, 3, 5, 5 |
|
| 4719 | Calibration-then-Calculation: A Variance Reduced Metric Framework | 4.60 | 4.60 | 1.36 | 0.00 | | 6, 3, 5, 6, 3 | | 6, 3, 5, 6, 3 |
|
| 4720 | Acoustic Prompt Tuning: Empowering Large Language Models with Audition Capabilities | 4.60 | 4.60 | 2.42 | 0.00 | | 5, 3, 8, 6, 1 | | 5, 3, 8, 6, 1 |
|
| 4721 | Mitigating Interference in the Knowledge Continuum through Attention-Guided Incremental Learning | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 5, 5, 5, 3 | | 5, 5, 5, 5, 3 |
|
| 4722 | Diversity Modeling for Semantic Shift Detection | 4.40 | 4.60 | 1.36 | 0.20 | | 5, 6, 5, 3, 3 | | 6, 6, 5, 3, 3 |
|
| 4723 | Text-Aware Diffusion Policies | 3.80 | 4.60 | 1.36 | 0.80 | | 5, 3, 5, 3, 3 | | 6, 3, 5, 3, 6 |
|
| 4724 | ResiDual: Transformer with Dual Residual Connections | 4.60 | 4.20 | 1.94 | -0.40 | | 6, 5, 1, 6, 5 | | 6, 5, 1, 6, 3 |
|
| 4725 | Nash Equilibria in Reward-Potential Markov Games: Algorithms, Complexity, and Applications | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 3, 5, 5, 5 | | 5, 3, 5, 5, 5 |
|
| 4726 | MPPN: Multi-Resolution Periodic Pattern Network For Long-Term Time Series Forecasting | 4.20 | 4.60 | 0.80 | 0.40 | | 3, 3, 5, 5, 5 | | 5, 3, 5, 5, 5 |
|
| 4727 | Learning multi-modal generative models with permutation-invariant encoders and tighter variational bounds | 4.60 | 4.60 | 1.36 | 0.00 | | 3, 5, 3, 6, 6 | | 3, 5, 3, 6, 6 |
|
| 4728 | FrAug: Frequency Domain Augmentation for Time Series Forecasting | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 5, 3, 5, 5 | | 5, 5, 3, 5, 5 |
|
| 4729 | Neural Architecture Search for TinyML with Reinforcement Learning | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 5, 3, 5, 5 | | 5, 5, 3, 5, 5 |
|
| 4730 | Understanding and Improving Adversarial Attacks on Latent Diffusion Model | 4.60 | 4.60 | 1.36 | 0.00 | | 6, 6, 3, 5, 3 | | 6, 6, 3, 5, 3 |
|
| 4731 | Differentially Private One Permutation Hashing | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 5, 3, 5, 5 | | 5, 5, 3, 5, 5 |
|
| 4732 | Meta-Transformer: A Unified Framework for Multimodal Learning | 4.60 | 4.60 | 1.36 | 0.00 | | 6, 3, 6, 3, 5 | | 6, 3, 6, 3, 5 |
|
| 4733 | Sp-R-IP: A Decision-Focused Learning Strategy for Linear Programs that Avoids Overfitting | 4.60 | 4.60 | 1.36 | 0.00 | | 5, 3, 3, 6, 6 | | 5, 3, 3, 6, 6 |
|
| 4734 | ATraDiff: Accelerating Online Reinforcement Learning with Imaginary Trajectories | 4.40 | 4.60 | 1.36 | 0.20 | | 3, 5, 5, 3, 6 | | 3, 5, 6, 3, 6 |
|
| 4735 | Adaptive Bilevel Optimization | 4.60 | 4.60 | 1.36 | 0.00 | | 6, 3, 5, 3, 6 | | 6, 3, 5, 3, 6 |
|
| 4736 | Connecting Domains and Contrasting Samples: A Ladder for Domain Generalization | 4.20 | 4.60 | 0.80 | 0.40 | | 5, 5, 3, 3, 5 | | 5, 5, 3, 5, 5 |
|
| 4737 | Instant Complexity Reduction in CNNs using Locality-Sensitive Hashing | 4.60 | 4.60 | 1.36 | 0.00 | | 3, 3, 6, 6, 5 | | 3, 3, 6, 6, 5 |
|
| 4738 | Motif-aware Attribute Masking for Molecular Graph Pre-training | 4.60 | 4.60 | 1.36 | 0.00 | | 3, 6, 5, 6, 3 | | 3, 6, 5, 6, 3 |
|
| 4739 | Rethink Depth Separation with Intra-layer Links | 4.60 | 4.60 | 1.85 | 0.00 | | 1, 6, 5, 5, 6 | | 1, 6, 5, 5, 6 |
|
| 4740 | Stochastic Subnetwork Annealing: A Regularization Technique for Fine Tuning Subnetworks | 4.60 | 4.60 | 1.36 | 0.00 | | 6, 5, 3, 6, 3 | | 6, 5, 3, 6, 3 |
|
| 4741 | MaskCLR: Multi-Level Contrastive Learning for Robust Skeletal Action Recognition | 4.60 | 4.60 | 1.36 | 0.00 | | 5, 3, 6, 3, 6 | | 5, 3, 6, 3, 6 |
|
| 4742 | Emergent Mixture-of-Experts: Can Dense Pre-trained Transformers Benefit from Emergent Modular Structures? | 4.60 | 4.60 | 2.06 | 0.00 | | 6, 3, 3, 8, 3 | | 6, 3, 3, 8, 3 |
|
| 4743 | Consistency Regularization for Domain Generalization with Logit Attribution Matching | 4.40 | 4.60 | 1.36 | 0.20 | | 5, 6, 3, 3, 5 | | 6, 6, 3, 3, 5 |
|
| 4744 | Multimodal Representation Learning by Alternating Unimodal Adaptation | 4.60 | 4.60 | 0.80 | 0.00 | | 5, 5, 5, 5, 3 | | 5, 5, 5, 5, 3 |
|
| 4745 | FMLock: Preventing Unauthorized Use of Large Foundation Models | 4.60 | 4.60 | 2.06 | 0.00 | | 6, 8, 3, 3, 3 | | 6, 8, 3, 3, 3 |
|
| 4746 | Stress Testing Byzantine Robustness in Distributed Learning | 4.50 | 4.57 | 1.05 | 0.07 | | 3, 6, 5, 5, 3, 5 | | 3, 6, 5, 5, 3, 5, 5 |
|
| 4747 | Modelling Microbial Communities with Graph Neural Networks | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4748 | An Enhanced Gromov-Wasserstein Barycenter Method for Graph-based Clustering | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4749 | Two-shot learning of continuous interpolation using a conceptor-aided recurrent autoencoder | 5.00 | 4.50 | 1.50 | -0.50 | |
| 4750 | MAGDiff: Covariate Data Set Shift Detection via Activation Graphs of Deep Neural Networks | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4751 | Rethinking the Power of Graph Canonization in Graph Representation Learning with Stability | 4.50 | 6.00 | 0.00 | 1.50 | |
| 4752 | RL4CO: a Unified Reinforcement Learning for Combinatorial Optimization Library | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4753 | On the Long Range Abilities of Transformers | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4754 | Deep Anti-Regularized Ensembles | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4755 | When does In-context Learning Fall Short and Why? A Study on Specification-Heavy Tasks | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4756 | Mitigating backdoor attacks with generative modelling and dataset relabelling | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4757 | Leveraging Cross-Modal Neighbor Representation for Improved CLIP Classification | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4758 | Self Guided Exploration for Automatic and Diverse AI Supervision | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4759 | Bounding the Robustness and Generalization for Individual Treatment Effect | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4760 | Heterogeneous Decision Making towards Mixed Autonomy: When Uncertainty-aware Planning Meets Bounded Rationality | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4761 | Genetic Algorithm for Curriculum Generation in Multi-Agent Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4762 | FLOOD SIMULATION WITH PHYSICS-INFORMED MESSAGE PASSING | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4763 | MoAT: Multi-Modal Augmented Time Series Forecasting | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4764 | Jorge: Approximate Preconditioning for GPU-Efficient Second-Order Optimization | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4765 | Vector Quantized Representations for Efficient Hierarchical Delineation of Behavioral Repertoires | 4.75 | 4.50 | 0.87 | -0.25 | |
| 4766 | Simple Data Sharing for Multi-Tasked Goal-Oriented Problems | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4767 | Unsupervised Sign Language Translation and Generation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4768 | Relational Constraints On Neural Networks Reproduce Human Biases towards Abstract Geometric Regularity | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4769 | Learning High-Order Relationships of Brain Regions | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4770 | Regret Rates for $epsilon$-Greedy Strategies for Nonparametric Bandits with Delayed Rewards | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4771 | LLM Censorship: The Problem and its Limitations | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4772 | Certifiably Byzantine-Robust Federated Conformal Prediction | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4773 | Bring Your Own Data! Self-Supervised Evaluation for Large Language Models | 5.00 | 4.50 | 0.87 | -0.50 | |
| 4774 | SEER: Towards Efficient Preference-based Reinforcement Learning via Aligned Experience Estimation | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4775 | Leveraging image representations for bounded adversarial attacks and robustness | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4776 | xVal: A Continuous Number Encoding for Large Language Models | 4.00 | 4.50 | 2.06 | 0.50 | |
| 4777 | Spectral Highways: Injecting Homophily into Heterophilic Graphs | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4778 | AgentMixer: Multi-Agent Correlated Policy Factorization | 3.50 | 4.50 | 0.87 | 1.00 | |
| 4779 | Pushing Gradient towards Zero: A Novel Pruning Method for Large Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4780 | ICA model estimation using an optimized version of genetic algorithms | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4781 | ChunkAttention: Efficient Attention on KV Cache with Chunking Sharing and Batching | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4782 | ADELT: Transpilation Between Deep Learning Frameworks | 5.00 | 4.50 | 1.50 | -0.50 | |
| 4783 | Discouraging Posterior Collapse in Hierarchical Variational Autoencoders Using Context | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4784 | Online Fractional Knapsack With Predictions | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4785 | To guide or not to guide: Improving diffusion sampling with progressive guidance | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4786 | Mo' Data Mo' Problems: How Data Composition Compromises Scaling Properties | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4787 | Private Overparameterized Linear Regression without Suffering in High Dimensions | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4788 | Learning Differentially Private Rewards from Human Feedback | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4789 | GIFF: Generalized Inference Friendly Forward-Forward Algorithm | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4790 | MoMA: Model-based Mirror Ascent for Offline Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4791 | Consistent123: One Image to Highly Consistent 3D Asset Using Case-Aware Diffusion Priors | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4792 | Denoising Diffusion Variational Inference | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4793 | A Multi-Agent Reinforcement Learning Framework for Evaluating the U.S. ‘Ending the HIV Epidemic’ initiative | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4794 | MAGNet: Motif-Agnostic Generation of Molecules from Shapes | 3.75 | 4.50 | 2.69 | 0.75 | |
| 4795 | Casting Light on Large Generative Networks: Taming Epistemic Uncertainty in Diffusion Models | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4796 | Large-Scale Spectral Graph Neural Networks via Laplacian Sparsification | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4797 | Learning to Select In-context Examples from Reward | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4798 | Learning Latent Causal Semantics from Text: An Empirical Study of Next-Token Predictors Trained on Programs | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4799 | Imagine Within Practice: Conservative Rollout Length Adaptation for Model-Based Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4800 | Gaitor: Learning a Unified Representation for Continuous Gait Transition and Terrain Traversal for Quadruped Robots | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4801 | MoteS: Memory Optimization via Fine-grained Scheduling for DNNs on Tiny Devices | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4802 | A Critical Study of What Pre-trained Code Models (do not) Learn | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4803 | Unbalanced Diffusion Schrödinger Bridge | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4804 | AdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4805 | How To Train Your Covariance | 4.50 | 4.50 | 2.06 | 0.00 | |
| 4806 | ROBUST DIFFUSION GAN USING SEMI-UNBALANCED OPTIMAL TRANSPORT | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4807 | Time- and Label-efficient Active Learning by Diversity and Uncertainty of Probabilities | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4808 | A multiobjective continuation method to compute the regularization path of deep neural networks | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4809 | An Efficient Query Strategy for Active Learning via Optimal Transport | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4810 | Learning from Distinction: Mitigating backdoors using a low-capacity model | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4811 | Enhancing Deep Graph Neural Networks via Improving Signal Propagation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4812 | Dissecting Gradient Masking and Denoising in Diffusion Models for Adversarial Purification | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4813 | WASSERSTEIN-GUIDED SYMBOLIC REGRESSION: MODEL DISCOVERY OF NETWORK DYNAMICS | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4814 | Is Feature Extraction the most informative dimensionality reduction technique? Revisiting Unsupervised Feature Selection from a Dynamic Approach | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4815 | CoDBench: A Critical Evaluation of Data-driven Models for Continuous Dynamical Systems | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4816 | Continual Learning with Orthogonal Weights and Knowledge Transfer | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4817 | Federated Learning with Local Openset Noisy Labels | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4818 | Improved Function Space Variational Inference with Informative Priors | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4819 | Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4820 | Curvature-Informed SGD via General Purpose Lie-Group Preconditioners | 4.75 | 4.50 | 0.87 | -0.25 | |
| 4821 | DECap: Towards Generalized Explicit Caption Editing via Diffusion Mechanism | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4822 | Identifying and Mitigating Vulnerabilities in LLM-Integrated Applications | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4823 | DISTA: DENOISING SPIKING TRANSFORMER WITH INTRINSIC PLASTICITY AND SPATIOTEMPORAL ATTENTION | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4824 | On Socially Fair Regression and Low-Rank Approximation | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4825 | InsightMapper: A closer look at inner-instance information for vectorized High-Definition Mapping | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4826 | Optimizing Layerwise Polynomial Approximation for Efficient Private Inference on Fully Homomorphically Encryption: A Dynamic Programming Approach | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4827 | Grounding Code Generation with Input-Output Specifications | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4828 | Pipeline Parallelism Optimization with Deep Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4829 | Is Pre-training Truly Better Than Meta-Learning? | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4830 | A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4831 | Loco3D: Indoor Multiuser Locomotion 3D Dataset | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4832 | Time-sensitive Weight Averaging for Practical Temporal Domain Generalization | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4833 | Evaluating and Finetuning Models For Financial Time Series Forecasting | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4834 | HeaP: Hierarchical Policies for Web Actions using LLMs | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4835 | SynBench: Evaluating Pretrained Representations for Image Classification using Synthetic Data | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4836 | Annotation by Clicks: A Point-Supervised Contrastive Variance Method for Medical Semantic Segmentation | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4837 | What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4838 | SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4839 | Addressing Challenges in Reinforcement Learning for Recommender Systems with Conservative Objectives | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4840 | ILPO-NET: convolution network for the recognition of arbitrary volumetric patterns | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4841 | ARTIST: Towards Disentangled Text Painter with Diffusion Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4842 | Efficiently Quantifying Individual Agent Importance in Cooperative MARL | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4843 | Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4844 | From Malicious to Marvelous: The Art of Adversarial Attack as Diffusion | 4.50 | 4.50 | 2.69 | 0.00 | |
| 4845 | Random Walk Diffusion For Graph Generation | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4846 | FedGT: Identification of Malicious Clients in Federated Learning with Secure Aggregation | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4847 | A Symbolic Framework for Evaluating Mathematical Reasoning with Transformers | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4848 | Improved Algorithms for Replicable Bandits | 4.00 | 4.50 | 1.50 | 0.50 | |
| 4849 | The Unreasonable Effectiveness of Pretraining in Graph OOD | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4850 | Meta-Collaboration in Distillation: Pooled Learning from Multiple Students | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4851 | Beyond Labeling Oracles: What does it mean to steal ML models? | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4852 | Uniform Localized Convergence and Sharper Generalization Bounds for Minimax Problems | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4853 | Variational Bayes Classifier | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4854 | DURENDAL: Graph deep learning framework for temporal heterogeneous networks | 4.25 | 4.50 | 1.50 | 0.25 | |
| 4855 | Invisible and Adaptive Training-Phase Target-Conditioned Backdoors | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4856 | Planning with Theory of Mind for Few-Shot Adaptation in Sequential Social Dilemmas | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4857 | Chain of Images for Intuitively Reasoning | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4858 | Iterative Search Attribution for Deep Neural Networks | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4859 | TabGFN: Tabular data generation based on GFlowNets | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4860 | Balanced learning with Token Selection for Few-shot Classification | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4861 | LSSInst: Improving Geometric Modeling in LSS-Based BEV Perception with Instance Representation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4862 | Protein Captioning: Bridging the Gap between Protein Sequences and Natural Languages | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4863 | GraphGPT: Graph Learning with Generative Pre-trained Transformers | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4864 | MIXCON3D: SYNERGIZING MULTI-VIEW AND CROSS-MODAL CONTRASTIVE LEARNING FOR ENHANCING 3D REPRESENTATION | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4865 | Dozerformer: Sequence Adaptive Sparse Transformer for Multivariate Time Series Forecasting | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4866 | Towards Reliable Backdoor Attacks on Vision Transformers | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4867 | Large Scene Synthesis Controlled With Detailed Text Using View-wise Conditional Joint Diffusion With Hierarchical Spatial Controls | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4868 | Synthetic data shuffling accelerates the convergence of federated learning under data heterogeneity | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4869 | Bandit Learning in Matching: Unknown Preferences On Both Sides | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4870 | DeformUX-Net: Exploring a 3D Foundation Backbone for Medical Image Segmentation with Depthwise Deformable Convolution | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4871 | Probabilistic Graphical Model for Robust Graph Neural Networks against Noisy Labels | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4872 | Prompt-Based Length Controlled Generation with Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4873 | Parsimonious Demonstrations and Fine-Tuning for Large Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4874 | C-MCTS: Safe Planning with Monte Carlo Tree Search | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4875 | Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4876 | ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics | 4.75 | 4.50 | 0.87 | -0.25 | |
| 4877 | Differentially Private Low-dimensional Synthetic Data from High-dimensional Datasets | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4878 | GPT-Driver: Learning to Drive with GPT | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4879 | Which mode is better for federated learning? Centralized or Decentralized | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4880 | Holmex: Human-Guided Spurious Correlation Detection and Black-box Model Fixing | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4881 | Causal Discovery with Unobserved Variables: A Proxy Variable Approach | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4882 | Regulating Imbalanced Deep Models with User-Specified Metrics | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4883 | LeetPrompt: Leveraging Collective Human Intelligence to Study LLMs | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4884 | Traceable Federated Continual Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4885 | Meta Koopman Decomposition for Time Series Forecasting Under Distribution Shifts | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4886 | MSPipe: Minimal Staleness Pipeline for Efficient Temporal GNN Training | 4.25 | 4.50 | 2.06 | 0.25 | |
| 4887 | CCA Merge: Merging Many Neural Networks with Canonical Correlation Analysis | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4888 | MoveAnything: Controllable Scene Generation with Text-to-Image Diffusion Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4889 | Overcoming the Stability Gap in Continual Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4890 | Enhanced Gradient Aligned Continual Learning via Pareto Optimization | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4891 | TransNeXt: Aggregating Diverse Attentions in One Vision Model | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4892 | EigenGuard: Backdoor Defense in Eigenspace | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4893 | Asking Before Acting: Gather Information in Embodied Decision-Making with Language Models | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4894 | A Multi-In-Single-Out Network for Video Frame Interpolation without optical flow | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4895 | Representation Norm Amplification for Out-of-Distribution Detection in Long-Tail Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4896 | Frustratingly Easy Model Generalization by Dummy Risk Minimization | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4897 | BPQP: A Differentiable Convex Optimization Framework for Efficient End-to-End Learning | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4898 | Detecting Out-of-distribution with Insights from Neural Collapse | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4899 | Linking Finite-Time Lyapunov Exponents to RNN Gradient Subspaces and Input Sensitivity | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4900 | Automatic Fine-Tuned Offline-to-Online Reinforcement Learning via Increased Simple Moving Average Q-value | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4901 | Evidential Conservative Q-Learning for Dynamic Recommendations | 4.33 | 4.50 | 0.87 | 0.17 | |
| 4902 | Compositional Instruction Following with Language Models and Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4903 | Safeguarding Data in Multimodal AI: A Differentially Private Approach to CLIP Training | 5.00 | 4.50 | 3.50 | -0.50 | |
| 4904 | EGALA: Efficient Gradient Approximation for Large-scale Graph Adversarial Attack | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4905 | Cross-Model Semi-Supervised Prompt Learning for Vision-Language Models | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4906 | MITIGATING BIAS IN DATASET DISTILLATION | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4907 | FedConv: Enhancing Convolutional Neural Networks for Handling Data Heterogeneity in Federated Learning | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4908 | Interaction-centric Hypersphere Reasoning for Multi-person Video HOI Recognition | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4909 | PcLast: Discovering Plannable Continuous Latent States | 4.75 | 4.50 | 0.87 | -0.25 | |
| 4910 | PoisoningGuard: Provable Defense against Data Poisoning Attacks to Multi-label Classification | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4911 | Long-distance Targeted Poisoning Attacks on Graph Neural Networks | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4912 | StyleAdapter: A Unified Stylized Image Generation Model without Test-Time Fine-Tuning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4913 | B$^{3}$CT: Three-branch Coordinated Training for Domain Adaptive Semantic Segmentation | 5.00 | 4.50 | 0.87 | -0.50 | |
| 4914 | Fair Feature Importance Scores for Interpreting Tree-Based Methods and Surrogates | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4915 | DomainFusion: Generalizing To Unseen Domains with Latent Diffusion Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4916 | An Effective Universal Polynomial Basis for Spectral Graph Neural Networks | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4917 | Deterministic Diffusion for Sequential Tasks | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4918 | Structural Adversarial Objectives For Self-Supervised Representation Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4919 | Degradation-aware Unfolding Knowledge-assist Transformer for Spectral Compressive Imaging | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4920 | RNNS with gracefully degrading continuous attractors | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4921 | Privacy-Preserving Data Quality Evaluation in Federated Learning Using Influence Approximation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4922 | Long-Tailed Recognition on Binary Networks by Calibrating A Pre-trained Model | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4923 | GNeRV: A Global Embedding Neural Representation For Videos | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4924 | HiddenKey: Parameter-Efficient FineTuning Meets Dropout under a Unified Framework | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4925 | TAFS: Task-aware Activation Function Search for Graph Neural Networks | 4.50 | 5.00 | 0.00 | 0.50 | |
| 4926 | Communication-efficient Random-Walk Optimizer for Decentralized Learning | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4927 | Cleaning label noise with vision-language models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4928 | DIFFender: Diffusion-Based Adversarial Defense against Patch Attacks | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4929 | WinNet:time series forecasting with a window-enhanced period extracting and interacting | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4930 | Pick-or-Mix: Dynamic Channel Sampling for ConvNets | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4931 | Adaptive Offline Data Replay in Offline-to-Online Reinforcement Learning | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4932 | Prompt-Tuning Decision Transformer with Preference Ranking | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4933 | PanoOcc: Unified Occupancy Representation for Camera-based 3D Panoptic Segmentation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4934 | Pay attention to cycle for spatio-temporal graph neural network | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4935 | Density-Softmax: Efficient Test-time Model for Uncertainty Estimation and Robustness under Distribution Shifts | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4936 | ACID: Abstractive, Content-Based IDs for Document Retrieval with Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4937 | Every Mistake Counts: Spatial and Temporal Beliefs for Mistake Detection in Assembly Tasks | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4938 | AdaSR: Adaptive Super Resolution for Cross Platform and Dynamic Runtime Environments | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4939 | Unifying User Preferences and Critic Opinions: A Multi-View Cross-Domain Item-sharing Recommender System | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4940 | Learned Visual Features to Textual Explanations | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4941 | Towards Controllable Diffusion Models via Training-Phase Guided Exploration | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4942 | Test Error Guarantees for Batch-normalized two-layer ReLU Networks Trained with Gradient Descent | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4943 | Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4944 | Stylist: Style-Driven Feature Ranking for Robust Novelty Detection | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4945 | Soft Convex Quantization: Revisiting Vector Quantization with Convex Optimization | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4946 | NeuralQP: A General Hypergraph-based Optimization Framework for Large-scale Quadratically Constrained Quadratic Programs | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4947 | Learning within Sleeping: A Brain-Inspired Bayesian Continual Learning Framework | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4948 | Making Multimodal Generation Easier: When Diffusion Models Meet LLMS | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4949 | PROTEIN DESIGNER BASED ON SEQUENCE PROFILE USING ULTRAFAST SHAPE RECOGNITION | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4950 | Dual Diffusion Model for One-Shot High-Fidelity Talking Head Generation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4951 | Local Composite Saddle Point Optimization | 4.50 | 5.00 | 1.41 | 0.50 | |
| 4952 | Diffusion World Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4953 | Differentially Pivate Per-Instance Additive Noise Mechanism: A Game Theoretic Approach | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4954 | Incorporating Implicit Regularization to Enhance the Transition Matrix Method for Effective Handling of Diverse Label Noise | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4955 | Temporally Equivariant Contrastive Learning for Disease Progression | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4956 | Free-style and Fast 3D Portrait Synthesis | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4957 | TwinS: Revisiting Non-Stationarity in Multivariate Time Series Forecasting | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4958 | Efficient Link Prediction via GNN Layers Induced by Negative Sampling | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4959 | Graph Decision Transformer | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4960 | Data De-Duplication and Semantic Enhancement for Contrastive Language-Image Pre-training | 4.75 | 4.50 | 0.87 | -0.25 | |
| 4961 | Learning with Counterfactual Explanations for Radiology Report Generation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4962 | Necessary and Sufficient Watermark for Large Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4963 | Minimum Edit Distance Training for Conditional Language Generation Models | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4964 | ALP: Action-Aware Embodied Learning for Perception | 4.25 | 4.50 | 1.50 | 0.25 | |
| 4965 | The Closer, The Better: Towards Better Representation Learning for Few-Shot Class-Incremental Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4966 | MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4967 | SEESAW: Do Graph Neural Networks Improve Node Representation Learning for All? | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4968 | Delving Deep into Sim2Real Transformation: Maximizing Impact of Synthetic Data in Training | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4969 | Prompting-based Efficient Temporal Domain Generalization | 3.50 | 4.50 | 0.87 | 1.00 | |
| 4970 | Hadamard Domain Training with Integers for Class Incremental Quantized Learning | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4971 | Learnable Counterfactual Attention for Singer Identification | 4.25 | 4.50 | 1.50 | 0.25 | |
| 4972 | BioCLIP: A Vision Foundation Model for the Tree of Life | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4973 | DiPmark: A Stealthy, Efficient and Resilient Watermark for Large Language Models | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4974 | DiffAR: Denoising Diffusion Autoregressive Model for Raw Speech Waveform Generation | 4.50 | 5.50 | 0.50 | 1.00 | |
| 4975 | From Indeterminacy to Determinacy: Augmenting Logical Reasoning Capabilities with Large Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4976 | Alleviating Label Shift Through Self-trained Intermediate Distribution: Theory and Algorithms | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4977 | Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting | 5.00 | 4.50 | 0.87 | -0.50 | |
| 4978 | Upgrading VAE Training With Unlimited Data Plans Provided by Diffusion Models | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4979 | OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4980 | CurrMask: Learning Versatile Skills with Automatic Masking Curricula | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4981 | Dissolving Is Amplifying: Towards Fine-Grained Anomaly Detection | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4982 | NewTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4983 | Learn from the Past: A Proxy based Adversarial Defense Framework to Boost Robustness | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4984 | INRSTEG: FLEXIBLE CROSS-MODAL LARGE CAPACITY STEGANOGRAPHY VIA IMPLICIT REPRESENTATIONS | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4985 | Relaxed State-Adversarial Offline Reinforcement Learning: A Leap Towards Robust Model-Free Policies from Historical Data | 4.00 | 4.50 | 0.87 | 0.50 | |
| 4986 | Detecting Out-of-Distribution Samples via Conditional Distribution Entropy with Optimal Transport | 5.33 | 4.50 | 2.69 | -0.83 | |
| 4987 | Visual Grounding Helps Learn Word Meanings in Low-Data Regimes | 5.00 | 5.00 | 1.22 | 0.00 | |
| 4988 | APC: Predict Global Representation From Local Observation In Multi-Agent Reinforcement Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4989 | Sobolev acceleration for neural networks | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4990 | Learning to Select Camera Views: Efficient Multiview Understanding at Few Glances | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4991 | Probabilistic Stability of Stochastic Gradient Descent | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4992 | SlowFormer: Universal Adversarial Patch for Attack on Compute and Energy Efficiency of Inference Efficient Vision Transformers | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4993 | Time-Series AutoAugment: Data Augmentation Policy Search for Long-Term Forecasting | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4994 | DART: A Principled Approach to Adversarially Robust Unsupervised Domain Adaptation | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4995 | GM-DDPM: Denoising diffusion probabilistic models with Gaussian Mixture Noise | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4996 | How Far Have We Gone in Vulnerability Detection Using Large Language Model | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4997 | Learning Multiple Coordinated Agents under Directed Acyclic Graph Constraints | 4.50 | 4.50 | 1.50 | 0.00 | |
| 4998 | Form follows Function: Text-to-Text Conditional Graph Generation based on Functional Requirements | 4.50 | 4.50 | 0.87 | 0.00 | |
| 4999 | NL2ProGPT: Taming Large Language Model for Conversational Protein Design | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5000 | Activation Function Matters in Graph Transformers | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5001 | Generalization Bounds for Magnitude-Based Pruning via Sparse Matrix Sketching | 4.00 | 4.50 | 2.06 | 0.50 | |
| 5002 | Repositioning the Subject within Image | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5003 | DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation | 4.00 | 4.50 | 0.87 | 0.50 | |
| 5004 | SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5005 | CTP: A Causal Interpretable Model for Non-Communicable Disease Progression Prediction | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5006 | Zero-shot Visual Recognition via Pairwise Attribute Contrasting | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5007 | PIE: Simulating Disease Progression via Progressive Image Editing | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5008 | Keqing: Knowledge-based Question Answering is A Nature Chain-of-Thought mentor of LLMs | 4.75 | 4.50 | 0.87 | -0.25 | |
| 5009 | How does representation impact in-context learning: An exploration on a synthetic task | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5010 | Backdiff: a diffusion model for generalized transferable protein backmapping | 4.50 | 4.50 | 1.50 | 0.00 | |
| 5011 | ConvNet vs Transformer, Supervised vs CLIP: Beyond ImageNet Accuracy | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5012 | Language Models as Black-Box Optimizers for Vision-Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5013 | On the Embedding Collapse When Scaling up Recommendation Models | 4.50 | 5.00 | 0.00 | 0.50 | |
| 5014 | HUB: Enhancing Learned Optimizers via Hybrid Update-based Strategy | 4.33 | 4.50 | 0.87 | 0.17 | |
| 5015 | UniSeMi: Toward Unified Semi-supervised Medical Image Segmentation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5016 | Unpaired Panoramic Image-to-Image Translation Leveraging Pinhole Images | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5017 | Optimal Noise Pursuit for Augmenting Text-to-Video Generation | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5018 | AMMD: Attentive Maximum Mean Discrepancy for Few-Shot Image Classification | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5019 | Simple Yet Effective Spatio-Temporal Prompt Learning | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5020 | Progressive Fusion for Multimodal Integration | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5021 | Robustness May be More Brittle than We Think under Different Degrees of Distribution Shifts | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5022 | Winograd Structured Pruning | 4.50 | 4.50 | 1.50 | 0.00 | |
| 5023 | Choosing Public Datasets for Private Machine Learning via Gradient Subspace Distance | 4.50 | 4.50 | 1.50 | 0.00 | |
| 5024 | DynamicBEV: Leveraging Dynamic Queries and Temporal Context for 3D Object Detection | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5025 | Continual Learners are Viable Long-Tailed Recognizers | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5026 | Out-of-Distribution Detection & Applications With Ablated Learned Temperature Energy | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5027 | Addressing Long-Horizon Tasks by Integrating Program Synthesis and State Machines | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5028 | Unraveling the Enigma of Double Descent: An In-depth Analysis through the Lens of Learned Feature Space | 3.50 | 4.50 | 0.87 | 1.00 | |
| 5029 | Contrastive losses as generalized models of global epistasis | 4.50 | 4.50 | 1.50 | 0.00 | |
| 5030 | Self-Paced Augmentations (SPAug) for Improving Model Robustness | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5031 | Implicit Semi-auto-regressive Image-to-Video Diffusion | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5032 | Provable Convergence of Clipped Normalized-gradient Heavy-Ball Momentum for Adversarial Attacks | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5033 | Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5034 | Fast Learning in Balanced Deep Spiking Neural Networks with Strong and Weak Synapses | 4.50 | 4.50 | 2.69 | 0.00 | |
| 5035 | Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5036 | What Does Stable Diffusion Know about the 3D Scene? | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5037 | Enhancing Image Restoration Transformer with Adaptive Token Dictionary | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5038 | The Power of Linear Combinations: Learning with Random Convolutions | 4.50 | 4.50 | 1.50 | 0.00 | |
| 5039 | Model Pruning with Model Transfer | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5040 | Modelling brain connectomes networks: Solv is a worthy competitor to hyperbolic geometry! | 4.50 | 4.50 | 1.50 | 0.00 | |
| 5041 | Discovering the question-critical moments: Towards building event-aware multi-modal large language models for complex video question answering | 4.50 | 4.50 | 0.87 | 0.00 | |
| 5042 | Non-backtracking Graph Neural Networks | 4.20 | 4.40 | 1.20 | 0.20 | | 5, 3, 5, 5, 3 | | 5, 3, 5, 6, 3 |
|
| 5043 | Hessian-Aware Bayesian Optimization for Decision Making Systems | 4.40 | 4.40 | 2.33 | 0.00 | | 5, 5, 8, 3, 1 | | 5, 5, 8, 3, 1 |
|
| 5044 | From Child's Play to AI: Insights into Automated Causal Curriculum Learning | 4.40 | 4.40 | 1.96 | 0.00 | | 3, 3, 3, 5, 8 | | 3, 3, 3, 5, 8 |
|
| 5045 | Multi-Objective Multi-Solution Transport | 4.00 | 4.40 | 2.33 | 0.40 | | 1, 5, 5, 1, 8 | | 3, 5, 5, 1, 8 |
|
| 5046 | STIMULUS: Achieving Fast Convergence and Low Sample Complexity in Stochastic Multi-Objective Learning | 4.40 | 4.40 | 1.96 | 0.00 | | 3, 5, 8, 3, 3 | | 3, 5, 8, 3, 3 |
|
| 5047 | Imitation Learning Using Generalized Sliced Wasserstein Distances | 4.40 | 4.40 | 1.20 | 0.00 | | 6, 5, 3, 5, 3 | | 6, 5, 3, 5, 3 |
|
| 5048 | FIITED: Fine-grained embedding dimension optimization during training for recommender systems | 4.40 | 4.40 | 1.96 | 0.00 | | 3, 3, 8, 3, 5 | | 3, 3, 8, 3, 5 |
|
| 5049 | $nu$-ensembles: Improving deep ensemble calibration in the small data regime | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 3, 6, 5, 5 | | 3, 3, 6, 5, 5 |
|
| 5050 | UNITE:Universally Trustworthy GNN Via Subgraph Identification | 4.40 | 4.40 | 1.96 | 0.00 | | 3, 3, 5, 3, 8 | | 3, 3, 5, 3, 8 |
|
| 5051 | Can Language Agents Approach the Performance of RL? An Empirical Study On OpenAI Gym | 4.40 | 4.40 | 1.96 | 0.00 | | 8, 3, 3, 5, 3 | | 8, 3, 3, 5, 3 |
|
| 5052 | SAGMAN: Stability Analysis of Graph Neural Networks (GNNs) on the Manifolds | 4.40 | 4.40 | 1.20 | 0.00 | | 6, 5, 3, 3, 5 | | 6, 5, 3, 3, 5 |
|
| 5053 | From Stability to Chaos: Analyzing Gradient Descent Dynamics in Quadratic Regression | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 3, 5, 6, 5 | | 3, 3, 5, 6, 5 |
|
| 5054 | A Unified Framework of Theoretically Robust Contrastive Loss against Label Noise | 4.40 | 4.40 | 1.20 | 0.00 | | 6, 5, 5, 3, 3 | | 6, 5, 5, 3, 3 |
|
| 5055 | IntentGPT: Few-Shot Intent Discovery with Large Language Models | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 6, 3, 5 | | 5, 3, 6, 3, 5 |
|
| 5056 | Fine-Tuning Is All You Need to Mitigate Backdoor Attacks | 4.20 | 4.40 | 1.20 | 0.20 | | 3, 5, 5, 5, 3 | | 3, 6, 5, 5, 3 |
|
| 5057 | Learned Mixing Weights for Transferable Tabular Data Augmentation | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 3, 6, 5 | | 3, 5, 3, 6, 5 |
|
| 5058 | Source-Free Unsupervised Domain Adaptation with Hypothesis Consolidation of Prediction Rationale | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 5, 3, 6 | | 3, 5, 5, 3, 6 |
|
| 5059 | KVTQ: Compressing the KV Cache to Hardware Efficient Ternary Digits by Fine-Grained Dynamic Quantization | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 6, 3, 5, 3 | | 5, 6, 3, 5, 3 |
|
| 5060 | Optimal Kernel Choice for Score Function-based Causal Discovery | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 5, 3, 3, 6 | | 5, 5, 3, 3, 6 |
|
| 5061 | Deep Graph Predictions using Dirac-Bianconi Graph Neural Networks | 4.20 | 4.40 | 1.20 | 0.20 | | 5, 5, 3, 5, 3 | | 6, 5, 3, 5, 3 |
|
| 5062 | Beyond Gradient and Priors in Privacy Attacks: Leveraging Pooler Layer Inputs of Language Models in Federated Learning | 4.40 | 4.40 | 2.06 | 0.00 | | 1, 6, 6, 6, 3 | | 1, 6, 6, 6, 3 |
|
| 5063 | Characterizing Exceptional Distributions with Neural Rule Extraction | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 6, 3, 5 | | 3, 5, 6, 3, 5 |
|
| 5064 | V-JEPA: Latent Video Prediction for Visual Representation Learning | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 5, 6, 3 | | 3, 5, 5, 6, 3 |
|
| 5065 | Availability Attacks Need to Create Shortcuts for Contrastive Learning | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 3, 5, 5, 6 | | 3, 3, 5, 5, 6 |
|
| 5066 | Transferable Availability Poisoning Attacks | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 6, 3, 5 | | 3, 5, 6, 3, 5 |
|
| 5067 | Why SAM finetuning can benefit Out-of-Distribution Detection? | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 5, 6, 3, 3 | | 5, 5, 6, 3, 3 |
|
| 5068 | Semi-Supervised End-To-End Contrastive Learning For Time Series Classification | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 5, 3, 6 | | 5, 3, 5, 3, 6 |
|
| 5069 | Masked Pretraining for Multi-Agent Decision Making | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 3, 5, 6 | | 5, 3, 3, 5, 6 |
|
| 5070 | Graph Inference Acceleration by Bridging GNNs and MLPs with Self-Supervised Learning | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 6, 3, 5 | | 5, 3, 6, 3, 5 |
|
| 5071 | Measuring Local and Shuffled Privacy of Gradient Randomized Response | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 6, 5, 3, 5 | | 3, 6, 5, 3, 5 |
|
| 5072 | Rethinking Teacher-Student Curriculum Learning under the Cooperative Mechanics of Experience | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 5, 3, 6 | | 3, 5, 5, 3, 6 |
|
| 5073 | Generating Molecular Conformer Fields | 4.25 | 4.40 | 1.20 | 0.15 | |
| 5074 | MIPGen: Learning to Generate Scalable MIP Instances | 4.40 | 4.40 | 1.96 | 0.00 | | 3, 8, 5, 3, 3 | | 3, 8, 5, 3, 3 |
|
| 5075 | On the Verification Complexity of Deterministic Nonsmooth Nonconvex Optimization | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 3, 5, 6, 5 | | 3, 3, 5, 6, 5 |
|
| 5076 | Robustify the Latent Space: Offline Distributionally Robust Reinforcement Learning with Linear Function Approximation | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 6, 3, 5 | | 5, 3, 6, 3, 5 |
|
| 5077 | Mixture Stochastic Block Model for Multi-Group Community Detection in Multiplex Graphs | 3.80 | 4.40 | 1.20 | 0.60 | | 3, 3, 3, 5, 5 | | 5, 3, 3, 5, 6 |
|
| 5078 | Autoencoders with Intrinsic Dimension Constraints for Learning Low Dimensional Image Representations | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 6, 5, 3 | | 5, 3, 6, 5, 3 |
|
| 5079 | ZeroP: Zero-Shot Quantization via Proxy Data | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 5, 6, 3 | | 5, 3, 5, 6, 3 |
|
| 5080 | Domain Bridge: Generative Model-based Domain Forensic for Black-box Models | 4.40 | 4.40 | 1.20 | 0.00 | | 6, 5, 3, 5, 3 | | 6, 5, 3, 5, 3 |
|
| 5081 | Modeling Time Series as Text Sequence A Frequency-vectorization Transformer for Time Series Forecasting | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 6, 3, 3, 5 | | 5, 6, 3, 3, 5 |
|
| 5082 | GenN2N: Generative NeRF2NeRF Translation | 4.40 | 4.40 | 1.20 | 0.00 | | 3, 5, 3, 5, 6 | | 3, 5, 3, 5, 6 |
|
| 5083 | Unveiling Temporal Telltales: Are Unconditional Video Generation Models Implicitly Encoding Temporal Information? | 4.40 | 4.40 | 1.20 | 0.00 | | 5, 3, 5, 3, 6 | | 5, 3, 5, 3, 6 |
|
| 5084 | Do Current Large Language Models Master Adequate Clinical Knowledge? | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5085 | Everyone Deserves A Reward: Learning Customized Human Preferences | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5086 | IKL: Boosting Long-Tail Recognition with Implicit Knowledge Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5087 | Syntactic Representations Enable Interpretable Hierarchical Word Vectors | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5088 | Towards Analyzing Self-attention via Linear Neural Network | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5089 | Phase Transitions in Contrastive Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5090 | Controllable Text-to-Image Generation with Automatic Sketches | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5091 | Learning Invariances via Neural Network Pruning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5092 | FusionViT: Hierarchical 3D Object Detection via Lidar-Camera Vision Transformer Fusion | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5093 | Deep-Learning Approaches for Optimized Web Accessibility: Correcting Violations and Enhancing User Experience | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5094 | Provable Repair of Vision Transformers: Last Layer is All You Need | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5095 | SGOOD: Substructure-enhanced Graph-Level Out-of-Distribution Detection | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5096 | Optimal algorithms for group distributionally robust optimization and beyond | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5097 | Federated Binary Matrix Factorization using Proximal Optimization | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5098 | Contrastive Decoding Improves Reasoning in Large Language Models | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5099 | SEArch: A Self-Evolving Framework for Network Architecture Optimization | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5100 | Instance Needs More Care: Rewriting Prompts for Instances Yields Better Zero-Shot Performance | 4.67 | 4.33 | 0.94 | -0.33 | |
| 5101 | Apollo: Zero-shot MultiModal Reasoning with Multiple Experts | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5102 | Splicing Up Your Predictions with RNA Contrastive Learning | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5103 | Unnormalized Density Estimation with Root Sobolev Norm Regularization | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5104 | High-Order Tensor Recovery with A Tensor $U_1$ Norm | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5105 | Synthesizing Programmatic Policy for Domain Generalization | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5106 | STUPD: A Synthetic Dataset for Spatial and Temporal Relation Reasoning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5107 | IMEX-Reg: Implicit-Explicit Regularization in the Function Space for Continual Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5108 | Curiosity Driven Protein Sequence Generation via Reinforcement Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5109 | Contrastive Representations Make Planning Easy | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5110 | SEEKING THE SEARCH SPACE FOR SIZE-AWARE VISION TRANSFORMER ARCHITECTURE | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5111 | Causal Influence-Aware Counterfactual Data Augmentation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5112 | Revealing Unintentional Information Leakage in Low-Dimensional Facial Portrait Representations | 4.33 | 6.00 | 1.41 | 1.67 | |
| 5113 | Neural Networks and Solomonoff Induction | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5114 | BiXT: Perceiving Longer Sequences With Bi-Directional Cross-Attention Transformers | 4.00 | 4.33 | 2.36 | 0.33 | |
| 5115 | Machine Learning for PROTAC Engineering | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5116 | Imbalanced data robust online continual learning based on evolving class aware memory selection and built-in contrastive representation learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5117 | Beyond Unimodal Learning: The Importance of Integrating Multiple Modalities for Lifelong Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5118 | Enhancing Medical Image Generation with Anatomical Precision: A Multi-Headed VAE-Based Diffusion Model | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5119 | AdaFlood: Adaptive Flood Regularization | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5120 | Towards Cost-Efficient Federated Multi-Agent Reinforcement Learning with Learnable Aggregation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5121 | NeRF Compression via Transform Coding | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5122 | Learning from Shortcut: A Shortcut-guided Approach for Graph Rationalization | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5123 | Who SAID that? Benchmarking Social Media AI Detection | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5124 | Connect Later: Improving Fine-Tuning for Robustness with Targeted Augmentations | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5125 | SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5126 | Theoretically Understanding Data Reconstruction Leakage in Federated Learning | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5127 | PromptFix: Few-shot Backdoor Removal via Adversarial Prompt Tuning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5128 | The Power of the Senses: Generalizable Manipulation from Vision and Touch through Masked Multimodal Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5129 | Exact Path Kernels Naturally Decompose Model Predictions | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5130 | Denoising Low-Rank Data Under Distribution Shift: Double Descent and Data Augmentation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5131 | Signatures Meet Dynamic Programming: Generalizing Bellman Equations for Trajectory Following | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5132 | Latent Concept-based Explanation of NLP Models | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5133 | Rank-adaptive spectral pruning of convolutional layers during training | 3.00 | 4.33 | 0.94 | 1.33 | |
| 5134 | Efficient Graph Representation Learning by Non-Local Information Exchange | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5135 | A universal metric of dataset similarity for multi-source learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5136 | Metric Space Magnitude for Evaluating Unsupervised Representation Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5137 | Towards Subgraph Isomorphism Counting with Graph Kernels | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5138 | Agent Instructs Large Language Models to be General Zero-Shot Reasoners | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5139 | Simplifying Self-Supervised Object Detection Pretraining | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5140 | Understanding Sparse Feature Updates in Deep Networks using Iterative Linearisation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5141 | Interpretable Concept Discovery and Learning from Pretrained Vision-Language Models | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5142 | Leveraging Heterogeneous Side Information via Diffusion Models for Time-series Anomaly Detection | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5143 | The Devil is in the Edges: Monocular Depth Estimation with Edge-aware Consistency Fusion | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5144 | Estimating Post-Synaptic Effects for Online Training of Feed-Forward SNNs | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5145 | Distilling ODE Solvers of Diffusion Models into Smaller Steps | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5146 | Retro: Reusing teacher projection head for efficient embedding distillation on Lightweight Models via Self-supervised Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5147 | Intuitive or Dependent? Investigating LLms’ Robustness to Conflicting Prompts | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5148 | Explaining recommendation systems through contrapositive perturbations | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5149 | Rethinking Self-Supervise Learning: An Instance-wise Similarity Perspective | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5150 | Unified Long-Term Time-Series Forecasting Benchmark | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5151 | The Underlying Scaling Laws and Universal Statistical Structure of Complex Datasets | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5152 | Learning a Diffusion Model Policy from Rewards via Q-Score Matching | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5153 | EdVAE: Mitigating Codebook Collapse with Evidential Discrete Variational Autoencoders | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5154 | Proper Backward Connection Placement Boosts Spiking Neural Networks | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5155 | Differentially Private Principal Component Analysis for Vertically Partitioned Data | 4.33 | 4.33 | 2.36 | 0.00 | |
| 5156 | SCoRF: Single-stage convolutional radiance fields for effective 3D scene representation | 4.67 | 4.33 | 0.94 | -0.33 | |
| 5157 | USTAM: UNIFIED SPATIO-TEMPORAL ATTENTION MIXFORMER FOR VISUAL OBJECT TRACKING | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5158 | Robust Backdoor Attack with Visible, Semantic, Sample-specific and Compatible Triggers | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5159 | Boosting Adverse Weather Crowd Counting via Multi-queue Contrastive Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5160 | Encoding Speaker-Specific Latent Speech Feature for Speech Synthesis | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5161 | PETformer: Long-term Time Series Forecasting via Placeholder-enhanced Transformer | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5162 | Communication-Efficient Federated Learning with Accelerated Client Gradient | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5163 | ERA-Solver: Error-Robust Adams Solver for Fast Sampling of Diffusion Probabilistic Models | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5164 | Meta-Knowledge Extraction: Uncertainty-Aware Prompted Meta-Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5165 | DebateGPT: Fine-tuning Large Language Models with Multi-agent Debate Supervision | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5166 | Fairness without Sensitive attributes via Noise and Uncertain Predictions | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5167 | Splitted Wavelet Differential Inclusion | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5168 | Error-Feedback Meets Stochastic Approximation with Two Time Scales | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5169 | OSRT: An Online Sparse Approximation Model for Scattered Data | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5170 | Harnessing the Power of Federated Learning in Federated Contextual Bandits | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5171 | Score-based Neural Processes | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5172 | Examining the Achilles' Heel of CLIP Models: The Worst-Performing Categories | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5173 | CaStRL: Context-Aware State Representation learning with Transformer | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5174 | Assessing the Impact of Distribution Shift on Reinforcement Learning Performance | 3.67 | 4.67 | 1.25 | 1.00 | |
| 5175 | Multil-Level Multimodal Alignment with Knowledge-Guided Instance-Wise Discrimination | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5176 | Cooperative Minibatching in Graph Neural Networks | 4.00 | 4.33 | 2.36 | 0.33 | |
| 5177 | DIFUSCO-LNS: Diffusion-Guided Large Neighbourhood Search for Integer Linear Programming | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5178 | Adversarial Defense using Targeted Manifold Manipulation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5179 | Modeling non-uniform uncertainty in Reaction Prediction via Boosting and Dropout | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5180 | Fractal Patterns May Unravel the Intelligence in Next-Token Prediction | 4.33 | 4.33 | 2.36 | 0.00 | |
| 5181 | Topology Matters in Fair Graph Learning: a Theoretical Pilot Study | 4.67 | 4.33 | 0.94 | -0.33 | |
| 5182 | Editable Graph Neural Network for Node Classifications | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5183 | Incentivized Collaborative Learning: Architectural Design and Insights | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5184 | Overcome Data Heterogeneity in Federated Learning with Filter Decomposition | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5185 | Unsupervised Feature Learning with Emergent Data-Driven Prototypicality | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5186 | Hyper-parameter Tuning for Fair Classification without Sensitive Attribute Access | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5187 | Sparsify the Weights but Let the Gradients Flow! | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5188 | Fairness-Aware Domain Generalization under Covariate and Dependence Shifts | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5189 | Reflected Schr'odinger Bridge for Constrained Generative Modeling | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5190 | Zero-Level-Set Encoder for Neural Distance Fields | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5191 | Characterising Partial Identifiability in Inverse Reinforcement Learning For Agents With Non-Exponential Discounting | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5192 | Liteformer: Lightweight Evoformer for Protein Structure Prediction | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5193 | OccuQuest: Mitigating Occupational Bias for Inclusive Large Language Models | 4.00 | 4.33 | 0.94 | 0.33 | |
| 5194 | Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5195 | Multi-Concept T2I-Zero: Tweaking Only The Text Embeddings And Nothing Else | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5196 | Budgeted Online Continual Learning by Adaptive Layer Freezing and Frequency-based Sampling | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5197 | Measuring Value Understanding in Language Models through Discriminator-Critique Gap | 4.00 | 4.33 | 0.94 | 0.33 | |
| 5198 | Bridging the Domain Gap by Clustering-based Image-Text Graph Matching | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5199 | DataFreeShield: Defending Adversarial Attacks without Training Data | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5200 | Decentralized Decoupled Training for Federated Long-Tailed Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5201 | PDED: Revitalize physics laws submerged in data information for Traffic State Estimation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5202 | Topology-Informed Graph Transformer | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5203 | MGTST: Multi-scale and Cross-channel Gated Transformer for Multivariate long-term time-series forecasting | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5204 | Generative and Explainable Data Augmentation for Single-Domain Generalization | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5205 | Scaling Properties For Artificial Neural Network Models of the $textit{C. elegans}$ Nervous System | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5206 | LoRA ensembles for large language model fine-tuning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5207 | Boosting Self-Supervised Graph Representation Learning via Anchor-Neighborhood Alignment and Isotropic Constraints | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5208 | BiDST: Dynamic Sparse Training is a Bi-Level Optimization Problem | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5209 | Domain Generalization for Domain-Linked Classes | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5210 | MAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5211 | POUTA - Produce once, utilize twice for anomaly detection | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5212 | CARD: Certifiable Reweighting for Single Domain Generalization Object Detection | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5213 | Masked Diffusion Models are Fast Distribution Learners | 4.33 | 4.33 | 0.94 | 0.00 | | 5, 5, 3, 3, 5, 5 | | 5, 5, 3, 3, 5, 5 |
|
| 5214 | Pushing the Limits of Pre-training for Time Series Forecasting in the CloudOps Domain | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5215 | CAT-Seg: Cost Aggregation for Open-vocabulary Semantic Segmentation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5216 | MST-GNN: Graph Neural Network with Multi-Granularity in Space and Time for Traffic Prediction | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5217 | TOAST: Transfer Learning via Top-Down Attention Steering | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5218 | Image Compression Is an Effective Objective for Visual Representation Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5219 | DivKnowQA: Verifying the Reasoning Ability of LLM Through Open-Domain Question Answering Over Knowledge Base and Text | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5220 | Hexa: Self-Improving for Knowledge Augmented Dialogue System | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5221 | Nonnegative Matrix Factorization through Canonical Edges | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5222 | Compound Returns Reduce Variance in Reinforcement Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5223 | Exploiting River Network Topology for Flood Forecasting with Graph Neural Networks | 4.00 | 4.33 | 0.94 | 0.33 | |
| 5224 | Everyone Counts: Fair and Accurate Heterogeneous Federated Learning with Resource-Adaptive Model Modulation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5225 | Improved Regret Bounds in Stochastic Contextual Bandits with Graph Feedback | 4.33 | 4.33 | 2.36 | 0.00 | |
| 5226 | Equal Long-term Benefit Rate: Adapting Static Fairness Notions to Sequential Decision Making | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5227 | PETNet - Coincident Particle Event Detection using Spiking Neural Networks | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5228 | Encoding Unitig-level Assembly Graphs with Heterophilous Constraints for Metagenomic Contigs Binning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5229 | Multimodal Meta-learning of Implicit Neural Representations with Iterative Adaptation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5230 | Exploring View Sampling Strategy in Novel View Synthesis from Causal Perspectives | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5231 | FLNERF: 3D FACIAL LANDMARKS ESTIMATION IN NEURAL RADIANCE FIELDS | 4.67 | 4.33 | 0.94 | -0.33 | |
| 5232 | pEBR: A Probabilistic Approach to Embedding Based Retrieval | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5233 | Node Duplication Improves Cold-start Link Prediction | 3.67 | 4.33 | 0.94 | 0.67 | |
| 5234 | From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5235 | Low-coherence Subspace Projection: Enhance the Learning Capacity of Orthogonal Projection Methods on Long Task Sequences | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5236 | Online Continual Learning Without the Storage Constraint | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5237 | Vision ELECTRA: Adversarial Masked Image Modeling with Hierarchical Discriminator | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5238 | Instructed Diffuser with Temporal Condition Guidance for Offline Reinforcement Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5239 | Multi-Objective Molecular Design through Learning Latent Pareto Set | 4.33 | 4.67 | 1.25 | 0.33 | |
| 5240 | Rethinking One-vs-the-Rest Loss for Instance-dependent Complementary Label Learning | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5241 | OceanGPT: A Large Language Model for Ocean Science Tasks | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5242 | Implicit Reinforcement Learning Properties in Supervised Transformer-based Object Detection | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5243 | Simplifying and Stabilizing Model Selection in Unsupervised Domain Adaptation | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5244 | SingleInsert: Inserting New Concepts from a Single Image into Text-to-Image Models for Flexible Editing | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5245 | MuDreamer: Learning Predictive World Models without Reconstruction | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5246 | Omnipotent Adversarial Training in the Wild | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5247 | Aligner: One Global Token is Worth Millions of Parameters When Aligning LLMs | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5248 | A Unified View on Neural Message Passing with Opinion Dynamics for Social Networks | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5249 | On the Importance of Backbone to the Adversarial Robustness of Object Detectors | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5250 | Motion Flow Matching for Efficient Human Motion Synthesis and Editing | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5251 | Long-Tailed 3D Detection via 2D Late Fusion | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5252 | Sample-aware RandAugment | 4.33 | 4.33 | 0.94 | 0.00 | |
| 5253 | Fishnets: Information-Optimal, Scalable Aggregation for Sets and Graphs | 4.29 | 4.29 | 1.16 | 0.00 | | 3, 3, 5, 3, 6, 5, 5 | | 3, 3, 5, 3, 6, 5, 5 |
|
| 5254 | BATTLE: Towards Behavior-oriented Adversarial Attacks against Deep Reinforcement Learning | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5255 | Neural Evolutionary Kernel Method: A Knowledge-Based Learning Architechture for Evolutionary PDEs | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5256 | Deep Network Partition Density Exhibits Double Descent | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5257 | Exploring mechanisms of Neural Robustness: probing the bridge between geometry and spectrum | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5258 | Prototypes-Injected Prompt for Federated Class Incremental Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5259 | Instruction-tuned LLMs with World Knowledge are More Aligned to the Human Brain | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5260 | Mask Frozen-DETR: High Quality Instance Segmentation with One GPU | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5261 | FLAT-Chat: A Word Recovery Attack on Federated Language Model Training | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5262 | Unlocking Anticipatory Text Generation: A Constrained Approach for Faithful Decoding with Large Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5263 | Estimation error of gradient descent in deep regressions | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5264 | Misusing Tools in Large Language Models With Visual Adversarial Examples | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5265 | DECOUPLING REASONING FROM OBSERVATIONS FOR EFFICIENT AUGMENTED LANGUAGE MODELS | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5266 | GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5267 | MiniFold: Simple, Fast and Accurate Protein Structure Prediction | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5268 | Learning and Forgetting Unsafe Examples in Large Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5269 | Federated Generalization via Information-Theoretic Distribution Diversification | 3.00 | 4.25 | 1.30 | 1.25 | |
| 5270 | XplainLLM: A QA Explanation Dataset for Understanding LLM Decision-Making | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5271 | Rethinking Counterfactual Fairness: On Which Individuals to Enforce, and How? | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5272 | Deep Neural Networks Can Learn Generalizable Same-Different Visual Relations | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5273 | Text2Data: Low-Resource Data Generation with Textual Control | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5274 | Parameter-Efficient Tuning Helps Language Model Alignment | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5275 | DIRECTIONALITY IN GRAPH TRANSFORMERS | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5276 | Graph Neural Networks Gone Hogwild | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5277 | Efficient Subgraph Rule Induction via Tree Folding in Differentiable Logic Programming | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5278 | Strategic Recommendations for Improved Outcomes in Congestion Games | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5279 | A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5280 | Nature-Inspired Local Propagation | 4.25 | 4.25 | 1.92 | 0.00 | |
| 5281 | Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5282 | Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5283 | URDFormer: Constructing interactive Realistic Scenes from Real Images via Simulation and Generative Modeling | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5284 | Scaling Safe Learning-based Control to Long-Horizon Temporal Tasks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5285 | Unifying Model-Based and Model-Free Reinforcement Learning with Equivalent Policy Sets | 4.00 | 4.75 | 1.09 | 0.75 | |
| 5286 | Feasibility with Language Models for Open-World Compositional Zero-Shot Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5287 | Everybody Needs a Little HELP: Explaining Graphs via Hierarchical Concepts | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5288 | Recurrent Neural Cellular Automata with Self-Attention for Multi-agent System | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5289 | PhaseFusion: A Diffusion-based Periodic Parameterized Motion Generation Framework | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5290 | On the memorisation of image classifiers | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5291 | Sorting Out Quantum Monte Carlo | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5292 | Conditional Generative Models are Sufficient to Sample from Any Causal Effect Estimand | 4.00 | 4.25 | 1.92 | 0.25 | |
| 5293 | PaperQA: Retrieval-Augmented Generative Agent for Scientific Research | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5294 | Reservoir Transformer at Infinite Horizon: the Lyapunov Time and the Butterfly Effect | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5295 | Optimization for Neural Operator Learning: Wider Networks are Better | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5296 | D5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning | 4.00 | 4.75 | 1.09 | 0.75 | |
| 5297 | Head Information Bottleneck: An Evaluation Method for Transformer Head Contributions in Speech Task | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5298 | Greedy PIG: Adaptive Integrated Gradients | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5299 | SARI: SIMPLISTIC AVERAGE AND ROBUST IDENTIFICATION BASED NOISY PARTIAL LABEL LEARNING | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5300 | Two-sided Competing Matching Markets With Complementary Preferences | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5301 | Unsupervised graph neural networks with recurrent features for solving combinatorial optimization problems | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5302 | MeRino: Entropy-driven Design for Mobile-friendly Generative Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5303 | Refined Tensorial Radiance Field: Harnessing coordinate based networks for novel view synthesis from sparse inputs | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5304 | Compositional Interfaces for Compositional Generalization | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5305 | Prodigy: An Expeditiously Adaptive Parameter-Free Learner | 4.25 | 4.25 | 1.92 | 0.00 | |
| 5306 | HiLoRL: A Hierarchical Logical Model for Learning Composite Tasks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5307 | A trainable manifold for accurate approximation with ReLU Networks | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5308 | Federated Learning Under Second-Order Data Heterogeneity | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5309 | Extrapolating Large Language Models to Non-English by Aligning Languages | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5310 | Information-Theoretic World Model learning for Denoised Predictions | 4.00 | 4.75 | 1.09 | 0.75 | |
| 5311 | Leveraging Print Debugging to Improve Code Generation in Large Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5312 | Fill with Anything: High-Resolution and Prompt-Faithful Image Completion | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5313 | Analyzing Local Representations of Self-supervised Vision Transformers | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5314 | Learnable Invisible Backdoor for Diffusion Models | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5315 | One is More: Diverse Perspectives within a Single Network for Efficient DRL | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5316 | Graphical Object-Centric Actor-Critic | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5317 | Effective Offline Environment Reconstruction when the Dataset is Collected from Diversified Behavior Policies | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5318 | Dynamics of Instruction Tuning: Each Ability of Large Language Models Has Its Own Growth Pace | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5319 | Value-Biased Maximum Likelihood Estimation for Model-based Reinforcement Learning in Discounted Linear MDPs | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5320 | How to Craft Backdoors with Unlabeled Data Alone? | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5321 | QORA: Zero-Shot Transfer via Interpretable Object-Relational Model Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5322 | Augmented Policy Optimization for Safe Reinforcement Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5323 | Mitigating Mode Collapse in Sequential Disentanglement via an Architecture Bias | 3.50 | 4.50 | 2.06 | 1.00 | |
| 5324 | On the Global Convergence of Natural Actor-Critic with Neural Network Parametrization | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5325 | Push: Concurrent Probabilistic Programming for Bayesian Deep Learning | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5326 | First-Explore, then Exploit: Meta-Learning Intelligent Exploration | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5327 | Margin Discrepancy-based Adversarial Training for Multi-Domain Text Classification | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5328 | Graph Neural Networks with Directional Encodings for Anisotropic Elasticity | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5329 | Federated Tuning for Black Box Large Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5330 | FireAct: Toward Language Agent Finetuning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5331 | Discovering Mathematical Formulas from Data via LSTM-guided Monte Carlo Tree Search | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5332 | Invariant Attention: Provable Clustering Under Transformations | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5333 | Periodic Set Transformer: Material Property Prediction from Continuous Isometry Invariants | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5334 | V-Former: Offline RL with Temporally-Extended Actions | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5335 | Enhancing Clinical Note Summarization: Iterative Reflexions with Small-model Supervision and Error2Correct Demonstrations | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5336 | Multi-agent Optimistic Soft Q-Learning: A co-MARL Algorithm with a Global Convergence Guarantee | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5337 | Adaptive Continual Learning: Rapid Adaptation and Knowledge Refinement | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5338 | Fast and Reliable Generation of EHR Time Series via Diffusion Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5339 | Efficient VideoMAE via Temporal Progressive Training | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5340 | SCALE: Scaling up the Complexity for Advanced Language Model Evaluation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5341 | Real-time learning of decay trajectory of Higgs boson using reservoir-in-reservoir architecture | 3.50 | 4.25 | 1.92 | 0.75 | |
| 5342 | Large Language Model Routing with Benchmark Datasets | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5343 | Detecting Influence Structures in Multi-Agent Reinforcement Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5344 | Clustering Entity Specific Embeddings Towards a Prescribed Distribution | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5345 | Interpreting Categorical Distributional Reinforcement Learning: An Implicit Risk-Sensitive Regularization Effect | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5346 | Physics-aware Causal Graph Network for Spatiotemporal Modeling | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5347 | Pruning neural networks using FishLeg estimation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5348 | Faster and Accurate Neural Networks with Semantic Inference | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5349 | Speech language models lack important brain-relevant semantics | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5350 | Improving length generalization in transformers via task hinting | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5351 | Inference from Real-World Sparse Measurements | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5352 | BOtied: Multi-objective Bayesian optimization with tied multivariate ranks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5353 | Expecting The Unexpected: Towards Broad Out-Of-Distribution Detection | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5354 | Towards guarantees for parameter isolation in continual learning | 4.25 | 4.25 | 1.92 | 0.00 | |
| 5355 | BMAD: Benchmarks for Medical Anomaly Detection | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5356 | Image Super-Resolution via Latent Diffusion: A Sampling-Space Mixture of Experts and Frequency-Augmented Decoder Approach | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5357 | NAG-GS: Semi-Implicit, Accelerated and Robust Stochastic Optimizer | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5358 | EchoPrompt: Instructing the Model to Rephrase Queries for Improved In-context Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5359 | A Lennard-Jones Layer for Distribution Normalization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5360 | Part-based bird classifiers with an explainable, editable language bottleneck | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5361 | MultiContrievers: Analysis of Dense Retrieval Representations | 4.25 | 4.50 | 1.50 | 0.25 | |
| 5362 | Looping LOCI: Developing Object Permanence from Videos | 3.67 | 4.25 | 1.30 | 0.58 | |
| 5363 | Comprehensive Comparison between Vision Transformers and Convolutional Neural Networks for Face Recognition Tasks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5364 | Aligning brain functions boosts the decoding of videos in novel subjects | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5365 | DynaEval: A Dynamic Interaction-based Evaluation Framework for Assessing LLMs in Real-world Scenarios | 4.75 | 4.25 | 1.30 | -0.50 | |
| 5366 | Localized Text-to-Image Generation For Free via Cross Attention Control | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5367 | FedORION: Aggregation-Assisted Proxyless Distillation for Heterogeneous Federated Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5368 | SQS: Speech Quality Assessment in the Data Annotation Context | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5369 | Cross-modality Interpretable image classification via Concept Decomposition Vector of Visual Language Models | 4.25 | 4.25 | 1.92 | 0.00 | |
| 5370 | Towards Pareto-Optimality for Test-Time Adaptation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5371 | DOG: Discriminator-only Generation Beats GANs on Graphs | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5372 | Non-Redundant Graph Neural Networks with Improved Expressiveness | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5373 | Good Better Best: Self-Motivated Imitation Learning For Noisy Demonstrations | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5374 | Safe Online Bid Optimization with Return On Investment and Budget Constraints | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5375 | Evolving Computation Graphs | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5376 | Disco-Bench: A Context-Aware Evaluation Benchmark for Language Modelling | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5377 | PASTA: Pretrained Action-State Transformer Agents | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5378 | Can long-context large language models understand long contexts? | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5379 | APBench: A Unified Benchmark for Availability Poisoning Attacks and Defenses | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5380 | The Noise Geometry of Stochastic Gradient Descent: A Quantitative and Analytical Characterization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5381 | AV-PEA: PARAMETER-EFFICIENT ADAPTER FOR AUDIO-VISUAL MULTIMODAL LEARNING | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5382 | Corgi$^2$: A Hybrid Offline-Online Approach To Storage-Aware Data Shuffling For SGD | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5383 | Learning a Reusable Meta Denoiser for Learning with Noisy Labels on Multiple Target Domains | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5384 | Getting a-Round Guarantees: Floating-Point Attacks on Certified Robustness | 4.25 | 4.25 | 2.59 | 0.00 | |
| 5385 | Continual Memory Neurons | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5386 | Incentivizing Data Collection from Heterogeneous Clients in Federated Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5387 | Connectivity-based Token Condensation for Efficient Vision Transformer | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5388 | Model2Scene: Learning 3D Scene Representation via Contrastive Language-CAD Models Pre-training | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5389 | Knowledge Crosswords: Geometric Reasoning over Structured Knowledge with Large Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5390 | ${rm EFO}_k$-CQA: Towards Knowledge Graph Complex Query Answering beyond Set Operation | 4.75 | 4.25 | 1.30 | -0.50 | |
| 5391 | Fairness Improves Learning from Noisily Labeled Long-Tailed Data | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5392 | Average Sensitivity of Hierarchical Clustering | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5393 | Transferable Deep Clustering Model | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5394 | Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware GPT-4 | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5395 | Bayesian Preference Elicitation for Personalized Prefactual Recommendation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5396 | Boosting Fast and High-Quality Speech Synthesis with Linear Diffusion | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5397 | HOVER: Hyperbolic Video-text Retrieval | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5398 | ProGO: Probabilistic Global Optimizer | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5399 | Deep PDE Solvers for Subgrid Modelling and Out-of-Distribution Generalization | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5400 | Visual Attention-Prompted Prediction and Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5401 | Rehearsal NeRF: Disentangling Dynamic Illuminations in Neural Radiance Fields | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5402 | FP-IRL: Fokker-Planck-based Inverse Reinforcement Learning --- A Physics-Constrained Approach to Markov Decision Processes | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5403 | Prompt Tuning Is All We Need? | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5404 | GRepsNet: A Simple Equivariant Network for Arbitrary Matrix Groups | 4.75 | 4.25 | 2.59 | -0.50 | |
| 5405 | Learning Transferable Robust Representations for Few-shot Learning via Multi-view Consistency | 4.67 | 4.25 | 1.30 | -0.42 | |
| 5406 | Semi-supervised Diffusion Solver for Travelling Salesman Problem | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5407 | Revisiting the Temporal Modeling in Spatio-Temporal Predictive Learning under A Unified View | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5408 | CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5409 | GPT Is Becoming a Turing Machine: Here Are Some Ways to Program It | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5410 | Learning An Efficient-And-Rigorous Neural Multigrid Solver | 3.75 | 4.25 | 1.30 | 0.50 | |
| 5411 | Can Euclidean Symmetry Help in Reinforcement Learning and Planning? | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5412 | Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5413 | Advantage-Conditioned Diffusion: Offline RL via Generalization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5414 | The Update Equivalence Framework for Decision-Time Planning | 4.75 | 4.25 | 1.30 | -0.50 | |
| 5415 | ReLU soothes NTK conditioning and accelerates optimization for wide neural networks | 3.67 | 4.25 | 1.30 | 0.58 | |
| 5416 | Todyformer: Towards Holistic Dynamic Graph Transformers with Structure-Aware Tokenization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5417 | Graph Positional and Structural Encoder | 3.50 | 4.25 | 1.92 | 0.75 | |
| 5418 | Understanding Graph Transformers by Generalized Propagation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5419 | Causality is Invariance Across Heterogeneous Units | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5420 | Selective Perception: Learning Concise State Descriptions for Language Model Actors | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5421 | Persistent homology for high-dimensional data based on spectral methods | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5422 | Learning Concept-Based Visual Causal Transition and Symbolic Reasoning for Visual Planning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5423 | Graph-Based Automatic Feature Selection for Multi-Class Classification via Mean Simplified Silhouette | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5424 | How Hessian structure explains mysteries in sharpness regularization | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5425 | RealFM: A Realistic Mechanism to Incentivize Data Contribution and Device Participation | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5426 | Reconstruction as Sequence for Efficient Unified Unsupervised Anomaly Detection | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5427 | Beyond Laplace and Gaussian: Exploring the Generalized Gaussian Mechanism for Private Machine Learning | 4.25 | 4.25 | 2.59 | 0.00 | |
| 5428 | Automata Learning for Neural Event ODEs: An Interpretable Model of Piecewise Dynamics | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5429 | Uncertainty for Active Learning on Graphs | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5430 | Uniform as Glass: Gliding over the Pareto Front with Neural Adaptive Preferences | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5431 | Leveraging Large Language Models for Optimised Coordination in Textual Multi-Agent Reinforcement Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5432 | GenNBV: Generalizable Next-Best-View Policy for Active 3D Reconstruction | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5433 | Harnessing Orthogonality to Train Low-Rank Neural Networks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5434 | Boosting Meta-Training with Base Class Information for Few-Shot Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5435 | Suppressing Overestimation in Q-Learning through Adversarial Behaviors | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5436 | TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5437 | GC-Mixer: A Novel Architecture for Time-varying Granger Causality Inference | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5438 | Sequence-SOD: Sequence-aware Spiking Object Detection for Event Cameras | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5439 | Learning Equi-angular Representations for Online Continual Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5440 | The Program Testing Ability of Large Language Models for Code | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5441 | DOG: Diffusion-based Outlier Generation for Out-of-Distribution Detection | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5442 | Test-Time Training for Semantic Segmentation with Output Contrastive Loss | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5443 | In Defence Of Wasserstein | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5444 | A computational approach to visual ecology with deep reinforcement learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5445 | CCD-3DR: Consistent Conditioning in Diffusion for Single-Image 3D Reconstruction | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5446 | Improving Discriminative Multi-Modal Learning with Large-Scale Pre-Trained Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5447 | BOT: Bootstrapped Optimal Transport for Multi-label Noise Learning | 4.25 | 3.75 | 1.30 | -0.50 | |
| 5448 | DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5449 | Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study with Linear Models | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5450 | Understanding the Approximation Gap of Neural Networks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5451 | Less is More: Toward Zero-Shot Local Scene Graph Generation via Foundation Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5452 | Hindsight-DICE: Stable Credit Assignment for Deep Reinforcement Learning | 4.25 | 4.25 | 1.92 | 0.00 | |
| 5453 | Episodic Memory Theory for the Mechanistic Interpretation of Recurrent Neural Networks | 3.75 | 4.25 | 1.92 | 0.50 | |
| 5454 | A Differentiable Sequence Model Perspective on Policy Gradients | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5455 | Make Small Data Great Again: Learning from Partially Annotated Data via Policy Gradient for Multi-Label Classification Tasks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5456 | SEE-OoD: Supervised Exploration for Enhanced Out-of-Distribution Detection | 4.75 | 4.25 | 2.17 | -0.50 | |
| 5457 | Comfetch: Federated Learning of Large Networks on Constrained Clients via Sketching | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5458 | Your CLIP Model Might Be Undertrained | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5459 | Towards Explaining Deep Neural Network Compression Through a Probabilistic Latent Space | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5460 | Advancing Vision Transformers with Group-Mix Attention | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5461 | Emergent Robust Communication for Multi-Round Interactions in Noisy Environments | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5462 | IMAST: Importance-Aware Statistical Test for Transformer Interpretability Evaluation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5463 | A Simple Open-Loop Baseline for Reinforcement Learning Locomotion Tasks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5464 | Vicinal Assessment of Model Generalization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5465 | Neural Priority Queues for Graph Neural Networks (GNNs) | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5466 | Physics-informed neural networks with unknown measurement noise | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5467 | Recovery of Training Data from Overparameterized Autoencoders: An Inverse Problem Perspective | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5468 | Multi-interest Disentangled Representation Learning for Multimodal Recommendation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5469 | Noises are Transferable - An Empirical Study on Heterogeneous Domain Adaptation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5470 | Beyond the Benchmark: Detecting Diverse Anomalies in Videos | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5471 | SELF-TAILORING PROMPTS FOR PARAMETER EFFICIENT TUNING SPEECH RECOGNITION | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5472 | SUBER: An RL Environment with Simulated Human Behavior for Recommender Systems | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5473 | CLIP Facial Expression Recognition: Balancing Precision and Generalization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5474 | Convolution on Your 12× Wide Feature: A ConvNet with Nested Design | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5475 | GETMusic: Generating Music Tracks with a Unified Representation and Diffusion Framework | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5476 | Evaluating graph generative models with graph kernels: what structural characteristics are captured? | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5477 | FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5478 | Maximizing Benefits under Harm Constraints: A Generalized Linear Contextual Bandit Approach | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5479 | Overcoming both Domain Shift and Label Shift for Referring Video Segmentation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5480 | FedBug: A Bottom-Up Gradual Unfreezing Framework for Federated Learning With Client Drift | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5481 | Learning Graph Representations in Normed Spaces | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5482 | PagFormer: Polar Accumulator Grid Integrated into Transformers for Medical Image Segmentation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5483 | FiLM: Fill-in Language Models for Any-Order Generation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5484 | Training Neural Networks from Scratch with Parallel Low-Rank Adapters | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5485 | MOTSC: Model-based Offline Traffic Signal Control | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5486 | Understanding Pathologies of Deep Heteroskedastic Regression | 4.25 | 4.25 | 2.59 | 0.00 | |
| 5487 | QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5488 | Grounding Everything: Emerging Localization Properties in Vision-Language Transformers | 4.25 | 4.25 | 1.92 | 0.00 | |
| 5489 | Infinitely Deep Residual Networks: Unveiling Wide Neural ODEs as Gaussian Processes | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5490 | On robust overfitting: adversarial training induced distribution matters | 4.25 | 4.75 | 2.05 | 0.50 | |
| 5491 | Breaking Physical and Linguistic Borders: Multilingual Federated Prompt Tuning for Low-Resource Languages | 4.75 | 4.25 | 2.59 | -0.50 | |
| 5492 | NeRT: Implicit Neural Representation for Time Series | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5493 | Context-Aware Unsupervised Domain Adaptive Lane Detection | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5494 | Fine-grained Separation of Action-Background for Point-Level Temporal Action Localization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5495 | Easing Non-IID Pain with Dual Relaxations in Federated Learning: SimFAFL redeems an enhanced efficacy | 4.67 | 4.25 | 1.30 | -0.42 | |
| 5496 | ViTKD: Feature-based Knowledge Distillation for Vision Transformers | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5497 | Detecting Change Points in Time Series via Curvatures of Representation Trajectories | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5498 | ASPEST: Bridging the Gap Between Active Learning and Selective Prediction | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5499 | Physics-Guided Learning of Meteorological Dynamics for Weather Forecasting and Downscaling | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5500 | Local Superior Soups: A Catalyst for Reducing Communication Rounds in Federated Learning with Pre-trained Model | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5501 | From Fake to Real: Pretraining on Balanced Synthetic Images to Prevent Bias | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5502 | Towards Environmental Robustness in Deep Reinforcement Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5503 | On the Positive Definiteness of the Neural Tangent Kernel | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5504 | Understanding Calibration Transfer in Knowledge Distillation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5505 | AdaProj: Adaptively Scaled Angular Margin Subspace Projections for Anomaly Detection with Auxiliary Classification Tasks | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5506 | PRD: Peer Rank and Discussion Improve Large Language Model based Evaluations | 3.75 | 4.25 | 1.92 | 0.50 | |
| 5507 | LLM-Oriented Retrieval Tuner | 4.25 | 4.75 | 1.09 | 0.50 | |
| 5508 | Debias the Training of Diffusion Models | 4.75 | 4.25 | 2.59 | -0.50 | |
| 5509 | Towards Personalized AI: Early-stopping Low-Rank Adaptation of Foundation Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5510 | Rethinking Effectiveness of Unsupervised Domain Adaptation Methods | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5511 | Accelerating Retrieval-augmented Language Model Serving with Speculation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5512 | Predicate-Argument Relations in the Human Brain | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5513 | Aligning Persistent Homology with Graph Pooling | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5514 | Arithmetic with Language Models: from Memorization to Computation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5515 | Towards Complex-query Referring Image Segmentation: A Novel Benchmark | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5516 | Characterizing Robust Overfitting in Adversarial Training via Cross-Class Features | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5517 | Dataset Distillation in Latent Space | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5518 | Reason for Future, Act for Now: A Principled Architecture for Autonomous LLM Agents | 3.50 | 4.75 | 1.09 | 1.25 | |
| 5519 | LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5520 | Learning Identifiable Causal Structures with Pairwise Representation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5521 | Knowledge Fusion by Evolving Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5522 | ComSD: Balancing Behavioral Quality and Diversity in Unsupervised Skill Discovery | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5523 | Text-Driven Image Editing using Cycle-Consistency-Driven Metric Learning | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5524 | α-Rank: Unified Item-Fair Ranking from A Cooperative Game Theory View | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5525 | Toward Open-ended Embodied Tasks Solving | 4.50 | 4.25 | 1.30 | -0.25 | |
| 5526 | PROSPECT: Learn MLPs Robust against Graph Adversarial Structure Attacks | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5527 | State-drive Implicit Modeling | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5528 | SSIF: Learning Continuous Image Representation for Spatial-Spectral Super-Resolution | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5529 | Deep Neural Room Acoustics Primitive | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5530 | DISPEL: Domain Generalization via Domain-Specific Liberating | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5531 | SPFQ: A Stochastic Algorithm and Its Error Analysis for Neural Network Quantization | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5532 | Planning with an Ensemble of World Models | 4.25 | 4.25 | 2.17 | 0.00 | |
| 5533 | 3D-GPT: Procedural 3D Modeling with Large Language Models | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5534 | Representing part-whole hierarchy with coordinated synchrony in neural networks | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5535 | Zero-Shot Video Sampling from Image | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5536 | Provably Efficient Learning in Partially Observable Contextual Bandit | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5537 | TreeDQN: Learning to minimize Branch-and-Bound tree | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5538 | Multi-Instance Learning Based Anomaly Detection Method for Sequence Data with Application to the Credit Card Delinquency Risk Control | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5539 | Perceptual Metrics for Video Game Playstyle Similarity and Diversity | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5540 | Bridging ML and algorithms: comparison of hyperbolic embeddings | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5541 | Challenging the Foundations: Mining Hard Test Samples through Diffusion Generation | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5542 | Going Further: Flatness at the Rescue of Early Stopping for Adversarial Example Transferability | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5543 | Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention | 4.25 | 4.25 | 1.30 | 0.00 | |
| 5544 | Contrastive Predict-and-Search for Mixed Integer Linear Programs | 3.50 | 4.25 | 1.30 | 0.75 | |
| 5545 | OrthCaps: An Orthogonal CapsNet with Sparse Attention Routing and Pruning | 4.20 | 4.20 | 1.94 | 0.00 | | 5, 6, 6, 1, 3 | | 5, 6, 6, 1, 3 |
|
| 5546 | Uncovering Causal Variables in Transformers Using Circuit Probing | 4.20 | 4.20 | 1.94 | 0.00 | | 6, 3, 6, 1, 5 | | 6, 3, 6, 1, 5 |
|
| 5547 | Can LLMs Effectively Leverage Graph Structural Information: When and Why | 4.20 | 4.20 | 1.47 | 0.00 | | 3, 3, 3, 6, 6 | | 3, 3, 3, 6, 6 |
|
| 5548 | Why Do We Need Weight Decay in Modern Deep Learning? | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 5, 5 |
|
| 5549 | Lyfe Agents: generative agents for low-cost real-time social interactions | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 3, 5, 5 | | 3, 5, 3, 5, 5 |
|
| 5550 | Closing the gap on tabular data with Fourier and Implicit Categorical Features | 4.40 | 4.20 | 0.98 | -0.20 | | 6, 3, 5, 3, 5 | | 5, 3, 5, 3, 5 |
|
| 5551 | Recent Link Classification on Temporal Graphs Using Profile Builder | 4.20 | 4.20 | 1.60 | 0.00 | | 1, 5, 5, 5, 5 | | 1, 5, 5, 5, 5 |
|
| 5552 | Quantile-Free Regression: A Flexible Alternative to Quantile Regression | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 5, 5 |
|
| 5553 | Efficient and scalable reinforcement learning via hypermodel | 5.00 | 4.20 | 1.47 | -0.80 | | 10, 3, 6, 3, 3 | | 6, 3, 6, 3, 3 |
|
| 5554 | Towards Robust 3D Pose Transfer with Adversarial Learning | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 3, 5, 3, 5 | | 5, 3, 5, 3, 5 |
|
| 5555 | Grokking Tickets: Lottery Tickets Accelerate Grokking | 4.25 | 4.20 | 1.47 | -0.05 | |
| 5556 | Saliency-Guided Hidden Associative Replay for Continual Learning | 4.20 | 3.60 | 1.20 | -0.60 | | 3, 6, 3, 3, 6 | | 3, 3, 3, 3, 6 |
|
| 5557 | Systolic Array Acceleration of Spiking Neural Networks with Application-Independent Split-Time Temporal Coding | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 5, 5, 3, 3 | | 5, 5, 5, 3, 3 |
|
| 5558 | SiGeo: Sub-One-Shot NAS via Information Theory and Geometry of Loss Landscape | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 5, 3, 3, 5 | | 5, 5, 3, 3, 5 |
|
| 5559 | Computing high-dimensional optimal transport by flow neural networks | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 5, 5 |
|
| 5560 | EduGym: An Environment Suite for Reinforcement Learning Education | 4.00 | 4.20 | 1.47 | 0.20 | | 6, 3, 5, 3, 3 | | 6, 3, 6, 3, 3 |
|
| 5561 | Attacking Graph Neural Networks with Bit Flips: Weisfeiler and Lehman Go Indifferent | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 5, 5 |
|
| 5562 | Unified Mirror Descent: Towards a Big Unification of Decision Making | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 5, 3, 5 | | 3, 5, 5, 3, 5 |
|
| 5563 | AugUndo: Scaling Up Augmentations for Unsupervised Depth Completion | 4.20 | 4.20 | 1.47 | 0.00 | | 6, 6, 3, 3, 3 | | 6, 6, 3, 3, 3 |
|
| 5564 | InfoScissors: Defense against Data Leakage in Collaborative Inference through the Lens of Mutual Information | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 3, 5, 5, 5 | | 3, 3, 5, 5, 5 |
|
| 5565 | Reverse Chain: A Generic Rule for LLMs to Master Multi-API Planning | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 3, 5, 5 | | 3, 5, 3, 5, 5 |
|
| 5566 | PRISM: Privacy-Preserving Improved Stochastic Masking For Federated Generative Models | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 5, 3, 5 | | 3, 5, 5, 3, 5 |
|
| 5567 | Fast Unsupervised Deep Outlier Model Selection with Hypernetworks | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 5, 5, 3 | | 3, 5, 5, 5, 3 |
|
| 5568 | Adversarial Learning of Decomposed Representations for Treatment Effect Estimation | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 5, 5, 3 | | 3, 5, 5, 5, 3 |
|
| 5569 | Big Learning Variational Auto-Encoders | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 5, 5, 3 | | 3, 5, 5, 5, 3 |
|
| 5570 | NeuralMatrix: Compute the Entire Neural Networks with Linear Matrix Operations for Efficient Inference | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 5, 3, 5, 3 | | 5, 5, 3, 5, 3 |
|
| 5571 | GSINA: Improving Graph Invariant Learning via Graph Sinkhorn Attention | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 5, 3, 3, 5 | | 5, 5, 3, 3, 5 |
|
| 5572 | Robust Video Perception by Seeing Motion | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 5, 5 |
|
| 5573 | Generating Less Certain Adversarial Examples Improves Robust Generalization | 4.20 | 4.20 | 0.98 | 0.00 | | 5, 5, 5, 3, 3 | | 5, 5, 5, 3, 3 |
|
| 5574 | Collaborative World Models: An Online-Offline Transfer RL Approach | 4.20 | 4.40 | 1.20 | 0.20 | | 5, 3, 3, 5, 5 | | 5, 3, 3, 6, 5 |
|
| 5575 | One-shot Federated Learning with Training-Free Client | 4.20 | 4.20 | 0.98 | 0.00 | | 3, 5, 3, 5, 5 | | 3, 5, 3, 5, 5 |
|
| 5576 | MULTISCALE ATTENTION VIA WAVELET NEURAL OPERATORS FOR VISION TRANSFORMER | 4.20 | 4.20 | 1.47 | 0.00 | | 3, 3, 6, 3, 6 | | 3, 3, 6, 3, 6 |
|
| 5577 | Robustness Evaluation Using Local Substitute Networks | 4.17 | 4.17 | 1.86 | 0.00 | | 3, 3, 8, 3, 5, 3 | | 3, 3, 8, 3, 5, 3 |
|
| 5578 | WaveFluid: A New Adversarial Approach for Efficient High-Fidelity Speech Synthesis | 4.17 | 4.17 | 1.21 | 0.00 | | 3, 5, 6, 3, 5, 3 | | 3, 5, 6, 3, 5, 3 |
|
| 5579 | Diffusion Random Feature Model | 4.17 | 4.17 | 1.21 | 0.00 | | 5, 3, 3, 6, 3, 5 | | 5, 3, 3, 6, 3, 5 |
|
| 5580 | Bilevel Optimization without Lower-Level Strong Convexity from the Hyper-Objective Perspective | 4.17 | 4.17 | 1.21 | 0.00 | | 5, 6, 3, 3, 5, 3 | | 5, 6, 3, 3, 5, 3 |
|
| 5581 | On the Paradox of Generalizable Logical Reasoning in Large Language Models | 4.17 | 4.17 | 1.21 | 0.00 | | 3, 5, 6, 5, 3, 3 | | 3, 5, 6, 5, 3, 3 |
|
| 5582 | FR-NAS: Forward-and-Reverse Graph Predictor for Efficient Neural Architecture Search | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5583 | PEACH: Pretrained-embedding Explanation Across Contextual and Hierarchical Structure | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5584 | UBERT: Unsupervised adaptive early exits in BERT | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5585 | LatentCBF: A Control Barrier Function in Latent Space for Safe Control | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5586 | Harnessing Text to Image Diffusion for Dense Prediction Tasks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5587 | BEV-CLIP: Multi-modal BEV Retrieval Methodology for Complex Scene in Autonomous Driving | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5588 | Neuron to Graph: Interpreting Language Model Neurons at Scale | 4.00 | 4.00 | 1.79 | 0.00 | | 6, 5, 1, 3, 5 | | 6, 5, 1, 3, 5 |
|
| 5589 | FEATHER: Lifelong Test-Time Adaptation with Lightweight Adapters | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5590 | Adjustable Quantile-Guided Diffusion Policy for Diverse Behavior Generation in Offline RL | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5591 | Prompt Optimization via Adversarial In-Context Learning | 3.67 | 4.67 | 1.25 | 1.00 | |
| 5592 | Rethinking Actor-Critic: Successive Actors for Critic Maximization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5593 | Generative Models are Self-Watermarked: Intellectual Property Declaration through Re-Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5594 | CodeComplex: A Time-complexity Dataset for Multi-language Source Codes | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5595 | Sensitivity-Aware Differentially Private Decentralized Learning with Adaptive Noise | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 3, 6, 5 | | 3, 3, 3, 6, 5 |
|
| 5596 | ProteinAdapter: Adapting Pre-trained Large Protein Models for Efficient Protein Representation Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5597 | LLM+A: Grounding Large Language Models in Physical World with Affordance Prompting | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5598 | FHA-Kitchens: A Novel Dataset for Fine-Grained Hand Action Recognition in Kitchen Scenes | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5599 | A Convergent Federated Clustering Algorithm without Initial Condition | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5600 | DreamFuser: Value-guided Diffusion Policy for Offline Reinforcement Learning | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5601 | Implicit Neural Representation Image Codec with Mixed Context for Fast Decoding | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5602 | Meta Compression: Learning to compress Deep Neural Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5603 | Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5604 | Multi-Scale Generative Modeling in Wavelet Domain | 4.00 | 4.00 | 2.94 | 0.00 | |
| 5605 | Investigating the Fairness of Large Language Models for Predictions on Tabular Data | 4.00 | 4.00 | 1.00 | 0.00 | | 3, 3, 3, 5, 5, 5 | | 3, 3, 3, 5, 5, 5 |
|
| 5606 | High variance score function estimates help diffusion models generalize | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5607 | Transformer-Based Large Language Models Are Not General Learners: A Universal Circuit Perspective | 4.00 | 4.00 | 1.79 | 0.00 | | 5, 5, 3, 6, 1 | | 5, 5, 3, 6, 1 |
|
| 5608 | CT++: Complementary Co-Training for Semi-Supervised Semantic Segmentation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5609 | EMP-SSL: Towards Self-Supervised Learning in One Training Epoch | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5610 | Local-Forward: Towards Biological Plausibility in Deep Reinforcement Learning | 3.33 | 5.00 | 1.41 | 1.67 | |
| 5611 | Multiple Modes for Continual Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5612 | Flashback: Understanding and Mitigating Forgetting in Federated Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5613 | Learning Latent Structural Causal Models | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5614 | A graph transformer for symbolic regression | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5615 | Dynamic Representation of Optimal Transport via Ensemble Systems | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5616 | FORKS: Fast Second-Order Online Kernel Learning using Incremental Sketching | 4.00 | 4.00 | 1.79 | 0.00 | | 5, 6, 1, 5, 3 | | 5, 6, 1, 5, 3 |
|
| 5617 | In-context Curriculum for Mathematical Reasoning in Small Language Models | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 3, 6, 5 | | 3, 3, 3, 6, 5 |
|
| 5618 | Efficient Multi-task Reinforcement Learning via Selective Behavior Sharing | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5619 | End-to-end Story Plot Generator | 4.33 | 4.00 | 2.16 | -0.33 | |
| 5620 | Llamas Know What GPTs Don't Show: Surrogate Models for Selective Classification | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5621 | Efficient Model-Agnostic Multi-Group Equivariant Networks | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5622 | Estimating uncertainty from feed-forward network based sensing using quasilinear approximation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5623 | Understanding Your Agent: Leveraging Large Language Models for Behavior Explanation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5624 | Revisitng graph neural networks for traffic forecasting | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5625 | Learning Multi-Agent Communication using Regularized Attention Messages | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5626 | Contrastive Post-training Large Language Models on Data Curriculum | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5627 | Learning to Reach Goals via Diffusion | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5628 | Absolute Policy Optimization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5629 | VideoDirectorGPT: Consistent Multi-Scene Video Generation via LLM-Guided Planning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5630 | Out-of-domain Fact Checking | 4.67 | 4.00 | 1.41 | -0.67 | |
| 5631 | Battle of the Wordsmiths: Comparing ChatGPT, GPT-4, Claude, and Bard | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5632 | Video2Demo: Grounding Videos in State-Action Demonstrations | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5633 | GLASU: A Communication-Efficient Algorithm for Federated Learning with Vertically Distributed Graph Data | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5634 | Constraining Non-Negative Matrix Factorization to Improve Signature Learning | 3.67 | 4.00 | 1.41 | 0.33 | |
| 5635 | GOODFIT: A Deep Learning Optimizer Fine Tuned for Fine Tuning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5636 | RePLan: Robotic Replanning with Perception and Language Models | 3.50 | 4.25 | 1.30 | 0.75 | |
| 5637 | Consensus Optimization at Representation: Improving Personalized Federated Learning via Data-Centric Regularization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5638 | SAFHE: Defending Against Backdoor and Gradient Inversion Attacks in Federated Learning | 4.33 | 4.00 | 2.16 | -0.33 | |
| 5639 | Generation, Reconstruction, Representation All-in-One: A Joint Autoencoding Diffusion Model | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5640 | Composite Backdoor Attacks Against Large Language Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5641 | Identifying Drivers of Predictive Uncertainty using Variance Feature Attribution | 4.00 | 4.00 | 3.08 | 0.00 | |
| 5642 | CycleAlign: Iterative Distillation from Black-box LLM to White-box Models for Better Human Alignment | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5643 | Enhancing Group Fairness in Federated Learning through Personalization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5644 | Understanding the Theoretical Generalization Performance of Federated Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5645 | A Simple and Efficient Baseline for Data Attribution on Images | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5646 | Two-Stage Diffusion Models: Better Image Synthesis by Explicitly Modeling Semantics | 4.67 | 4.00 | 1.41 | -0.67 | |
| 5647 | Robust Policy Optimization with Evolutionary Techniques | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5648 | From Local Explainability to Global Robustness: Improving the Robustness of Machine Learning Models Using Counterfactual Explanations | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5649 | Backdoor Attack for Federated Learning with Fake Clients | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5650 | Corrupting Unbounded Unlearnable Datasets with Pixel-based Image Transformations | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5651 | The common Stability Mechanism behind most Self-Supervised Learning Approaches | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5652 | Towards Dynamic EHR Phenotyping: A Generative Clustering Model | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5653 | A Generative Model for Game Theory with Flow Equilibrium | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5654 | Prompt-aware Adapter: Towards Learning Effective Visual Tokens for GPT4-Style Multimodal Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5655 | How Hard is Trojan Detection in DNNs? Fooling Detectors With Evasive Trojans | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5656 | RetroTune: Mitigating spurious features via retrospective fine-tuning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5657 | Iteratively Refined Behavior Regularization for Offline Reinforcement Learning | 3.67 | 4.00 | 1.41 | 0.33 | |
| 5658 | MorphOcc: An Implicit Generative Model of Neuronal Morphologies | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5659 | Boosting Reinforcement Learning with Extremum Experiences | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5660 | Causal-based Analysis on Credibility of Feedforward Neural Network | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5661 | WHICH RESTRAINS FEW-SHOT CLASS-INCREMENTAL LEARNING, FORGETTING OR FEW-SHOT LEARNING? | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5662 | Linguistic Image Understanding | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5663 | Towards Plastic and Stable Exemplar-Free Incremental Learning: A Dual-Learner Framework with Cumulative Parameter Averaging | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5664 | Quality Control at Your Fingertips: Quality-Aware Translation Models | 4.67 | 4.00 | 1.41 | -0.67 | |
| 5665 | Streamlining Generative Models for Structure-Based Drug Design | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5666 | StyleDreamer: Make Your 3D Style Avatar from a Single View with Consistency Score Distillation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5667 | VQ-CAD: Computer-Aided Design Model Generation with Vector Quantized Diffusion | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5668 | Violence Detection and Localization in Video Through Subgroup Analysis | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5669 | Global Optimality for Non-linear Constrained Restoration Problems via Invexity | 4.00 | 4.67 | 1.25 | 0.67 | |
| 5670 | Ghost in the Minecraft: Hierarchical Agents for Minecraft via Large Language Models with Text-based Knowledge and Memory | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5671 | BENCHMARKING SEQUENTIAL VISUAL INPUT REASONING AND PREDICTION IN MULTIMODAL LARGE LANGUAGE MODELS | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5672 | Deep concept removal | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5673 | DeepEMD: A Transformer-based Fast Estimation of the Earth Mover’s Distance | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5674 | Revisiting Ternary Neural Networks towards Asymmetric Thresholds and Uniform Distribution | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5675 | Meta-Learning Nonlinear Dynamical Systems with Deep Kernels | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5676 | Exploring High-Order Message-Passing in Graph Transformers | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5677 | Twinned Interventional Flows | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5678 | Prompt Backdoors in Visual Prompt Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5679 | Constructing Sparse Neural Architecture with Deterministic Ramanujan Graphs | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5680 | Domain Feature Perturbation for Domain Generalization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5681 | Prometheus: Inducing Evaluation Capability in Language Models | 4.00 | 4.00 | 2.16 | 0.00 | |
| 5682 | NOISY MULTI-VIEW CONTRASTIVE LEARNING FRAMEWORK FOR ENHANCING TOP-K RECOMMENDATION | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5683 | Forked Diffusion for Conditional Graph Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5684 | On the Generalization of Gradient-based Neural Network Interpretations | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5685 | 3D Dense Captioning beyond Nouns: A Middleware for Autonomous Driving | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5686 | Capturing The Channel Dependency Completely Via Knowledge-Episodic Memory For Time Series Forecasting | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5687 | Memory-efficient particle filter recurrent neural network for object localization | 4.00 | 4.00 | 2.94 | 0.00 | |
| 5688 | $beta$-DQN: Diverse Exploration via Learning a Behavior Function | 4.00 | 4.00 | 1.26 | 0.00 | | 6, 5, 3, 3, 3 | | 6, 5, 3, 3, 3 |
|
| 5689 | Calibration Attack: A Framework For Adversarial Attacks Targeting Calibration | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5690 | NAP2: Neural Networks Hyperparameter Optimization Using Weights and Gradients Analysis | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5691 | TKG-LM: Temporal Knowledge Graph Extrapolation Enhanced by Language Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5692 | Generating Robot Policy Code for High-Precision and Contact-Rich Manipulation Tasks | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5693 | Skill Reinforcement Learning and Planning for Open-World Long-Horizon Tasks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5694 | RetPur: Diffusion Purification Model for Defending Hash Retrieval Target Attacks | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5695 | E(3) Equivariant Scalar Interaction Network | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5696 | A Causal Ordering Prior for Unsupervised Representation Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5697 | S$^6$-DAMON: Unlocking Structured Sparsity in Self-Supervised Speech Models via Data-Model Co-Compression | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5698 | Quality Diversity through Human Feedback | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5699 | Perceptual Context and Sensitivity in Image Quality Assessment: A Human-Centric Approach | 4.00 | 4.00 | 1.79 | 0.00 | | 1, 3, 6, 5, 5 | | 1, 3, 6, 5, 5 |
|
| 5700 | Automatic Hallucination Assessment for Aligned Large Language Models via Transferable Adversarial Attacks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5701 | Representation-space diffusion models for generating periodic materials | 4.00 | 4.60 | 1.36 | 0.60 | | 3, 5, 6, 3, 3 | | 3, 5, 6, 3, 6 |
|
| 5702 | A Geometric Analysis of Multi-label Learning under Pick-all-label Loss via Neural Collapse | 4.50 | 4.00 | 1.41 | -0.50 | |
| 5703 | DLCNet: Enabling Long-Range Convolution with Data Dependency | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5704 | Evade ChatGPT Detectors via A Single Space | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5705 | Complex Logical Reasoning over Knowledge Graphs using Large Language Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5706 | GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5707 | Delayed Local-SGD for Distributed Learning with Linear Speedup | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5708 | Mobile Object Rearrangement with Learned Localization Uncertainty | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5709 | Online Continual Learning via Pursuing Class-conditional Funtion | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5710 | Continual Traffic Forecasting via Mixture of Experts | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5711 | One Training Fits All: Addressing Model-Heterogeneity Federated Learning via Architecture Probing | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5712 | Distribution Calibration For Few-Shot Learning by Bayesian Relation Inference | 4.00 | 4.33 | 0.94 | 0.33 | |
| 5713 | Counterfactual Fairness With the Human in the Loop | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5714 | Towards Greener and Sustainable Airside Operations: A Deep Reinforcement Learning Approach to Pushback Rate Control for Mixed-Mode Runways | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5715 | An Invex Relaxation Approach for Minimizing Polarization from Fully and Partially Observed Initial Opinions | 4.00 | 4.00 | 2.94 | 0.00 | |
| 5716 | Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection | 4.00 | 4.75 | 2.05 | 0.75 | |
| 5717 | Beyond Scale: the Diversity Coefficient as a Data Quality Metric Demonstrates LLMs are Pre-trained on Formally Diverse Data | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5718 | Learning Conditional Policy for Crystal Design using Offline Reinforcement Learning | 4.50 | 4.00 | 1.00 | -0.50 | |
| 5719 | DEBOSH: Deep Bayesian Shape Optimization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5720 | Approximate Clustering for Extracting Task Relationships in Multi-Instruction Tuning | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5721 | Taming AI Bots: Controllability of Neural States in Large Language Models | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5722 | AUTOMATIC NEURAL SPATIAL INTEGRATION | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5723 | OpenLEAF: Open-Domain Interleaved Image-Text Generation and Evaluation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5724 | On the Effectiveness of One-Shot Federated Ensembles in Heterogeneous Cross-Silo Settings | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5725 | Variance-Covariance Regularization Improves Representation Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5726 | Rapid Learning without Catastrophic Forgetting in the Morris Water Maze | 4.00 | 5.00 | 1.22 | 1.00 | |
| 5727 | Fairness Under Demographic Scarce Regime | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5728 | Encoding Ontologies with Holographic Reduced Representations for Transformers | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5729 | ON TRAINING DERIVATIVE-CONSTRAINED NEURAL NETWORKS | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5730 | FedPnP:A Plug and Play Approach For Personalized Graph-Structured Federated Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5731 | HHD-Ethiopic: A Historical Handwritten Dataset for Ethiopic OCR with Baseline Models and Human-level Performance | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5732 | E$^{2}$GAN: Efficient Training of Efficient GANs for Image-to-Image Translation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5733 | Improved DDIM Sampling with Moment Matching Gaussian Mixtures | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5734 | Evaluating and Improving Generation Consistency of Large Language Models via A Divide-Conquer-Reasoning Approach | 3.67 | 4.67 | 1.25 | 1.00 | |
| 5735 | $sigma$-PCA: a unified neural model for linear and nonlinear principal component analysis | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5736 | Stream: A Generalized Continual Learning Benchmark and Baseline | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5737 | Correct-by-design Safety Critics using Non-contractive Binary Bellman Operators | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5738 | Diversity-aware Continual Learning with Latent Knowledge Hypergraph | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5739 | Compositional Generalization in Multimodal Foundation Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5740 | HeroLT: Benchmarking Heterogeneous Long-Tailed Learning | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5741 | CoNO: Complex Neural Operator for Continuous Dynamical Systems | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5742 | ReLU for Inference Acceleration | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5743 | DISCRET: a self-interpretable framework for treatment effect estimation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5744 | Towards Exact Computation of Inductive Bias | 4.50 | 4.00 | 1.00 | -0.50 | |
| 5745 | Castor: Causal Temporal Regime Structure Learning | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5746 | ERM++: An Improved Baseline for Domain Generalization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5747 | Dataset Fairness: Achievable Fairness On Your Data With Utility Guarantees | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5748 | Reinforcement Learning with Partial Order Representation for Monotonic Physical System | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5749 | Structured Packing in LLM Training Improves Long Context Utilization | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5750 | Large Language Models as Gaming Agents | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5751 | Policy Learning For Video Streaming | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5752 | EXCOST: Semi-Supervised Classification with Exemplar-Contrastive Self-Training | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5753 | Identifying Interpretable Features in Convolutional Neural Networks | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5754 | Segment, Select, Correct: A Framework for Weakly-Supervised Referring Segmentation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5755 | Aligning Agents like Large Language Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5756 | FedEve: On Bridging the Client Drift and Period Drift for Cross-device Federated Learning | 4.50 | 4.00 | 1.41 | -0.50 | |
| 5757 | FTFT: efficient and robust Fine-Tuning by transFerring Training dynamics | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5758 | Model-Based Transfer RL with Task-Agnostic Offline Pretraining | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5759 | Learning Team-Level Information Integration in Multi-Agent Communication | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5760 | ODEdit: Blind Face Restoration through Ordinary Differential Equations | 4.50 | 4.00 | 1.00 | -0.50 | |
| 5761 | Protecting Sensitive Data through Federated Co-Training | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5762 | SINGLE-IMAGE COHERENT RECONSTRUCTION OF OBJECTS AND HUMANS | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5763 | Revisiting the Static Model in Robust Reinforcement Learning | 3.67 | 4.00 | 1.00 | 0.33 | |
| 5764 | Objectives Are All You Need: Solving Deceptive Problems Without Explicit Diversity Maintenance | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5765 | TopoFormer: Topology-aware Transformer for Reactive Motion Prediction in Close Interactions | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5766 | Exploiting Implicit Rigidity Constraints via Weight-Sharing Aggregation for Scene Flow Estimation from Point Clouds | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5767 | Spike Accumulation Forwarding for Effective Training of Spiking Neural Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5768 | Zero-shot Cross-task Preference Alignment for Offline RL via Optimal Transport | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5769 | EXPLAIN, AGREE and LEARN: A Recipe for Scalable Neural-Symbolic Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5770 | A Theoretically Grounded Extension of Universal Attacks from the Attacker's Viewpoint | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5771 | PREDICTING ACCURATE LAGRANGIAN MULTIPLIERS FOR MIXED INTEGER LINEAR PROGRAMS | 3.67 | 4.00 | 1.00 | 0.33 | |
| 5772 | A Game Theoretic Approach to Meta-Learning: Nash Model-Agnostic Meta-Learning | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5773 | Adaptive Compression of the Latent Space in Variational Autoencoders | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5774 | GraphAgent: Exploiting Large Language Models for Interpretable Learning on Text-attributed Graphs | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5775 | Lost in Translation: Conceptual Blind Spots in Text-to-Image Diffusion Models | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5776 | Offline Tracking with Object Permanence | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5777 | SOLO: Surrogate Online Learning at Once for Spiking Neural Networks | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5778 | PIANO PERFORMANCE EVALUATION DATASET WITH MULTI-LEVEL PERCEPTUAL FEATURES | 4.00 | 4.00 | 1.41 | 0.00 | | 3, 3, 6, 3, 6, 3 | | 3, 3, 6, 3, 6, 3 |
|
| 5779 | Riemannian Multiclass Logistics Regression for SPD Neural Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5780 | Adam through a Second-Order Lens | 4.50 | 4.00 | 2.12 | -0.50 | |
| 5781 | Causal Inference on Distributional Outcomes under Continuous Treatments | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5782 | Learning Interpretable Characteristic Kernels via Decision Forests | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5783 | LLaMA Rider: Spurring Large Language Models to Explore the Open World | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5784 | Self-supervised debiasing using low rank regularization | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5785 | Abstract Interpretation of ReLU Neural Networks with Optimizable Polynomial Relaxations | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5786 | Solving Continual Offline Reinforcement Learning with Decision Transformer | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5787 | Compensating for Nonlinear Reduction with Linear Computations in Private Inference | 4.00 | 4.00 | 2.16 | 0.00 | |
| 5788 | Spectral Self-supervised Feature Selection | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 6, 5, 3, 3 | | 3, 6, 5, 3, 3 |
|
| 5789 | Personas as a way to Model Truthfulness in Language Models | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5790 | KEFI: Kernel-based Feature Identification for Generalizable Classification | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5791 | DiffSound: Differentiable Modal Sound Simulation for Inverse Reasoning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5792 | Attribute-Guided Diffusion for Unsupervised Few-Shot Font Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5793 | Spectrum-guided Multi-view Graph Fusion | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5794 | TeG-Instruct: Towards Premium Instruction-Tuning Data via Text-Grounded Task Design | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5795 | Finite Sample Analysis for Single-Loop Single-Timescale Natural Actor-Critic Algorithm | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5796 | PointHR: Exploring High-Resolution Architectures for 3D Point Cloud Segmentation | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5797 | DSparsE: Dynamic Sparse Embedding for Knowledge Graph Completion | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5798 | Permutations improve performance in three-dimensional bin packing problem | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5799 | Robust Self-supervised Learning in Heterogeneous Graph Based on Feature-Topology Balancing | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5800 | ContextNER: Contextual Phrase Generation at Scale | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5801 | BeGin: Extensive Benchmark Scenarios and An Easy-to-use Framework for Graph Continual Learning | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5802 | StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5803 | Towards Readable Scalable Vector Graphic Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5804 | Text2NKG: Fine-Grained N-ary Relation Extraction for N-ary relational Knowledge Graph Construction | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5805 | Understanding Vision and Language Representations under the Lens of Intrinsic Dimension | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5806 | PromptCoT: Align Prompt Distribution via Adapted Chain-of-Thought | 4.50 | 4.00 | 1.41 | -0.50 | |
| 5807 | Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation | 4.00 | 4.00 | 2.00 | 0.00 | | 3, 3, 3, 8, 3 | | 3, 3, 3, 8, 3 |
|
| 5808 | Deep Reinforcement Learning from Weak Hierarchical Preference Feedback | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5809 | Learning Spatio-Temporal Representation for Multivariate Time Series | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 6, 5, 3 | | 3, 3, 6, 5, 3 |
|
| 5810 | Functional Geometry Guided Protein Sequence and Backbone Structure Co-Design | 3.00 | 4.00 | 1.41 | 1.00 | |
| 5811 | Exploring Counterfactual Alignment Loss towards Human-Centered AI | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5812 | Finite-Time Analysis of Federated Temporal Difference Learning with Linear Function Approximation under Environment and Computation Heterogeneity | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5813 | Data Curation for Large Scale Detection Pretraining | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5814 | ControlVideo: Conditional Control for Text-driven Video Editing and Beyond | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5815 | Adapting Retrieval Models to Task-Specific Goals using Reinforcement Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5816 | GraphLLM: Boosting Graph Reasoning Ability of Large Language Model | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5817 | BOOT: Data-free Distillation of Denoising Diffusion Models with Bootstrapping | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5818 | Image-driven Video Editing with Latent Diffusion Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5819 | POSITION EMBEDDING INTERPOLATION IS ALL YOU NEED FOR EFFICIENT IMAGE-TO-IMAGE VIT | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5820 | Hierarchical Data-efficient Representation Learning for Tertiary Structure-based RNA Design | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5821 | Source-free Cross-modal Knowledge Transfer by Unleashing the Potential of Task-Irrelevant Data | 4.00 | 4.00 | 1.00 | 0.00 | | 5, 3, 3, 5, 3, 5 | | 5, 3, 3, 5, 3, 5 |
|
| 5822 | Self-Supervision is Not All You Need: In Defense of Semi-Supervised Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5823 | PyTorch Geometric High Order: A Unified Library for High Order Graph Neural Network | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5824 | Balancing Fairness and Accuracy in Data-Restricted Binary Classification | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5825 | Robust Algorithmic Recourse Design Under Model Shifts | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5826 | A Cooperative-Game-Theoretical Model for Ad Hoc Teamwork | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5827 | Making PPO even better: Value-Guided Monte-Carlo Tree Search decoding | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5828 | Cascaded Contrastive Medical Language-Image Pretraining on Radiology Images | 5.25 | 4.00 | 1.00 | -1.25 | |
| 5829 | D^3: Distributional Dataset Distillation with Latent Priors | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5830 | Explainable, Steerable Models with Natural Language Parameters and Constraints | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5831 | Learning to Stylize Soundscapes from In-the-Wild Videos | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5832 | RepoFusion: Training Code Models to Understand Your Repository | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5833 | EvolMPNN: Predicting Mutational Effect on Homologous Proteins by Evolution Encoding | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5834 | Multiobjective Stochastic Linear Bandits under Lexicographic Ordering | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5835 | Automated Search-Space Generation Neural Architecture Search | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5836 | Structured Pruning of CNNs at Initialization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5837 | Grid Cell-Inspired Fragmentation and Recall for Efficient Map Building | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5838 | SynerGPT: In-Context Learning for Personalized Drug Synergy Prediction and Drug Design | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5839 | DisCo: Disentangled Control for Realistic Human Dance Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5840 | Polarity-Aware Semantic Retrieval with Fine-Tuned Sentence Embeddings | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5841 | Sparse Iso-FLOP Transformations for Maximizing Training Efficiency | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5842 | What does GPT store in its MLP weights? A case study of long-range dependencies | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5843 | Two Birds with One Stone: Protecting DNN Models Against Unauthorized Inference and Domain Transfer | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5844 | Exploring Memorization in Fine-tuned Language Models | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5845 | Video Anomaly Detection via Semantic Attributes | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5846 | CRAFT: Cross-Representation modeling on Audio waveForms and specTrograms | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5847 | SelfDreamer: Dual-Prototypical Regularization for Frame-masked Model-based Reinforcement Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5848 | What is a good question? Task-oriented asking with fact-level masking | 3.00 | 4.00 | 1.41 | 1.00 | |
| 5849 | Less is More: Selective Layer Finetuning with SubTuning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5850 | LOQA: Learning with Opponent Q-Learning Awareness | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 6, 3, 5, 3 | | 3, 6, 3, 5, 3 |
|
| 5851 | SocREval: LLMs with the Socratic Method for Reference-free Reasoning Evaluation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5852 | CARSO: Blending Adversarial Training and Purification Improves Adversarial Robustness | 4.50 | 4.00 | 1.73 | -0.50 | |
| 5853 | Towards Certified Probabilistic Robustness with High Accuracy | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5854 | Analysis of a class of stochastic component-wise soft-clipping schemes | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 6, 5, 3 | | 3, 3, 6, 5, 3 |
|
| 5855 | Chat-3D: Data-efficiently Tuning Large Language Model for Universal Dialogue of 3D Scenes | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5856 | SILC: Improving Vision Language Pretraining with Self-Distillation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5857 | Extracting Robust On-Manifold Interactions Encoded by Neural Networks | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5858 | Correlated dense associative memories | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5859 | Learning Time-Varying Convexifications of Multiple Fairness Measures | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5860 | Equivariant Protein Multi-task Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5861 | From Sparse to Dense: Learning to Construct 3D Human Meshes from WiFi | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5862 | Effective Learning by Node Perturbation in Deep Neural Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5863 | Cont-GRU: Fully Continuous Gated Recurrent Units for Irregular Time Series | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5864 | Benchmarking the Robustness of Cross-view Geo-localization Models | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5865 | Energy Calibration Head: A Plug-In Neural Network Head with Human-like Uncertainty | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5866 | Understanding Masked Autoencoders From a Local Contrastive Perspective | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5867 | Smooth Min-Max Monotonic Networks | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5868 | Enhancing Precision Drug Recommendations via Fine-grained Exploration of Motif Relationships | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5869 | SemSA: Semantic Sparse Attention is hidden in Large Language Models. | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5870 | Understanding and addressing spurious correlation via Neural Tangent Kernels: A spectral bias perspective | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5871 | Optimized Large Language Models Accurately Identify Recurrence of VT After Ablation from Complex Medical Notes: Will Chart Review Become Obsolete? | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5872 | Test Time Adaptation with Auxiliary Tasks | 3.67 | 4.67 | 1.25 | 1.00 | |
| 5873 | PointMLLM: Aligning multi-modality with LLM for point cloud understanding, generation and editing | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5874 | How many samples are needed to train a deep-ReLU neural network? | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5875 | Manifold Inspired Graph Contrastive Learning | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 6, 3, 3, 5 | | 3, 6, 3, 3, 5 |
|
| 5876 | Utility-based Adaptive Teaching Strategies using Bayesian Theory of Mind | 4.00 | 4.00 | 1.79 | 0.00 | | 5, 5, 6, 1, 3 | | 5, 5, 6, 1, 3 |
|
| 5877 | Focus on Primary: Differential Diverse Data Augmentation for Generalization in Visual Reinforcement Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5878 | Asymmetrically Decentralized Federated Learning | 3.67 | 4.00 | 1.00 | 0.33 | |
| 5879 | Adaptive-Solver Framework for Dynamic Strategy Selection in Large Language Model Reasoning | 4.00 | 4.25 | 1.30 | 0.25 | |
| 5880 | Improved Generalization of cGAN using Vicinal Estimation and Early Stopping | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5881 | Node Classification in the Heterophilic Regime via Diffusion-Jump GNNs | 4.00 | 4.00 | 2.94 | 0.00 | |
| 5882 | A Trust Region Approach for Few-Shot Sim-to-Real Reinforcement Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5883 | VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis | 3.50 | 4.00 | 1.73 | 0.50 | |
| 5884 | CONTROL: A Contrastive Learning Framework for Open World Semi-Supervised Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5885 | Conformal Normalization in Recurrent Neural Network of Grid Cells | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5886 | Diffusion Models as Strong Adversaries | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5887 | Are We in (A)Sync?: Guidance for Efficient Federated Learning | 3.67 | 4.00 | 1.41 | 0.33 | |
| 5888 | Embed-Search-Align: DNA Sequence Alignment using Transformer models | 3.67 | 4.00 | 1.41 | 0.33 | |
| 5889 | Causal Effect Estimation with Mixed Latent Confounders and Post-treatment Variables | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5890 | Adapting Large Language Models for Content Moderation: Pitfalls in Data Engineering and Supervised Fine-tuning | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5891 | Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5892 | Improving Generalization for Missing Data Imputation via Dual Corruption Denoising Autoencoders | 4.20 | 3.80 | 0.98 | -0.40 | | 3, 3, 3, 6, 6 | | 3, 3, 3, 5, 5 |
|
| 5893 | Rethinking the Polynomial Filter of GNNs via Graph Information Activation Theory | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5894 | A Region-Shrinking-Based Acceleration for Classification-Based Derivative-Free Optimization | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5895 | TCD: TEXT IMAGE CHANGE DETECTION FOR MULTILINGUAL DOCUMENT COMPARISON | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5896 | Learning Communication-Efficient Optimizers | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5897 | LoFT: Local Proxy Fine-tuning Improves Transferability to Large Language Model Attacks | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5898 | Culture in Artificial Intelligence: A Literature Review & Proposal | 4.00 | 4.00 | 2.94 | 0.00 | |
| 5899 | Refined Partitioning Boosts MGDA: Introducing RP-MGDA for Multi-Objective Learning | 4.33 | 4.00 | 1.00 | -0.33 | |
| 5900 | Probabilistic Sampling-Enhanced Temporal-Spatial GCN: A Scalable Framework for Transaction Anomaly Detection in Ethereum Networks | 3.50 | 4.00 | 1.73 | 0.50 | |
| 5901 | EA2N: Evidence-based AMR Attention Network for Fake News Detection | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5902 | Diffusion-based Data Generation for Out-of-Distribution Object Detection | 3.67 | 4.00 | 1.53 | 0.33 | | 1, 3, 5, 5, 3, 5 | | 1, 3, 5, 5, 5, 5 |
|
| 5903 | DiffImpute: Tabular Data Imputation With Denoising Diffusion Probabilistic Model | 3.67 | 4.00 | 1.00 | 0.33 | |
| 5904 | Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models | 4.00 | 4.00 | 1.73 | 0.00 | |
| 5905 | Fooling Contrastive Language-Image Pre-Training with CLIPMasterPrints | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5906 | HawkesVAE: Sequential Patient Event Synthesis for Clinical Trials | 4.25 | 4.00 | 1.00 | -0.25 | |
| 5907 | Generalising Multi-Agent Cooperation through Task-Agnostic Communication | 4.00 | 4.50 | 0.87 | 0.50 | |
| 5908 | EntProp: High Entropy Propagation via Auxiliary Batch Normalization Layers | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5909 | Towards Understanding Neural Collapse: The Effects of Batch Normalization and Weight Decay | 4.00 | 4.50 | 0.87 | 0.50 | |
| 5910 | Formally Specifying the High-Level Behavior of LLM-Based Agents | 4.00 | 4.00 | 1.26 | 0.00 | | 5, 3, 6, 3, 3 | | 5, 3, 6, 3, 3 |
|
| 5911 | XAL: EXplainable Active Learning Makes Classifiers Better Low-resource Learners | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5912 | Individual/Joint Deblurring and Low-Light Image Enhancement in One Go via Unsupervised Deblurring Paradigm | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5913 | Reinforcement Learning with Fine-grained Reward for Controllable Text Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5914 | A Unified Concept-Based System for Local, Global, and Misclassification Explanations | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 3, 5, 6 | | 3, 3, 3, 5, 6 |
|
| 5915 | Branch-level Network Re-parameterization with Neural Substitution | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 6, 5, 3, 3 | | 3, 6, 5, 3, 3 |
|
| 5916 | Cross-domain Few-shot Classification via Invariant-content Feature Reconstruction | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5917 | Language Guided Interpretable Image Recognition via Manifold Alignment | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5918 | LAVITA: Latent Video Diffusion Models with Spatio-temporal Transformers | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5919 | Discovering Mixtures of Structural Causal Models from Time Series Data | 3.67 | 4.00 | 1.00 | 0.33 | |
| 5920 | FutureDD: Planning in POMDP with Encoded Future Dynamics | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5921 | SemanticBoost: Elevating Motion Generation with Augmented Textual Cues | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5922 | Learning the Unlearnable: Adversarial Augmentations Suppress Unlearnable Example Attacks | 4.50 | 4.00 | 2.12 | -0.50 | |
| 5923 | Staleness-based subgraph sampling for large-scale GNNs training | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5924 | Enabling Model Parallelism for Neural Networks Based on Decoupled Supervised Contrastive Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5925 | Graph-level Representation Learning with Joint-Embedding Predictive Architectures | 3.67 | 4.00 | 1.41 | 0.33 | |
| 5926 | Jailbreaking Language Models at Scale via Persona Modulation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5927 | FedLAP-DP: Federated Learning by Sharing Differentially Private Loss Approximations | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5928 | Learning from the Future: Improve Long-term Mesh-based Simulation with Foresight | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5929 | Hierarchical GFlownet for Crystal Structure Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5930 | Wasserstein Distortion: Unifying fidelity and realism | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5931 | Potential Based Diffusion Motion Planning | 3.00 | 4.00 | 1.73 | 1.00 | |
| 5932 | Causal Representation Learning and Inference for Generalizable Cross-Domain Predictions | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5933 | Overcoming Generic Knowledge Loss with Selective Parameter Update | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5934 | REX: Rapid Exploration and eXploitation for AI agents | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5935 | Brain encoding models based on binding multiple modalities across audio, language, and vision | 4.00 | 4.00 | 2.94 | 0.00 | |
| 5936 | E-MCTS: Deep Exploration by Planning with Epistemic Uncertainty | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5937 | Semantic-Guided Consistency and Discrimination for Siamese Representation Learning | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 6, 3, 5, 3 | | 3, 6, 3, 5, 3 |
|
| 5938 | RayE-Sub: Countering Subgraph Degradation via Perfect Reconstruction | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5939 | FedDecay: Adapting to Data Heterogeneity in Federated Learning With Gradient Decay | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5940 | Information-Ordered Bottlenecks for Adaptive Dimensionality Reduction | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5941 | Sparse Training of Discrete Diffusion Models for Graph Generation | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5942 | Sequential Flow Straightening for Generative Modeling | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5943 | NeuroSURF: Neural Uncertainty-aware Robust Surface Reconstruction | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5944 | Reward-Free Exploration by Conditional Divergence Maximization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5945 | On Reconstructability of Graph Neural Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5946 | Efficient Discrete Physics-informed Neural Networks for Solving Evolutionary Partial Differential Equations | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5947 | Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5948 | CAST: Clustering self-Attention using Surrogate Tokens for efficient transformers | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5949 | Meta Domain Reweighting for Partially Known Out-of-Distribution Generalization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5950 | MoleSG: A Multi-Modality Molecular Pre-training Framework by Joint Non-overlapping Masked Reconstruction of SMILES and Graph | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5951 | Cognition-Supervised Learning: Contrasting EEG Signals and Visual Stimuli For Saliency Detection | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5952 | Quantum AdaBoost with Supervised Learning Guarantee | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5953 | ColCLIP: Enhancing Fine-Grained Image Retrieval with Pre-trained Embeddings | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5954 | Learning Forward Compatible Representation in Class Incremental Learning by Increasing Effective Rank | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5955 | Learning Invariant Graph Representations via Virtual Environment Inference | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5956 | FPTQ: FINE-GRAINED POST-TRAINING QUANTIZATION FOR LARGE LANGUAGE MODELS | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5957 | Semantic Decoupled Distillation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5958 | Overcoming Alignment Constraints: G-Patch for Practical Adversarial Attacks on ViTs | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5959 | Bayesian Knowledge Distillation for Online Action Detection | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5960 | Projected Off-Policy Q-Learning (POP-QL) for Stabilizing Offline Reinforcement Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5961 | Modeling Annotation Delay In Continual Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5962 | xMLP: Revolutionizing Private Inference with Exclusive Square Activation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5963 | GSVA: Gradient-Based Sparse Voxel Attacks on Point Cloud Object Detection | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5964 | Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5965 | Adapting Cross-View Localization to New Areas without Ground Truth Positions | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5966 | Set Features for Anomaly Detection | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5967 | R2D2-Net: Shrinking Bayesian Neural Networks via R2D2 Prior | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5968 | P4Q: Learning to Prompt for Quantization in Visual-language Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5969 | fMRI-PTE: A Large-scale fMRI Pretrained Transformer Encoder for Multi-Subject Brain Activity Decoding | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5970 | OTMatch: Improving Semi-Supervised Learning with Optimal Transport | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5971 | Connecting the Patches: Multivariate Long-term Forecasting using Graph and Recurrent Neural Network | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5972 | Associative Transformer is a Sparse Representation Learner | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5973 | UMMAN: UNSUPERVISED MULTI-GRAPH MERGE ADVERSARIAL NETWORK FOR DISEASE PREDICTION BASED ON INTESTINAL FLORA | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5974 | Understanding the Initial Condensation of Convolutional Neural Networks | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5975 | Learning Pseudo 3D Guidance for View-consistent 3D Texturing with 2D Diffusion | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5976 | The Logarithm Trick: achieve better long term forecast via Mean Logarithm Square Loss | 3.50 | 4.00 | 1.00 | 0.50 | |
| 5977 | Localized Linear Temporal Dynamics for Self-supervised Skeleton Action Recognition | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5978 | Reinforcement Learning for Node Selection in Branch-and-Bound | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5979 | Rethinking the Number of Shots in Robust Model-Agnostic Meta-Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5980 | Spade : Training-Free Improvement of Spatial Fidelity in Text-to-Image Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5981 | CEDNet: A Cascade Encoder-Decoder Network for Dense Prediction | 4.33 | 4.00 | 1.00 | -0.33 | |
| 5982 | Bi-directional Deformation for Parameterization of Neural Implicit Surfaces | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5983 | Learning Label Refinement and Thresholds for Imbalanced Semi-Supervised Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5984 | Multi-Task Learning with Hypernetworks and Task Metadata | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5985 | Sequence-Level Certainty Reduces Hallucination In Knowledge-Grounded Dialogue Generation | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5986 | Does GPT-4 have good intuition about functions? | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5987 | Efficient Quantization-aware Training with Adaptive Coreset Selection | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5988 | Pruning-as-Reconstruct: Masked Autoencoders are Efficient Importance Indicators | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5989 | Out of Sight: A Framework for Egocentric Active Speaker Detection | 4.00 | 4.00 | 2.12 | 0.00 | |
| 5990 | Vision-Language Instruction-enhanced Tuning via Parameter-efficient Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5991 | Can Pre-trained Networks Detect Familiar Out-of-Distribution Data? | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5992 | Sparse Labels Node Classification: Unsupervised Learning for Mentoring Supervised Learning in Sparse Label Settings | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5993 | From Cluster Assumption to Graph Convolution: Graph-based Semi-Supervised Learning Revisited | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5994 | Proactive Learning: Search-augmented learning using Pre-trained Models | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5995 | Mini-batch Submodular Maximization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5996 | Tree-as-a-Prompt: Boosting Black-Box Large Language Models on Few-Shot Classification of Tabular Data | 4.00 | 4.00 | 1.41 | 0.00 | |
| 5997 | Revisiting Few-Shot Object Detection using Vision-Language Models | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5998 | Unleashing the Power of Annotation: Enhancing Semi-Supervised Learning through Unsupervised Sample Selection | 4.00 | 4.00 | 1.00 | 0.00 | |
| 5999 | Molecular Conformation Generation via Shifting Scores | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6000 | Diversity, Plausibility, and Difficulty: Dynamic Data-Free Quantization | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6001 | Towards the Vulnerability of Watermarking Artificial Intelligence Generated Content | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6002 | Visualizing the Emergence of Primitive Interactions During the Training of DNNs | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6003 | DeNAV: Decentralized Self-Supervised Learning with a Training Navigator | 3.00 | 4.00 | 1.00 | 1.00 | |
| 6004 | Towards efficient deep spiking neural networks construction with spiking activity based pruning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6005 | Revisiting the Lottery Ticket Hypothesis for Pre-trained Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6006 | Text-driven Editing of 3D Scenes without Retraining | 4.00 | 4.00 | 1.73 | 0.00 | |
| 6007 | Class-Context-Aware Phantom Uncertainty Modeling | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6008 | Deep Metric Tensor Regularized Policy Gradient | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6009 | Long-Term Impacts of Model Retraining with Strategic Feedback | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6010 | Interleaving Multi-Task Neural Architecture Search | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6011 | Mode-Aware Continual Learning for Conditional Generative Adversarial Networks | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6012 | Learning Embodied Vision-Language Programming From Instruction, Exploration, and Environmental Feedback | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6013 | Generative Reinforcement Learning with Transformers | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 5, 6, 3 | | 3, 3, 5, 6, 3 |
|
| 6014 | Boosting Unsupervised Contrastive Learning Using Diffusion-Based Data Augmentation From Scratch | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6015 | Neural Network Diffusion | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6016 | ReweightOOD: Loss Reweighting for Distance-based OOD Detection | 4.00 | 4.00 | 1.26 | 0.00 | | 3, 3, 3, 5, 6 | | 3, 3, 3, 5, 6 |
|
| 6017 | Neural Manifold Operators for Learning the Evolution of Physical Dynamics | 4.20 | 4.00 | 2.37 | -0.20 | | 8, 3, 6, 3, 1 | | 8, 3, 5, 3, 1 |
|
| 6018 | The Pitfalls and Promise of Conformal Inference Under Adversarial Attacks | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6019 | Masked Autoencoders Are Robust Neural Architecture Search Learners | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6020 | Accelerated Inference and Reduced Forgetting: The Dual Benefits of Early-Exit Networks in Continual Learning | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6021 | Explicit Personalization and Local Training: Double Communication Acceleration in Federated Learning | 4.00 | 4.00 | 1.41 | 0.00 | |
| 6022 | A Simple Unified Uncertainty-Guided Framework for Offline-to-Online Reinforcement Learning | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6023 | PICL: Incorporating Coarse-Grained Data and Physics Information for Superior Physical Systems Modeling | 3.50 | 4.00 | 1.00 | 0.50 | |
| 6024 | Mastering Pixel-Based Reinforcement Learning via Positive Unlabeled Policy-Guided Contrast | 4.00 | 4.00 | 1.73 | 0.00 | |
| 6025 | Benchmarking Few-shot Transferability of Pre-trained Models with Improved Evaluation Protocols | 4.00 | 4.00 | 1.73 | 0.00 | |
| 6026 | Human-in-the-Loop Test-Time Domain Adaptation for Object Detection | 4.00 | 4.00 | 1.00 | 0.00 | |
| 6027 | P2RBOX:A SINGLE POINT IS ALL YOU NEED TRAINING ORIENTED OBJECT DETECTOR | 4.67 | 3.83 | 1.21 | -0.83 | | 6, 3, 8, 5, 3, 3 | | 3, 3, 6, 5, 3, 3 |
|
| 6028 | Village-Net clustering: A novel unsupervised manifold clustering method | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 3, 5, 3 | | 3, 5, 3, 5, 3 |
|
| 6029 | Lightweight uncertainty modelling using function space particle optimization | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 3, 5, 3 | | 3, 5, 3, 5, 3 |
|
| 6030 | Marginal Benefit Induced Unsupervised Environment Design | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 3, 5, 3 | | 3, 5, 3, 5, 3 |
|
| 6031 | A space-continuous implementation of Proper Orthogonal Decomposition by means of Neural Networks | 3.80 | 3.80 | 0.98 | 0.00 | | 5, 3, 5, 3, 3 | | 5, 3, 5, 3, 3 |
|
| 6032 | Jensen-Shannon Divergence Based Novel Loss Functions for Bayesian Neural Networks | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6033 | Sample as you Infer: Predictive Coding with Langevin Dynamics | 3.80 | 3.80 | 0.98 | 0.00 | | 5, 3, 3, 5, 3 | | 5, 3, 3, 5, 3 |
|
| 6034 | Simultaneous Dimensionality Reduction: A Data Efficient Approach for Multimodal Representations Learning | 3.40 | 3.80 | 0.98 | 0.40 | | 3, 5, 3, 1, 5 | | 3, 5, 3, 3, 5 |
|
| 6035 | Large Pre-trained time series models for cross-domain Time series analysis tasks | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6036 | A Label is a Label is a Label: Relation Augmentation for Scene Graph Generation | 3.80 | 3.80 | 0.98 | 0.00 | | 5, 5, 3, 3, 3 | | 5, 5, 3, 3, 3 |
|
| 6037 | Graph Clustering with Masked AutoEncoders | 3.80 | 3.80 | 0.98 | 0.00 | | 5, 5, 3, 3, 3 | | 5, 5, 3, 3, 3 |
|
| 6038 | Why are Modern GANs Poor Density Models? | 3.40 | 3.80 | 0.98 | 0.40 | | 3, 3, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6039 | GNRK: Graph Neural Runge-Kutta method for solving partial differential equations | 3.40 | 3.80 | 0.98 | 0.40 | | 3, 3, 3, 5, 3 | | 5, 3, 3, 5, 3 |
|
| 6040 | RACH-Space: Reconstructing Adaptive Convex Hull Space with applications in weak supervision | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6041 | STUDY: Socially Aware Temporally Causal Decoder Recommender Systems | 3.80 | 3.80 | 1.60 | 0.00 | | 5, 3, 5, 1, 5 | | 5, 3, 5, 1, 5 |
|
| 6042 | Bandwidth Selection for Gaussian Kernel Ridge Regression via Jacobian Control | 3.80 | 3.80 | 0.98 | 0.00 | | 5, 3, 3, 3, 5 | | 5, 3, 3, 3, 5 |
|
| 6043 | Beyond Conservatism: Diffusion Policies in Offline Multi-agent Reinforcement Learning | 4.00 | 3.80 | 0.98 | -0.20 | |
| 6044 | MultiHot Embedding: A Multiple Activation Embedding Model for Numerical Features in Deep Learning | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 3, 5, 3, 5 | | 3, 3, 5, 3, 5 |
|
| 6045 | A Critical Look at Classic Test-Time Adaptation Methods in Semantic Segmentation | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6046 | A Generative Augmentation Framework for Contrastive Learning | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 3, 3, 5 | | 3, 5, 3, 3, 5 |
|
| 6047 | Enhancing Graph Injection Attacks Through Over-Smoothing Amplification | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6048 | AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 5, 3, 3 | | 3, 5, 5, 3, 3 |
|
| 6049 | Large Language Models can $textit{Share}$ Images, Too! | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 3, 5, 5, 3 | | 3, 3, 5, 5, 3 |
|
| 6050 | Enhancing Graph Tasks with a Dual-Block Graph Transformer: A Synergistic Approach to Local and Global Attention | 3.80 | 3.80 | 0.98 | 0.00 | | 5, 5, 3, 3, 3 | | 5, 5, 3, 3, 3 |
|
| 6051 | MoDA: Mixture of Domain Adapters for Parameter-efficient Generalizable Person Re-Identification | 3.80 | 3.80 | 0.98 | 0.00 | | 3, 5, 3, 5, 3 | | 3, 5, 3, 5, 3 |
|
| 6052 | Black-box Targeted Adversarial Attack on Segment Anything (SAM) | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6053 | Categorical Features of entities in Recommendation Systems Using Graph Neural Networks | 3.50 | 3.75 | 1.30 | 0.25 | |
| 6054 | EvIL: Evolution Strategies for Generalisable Imitation Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6055 | CLASS-INCREMENTAL LEARNING USING GENERATIVE EXPERIENCE REPLAY BASED ON TIME-AWARE REGULARIZATION | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6056 | SR-OOD: Out-of-Distribution Detection via Sample Repairing | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6057 | Tensor-Train Point Cloud Compression and Efficient Approximate Nearest Neighbor Search | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6058 | Layer-wise Pre-weight Decay | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6059 | GNN-based Probabilistic Supply and Inventory Predictions in Supply Chain Networks | 3.75 | 4.25 | 1.30 | 0.50 | |
| 6060 | On information dropping and oversmoothing in graph neural networks | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6061 | On the Effect of Defection in Federated Learning and How to Prevent It | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6062 | Exploiting Action Distances for Reward Learning from Human Preferences | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6063 | Initializing the Layer-wise Learning Rate | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6064 | How does overparametrization affect features? | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6065 | Latent Conservative Objective Models for Offline Data-Driven Crystal Structure Prediction | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6066 | Non-stationary Contextual Bandit Learning via Neural Predictive Ensemble Sampling | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6067 | CrysFormer: Protein Structure Prediction via 3d Patterson Maps and Partial Structure Attention | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6068 | An empirical investigation of generalization dynamics in deep ReLU networks via nonlinear mode decomposition | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6069 | Causal Representation Learning in Temporal Data via Single-Parent Decoding | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6070 | Vision-Language Integration in Multimodal Video Transformers (Partially) Aligns with the Brain | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6071 | A Mechanism for Solving Relational Tasks in Transformer Language Models | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6072 | DS-Prover: A Dynamic Sampling Based Approach for Neural Theorem Proving | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6073 | PRO: Pseudo-label Regularized Optimization on Unlabeled Test Data | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6074 | Tensor Time-Series Forecasting and Anomaly Detection with Augmented Causality | 3.75 | 3.75 | 2.59 | 0.00 | |
| 6075 | Competition Priors for Object-Centric Learning | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6076 | Inverse Decision Making via Inverse Generative Modeling | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6077 | Can We Generate Realistic Hands Using Only Convolution? | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6078 | Navigating Scaling Laws: Accelerating Vision Transformer's Training via Adaptive Strategies | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6079 | Can Copyright be Reduced to Privacy? | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6080 | Metric Learning for Detection of Large Language Model Generated Texts | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6081 | Investigating the chaotic dynamics produced by deep reinforcement learning controllers | 3.25 | 3.75 | 1.30 | 0.50 | |
| 6082 | Pruning via Ranking (PvR): A unified structured pruning approach | 4.00 | 3.75 | 1.30 | -0.25 | |
| 6083 | Learning Node Selection via Tripartite Graph Representation in Mixed Integer Linear Programming | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6084 | MPformer: Advancing Graph Modeling Through Heterophily Relationship-Based Position Encoding | 3.75 | 3.50 | 0.87 | -0.25 | |
| 6085 | Reward Translation via Reward Machine in Semi-Alignable MDPs | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6086 | Iterative Graph Neural Network Enhancement Using Explanations | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6087 | Don't be so negative! Score-based Generative Modeling with Oracle-assisted Guidance | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6088 | Attend to Context for Refining Embeddings in Deep Metric Learning | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6089 | ChronoGAM: An End-to-End One-Class Time Series Gaussian Mixture Model | 3.50 | 3.75 | 1.92 | 0.25 | |
| 6090 | TADIS: Steering Models for Deep-Thinking about Demonstration Examples | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6091 | The Certification Paradox: Certifications Admit Better Evasion Attacks | 4.25 | 3.75 | 1.92 | -0.50 | |
| 6092 | A Joint Spectro-Temporal Relational Thinking Based Acoustic Modeling Framework | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6093 | Customizing Global Model for Diverse Target Distributions in Federated Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6094 | FedBiF: Communication-Efficient Federated Learning via Bits Freezing | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6095 | RoboGPT : An intelligent agent of making embodied long-term decisions for daily instruction tasks | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6096 | Symmetrized Schrödinger Bridge Matching | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6097 | Exploring Adversarial Robustness of Graph Neural Networks in Directed Graphs | 3.75 | 5.25 | 1.30 | 1.50 | |
| 6098 | Unleashing the Potential of Regularization Strategies in Learning with Noisy Labels | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6099 | Non-asymptotic Analysis of Stochastic Gradient Descent under Local Differential Privacy Guarantee | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6100 | Learning the Unseen: Peer-to-Peer Fine-tuning of Vision Transformers | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6101 | Active Prompting with Chain-of-Thought for Large Language Models | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6102 | ToolTalk: Evaluating Tool Usage in a Conversational Setting | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6103 | Investigating the effective dimensionality of a model using a thermodynamic learning capacity | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6104 | Discovering Divergences between Language Models and Human Brains | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6105 | FAIR-Ensemble: Homogeneous Deep Ensembling Naturally Attenuates Disparate Group Performances | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6106 | FT-SHIELD: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6107 | Controlling language over-optimization by targeting reward distribution | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6108 | Beyond Joint Demonstrations: Personalized Expert Guidance for Efficient Multi-Agent Reinforcement Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6109 | Node-wise Calibration of Graph Neural Networks under Out-of-Distribution Nodes via Reinforcement Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6110 | Solving the Quadratic Assignment Problem With Deep Reinforcement Learning | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6111 | Resolving Partial Observability in Decision Processes via the Lambda Discrepancy | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6112 | Connected Hidden Neurons (CHNNet): An Artificial Neural Network for Rapid Convergence | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6113 | Constrained Bayesian Optimization with Adaptive Active Learning of Unknown Constraints | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6114 | Generalized Adversarial Learning--An Innovative Unsupervised Paradigm In LLM's Calibration | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6115 | General-Purpose In-Context Learning by Meta-Learning Transformers | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6116 | Subgraph Mining for Graph Neural Networks | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6117 | Knowledge Accumulation in Continually Learned Representations and the Issue of Feature Forgetting | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6118 | JOSENet: A Joint Stream Embedding Network for Violence Detection in Surveillance Videos | 3.75 | 3.50 | 0.87 | -0.25 | |
| 6119 | Is Memorization Actually Necessary for Generalization? | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6120 | United We Train, Divided We Fail! Representation Learning for Time Series by Pretraining from 75 Datasets at Once | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6121 | Adversarial latent representation for positive unlabeled learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6122 | Non-uniform Noise Injection For Enhancing DNN Adversarial Robustness And Efficiency | 4.25 | 3.75 | 1.30 | -0.50 | |
| 6123 | OpenPatch: a 3D patchwork for Out-Of-Distribution detection | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6124 | Tiny-StyleWizard: Unleashing the Potential of Small Language Models in Complex Style Transfer | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6125 | Memory-Efficient Backpropagation through Large Linear Layers | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6126 | EquiAV: Single-modal Equivariance Promotes Audio-Visual Contrastive Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6127 | Text-guided Diffusion Model for 3D Molecule Generation | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6128 | Trend/Seasonality based Causal Structure for Time Series Counterfactual Outcome Prediction | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6129 | Normalized Space Alignment: A Versatile Metric for Representation Space Discrepancy Minimization | 3.50 | 3.75 | 1.30 | 0.25 | |
| 6130 | Benchmarks for Reinforcement Learning with Biased Offline Data and Imperfect Simulators | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6131 | Know2BIO: A Comprehensive Dual-View Benchmark for Evolving Biomedical Knowledge Graphs | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6132 | Solving Inverse Problem With Unspecified Forward Operator Using Diffusion Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6133 | InfoAug: Mutual Information Informed Augmentation for Representation Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6134 | Estimating Heterogeneous Treatment Effect with Delayed Response | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6135 | Opponent Modeling based on Sub-Goal Inference | 4.25 | 3.75 | 1.30 | -0.50 | |
| 6136 | Benchmarking Multivariate Time Series Anomaly Detection with Large-Scale Real-World Datasets | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6137 | pFedSAM: Secure Federated Learning Against Backdoor Attacks via Personalized Sharpness-Aware Minimization | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6138 | Enhanced Model-agnostic Training of Deep Tabular Generation Models | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6139 | Accelerating Simulation-Based Influence Maximization via Bayesian Optimization | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6140 | MetaDist: An Infrastructure for Automatic Parallelism via ShardCombine Algorithm | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6141 | Large Language Models as Decision Makers for Autonomous Driving | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6142 | Ref-Diff: Zero-shot Referring Image Segmentation with Generative Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6143 | CICD-Coder: Chinese EMRs Based ICD Coding With Multi-axial Supported Clinical Evidence | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6144 | Hierarchical Approach to Explaining Poisoned AI Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6145 | Learning to (Learn at Test Time) | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6146 | Clustering for Protein Representation Learning | 3.75 | 3.75 | 2.59 | 0.00 | |
| 6147 | When and Why Momentum Accelerates SGD: An Empirical Study | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6148 | Global Convergence Rate of Deep Equilibrium Models with General Activations | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6149 | Comparative Knowledge Distillation | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6150 | Why Sanity Check for Saliency Metrics Fails? | 3.75 | 3.75 | 2.59 | 0.00 | |
| 6151 | Diversity-Aware Agnostic Ensemble of Sharpness Minimizers | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6152 | Cross-Modal Self-Supervised Learning with Effective Contrastive Units for Point Clouds | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6153 | On the power of graph neural networks and the role of the activation function | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6154 | Strategies and impact of learning curve estimation for CNN-based image classification | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6155 | Concept Matching: Clustering-based Federated Continual Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6156 | Data-Centric Defense: Shaping Loss Landscape with Augmentations to Counter Model Inversion | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6157 | Curriculum Dynamic Graph Invariant Learning under Distribution Shift | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6158 | Leveraging Neuron Activation Patterns to Explain and Improve Deep Learning Classifiers | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6159 | Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6160 | Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6161 | $mathrm{BP}(lambda)$: bias-free online learning via synthetic gradients | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6162 | Generalization for Discriminator-Guided Diffusion Models via Strong Duality | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6163 | Diving into Class-Incremental Learning from Better Balancing Old and New knowledge | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6164 | Provably Robust Cost-Sensitive Learning via Randomized Smoothing | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6165 | Active Automated Machine Learning with Self-Training | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6166 | Spiking CenterNet: A Distillation-boosted Spiking Neural Network for Object Detection | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6167 | A Theoretical Approach to Characterize the Accuracy-Fairness Trade-off Pareto Frontier | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6168 | TabGraphs: new benchmark and insights for learning on graphs with tabular features | 3.25 | 3.75 | 1.30 | 0.50 | |
| 6169 | OneSpike: Ultra-low latency spiking neural networks | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6170 | Meta-Learning with Task-Environment Interaction | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6171 | Reducing Atomic Clashes in Geometric Diffusion Models for 3D Structure-Based Drug Design | 3.50 | 3.75 | 1.30 | 0.25 | |
| 6172 | JEN-1: Text-Guided Universal Music Generation with Omnidirectional Diffusion Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6173 | SODA: Stream Out-of-Distribution Adaptation | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6174 | LLM-Rec: Personalized Recommendation via Prompting Large Language Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6175 | FairReweighing: density estimation-based reweighing framework for improving separation in fair regression | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6176 | Mask Models are Token Level Contrastive Learners | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6177 | Learning Riemannian Metrics for Interpolating Animations | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6178 | Towards Enhanced Controllability of Diffusion Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6179 | Reinforcement Learning with Elastic Time Steps | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6180 | Dissecting Causal Biases | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6181 | SNN-LPCG: Spiking Neural Networks with Local Plasticity Context Gating for Lifelong Learning | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6182 | Adaptive Hierarchical Certification for Semantic Segmentation using Randomized Smoothing | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6183 | DISK: Domain Inference for Discovering Spurious Correlation with KL-Divergence | 3.25 | 3.75 | 1.30 | 0.50 | |
| 6184 | On Compositional Generalization in Language Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6185 | Pre-Training and Fine-Tuning Image Super-Resolution Models for Efficient Video Super-Resolution | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6186 | EMU: EFFICIENT NEGATIVE SAMPLE GENERATION METHOD FOR KNOWLEDGE GRAPH LINK PREDICTION | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6187 | EditHOI: A framework for HOI image editing with self-generated skeleton guidance | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6188 | InstructionGPT-4: A 200-Instruction Paradigm for Fine-Tuning MiniGPT-4 | 4.75 | 3.75 | 1.92 | -1.00 | |
| 6189 | Adaptive Resolution Residual Networks | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6190 | Personalization Mitigates the Perils of Local SGD for Heterogeneous Distributed Learning | 3.75 | 3.75 | 2.59 | 0.00 | |
| 6191 | Memorization for Good: Encryption with Autoregressive Language Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6192 | Enhancing Vision-Language Model with Unmasked Token Alignment at Scale | 4.25 | 3.75 | 1.30 | -0.50 | |
| 6193 | Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6194 | In-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations | 3.50 | 3.75 | 1.30 | 0.25 | |
| 6195 | FedMef: Towards Memory-efficient Federated Dynamic Pruning | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6196 | Prompt-based 3D Molecular Diffusion Models for Structure-based Drug Design | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6197 | QuickDrop: Efficient Federated Unlearning by Integrated Dataset Distillation | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6198 | InstructEdit: Improving Automatic Masks for Diffusion-based Image Editing With User Instructions | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6199 | SCREWS: A Modular Framework for Reasoning with Revisions | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6200 | Local Expert Diffusion Models for Efficient Training in Denoising Diffusion Probabilistic Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6201 | FIAT: Fusing learning paradigms with Instruction-Accelerated Tuning | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6202 | VC dimensions for deep neural networks with bounded-rank weight matrices | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6203 | Structured Pruning Adapters | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6204 | DER-Solomon: A Large Number of CVRPTW Instances Generated Based on the Solomon Benchmark Distribution | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6205 | 3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6206 | Agent-Centric State Discovery for Finite-Memory POMDPs | 3.75 | 3.75 | 2.95 | 0.00 | |
| 6207 | Accelerated Neural Network Training with Rooted Logistic Objectives | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6208 | A Generalized Convolutional Neural Network for Small Dataset Classification | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6209 | Revisiting High-Resolution ODEs for Faster Convergence Rates | 3.75 | 3.75 | 2.59 | 0.00 | |
| 6210 | Harnessing Attention Prior for Reference-based Multi-view Image Synthesis | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6211 | From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6212 | SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks | 3.75 | 3.75 | 1.92 | 0.00 | |
| 6213 | Diffusion Model-Augmented Behavioral Cloning | 4.00 | 3.75 | 1.30 | -0.25 | |
| 6214 | Towards Robust Training via Gradient-diversified Backpropagation | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6215 | Generalization error bounds for iterative learning algorithms with bounded updates | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6216 | Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation | 3.75 | 3.75 | 1.30 | 0.00 | |
| 6217 | Weight-Entanglement Meets Gradient-Based Neural Architecture Search | 3.75 | 4.25 | 1.30 | 0.50 | |
| 6218 | FairPATE: Exposing the Pareto Frontier of Fairness, Privacy, Accuracy, and Coverage | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6219 | Object-Centric Noise Filtering in Neural Radiance Fields via Influence Functions and Segmentation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6220 | Why are hyperbolic neural networks effective? A study on hierarchical representation capability | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6221 | InstaTAP: Instance Motion Estimation for Tracking Any Point | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6222 | OPTIMIZING STABILIZATION IN SINGULARLY PER- TURBED PROBLEMS WITH SUPG SCHEME | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6223 | Causal Inference Using LLM-Guided Discovery | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6224 | Explorative Latent Self-Supervised Active Search Algorithm (ELSA) | 4.00 | 3.67 | 1.89 | -0.33 | |
| 6225 | Adaptive Environmental Modeling for Task-Oriented Language Agents | 3.67 | 4.33 | 0.94 | 0.67 | |
| 6226 | RILe: Reinforced Imitation Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6227 | Latent Lie Group Representations | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6228 | CORE: Common Random Reconstruction for Distributed Optimization with Provable Low Communication Complexity | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6229 | Post-Training Recovery from Injected Bias with Self-Influence | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6230 | Fairness-Aware Attention for Contrastive Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6231 | Defender of privacy and fairness: tiny but reversible generative model via mutually collaborative knowledge distillation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6232 | QuantEase: Optimization-based Quantization for Large Language Models | 5.00 | 3.67 | 0.94 | -1.33 | |
| 6233 | AceGPT, Localizing Large Language Models in Arabic | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6234 | Decompose Time and Frequency Dependencies: Multivariate Time Series Physiological Signal Emotion Recognition | 4.00 | 3.67 | 0.94 | -0.33 | |
| 6235 | Continual Graph Learning for Thermal Analysis of Composite Materials under Interface Variations | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6236 | Neural Collapse meets Differential Privacy: Curious behaviors of NoisySGD with Near-Perfect Representation Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6237 | A New, Physics-Based Continuous-Time Reinforcement Learning Algorithm with Performance Guarantees | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6238 | Centroid-Based Learning for Malware Detection and Novel Family Identification | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6239 | AlphaFold Distillation for Protein Design | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6240 | Learning Structured Sparse Neural Networks Using Group Envelope Regularization | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6241 | Exchangeable Dataset Amortization for Bayesian Posterior Inference | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6242 | A SIMILARITY-AGNOSTIC REINFORCEMENT LEARNING APPROACH FOR LEAD OPTIMIZATION | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6243 | Quack: Automatic Jailbreaking Large Language Models via Role-playing | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6244 | ACES: Generating Diverse Programming Puzzles with Autotelic Language Models and Semantic Descriptors | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6245 | Bridging Debiasing Tasks with Sufficient Projection: A General Theoretical Framework for Vector Representations | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6246 | EPIC: Compressing Deep GNNs via Expressive Power Gap-Induced Knowledge Distillation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6247 | MIRAGE: Modelling Interpretable Multivariate Time Series Forecasts with Actionable Ground Explanations | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6248 | High Dimensional Causal Inference with Variational Backdoor Adjustment | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6249 | Embedding File Structure for Tabular File Preparation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6250 | Conditional Guided Diffusion Probabilistic Models for Image Super-Resolution | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6251 | Are LLMs Aware that Some Questions are not Open-ended? | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6252 | Federated Zeroth-Order Optimization using Trajectory-Informed Surrogate Gradients | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6253 | SpecAR-Net: Spectrogram Analysis and Representation Network for Time Series | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6254 | FedQV: Leveraging Quadratic Voting in Federated Learning | 3.00 | 4.00 | 1.00 | 1.00 | |
| 6255 | Balancing Information Preservation and Computational Efficiency: L2 Normalization and Geodesic Distance in Manifold Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6256 | BDQL: Offline RL via Behavior Diffusion Q-learning without Policy Constraint | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6257 | A Soft Labeling Approach for Fairness-aware Learning Under Partially Annotated Sensitive Attributes | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6258 | Balance Beam: adaptive computation for affordable training and inference with high-throughput offloading for LLMs | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6259 | I Know You Did Not Write That! A Sampling Based Watermarking Method for Identifying Machine Generated Text | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6260 | XIMAGENET-12: An Explainable AI Benchmark Dataset for Model Robustness Evaluation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6261 | Full Elastic Weight Consolidation via the Surrogate Hessian-Vector Product | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6262 | Towards Better Orthogonality Regularization with Disentangled Norm in Training Deep CNNs | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6263 | Enhancing Decision Tree Learning with Deep Networks | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6264 | Unsupervised Learning of Object-Centric Representation from Multi-Viewpoint Scenes | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6265 | Delayed Spiking Neural Network and Exponential Time Dependent Plasticity Algorithm | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6266 | SketchEdit: Editing Freehand Sketches At The Stroke-Level | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6267 | Decoupling Intrinsic and Measurement Trends: A Crucial Consideration in Time Series Causal Discovery | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6268 | Test Time Augmentations are Worth One Million Images for Out-of-Distribution Detection | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6269 | Stochastic Adversarial Networks for Multi-Domain Text Classification | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6270 | Towards a Self-Made Model: Zero-Shot Self-Supervised Purification for Adversarial Attacks | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6271 | Quantum sequential scattering model for quantum state learning | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6272 | Spatial Matching Loss Function for Mass Segmentation on Whole Mammography Images | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6273 | Regularized Optimal Transport for Temporal Trajectory Analysis in Single-Cell Data | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6274 | Reconstruction of Cortical Surfaces with Spherical Topology from Infant Brain MRI via Recurrent Deformation Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6275 | CoSDA: Continual Source-Free Domain Adaptation | 3.67 | 3.67 | 0.94 | 0.00 | | 3, 5, 3, 5, 3, 3 | | 3, 5, 3, 5, 3, 3 |
|
| 6276 | Bi-Directional Goal-Conditioning on Single Policy Function for State Space Search | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6277 | Fantastic DNN-Classifier Identification without Testing Dataset | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6278 | LLM-Prop: Predicting Physical And Electronic Properties of Crystalline Solids From Their Text Descriptions | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6279 | Efficient Parameter Tuning of Large Protein Language Models for De Novo Protein Design | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6280 | Lightweight Unsupervised Federated Learning with Pretrained Vision Language Model | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6281 | Amphibian: A Meta-Learner for Rehearsal-Free Fast Online Continual Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6282 | Inducing Precision in Lagrangian Neural Networks : Proof of concept application on Chaotic systems | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6283 | Deep Generalized Prediction Set Classifier and Its Theoretical Guarantees | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6284 | Variational Language Concepts for Interpreting Pretrained Language Models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6285 | GEOFFair: a GEOmetric Framework for Fairness | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6286 | DIVERSITY OF THOUGHT IMPROVES REASONING ABILITIES OF LARGE LANGUAGE MODELS | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6287 | Reclaiming the Source of Programmatic Policies: Programmatic versus Latent Spaces | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6288 | Depth-Guided Self-Supervised Learning: Seeing the World in 3D | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6289 | Capacity Analysis of Vector Symbolic Architectures | 4.00 | 3.67 | 0.94 | -0.33 | |
| 6290 | Implicit Latent Causal Representation Learning through Soft Interventions | 3.67 | 3.67 | 0.94 | 0.00 | | 3, 5, 3, 3, 3, 5 | | 3, 5, 3, 3, 3, 5 |
|
| 6291 | Continual Reinforcement Learning by Reweighting Bellman Targets | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6292 | Contextualized Policy Recovery: Modeling and Interpreting Medical Decisions with Adaptive Imitation Learning | 3.67 | 4.33 | 0.94 | 0.67 | |
| 6293 | RAND: Robustness Aware Norm Decay For Quantized Seq2seq Models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6294 | Conditional Generative Modeling for High-dimensional Marked Temporal Point Processes | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6295 | On Robustness-Accuracy Characterization of Large Language Models using Synthetic Datasets | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6296 | Pylic: Leveraging Source Code for Planning in Structured Environments | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6297 | A Unified Framework for Heterogeneous Semi-supervised Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6298 | Coupling Fairness and Pruning in a Single Run: a Bi-level Optimization Perspective | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6299 | KNIFE: Distilling Reasoning Knowledge From Free-Text Rationales | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6300 | Option Boosting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6301 | Rendering Wireless Environments Useful for Gradient Estimators: A Zero-Order Stochastic Federated Learning Method | 3.67 | 3.67 | 0.94 | 0.00 | | 5, 3, 5, 3, 3, 3 | | 5, 3, 5, 3, 3, 3 |
|
| 6302 | Implicit Chain of Thought Reasoning via Knowledge Distillation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6303 | GraphMaker: Can Diffusion Models Generate Large Attributed Graphs? | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6304 | Learning with Instance-Dependent Noisy Labels by Hard Sample Selection with Anchor Hallucination | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6305 | ResBit: Residual Bit Vector for Categorical Values | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6306 | The Extrapolation Power of Implicit Models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6307 | Learning Counterfactually Invariant Predictors | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6308 | 3D Tissue Reconstruction and Generation for Single-Cell Spatial Transcriptomics using Neural Radiance Fields | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6309 | Are machines automating morality? | 4.00 | 3.67 | 0.94 | -0.33 | |
| 6310 | Learning to Count without Annotations | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6311 | DIFAIR: Towards learning differenciated and interpretable representations | 3.40 | 3.67 | 0.94 | 0.27 | | 5, 3, 3, 3, 3 | | 5, 3, 3, 3, 3, 5 |
|
| 6312 | Pseudo-Mask and Language: A Simple Recipe for Open-Vocabulary Semantic Segmentation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6313 | Dirichlet-based Uncertainty Quantification for Personalized Federated Learning with Improved Posterior Networks | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6314 | DITTO: Offline Imitation Learning with World Models | 3.67 | 3.33 | 0.75 | -0.33 | | 5, 3, 3, 3, 5, 3 | | 3, 3, 3, 3, 5, 3 |
|
| 6315 | Curve Your Attention: Mixed-Curvature Transformers for Graph Representation Learning | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6316 | Bridging Sub-Tasks to Long-Horizon Task in Hierarchical Goal-Based Reinforcement Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6317 | AutoHall: Automated Hallucination Dataset Generation for Large Language Models | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6318 | Tall Tales at Different Scales: Evaluating Scaling Trends For Deception in Language Models | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6319 | ProteiNexus: Illuminating Protein Pathways through Structural Pre-training | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6320 | Why Diffusion Models Are Stable and How to Make Them Faster: An Empirical Investigation and Optimization | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6321 | Learning Constraints from Offline Dataset via Inverse Dual Values Estimation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6322 | Domain-Agnostic Self-Training for Semi-Supervised Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6323 | FlowHash: Accelerating Audio Search with Balanced Hashing via Normalizing Flow | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6324 | ExcelFormer: Making Neural Network Excel in Small Tabular Data Prediction | 3.67 | 5.00 | 0.00 | 1.33 | |
| 6325 | Quantifying Anonymity in Score-Based Generators with Adversarial Fingerprinting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6326 | Stochastic Gradient Langevin Dynamics Based on Quantization with Increasing Resolution | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6327 | Benchmarks and Custom Package for Electrical Load Forecasting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6328 | Noise-guided Unsupervised Outlier Detection | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6329 | Evaluating Multi-Agent Coordination Abilities in Large Language Models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6330 | DIA: Diffusion based Inverse Network Attack on Collaborative Inference | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6331 | Adversarially Robust and Privacy-Preserving Representation Learning via Information Theory | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6332 | Exploring Federated Optimization by Reducing Variance of Adaptive Unbiased Client Sampling | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6333 | LayerDiff: Exploring Text-guided Multi-layered Composable Image Synthesis via Layer-Collaborative Diffusion Model | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6334 | HGAMLP: A Scalable Training Framework for Heterogeneous Graph Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6335 | Observable Propagation: Uncovering Feature Vectors in Transformers | 4.33 | 3.67 | 0.94 | -0.67 | |
| 6336 | Are Large Language Models Post Hoc Explainers? | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6337 | Adaptive Multi-head Contrastive Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6338 | DiffSDS: A geometric sequence diffusion model for protein backbone inpainting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6339 | FusionShot: Boosting Few Shot Learners with Focal-Diversity Optimized Ensemble Method | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6340 | Mining latent labels for imbalance classification: a regrouping perspective | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6341 | Speed Up Federated Learning in Heterogeneous Environment: A Dynamic Tiering Approach | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6342 | MultiLayerDiffusion: Composing Global Contexts and Local Details in Image Generation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6343 | On the Equivalence of Graph Convolution and Mixup | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6344 | Partition and Conquer: A Multimodal Autoregressive Model for Time-Aligned and Contextual Modalities | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6345 | Soon Filter: Advancing Feed-Forward Neural Architectures for Inference at the Edge | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6346 | Is Scale All You Need For Anomaly Detection? | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6347 | On the Efficiency of Transformers: The Effect of Attention Rank | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6348 | Ophiuchus: Scalable Modeling of Protein Structures through Hierarchical Coarse-graining SO(3)-Equivariant Autoencoders | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6349 | Listen to Motion: Robustly Learning Correlated Audio-Visual Representations | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6350 | HAct: Out-of-Distribution Detection with Neural Net Activation Histograms | 4.33 | 3.67 | 0.94 | -0.67 | |
| 6351 | On the Matrix Form of the Quaternion Fourier Transform and Quaternion Convolution | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6352 | LLM2Labels: Zero-shot dataset summarizing and labeling using foundational LLM models | 3.00 | 3.50 | 1.66 | 0.50 | |
| 6353 | CNNGEN: A GENERATOR AND BENCHMARK FOR SUSTAINABLE CONVOLUTIONAL NEURAL NETWORK SEARCH | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6354 | Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6355 | Theory-of-Mind Enhanced Dialogue Generation in Situated Contexts | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6356 | Instance-aware 3D Semantic Segmentation powered by Shape Reconstruction and Classification | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6357 | Learning then Leveraging Structures Help with Complex, Compositional, Causal Sequential Tasks in Inverse Reinforcement Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6358 | FastDCFlow: Fast and Diverse Counterfactual Explanations Using Normalizing Flows | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6359 | HOSC: Hyperbolic Oscillating Periodic Activations for Sharp Feature Preservation in Implicit Neural Representations | 4.67 | 3.67 | 0.94 | -1.00 | |
| 6360 | Interpretable Latent Distributions Using Space-Filling Curves | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6361 | Regularized KL-Divergence for well-defined function space variational inference in BNNs | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6362 | SignKD: Multi-modal Hierarchical Knowledge Distillation for Continuous Sign Language Recognition | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6363 | Multimodal Variational Disentangled Knowledge Alignment for Cross-domain Recommendation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6364 | REDUCR: Robust Data Downsampling Using Class Priority Reweighting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6365 | TCL-VS: Temporal Contrastive Learning for Self-Supervised Video Summarization | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6366 | Explainable Multi-Objective Model Selection for Time Series Forecasting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6367 | Democratized Diffusion Language Model | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6368 | AntifakePrompt: Prompt-Tuned Vision-Language Models are Fake Image Detectors | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6369 | Hierarchy-aware Biased Bound Loss Function for Hierarchical Text Classification | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6370 | Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6371 | Fine-tune Language Models to Approximate Unbiased In-context Learning | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6372 | Quantifying Uncertainty in Answers from any Language Model and Enhancing their Trustworthiness | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6373 | FUND-RELATED GRAPH REPRESENTATION FOR MARGINAL EFFECTIVENESS IN MULTI-FACTORS QUANTITATIVE STRATEGY | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6374 | Look-Ahead Selective Plasticity for Continual Learning of Visual Tasks | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6375 | vFedSec: Efficient Secure Aggregation for Vertical Federated Learning via Secure Layer | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6376 | Sporadicity in Decentralized Federated Learning: Theory and Algorithm | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6377 | Maximizing LLMs Potential: Enhancing Mongolian Chinese Machine Translation with RL Agents and Adversarial Multi Knowledge Distillation | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6378 | Understanding and Controlling a Maze-Solving Policy Network | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6379 | RGB-Event MOT: A Cross-Modal Benchmark for Multi-Object Tracking | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6380 | ProtoNMF: Turning a Black Box into a Prototype Based Interpretable Model via Non-negative Matrix Factorization | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6381 | UniBoost: Boost Zero-shot Vision-Language Tasks via Multitask Fine-tuning with Unsupervised Unimodal Pre-training | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6382 | Deep Regression Representation Learning with Topology | 3.67 | 3.67 | 0.94 | 0.00 | | 3, 5, 5, 3, 3, 3 | | 3, 5, 5, 3, 3, 3 |
|
| 6383 | A Teacher-Guided Framework for Graph Representation Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6384 | Drag View: Generalizable Novel View Synthesis with Unposed Imagery | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6385 | Preprocessing Enhanced Image Compression for Machine Vision | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6386 | Parameter-Efficient Fine-Tuning via Partially Decomposable Loss Analysis and Sharing | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6387 | Instruction-following Evaluation through Verbalizer Manipulation | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6388 | Symbolic equation solving via reinforcement learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6389 | Ricci Curvature, Robustness, and Causal Inference on Networked Data | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6390 | StyleCL : Latent Dictionary Learning for StyleGAN Without Forgetting | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6391 | Hybrid Representation Learning Via Epistemic Graph | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6392 | Information based explanation methods for deep learning agents -- with applications on large open-source chess models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6393 | HyperMask: Adaptive Hypernetwork-based Masks for Continual Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6394 | Partitioning-Guided K-Means: Extreme Empty Cluster Resolution for Extreme Model Compression | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6395 | Style Over Substance: Evaluation Biases for Large Language Models | 4.00 | 3.67 | 0.94 | -0.33 | |
| 6396 | How do agents invest strategically under persistent improvement? | 3.67 | 3.67 | 1.89 | 0.00 | |
| 6397 | Model-Based Offline Reinforcement Learning with Conservative Bidirectional Rollouts | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6398 | Towards More Accurate Diffusion Model Acceleration with A Timestep Aligner | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6399 | Observation-Guided Diffusion Probabilistic Models | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6400 | Multi-conditioned Graph Diffusion for Neural Architecture Search | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6401 | Proto-CLIP: A Vision-Language Prototype Alignment Approach for Few-Shot Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6402 | Diverse Offline Imitation Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6403 | On Accelerating Diffusion-based Molecular Conformation Generation in SE(3)-invariant Space | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6404 | Dolfin: Diffusion Layout Transformers without Autoencoder | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6405 | Mask and Restore: Blind Backdoor Defense at Test Time with Masked Autoencoder | 3.00 | 3.67 | 0.94 | 0.67 | |
| 6406 | DIVA: A Dirichlet Process Mixtures Based Incremental Deep Clustering Algorithm via Variational Auto-Encoder | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6407 | Cluster-Learngene: Inheriting Adaptive Clusters for Self-Attention | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6408 | AbnormalLog: A Deep Anomaly Detection Method for Log Sequence Data | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6409 | Learning Deep Improvement Representation to Accelerate Evolutionary Optimization | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6410 | Tackling Underestimation Bias in Successor Features by Distributional Reinforcement Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6411 | Lightweight Image Classification Network Based on Feature Extraction Network SimpleResUNet and Attention | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6412 | Revisiting Supervision for Continual Representation Learning | 3.67 | 3.67 | 0.94 | 0.00 | |
| 6413 | FSN: Feature Shift Network for Load-Domain Domain Generalization | 3.62 | 3.62 | 1.11 | 0.00 | | 6, 3, 3, 3, 3, 3, 5, 3 | | 6, 3, 3, 3, 3, 3, 5, 3 |
|
| 6414 | Physics Informed Neurally Constructed ODE Networks (PINeCONes) | 3.60 | 3.60 | 1.20 | 0.00 | | 3, 6, 3, 3, 3 | | 3, 6, 3, 3, 3 |
|
| 6415 | Binder: Hierarchical Concept Representation through Order Embedding of Binary Vectors | 3.60 | 3.60 | 1.74 | 0.00 | | 5, 6, 3, 1, 3 | | 5, 6, 3, 1, 3 |
|
| 6416 | A neuro-symbolic framework for answering conjunctive queries | 3.60 | 3.60 | 1.20 | 0.00 | | 3, 3, 6, 3, 3 | | 3, 3, 6, 3, 3 |
|
| 6417 | IG-Net: Image-Goal Network for Offline Visual Navigation on A Large-Scale Game Map | 3.60 | 4.00 | 1.26 | 0.40 | | 3, 6, 3, 3, 3 | | 3, 6, 5, 3, 3 |
|
| 6418 | Adaptive Temperature Enhanced Dual-level Hypergraph Contrastive Learning | 3.60 | 3.40 | 1.50 | -0.20 | | 1, 3, 3, 5, 6 | | 1, 3, 3, 5, 5 |
|
| 6419 | On Gaussian Mixture Models | 3.60 | 4.00 | 1.26 | 0.40 | | 6, 3, 3, 1, 5 | | 6, 3, 3, 3, 5 |
|
| 6420 | Beyond Shortest-Paths: A Benchmark for Reinforcement Learning on Traffic Engineering | 3.60 | 3.60 | 1.20 | 0.00 | | 3, 3, 6, 3, 3 | | 3, 3, 6, 3, 3 |
|
| 6421 | MILE: Mutual Information LogDet Estimator | 3.60 | 3.60 | 1.20 | 0.00 | | 3, 3, 6, 3, 3 | | 3, 3, 6, 3, 3 |
|
| 6422 | DisFormer: Disentangled Object Representations for Learning Visual Dynamics Via Transformers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6423 | Large Language Models as superpositions of cultural perspectives | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6424 | Episode Transformer: Model-based Episodic Reinforcement Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6425 | Vision Transformer with Irregular Attention | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6426 | An Optimization-Based Framework for Adversarial Defence of Graph Neural Networks Via Adaptive Lipschitz Regularization | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6427 | Adapting ConvNets for New Cameras without Retraining | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6428 | Relating Implicit Bias and Adversarial Attacks through Intrinsic Dimension | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6429 | Screening Unlearnable Examples via Iterative Self Regression | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6430 | Implicit Regularisation in Overparametrized Networks: A Multiscale Analysis of the Fokker-Planck equation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6431 | Slot Structured World Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6432 | All Languages Matter: On the Multilingual Safety of Large Language Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6433 | VRAda: A Variance Reduced Adaptive Algorithm for Stochastic Parameter-Agnostic Minimax Optimizations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6434 | There is More to Graphs than Meets the Eye: Learning Universal Features with Self-supervision | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6435 | Principal Component Analysis for Cross-Sectionally Correlated Pricing Errors | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6436 | L-MBOP-E: Latent-Model Based Offline Planning with Extrinsic Policy Guided Exploration | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6437 | Combine and Compare: Graph Rationale Learning with Conditional Non-Rationale Sampling | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6438 | Plasticity-Driven Sparsity Training for Deep Reinforcement Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6439 | STARLING: Self-supervised Training of Text-based Reinforcement Learning Agent with Large Language Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6440 | Zero-shot Clustering of Embeddings with Pretrained and Self-Supervised Learning Encoders | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6441 | AdaO2B: Adaptive Online to Batch Conversion for Out-of-Distribution Generalization | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6442 | Latent Shattering: Turning Unconditional Pretrained Generators Into Conditional Models By Imposing Latent Structure | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6443 | A Data-Centric Approach for Financial Large Language Models with Abductive Augmentation Reasoning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6444 | An Implicit Watermark Framework for Adversary Identification | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6445 | Attribute-Enhanced Similarity Ranking for Sparse Link Prediction | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6446 | Measuring Graph Similarity Using Transfer Cost of Forster Distributions | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6447 | ABKD: Graph Neural Network Compression with Attention-Based Knowledge Distillation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6448 | Semi-Supervised Learning of Tree-Based Models Using Uncertain Interpretation of Data | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6449 | Positional Description Matters for Transformers Arithmetic | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6450 | Latent Space Simulator for Unveiling Molecular Free Energy Landscapes and Predicting Transition Dynamics | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6451 | Embedding Improves Neural Regularizers for Inverse Problems | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6452 | Efficient Value Propagation with the Compositional Optimality Equation | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6453 | RPNet: Robust Non-Interactive Private Inference against Malicious Clients with Adversarial Attacks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6454 | Large Language Models Can Design Game-Theoretic Objectives for Multi-Agent Planning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6455 | UnifiedGT: Exploring the Effective Ingredients of Transformers in Large Graphs | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6456 | FroSSL: Frobenius Norm Minimization for Self-Supervised Learning | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6457 | In-Context Learning for Few-Shot Molecular Property Prediction | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6458 | Graph Neural Modeling of Network Flows | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6459 | Controllable Data Generation via Iterative Data-Property Mutual Mappings | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6460 | Parameter Estimation of Long Memory Stochastic Processes with Deep Neural Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6461 | PrivilegedDreamer: Explicit Imagination of Privileged Information for Adaptation in Uncertain Environments | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6462 | Competitive-Collaborative GAN with Performance Guarantee | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6463 | Randomized Benchmarking of Local Zeroth-Order Optimizers for Variational Quantum Systems | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6464 | Fusion Token: Enhancing Compression and Efficiency in Language Model Tokenization | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6465 | Minimalist and High-Performance Semantic Segmentation with Plain Vision Transformers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6466 | In-Depth Comparison of Regularization Methods For Long-Tailed Learning in Trajectory Prediction | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6467 | Hyperbolic Embeddings in Sequential Self-Attention for Improved Next-Item Recommendations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6468 | Multi-Scale Window based Transformer Network for High Quality Image Inpainting | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6469 | Human-in-the-loop Detection of AI-generated Text via Grammatical Patterns | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6470 | Tab2Gan: Utilizing image conversion and Gan inversion for tabular model robustness | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6471 | Predicting the Encoding Error of Implicit Neural Representations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6472 | Boosting Multi-Agent Reinforcement Learning via Transition-Informed Representations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6473 | Towards Foundation Models for Learning on Tabular Data | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6474 | Schrodinger Bridge to Bridge Generative Diffusion Method to Off-Policy Evaluation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6475 | DNCs require more planning steps | 3.50 | 4.00 | 1.00 | 0.50 | |
| 6476 | Modify Training Direction in Function Space to Reduce Generalization Error | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6477 | Rigid Motion Compensated Compressed Sensing MRI with Untrained Neural Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6478 | BAFFLE: A Baseline of Backpropagation-Free Federated Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6479 | Self-supervision Meets Bootstrap Estimation: New Paradigm for Unsupervised Reconstruction with Uncertainty Quantification | 3.25 | 3.50 | 0.87 | 0.25 | |
| 6480 | Learning to ignore: Single Source Domain Generalization via Oracle Regularization | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6481 | What Makes for Robust Multi-Modal Models in the Face of Missing Modalities? | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6482 | PromptNER : Prompting For FewShot Named Entity Recognition | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6483 | SASS: Self-Alignment with Semi-Supervised Instruction Data Generation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6484 | A Geometric Perspective on Diffusion Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6485 | S4++: Elevating Long Sequence Modeling with State Memory Reply | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6486 | Unveiling Linear Mode Connectivity of Re-basin from Neuron Distribution Perspective | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6487 | Motor Imagery Decoding Using Ensemble Curriculum Learning and Collaborative Training | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6488 | Architectural Insights for efficient Physics-Informed Neural Network optimization | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6489 | DockGame: Cooperative Games for Multimeric Rigid Protein Docking | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6490 | Continual Knowledge Graph Link Prediction: Beyond Experience Replay | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6491 | Discovering Knowledge-Critical Subnetworks in Neural Language Models | 3.50 | 4.00 | 1.00 | 0.50 | |
| 6492 | Stop overkilling simple tasks with black-box models, use more transparent models instead | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6493 | Edge-free but Structure-aware: Prototype-Guided Knowledge Distillation from GNNs to MLPs | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6494 | Performance Adjustment for Federated Learning Marketplace | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6495 | Towards Predicate-powered Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6496 | LLM4GCL: CAN LARGE LANGUAGE MODEL EM-POWER GRAPH CONTRASTIVE LEARNING? | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6497 | GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6498 | Semi-supervised Long-tailed Recognition using Alternate Sampling | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6499 | 3D Autoencoding Diffusion Model for Molecule Interpolation and Manipulation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6500 | Non-Intrusive Adaptation: Input-Centric Parameter-efficient Fine-Tuning for Versatile Multimodal Modeling | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6501 | On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused? | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6502 | A Symmetry-Aware Learning Approach for Solving Mixed-Integer Linear Programs | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6503 | POPULATION DESCENT: A NATURAL-SELECTION BASED HYPER-PARAMETER TUNING FRAMEWORK | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6504 | Learning A Disentangling Representation For PU Learning | 3.75 | 3.50 | 0.87 | -0.25 | |
| 6505 | scHyena: Foundation Model for Full-Length Single-Cell RNA-Seq Analysis in Brain | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6506 | Outlier-Robust Orthogonal Regression on Manifolds | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6507 | Revisiting differentially private XGBoost: are random decision trees really better than greedy ones? | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6508 | EFFICIENT QUANTUM STATE RECONSTRUCTION USING UNSUPERVISED LEARNING FOR QUANTUM CIRCUIT CUTTING | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6509 | Conditional Diffusion Distillation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6510 | De Novo Drug Design with Joint Transformers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6511 | On Sarcasm Detection with OpenAI GPT-based Models | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6512 | AMPNet: Attention as Message Passing for Graph Neural Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6513 | Measuring Feature Sparsity in Language Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6514 | Neural mechanisms of cognitive flexibility: Belief updating in dynamic environments with sparse rewards | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6515 | Protein Language Models Enable Accurate Cryptic Ligand Binding Pocket Prediction | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6516 | POET: Prompt Offset Tuning for Continual Few-Shot Action Recognition | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6517 | Learning to Solve New sequential decision-making Tasks with In-Context Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6518 | A Shot-Efficient Differential Equation Integrator using Quantum Neural Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6519 | Handling Cost and Constraints with Off-Policy Deep Reinforcement Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6520 | UGSL: A Unified Framework for Benchmarking Graph Structure Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6521 | Reducing distortions in Real World Image Super Resolution using Attention | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6522 | Promoting Sparsity in Continuous-time Neural Networks to Learn Dependence Structures | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6523 | Eliciting Attributions from LLMs with Minimal Supervision | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6524 | Mitigating Estimation Errors By Twin TD-Regularized Actor and Critic for Deep Reinforcement Learning | 4.00 | 3.50 | 0.87 | -0.50 | |
| 6525 | Optimizing the trade-off between utility and performance in interpretable sleep classification | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6526 | Neural Coherence | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6527 | Quality-Diversity Transfer Learning (QDTL) | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6528 | Pre-trained Neural Recommenders: Learning Statistical Representations for Zero-shot Recommender Systems | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6529 | Optimization Framework of Transfer Learning and its Feasibility | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6530 | From PDEs to Wingbeats: A Novel Convolutional Fourier Layer-based ResNet Model | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6531 | Learning From Multi-Expert Demonstrations: A Multi-Objective Inverse Reinforcement Learning Approach | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6532 | Provably Accurate ODE Forecasting Through Explicit Trajectory Optimization | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6533 | Enhancing Graph Neural Networks with Quantum Computed Encodings | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6534 | DiffSim: Aligning Diffusion Model and Molecular Dynamics Simulation for Accurate Blind Docking | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6535 | Stochastic Competition Networks for Deep Learning on Tabular Data | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6536 | What Apples Tell About Oranges: Connecting Pruning Masks and Hessian Eigenspaces | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6537 | IMPLICIT STACKED AUTOREGRESSIVE MODEL FOR WEATHER FORECASTING | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6538 | Audio Image Generation for Denoising | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6539 | End-to-End Training of Unsupervised Trees: KAURI and DOUGLAS | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6540 | Rethinking Semantic Few-Shot Image Classification | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6541 | Data augmentation guided Decouple Knowledge Distillation for low-resolution fine-grained image classification | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6542 | Using Forwards-Backwards Models to Approximate MDP Homomorphisms | 3.75 | 3.50 | 0.87 | -0.25 | |
| 6543 | Privacy Preserving API Fine-tuning for LLMs | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6544 | Untrained Networks' Class Bias: A Theoretical Investigation | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6545 | Experts on Demand: Dynamic Routing for Personalized Diffusion Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6546 | $MC^2$: Multimodal Concept-based Continual learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6547 | Lost in Transformation: Current roadblocks for Transformers in 3D medical image segmentation | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6548 | A Dynamic Mixup Approach Towards Improved Robustness of Classifiers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6549 | Towards Demystifying the Generalization Behaviors When Neural Collapse Emerges | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6550 | Learning System Dynamics from Sensory Input under Optimal Control Principles | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6551 | A Weight Variation-Aware Training Method for Hardware Neuromorphic Chips | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6552 | MusicAOG: an Energy-Based Model for Learning and Sampling a Hierarchical Representation of Symbolic Music | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6553 | Enhancing Fine-Tuning Performance of Large-Scale Text-to-Image Models on Specialized Datasets | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6554 | Zero-shot Image Restoration via Diffusion Inversion | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6555 | Incremental Successive Halving for Hyperparameter Optimization with Budget Constraints | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6556 | Meta-Prior: Meta learning for Adaptive Inverse Problem Solvers | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6557 | What Do GNNs Actually Learn? Towards Understanding their Representations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6558 | Tell, Don't Show: Internalized Reasoning influences how LLMs generalize | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6559 | Leveraging Graph Neural Networks to Boost Fine-Grained Image Classification | 3.50 | 3.00 | 0.00 | -0.50 | |
| 6560 | Guide Your Anomaly with Language | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6561 | RSAM: Learning on Manifolds with Riemannian Sharpness-Aware Minimization | 3.00 | 3.50 | 1.66 | 0.50 | |
| 6562 | Knowledge Is Not Wisdom: Weight Balancing Mechanism for Local and Global Training in Federated Learning | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6563 | Train Short, Test Long In Combinatorial Optimization | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6564 | A Case Study for the Behaviors of Generalists and Specialists in Competitive Games | 3.75 | 3.50 | 0.87 | -0.25 | |
| 6565 | T1: Scaling Diffusion Probabilistic Fields to High-Resolution on Unified Visual Modalities | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6566 | Dynamic Training Guided by Training Dynamics | 4.00 | 3.50 | 0.87 | -0.50 | |
| 6567 | Feynman-Kac Operator Expectation Estimator: An Innovative Method for Enhancing MCMC Efficiency and Reducing Variance | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6568 | Efficient Realistic Avatar Generation via Model Compression and Enhanced Rendering | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6569 | Towards Better Propagation of Non-parametric GNNs | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6570 | Class-Incremental Continual Learning for Multi-View Clustering | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6571 | Improving Sample Efficiency in Off-policy RL with Low-dimensional Policy Representation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6572 | InfoIGL: Invariant Graph Learning Driven by Information Theory | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6573 | An Entropic Risk Measure for Robust Counterfactual Explanations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6574 | Multiclass Alignment of Confidences and Softened Target Occurrences for Train-time Calibration | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6575 | Strategic Classification with Unforeseeable Outcomes | 3.75 | 4.00 | 1.00 | 0.25 | |
| 6576 | OneBNet: Binarized Neural Networks using Decomposed 1-D Binarized Convolutions on Edge Device | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6577 | Self-Prompt SAM: Automatic Prompt SAM Adaptation for Medical Image Segmentation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6578 | Certifying LLM Safety against Adversarial Prompting | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6579 | LIPEx -- Locally Interpretable Probabilistic Explanations -- To Look Beyond The True Class | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6580 | Detecting and Removing Adversarial Patches using Frequency Signatures | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6581 | Mechanism of clean-priority learning in early stopped neural networks of infinite width | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6582 | SDM-RL: Steady-State Divergence Maximization for Robust Reinforcement Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6583 | Towards Universal Robust Federated Learning via Meta Stackelberg Game | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6584 | T-Measure: A Measure for Model Transferabilty | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6585 | SGD batch saturation for training wide neural networks | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6586 | Global minima, recoverability thresholds, and higher-order structure in GNNs | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6587 | OS-net: Orbitally Stable Neural Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6588 | Reward Adaptation Via Q-Manipulation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6589 | Confession Networks: Boosting Accuracy and Improving Confidence in Classification | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6590 | Representation Learning from Interventional Data | 4.00 | 3.50 | 0.87 | -0.50 | |
| 6591 | DeCCaF: Deferral Under Cost and Capacity Constraints Framework | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6592 | AS-LLM: When Algorithm Selection Meets Large Language Model | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6593 | Understanding the Transfer of High-Level Reinforcement Learning Skills Across Diverse Environments | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6594 | CLA-RA: COLLABORATIVE ACTIVE LEARNING AMIDST RELABELING AMBIGUITY | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6595 | Advancing the Adversarial Robustness of Neural Networks from the Data Perspective | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6596 | PINF: Continuous Normalizing Flows for Physics-Constrained Deep Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6597 | LLM Lies: Hallucinations are not Bugs, but Features as Adversarial Examples | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6598 | Capturing Static, Short-Term, and Long-Term Dynamics Through Self-Supervised Time Series Learning: CHRONOS | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6599 | Adding 32 Parameters to a LLM can improve fine-tuned classification performance by up to 1.5-6 percentage points | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6600 | Edge-Sampler: Efficient Importance Sampling for Neural Implicit Surfaces Reconstruction | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6601 | Curvature MPNNs : Improving Message Passing with Local Structural Properties | 3.00 | 3.50 | 1.66 | 0.50 | |
| 6602 | Diversifying Deep Ensembles: A Saliency Map Approach for Enhanced OOD Detection, Calibration, and Accuracy | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6603 | FedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6604 | Adiabatic replay for continual learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6605 | Designing Long-term Group Fair Policies in Dynamical Systems | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6606 | Dual Fusion AutoEncoder for Graph Clustering | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6607 | Gazelle: A Multimodal Learning System Robust to Missing Modalities | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6608 | Sparse-PGD: An Effective and Efficient Attack for $l_0$ Bounded Adversarial Perturbation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6609 | Graph Neural Networks for Multivariate Time-Series Forecasting via Learning Hierarchical Spatiotemporal Dependencies | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6610 | UNLEARNING THE UNWANTED DATA FROM A PERSONALIZED RECOMMENDATION MODEL | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6611 | Amortising the Gap between Pre-training and Fine-tuning for Video Instance Segmentation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6612 | Time-Sensitive Replay for Continual Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6613 | Tensor methods to learn the Green's function to solve high-dimensional PDE | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6614 | Look Ma, No Training! Observation Space Design for Reinforcement Learning | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6615 | Mining Shallow Layer Representations in Class-Incremental Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6616 | RLAdapter: Bridging Large Language Models to Reinforcement Learning in Open Worlds | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6617 | UniContact:A Basic Model for Robotic Manipulation of Contact Synthesis on Rigid and Articulated Rigid Bodies with Arbitrary Manipulators | 4.00 | 3.50 | 0.87 | -0.50 | |
| 6618 | 3D Morphable Master Face Generation: Towards Controllable Wolf Attacks against 2D and 3D Face Recognition Systems | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6619 | A Data-Driven Solution for the Cold Start Problem in Biomedical Image Classification | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6620 | Federated Learning with a Single Shared Image | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6621 | Learning Multi-Modal Representation Alignments from Noisy Data-Pairs | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6622 | A Study of the Effects of Transfer Learning on Adversarial Robustness | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6623 | FENDA-FL: Personalized Federated Learning on Heterogeneous Clinical Datasets | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6624 | OLGA: One-cLass Graph Autoencoder | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6625 | POI-based Traffic Generation via Supervised Contrastive Learning on Reconstructed Graph | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6626 | Delve into Image Style Diffusion Towards Schrödinger Bridge Problem | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6627 | Reasoning-Enhanced Object-Centric Learning for Videos | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6628 | Enable Quantum Graph Neural Networks on a Single Qubits | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6629 | TETA: Temporal-Enhanced Text-to-Audio Generation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6630 | Predict-then-Optimize via Learning to Optimize from Features | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6631 | Completion Consistency for Point Cloud Completion Enhancement | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6632 | On Function-Coupled Watermarks for Deep Neural Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6633 | Policy Disentangled Variational Autoencoder | 3.75 | 3.50 | 0.87 | -0.25 | |
| 6634 | MVoice: Multilingual Unified Voice Generation With Discrete Representation at Scale | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6635 | Dual Grained Quantization: Efficient Fine-grained Quantization for LLM | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6636 | YOLOR-Based Multi-Task Learning | 3.50 | 3.00 | 1.41 | -0.50 | |
| 6637 | Uncovering Time-Invariant Latent Representation for Brain Disorder Diagnosis via Self-Supervised Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6638 | Synergistic Classification and Unknown Discrimination for Open Set Recognition | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6639 | SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6640 | Deterministic Error Bounds for Euclidean Clustering | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6641 | Universal Clustering Bounds | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6642 | Maximum Margin Based Activation Clipping for Post-Training Overfitting Mitigation in DNN Classifiers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6643 | ResTran: A GNN Alternative To Learn Graph With Features | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6644 | One-Hot Encoding Strikes Back: Fully Orthogonal Coordinate-Aligned Class Representations | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6645 | Linear Indexed Minimum Empirical Divergence Algorithms | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6646 | Human-Producible Adversarial Examples | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6647 | Dissecting Zero-Shot Visual Reasoning Capabilities in Vision and Language Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6648 | Improving Compositional Text-to-image Generation with Large Vision-Language Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6649 | Long BERT for bankruptcy prediction | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6650 | Identifiable Representation Learning via Architecture Equivariances | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6651 | Symmetry-preserving graph attention network to solve routing problems at multiple resolutions | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6652 | Detailed 3D Face Reconstruction in Full Pose Range | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6653 | TuneMV3D: Tuning Foundational Image Diffusion Models for Generalizable and Scalable Multiview 3D Generation | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6654 | Heterogeneous Domain Generalization for Single-Source Cross-Dataset Person ReID: An Adaptive Adversarial Augmentation Approach | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6655 | Provable Dynamic Regularization Calibration | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6656 | Hot PATE: Private Aggregation of Distributions for Diverse Tasks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6657 | Entropy-enhanced context-aware event prediction based on ontology and external knowledge | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6658 | Task Regularized Hybrid Knowledge Distillation For Incremental Object Detection | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6659 | Communication Efficient Federated Representation Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6660 | Network calibration under domain shift based on estimating the target domain accuracy | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6661 | Analysis of Task Transferability in Large Pre-trained Classifiers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6662 | Chunking: Forgetting Matters in Continual Learning even without Changing Tasks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6663 | Ensembler: Combating model inversion attacks using model ensemble during collaborative inference | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6664 | TransFusion: Contrastive Learning with Attention Layers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6665 | NDIM: Neuronal Diversity Inspired Model for Multisensory Emotion Recognition | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6666 | Block-operations: Creating an Inductive Bias to Route Data and Reuse Subnetworks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6667 | What Large Language Models Bring to Text-oriented VQA? | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6668 | Light-Implicit Uncalibrated Photometric Stereo Network With Fourier Embedding | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6669 | A Hierarchical Reinforcement Learning Based Optimization FrameWork for Large Scale Storage Location Assignment Problem | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6670 | Optimal and Generalizable Multimodal Representation Learning Framework through Adaptive Graph Construction | 3.00 | 3.50 | 0.87 | 0.50 | |
| 6671 | WinSyn: A High Resolution Testbed for Synthetic Data | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6672 | Traveling Words: A Geometric Interpretation of Transformers | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6673 | Learning from Fragmentary Multivariate Time Series Data with Scalable Numerical Embedding | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6674 | RRescue: Ranking LLM Responses to Enhance Reasoning Over Context | 3.50 | 3.00 | 0.00 | -0.50 | |
| 6675 | Prompt Space Optimizing Few-shot Reasoning Success with Large Language Models | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6676 | SEFAR: SparsE-FeAture-based Regularization for Fine-Tuning on Limited Downstream Data | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6677 | Human Pose Estimation via Parse Graph of Body Structure | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6678 | Rare Event Probability Learning by Normalizing Flows | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6679 | MOESR: MULTI-OBJECTIVE EVOLUTIONARY ALGORITHM FOR IMAGE SUPER-RESOLUTION | 3.67 | 3.50 | 1.66 | -0.17 | |
| 6680 | Bound and Average: Leveraging Weights as Knowledge for Class Incremental Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6681 | Decoupled Diffusion Models: Image to Zero and Zero to Noise | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6682 | Language as Kernels | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6683 | NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6684 | Rethinking Adversarial Training with Neural Tangent Kernel | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6685 | ViR: Vision Retention Networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6686 | Revealing Hidden Causal Variables and Latent Factors from Multiple Distributions | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6687 | PrACTiS: Perceiver-Attentional Copulas for Time Series | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6688 | Co-learning synaptic delays, weights and adaptation in spiking neural networks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6689 | Boosting Efficiency in Task-Agnostic Exploration Through Causal Knowledge | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6690 | PROSAC: Provably Safe Certification for Machine Learning Models under Adversarial Attacks | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6691 | On the Role of Riemannian Metric in Isometric Representation Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6692 | Offline Robustness of Distributional Actor-Critic Ensemble Reinforcement Learning | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6693 | Decoupled Prioritized Resampling: Advancing Offline RL with Improved Behavior Policy | 3.50 | 3.50 | 1.66 | 0.00 | |
| 6694 | REVO-LION: Evaluating and Refining Vision-Language Instruction Tuning Datasets | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6695 | Realistic Evaluation of Test-Time Adaptation: Surrogate-Based Model Selection Strategies | 3.50 | 3.50 | 0.87 | 0.00 | |
| 6696 | Attributed Graph Clustering via Coarsening with Modularity | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 3, 5, 3 | | 3, 3, 3, 5, 3 |
|
| 6697 | Integrated Model Explanations by Independent and Collaborative Feature Influence via Linear-Nonlinear Perspectives. | 3.40 | 3.40 | 0.80 | 0.00 | | 5, 3, 3, 3, 3 | | 5, 3, 3, 3, 3 |
|
| 6698 | LLMatic: Neural Architecture Search via Large Language Models and Quality Diversity Optimization | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 5, 3, 3, 3 | | 3, 5, 3, 3, 3 |
|
| 6699 | ScoreFlow: Bridging Score and Neural ODE for Reversible Generative Modeling | 3.40 | 3.40 | 1.50 | 0.00 | | 3, 3, 5, 5, 1 | | 3, 3, 5, 5, 1 |
|
| 6700 | Weight Uncertainty in Individual Treatment Effect | 3.40 | 3.40 | 1.50 | 0.00 | | 3, 5, 3, 1, 5 | | 3, 5, 3, 1, 5 |
|
| 6701 | SOLVING SCHRODINGER BRIDGE PROBLEM VIA STOCHASTIC ACTION MINIMIZATION | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 5, 3, 3, 3 | | 3, 5, 3, 3, 3 |
|
| 6702 | Playing repeated games with Large Language Models | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 5, 3, 3, 3 | | 3, 5, 3, 3, 3 |
|
| 6703 | Demonstration Distillation for Efficient In-Context Learning | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 5, 3, 3, 3 | | 3, 5, 3, 3, 3 |
|
| 6704 | A Conceptual Framework for Analyzing Social Representation in Unstructured Data | 3.40 | 3.40 | 0.80 | 0.00 | | 5, 3, 3, 3, 3 | | 5, 3, 3, 3, 3 |
|
| 6705 | LNL+K: Enhancing Learning with Noisy Labels Through Noise Source Knowledge Integration | 3.40 | 3.40 | 1.50 | 0.00 | | 1, 5, 3, 5, 3 | | 1, 5, 3, 5, 3 |
|
| 6706 | CAUSAL NEURAL NETWORKS FOR CONTINUOUS TREATMENT EFFECT ESTIMATION | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 5, 3, 3, 3 | | 3, 5, 3, 3, 3 |
|
| 6707 | Non-ergodicity in reinforcement learning: robustness via ergodic transformations | 3.40 | 3.40 | 1.50 | 0.00 | | 3, 1, 3, 5, 5 | | 3, 1, 3, 5, 5 |
|
| 6708 | Identifiable State Disentanglement for Reinforcement Learning with Policy Optimality | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 3, 5, 3 | | 3, 3, 3, 5, 3 |
|
| 6709 | Close the Gap: Lightweight Image Captioning via Retrieval Augmentation | 3.60 | 3.40 | 0.80 | -0.20 | | 3, 3, 3, 6, 3 | | 3, 3, 3, 5, 3 |
|
| 6710 | The Cyclical Chaos And Its Equilibrium | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 5, 3, 3, 3 | | 3, 5, 3, 3, 3 |
|
| 6711 | A One-Step MSE Estimation of Models in Production | 3.40 | 3.40 | 0.80 | 0.00 | | 5, 3, 3, 3, 3 | | 5, 3, 3, 3, 3 |
|
| 6712 | Diff-Transfer: Model-based Robotic Manipulation Skill Transfer via Differentiable Physics Simulation | 3.40 | 3.40 | 1.50 | 0.00 | | 5, 5, 3, 1, 3 | | 5, 5, 3, 1, 3 |
|
| 6713 | Normalizing Flows For Out of Distribution Detection via Latent Density Estimation | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 3, 5, 3 | | 3, 3, 3, 5, 3 |
|
| 6714 | FedSRC: Federated Learning with Self-Regulating Clients | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 3, 3, 5 | | 3, 3, 3, 3, 5 |
|
| 6715 | Byzantine-Robust Dynamic Weighted Aggregation Framework for Optimal Attack Mitigation in Federated Learning | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 3, 3, 5 | | 3, 3, 3, 3, 5 |
|
| 6716 | SuperSNN: Training Spiking Neural Networks with Knowledge from Artificial Neural Networks | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 3, 3, 5 | | 3, 3, 3, 3, 5 |
|
| 6717 | Unsupervised Learning via Network-Aware Embeddings | 3.00 | 3.40 | 1.50 | 0.40 | | 3, 5, 3, 3, 1 | | 3, 5, 5, 3, 1 |
|
| 6718 | Correcting Flaws in Common Disentanglement Metrics | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 5, 3, 3 | | 3, 3, 5, 3, 3 |
|
| 6719 | Knowledge Transfer through Value Function for Compositional Tasks | 3.40 | 3.40 | 0.80 | 0.00 | | 3, 3, 5, 3, 3 | | 3, 3, 5, 3, 3 |
|
| 6720 | OmniMixup: Generalize Mixup with Mixing-Pair Sampling Distribution | 3.40 | 3.40 | 1.50 | 0.00 | | 3, 3, 5, 1, 5 | | 3, 3, 5, 1, 5 |
|
| 6721 | Asynchronous Graph Generators | 3.00 | 3.40 | 0.80 | 0.40 | |
| 6722 | Continuous Multi-step Predictions of Highly Imbalanced Multivariate Time Series via Deep Learning Network | 3.25 | 3.40 | 1.50 | 0.15 | |
| 6723 | FedOD: Federated Outlier Detection via Neural Approximation | 3.33 | 3.33 | 2.05 | 0.00 | |
| 6724 | SafeDiffuser: Safe Planning with Diffusion Probabilistic Models | 4.00 | 3.33 | 2.05 | -0.67 | |
| 6725 | Unlocking the Potential of Federated Learning for Deeper Models | 3.33 | 3.33 | 2.05 | 0.00 | |
| 6726 | Freenets: Learning Layerfree Neural Network Topologies | 3.33 | 3.33 | 2.05 | 0.00 | |
| 6727 | Indeterminate Probability Theory | 3.00 | 3.33 | 2.05 | 0.33 | |
| 6728 | Cross-Task Gradient Harmonization for Meta-Learning | 3.33 | 3.33 | 0.75 | 0.00 | | 3, 3, 3, 3, 3, 5 | | 3, 3, 3, 3, 3, 5 |
|
| 6729 | The Map Equation goes Neural | 2.33 | 3.33 | 2.05 | 1.00 | |
| 6730 | Limits to Reservoir Learning | 3.33 | 3.33 | 2.05 | 0.00 | |
| 6731 | Matrix and Tensor Completion with Noise via Low-rank Deconvolution | 3.33 | 3.33 | 2.05 | 0.00 | |
| 6732 | Real-time computer vision on low-end boards via clustering motion vectors | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6733 | AdaLomo: Low-memory Optimization with Adaptive Learning Rate | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6734 | Physics-informed neural networks for transformed geometries and manifolds | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6735 | Fair Domain Generalization with Arbitrary Sensitive Attributes | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6736 | ZGS-Based Event-Driven Algorithms for Bayesian Optimization in Fully Distributed Multi-Agent Systems | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6737 | Towards Understanding The Winner-Take-Most Behavior Of Neural Network Representations | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6738 | Concept Alignment as a Prerequisite for Value Alignment | 4.00 | 3.25 | 1.79 | -0.75 | |
| 6739 | Temporal graph models fail to capture global temporal dynamics | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6740 | Robust Reinforcement Learning for Portfolio Management via Competition and Cooperation Strategies | 3.25 | 3.25 | 0.66 | 0.00 | | 5, 3, 3, 3, 3, 3, 3, 3 | | 5, 3, 3, 3, 3, 3, 3, 3 |
|
| 6741 | Training-Free Generalization on Heterogeneous Tabular Data via Meta-Representation | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6742 | A Latent Space Theory for Emergent Abilities in Large Language Models | 3.33 | 3.25 | 1.79 | -0.08 | |
| 6743 | Crystals with Transformers on Graphs, for predictions of crystal material properties | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6744 | A counterfactual-based approach to prevent crowding in intelligent subway systems | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6745 | Low-Rank Robust Graph Contrastive Learning | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6746 | Towards Efficient Trace Estimation for Optimal Transport in Domain Adaptation | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6747 | Efficient OCR for Building a Diverse Digital History | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6748 | Divergence at the Interpolation Threshold: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6749 | RL Simplex: Bringing Computational Efficiency in Linear Programming via Reinforcement Learning | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6750 | Domain Prompt Matters a Lot in Multi-Source Few-Shot Domain Adaptation | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6751 | CropNet: An Open Large-Scale Dataset with Multiple Modalities for Climate Change-aware Crop Yield Predictions | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6752 | Prediction-Consistent Koopman Autoencoders | 3.25 | 3.25 | 2.86 | 0.00 | |
| 6753 | Structure-Rich Text Benchmark for Knowledge Inference Evaluation | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6754 | Gauging Learnability in Supervised Fine-tuning Data | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6755 | Text-To-Energy: Accelerating Quantum Chemistry Calculations through Enhanced Text-to-Vector Encoding and Orbital-Aware Multilayer Perceptron | 3.25 | 3.25 | 2.86 | 0.00 | |
| 6756 | Teach Large Language Models the Concept of Meta-cognition to Reduce Hallucination Text Generation | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6757 | SEMANTIC RHEOLOGY: THE FLOW OF IDEAS IN LANGUAGE MODELS | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6758 | LeBD: A Run-time Defense Against Backdoor Attack in YOLO | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6759 | Tracking the Change of Knowledge Through Layers in Neural Networks | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6760 | Can Neural Networks Improve Classical Optimization of Inverse Problems? | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6761 | CASR: Refining Action Segmentation via marginalizing frame-level causal relationships | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6762 | What Images are More Memorable to Machines? | 3.25 | 3.25 | 1.79 | 0.00 | |
| 6763 | Prompt2Rec : Prompt based user and item Re-characterizing method for Recommendation | 3.20 | 3.20 | 1.60 | 0.00 | | 3, 1, 6, 3, 3 | | 3, 1, 6, 3, 3 |
|
| 6764 | On the Onset of Robust Overfitting in Adversarial Training | 3.20 | 3.20 | 1.60 | 0.00 | | 1, 3, 3, 3, 6 | | 1, 3, 3, 3, 6 |
|
| 6765 | Causal Structure Learning Supervised by Large Language Model | 3.20 | 3.20 | 1.60 | 0.00 | | 1, 3, 3, 3, 6 | | 1, 3, 3, 3, 6 |
|
| 6766 | Learning from A Single Graph is All You Need for Near-Shortest Path Routing | 3.17 | 3.17 | 1.46 | 0.00 | | 3, 1, 3, 6, 3, 3 | | 3, 1, 3, 6, 3, 3 |
|
| 6767 | Temporal Parallelization for GPU Acceleration of Spiking Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6768 | SIMULTANEOUS GENERATION AND IMPROVEMENT: A UNIFIED RL PARADIGM FOR FJSP OPTIMIZATION | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6769 | 3D Molecular Pretraining via Localized Geometric Generation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6770 | Causal Impact Index: A Causal Formulation of Citations | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6771 | Node-CwR: Node Classification with Reject Option | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6772 | Segment Anything Meets Universal Adversarial Perturbation | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6773 | A Weakly Supervised and Globally Explainable Learning Framework for Brain Tumor Segmentation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6774 | AN ENTROPY PERSPECTIVE IN KNOWLEDGE DISTILLATION | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6775 | Universal Algorithm for Extreme Bandits with the Minimal Complexities | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6776 | Brain-inspired Geometry Constrain on Represention for Compositional Generalization | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6777 | Residual Factorized Fourier Neural Operator for simulation of three-dimensional turbulence | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6778 | Disentangling Covariates to Predict Counterfactuals for single-cell data | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6779 | Can General-Purpose Language Models Emulate a General-Purpose Computer In-Context? | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6780 | The KNN Score for Evaluating Probabilistic Multivariate Time Series Forecasting | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6781 | Feature Selection in the Presence of Monotone Batch Effects | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6782 | TPA-Gen: A Multi-modal Data Generative Method for Text and Physics-based Animation | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6783 | DFITE: Estimation of Individual Treatment Effect Using Diffusion Model | 3.40 | 3.00 | 1.26 | -0.40 | | 3, 3, 3, 5, 3 | | 3, 3, 1, 5, 3 |
|
| 6784 | An Explainable AI-based Complementary Attention Mechanism for Detecting Identity Swaps | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6785 | Moral High Ground: A text-based games benchmark for moral evaluation | 3.00 | 3.00 | 2.00 | 0.00 | |
| 6786 | Achieving Certified Robustness and Maintaining Clean Accuracy via Vanilla Model Guide | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6787 | Referring Expression Matters: Multi-referring Feature Aggregation for Referring Video Object Segmentation | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6788 | Turing Complete Transformers: Two Transformers Are More Powerful Than One | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6789 | Flexible Diffusion for Graph Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6790 | Open-Ended Learning in General-Sum Games: The Role of Diversity in Correlated Equilibrium | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6791 | Learning Boolean functions with neural networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6792 | Emergent Corpus Pretraining Benefits Vision Language Modeling | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6793 | Fairness-enhancing mixed effects deep learning improves fairness on in- and out-of-distribution clustered (non-iid) data | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6794 | Improving Large Language Model Fine-tuning for Solving Math Problems | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6795 | Ensemble Systems Representation for Function Learning over Manifolds | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6796 | On the Dynamics of Learning Time-Aware Behavior with RNNs | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6797 | Is the Glass Half-Empty or Half-Full? A Mixture-Of-Tasks Perspective on Missing Modality | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6798 | DIG-MILP: a Deep Instance Generator for Mixed-Integer Linear Programming with Feasibility Guarantee | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6799 | Depth From Camera Model | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6800 | Impact of Molecular Representations on Deep Learning Model Comparisons in Drug Response Predictions | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6801 | Auto DP-SGD: Dual Improvements of Privacy and Accuracy via Automatic Clipping Threshold and Noise Multiplier Estimation | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6802 | COTIC: Embracing Non-uniformity in Event Sequence Data via Multilayer Continuous Convolution | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6803 | Bridging the Fairness Divide: Achieving Group and Individual Fairness in Graph Neural Networks | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6804 | GEO: Generative Engine Optimization | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6805 | From gradient attacks to data poisoning | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6806 | G-Local Attention Graph Pooling for Graph Classification | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6807 | Compositional Search of Stable Crystalline Structures in Multi-Component Alloys Using Generative Diffusion Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6808 | Plan-based Prompting Improves Literature Review Generation | 3.00 | 3.00 | 1.26 | 0.00 | | 3, 5, 3, 3, 1 | | 3, 5, 3, 3, 1 |
|
| 6809 | A Theoretical and Empirical Analysis on Reconstruction Attacks and Defenses | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6810 | DynamicsDiffusion: Generating and Rare Event Sampling of Molecular Dynamic Trajectories Using Diffusion Models | 3.00 | 3.00 | 0.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
|
| 6811 | Machine learning pipelines synthesis with large language models | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6812 | Towards Deep Viticultural Representations: Joint Region and Grape Variety Embeddings | 2.50 | 3.00 | 0.00 | 0.50 | |
| 6813 | Travelling Salesman Problem Goes Sparse With Graph Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6814 | Simplifying GNN Performance with Low Rank Kernel Models | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6815 | SurroCBM: Concept Bottleneck Surrogate Models for Joint Unsupervised Concept Discovery and Post-hoc Explanation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6816 | Algorithm Design for Learned Algorithms | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6817 | Learning Dynamics on Manifolds with Neural Ordinary Differential Equations | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6818 | Certified Copy: A Resistant Backdoor Attack | 3.00 | 3.00 | 1.07 | 0.00 | | 1, 3, 3, 3, 3, 5, 3 | | 1, 3, 3, 3, 3, 5, 3 |
|
| 6819 | Detecting Shortcuts using Mutual Information | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6820 | Towards Adversarially Robust Condensed Dataset by Curvature Regularization | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6821 | Robot Learning from Demonstration: Enhancing Plan Execution with Failure Detection Model | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6822 | Controllable Pareto Trade-off between Fairness and Accuracy | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6823 | Dynamic Assortment Selection and Pricing with Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6824 | Towards Meta-Models for Automated Interpretability | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6825 | Reason to Behave: Achieving Human-Like Task Execution for Physics-Based Characters | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6826 | Orthogonal Sequential Fusion in Multimodal Learning | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6827 | Fake News Detection via an Adaptive Feature Matching Optimization Framework | 3.50 | 3.00 | 0.00 | -0.50 | |
| 6828 | HIWE: Scene Importance Weighted Encoding For Fast Neural Radiance Field Training | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6829 | Learning Successor Representations with Distributed Hebbian Temporal Memory | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6830 | BaDLoss: Backdoor Detection via Loss Dynamics | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6831 | Bit Cipher — A Simple yet Powerful Word Representation System that Integrates Efficiently with Language-Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6832 | INCYDE: A large scale cyclone detection and intensity estimation dataset using satellite infrared imagery | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6833 | Red Pill or Blue Pill? Thresholding Strategies for Neural Network Monitoring | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6834 | Informing Reinforcement Learning Agents by Grounding Natural Language to Markov Decision Processes | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6835 | Heterogeneous Value Alignment Evaluation for Large Language Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6836 | Transformers Perform In-Context Learning through Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6837 | M-IDAS: MULTI-MODAL INTRUSION DETECTION AND ANALYTIC SYSTEM | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6838 | Humans vs ChatGPT: Uncovering the Non-trivial Distinctions by Evaluating Parallel Responses | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6839 | MapSelect: Sparse & Interpretable Graph Attention Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6840 | OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6841 | MAAD Private: Multi-Attribute Adversarial Debiasing with Differential Privacy | 3.00 | 3.00 | 0.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
|
| 6842 | Dantzig-Wolfe Decomposition and Deep Reinforcement Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6843 | Fully Hyperbolic Representation Learning on Knowledge Hypergraph | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6844 | On the Relation between Gradient Directions and Systematic Generalization | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6845 | Discovering Minimal Reinforcement Learning Environments | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6846 | Early Weight Averaging Meets High Learning Rates for LLM Pre-training | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6847 | Language-Conditioned Imitation Learning With Base Skill Priors Under Unstructured Data | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6848 | Universally Amplifying Randomized Smoothing for Certified Robustness with Anisotropic Noise | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6849 | PowerGPT: Foundation Model for Power Systems | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6850 | Efficient PDE Solutions using Hartley Neural Operators in Physics-Informed Networks: Potentials and Limitations | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6851 | Fairness Feedback Loops: Training on Synthetic Data Amplifies Bias | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6852 | Hybrid Classification-Regression Adaptive Loss for Dense Object Detection | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6853 | Online Learning in Varying Feature Spaces with Informative Variation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6854 | An Axiomatic Approach to Model-Agnostic Concept Explanations | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6855 | Enhanced Bayesian Optimization via Preferential Modeling of Abstract Properties | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6856 | Evaluating Adversarial Defense in the Era of Large Language Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6857 | SuperFormer: Superpixel-based Transformers for Salient Object Detection | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6858 | Always-Sparse Training with Guided Stochastic Exploration | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6859 | VibeSpace: Automatic vector embedding creation for arbitrary domains and mapping between them using large language models | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6860 | Time Series Modeling at Scale: A Universal Representation Across Tasks and Domains | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6861 | EXPLORING BATTERY USAGE IN ELECTRIC VEHICLES THROUGH GRAPH BASED CASCADED CLUSTERING | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6862 | A GRAPH-BASED REPRESENTATION LEARNING APPROACH FOR BREAST CANCER RISK PREDICTION USING GENOTYPE DATA | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6863 | Three ways that non-differentiability affects neural network training | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6864 | Towards Explainable and Efficient Multi-Modality Learning: Domain-Agnostic Concept Space Paired with Domain-Specific Projection Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6865 | Online Weight Approximation for Continual Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6866 | Unsupervised Learning Based Object Detection Using Contrastive Learning | 3.00 | 3.00 | 1.15 | 0.00 | | 3, 3, 5, 3, 1, 3 | | 3, 3, 5, 3, 1, 3 |
|
| 6867 | XAI Procedural Fairness Auditing Framework: avoid misguided outcomes by refocusing on fairness properties | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6868 | Simple-TTS: End-to-End Text-to-Speech Synthesis with Latent Diffusion | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6869 | Don't forget private retrieval: distributed private similarity search for large language models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6870 | Neural Optimizer Equation, Decay Function, and Learning Rate Schedule Joint Evolution | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6871 | ARE YOU CERTAIN THAT IT IS A DEEPFAKE? DETECTION, GENERATION, AND SOURCE DETECTION FROM AN UNCERTAINTY PERSPECTIVE | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6872 | Sparling: Learning Latent Representations With Extremely Sparse Activations | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6873 | An Invariant Information Geometric Method for High-dimensional Online Optimization | 3.67 | 3.00 | 2.00 | -0.67 | |
| 6874 | Explicit Foundation Model Optimization with Self-Attentive Feed-Forward Neural Units | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6875 | DPAF: Image Synthesis via Differentially Private Aggregation in Forward Phase | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6876 | Generalized Category Discovery with Hierarchical Label Smoothing | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6877 | Visual Topics via Visual Vocabularies | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6878 | Anomaly Detection with Variance Stabilized Density Estimation | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6879 | Inductive Link Prediction in Knowledge Graphs using Path-based Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6880 | Learning Fair Representations with High-Confidence Guarantees | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6881 | CLAM: Class-wise Layer-wise Attribute Model for Explaining Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6882 | InfoNet: Missing Information Retrieval in Multi-Stream Sensing Systems | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6883 | Factorized Neural Radiance Field with Depth Covariance Function for Dense RGB Mapping | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6884 | SSC Layer - A replacement for convolutional layers | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6885 | Hyperion: Fused Multi-Trial and Gradient Descent for Joint Hyperparameter and Neural Architecture Optimization | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6886 | Asymmetric Momentum: A Rethinking of Gradient Descent | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6887 | How far can we go without finetuning? | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6888 | Language Decision Transformers with Exponential Tilt for Interactive Text Environments | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6889 | Learning Multi-Objective Program Through Online Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6890 | Regulating the level of manipulation in text augmentation with systematic adjustment and advanced sentence-embedding | 3.25 | 3.00 | 1.41 | -0.25 | |
| 6891 | Ask Your Distribution Shift if Pre-Training is Right for You | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6892 | Homotopy Relaxation Training Algorithms for Infinite-Width Two-Layer ReLU Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6893 | Data Distribution Valuation with Incentive Compatibility | 2.00 | 3.00 | 1.63 | 1.00 | |
| 6894 | Learning Multi-modal Representations Under Incomplete Data Via Dual Level Alignments | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6895 | DAG-based Generative Regression | 3.00 | 3.00 | 0.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
|
| 6896 | Central Force Field: Unifying Generative and Discriminative Models While Harmonizing Energy-Based and Score-Based Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6897 | Afterstate Reinforcement Learning for Continuous Control | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6898 | LARG2, Language-based Automatic Reward and Goal Generation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6899 | Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6900 | Bias Resilient Multi-Step Off-Policy Goal-Conditioned Reinforcement Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6901 | Contrastive Grouping-based Invariant Learning for Generalizable Graph Learning | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6902 | Bayesian Uncertainty Quantification Meets Topology | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6903 | Domain Generalization Using Large Pretrained Models With Mixture-of-Adapters | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6904 | MPXGAT: An Attention based Deep Learning Model for Multiplex Graphs Embedding | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6905 | Elastic Load Balancing for Dynamic LLMs | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6906 | AFFINE INVARIANCE IN CONTINUOUS-DOMAIN CONVOLUTIONAL NEURAL NETWORKS | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6907 | AnoRand - Deep Learning-Based Semi-Supervised Anomaly Detection with Synthetic Labels | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6908 | Enhancing Weakly Supervised 3D Medical Image Segmentation through Probabilistic-aware Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6909 | Converging and Stabilizing Generative Adversarial Imitation Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6910 | ORBIS: Open Dataset Can Rescue You From Dataset Bias | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6911 | Elephant Neural Networks: Born to Be a Continual Learner | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6912 | Interpreting Reward Models in RLHF-Tuned Language Models Using Sparse Autoencoders | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6913 | Diffusion-Stego: Training-free Diffusion Generative Steganography via Message Projection | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6914 | A Novel Evaluation Framework for Image Inpainting via Multi-Pass Self-Consistency | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6915 | Diffusion Models without Attention | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6916 | Continual Nonlinear ICA-Based Representation Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6917 | Visual Analysis of the Bumpiness and Ruggedness of Residual Neural Network Landscapes | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6918 | ACHIEVING DYNAMIC ACCURACY IN MACHINE-LEARNED CG POTENTIALS BY MODULATING POTENTIAL ENERGY LANDSCAPE | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6919 | Theoretical insights into pseudo-label-based semi-supervised learning: Convergence rate and sample complexity analysis | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6920 | Interpretable word-level context-based sentiment analysis | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6921 | Learning an Inventory Control Policy with General Inventory Arrival Dynamics | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6922 | Stochastic Safe Action Model Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6923 | G-TIGRE: A new generative framework for Multivariate Time Series Imputation By Graph Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6924 | Hopfield Encoding Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6925 | MoMo: Momentum Models for Adaptive Learning Rates | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6926 | UGradSL: Machine Unlearning Using Gradient-based Smoothed Label | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6927 | Don't Pre-train, Teach Your Small Model | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6928 | WATT FOR WHAT: RETHINKING DEEP LEARNING’S ENERGY-PERFORMANCE RELATIONSHIP | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6929 | Buffered Asynchronous Federated Learning with Local Differential Privacy | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6930 | Using Attention to Weight Particles in Particle Filters | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6931 | Efficient Interactive Preference Learning in Evolutionary Algorithms: Active Dueling Bandits and Active Learning Integration | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6932 | Conservative Reinforcement Learning by Q-function Disagreement | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6933 | Variational Quantum Linear Solver enhanced Quantum Support Vector machine | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6934 | LARGE LANGUAGE MODELS FOR BIOMEDICAL KNOWLEDGE GRAPH CONSTRUCTION | 3.00 | 3.00 | 1.26 | 0.00 | | 1, 5, 3, 3, 3 | | 1, 5, 3, 3, 3 |
|
| 6935 | Learning to focus on target for weakly supervised visual grounding | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6936 | α-Former: Local-Feature-Aware (L-FA) Transformer | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6937 | Simplicity Bias in Overparameterized Machine Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6938 | Beyond Dynamics: Learning to Discover Conservation Principles | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6939 | Balanced Multimodal Learning: An Integrated Framework for Multi-Task Learning in Audio-Visual Fusion | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6940 | A multi-view latent space learning framework via adaptive graph embedding | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6941 | NoiseOut: Learning to Gate Improves Robustness in Deep Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6942 | DeepHandMesh-lite: Learning personalized hand shape using limited data and weak supervision | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6943 | SPFNO: spectral operator learning for PDEs with Dirichlet and Neumann boundary conditions | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6944 | ADAPTER-RL: Adaptation of Any Agent using Reinforcement Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6945 | Intrinsic Mesh CNNs | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6946 | Entropy Voting Between Capsules | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6947 | Time Series Prediction With Events Disturbance Based Causal Representation Learnin | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6948 | D3AD: DYNAMIC DENOISING DIFFUSION PROBABILISTIC MODEL FOR ANOMALY DETECTION | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6949 | Meta-Learning with Personalized Learning Rates for Rapid Task Mastery | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6950 | Improving the Reliability of Large Language Models by Leveraging Uncertainty-Aware In-Context Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6951 | Are Large Language Models Really Robust to Word-Level Perturbations? | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6952 | Cross-domain Recommendation from Implicit Feedback | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6953 | How Neural Networks With Derivative Labels Work: A Neural Tangent Kernel Perspective | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6954 | MG-NeRF: Multimodal Representation Learning for Generalizable NeRF | 3.00 | 2.50 | 1.66 | -0.50 | |
| 6955 | Poor Teaching: Explore and Question Knowledge Distillation under Distribution Shift | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6956 | An Attention-based Approach for Bayesian Optimization with Dependencies | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6957 | A2FC: A FEDERATED ADVANTAGE ACTOR-CRITIC LEARNING APPROACH FOR HETEROGENEOUS ACTION SPACES | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6958 | HyperDisGAN: A Controllable Variety Generative Model Via Hyperplane Distances for Downstream Classifications | 3.00 | 3.00 | 2.00 | 0.00 | |
| 6959 | Operator-theoretic Implicit Neural Representation | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6960 | A Reinforcement Learning Approach to Effective Forecasting of Pediatric Hypoglycemia in Diabetes I Patients: an extended de Bruijn Graph | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6961 | Neural scaling laws for phenotypic drug discovery | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6962 | Gradient-norm Constrained Algorithm on Offline and Online Learning | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6963 | Centroid- and Orientation-aware Feature Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6964 | Federated Learning with Differential Privacy for End-to-End Speech Recognition | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6965 | Large Language Models as Rational Players in Competitive Economics Games | 3.00 | 3.00 | 0.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
|
| 6966 | Tabular Deep-SMOTE: A supervised autoencoder-based minority-oversampling technique for class-imbalanced tabular classification | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6967 | Neural Networks Decoded: Targeted and Robust Analysis of Neural Network Decisions via Causal Explanations and Reasoning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6968 | LOLAMEME: LOGIC, LANGUAGE, MEMORY, MECHANISTIC FRAMEWORK | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6969 | Inductive Transformers: How Large Language Models Form Concepts, And How to Make Them Even Better At It | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6970 | Active Probabilistic Clustering | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6971 | TorSeq: Torsion Sequential Modeling for Molecular 3D Conformation Generation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6972 | Multi-Task Reinforcement Learning with Shared-Unique Features and Task-Aware Prioritized Experience Replay | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6973 | Self-distillation for diffusion models | 3.67 | 3.00 | 0.00 | -0.67 | |
| 6974 | From Images to Connections: Can DQN with GNNs learn the Strategic Game of Hex? | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6975 | CEIR: Concept-based Explainable Image Representation Learning | 3.50 | 3.00 | 0.00 | -0.50 | |
| 6976 | Efficient Multi-Fidelity NAS with Zero-Cost Proxy-Guided Local Search | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6977 | YOLOV6: A SINGLE-STAGE OBJECT DETECTION FRAMEWORK FOR INDUSTRIAL APPLICATIONS | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6978 | SMAFace: Sample Mining Guided Adaptive Loss for Face Recognition | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6979 | Addressing Covariate Shifts with Influence Aware Energy Regularization | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6980 | An Intrinsic Dimension Perspective of Transformers for Sequential Modeling | 3.00 | 3.00 | 1.26 | 0.00 | | 5, 3, 3, 3, 1 | | 5, 3, 3, 3, 1 |
|
| 6981 | DAGCN: Distance-based and Aspect-oriented Graph Convolutional Network for Aspect-based Sentiment Analysis | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6982 | CutSharp: A Simple Data Augmentation Method for Learned Image Compression | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6983 | Unmasking Transformers: A Theoretical Approach to Data Recovery via Attention Weights | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6984 | An Empirical Study of Simplicial Representation Learning with Wasserstein Distance | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6985 | Prompt-Guided Dynamic Network for Image Super Resolution | 4.50 | 3.00 | 0.00 | -1.50 | |
| 6986 | Adversarial Instance Attacks for Interactions between Human and Object | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6987 | Building a Special Representation for the Chinese Ancient Buildings in Diffusion models. | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6988 | Multi-agent Trajectory Prediction with Scalable Diffusion Transformer | 3.67 | 3.00 | 0.00 | -0.67 | |
| 6989 | Exploring Efficient Foundational Multi-modal Models for Video Summarization | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6990 | WL-Tree: a New Tool for Analyzing Graph Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6991 | Atoms as Words: A Novel Approach to Deciphering Material Properties using NLP-inspired Machine Learning on Crystallographic Information Files (CIFs) | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6992 | Certainty In, Certainty Out: REVQCs for Quantum Machine Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6993 | How Does RLHF Shift Behavior Distributions? Distinguishability and Steerability | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6994 | Enhancing Vision-Language Prompt Learning through Image-Text Distribution Alignment | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6995 | Towards Understanding Masked Distillation | 3.50 | 3.00 | 1.41 | -0.50 | |
| 6996 | Test Relative Fairness in Human Decisions With Machine Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 6997 | Cross-Modality Masked Pre-training for Visible-Infrared Person Re-identification | 3.00 | 3.00 | 1.63 | 0.00 | |
| 6998 | FMM-Head: Enhancing Autoencoder-based ECG anomaly detection with prior knowledge | 3.00 | 3.00 | 1.41 | 0.00 | |
| 6999 | Advective Diffusion Transformers for Topological Generalization in Graph Learning | 4.25 | 3.00 | 0.00 | -1.25 | |
| 7000 | VIPER: Vibrant Period Representation for Robust and Efficient Time Series Forecasting | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7001 | Generalizable Deep RL-Based TSP Solver via Approximate Invariance | 3.00 | 3.00 | 1.41 | 0.00 | |
| 7002 | LEA: Learning Latent Embedding Alignment Model for fMRI Decoding and Encoding | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7003 | Ligand Conformation Generation: from singleton to pairwise | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7004 | Imagination Mechanism: Mesh Information Propagation for Enhancing Data Efficiency in Reinforcement Learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7005 | IMO: Greedy Layer-Wise Sparse Representation Learning for Out-of-Distribution Text Classification with Pre-trained Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7006 | Cognitive Modeling for Human-Robot Value Soft Alignment | 3.00 | 3.00 | 1.63 | 0.00 | |
| 7007 | RoBERT: Low-Cost Bi-Directional Sequence Model for Flexible Robot Behavior Control | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7008 | Time Series Missing Imputation with Multivariate Radial Based Function Neural Network | 3.00 | 3.00 | 1.63 | 0.00 | |
| 7009 | Transplant of Perceptrons | 3.00 | 3.00 | 1.41 | 0.00 | |
| 7010 | Fairly Explaining Monotonic Models: a New Shapley Value | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7011 | Maximum Entropy On-Policy Actor-Critic via Entropy Advantage Estimation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7012 | Splatting-based Motion Context Encoding for Deep Video Compression | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7013 | generative adversarial network with hierarchical semantic prompt constrainting clip for high-quality text-to-image synthesis | 3.00 | 3.00 | 1.41 | 0.00 | |
| 7014 | Uniform Approximation of Equivariant/Invariant Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7015 | Fusion over the Grassmannian for High-Rank Matrix Completion | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7016 | Unsupervised Data Generation for Offline Reinforcement Learning: A Perspective from Model | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7017 | Polyak Parameter Ensemble: Exponential Parameter Growth Leads to Better Generalization | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7018 | Biased Binary Attribute Classifiers Ignore the Majority Classes | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7019 | Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7020 | Finite Element Operator Learning for Solving Parametric PDEs without Labeled Data | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7021 | Manifold Kernel Rank Reduced Regression | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7022 | Hybrid Defense Strategy for Face Recognition Model Inversion Attack | 3.00 | 3.00 | 1.63 | 0.00 | |
| 7023 | Solving Robust MDPs through No-Regret Dynamics | 3.00 | 3.00 | 0.00 | 0.00 | | 3, 3, 3, 3, 3 | | 3, 3, 3, 3, 3 |
|
| 7024 | STFormer : Spatial Temporal Spiking Transformer | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7025 | De novo Drug Design using Reinforcement Learning with Dynamic Vocabulary | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7026 | VEGA: Visual Expression Guidance for Referring Expression Segmentation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7027 | To Simulate Neural Organoid: A Framework and A Benchmark based on AI | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7028 | Goal2FlowNet: Learning Diverse Policy Covers using GFlowNets for Goal-Conditioned RL | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7029 | MultiIoT: Towards Large-scale Multisensory Learning for the Internet of Things | 3.00 | 3.00 | 1.63 | 0.00 | |
| 7030 | Individual Fairness as an Extension of Group Fairness | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7031 | Synthetic Data as Validation | 3.00 | 3.00 | 1.26 | 0.00 | | 3, 3, 5, 1, 3 | | 3, 3, 5, 1, 3 |
|
| 7032 | Leveraging Temporal Graph Networks Using Module Decoupling | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7033 | Evolving Neural Network's Weights at Imagenet Scale | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7034 | Zero-shot Inversion Process for Image Attribute Editing with Diffusion Models | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7035 | Towards the Universal Learning Principle for Graph Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7036 | A unified theory of scene representation learning and object representation learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7037 | Learning Rate Re-scheduling for AdaGrad in training Deep Neural Networks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7038 | Action Shapley: A training data selection metric for high performance and cost efficient reinforcement learning | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7039 | Gate-guided and subgraph-aware Bilateral Fusion for Molecular Property Prediction | 3.00 | 3.00 | 1.41 | 0.00 | |
| 7040 | Diffusion Denoising as a Certified Defense Against Clean-Label Poisoning Attacks | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7041 | Clean-NeRF: Defogging using Ray Statistics Prior in Natural NeRFs | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7042 | CResT: Cross-Query Residual Transformer for Object Goal Navigation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7043 | Communication-Efficient Federated Learning via Gradient Distillation | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7044 | Towards Well-distributed Generative Networks Using Adversarial Autoencoders | 3.00 | 3.00 | 0.00 | 0.00 | |
| 7045 | FStega: Fourier Neural Operators for printer-proof steganography | 2.80 | 2.80 | 1.83 | 0.00 | | 1, 3, 6, 3, 1 | | 1, 3, 6, 3, 1 |
|
| 7046 | A Novel Variational Lower Bound For Inverse Reinforcement Learning | 3.25 | 2.75 | 2.05 | -0.50 | |
| 7047 | 3D Diffuser Actor: Multi-task 3D Robot Manipulation with Iterative Error Feedback | 4.25 | 3.75 | 1.92 | -0.50 | |
| 7048 | Self-Supervised Deep Visual Stereo Odometry with 3D-Geometric Constraints | 2.75 | 2.75 | 2.05 | 0.00 | |
| 7049 | STARformer: STructural Attention tRansformer for Long-term Time Series Forecasting | 2.75 | 2.75 | 2.05 | 0.00 | |
| 7050 | How Powerful are Graph Neural Networks with Random Weights? | 2.67 | 2.67 | 2.36 | 0.00 | |
| 7051 | Going Deeper with General and Specific Inductive Bias for Real-Time Stereo Matching | 3.00 | 2.60 | 0.80 | -0.40 | | 3, 3, 3, 1, 5 | | 3, 3, 3, 1, 3 |
|
| 7052 | Operator Learning Meets Numerical Analysis: Improving Neural Networks through Iterative Methods | 2.60 | 2.60 | 0.80 | 0.00 | | 3, 3, 3, 3, 1 | | 3, 3, 3, 3, 1 |
|
| 7053 | Understanding Deep Neural Networks as Dynamical Systems: Insights into Training and Fine-tuning | 2.60 | 2.60 | 1.50 | 0.00 | | 1, 5, 1, 3, 3 | | 1, 5, 1, 3, 3 |
|
| 7054 | Joint Training Does Not Transfer Information between EEG and Image Classifiers | 2.60 | 2.60 | 1.96 | 0.00 | | 1, 1, 1, 5, 5 | | 1, 1, 1, 5, 5 |
|
| 7055 | GNN-based Reinforcement Learning Agent for Session-based Recommendation | 2.50 | 2.60 | 1.50 | 0.10 | |
| 7056 | Solving (partial) unbalanced optimal transport via transform coefficients and beyond | 2.60 | 2.60 | 0.80 | 0.00 | | 3, 3, 1, 3, 3 | | 3, 3, 1, 3, 3 |
|
| 7057 | Visuo-emotional perception and Human Cognition to engineer content-generation using Generative AI | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7058 | Metanetwork: A novel approach to interpreting ANNs | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7059 | Tracking Cognitive Development of Large Language Models | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7060 | Stealing the Invisible: Unveiling Pre-Trained CNN Models through Adversarial Examples and Timing Side-Channels | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7061 | LST-Bench:A Benchmark for long sequence time-series forecasting Task | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7062 | Nonlinear Inference Learning for Differentially Private Massive Data | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7063 | Optimal spherical codes for locality-sensitive hashing | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7064 | Efficient Backdoor Mitigation in Federated Learning with Contrastive Loss | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7065 | Patch Ranking Map: Explaining Relations among Top-Ranked Patches, Top-Ranked Features and Decisions of Convolutional Neural Networks for Image Classification | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7066 | Transforming Smallholder Farmers Support with an AI-Powered FAQbot: A Comparison of Techniques | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7067 | Multi-timestep models for Model-based Reinforcement Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7068 | Robustness to Multi-Modal Environment Uncertainty in MARL using Curriculum Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7069 | A Novel Autoencoder Based Approach for Counterfactual Estimation Using Sparsity Constraints | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7070 | Exploring the Edge of Stability: Insights from a Fine-Grained Analysis of Gradient Descent in Shallow ReLU Networks | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7071 | Using Approximate Models for Efficient Exploration in Reinforcement Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7072 | PLPP: PROMPT LEARNING WITH PERPLEXITY FOR VISION-LANGUAGE MODELS | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7073 | Interactive Semantic Map Representation for Skill-based Visual Object Navigation | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7074 | Reducing the Need for Backpropagation and Discovering Better Optima With Explicit Optimizations of Neural Networks | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7075 | Exploring the Limitations of Graph-based Logical Reasoning in Large Language Models | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7076 | Tube Loss: A Novel Approach for High Quality Prediction Interval Estimation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7077 | CARENET : A NOVEL ARCHITECTURE FOR LOW DATA REGIME MIXING CONVOLUTIONS AND ATTENTION | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7078 | Post-prediction confidence training complements supervised learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7079 | A Framework for PromptOps in GenAI Application Development Lifecycle | 2.33 | 2.50 | 0.87 | 0.17 | |
| 7080 | Optimal Neural Network Approximation for High-Dimensional Continuous Functions | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7081 | GRADSIMCORE: GRADIENT SIMILARITY BASED REPRESENTATIVE INSTANCES AS CORESET | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7082 | Hybrid Reinforcement Learning for Optimizing Pump Sustainability in Real-World Water Distribution Networks | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7083 | Novel Domain Extrapolation with Large Language Models | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7084 | Don't Reinvent the Steering Wheel | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7085 | Word Importance Explains How Prompts Affect Language Model Outputs | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7086 | Dream to Adapt: Meta Reinforcement Learning by Latent Context Imagination and MDP Imagination | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7087 | Informed weight initialization of Graph Neural Networks and its effect on Oversmoothing | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7088 | Distributed Linear Dimensionality Reduction Assisted by Centralized NN for Classification | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7089 | A Calibrated Simulation for Offline Training of Reinforcement Learning Agents to Optimize Energy and Emission in Office Buildings | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7090 | PeriodNet:Lightweight And Efficient Time Series Prediction Model Based On Periodic Characteristics | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7091 | DOMAIN-GROUNDING OF NEURAL NETWORKS FOR SPATIOTEMPORAL REASONING | 3.25 | 2.50 | 0.87 | -0.75 | |
| 7092 | Enhancing Robustness of Visual Object Localization by Introducing Retina-Inspired Mapping to Convolutional Neural Networks | 3.00 | 2.50 | 0.87 | -0.50 | |
| 7093 | Revealing The Intrinsic Ability of Generative Text Summarizers for Outlier Paragraph Detection | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7094 | Exploring Deep Learning Parameter Space with a-GPS: Approximate Gaussian Proposal Sampler | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7095 | Integrating Visual Cues via Prompting for Low-Resource Multimodal Named Entity Recognition | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7096 | Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games | 3.00 | 2.50 | 0.87 | -0.50 | |
| 7097 | Neural Translation of Input Specifications into Formal Grammars for Test Case Generation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7098 | Detection and Segmentation of Solar Farms in Satellite Imagery: A Study of Deep Neural Network Architectures | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7099 | Counterfactual Image Generation for adversarially robust and interpretable Classifiers | 3.00 | 2.50 | 0.87 | -0.50 | |
| 7100 | Iteration and Stochastic First-order Oracle Complexities of Stochastic Gradient Descent using Constant and Decaying Learning Rates | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7101 | Data Descriptions from Large Language Models with Influence Estimation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7102 | Label Space-Induced Pseudo Label Refinement for Multi-Source Black-Box Domain Adaptation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7103 | DUAL DENOISING LOGICAL REASONING FOR INDUC�TIVE KNOWLEDGE GRAPH COMPLETION | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7104 | Bayesian Pseudo-Coresets via Contrastive Divergence | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7105 | Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7106 | A-Loc: Efficient Alternating Iterative Methods for Locating the $k$ Largest/Smallest Elements in a Factorized Tensor | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7107 | ThEBES: Thorough Energy-Based Evolution Strategy | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7108 | Demystifying the Myths and Legends of Nonconvex Convergence of SGD | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7109 | Unsupervised Image-to-Video Domain Adaptation for Fine-Grained Video Understanding | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7110 | ivrit.ai: A Comprehensive Dataset of Hebrew Speech for AI Research and Development | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7111 | Semi-supervised Domain Adaptation via Joint Error based Triplet Alignment | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7112 | Explainable medical image clustering | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7113 | Unsupervised Cognition | 3.00 | 2.50 | 1.66 | -0.50 | |
| 7114 | Knowledge Graph Reasoning with Reinforcement Learning Agent guided by Multi-relational Graph Neural Networks | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7115 | Heterogeneity of Regularization between adjacent periods | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7116 | A Fault Forecasting Approach Using Two-Dimensional Optimization (TDO) | 4.25 | 2.50 | 0.87 | -1.75 | |
| 7117 | Cellular Interplay in COVID-19: Insights from Graph Neural Networks with Multidimensional Edge Features | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7118 | Adversarial enhanced representation for link prediction in multi-layer networks | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7119 | Search and Retrieval in Semantic-Structural Representations of Novel Malware | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7120 | Z-score Normalized SAC Plus Behavioural Cloning for Offline Reinforcement Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7121 | Active Probabilistic Drug Discovery | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7122 | A Self-Supervised Pre-Training Model for Time Series Classification based on Data Pre-Processing | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7123 | Reinforcement Learning based Image Generation via Visual Consensus Evaluation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7124 | Gated Attention Bins for Depth Estimation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7125 | Reinforcement Learning for Control with Stability Guarantee | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7126 | Efficient Low-Rank Diffusion Model Training for Text-to-Image Generation | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7127 | Multi-Vision Multi-Prompt for Few-Shot Learning in Vision-Language Model | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7128 | Unsupervised Representation Learning to Aid Semi-Supervised Meta Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7129 | Meta-Tasks: Improving Robustness in Few-Shot Classification with Unsupervised and Semi-Supervised Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7130 | How Out-of-Distribution important is | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7131 | A PERSPECTIVE OF IMPROPER DYNAMICS ON OFFLINE MODEL-BASED PLANNING | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7132 | Hypothesis- and Structure-based prompting for medical and business diagnosis | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7133 | A Logical Framework for Verification of AI Fairness | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7134 | Efficient Offline Preference-Based Reinforcement Learning with Transition-Dependent Discounting | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7135 | Wide Neural Network Training Dynamics for Reinforcement Learning | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7136 | Guided Sketch-Based Program Induction by Search Gradients | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7137 | Specializing SAM: Online Adaptation of the Segment Anything Model for Interactive Segmentation in Uncommon Situations | 2.50 | 2.50 | 1.66 | 0.00 | |
| 7138 | RetinexGAN Enables More Robust Low-Light Image Enhancement Via Retinex Decomposition Based Unsupervised Illumination Brightening | 2.50 | 2.50 | 0.87 | 0.00 | |
| 7139 | Boosted Long Short-Term Memory with Additional Inner Layers | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7140 | Contrastive Implicit Representation Learning | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7141 | Neural Bounds on Bayes Error: Advancing Classification and Generative Models | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7142 | Improving classifier decision boundaries using nearest neighbors | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7143 | Sentiment-Enhanced Stock Price Prediction: A Novel Ensemble Model Approach | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7144 | QualEval: Qualitative Evaluation for Model Improvement | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7145 | Enhancement-Driven Pretraining for Robust Fingerprint Representation Learning | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7146 | Learning with Language Inference and Tips for Continual Reinforcement Learning | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7147 | Enhancing Tropical Cyclone Formation Prediction Using Graph Neural Networks | 2.33 | 2.33 | 1.89 | 0.00 | |
| 7148 | Self-Supervised Pseudodata Filtering for Improved Replay with Sub-Optimal Generators | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7149 | Dual-target Point Cloud Registration Using Representative Overlapping Points | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7150 | Self, Semi and Fully Supervised Training for Autoencoders using Ternary Classification | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7151 | Key point is key in resolving the offline three-dimensional bin packing problem | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7152 | A Vision-free Baseline for Multimodal Grammar Induction | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7153 | Strided Transformers for Partially-Parallelized Inference | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7154 | ENHANCEMENT OF GNN’S EXPRESSIVE POWER VIA RECONSIDERING MODAL LOGIC | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7155 | Understanding Continuous-depth Networks through the Lens of Homogeneous Ricci Flows | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7156 | PQ-VAE: Learning Hierarchical Discrete Representations with Progressive Quantization | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7157 | Weak Correlations as the Underlying Principle for Linearization of Gradient-Based Learning Systems | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7158 | Enhancing Airside Monitoring: Multi-view Approach for Accurate Aircraft Distance-To-Touchdown Estimation in Digital Towers | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7159 | Reinforcement Learning with Extreme Minimum Distribution | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7160 | Non-Parameterized Randomization for Environmental Generalization in Deep Reinforcement Learning | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7161 | Rethinking Texture Patterns in Transformer Neural NetWork for Medical Image Analysis | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7162 | Continuously Volumetric Rendering with Neural Density-Distance Fields | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7163 | A Conservative Image Boundary Extraction Method with Application to the ILM Tumor Surgery | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7164 | SITTO: Single-Image Textured Mesh Reconstruction through Test-Time Optimization | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7165 | GUC: UNSUPERVISED NON-PARAMETRIC GLOBAL CLUSTERING AND ANOMALY DETECTION | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7166 | Feature selection with neural estimation of mutual information | 2.33 | 2.33 | 0.94 | 0.00 | |
| 7167 | PDE-Diffusion: Physic guided diffusion model for solving partial derivative equations | 2.20 | 2.20 | 0.98 | 0.00 | | 3, 3, 3, 1, 1 | | 3, 3, 3, 1, 1 |
|
| 7168 | Deep Reinforcement Learning for Dynamic Capacitated Vehicle Routing Problem | 2.20 | 2.20 | 0.98 | 0.00 | | 3, 1, 1, 3, 3 | | 3, 1, 1, 3, 3 |
|
| 7169 | A Neural Sandbox Framework for Discovering Spurious Concpets in LLM Decisions | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7170 | Faster Maximum Inner Product Search in High Dimensions | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7171 | Projected Subnetworks Scale Adaptation | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7172 | The crossover strategy based on the cellular automata for genetic Algorithms with binary chromosomes population | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7173 | PARAMETER OPTIMIZATION FOR EPIDEMIOLOGICAL MODEL WITH GENETIC ALGORITHM | 1.67 | 2.00 | 1.00 | 0.33 | |
| 7174 | Restorer Guided Diffusion Models for Variational Inverse Problems | 2.50 | 2.00 | 1.00 | -0.50 | |
| 7175 | Automatic Calibration Diagnosis: Interpreting Probability Integral Transform (PIT) Histograms | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7176 | FreeLM: Fine-Tuning-Free Language Model | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7177 | CI-VAE: a Generative Deep Learning Model for Class-Specific Data Interpolation | 2.00 | 1.67 | 0.94 | -0.33 | |
| 7178 | MetaTST: Essential Transformer Components for Time Series Analysis | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7179 | Graph Decoding via Generalized Random Dot Product Graph | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7180 | Improving High-Frequency Details in Cerebellum for Brain MRI Super-Resolution | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7181 | Navigating the Impending Arms Race between Attacks and Defenses in LLMs | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7182 | BiTGNN: prediction of drug-target interactions based on bidirectional transformer and graph neural network on heterogeneous graph | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7183 | CPLLM: Clinical Prediction with Large Language Models | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7184 | A Novel Approach For Adversarial Robustness | 2.00 | 2.00 | 1.00 | 0.00 | |
| 7185 | Improving Learning Conditions for Computer Science Students by Using the Flipped Classroom | 1.80 | 1.80 | 0.98 | 0.00 | | 1, 1, 3, 1, 3 | | 1, 1, 3, 1, 3 |
|
| 7186 | Unleashing the Potential of LLMs for Quantum Computing: A Study in Quantum Architecture Design | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7187 | On Sampling Information Sets to Learn from Imperfect Information | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7188 | Deep Models modelled after human brain boost performance in action classification | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7189 | DISTPAR:TENSOR PARTITIONING FOR DISTRIBUTED NEURAL NETWORK COMPUTING | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7190 | A Pipeline-Based Approach for Object Detection on Resource Constrained Internet of Things Devices | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7191 | Enhancing Machine Learning System Reliability in Healthcare through Uncertainty Estimation and Multi-Modal Learning | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7192 | Multi-Label Generalized Zero Shot Chest Xray Classification Using Feature Disentanglement and Multi-Modal Dictionaries | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7193 | CRL-NET: ACCELERATED MAGNETIC RESONANCE IMAGING RECONSTRUCTION THROUGH COIL REPRESENTATION LEARNING | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7194 | FedHC: Proximal Correction with Hessian and Cosine Correlation for Federated Learning | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7195 | Experimental methodology to evaluate the effectiveness of uncertainty disentanglement on regression models | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7196 | Explaining How a Neural Network Play the Go Game and Let People Learn | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7197 | HarmonyLM: Advancing Unified Large-Scale Language Modeling for Sound and Music Generation | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7198 | Based on What We Can Control Artificial Neural Networks | 1.67 | 1.67 | 0.94 | 0.00 | |
| 7199 | Outliers Memorized Last: Trends in Memorization of Diffusion Models Based on Training Distribution and Epoch | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7200 | Adaptive Memory Module for Sequential Planning and Reasoning | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7201 | LLM-based Stock Market Trend Prediction | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7202 | Long Horizon Episodic Decision Making for Cognitively Inspired Robots | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7203 | TCIG: Two-Stage Controlled Image Generation with Quality Enhancement through Diffusion | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7204 | FENNs: A Resource-Efficient, Adaptive, Privacy-Preserving Decentralized Learning Framework | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7205 | Learning Graph Representation for Model Ensemble | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7206 | Sequential Indeterminate Probability Theory for Multivariate Time Series Forecasting | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7207 | Precision and Recall Reject Curves for Classification | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7208 | Forward Explanation : Why Catastrophic Forgetting Occurs | 1.50 | 1.50 | 0.87 | 0.00 | |
| 7209 | Analyzing Complex Interdependencies in Financial Markets: A Neural Network-Based Approach for News Impact Assessment | 1.00 | 1.00 | 0.00 | 0.00 | |
| 7210 | The Fine-Grained Chip Placement with Hybrid Action Spaces and Feature Fusion | 1.00 | 1.00 | 0.00 | 0.00 | |
| 7211 | Generative AI in healthcare: A trustworthy approach | 1.00 | 1.00 | 0.00 | 0.00 | |
| 7212 | Deep Learning-based Discrimination of Pause Episodes in Insertable Cardiac Monitors | 1.00 | 1.00 | 0.00 | 0.00 | |
| 7213 | Using Machine Learning Models to Predict Genitourinary Involvement Among Gastrointestinal Stromal Tumour Patients | 1.00 | 1.00 | 0.00 | 0.00 | |
| 7214 | Beyond adversarial examples: sampling and repairing diverse failures with RADIUM | 1.00 | 1.00 | 0.00 | 0.00 | |
| 7215 | A path toward primitive machine intelligence: LMM not LLM is what you need. | 1.00 | 1.00 | 0.00 | 0.00 | |
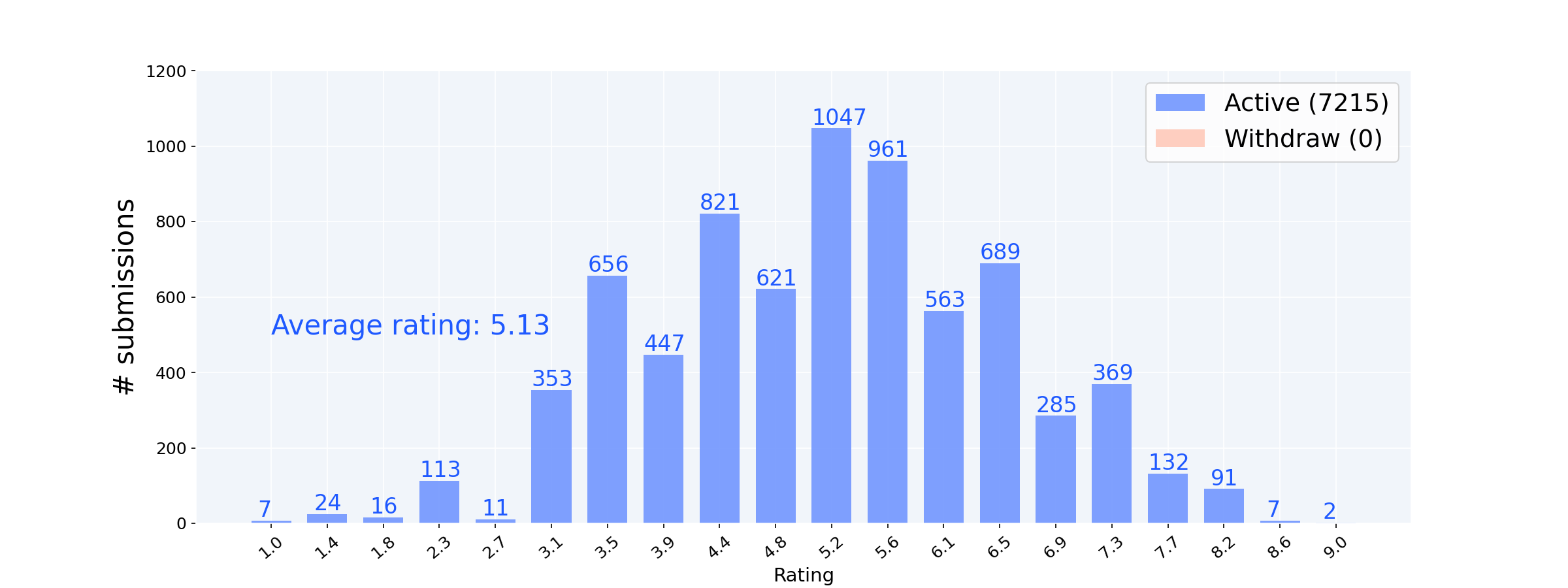
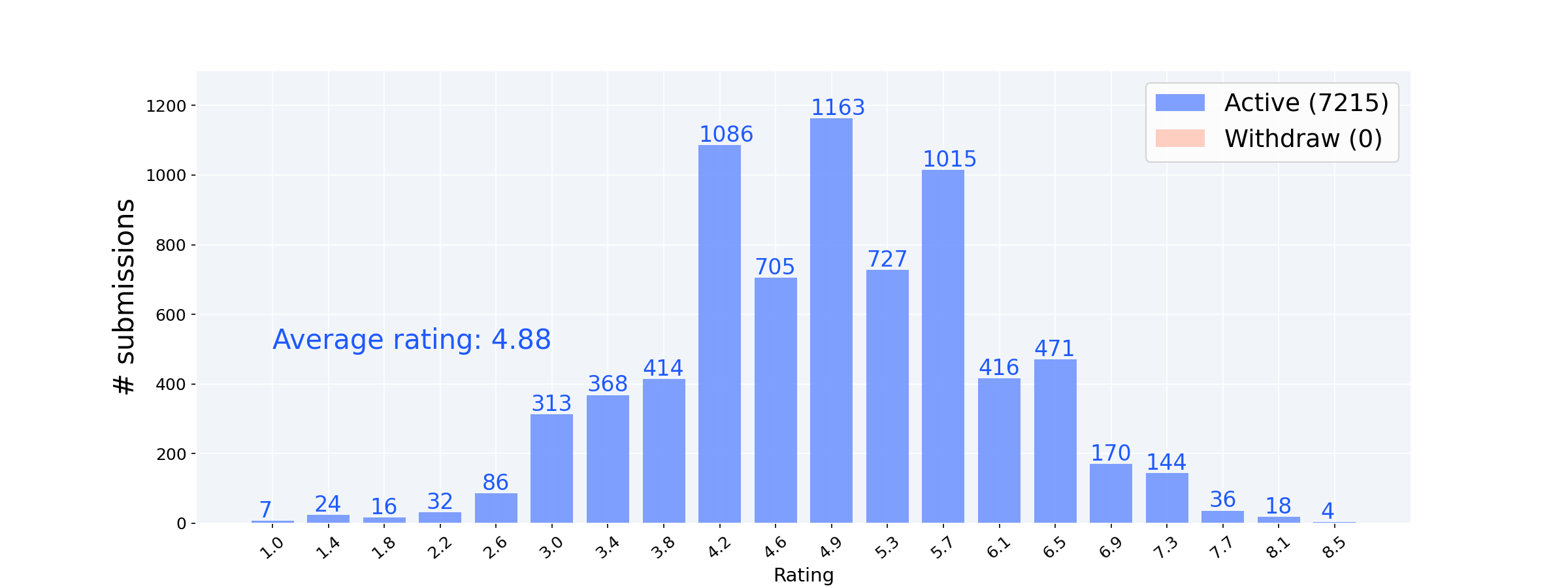
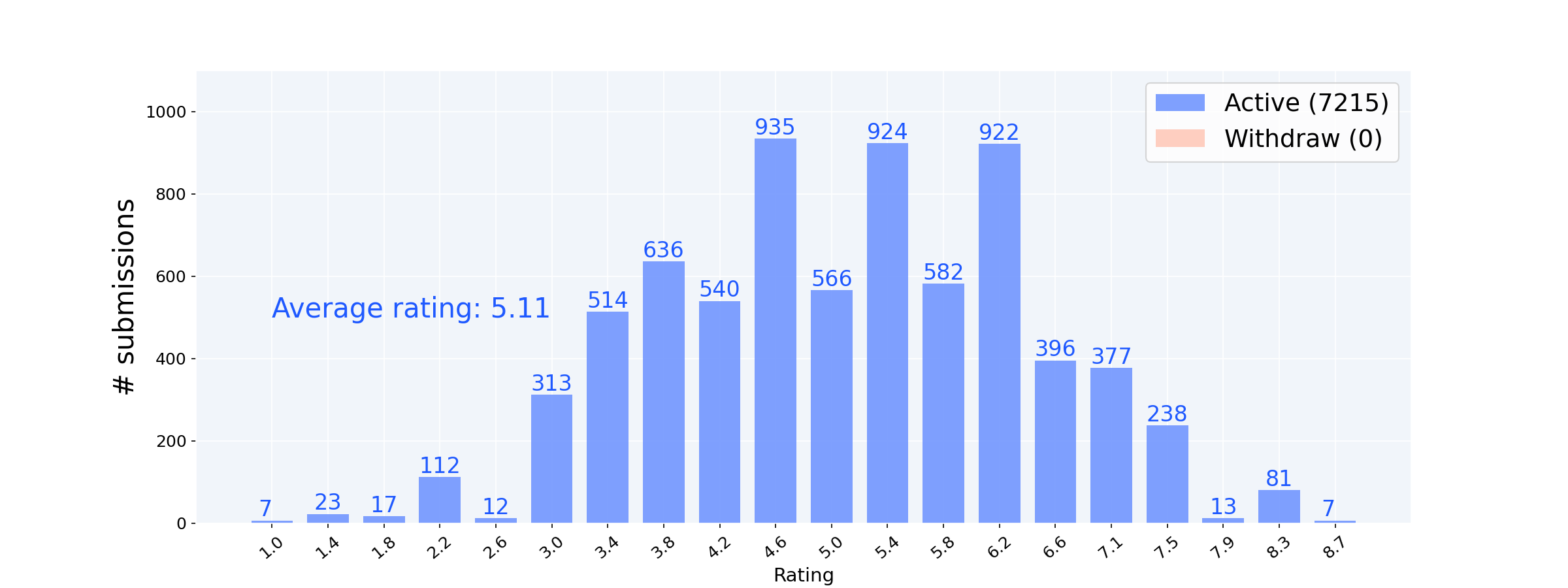{kind=link}